Power Platform の Power BI モデリング ガイダンス
Microsoft Dataverse は、Dynamics 365 Customer Engagement や Power Apps キャンバス アプリ、また、Dynamics 365 Customer Voice (以前の Microsoft Forms Pro)、Power Automate の承認、Power Apps ポータルなどを含む多くの Microsoft ビジネス アプリケーション製品の標準データ プラットフォームです。
この記事では、Dataverse に接続する Power BI データ モデルを作成する方法に関するガイダンスを提供します。 Dataverse スキーマと最適化された Power BI スキーマの違いについて説明し、Power BI でビジネス アプリケーション データの可視性を拡張するためのガイダンスを提供します。
セットアップが容易で展開が迅速であり、広く導入が進んでいるため、組織全体の環境でますます多くのデータが Dataverse で保存および管理されています。 つまり、分析をそれらのプロセスと統合する必要性と機会がさらに増えます。 次のような機会があります。
- 組み込みグラフの制約を超えて移動するすべての Dataverse データについてレポートする。
- 特定のレコード内で、コンテキストに応じてフィルター処理された関連レポートへの容易なアクセスを提供する。
- 外部データと統合することによって Dataverse データの価値を高める。
- 複雑なコードを記述する必要なく、Power BI の組み込み人工知能 (AI) を活用する。
- Power Platform ソリューションの有用性と価値を高めることにより、Power Platform ソリューションの導入を増やす。
- アプリ内のデータの価値をビジネス上の意思決定者に提供する。
Power BI を Dataverse に接続する
Power BI を Dataverse に接続するには、Power BI データ モデルを作成する必要があります。 Power BI モデルを作成するには、3 つの方法から選択できます。
- Dataverse コネクタを使用して Dataverse データをインポートする: この方法では、Dataverse データを Power BI モデルにキャッシュ (保存) します。 インメモリ クエリのおかげでパフォーマンスが非常に高速です。 また、モデラーに設計の柔軟性が提供され、他のソースからのデータを統合することも可能になります。 これらの強みにより、Power BI Desktop でモデルを作成するとき、既定モードはデータのインポートです。
- Azure Synapse Link を使用して Dataverse データをインポートする: この方法はインポートによる方法のバリエーションであり、同じように Power BI モデルにデータをキャッシュしますが、Azure Synapse Analytics に接続することによってそれを行います。 Azure Synapse Link for Dataverse を使用すると、Dataverse テーブルは継続的に Azure Synapse または Azure Data Lake Storage (ADLS) Gen2 にレプリケートされます。 このアプローチは、Dataverse 環境の数十万件または数百万件ものレコードに関するレポートを作成するために使用します。
- Dataverse コネクタを使用して DirectQuery 接続を作成する: この方法は、データをインポートする代わりに使用します。 DirectQuery モデルは、モデル構造を定義するメタデータのみで構成されます。 ユーザーがレポートを開くと、データを取得するために Power BI から Dataverse にネイティブ クエリが送信されます。 ほぼリアルタイムの Dataverse データをレポートに表示する必要がある場合、または Dataverse でロール ベースのセキュリティを適用し、アクセスする特権があるデータのみをユーザーに表示する必要がある場合は、DirectQuery モデルを作成することを検討してください。
重要
DirectQuery モデルは、ほぼリアルタイムのレポート作成またはレポートでの Dataverse セキュリティの適用が必要な場合に適した代替手段ですが、そのレポートのパフォーマンスが低下する場合があります。
DirectQuery に関する考慮事項については、この記事の後半で説明します。
Power BI モデルに適した方法を決定するには、次の点を考慮する必要があります。
- クエリ パフォーマンス
- データ ボリューム
- データの遅延時間
- ロール ベース セキュリティ
- セットアップの複雑さ
ヒント
モデル フレームワーク (インポート、DirectQuery、または複合)、その利点と制限事項、Power BI データ モデルの最適化に役立つ機能の詳細については、「Power BI モデル フレームワークを選ぶ」を参照してください。
クエリ パフォーマンス
モデルをインポートするために送信されるクエリは、DirectQuery データ ソースに送信されるネイティブ クエリよりも高速です。 それは、インポートされたデータがメモリにキャッシュされ、分析クエリ (フィルター、グループ化、集計の操作) 用に最適化されているためです。
逆に、DirectQuery モデルは、ユーザーがレポートを開いた後にのみソースからデータを取得し、レポートが表示されるまでに数秒の遅延が発生します。 さらに、レポートに対するユーザーの操作では、Power BI でソースに再クエリを実行する必要があり、応答性がさらに低下します。
データ ボリューム
インポート モデルを開発するときは、モデルに読み込まれるデータを最小限に抑えるようにする必要があります。 大規模なモデルや、時間の経過と共に大規模になると予測されるモデルの場合は、特にそうです。 詳細については、「インポート モデリングのデータ削減手法」を参照してください。
レポートのクエリ結果が大規模でない場合は、Dataverse への DirectQuery 接続が適しています。 大規模なクエリ結果は、レポートのソース テーブルで 20,000 行を超えているか、フィルターが適用された後にレポートに返される結果が 20,000 行を超えています。 この場合は、Dataverse コネクタを使用して Power BI レポートを作成できます。
注意
20,000 という行サイズはハード制限ではありません。 ただし、各データ ソース クエリから結果が 10 分以内に返されるはずです。 この記事の後半では、これらの制限内で作業する方法と、Dataverse DirectQuery の設計に関するその他の考慮事項について説明します。
Dataverse コネクタを使ってデータをデータ モデルにインポートすることで、大きなセマンティック モデル (以前はデータセットと呼ばれていたもの) のパフォーマンスを向上させることができます。
さらに大きなセマンティック モデル (数十万または数百万行) の場合でも、Azure Synapse Link for Dataverse を使うとベネフィットを得ることができます。 このアプローチでは、Dataverse のデータを CSV または Parquet ファイルとして ADLS Gen2 にコピーする、継続的なマネージド パイプラインを設定します。 その後、Power BI で Azure Synapse サーバーレス SQL プールに対してクエリを実行して、インポート モデルを読み込むことができます。
データの遅延時間
Dataverse データの変化が急速で、レポート ユーザーが最新データを参照する必要がある場合は、DirectQuery モデルを使用することで、ほぼリアルタイムのクエリ結果を提供できます。
ヒント
ページの自動更新を使用してリアルタイムの更新を表示する Power BI レポートを作成できます。ただし、レポートが DirectQuery モデルに接続されている場合に限ります。
データ モデルをインポートする場合、最近のデータ変更に関するレポートを作成できるように、データ更新を完了する必要があります。 毎日スケジュールされているデータ更新操作の回数には制限があることに注意してください。 共有容量の場合は、1 日に最大 8 回の更新をスケジュールできます。 Premium 容量の場合は、1 日に最大 48 回の更新をスケジュールでき、15 分間の更新頻度を実現できます。
増分更新を使用して、更新の高速化とほぼリアルタイムのパフォーマンス (Premium でのみ使用できます) を実現することもできます。
ロール ベース セキュリティ
ロール ベースのセキュリティを適用する必要がある場合は、それが Power BI モデル フレームワークの選択に直接影響を与える可能性があります。
Dataverse で複雑なロール ベースのセキュリティを適用して、特定のユーザーに対して特定のレコードへのアクセスを制御できます。 たとえば、営業担当者は営業案件のみを表示できますが、営業マネージャーはすべての営業担当者のすべての営業案件を表示できます。 組織のニーズに基づいて複雑さのレベルを調整できます。
Dataverse に基づく DirectQuery モデルでは、レポート ユーザーのセキュリティ コンテキストを使用した接続ができます。 こうすることで、レポート ユーザーには、アクセスが許可されているデータのみが表示されます。 この方法を使用すると、レポートの設計を簡略化でき、許容範囲のパフォーマンスが提供されます。
パフォーマンス向上のためには、代わりに Dataverse に接続するインポート モデルを作成できます。 この場合、必要に応じて、行レベル セキュリティ (RLS) をモデルに追加できます。
注意
Dataverse で複雑なアクセス許可が適用されている場合は特に、一部の Dataverse ロール ベース セキュリティを Power BI RLS としてレプリケートすることが困難な場合があります。 さらに、Power BI のアクセス許可を Dataverse のアクセス許可と同期させるために、継続的な管理が必要になる場合があります。
Power BI RLS の詳細については、「Power BI Desktop での行レベルのセキュリティ (RLS) のガイダンス」を参照してください。
セットアップの複雑さ
インポートと DirectQuery のどちらのモデルであっても、Power BI で Dataverse コネクタを使用することは簡単で、特別なソフトウェアや管理者特権の Dataverse アクセス許可は必要ありません。 これは、作業を開始する組織または部門にとって利点です。
Azure Synapse Link オプションには、Dataverse へのシステム管理者のアクセス許可と特定の Azure アクセス許可が必要です。 これらの Azure アクセス許可は、ストレージ アカウントと Synapse ワークスペースを設定するために必要です。
推奨プラクティス
このセクションでは、Dataverse に接続する Power BI モデルを作成するときに考慮する必要がある設計パターン (およびアンチパターン) について説明します。 これらのパターンのうち、Dataverse に固有のものはごくわずかですが、Dataverse 作成者が Power BI レポートを作成する際によくある課題となる傾向があります。
特定のユース ケースに焦点を合わせる
"すべて" を解決しようとするのではなく、特定のユース ケースに焦点を合わせましょう。
この推奨事項は、最も一般的な、回避するのが最も困難になりやすいアンチパターンと言えるでしょう。 セルフサービス レポートのすべてのニーズを実現する単一のモデルを構築することは困難です。 実際には、成功したモデルは、単一のコア トピックについての一連のファクトに関する質問に答えるために構築されています。 最初はモデルを制限しているように見えるかもしれませんが、そのトピック内の質問に答えるためにモデルを調整および最適化できるため、実際には力を発揮します。
モデルの目的を明確に理解できるように、以下について自問してみてください。
- このモデルでは、どのようなトピック領域がサポートされますか?
- このレポートが想定しているのは、どのような利用者層でしょうか?
- レポートでどのような質問に回答しようとしていますか?
- 実行可能な最小のセマンティック モデルは何ですか?
レポート ユーザーが複数のトピック領域にわたる質問を単一のレポートで対処することを望んでいるという理由だけで、複数のトピック領域を 1 つのモデルに結合することは避けてください。 そのレポートを複数のレポートに分割し、それぞれ異なるトピック (またはファクト テーブル) に焦点を合わせることで、はるかに効率的でスケーラブルな管理しやすいモデルを作成できます。
スター スキーマを設計する
Dataverse スキーマに慣れている Dataverse 開発者と管理者は、Power BI で同じスキーマを再現したくなる可能性があります。 このアプローチはアンチパターンですが、一貫性を維持することは "正しいと感じる" ので、克服するのは最も困難と言えます。
リレーショナル モデルとしての Dataverse は、その目的に十分適しています。 ただし、分析レポート用に最適化された分析モデルとしては設計されていません。 分析データをモデリングするための最も一般的なパターンは、"スター スキーマ" 設計です。 スター スキーマは、リレーショナル データ ウェアハウスで広く採用されている成熟したモデリング手法です。 モデラーは、モデル テーブルを "ディメンション" または "ファクト" として分類する必要があります。 レポートでは、ディメンション テーブル列を使用してフィルター処理またはグループ化したり、ファクト テーブルの列を集計したりできます。
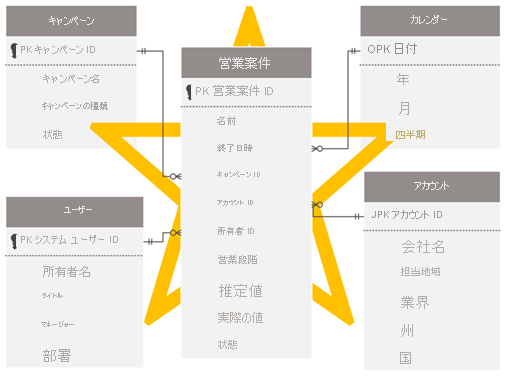
詳細については、「スター スキーマと Power BI での重要性を理解する」を参照してください。
Power Query クエリを最適化する
Power Query のマッシュアップ エンジンは、効率を高めるために、可能な場合は常に "クエリ フォールディング" を適用しようとします。 フォールディングを実現するクエリは、クエリ処理をソース システムに委任します。
ソース システム (この場合は Dataverse) は、フィルター処理または要約された結果を Power BI に提供する必要があります。 フォールドされたクエリは、多くの場合、フォールドされていないクエリよりも大幅に高速で効率的です。
クエリ フォールディングを実現する方法の詳細については、「Power Query のクエリ フォールディング」を参照してください。
注意
Power Query の最適化は、広範なトピックです。 Power BI Desktop での作成時およびモデル更新時に、Power Query で行われていることについて理解を深めるには、「クエリ診断」を参照してください。
クエリ列の数を最小限に抑える
既定では、Power Query を使用して Dataverse テーブルを読み込むと、すべての行とすべての列が取得されます。 たとえば、システム ユーザー テーブルに対してクエリを実行するとき、1,000 を超える列が含まれる可能性があります。 メタデータ内の列には、他のエンティティとのリレーションシップとオプション ラベルへの参照が含まれているため、列の合計数は Dataverse テーブルの複雑さに応じて増加します。
すべての列からデータを取得しようとすることは、アンチパターンになります。 多くの場合、データ更新操作が長くなり、データを返すために必要な時間が 10 分を超えるとクエリが失敗します。
レポートに必要な列のみを取得することをお勧めします。 多くの場合、レポートの開発が完了したときにクエリを再評価してリファクタリングすることをお勧めします。そうすることで、未使用の列を識別して削除できます。 詳細については、「インポート モデリングのデータ削減手法 (不要な列を削除する)」を参照してください。
さらに、ソースにフォールドバックされるように、Power Query の "列の削除" ステップを早い段階で導入してください。 こうすることで、後から破棄するためだけに (展開されたステップで) ソース データを抽出するという不要な作業を回避できます。
多数の列を含むテーブルがある場合、Power Query の対話型クエリ ビルダーを使用するのは現実的でないことがあります。 この場合は、次のようにすることができます。まず空のクエリを作成します。 その後、詳細エディターを使用して、開始点を作成する最小限のクエリを貼り付けることができます。
account テーブルの 2 つの列からだけデータを取得する次のクエリについて考えてみましょう。
let
Source = CommonDataService.Database("demo.crm.dynamics.com", [CreateNavigationProperties=false]),
dbo_account = Source{[Schema="dbo", Item="account"]}[Data],
#"Removed Other Columns" = Table.SelectColumns(dbo_account, {"accountid", "name"})
in
#"Removed Other Columns"
ネイティブ クエリを記述する
特定の変換要件がある場合は、Transact-SQL のサブセットである Dataverse SQL で記述されたネイティブ クエリを使用して、パフォーマンスを向上させることができます。 ネイティブ クエリは、次の目的のために記述できます。
- (
WHERE句を使用して) 行の数を減らす。 - (
GROUP BYおよびHAVING句を使用して) データを集計する。 - (
JOINまたはAPPLY構文を使用して) 特定の方法でテーブルを結合する。 - サポートされている SQL 関数を使用する。
詳細については、次を参照してください。
EnableFolding オプションを使用してネイティブ クエリを実行する
Power Query で Value.NativeQuery 関数を使用してネイティブ クエリを実行します。
この関数を使用する場合は、クエリを確実に Dataverse サービスにフォールドバックするために、EnableFolding=true オプションを追加することが重要です。 このオプションを追加しない限り、ネイティブ クエリはフォールドされません。 このオプションを有効にすると、パフォーマンスが大幅に向上し、場合によっては最大 97% 高速になります。
account テーブルから選択した列をネイティブ クエリを使用して取得する次のクエリを考えてみましょう。 EnableFolding=true オプションが設定されているため、ネイティブ クエリはフォールドされます。
let
Source = CommonDataService.Database("demo.crm.dynamics.com"),
dbo_account = Value.NativeQuery(
Source,
"SELECT A.accountid, A.name FROM account A"
,null
,[EnableFolding=true]
)
in
dbo_account
大量のデータからデータのサブセットを取得する場合、最大のパフォーマンス向上を期待できます。
ヒント
パフォーマンスの向上は、Power BI がソース データベースにクエリを実行する方法によっても異なります。 たとえば、COUNTDISTINCT DAX 関数を使用するメジャーでは、フォールディング ヒントの有無にかかわらず、ほとんど改善が見られなくなりました。 SUMX DAX 関数を使用するようにメジャー数式を書き換えると、クエリのフォールディングによって、ヒントのない同じクエリに対して 97% の向上がもたらされました。
詳細については、「Value.NativeQuery」を参照してください。 (EnableFolding オプションは特定のデータ ソースにのみ固有であるため、説明されていません。)
評価ステージを高速化する
Dataverse コネクタ (旧称 Common Data Service) を使用している場合は、データ インポートの評価ステージを高速化する CreateNavigationProperties=false オプションを追加できます。
データ インポートの評価ステージでは、そのソースのメタデータを反復処理して、考えられるすべてのテーブル リレーションシップが特定されます。 そのメタデータは、Dataverse の場合は特に、広範囲に及ぶことがあります。 このオプションをクエリに追加することで、これらのリレーションシップを使用しないことを Power Query に指示します。 このオプションを使用すると、Power BI Desktop で更新のそのステージをスキップし、データの取得に進むことができます。
注意
クエリが展開されたリレーションシップ列に依存する場合は、このオプションを使用しないでください。
account テーブルからデータを取得する例を考えてみましょう。 これには、区域に関連した 3 つの列が含まれています。territory、territoryid、territoryidname です。
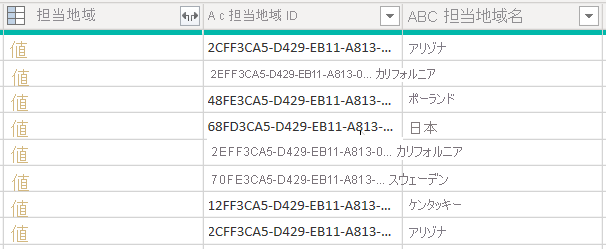
CreateNavigationProperties=false オプションを設定すると、territoryid および territoryidname 列は残りますが、リレーションシップ列である territory 列 (Value のリンクが表示されている) は除外されます。 Power Query のリレーションシップ列は、"モデル リレーションシップ" (モデル テーブル間でフィルターを伝達する) とは異なる概念であることを理解しておくことが重要です。
CreateNavigationProperties=false オプションを (Source ステップで) 使用してデータ インポートの評価ステージを高速化する次のクエリを考えてみましょう。
let
Source = CommonDataService.Database("demo.crm.dynamics.com"
,[CreateNavigationProperties=false]),
dbo_account = Source{[Schema="dbo", Item="account"]}[Data],
#"Removed Other Columns" = Table.SelectColumns(dbo_account, {"accountid", "name", "address1_stateorprovince", "address1_country", "industrycodename", "territoryidname"}),
#"Renamed Columns" = Table.RenameColumns(#"Removed Other Columns", {{"name", "Account Name"}, {"address1_country", "Country"}, {"address1_stateorprovince", "State or Province"}, {"territoryidname", "Territory"}, {"industrycodename", "Industry"}})
in
#"Renamed Columns"
このオプションを使用すると、Dataverse テーブルに他のテーブルとのリレーションシップが多数ある場合に、パフォーマンスが大幅に向上する可能性があります。 たとえば、SystemUser テーブルはデータベース内の他のすべてのテーブルに関連しているため、このテーブルの更新パフォーマンスは CreateNavigationProperties=false オプションを設定することでメリットがあります。
注意
このオプションを使用すると、インポート テーブルまたはデュアル ストレージ モード テーブルのデータ更新のパフォーマンスを向上させることができます。これには、Power Query エディター ウィンドウの変更を適用するプロセスが含まれます。 DirectQuery ストレージ モード テーブルの対話型クロスフィルター処理のパフォーマンスは向上しません。
空白の選択ラベルを解決する
Power BI で Dataverse の選択ラベルが空白であることが判明した場合、ラベルが表形式データ ストリーム (TDS) エンドポイントに発行されていないことが原因である可能性があります。
この場合は、Dataverse Maker ポータルを開き、[ソリューション] 領域に移動してから、[すべてのカスタマイズの発行] を選択します。 発行プロセスでは、TDS エンドポイントが最新のメタデータで更新され、Power BI でオプション ラベルを使用できるようになります。
Azure Synapse Link を使う大きなセマンティック モデル
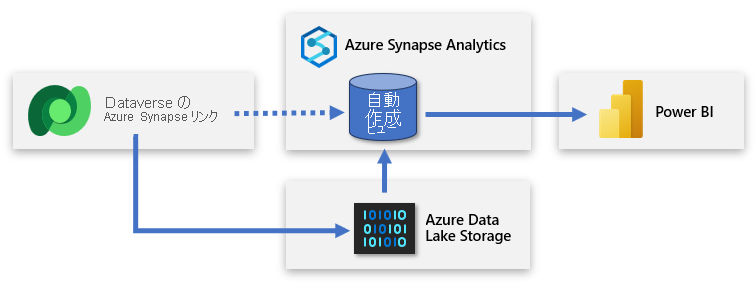
Dataverse には、テーブルを Azure Data Lake Storage (ADLS) に同期し、Azure Synapse ワークスペースを介してそのデータに接続する機能が含まれています。 最小限の労力で、Azure Synapse Link を設定して Dataverse データを Azure Synapse に挿入し、データ チームがより深い分析情報を検出できるようにすることができます。
Azure Synapse Link を使用すると、Dataverse からデータ レイクへのデータとメタデータの継続的なレプリケーションが可能になります。 また、Power BI クエリの便利なデータ ソースとして、組み込みのサーバーレス SQL プールも提供されます。
このアプローチの強みは重要です。 お客様は、さまざまな高度なサービスを使用して、Dataverse データ全体の分析、ビジネス インテリジェンス、機械学習のワークロードを実行できます。 高度なサービスには、Apache Spark、Power BI、Azure Data Factory、Azure Databricks、Azure Machine Learning が含まれます。
Dataverse 用 Azure Synapse リンクを作成する
Dataverse 用 Azure Synapse リンクを作成するには、次の前提条件を確認する必要があります。
- Dataverse 環境へのシステム管理者のアクセス許可。
- Azure Data Lake Storage の場合:
- ADLS Gen2 で使用するストレージ アカウントが必要です。
- ストレージ アカウントに対するストレージ BLOB データ所有者とストレージ BLOB データ共同作成者のアクセス許可が割り当てられている必要があります。 詳細については、「ロールベースのアクセス制御 (Azure RBAC)」を参照してください。
- ストレージ アカウントで階層型名前空間を有効にする必要があります。
- ストレージ アカウントで読み取りアクセス geo 冗長ストレージ (RA-GRS) を使用することをお勧めします。
- Synapse ワークスペースの場合:
- Synapse ワークスペースへのアクセス権があり、Synapse 管理者のアクセス許可が割り当てられている必要があります。 詳細については、「組み込みの Synapse RBAC ロールとスコープ」を参照してください。
- ワークスペースは、ADLS Gen2 ストレージ アカウントと同じリージョンに存在する必要があります。
セットアップのためには、Power Apps にサインインし、Dataverse を Azure Synapse ワークスペースに接続する必要があります。 ウィザードに似たエクスペリエンスにより、ストレージ アカウントとエクスポートするテーブルを選択して、新しいリンクを作成できます。 すると、Azure Synapse Link で ADLS Gen2 ストレージにデータがコピーされ、組み込みのAzure Synapseサーバーレス SQL プールにビューが自動的に作成されます。 その後、それらのビューに接続して Power BI モデルを作成できます。
ヒント
Azure Synapse リンクの作成、管理、監視に関する完全なドキュメントについては、「Azure Synapse Workspace を使用して Azure Synapse Link for Dataverse を作成する」を参照してください。
2 つ目のサーバーレス SQL データベースを作成する
2 つ目のサーバーレス SQL データベースを作成し、それを使用してカスタム レポート ビューを追加できます。 このようにして、有用で関連性の高いデータに基づいたモデルを作成できるように、簡略化されたデータ セットを Power BI 作成者に提示できます。 新しいサーバーレス SQL データベースは、作成者のプライマリ ソース接続になり、データ レイクから取得されたデータのわかりやすい表現になります。
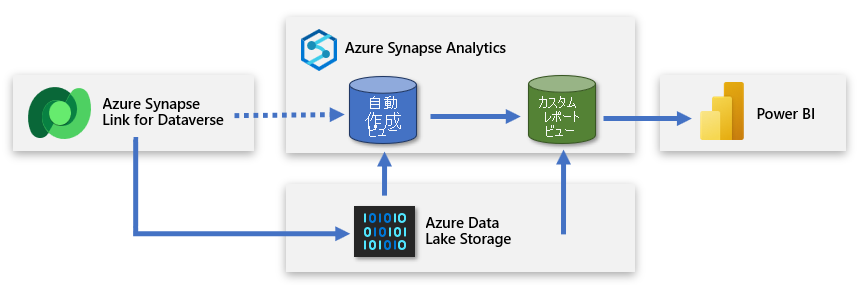
このアプローチでは、フォーカス、エンリッチ、フィルター処理されたデータが Power BI に提供されます。
Azure Synapse Studio を使用して、Azure Synapse ワークスペースにサーバーレス SQL データベースを作成できます。 SQL データベースの種類として [サーバーレス] を選択し、データベース名を入力します。 Power Query からワークスペースの SQL エンドポイントに接続することで、このデータベースに接続できます。
カスタム ビューを作成する
サーバーレス SQL プール クエリをラップしたカスタム ビューを作成できます。 これらのビューは、Power BI の接続先データの簡単でクリーンなソースとして機能します。 ビューは次のようになります。
- 選択肢フィールドに関連付けられているラベルを含みます。
- データ モデリングに必要な列のみを含めることで、複雑さを軽減します。
- 非アクティブなレコードなどの不要な行を除外します。
キャンペーン データを取得する次のビューについて考えてみましょう。
CREATE VIEW [VW_Campaign]
AS
SELECT
[base].[campaignid] AS [CampaignID]
[base].[name] AS [Campaign],
[campaign_status].[LocalizedLabel] AS [Status],
[campaign_typecode].[LocalizedLabel] AS [Type Code]
FROM
[<MySynapseLinkDB>].[dbo].[campaign] AS [base]
LEFT OUTER JOIN [<MySynapseLinkDB>].[dbo].[OptionsetMetadata] AS [campaign_typecode]
ON [base].[typecode] = [campaign_typecode].[option]
AND [campaign_typecode].[LocalizedLabelLanguageCode] = 1033
AND [campaign_typecode].[EntityName] = 'campaign'
AND [campaign_typecode].[OptionSetName] = 'typecode'
LEFT OUTER JOIN [<MySynapseLinkDB>].[dbo].[StatusMetadata] AS [campaign_status]
ON [base].[statuscode] = [campaign_Status].[status]
AND [campaign_status].[LocalizedLabelLanguageCode] = 1033
AND [campaign_status].[EntityName] = 'campaign'
WHERE
[base].[statecode] = 0;
ビューには 4 つの列のみが含まれていて、それぞれがフレンドリ名でエイリアス化されていることに注意してください。 必要な行 (この場合はアクティブなキャンペーン) のみを返す WHERE 句もあります。 また、ビューは OptionsetMetadata および StatusMetadata テーブルに結合されているキャンペーン テーブルに対してクエリを実行し、それによって選択ラベルを取得します。
ヒント
メタデータを取得する方法の詳細については、「Azure Synapse Link for Dataverse から選択ラベルに直接アクセスする」を参照してください。
適切なテーブルのクエリを実行する
Azure Synapse Link for Dataverse を使用すると、データがデータ レイク内のデータと継続的に同期されます。 使用率の高いアクティビティでは、同時書き込みと読み取りによってロックが作成され、クエリが失敗する可能性があります。 データを取得するときの信頼性を確保するために、テーブル データの 2 つのバージョンが Azure Synapse で同期されます。
- ほぼリアルタイムのデータ: 最初に抽出または最後に同期されてから変更されたデータを検出することで、Azure Synapse Link を介して Dataverse から同期されたデータのコピーを効率的に提供します。
- スナップショット データ: 一定の間隔 (この場合は 1 時間ごと) で更新される、ほぼリアルタイムのデータの読み取り専用コピーを提供します。 スナップショット データ テーブル名には、名前に _partitioned が追加されます。
大量の読み取りおよび書き込み操作が同時に実行されると予想される場合は、クエリ エラーを回避するためにスナップショット テーブルからデータを取得します。
詳細については、「ほぼリアルタイムのデータと読み取り専用のスナップショット データにアクセスする」を参照してください。
Synapse Analytics に接続する
Azure Synapse サーバーレス SQL プールに対してクエリを実行するには、そのワークスペースの SQL エンドポイントが必要です。 サーバーレス SQL プールのプロパティを開くと、Synapse Studio からエンドポイントを取得できます。
Power BI Desktop で、Azure Synapse Analytics SQL コネクタを使用して Azure Synapse に接続できます。 サーバーの入力を求められたら、ワークスペースの SQL エンドポイントを入力します。

DirectQuery に関する考慮事項
DirectQuery ストレージ モードを使用して要件を解決できる多くのユース ケースがあります。 ただし、DirectQuery を使用すると、Power BI レポートのパフォーマンスに悪影響を及ぼす可能性があります。 Dataverse への DirectQuery 接続を使用するレポートは、インポート モデルを使用するレポートほど高速ではなくなります。 一般に、可能な場合は常に、Power BI にデータをインポートすることをお勧めします。
DirectQuery を使用する場合は、このセクションのトピックを検討することをお勧めします。
どのようなときに DirectQuery ストレージ モードを使用するかの決定について詳しくは、「Power BI モデル フレームワークを選ぶ」を参照してください。
デュアル ストレージ モード ディメンション テーブル
デュアル ストレージ モード テーブルは、インポート モードと DirectQuery ストレージ モードの両方を使用するように設定されます。 Power BI は、クエリ時に、使用する最も効率的なモードを決定します。 Power BI では、可能な場合は常に、インポートされたデータを使用してクエリを満たそうとします。その方が高速だからです。
必要に応じて、ディメンション テーブルをデュアル ストレージ モードに設定することを検討してください。 そうすることで、ディメンション テーブルの列に基づくことが多いスライサー ビジュアルとフィルター カード リストは、より迅速にレンダリングされます。これは、インポートされたデータからクエリが実行されるためです。
重要
ディメンション テーブルで Dataverse セキュリティ モデルを継承する必要がある場合、デュアル ストレージ モードを使用することは適切ではありません。
通常、大量のデータを格納するファクト テーブルは、DirectQuery ストレージ モード テーブルとして維持する必要があります。 それらは、関連するデュアル ストレージ モード ディメンション テーブルによってフィルター処理されます。それをファクト テーブルに結合して、効率的なフィルター処理とグループ化を実現できます。
次のデータ モデル設計について考えてみましょう。 Owner、Account、Campaign という 3 つのディメンション テーブルにはストライプの境界線がついています。これは、デュアル ストレージ モードに設定されていることを意味します。
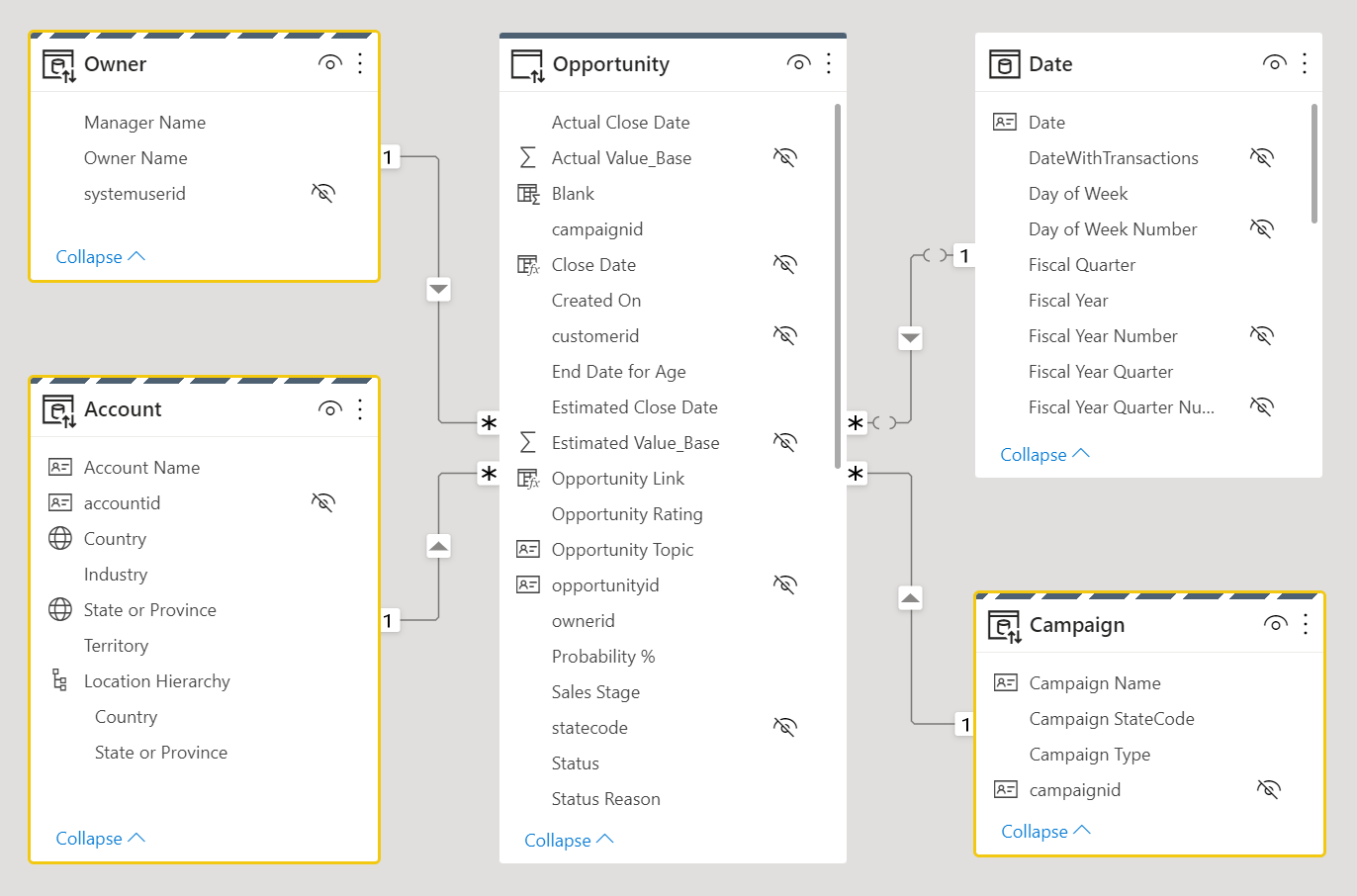
デュアル ストレージを含むテーブル ストレージのモードについて詳しくは、「Power BI Desktop でストレージ モードを管理する」を参照してください。
シングル サインオンを有効にする
DirectQuery モデルを Power BI サービスに発行するときに、セマンティック モデルの設定を使って、Microsoft Entra ID (旧称: Azure Active Directory) OAuth2 を使ったシングル サインオン (SSO) をレポート ユーザーに対して有効にできます。 レポート ユーザーのセキュリティ コンテキストで Dataverse クエリを実行する必要がある場合は、このオプションを有効にする必要があります。
SSO オプションを有効にすると、Power BI から Dataverse へのクエリで、レポート ユーザーの認証済み Microsoft Entra 資格情報が送信されます。 このオプションを使用すると、データ ソースで設定されているセキュリティ設定を Power BI で優先できます。
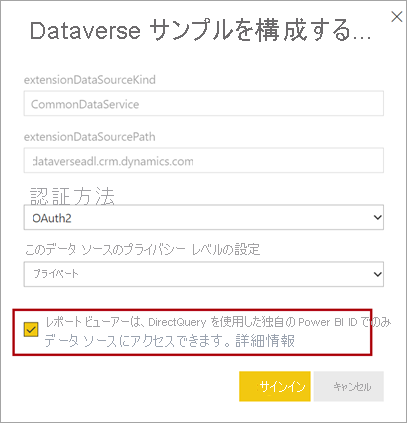
詳細については、「DirectQuery ソースのシングル サインオン (SSO)」を参照してください。
Power Query で "自分の" フィルターをレプリケートする
Dataverse 上に構築された Microsoft Dynamics 365 Customer Engagement (CE) とモデル駆動型 Power Apps を使用する場合は、所有者などのユーザー名フィールドが現在のユーザーと等しいレコードのみを表示するビューを作成できます。 たとえば、"自分のオープンしている営業案件"、"自分のアクティブなサポート案件" のような名前のビューを作成できます。
Dynamics 365 の "自分のアクティブな取引先企業" ビューに、"所有者が現在のユーザーと等しい" フィルターを含める方法の例を考えてみましょう。
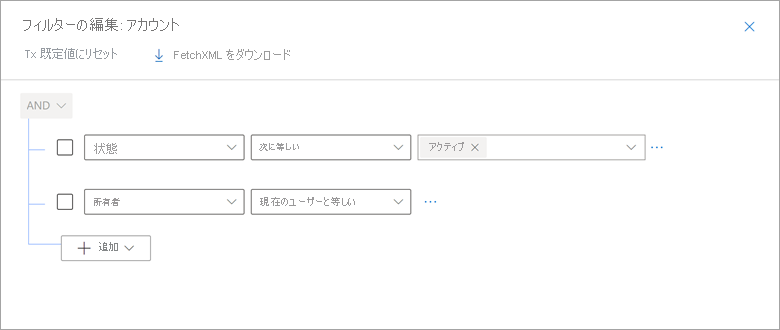
CURRENT_USER トークンを埋め込むネイティブ クエリを使用して、この結果を Power Query で再現できます。
現在のユーザーの取引先企業を返すネイティブ クエリを示す次の例を考えてみましょう。 WHERE 句で、ownerid 列が CURRENT_USER トークンによってフィルター処理されていることに注意してください。
let
Source = CommonDataService.Database("demo.crm.dynamics.com", [CreateNavigationProperties=false],
dbo_account = Value.NativeQuery(Source, "
SELECT
accountid, accountnumber, ownerid, address1_city, address1_stateorprovince, address1_country
FROM account
WHERE statecode = 0
AND ownerid = CURRENT_USER
", null, [EnableFolding]=true])
in
dbo_account
モデルを Power BI サービスに発行するときに、シングル サインオン (SSO) を有効にする必要があります。これにより、Power BI から Dataverse にレポート ユーザーの認証済み Microsoft Entra 資格情報が送信されます。
補足的なインポート モデルを作成する
パフォーマンスが低下することを "知りながら" Dataverse のアクセス許可を適用する DirectQuery モデルを作成できます。 その後、RLS アクセス許可を適用できる特定のサブジェクトまたは対象ユーザーを対象とするインポート モデルを使って、このモデルを補完できます。
たとえば、インポート モデルでは、すべての Dataverse データへのアクセスを提供できますが、アクセス許可は適用されません。 このモデルは、すべての Dataverse データに既にアクセスできる役員に適しています。
別の例として、Dataverse で販売地域別にロール ベースのアクセス許可を適用する場合、1 つのインポート モデルを作成し、RLS を使用してそれらのアクセス許可をレプリケートできます。 または、販売地域ごとにモデルを作成することもできます。 その後、各地域の営業担当者に、それらのモデル (セマンティック モデル) に対する読み取りアクセス許可を付与できます。 これらの地域モデルの作成を容易にするために、パラメーターとレポート テンプレートを使用できます。 詳細については、「Power BI Desktop でレポート テンプレートを作成して使用する」を参照してください。
関連するコンテンツ
この記事に関する詳細については、次のリソースを参照してください。
- Azure Synapse Link for Dataverse
- Power BI のスター スキーマおよび重要性について
- インポート モデリングのデータ削減手法
- わからないことがある場合は、 Power BI コミュニティで質問してみてください。
- Power BI チームへのご提案は、 Power BI を改善するためのアイデアをお寄せください
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示