この参照アーキテクチャでは、Azure Batch を使用して R モデルでバッチ スコアリングを実行する方法について説明します。 Azure Batch は、本質的に並列なワークロードに適しており、ジョブのスケジュール設定とコンピューティング管理を含みます。 バッチの推論 (スコアリング) は、顧客のセグメント化、売上の予測、顧客の行動の予測、メンテナンスの予測、またはサイバー セキュリティの向上を目的として広く使用されています。
このアーキテクチャの Visio ファイルをダウンロードします。
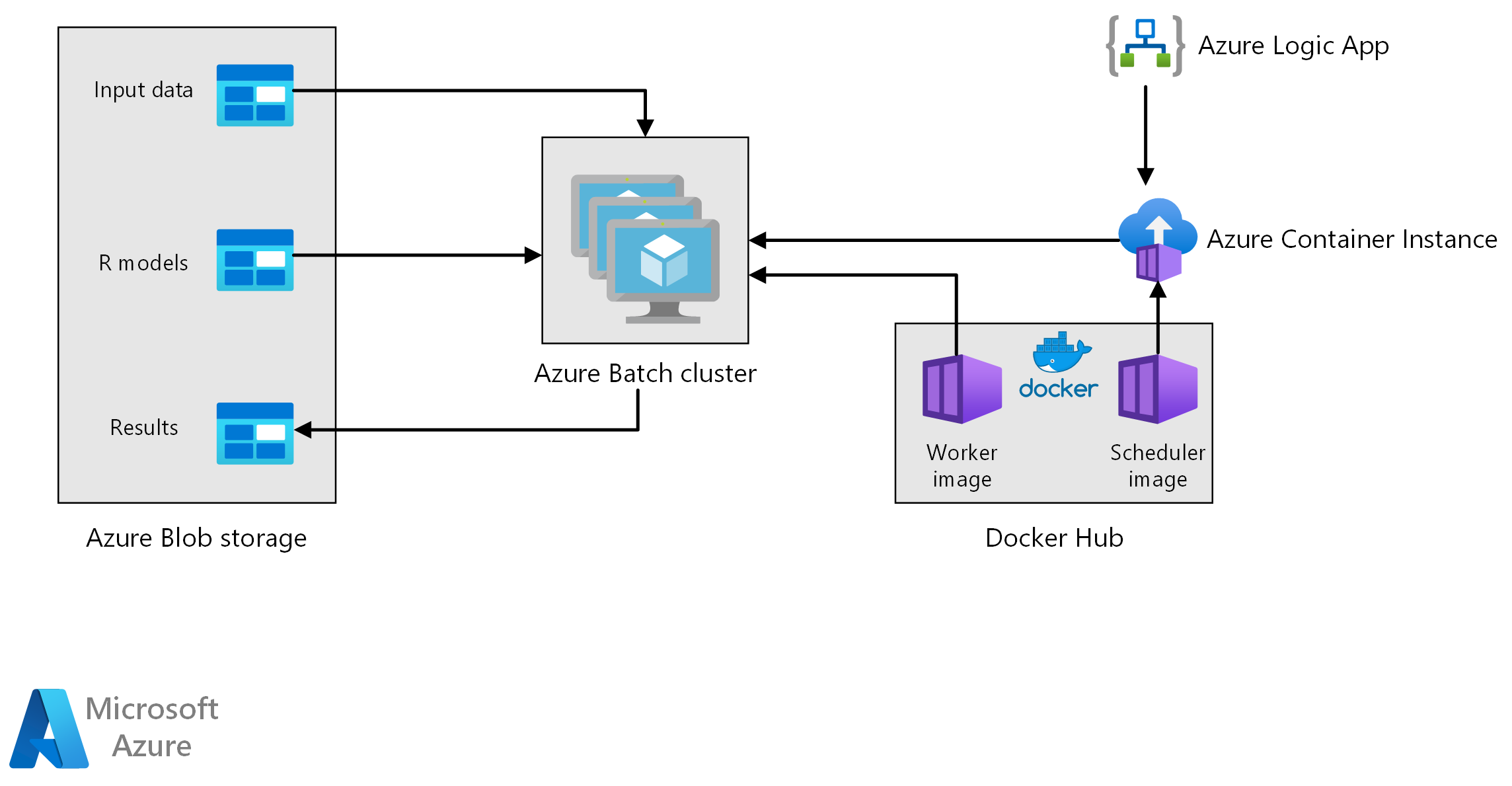
ワークフロー
このアーキテクチャは、次のコンポーネントで構成されます。
Azure Batch は、クラスターまたは仮想マシンで予測生成ジョブを並列に実行します。 予測は、R で実装されたトレーニング済みの機械学習モデルを使用して行われます。Azure Batch は、クラスターに送信されたジョブの数に基づいて VM の数を自動的にスケーリングできます。 各ノードでは、R スクリプトが Docker コンテナー内で実行されてデータのスコアリングが行われ、予測が生成されます。
Azure Blob Storage は、入力データ、事前トレーニング済みの機械学習モデル、および予測結果を格納します。 これは、このワークロードに必要なパフォーマンスに対して費用効率の良いストレージを提供します。
Azure Container Instances は、オンデマンドでサーバーレス コンピューティングを提供します。 このケースでは、スケジュールに基づいてコンテナー インスタンスがデプロイされ、予測を生成する Batch ジョブがトリガーされます。 Batch ジョブは、doAzureParallel パッケージを使用して R スクリプトからトリガーされます。 ジョブが完了すると、コンテナー インスタンスが自動的にシャットダウンされます。
Azure Logic Apps は、スケジュールに基づいてコンテナー インスタンスをデプロイして、ワークフロー全体をトリガーします。 Logic Apps 内の Azure Container Instances コネクターにより、一連のトリガー イベントでインスタンスがデプロイされます。
コンポーネント
ソリューションの詳細
以下のシナリオは小売店の売上予測に基づいていますが、このアーキテクチャは、R モデルを使用した大規模な予測の生成を必要とするどのシナリオ向けにも一般化することができます。 このアーキテクチャの参照実装は、GitHub で入手できます
考えられるユース ケース
あるスーパー マーケット チェーンで、次の四半期の商品売上を予測する必要があります。 この予測により、企業はサプライ チェーンをより的確に管理して、各店舗の商品の需要に確実に対応することができます。 この企業では、毎週、前の週の新しい売上データが利用可能になるたびに予測を更新して、次の四半期のマーケティング戦略が設定されます。 個々の売上予測の不確実性を推測するために分位点予測が生成されます。
処理には次の手順が含まれます。
Azure Logic App が、週に 1 回、予測生成処理をトリガーします。
ロジック アプリは、スケジューラー Docker コンテナーを実行する Azure コンテナー インスタンスを開始し、それにより Batch クラスターでスコアリング ジョブがトリガーされます。
スコアリング ジョブは、Batch クラスターの複数のノードにわたって並列で実行されます。 各ノードは以下のことを実行します。
ワーカー Docker イメージをプルして、コンテナーを開始する。
Azure Blob Storage から入力データと事前トレーニング済みの R モデルを読み取る。
データをスコアリングすることで予測を生成する。
予測結果を Blob Storage に書き込む。
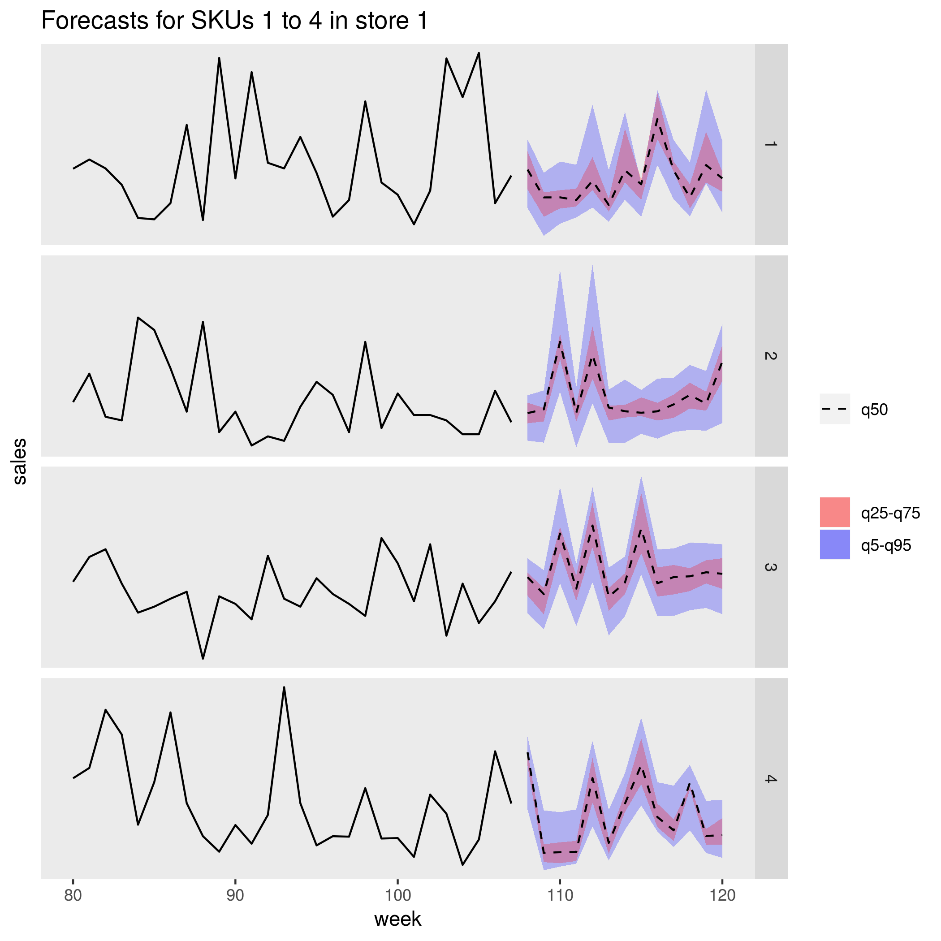
次の図は、ある店舗での 4 つの商品 (SKU) の予測売上を示しています。 黒の線は売上の履歴、破線は中央値 (q50) の予測、ピンク色の部分は 25 パーセンタイルと 75 パーセンタイルを表しており、青色の部分は 50 パーセンタイルと 95 パーセンタイルを表しています。
考慮事項
以降の考慮事項には、ワークロードの品質向上に使用できる一連の基本原則である Azure "Well-Architected Framework" の要素が組み込まれています。 詳細については、「Microsoft Azure Well-Architected Framework」を参照してください。
パフォーマンス
コンテナー化されたデプロイ
このアーキテクチャでは、すべての R スクリプトは Docker コンテナー内で実行されます。 コンテナーを使用することで、スクリプトは毎回、一貫性のある環境で、同じ R バージョンとパッケージ バージョンを使用して実行されます。 スケジューラー コンテナーとワーカー コンテナーには別々の Docker イメージが使用されます。これは、それぞれ異なる R パッケージ依存関係のセットを持っているからです。
Azure Container Instances は、スケジューラー コンテナーを実行するためのサーバーレス環境を提供します。 スケジューラ コンテナーは、Azure Batch クラスターで実行される個々のスコアリング ジョブをトリガーする R スクリプトを実行します。
Batch クラスターの各ノードは、スコアリング スクリプトを実行するワーカー コンテナーを実行します。
ワークロードを並列化する
R モデルでデータのバッチ スコアリングを行うときは、ワークロードを並列化することを検討してください。 スコアリング操作を複数のクラスター ノードに分散できるように、入力データをパーティション分割する必要があります。 さまざまな方法を試して、ワークロードを分散するための最良の選択を見つけてください。 ケースごとに、次の点を考慮してください。
- 1 つのノードのメモリで読み込んで処理できるデータの量。
- 各 Batch ジョブの開始によるオーバーヘッド。
- R モデルの読み込みによるオーバーヘッド。
この例で使用されているシナリオでは、モデル オブジェクトは大型で、個別の商品の予測を生成するためにかかる時間は数秒です。 この理由により、商品をグループ化して、ノードごとに 1 つの Batch ジョブを実行することができます。 各ジョブ内のループにより、順番に商品の予測が生成されます。 この方式が、この特定のワークロードを並列化する最も効率的な方法になります。 この方式では、数多くの小さなバッチ ジョブを開始して、繰り返し R モデルを読み込むことによるオーバーヘッドが回避されます。
別の方法は、商品ごとに 1 つのバッチ ジョブをトリガーするというものです。 Azure Batch は自動的にジョブのキューを形成し、ノードが使用可能になるとそれらをクラスターで実行するために送信します。 自動スケーリングを使用して、ジョブの数に応じてクラスター内のノードの数を調整します。 この方法は、各スコアリング操作の完了に比較的長い時間がかかり、ジョブを開始してモデル オブジェクトを再読み込みすることによるオーバーヘッドが正当化される場合には役立ちます。 また、この方法は実装が容易であり、合計ワークロード サイズが事前にわからない場合に重要な考慮事項となる自動スケーリングを使用する柔軟性も得ることができます。
Azure Batch ジョブの監視
Batch ジョブの監視と終了は、Azure portal の Batch アカウントの [ジョブ] ウィンドウから行います。 個別のノードの状態を含め、バッチ クラスターを監視は、 [プール] ウィンドウから行います。
doAzureParallel によるログ記録
doAzureParallel パッケージは、Azure Batch で送信されたすべてのジョブのすべての stdout/stderr のログを自動的に収集します。 これらのログは、セットアップ時に作成されたストレージ アカウントにあります。 それらを表示するには、Azure Storage Explorer や Azure portal などのストレージ ナビゲーション ツールを使用します。
開発中に Batch ジョブをすばやくデバッグするには、ローカル R セッションでログを表示します。 詳細については、「トレーニングの実行を構成して送信する」を参照してください。
コストの最適化
コストの最適化とは、不要な費用を削減し、運用効率を向上させる方法を検討することです。 詳しくは、コスト最適化の柱の概要に関する記事をご覧ください。
この参照アーキテクチャで使用されるコンピューティング リソースは、最も費用がかかるコンポーネントです。 このシナリオでは、ジョブがトリガーされるたびに固定サイズのクラスターが作成され、ジョブが完了するとシャットダウンされます。 費用が発生するのは、クラスター ノードの開始中、実行中、またはシャット ダウン中だけです。 この方法は、予測を生成するために必要なコンピューティング リソースがどのジョブでも比較的一定であるシナリオに適しています。
ジョブを完了するために必要なコンピューティング量が事前にわからないシナリオでは、自動スケーリングを使用する方が適している可能性があります。 この方法では、クラスターのサイズはジョブのサイズに応じてスケールアップまたはスケールダウンされます。 Azure Batch では、doAzureParallel API を使用してクラスターを定義するときに設定できる一連の自動スケーリングの数式をサポートしています。
一部のシナリオでは、ジョブ間の時間が、クラスターをシャット ダウンして起動するのに短すぎる場合があります。 このようなケースでは、適切な場合、ジョブとジョブとの間、クラスターを実行したままにしておきます。
Azure Batch と doAzureParallel では、優先順位の低い VM の使用がサポートされています。 これらの VM には大幅な割引がありますが、他の優先順位の高いワークロードによって割り当てられるリスクが伴います。 そのため、優先順位の低い VM を使用することは、重要な運用環境のワークロードにはお勧めできません。 ただし、これらは実験用ワークロードや開発用ワークロードには有用です。
このシナリオのデプロイ
この参照アーキテクチャをデプロイするには、GitHub リポジトリで説明されている手順に従ってください。
共同作成者
この記事は、Microsoft によって保守されています。 当初の寄稿者は以下のとおりです。
プリンシパル作成者:
- Angus Taylor | シニア データ科学者
パブリックでない LinkedIn プロファイルを表示するには、LinkedIn にサインインします。