Azure Site Recovery を使用して多層 SharePoint アプリケーションのディザスター リカバリーを設定する
この記事では、Azure Site Recovery を使用して SharePoint アプリケーションを保護する方法の詳細を説明します。
概要
Microsoft SharePoint は、グループあるいは部署が情報を整理、コラボレート、および共有するのに役立つ強力なアプリケーションです。 SharePoint は、イントラネット ポータルや、ドキュメントおよびファイル管理、コラボレーション、ソーシャル ネットワーク、エクストラネット、web サイト、エンタープライズ検索、およびビジネス インテリジェンスを提供できます。 また、システム統合やプロセス統合、ワークフロー自動化機能もあります。 通常 組織は、ダウンタイムやデータ損失が重視される第 1 層アプリケーションとみなされます。
現在 Microsoft SharePoint には、すぐに利用できるよう準備されているディザスター リカバリー機能はありません。 災害の種類と規模に関係なく、復旧では待機データ センターが使用され、ファームを復旧することができます。 一次データセンター側の機能停止からローカルの冗長システムやバックアップを回復できない場合は、待機データ センターが必要です。
優れたディザスター リカバリー ソリューションは、SharePoint のように複雑なアーキテクチャを持つアプリケーションでも、復旧計画を立てられる必要があります。 また、さまざまな階層間のアプリケーション マッピングを処理する独自のステップを追加する機能も用意し、災害発生時はわずかな RTO でクリック 1 回でのフェイルオーバーを提供できるようにします。
この記事では、Azure Site Recovery を使用して SharePoint アプリケーションを保護する方法の詳細を説明します。 また、3 層の SharePoint アプリケーションを Azure にレプリケートするさいのベスト プラクティスや、ディザスター リカバリー訓練の実施方法、アプリケーションを Azure にフェールオーバーする方法についても説明します。
下記は、Azure への多層アプリケーションの回復を扱ったビデオです。
前提条件
開始する前に、以下を理解していることを確認してください。
- Azure への仮想マシンのレプリケート
- 復旧ネットワークの設計方法
- Azure へのテスト フェールオーバーの実行
- Azure へのフェールオーバーの実行
- ドメイン コントローラーのレプリケート方法
- SQL Server のレプリケート方法
SharePoint のアーキテクチャ
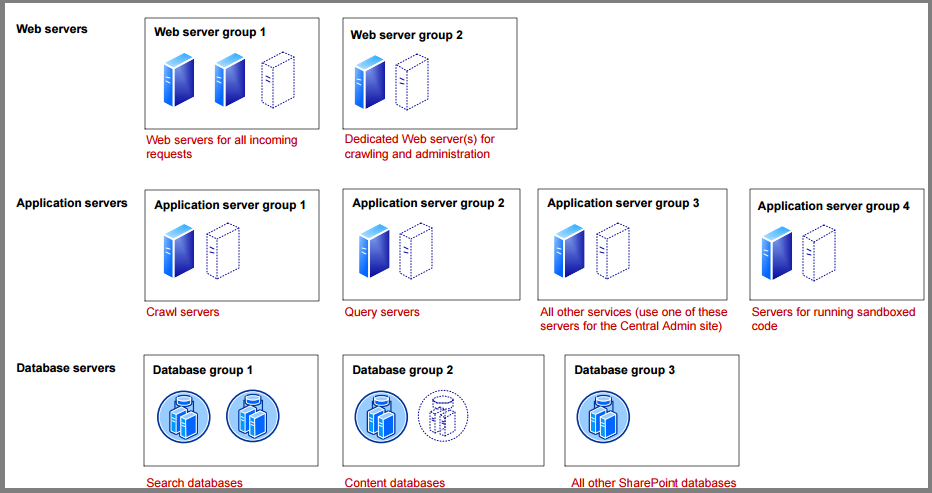
SharePoint は階層型トポロジーとサーバー ロールを使用して 1 つまたは複数のサーバーにデプロイすることで、特定の目標や目的に合ったファーム デザインを実現できます。 多数の同時ユーザー、大量のコンテンツ項目をサポートしている通常の大規模で高デマンドの SharePoint サーバー ファームは、そのスケーラビービリティ戦略の一環としてサービスのグループ化を利用します。 このアプローチでは、サービスを専用のサーバー上で実行します。それらサービスはグループにまとめられ、専用のサーバーが 1 つのグループとしてスケールアウトされます。 下記のトポロジは、3 層 SharePoint サーバー ファームに対するサービスとサーバーのグループ化を表しています。 さまざまな SharePoint トポロジについての詳細な指針については、SharePoint のマニュアルおよび製品系列のアーキテクチャを参照してください。 本書でも、SharePoint 2013 のデプロイに関する詳細を説明しています。
Site Recovery のサポート
Site Recovery はアプリケーションに依存しないため、サポートされるマシン上で実行されているすべてのバージョンの SharePoint で機能します。 この記事の作成には、VMware 仮想マシンと Windows Server 2012 R2 Enterprise を使用しました。 SharePoint 2013 Enterprise Edition および SQL Server 2014 Enterprise Edition も使用しています。
ソースとターゲット
| シナリオ | セカンダリ サイトへ | Azure へ |
|---|---|---|
| Hyper-V | はい | はい |
| VMware | はい | はい |
| 物理サーバー | はい | はい |
| Azure | NA | はい |
留意事項
アプリケーション内の任意の階層で共有ディスクベースのクラスターを使用している場合、Site Recovery レプリケーションを使って仮想マシンをレプリケートすることはできません。 アプリケーションが提供するネイティブのレプリケーションを使用してから、復旧計画を使用してすべての階層をフェールオーバーできます。
仮想マシンをレプリケートする
このガイダンスに従うことで、Azure に全仮想マシンをレプリケートすることができます。
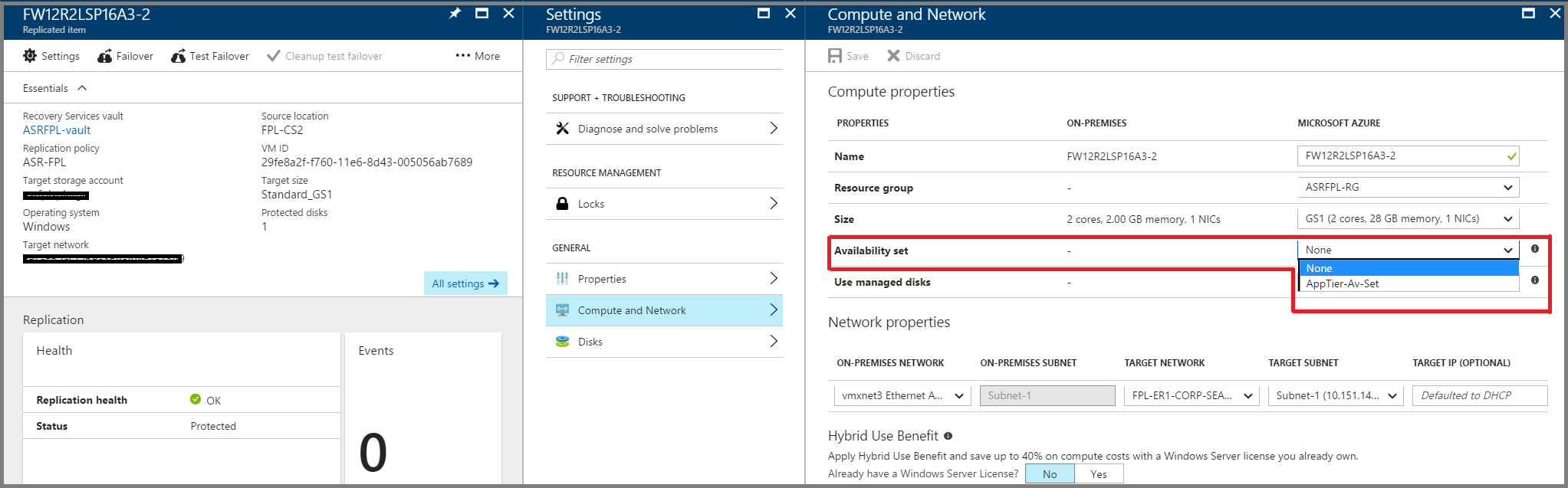
レプリケーションが完了したら、各層の各仮想マシンに移動して、[Replicated item](レプリケートしている項目) > [Settings](設定) > [Properties](プロパティ) > [Compute and Network](コンピューティングとネットワーク) で、同じ可用性セットを選択します。 たとえば Web 階層に 3 台の仮想マシンがある場合は、必ず、その 3 台の仮想マシンのすべてが Azure の同じ可用性セットのメンバーになるように設定します。
Active Directory と DNS の保護に関するガイダンスは、Protect Active Directory and DNSドキュメントを参照してください。
SQL Server 上で動作するデータベース層の保護に関するガイダンスは、Protect SQL Server ドキュメントを参照してください。
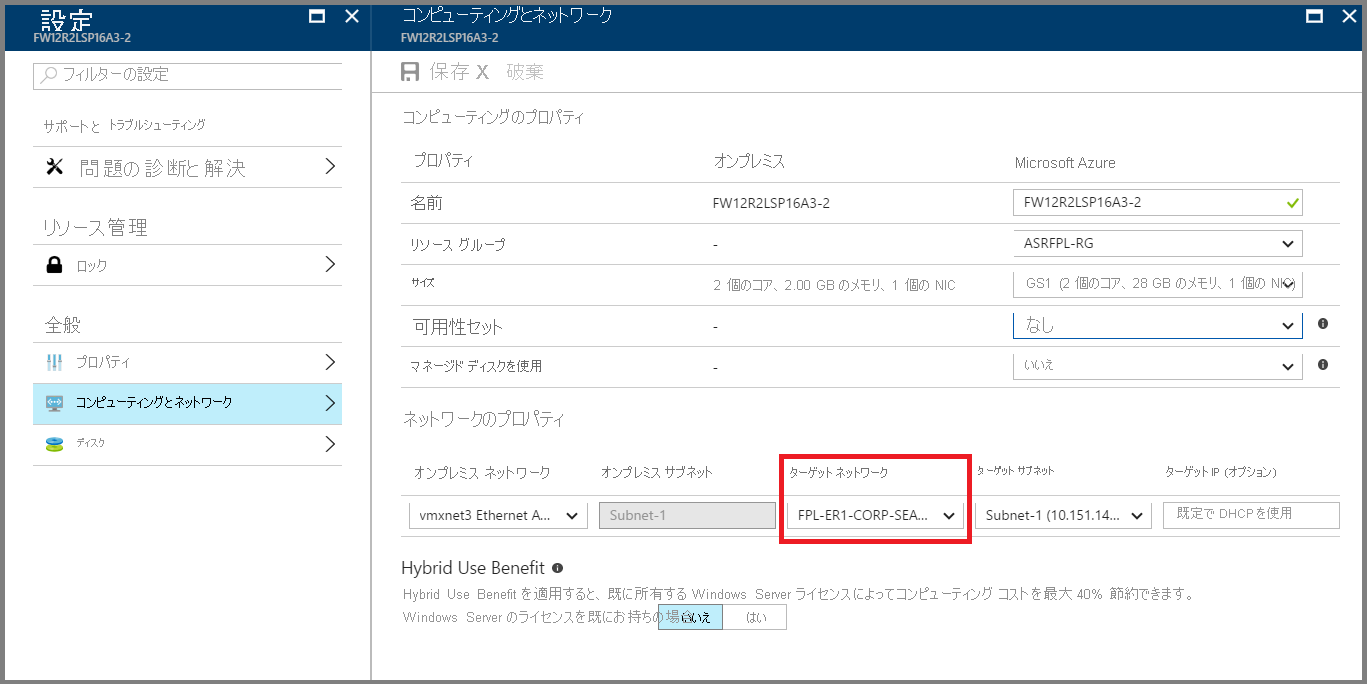
ネットワーク構成
ネットワークのプロパティ
アプリ層と Web 層の仮想マシンについては、仮想マシンがフェールオーバー後に適切な DR ネットワークにアタッチできるように、Azure ポータルでネットワーク設定を行います。
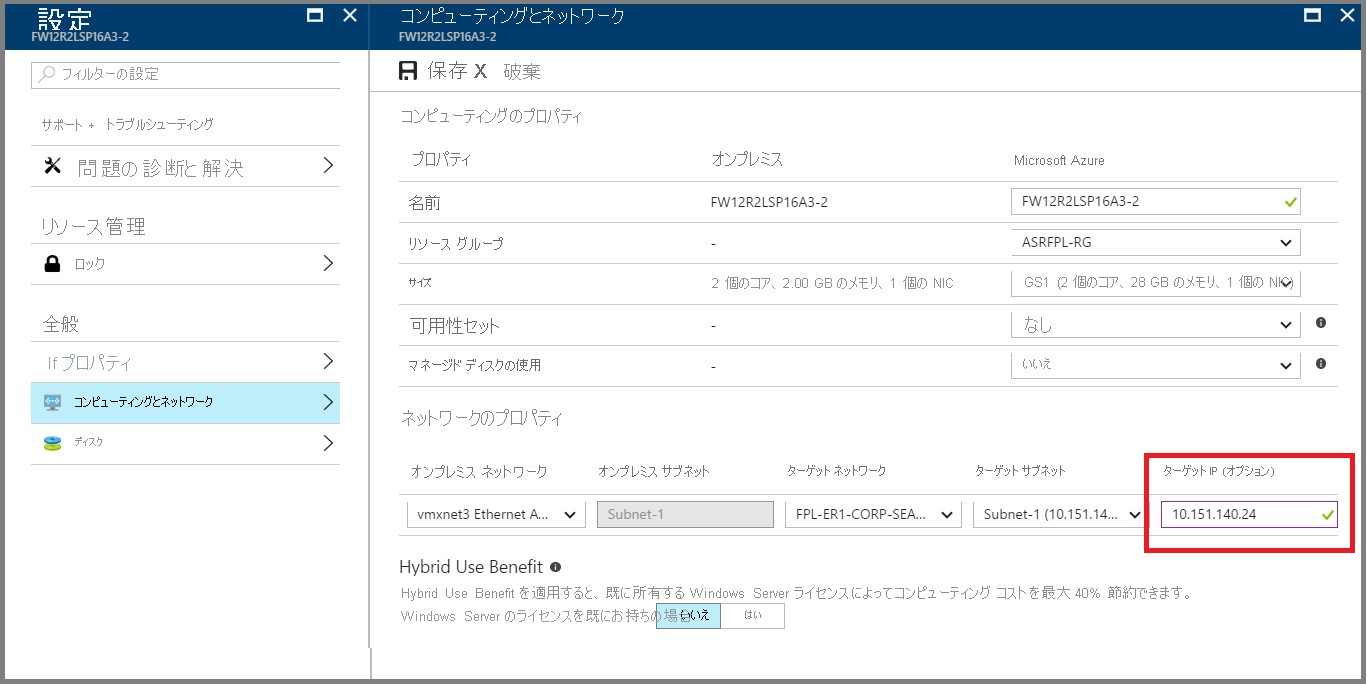
静的 IP を使用している場合は、 [ターゲット IP] フィールドで仮想マシンに割り当てる IP を指定します。
DNS とトラフィックのルーティング
インターネットに面しているサイトの場合は、Azure サブスクリプションで[Priority] 型の Traffic Manager プロファイルを作成します。 そして、次の方法で DNS と Traffic Managerプロファイル の設定をします。
| Where | ソース | 移行先 |
|---|---|---|
| パブリック DNS | SharePoint サイト用のパブリック DNS 例: sharepoint.contoso.com |
Traffic Manager contososharepoint.trafficmanager.net |
| オンプレミス DNS | sharepointonprem.contoso.com | オンプレミスファーム上のパブリック IP |
Traffic Manager プロファイルでプライマリ エンドポイントと復旧エンドポイントを作成します。 オンプレミス エンドポイントには外部エンドポイント、Azure エンドポイントにはパブリック IP を使用してください。 優先順位は、必ずオンプレミス エンドポイントを高く設定します。
Traffic Manager がフェールオーバー後に可用性ポストを自動的に検出できるようにするには、SharePoint の Web 層上の特定のポート (800 など) でテスト ページをホストします。 これは、SharePoint サイトで匿名認証を有効にできない場合の回避策です。
以下の設定値で Traffic Manager プロファイルを設定します。
- ルーティング方法 - [優先順位]
- DNS の有効時間 (TTL) - [30 秒]
- エンドポイント モニター設定 - 匿名認証を有効にできる場合は、特定の Web サイト エンドポイントを指定できます。 あるいは、特定のポート (たとえば 800) でテスト ページを利用できます。
復旧計画の作成
復旧計画では、多層アプリケーションのさまざまな階層のフェールオーバーをシーケンス処理できるため、アプリケーションの整合性が維持されます。 以下の手順に従って、多層 Web アプリケーションの復旧計画を作成します。 復旧計画の作成の詳細については、こちらを参照してください。
フェールオーバー グループへの仮想マシンの追加
アプリおよび Web 層の仮想マシンを追加することによって復旧計画を作成します。
[カスタマイズ] をクリックして仮想マシンをグループ化します。 既定では、すべての仮想マシンが「グループ 1」のメンバーです。
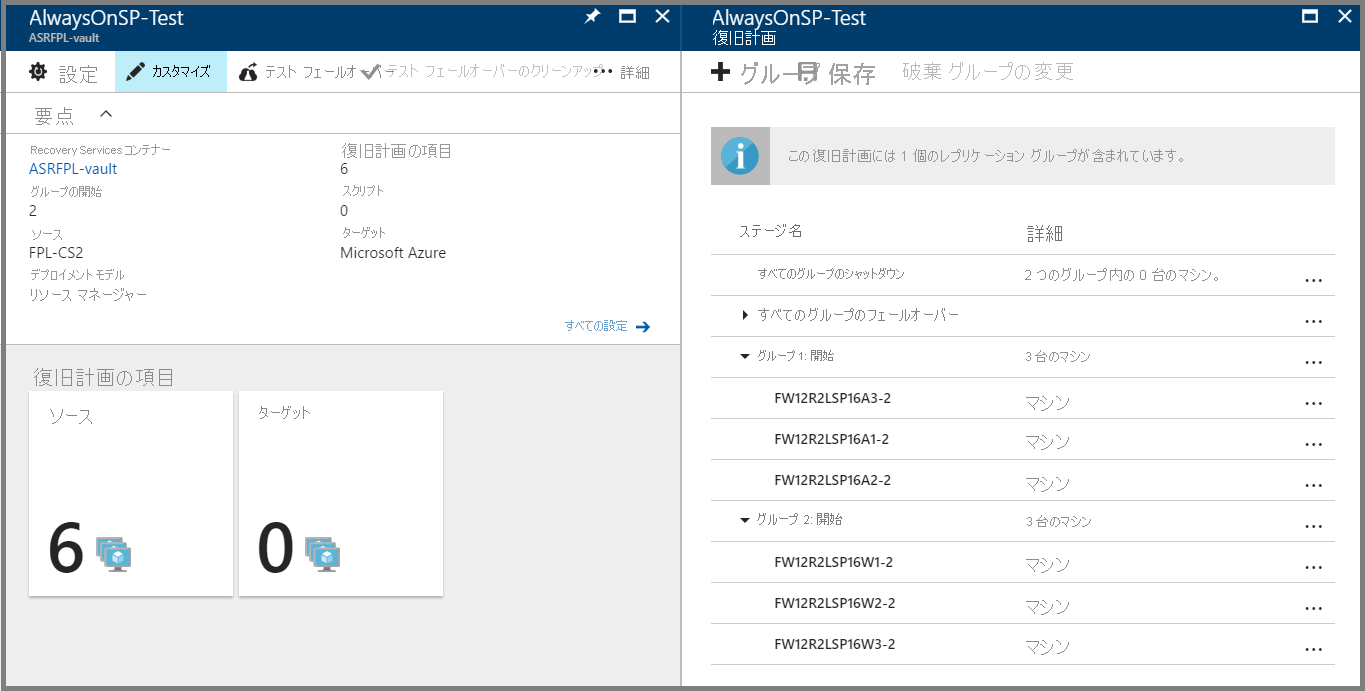
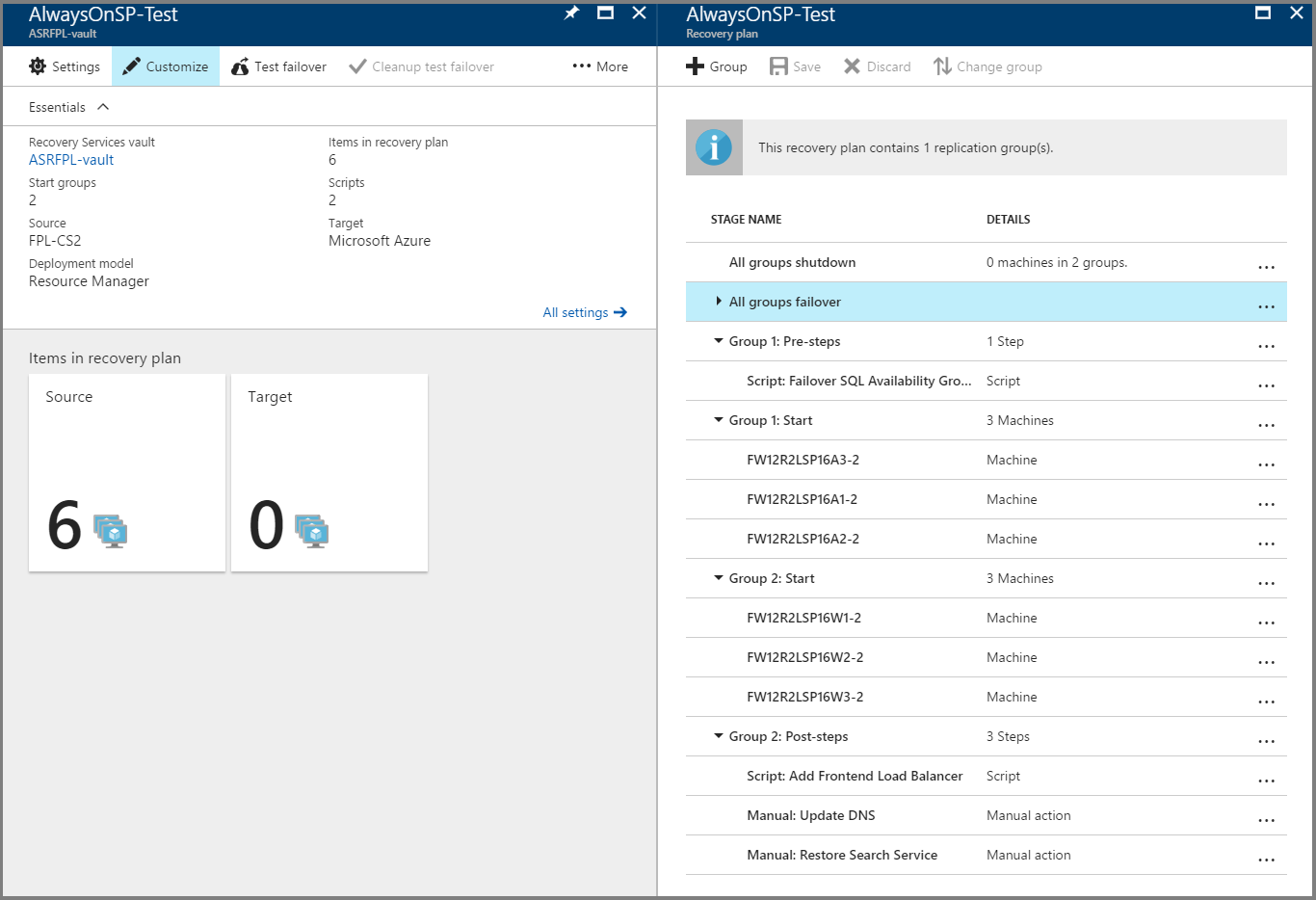
別のグループ (グループ 2) を作成し、Web 層の全仮想マシンをその新しいグループに移動します。 これで、アプリ層の仮想マシンは「グループ 1」のメンバー、Web 層の仮想マシンは「グループ 2」のメンバーになります。 これで、アプリ層の仮想マシンが先ず起動してから、Web 層の仮想マシンが起動します。
復旧計画へのスクリプトの追加
次の [Deploy to Azure] ボタンをクリックすると、オートメーション アカウントによく使われる Azure Site Recovery のスクリプトをデプロイできます。 公開されているスクリプトを使用する場合は、必ず、そのスクリプトのガイダンスに従ってください。

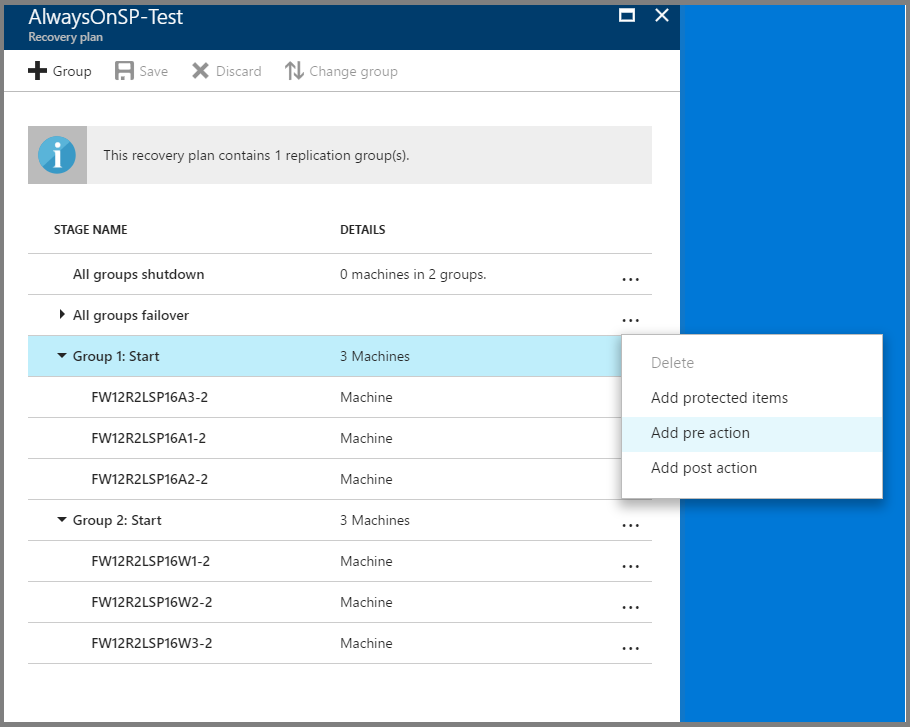
SQL 可用性グループをフェールオーバーするための前処理スクリプトを「グループ 1」に追加します。 サンプル スクリプトで公開されている「ASR-SQL-FailoverAG」スクリプトを使用してください。 必ずスクリプトのガイダンスに従い、適宜、スクリプトの内容を変更します。
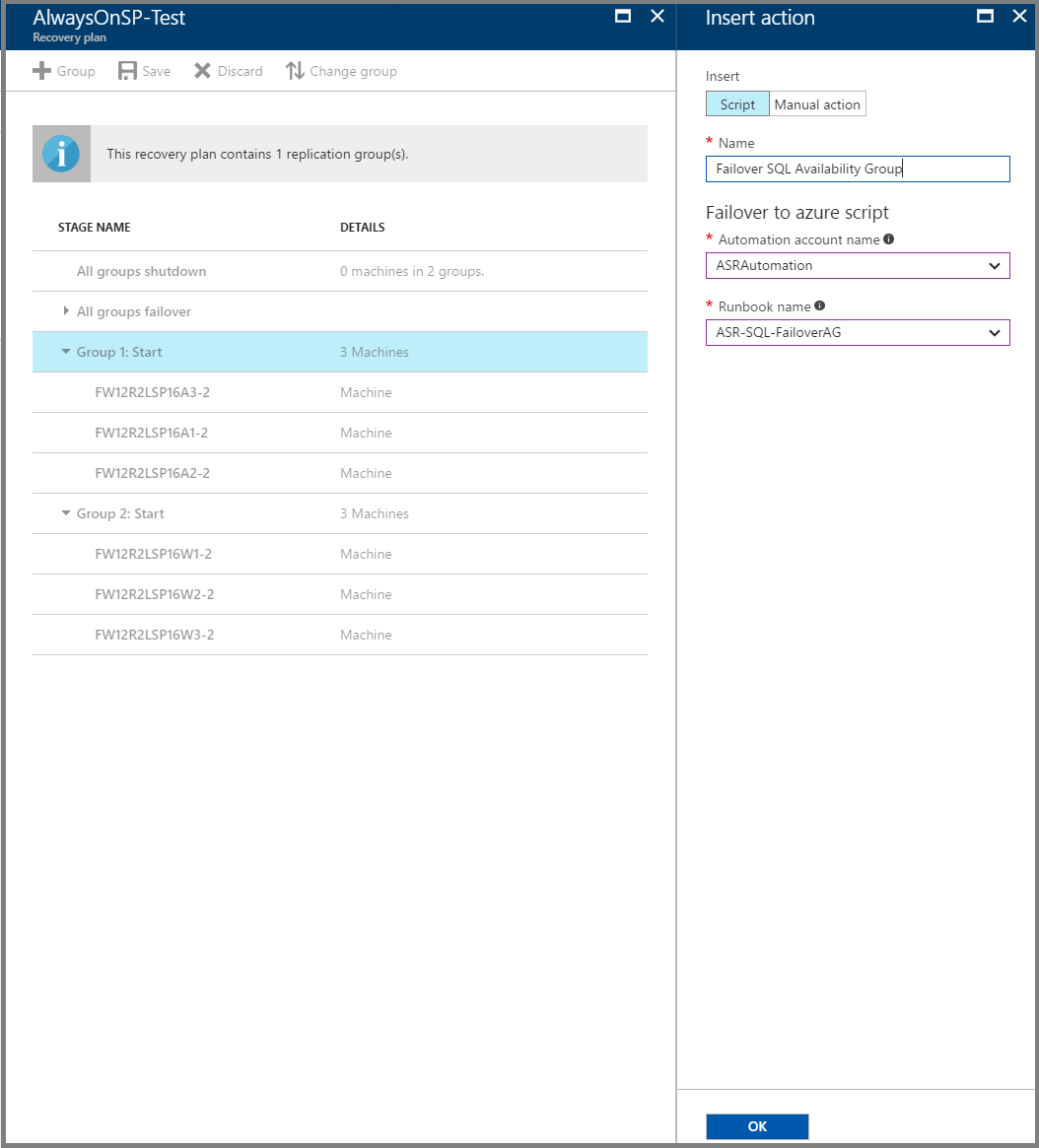
フェールオーバー後のWeb 層仮想マシン (グループ 2) 上のロード バランサーをアタッチするための後処理スクリプトを追加します。 サンプル スクリプトで公開されている「ASR-AddSingleLoadBalancer」スクリプトを使用してください。 必ずスクリプトのガイダンスに従い、適宜、スクリプトの内容を変更します。
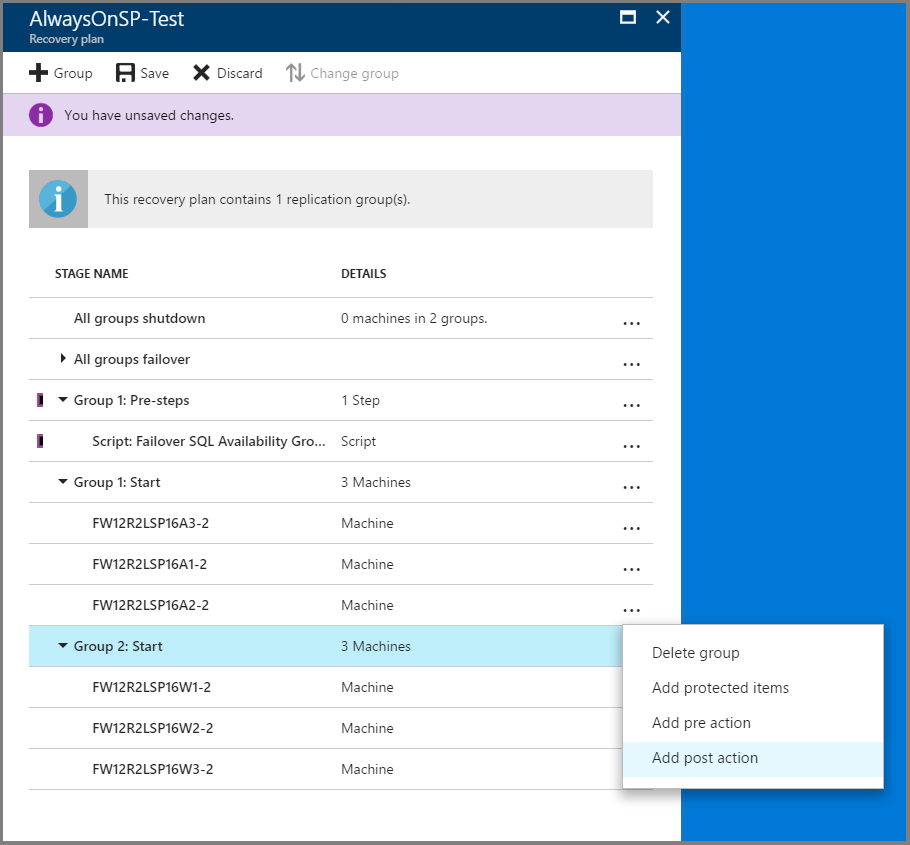
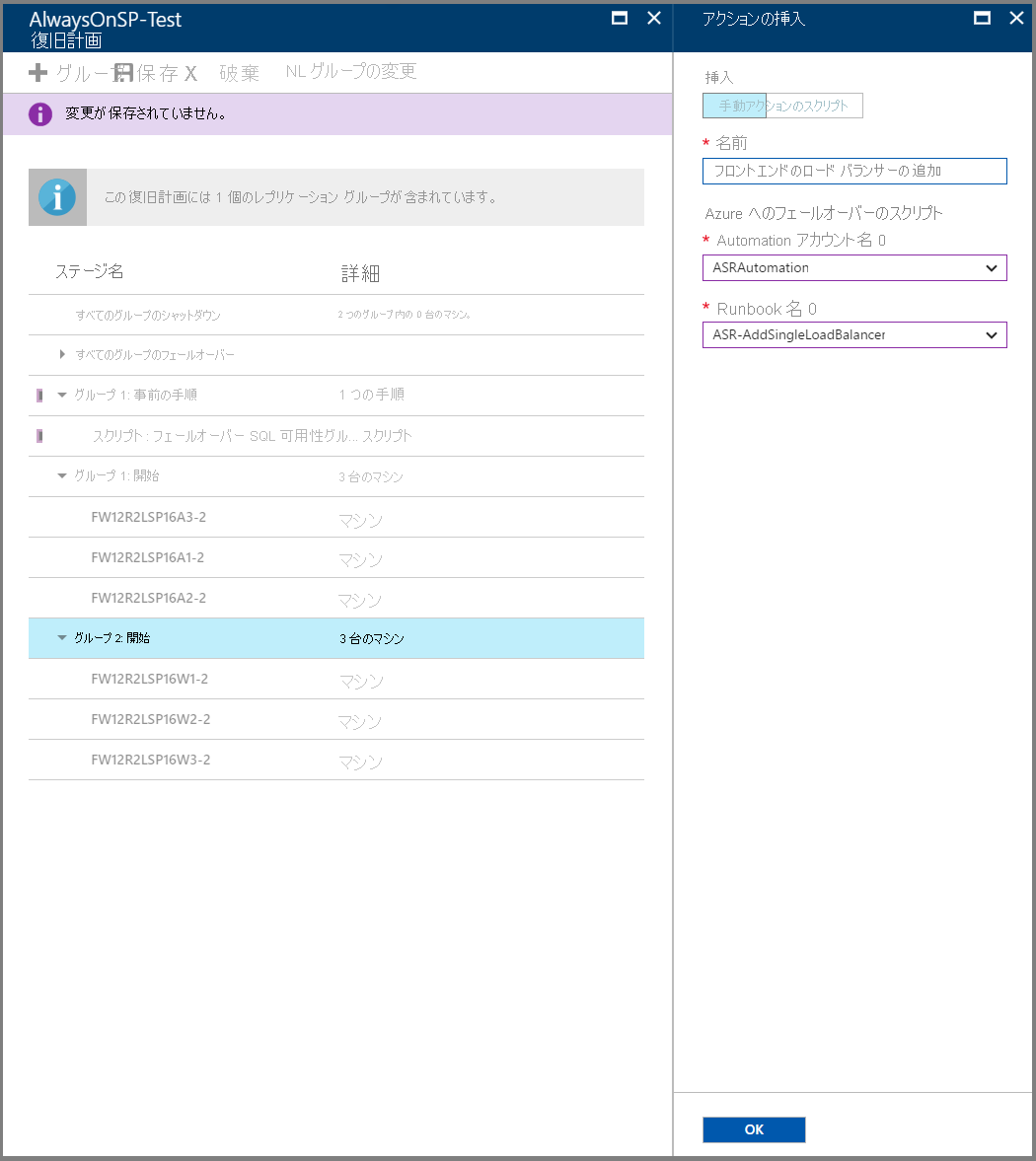
Azure 内の新しいファームを指し示すには、DNS レコードを更新するための手動ステップを追加します。
インターネットに面しているサイトの場合、フェールオーバー後の DNS 更新は必要ありません。 「Networking guidance」の説で説明している手順に従って Traffic Manager の設定をします。 前節の説明通りに Traffic Manager プロファイルを設定したら、Azure 仮想マシン上のダミー ポート (この例では 800) を開くためのスクリプトを追加します。
インターネットに面しているサイトの場合は、新しい Web 層仮想マシンのロード バランサー の IP を指し示すよう DNS レコードを更新するための手動ステップを追加します。
バックアップから検索アプリケーションを復元するか、新しい検索サービスを起動するための手動ステップを追加します。
バックアップから検索サービスアプリケーションを復元する場合は、次の手順に従ってください。
- この手順では、重大イベントの前に Search Service Application のバックアップを実施済みで、かつそのバックアップが障害復旧サイトに存在していると仮定しています。
- バックアップは、そのスケジュールを設定し (たとえば 1 日に 1 回)、コピー手順を使って DR サイトにバックアップを置くようにすることで簡単に行うことができます。 コピー手順には、AzCopy (Azure Copy) などのスクリプト形式のプログラムや、DFSR (Distributed File Services Replication) の設定などを含めることができます。
- SharePoint ファームが稼働していますから、Central Administration に移動し、 [バックアップと復元] から [復元] を選択します。 復元では、指定していたバックアップ先の問い合わせがあります (値の更新が必要になることがあります)。 復元する Search Service Application のバックアップを選択します。
- アプリケーションが復元されます。 復元では、同じトポロジ (サーバーが同数)で、それらサーバーに同じハードディスクドライブ文字が割り当てられていると想定していることに留意してください。 詳細は、SharePoint 2013 ドキュメントの「Restore Search service application」を参照してください。
新しい Search Service Application を使って開始する場合は、以下の手順に従います。
- この手順では、「Search Administration」データベースのバックアップが DR サイトに存在するものと書いてしています。
- 他の Search Service Application のデータベースをレプリケートしていないため、それらデータベースを再作成する必要があります。 このためには、Central Administration に移動し、Search Service Application を削除します。 検索インデックスをホストしている任意のサーバーから、インデックス ファイルを削除します。
- Search Service Application を再作成します。これにより、すべてのデータベースが再作成されます。 GUI からすべてのアクションを行うことは不可能であるため、このサービスアプリケーションを再作成するスクリプトを用意しておくことをお勧めします。 たとえば、インデックスの場所 (ドライブ) や検索トポロジは、SharePoint PowerShell コマンドレットを使用してのみ設定できます。 Windows PowerShell の cmdlet Restore-SPEnterpriseSearchServiceApplication を使用し、ログ出荷されてレプリケート済みの Search Administration データベース、Search_Service__DB を指定します。 このコマンドレットは検索設定とスキーマ、管理対象プロパティ、ルール、およびソースを提供し、他のすべてのコンポーネントの既定セットを作成します。
- Search Service Application を再作成したら、すべてのコンテンツソースについてそれぞれ全クロールを開始して Search Service を開始します。 オンプレミス ファームの、推奨検索事項などの一部分析情報が失われます。
すべての手順を完了したら、復旧計画を保存します。最終的な復旧計画は以下のようになります。
テスト フェールオーバーの実行
このガイダンスに従って、テスト フェールオーバーを実行します。
- Azure Portal に移動し、Recovery Services コンテナーを選択します。
- SharePoint アプリケーション用に作成した復旧計画をクリックします。
- [テスト フェールオーバー] をクリックします。
- テスト フェールオーバー プロセスを開始する復旧ポイントと Azure 仮想ネットワークを選択します。
- セカンダリ環境が立ち上がったら、検証を行うことができます。
- 検証が完了したら、復旧計画で [Cleanup test failover] をクリックできるようになります。テスト フェールオーバー環境がクリーンアップされます。
AD および DNS に対するテスト フェールオーバーの実行に関するガイダンスは、 Test failover considerations for AD and DNS ドキュメントを参照してください。
SQL Always ON 可用性グループのテスト フェールオーバーの実行に関するガイダンスについては、Azure Site Recovery を使用したアプリケーションの DR の実行とテスト フェールオーバーの実行 に関するドキュメントをご覧ください。
フェールオーバーの実行
フェールオーバーの実行については、このガイダンスに従ってください。
- Azure Portal に移動し、Recovery Service コンテナーを選択します。
- SharePoint アプリケーション用に作成した復旧計画をクリックします。
- [フェールオーバー] をクリックします。
- フェールオーバー プロセスを開始する復旧ポイントを選択します。
次のステップ
Site Recovery を利用した他のアプリケーションのレプリケーションについては、他の場所でも説明しています。