この参照アーキテクチャでは、エンド ツー エンドのストリーム処理パイプラインを示します。 このパイプラインでは、2 つのソースからデータを取り込み、2 つのストリームのレコードを関連付けて、時間枠全体の移動平均を計算します。 結果が保存され、さらに詳しい分析が行われます。
 このアーキテクチャの参照実装は、 GitHub で入手できます。
このアーキテクチャの参照実装は、 GitHub で入手できます。
アーキテクチャ

このアーキテクチャの Visio ファイル をダウンロードします。
ワークフロー
アーキテクチャは、次のコンポーネントで構成されています。
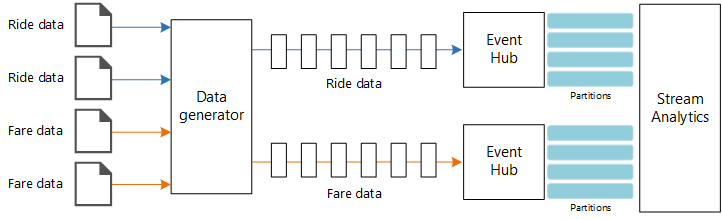
データ ソース。 このアーキテクチャには、リアルタイムでデータ ストリームを生成する 2 つのデータ ソースがあります。 1 つ目のストリームには乗車情報が含まれ、2 つ目のストリームには料金情報が含まれます。 参照アーキテクチャには、一連の静的ファイルから読み取り、データを Event Hubs にプッシュするシミュレートされたデータ ジェネレーターが含まれています。 実際のアプリケーションでは、データ ソースはタクシーに設置されたデバイスになります。
Azure Event Hubs。 Event Hubs はイベント取り込みサービスです。 このアーキテクチャでは、2 つのイベント ハブ インスタンス (データ ソースごとに 1 つ) を使用します。 各データ ソースは、関連付けられたイベント ハブにデータ ストリームを送信します。
Azure Stream Analytics。 Stream Analytics はイベント処理エンジンです。 Stream Analytics ジョブでは、2 つのイベント ハブからデータ ストリームを読み取り、ストリーム処理を実行します。
Azure Cosmos DB Stream Analytics ジョブの出力は一連のレコードであり、JSON ドキュメントとして Azure Cosmos DB ドキュメント データベースに書き込まれます。
Microsoft Power BI。 Power BI は、データを分析してビジネスの分析情報を得る一連のビジネス分析ツールです。 このアーキテクチャでは、Azure Cosmos DB からデータを読み込みます。 これにより、ユーザーは収集された過去のデータの完全なセットを分析できます。 また、Stream Analytics から Power BI に結果を直接ストリーミングして、データのリアルタイム ビューを表示することもできます。 詳細については、「Power BI のリアルタイム ストリーミング」をご覧ください。
Azure Monitor。 Azure Monitor は、ソリューションにデプロイされた Azure サービスに関するパフォーマンス メトリックを収集します。 ダッシュボードでこれらを視覚化することで、ソリューションの正常性を把握できます。
シナリオの詳細
シナリオ:タクシー会社が各乗車に関するデータを収集しています。 このシナリオでは、データを送信する 2 つのデバイスがあることを想定しています。 タクシーには、各乗車の情報 (走行時間、距離、乗車場所と降車場所) を送信するメーターがあります。 別のデバイスでは、乗客からの支払いを受け付け、料金に関するデータを送信します。 タクシー会社では、傾向をつかむために、走行 1 マイルあたりの平均チップをリアルタイムで計算したいと考えています。
考えられるユース ケース
このソリューションは、小売シナリオ向けに最適化されています。
データ インジェスト
データ ソースをシミュレートするために、この参照アーキテクチャでは New York City Taxi Data データセット[1] を使用します。 このデータセットには、ニューヨーク市の 4 年間 (2010 年から 2013 年) のタクシー乗車に関するデータが含まれています。 乗車データと料金データの 2 種類のレコードがあります。 乗車データには、走行時間、乗車距離、乗車場所と降車場所が含まれます。 料金データには、料金、税、チップの金額が含まれます。 この 2 種類のレコードの共通フィールドには、営業許可番号、タクシー免許、ベンダー ID があります。 この 3 つのフィールドを組み合わせて、タクシーと運転手が一意に識別されます。 データは CSV 形式で保存されます。
[1] Donovan, Brian; Work, Dan (2016):New York City Taxi Trip Data (2010-2013). イリノイ大学アーバナシャンペーン校。 https://doi.org/10.13012/J8PN93H8
データ ジェネレーターは、レコードを読み取り、Azure Event Hubs に送信する .NET Core アプリケーションです。 ジェネレーターは、JSON 形式の乗車データと CSV 形式の料金データを送信します。
Event Hubs では、 パーティション を使用してデータをセグメント化します。 複数のパーティションでは、コンシューマーは各パーティションを並列で読み取ることができます。 Event Hubs にデータを送信するときに、パーティション キーを明示的に指定できます。 それ以外の場合は、ラウンド ロビン方式でパーティションにレコードが割り当てられます。
このシナリオでは、特定のタクシーの乗車データと料金データは、最終的に同じパーティション ID を共有します。 これにより、Stream Analytics は 2 つのストリームを関連付けるときに、ある程度の並列処理を適用できます。 乗車データのパーティション n 内のレコードは、料金データのパーティション n 内のレコードに対応します。
データ ジェネレーターでは、両方のレコードの種類の共通データ モデルに、 Medallion、 HackLicenseおよび VendorIdを連結した PartitionKey プロパティがあります。
public abstract class TaxiData
{
public TaxiData()
{
}
[JsonProperty]
public long Medallion { get; set; }
[JsonProperty]
public long HackLicense { get; set; }
[JsonProperty]
public string VendorId { get; set; }
[JsonProperty]
public DateTimeOffset PickupTime { get; set; }
[JsonIgnore]
public string PartitionKey
{
get => $"{Medallion}_{HackLicense}_{VendorId}";
}
このプロパティを使用して、Event Hubs への送信時に明示的なパーティション キーが提供されます。
using (var client = pool.GetObject())
{
return client.Value.SendAsync(new EventData(Encoding.UTF8.GetBytes(
t.GetData(dataFormat))), t.PartitionKey);
}
ストリーム処理
ストリーム処理ジョブは、複数の異なるステップで SQL クエリを使用して定義されます。 最初の 2 つのステップでは、2 つの入力ストリームからレコードを選択するだけです。
WITH
Step1 AS (
SELECT PartitionId,
TRY_CAST(Medallion AS nvarchar(max)) AS Medallion,
TRY_CAST(HackLicense AS nvarchar(max)) AS HackLicense,
VendorId,
TRY_CAST(PickupTime AS datetime) AS PickupTime,
TripDistanceInMiles
FROM [TaxiRide] PARTITION BY PartitionId
),
Step2 AS (
SELECT PartitionId,
medallion AS Medallion,
hack_license AS HackLicense,
vendor_id AS VendorId,
TRY_CAST(pickup_datetime AS datetime) AS PickupTime,
tip_amount AS TipAmount
FROM [TaxiFare] PARTITION BY PartitionId
),
次のステップでは、2 つの入力ストリームを結合して、各ストリームから一致するレコードを選択します。
Step3 AS (
SELECT tr.TripDistanceInMiles,
tf.TipAmount
FROM [Step1] tr
PARTITION BY PartitionId
JOIN [Step2] tf PARTITION BY PartitionId
ON tr.PartitionId = tf.PartitionId
AND tr.PickupTime = tf.PickupTime
AND DATEDIFF(minute, tr, tf) BETWEEN 0 AND 15
)
このクエリでは、一致するレコードを一意に識別する一連のフィールド (PartitionId と PickupTime) でレコードを結合します。
注意
TaxiRide および TaxiFare ストリームは、 Medallion、 HackLicense、 VendorId および PickupTime の一意の組み合わせによって結合します。 この場合、 PartitionId は Medallion、 HackLicense および VendorId の各フィールドを対象としますが、これは一般的ではありません。
Stream Analytics では、結合は 一時的 なものであり、特定の期間内だけレコードが結合されます。 それ以外は、ジョブでは一致を無期限に待つ必要があります。 DATEDIFF 関数は、一致と見なされるために、一致する 2 つのレコードの許容される時間の間隔を指定します。
ジョブの最後のステップでは、5 分のホッピング ウィンドウでグループ化された、1 マイルあたりの平均チップを計算します。
SELECT System.Timestamp AS WindowTime,
SUM(tr.TipAmount) / SUM(tr.TripDistanceInMiles) AS AverageTipPerMile
INTO [TaxiDrain]
FROM [Step3] tr
GROUP BY HoppingWindow(Duration(minute, 5), Hop(minute, 1))
Stream Analytics には、 ウィンドウ関数 がいくつか用意されています。 ホッピング ウィンドウは、一定期間単位で時間が進みます (この例では、1 ホップあたり 1 分)。 結果は、過去 5 分間の移動平均を計算したものです。
ここで示すアーキテクチャでは、Stream Analytics ジョブの結果だけが Azure Cosmos DB に保存されます。 ビッグ データ シナリオでは、 Event Hubs Capture を使用して、生イベント データを Azure Blob Storage に保存することも検討してください。 生データを保持すると、データから新しい分析情報を引き出すために、後で過去のデータに対してバッチ クエリを実行できます。
考慮事項
以降の考慮事項には、ワークロードの品質向上に使用できる一連の基本原則である Azure "Well-Architected Framework" の要素が組み込まれています。 詳細については、「Microsoft Azure Well-Architected Framework」を参照してください。
スケーラビリティ
Event Hubs
Event Hubs のスループット容量は、 スループット ユニット で測定されます。 自動インフレを有効にすると、イベント ハブを自動スケーリングできます。自動インフレでは、トラフィックに基づいて、スループット ユニットが構成済みの最大値まで自動的にスケーリングされます。
Stream Analytics
Stream Analytics の場合、ジョブに割り当てられたコンピューティング リソースがストリーミング ユニットで測定されます。 ジョブを並列化できる場合は、Stream Analytics ジョブが最も効果的にスケーリングされます。 この場合、Stream Analytics は複数のコンピューティング ノードにジョブを分散できます。
Event Hubs の入力では、 PARTITION BY キーワードを使用して Stream Analytics ジョブをパーティション分割します。 データは、Event Hubs のパーティションに基づいてサブセットに分割されます。
ウィンドウ関数と一時的な結合には追加の SU が必要です。 可能であれば、各パーティションが個別に処理されるように、 PARTITION BY を使用します。 詳細については、「ストリーミング ユニットの理解と調整」をご覧ください。
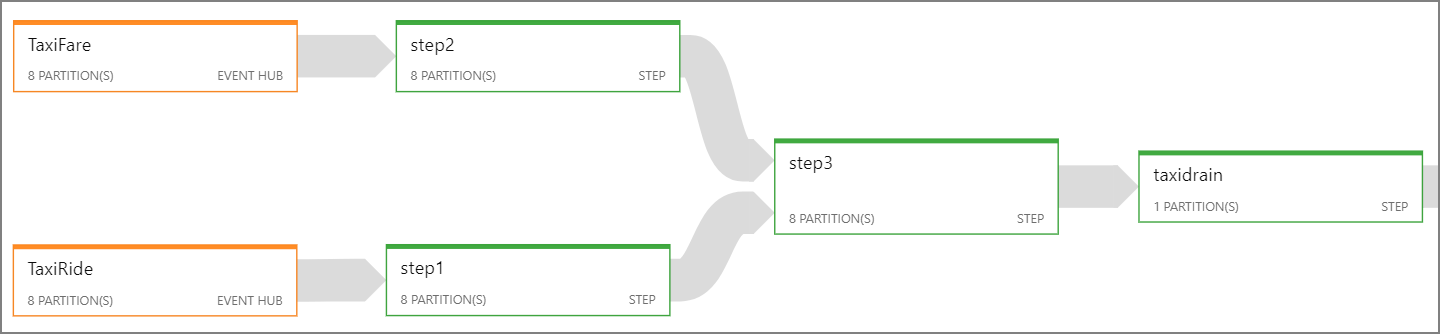
Stream Analytics ジョブ全体を並列化できない場合は、ジョブを複数のステップに分割し、1 つ以上の並列ステップから開始することを試みます。 これにより、最初のステップを並列実行できます。 たとえば、この参照アーキテクチャでは、ステップは次のようになります。
- ステップ 1 と 2 は、1 つのパーティション内のレコードを選択する単純な
SELECTステートメントです。 - ステップ 3 では、2 つの入力ストリーム間でパーティション結合を実行します。 このステップでは、一致するレコードは同じパーティション キーを共有するので、各入力ストリームに同じパーティション ID が含まれていることが保証されるという事実を利用しています。
- ステップ 4 では、すべてのパーティションにわたる集計を実行します。 このステップは並列化できません。
ジョブの各ステップに割り当てられているパーティションの数を確認するには、Stream Analytics の ジョブ ダイアグラム を使用します。 次の図は、この参照アーキテクチャのジョブ ダイアグラムを示しています。
Azure Cosmos DB
Azure Cosmos DB のスループット容量は、 要求ユニット (RU) で測定されます。 Azure Cosmos DB コンテナーを 10,000 RU を超えてスケーリングするには、コンテナーの作成時に パーティション キー を指定し、すべてのドキュメントにパーティション キーを含める必要があります。
この参照アーキテクチャでは、新しいドキュメントは 1 分に 1 回だけ (ホッピング ウィンドウ間隔) 作成されるので、スループット要件は非常に低くなっています。 そのため、このシナリオではパーティション キーを割り当てる必要はありません。
監視
ストリーム処理ソリューションでは、システムのパフォーマンスと正常性を監視することが重要です。 Azure Monitor は、アーキテクチャで使用されている Azure サービスのメトリックと診断ログを収集します。 Azure Monitor は Azure プラットフォームに組み込まれており、アプリケーションにコードを追加する必要はありません。
次の警告シグナルは、該当する Azure リソースをスケールアウトする必要があることを示しています。
- Event Hubs が要求を調整しているか、1 日のメッセージ クォータに近づいている。
- Stream Analytics ジョブが、割り当てられたストリーミング ユニット (SU) の 80% 以上を常に使用している。
- Azure Cosmos DB が要求を調整し始めている。
参照アーキテクチャには、Azure portal にデプロイされるカスタム ダッシュボードが含まれています。 アーキテクチャをデプロイしたら、 Azure portal を開き、ダッシュボードの一覧から TaxiRidesDashboard を選択することでダッシュボードを表示できます。 Azure portal でのカスタム ダッシュボードの作成とデプロイの詳細については、「プログラムによる Azure ダッシュボードの作成」をご覧ください。
次の画像は、Stream Analytics ジョブが約 1 時間実行された後のダッシュボードを示しています。
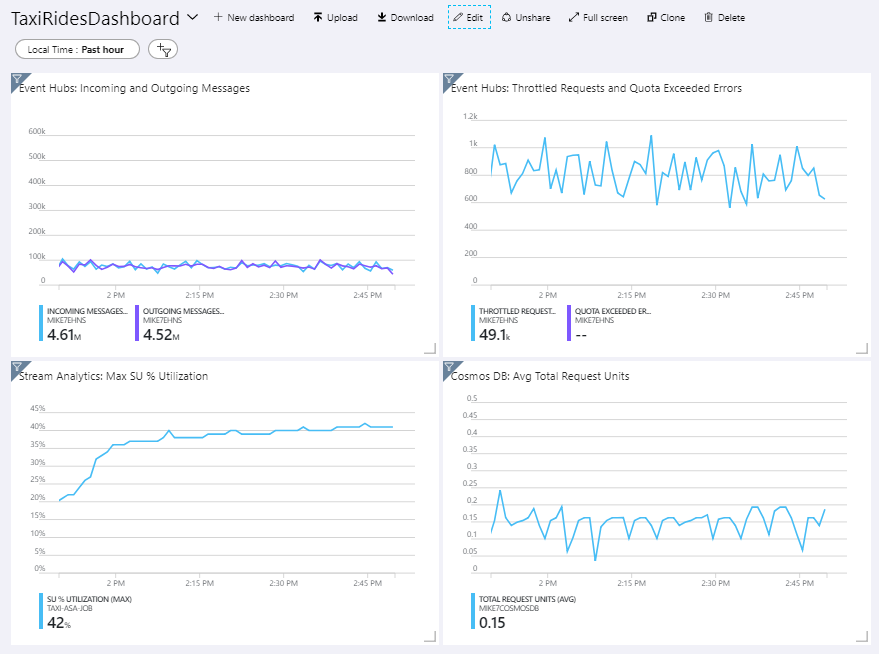
左下のパネルは、Stream Analytics ジョブの SU 消費量が最初の 15 分間に上昇した後、横ばい状態になっていることを示しています。 これは、ジョブが定常状態に達するときの一般的なパターンです。
右上のパネルに示すように、Event Hubs が要求を調整していることに注意してください。 Event Hubs クライアント SDK は、調整エラーが発生すると自動的に再試行するため、不定期に調整される要求は問題ありません。 ただし、調整エラーが常に発生する場合は、イベント ハブにより多くのスループット ユニットが必要であることを意味しています。 次のグラフは、必要に応じてスループット ユニットを自動的にスケールアウトする、Event Hubs の自動インフレ機能を使用したテストの実行を示しています。

自動インフレは、06:35 マークあたりで有効化されました。 Event Hubs が 3 スループット ユニットに自動的にスケールアップされたため、調整された要求数が激減していることがわかります。
興味深いのは、これには、Stream Analytics ジョブの SU 使用率が増加するという副作用があったことです。 調整によって、Event Hubs は Stream Analytics ジョブの取り込み率を故意に下げていました。 パフォーマンスの 1 つのボトルネックの解消によって、別のボトルネックが明らかになることは実際によくあります。 この例では、Stream Analytics ジョブに追加の SU を割り当てることで問題が解決されました。
コストの最適化
コストの最適化とは、不要な費用を削減し、運用効率を向上させる方法を検討することです。 詳しくは、 コスト最適化の柱の概要 に関する記事をご覧ください。
コストの見積もりには、Azure 料金計算ツール をご利用ください。 ここでは、この参照アーキテクチャで使用されるサービスに関するいくつかの考慮事項を示します。
Azure Stream Analytics
Azure Stream Analytics の価格は、サービスに入力されるデータを処理するために必要なストリーミング ユニット ($0.11/時) の数に基づいて決まります。
リアルタイムでデータを処理していない場合、または処理するデータが少量ではない場合は、Stream Analytics のコストが高くなる可能性があります。 それらのユース ケースについては、Azure Functions または Logic Apps を使用して、Azure Event Hubs からデータ ストアにデータを移動することを検討してください。
Azure Event Hubs および Azure Cosmos DB
Azure Event Hubs と Azure Cosmos DB のコストに関する考慮事項については、 Azure Databricks によるストリーム処理 に関する参照アーキテクチャの「コストに関する考慮事項」を参照してください。
DevOps
運用、開発、およびテスト環境それぞれに対して個別のリソース グループを作成してください。 個別のリソース グループにより、デプロイの管理、テスト デプロイの削除、およびアクセス権の割り当てが行いやすくなります。
Azure Resource Manager テンプレート を使用して、コードとしてのインフラストラクチャ (IaC) プロセスに従って Azure リソースをデプロイします。 テンプレートを使用すると、 Azure DevOps Services またはその他の CI/CD ソリューションを使用したデプロイの自動化が簡単になります。
各ワークロードを別々のデプロイ テンプレートに配置し、リソースをソース管理システムに格納します。 テンプレートは一緒にデプロイすることも、CI/CD プロセスの一環として個別にデプロイすることもできるため、自動化プロセスが簡単になります。
このアーキテクチャでは、Azure Event Hubs、Log Analytics、および Azure Cosmos DB が 1 つのワークロードとして識別されます。 これらのリソースは、1 つの ARM テンプレートに含まれます。
ワークロードをステージングすることを検討してください。 さまざまなステージにデプロイし、各ステージで検証チェックを実行してから、次のステージに進みます。 これにより、高度に制御された方法で運用環境に更新プログラムをプッシュし、予期しないデプロイの問題を最小限に抑えることができます。
ストリーム処理パイプラインのパフォーマンスを分析するには、 Azure Monitor の使用を検討してください。 詳細については、「Azure Databricks の監視」を参照してください。
詳細については、 Microsoft Azure Well-Architected Framework に関するページのオペレーショナル エクセレンスに関する重要な要素を参照してください。
このシナリオのデプロイ
リファレンス実装をデプロイおよび実行するには、 GitHub readme の手順に従ってください。
関連リソース
同じテクノロジの一部を使用する具体的なソリューションを示す次の Azure のサンプル シナリオ をレビューできます。