Azure VM での SAP HANA データベースのバックアップ
この記事では、Azure VM で稼働している SAP HANA データベースを Azure Backup Recovery Services コンテナーにバックアップする方法について説明します。
SAP HANA データベースは、低い回復ポイントの目標値 (RPO) と長期リテンション期間を必要とする重要なワークロードです。 [Azure Backup] を使用して、Azure 仮想マシン (VM) 上で稼働している SAP HANA データベースをバックアップできます。
Note
サポートされている構成とシナリオの詳細については、「SAP HANA バックアップのサポート マトリックス」を参照してください。
前提条件
バックアップ用にデータベースを設定するには、[前提条件] と [事前登録スクリプトで実行される処理] のセクションを参照してください。
ネットワーク接続を確立する
すべての操作において、Azure VM で実行されている SAP HANA データベースには Azure Backup サービス、Azure Storage、Microsoft Entra ID への接続が必要です。 これは、プライベート エンドポイントを使用するか、必要なパブリック IP アドレスまたは FQDN へのアクセスを許可することによって実現できます。 必要な Azure サービスへの適切な接続を許可しないと、データベースの検出、バックアップの構成、バックアップの実行、データの復元などの操作の失敗につながる可能性があります。
次の表に、接続の確立に使用できるさまざまな選択肢を示します。
| オプション | 長所 | 短所 |
|---|---|---|
| プライベート エンドポイント | 仮想ネットワーク内のプライベート IP 経由でのバックアップを可能にする ネットワークとコンテナーの側で詳細な制御を提供する |
標準のプライベート エンドポイント コストが発生する |
| NSG サービス タグ | 範囲の変更が自動的にマージされるため管理しやすい 追加のコストが発生しない |
NSG でのみ使用可能 サービス全体へのアクセスを提供する |
| Azure Firewall の FQDN タグ | 必要な FQDN が自動的に管理されるため管理しやすい | Azure Firewall でのみ使用可能 |
| サービスの FQDN/IP へのアクセスを許可する | 追加のコストが発生しない。 すべてのネットワーク セキュリティ アプライアンスとファイアウォールで動作する。 Storage にサービス エンドポイントを使用することもできます。 ただし、Azure Backup と Microsoft Entra ID の場合、対応する IP/FQDN へのアクセスを割り当てる必要があります。 |
広範な IP または FQDN のセットへのアクセスが必要になる場合があります。 |
| 仮想ネットワーク サービス エンドポイント | Azure Storage に使用できます。 データ プレーン トラフィックのパフォーマンスを最適化する上で大きなメリットがあります。 |
Microsoft Entra ID、Azure Backup サービスには使用できません。 |
| ネットワーク仮想アプライアンス | Azure Storage、Microsoft Entra ID、Azure Backup サービスには使用できません。 データ プレーン
Azure Firewall のサービス タグの詳細を参照してください。 |
データ プレーン トラフィックにオーバーヘッドが追加され、スループットとパフォーマンスが低下します。 |
これらのオプションを使用する方法の詳細については、以下を参照してください。
プライベート エンドポイント
プライベート エンドポイントを使用すると、仮想ネットワーク内のサーバーから Recovery Services コンテナーに安全に接続できます。 プライベート エンドポイントでは、お使いのコンテナーの VNET アドレス空間からの IP アドレスが使用されます。 仮想ネットワーク内のリソースとコンテナー間のネットワーク トラフィックは、仮想ネットワークと Microsoft のバックボーン ネットワーク上のプライベート リンクを経由します。 これにより、パブリック インターネットへの露出が排除されます。 [こちら] から、Azure Backup のプライベート エンドポイントの詳細を参照してください。
注意
プライベート エンドポイントは、Azure Backup と Azure ストレージでサポートされています。 Microsoft Entra ID では、プライベート プレビューでプライベート エンドポイントがサポートされています。 一般提供されるまで、Azure Backup では、HANA VM に送信接続が必要ないように、Microsoft Entra ID のプロキシ設定がサポートされます。 詳細については、プロキシ サポートのセクションを参照してください。
NSG タグ
ネットワーク セキュリティ グループ (NSG) を使用する場合は、
[すべてのサービス] で、 [ネットワーク セキュリティ グループ] に移動して、ネットワーク セキュリティ グループを選択します。
[設定] で [送信セキュリティ規則] を選択します。
[追加] を選択します。 セキュリティ規則の設定の説明に従って、新しい規則を作成するために必要なすべての詳細を入力します。 オプション [宛先] が [サービス タグ] に、 [宛先サービス タグ] が [AzureBackup] に設定されていることを確認します。
[追加] を選択して、新しく作成した送信セキュリティ規則を保存します。
Azure Storage と Microsoft Entra ID に対する NSG 送信セキュリティ規則も、同様に作成できます。 サービス タグの詳細については、こちらの記事を参照してください。
Azure Firewall タグ
Azure Firewall を使用している場合は、AzureBackupAzure Firewall FQDN タグを使用してアプリケーション規則を作成します。 これにより、Azure Backup へのすべての発信アクセスが許可されます。
サービスの IP 範囲へのアクセスを許可する
サービスの IP へのアクセスを許可することを選択した場合は、[こちら]から利用可能な IP 範囲の JSON ファイルを参照してください。 Azure Backup、Azure Storage、Microsoft Entra ID に対応する IP へのアクセスを許可する必要があります。
サービスの FQDN へのアクセスを許可する
次の FQDN を使用することで、サーバーから必要なサービスへのアクセスを許可することもできます。
| サービス | アクセスするドメイン名 | ポート |
|---|---|---|
| Azure Backup | *.backup.windowsazure.com |
443 |
| Azure Storage | *.blob.core.windows.net *.queue.core.windows.net *.blob.storage.azure.net |
443 |
| Azure AD | *.login.microsoft.com この記事に従って、セクション 56 および 59 の FQDN へのアクセスを許可します |
443 該当する場合 |
トラフィックをルーティングするために HTTP プロキシ サーバーを使用する
Note
現在、SAP HANA に対する Microsoft Entra トラフィックの HTTP プロキシのみがサポートされています。 HANA VM での Azure Backup によるデータベース バックアップに対するアウトバウンド接続要件 (Azure Backup および Azure Storage トラフィックについて) を削除する必要がある場合は、プライベート エンドポイントなどの他のオプションを使用します。
Microsoft Entra トラフィックに HTTP プロキシ サーバーを使用する
"opt/msawb/bin" フォルダーに移動します
「ExtensionSettingsOverrides.json」 という名前の新しい JSON ファイルを作成します
JSON ファイルに、次のキーと値のペアを追加します。
{ "UseProxyForAAD":true, "UseProxyForAzureBackup":false, "UseProxyForAzureStorage":false, "ProxyServerAddress":"http://xx.yy.zz.mm:port" }ファイルのアクセス許可と所有権を次のように変更します。
chmod 750 ExtensionSettingsOverrides.json chown root:msawb ExtensionSettingsOverrides.jsonサービスを再起動する必要はありません。 Azure Backup サービスは、JSON ファイルに記載されているプロキシ サーバーを介して、Microsoft Entra トラフィックのルーティングを試みます。
アウトバウンド規則を使用する
ファイアウォールまたは NSG 設定が、Azure 仮想マシンから “management.azure.com” ドメインをブロックしている場合、スナップショット バックアップは失敗します。
次のアウトバウンド規則を作成し、ドメイン名でデータベースのバックアップを実行できるようにします。 アウトバウンド規則の作成方法を学習します。
- ソース: VM の IP アドレス。
- 宛先: サービス タグ。
- 宛先サービス タグ:
AzureResourceManager

Recovery Services コンテナーを作成する
Recovery Services コンテナーは、時間の経過と共に作成される復旧ポイントを格納する管理エンティティであり、バックアップ関連の操作を実行するためのインターフェイスが用意されています。 たとえば、オンデマンドのバックアップの作成、復元の実行、バックアップ ポリシーの作成などの操作です。
Recovery Services コンテナーを作成するには、次の手順に従います。
Azure portal にサインインします。
「バックアップ センター」を検索し、[バックアップ センター] ダッシュボードに移動します。
![[バックアップ センター] を検索し、選択する場所を示すスクリーンショット。](../includes/media/backup-create-rs-vault/backup-center-search-backup-center.png)
[概要] ペインで、[コンテナー] を選択します。
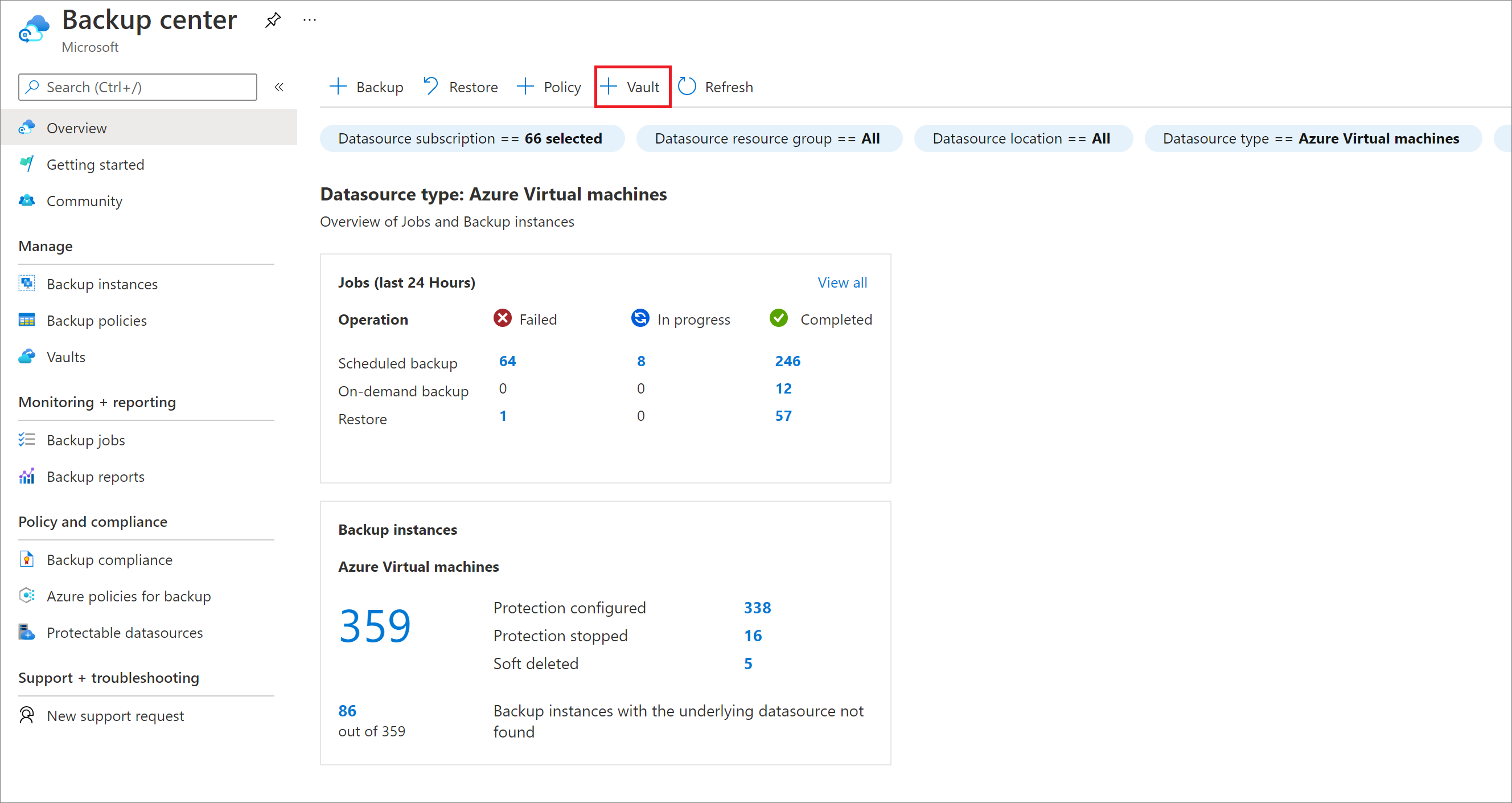
[Recovery Services コンテナー]>[続行] の順に選択します。
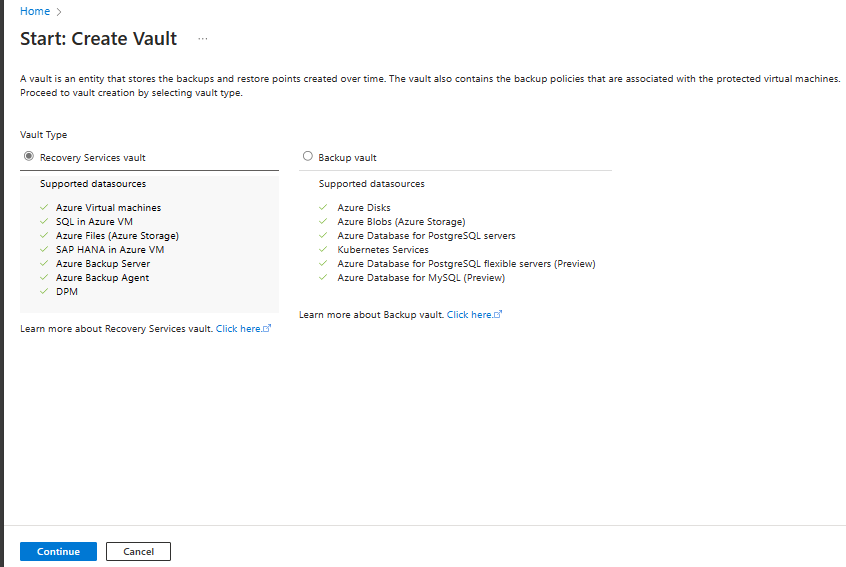
[Recovery Services コンテナー] ペインで、次の値を入力します。
[サブスクリプション] : 使用するサブスクリプションを選択します。 1 つのサブスクリプションのみのメンバーの場合は、その名前が表示されます。 どのサブスクリプションを使用すればよいかがわからない場合は、既定のサブスクリプションを使用してください。 職場または学校アカウントが複数の Azure サブスクリプションに関連付けられている場合に限り、複数の選択肢が存在します。
[リソース グループ] :既存のリソース グループを使用するか、新しいリソース グループを作成します。 サブスクリプションの使用可能なリソース グループの一覧を表示するには、[既存のものを使用] を選択してから、ドロップダウン リストでリソースを選択します。 新しいリソース グループを作成するには、[新規作成] を選択し、名前を入力します。 リソース グループの詳細については、「Azure Resource Manager の概要」を参照してください。
[コンテナー名]: コンテナーを識別するフレンドリ名を入力します。 名前は Azure サブスクリプションに対して一意である必要があります。 2 文字以上で、50 文字以下の名前を指定します。 名前の先頭にはアルファベットを使用する必要があります。また、名前に使用できるのはアルファベット、数字、ハイフンのみです。
[リージョン]: コンテナーの地理的リージョンを選択します。 データ ソースを保護するためのコンテナーを作成するには、コンテナーがデータ ソースと同じリージョン内にある "必要があります"。
重要
データ ソースの場所が不明な場合は、ウィンドウを閉じます。 ポータルの自分のリソースの一覧に移動します。 複数のリージョンにデータ ソースがある場合は、リージョンごとに Recovery Services コンテナーを作成します。 最初の場所にコンテナーを作成してから、別の場所にコンテナーを作成します。 バックアップ データを格納するためにストレージ アカウントを指定する必要はありません。 Recovery Services コンテナーと Azure Backup で自動的に処理されます。
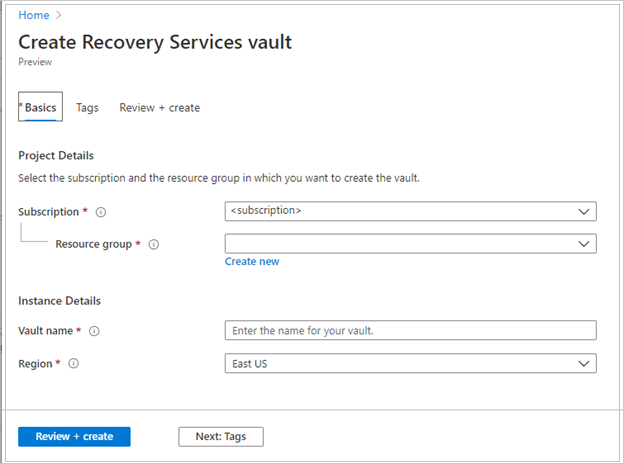
値を指定したら、 [確認と作成] を選択します。
Recovery Services コンテナーの作成を完了するには、[作成] を選択します。
Recovery Services コンテナーの作成に時間がかかることがあります。 右上の [通知] 領域で、状態の通知を監視します。 作成されたコンテナーは、Recovery Services コンテナーのリストに表示されます。 コンテナーが表示されない場合は、[最新の情報に更新] を選択します。
注意
Azure Backup は、作成された復旧ポイントがバックアップ ポリシーに従って、有効期限切れ前に削除されないようにできる不変コンテナーをサポートするようになりました。 また、不変性を元に戻せないようにして、ランサムウェア攻撃や悪意のあるアクターなど、さまざまな脅威からバックアップ データを最大限に保護することができます。 詳細については、こちらを参照してください。
リージョンをまたがる復元を有効にする
Recovery Services コンテナーでは、リージョンをまたがる復元を有効にできます。 リージョンをまたがる復元を有効にする方法に関する記事を参照してください。
リージョンをまたがる復元に関する詳細情報を参照してください。
データベースを検出する
Azure portal で、[バックアップ センター] に移動し、[+ バックアップ] を選択します。
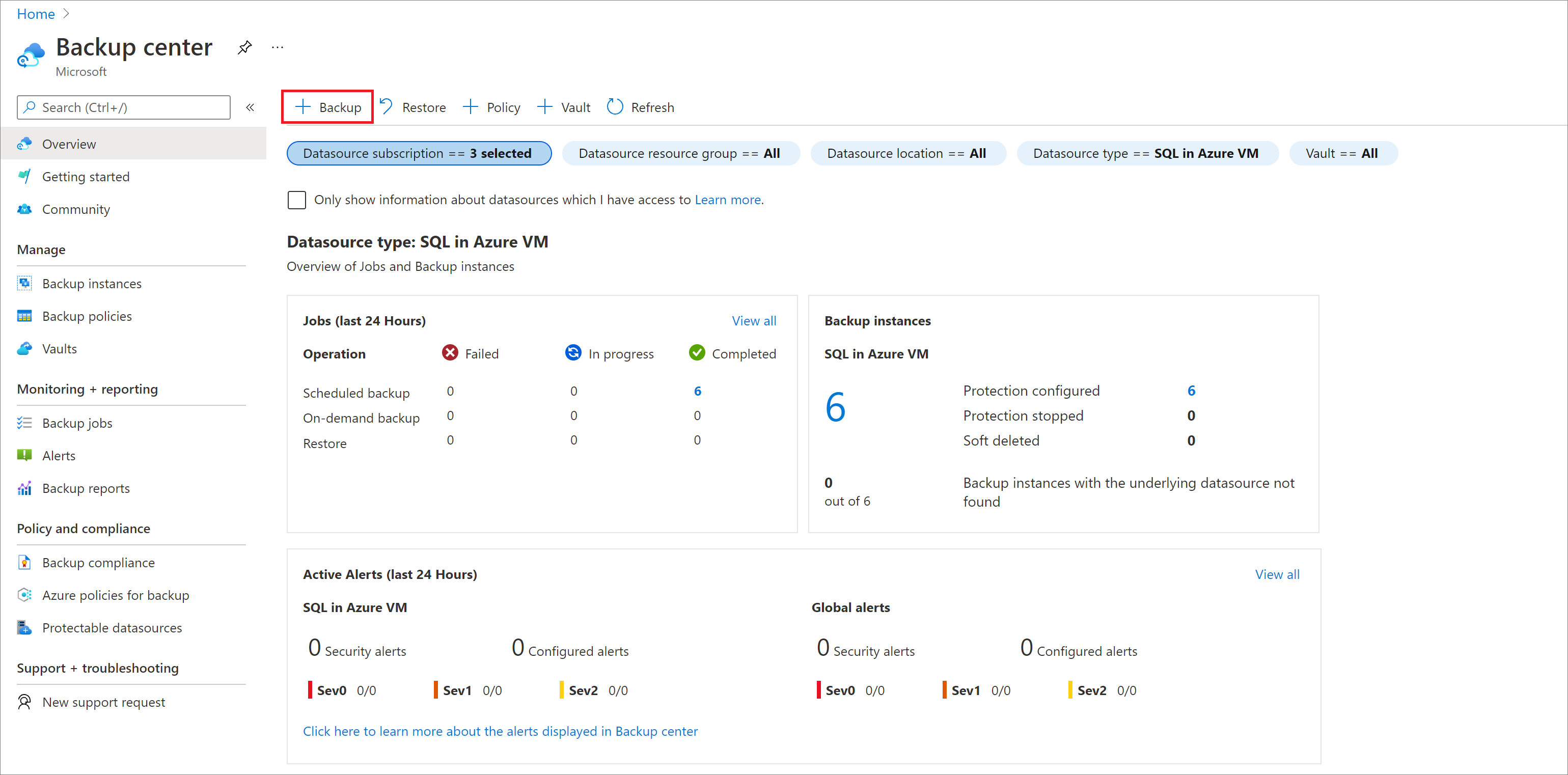
データ ソースの種類として [Azure VM 内の SAP HANA] を選び、バックアップに使う Recovery Services コンテナーを選んで、[続行] を選択します。
** [検出の開始]** を選択します。 これで、コンテナー リージョン内の保護されていない Linux VM の検出が開始されます。- 検出後、保護されていない VM は、ポータルで名前およびリソース グループ別に一覧表示されます。
- VM が予期したとおりに一覧表示されない場合は、それが既にコンテナーにバックアップされているかどうかを確認してください。
- 複数の VM を同じ名前にすることはできますが、それらは異なるリソース グループに属しています。
![[検出の開始] の選択を示すスクリーンショット。](media/backup-azure-sap-hana-database/hana-discover-databases.png)
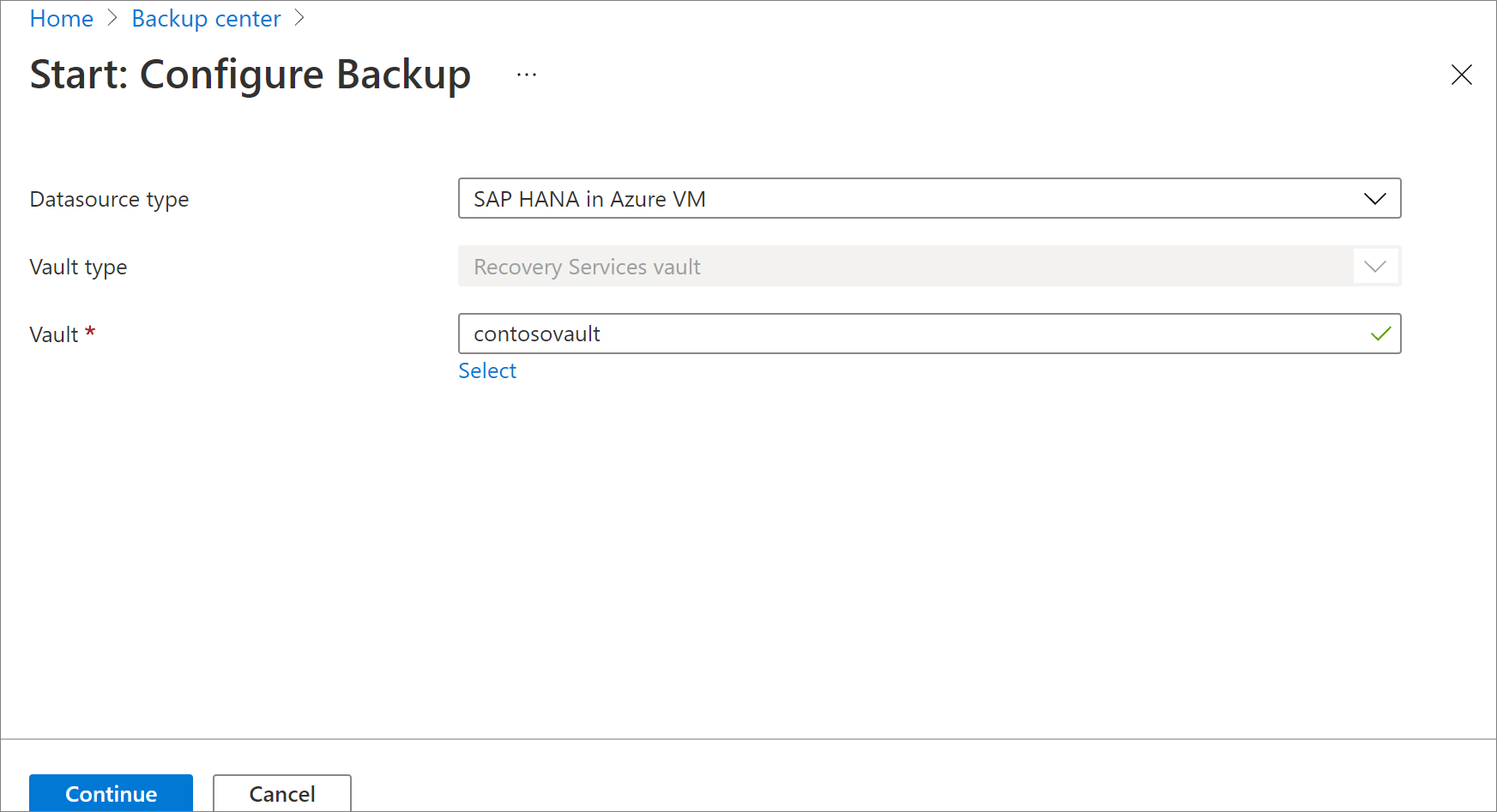
[仮想マシンの選択] で、リンクをクリックして、データベースの検出のために SAP HANA VM へのアクセス許可を Azure Backup サービスに与えるスクリプトをダウンロードします。
バックアップする SAP HANA データベースをホストしている各 VM でスクリプトを実行します。
VM でスクリプトを実行した後、 [仮想マシンの選択] で、VM を選択します。 次に、[データベースを検出] を選択します。
Azure Backup によって、VM 上のすべての SAP HANA データベースが検出されます。 検出中に、Azure Backup によって VM がコンテナーに登録され、VM に拡張機能がインストールされます。 エージェントはデータベースにインストールされません。
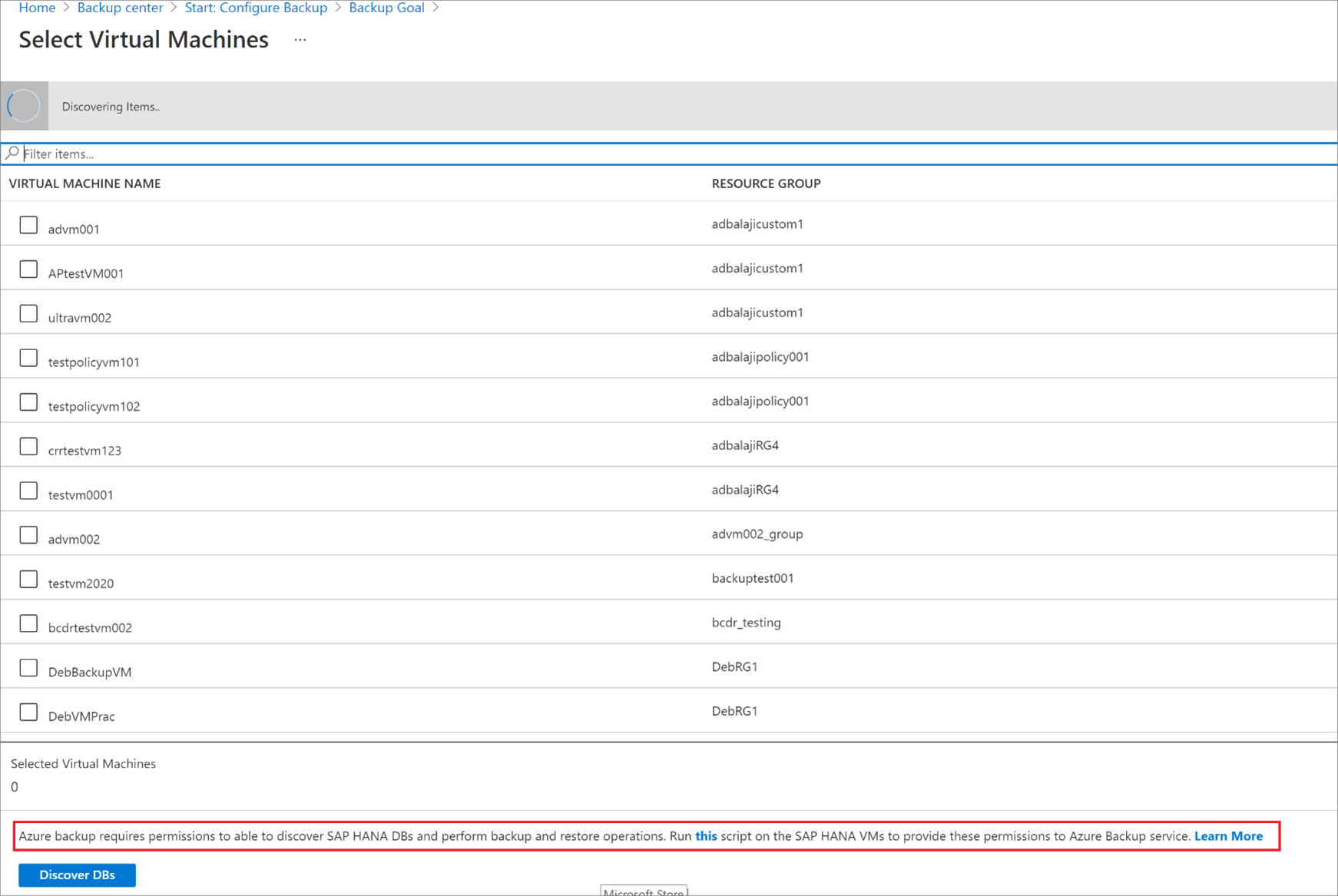


バックアップの構成
ここでバックアップを有効にします。
手順 2 で、 [バックアップの構成] を選択します。
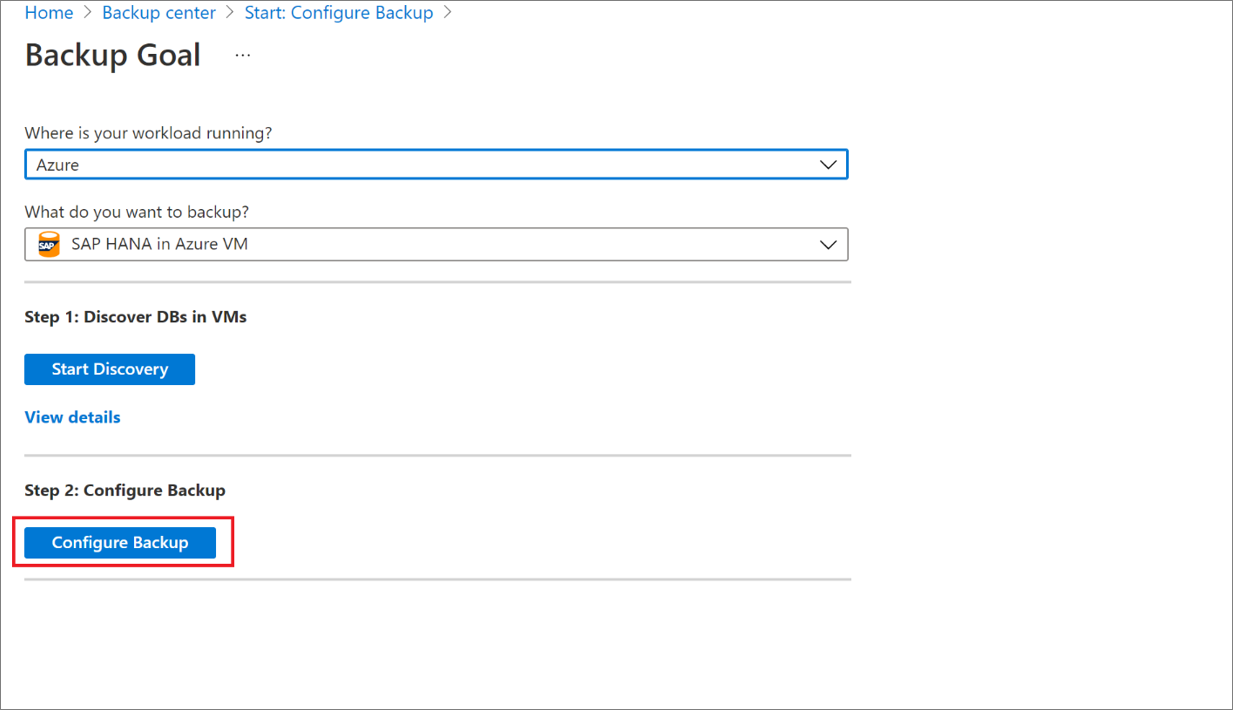
[バックアップする項目の選択] で、保護するデータベースをすべて選択し、[OK] を選びます。
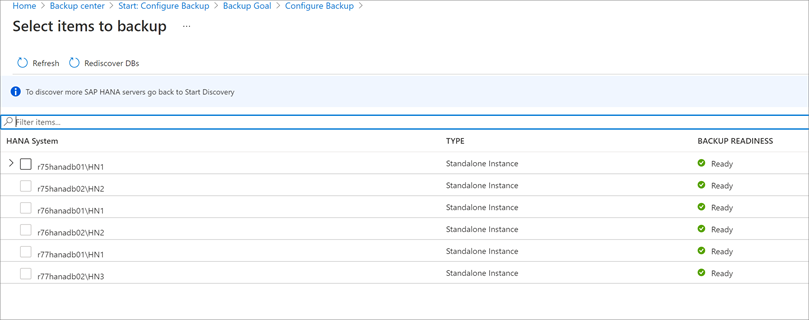
[バックアップ ポリシー]>[バックアップ ポリシーの選択] で、以下の手順に従って、データベースの新しいバックアップ ポリシーを作成します。
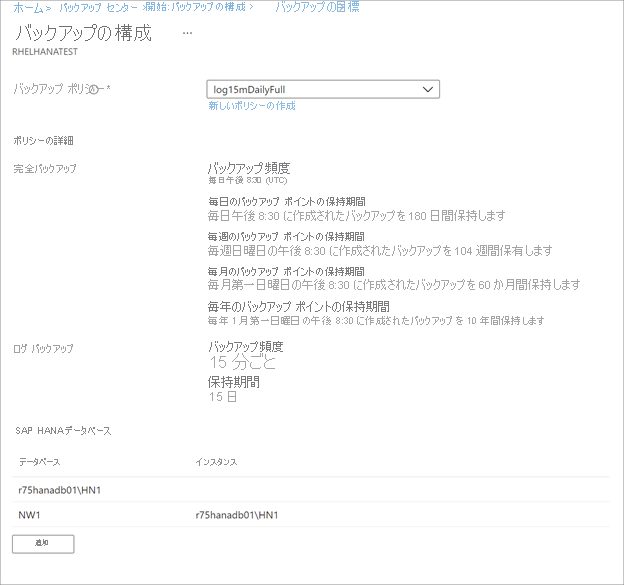
ポリシーを作成した後、 [バックアップ] メニューの [バックアップの有効化] を選択します。
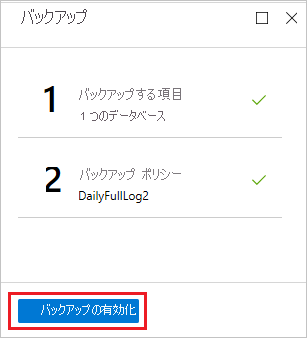
ポータルの [通知] 領域で、バックアップ構成の進行状況を追跡します。

バックアップ ポリシーの作成
バックアップ ポリシーでは、バックアップが取得されるタイミングと、それらが保持される期間を定義します。
- ポリシーはコンテナー レベルで作成されます。
- 複数のコンテナーでは同じバックアップ ポリシーを使用できますが、各コンテナーにバックアップ ポリシーを適用する必要があります。
Note
Azure Backup では、Azure VM で実行されている SAP HANA データベースをバックアップしている場合、夏時間変更に合わせた自動調整は行われません。
必要に応じて手動でポリシーを変更してください。
次のように、ポリシー設定を指定します。
[ポリシー名] に新しいポリシーの名前を入力します。
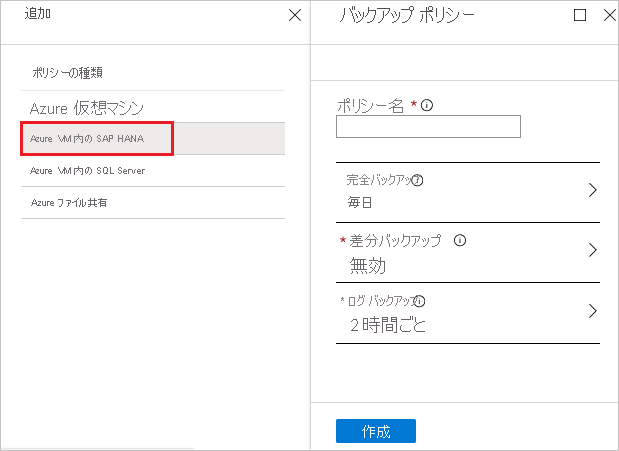
完全バックアップのポリシー で [バックアップ頻度] を選択し、 [毎日] または [毎週] を選びます。
- 日次:バックアップ ジョブが開始される、時刻とタイム ゾーンを選択します。
- 完全バックアップを実行する必要があります。 このオプションをオフにすることはできません。
- [完全バックアップ] を選択し、ポリシーを表示します。
- 日次の完全バックアップを選択する場合は、差分バックアップを作成できません。
- 毎週:バックアップ ジョブが実行される、曜日、時刻、およびタイム ゾーンを選択します。
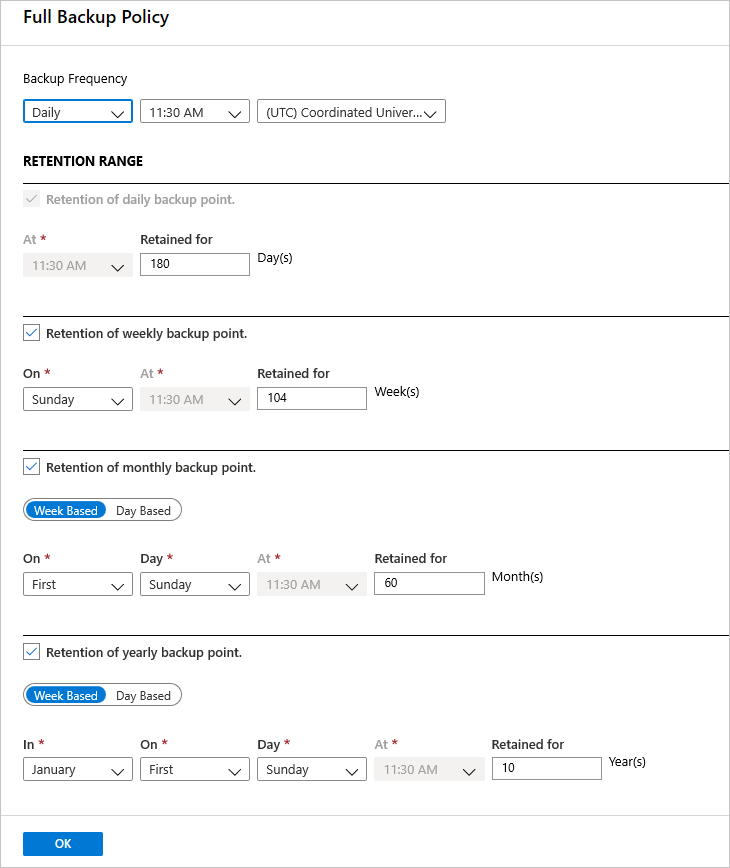
- 日次:バックアップ ジョブが開始される、時刻とタイム ゾーンを選択します。
[リテンション期間] で、完全バックアップのリテンション期間の設定を構成します。
- 既定では、すべてのオプションが選択されています。 使用しないリテンション期間の制限をすべてクリアして、使用するものを設定します。
- あらゆる種類のバックアップ (完全、差分、ログ) の最小保持期間は 7 日間です。
- 復旧ポイントは、そのリテンション期間の範囲に基づいて、リテンション期間に対してタグ付けされます。 たとえば、日次での完全バックアップを選択した場合、日ごとにトリガーされる完全バックアップは 1 回だけです。
- 特定の曜日のバックアップがタグ付けされ、週次でのリテンション期間と設定に基づいて保持されます。
- 月次および年次のリテンション期間の範囲でも、同様の動作になります。
完全バックアップのポリシー メニューで、 [OK] を選択して設定を確定します。
[差分バックアップ] を選択して、差分ポリシーを追加します。
差分バックアップのポリシーで、 [有効] を選択して頻度とリテンション期間の制御を開きます。
- 最多で、1 日に 1 回の差分バックアップをトリガーできます。
- 差分バックアップは、最大 180 日間保持できます。 より長いリテンション期間が必要な場合は、完全バックアップを使用する必要があります。
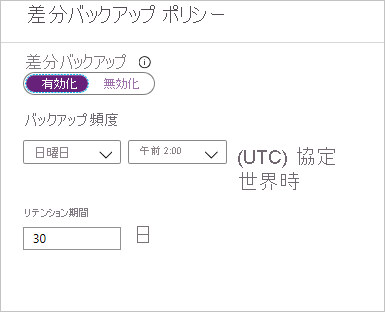
Note
毎日のバックアップとしては、差分バックアップまたは増分バックアップのどちらかを選択できます。両方を選択することはできません。
[増分バックアップ ポリシー] で、 [有効] を選択して頻度と保有期間の制御を開きます。
- 最多で、1 日に 1 回の増分バックアップをトリガーできます。
- 増分バックアップは、最大 180 日間保持できます。 より長いリテンション期間が必要な場合は、完全バックアップを使用する必要があります。
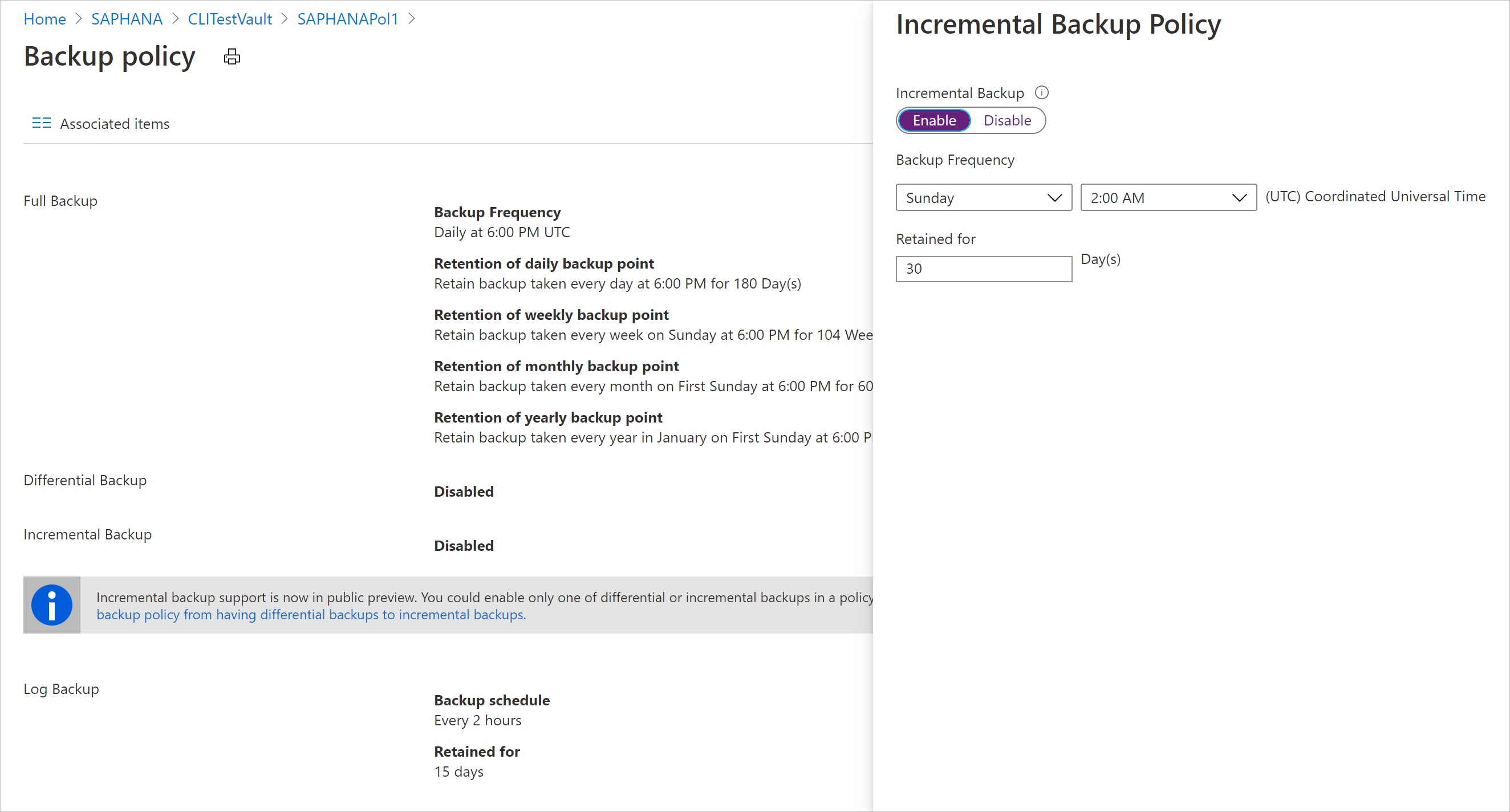
[OK] を選択してポリシーを保存し、 [バックアップ ポリシー] のメイン メニューに戻ります。
[ログ バックアップ] を選択し、トランザクション ログ バックアップ ポリシーを追加します。
- [ログ バックアップ] で、 [有効化] を選択します。 すべてのログ バックアップは SAP HANA で管理されるため、これを無効にすることはできません。
- 頻度とリテンション期間の制御を設定します。
Note
ログ バックアップでは、完全バックアップが正常に完了した後にのみ、フローが開始されます。
[OK] を選択してポリシーを保存し、 [バックアップ ポリシー] のメイン メニューに戻ります。
バックアップ ポリシーの定義が完了した後、 [OK] を選択します。
Note
各ログ バックアップは、復旧チェーンを形成するために、以前の完全バックアップにチェーンされています。 この完全バックアップは、前回のログ バックアップのリテンション期間が終了するまで保持されます。 これは、完全バックアップのリテンション期間を追加して、すべてのログが確実に復旧されるようにすることを意味します。 ユーザーが、週単位の完全バックアップ、日単位の差分、2 時間ごとのログを実行しているとしましょう。 これらのすべてが 30 日間保持されます。 ただし、週単位の完全バックアップは、次の完全バックアップが利用可能になった後でのみ、すなわち 30 + 7 日後に、実際にクリーンアップまたは削除することができます。 たとえば、週単位の完全バックアップが 11 月 16 日に行われたとします。 保持ポリシーに従って、12 月 16 日まで保持されます。 この完全バックアップに対する前回のログ バックアップは、11 月 22 日に予定されている次の完全バックアップの前に行われます。 このログが 12 月 22 日までに利用可能になるまでは、11 月 16 日の完全バックアップは削除されません。 そのため、11 月 16 日の完全バックアップは、12 月 22 日までは保持されます。
オンデマンド バックアップを実行する
バックアップは、ポリシー スケジュールに従って実行されます。 オンデマンド バックアップを実行する方法を確認してください。
Azure Backup のデータベースで SAP HANA ネイティブ クライアント バックアップを実行する
SAP HANA ネイティブ クライアントを使用して、Backint ではなくローカル ファイル システムへのオンデマンド バックアップを実行できます。 SAP ネイティブ クライアントを使用して操作を管理する方法をご覧ください。
Backint を使ってスループットを向上させるためにマルチストリーミング データ バックアップを構成する
マルチストリーミング データ バックアップを構成するには、SAP のドキュメントを参照してください。
サポートされているシナリオについて説明します。
バックアップの状態を確認する
Azure Backup は、VM にインストールされている拡張機能と Azure Backup サービスの間でデータソースを定期的に同期し、Azure portal にバックアップの状態を表示します。 次の表に、データソースの (4 つの) バックアップの状態を示します。
| バックアップの状態 | 説明 |
|---|---|
| Healthy | 最後のバックアップが成功しました。 |
| 異常 | 最後のバックアップが失敗しました。 |
| NotReachable | 現在、VM 上の拡張機能と Azure Backup サービスの間で同期は行われていません。 |
| IRPending | データソースの最初のバックアップがまだ発生していません。 |
通常、同期は "1 時間ごと" に行われます。 ただし、拡張機能レベルでは、Azure Backup は "5 分 ごと" に ポーリングして、前のバックアップと比較した最新のバックアップの状態の変更を確認します。 たとえば、前のバックアップが成功しても最新のバックアップが失敗した場合、Azure Backup はその情報をサービスに同期して、状況に合わせて Azure portal のバックアップ状態を "正常" または "異常" に更新します。
Azure Backup サービスに対し "2 時間" 以上データ同期が行われなかった場合、Azure Backup ではバックアップの状態は "NotReachable" と表示されます。 このシナリオは、VM が長期間シャットダウンされた場合、または VM にネットワーク接続の問題が発生し、同期が停止した場合に発生する可能性があります。 VM が再び動作し、拡張機能サービスが再起動されると、サービスへのデータ同期操作が再開され、最後のバックアップの状態に 基づいてバックアップの状態が "正常" または "異常" に変わります。
