BI-løsningsarkitektur i Kompetansesenteret
Denne artikkelen er rettet mot IT-eksperter og IT-ansvarlige. Du vil lære om BI-løsningsarkitektur i COE og de ulike teknologiene som brukes. Teknologier inkluderer Azure, Power BI og Excel. Sammen kan de utnyttes til å levere en skalerbar og datadrevet sky-BI-plattform.
Utforming av en robust BI-plattform er noe som å bygge en bro. en bro som kobler transformerte og berikede kildedata til dataforbrukere. Utformingen av en så kompleks struktur krever en teknisk tankegang, selv om det kan være en av de mest kreative og givende IT-arkitekturene du kan designe. I en stor organisasjon kan en BI-løsningsarkitektur bestå av:
- Datakilder
- Datainntak
- Klargjøring av store data / data
- Datalager
- SEMANTISKE BI-modeller
- Rapporter
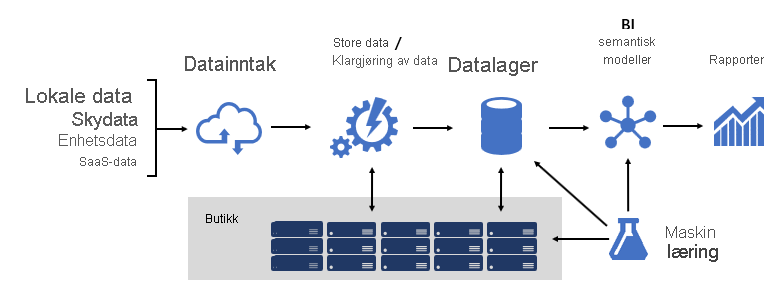
Plattformen må støtte spesifikke krav. Spesielt må den skalere og utføre for å møte forventningene til forretningstjenester og dataforbrukere. Samtidig må det være sikkert fra grunnen av. Og det må være tilstrekkelig robust til å tilpasse seg endringer , fordi det er en visshet om at nye data og emneområder med tiden må hentes på nettet.
Strukturer
Hos Microsoft har vi fra begynnelsen tatt i bruk en systemlignende tilnærming ved å investere i rammeutvikling. Rammeverk for tekniske prosesser og forretningsprosesser øker gjenbruk av utforming og logikk og gir et konsekvent resultat. De tilbyr også fleksibilitet i arkitektur som utnytter mange teknologier, og de effektiviserer og reduserer tekniske kostnader via repeterbare prosesser.
Vi lærte at godt utformede rammeverk øker synligheten i dataavstamming, konsekvensanalyse, vedlikehold av forretningslogikk, administrasjon av taksonomi og effektivisering av styring. Utviklingen ble også raskere, og samarbeid på tvers av store team ble mer responsivt og effektivt.
Vi vil beskrive flere av våre rammeverk i denne artikkelen.
Datamodeller
Datamodeller gir deg kontroll over hvordan data struktureres og åpnes. For forretningstjenester og dataforbrukere er datamodeller deres grensesnitt med BI-plattformen.
En BI-plattform kan levere tre ulike typer modeller:
- Enterprise-modeller
- SEMANTISKE BI-modeller
- Maskin-Læring (ML)-modeller
Enterprise-modeller
Enterprise-modeller bygges og vedlikeholdes av IT-arkitekter. Noen ganger kalles de dimensjonale modeller eller datamarter. Vanligvis lagres data i relasjonsformat som dimensjons- og faktatabeller. Disse tabellene lagrer rensede og berikede data konsolidert fra mange systemer, og de representerer en autoritativ kilde for rapportering og analyse.
Virksomhetsmodeller leverer en konsekvent og enkel datakilde for rapportering og BI. De bygges én gang og deles som en bedriftsstandard. Styringspolicyer sikrer at dataene er sikre, slik at tilgang til sensitive datasett, for eksempel kundeinformasjon eller økonomi, er begrenset på et behovsbasis. De vedtar navnekonvensjoner som sikrer konsistens, og dermed ytterligere etablerer troverdigheten til data og kvalitet.
I en skybasert BI-plattform kan bedriftsmodeller distribueres til et Synapse SQL-utvalg i Azure Synapse. Synapse SQL-utvalget blir deretter den eneste versjonen av sannheten organisasjonen kan stole på for rask og robust innsikt.
SEMANTISKE BI-modeller
SEMANTISKE BI-modeller representerer et semantisk lag over virksomhetsmodeller. De er bygget og vedlikeholdt av BI-utviklere og forretningsbrukere. BI-utviklere oppretter semantiske kjernemodeller for BI som henter data fra virksomhetsmodeller. Forretningsbrukere kan opprette mindre, uavhengige modeller – eller de kan utvide semantiske kjernemodeller for BI med avdelingsbaserte eller eksterne kilder. SEMANTISKE BI-modeller fokuserer vanligvis på ett enkelt emneområde, og deles ofte mye.
Forretningsfunksjoner aktiveres ikke bare av data, men av semantiske BI-modeller som beskriver konsepter, relasjoner, regler og standarder. På denne måten representerer de intuitive og lettforstingede strukturer som definerer datarelasjoner og innkapsler forretningsregler som beregninger. De kan også fremtvinge finkornede datatillatelser, slik at de riktige personene har tilgang til de riktige dataene. Viktigere er at de akselererer spørringsytelsen, noe som gir svært responsiv interaktiv analyse – selv over terabyte med data. I likhet med virksomhetsmodeller tar BI-semantiske modeller i bruk navnekonvensjoner som sikrer konsistens.
I en skybasert BI-plattform kan BI-utviklere distribuere semantiske BI-modeller til Azure Analysis Services, Power BI Premium-kapasiteter for Microsoft Fabric-kapasiteter.
Viktig
Til tider refererer denne artikkelen til Power BI Premium eller dets kapasitetsabonnementer (P SKU-er). Vær oppmerksom på at Microsoft for øyeblikket konsoliderer kjøpsalternativer og trekker tilbake Power BI Premium per kapasitet sKU-er. Nye og eksisterende kunder bør vurdere å kjøpe Fabric-kapasitetsabonnementer (F SKU-er) i stedet.
Hvis du vil ha mer informasjon, kan du se Viktige oppdateringer som kommer til Power BI Premium-lisensiering og vanlige spørsmål om Power BI Premium.
Vi anbefaler at du distribuerer til Power BI når det brukes som rapporterings- og analyselag. Disse produktene støtter ulike lagringsmoduser, slik at datamodelltabeller kan bufre dataene eller bruke DirectQuery, som er en teknologi som sender spørringer til den underliggende datakilden. DirectQuery er en ideell lagringsmodus når modelltabeller representerer store datavolumer, eller det er behov for å levere nesten sanntidsresultater. De to lagringsmodusene kan kombineres: Sammensatte modeller kombinerer tabeller som bruker ulike lagringsmoduser i én enkelt modell.
For modeller med mye spørring kan Azure Load Balancer brukes til å fordele spørringsbelastningen jevnt på tvers av modellreplikaer. Den lar deg også skalere programmene dine og opprette svært tilgjengelige SEMANTISKE BI-modeller.
Maskinmodeller Læring
Maskin-Læring (ML)-modeller bygges og vedlikeholdes av dataforskere. De er for det meste utviklet fra rå kilder i datasjøen.
Opplærte ML-modeller kan vise mønstre i dataene dine. I mange tilfeller kan disse mønstrene brukes til å lage prognoser som kan brukes til å berike data. Kjøpsatferd kan for eksempel brukes til å forutsi kundefrafall eller segmentkunder. Prognoseresultater kan legges til virksomhetsmodeller for å tillate analyse etter kundesegment.
I en skybasert BI-plattform kan du bruke Azure Machine-Læring til å lære opp, distribuere, automatisere, administrere og spore ML-modeller.
Datalager
Når du sitter i hjertet av en BI-plattform, er datalageret, som er vert for bedriftsmodellene dine. Det er en kilde til sanksjonerte data , som et system av posten og som en hub - som betjener bedriftsmodeller for rapportering, BI og datavitenskap.
Mange forretningstjenester, inkludert bransjeprogrammer (LOB), kan stole på datalageret som en autoritativ og styrt kilde til bedriftskunnskap.
Hos Microsoft driftes datalageret vårt på Azure Data Lake Storage Gen2 (ADLS Gen2) og Azure Synapse Analytics.
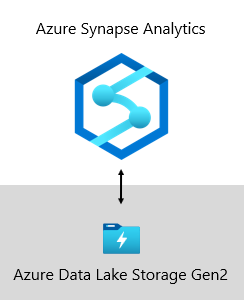
- ADLS Gen2 gjør Azure Storage til grunnlaget for bygging av bedriftsdatainnsjøer på Azure. Den er designet for å betjene flere petabyte med informasjon samtidig som den opprettholder hundrevis av gigabits av gjennomstrømming. Og det tilbyr rimelig lagringskapasitet og transaksjoner. Dessuten støtter den Hadoop-kompatibel tilgang, noe som gjør at du kan administrere og få tilgang til data akkurat som du ville gjort med et Hadoop Distributed File System (HDFS). Faktisk kan Azure HDInsight, Azure Databricks og Azure Synapse Analytics alle få tilgang til data som er lagret i ADLS Gen2. I en BI-plattform er det derfor et godt valg å lagre rå kildedata, halvbearbeidede eller trinnvise data og produksjonsklare data. Vi bruker den til å lagre alle forretningsdataene våre.
- Azure Synapse Analytics er en analysetjeneste som samler lager for virksomhetsdata og Big Data-analyse. Det gir deg friheten til å kjøre dataspørringer på dine vilkår ved å bruke enten serverløse eller klargjorte ressurser etter behov – i stor skala. Synapse SQL, en komponent i Azure Synapse Analytics, støtter fullstendig T-SQL-basert analyse, så det er ideelt å være vert for bedriftsmodeller bestående av dimensjons- og faktatabeller. Tabeller kan lastes effektivt inn fra ADLS Gen2 ved hjelp av enkle Polybase T-SQL-spørringer . Deretter har du kraften i MPP til å kjøre analyse med høy ytelse.
Rammeverk for forretningsreglermotor
Vi utviklet et BRE-rammeverk (Business Rules Engine ) for å katalogisere all forretningslogikk som kan implementeres i datalagerlaget. En BRE kan bety mange ting, men i sammenheng med et datalager er det nyttig for å opprette beregnede kolonner i relasjonstabeller. Disse beregnede kolonnene representeres vanligvis som matematiske beregninger eller uttrykk ved hjelp av betingede setninger.
Hensikten er å dele forretningslogikk fra kjerne-BI-kode. Tradisjonelt er forretningsregler hardkodet i SQL-lagrede prosedyrer, så det resulterer ofte i mye innsats for å opprettholde dem når forretningsbehovene endres. I en BRE defineres forretningsregler én gang og brukes flere ganger når de brukes på forskjellige datalagerenheter. Hvis beregningslogikken må endres, trenger den bare å oppdateres på ett sted og ikke i mange lagrede prosedyrer. Det er også en sidefordel: Et BRE-rammeverk gir gjennomsiktighet og synlighet i implementert forretningslogikk, som kan eksponeres via et sett med rapporter som oppretter selvoppdateringsdokumentasjon.
Datakilder
Et datalager kan konsolidere data fra praktisk talt alle datakilder. Det er for det meste bygget over LOB-datakilder, som vanligvis er relasjonsdatabaser som lagrer emnespesifikke data for salg, markedsføring, økonomi osv. Disse databasene kan være skybaserte, eller de kan ligge lokalt. Andre datakilder kan være filbaserte, spesielt nettlogger eller IOT-data hentet fra enheter. I tillegg kan data hentes fra Software-as-a-Service (SaaS)-leverandører.
Hos Microsoft sender noen av våre interne systemer driftsdata direkte til ADLS Gen2 ved hjelp av rå filformater. I tillegg til datasjøen består andre kildesystemer av relasjonelle LOB-programmer, Excel-arbeidsbøker, andre filbaserte kilder og Hoved dataadministrasjon (MDM) og egendefinerte datarepositorier. MDM-repositorier gjør det mulig for oss å administrere hoveddataene våre for å sikre autoritative, standardiserte og validerte versjoner av data.
Datainntak
På periodisk basis, og i henhold til virksomhetens rytmer, blir data inntatt fra kildesystemer og lastet inn i datalageret. Det kan være én gang om dagen eller med hyppigere intervaller. Datainntak er opptatt av å trekke ut, transformere og laste inn data. Eller kanskje omvendt: trekke ut, laste inn og deretter transformere data. Forskjellen kommer ned til hvor transformasjonen finner sted. Transformasjoner brukes til å rense, tilpasse, integrere og standardisere data. Hvis du vil ha mer informasjon, kan du se Trekke ut, transformere og laste inn (ETL).
Til syvende og sist er målet å laste inn de riktige dataene i bedriftsmodellen så raskt og effektivt som mulig.
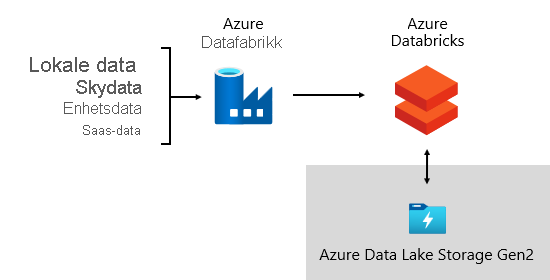
Hos Microsoft bruker vi Azure Data Factory (ADF). Tjenestene brukes til å planlegge og organisere datavalideringer, transformasjoner og massebelastninger fra eksterne kildesystemer til datasjøen vår. Den administreres av egendefinerte rammeverk for å behandle data parallelt og i stor skala. I tillegg utføres omfattende logging for å støtte feilsøking, ytelsesovervåking og for å utløse varslinger når bestemte betingelser oppfylles.
I mellomtiden utfører Azure Databricks – en Apache Spark-basert analyseplattform som er optimalisert for Azure Cloud Services-plattformen – transformasjoner spesielt for datavitenskap. Den bygger og kjører også ML-modeller ved hjelp av Python-notatblokker. Resultater fra disse ML-modellene lastes inn i datalageret for å integrere prognoser med virksomhetsprogrammer og rapporter. Fordi Azure Databricks får tilgang til datasjøfilene direkte, eliminerer eller minimerer det behovet for å kopiere eller hente data.
Inninntaksrammeverk
Vi utviklet et inntaksrammeverk som et sett med konfigurasjonstabeller og prosedyrer. Den støtter en datadrevet tilnærming til å anskaffe store mengder data i høy hastighet og med minimal kode. Kort sagt forenkler dette rammeverket prosessen med datainnsamling for å laste inn datalageret.
Rammeverket avhenger av konfigurasjonstabeller som lagrer datakilde- og datamålrelatert informasjon, for eksempel kildetype, server, database, skjema og tabellrelaterte detaljer. Denne utformingstilnærmingen betyr at vi ikke trenger å utvikle bestemte ADF-datasamlebånd eller SSIS-pakker (SQL Server Integration Services). I stedet skrives prosedyrer på språket vi velger for å opprette ADF-datasamlebånd som genereres dynamisk og kjøres på kjøretidspunktet. Datainnsamling blir derfor en konfigurasjonsøvelse som er lett å operasjonalisere. Tradisjonelt ville det kreve omfattende utviklingsressurser for å opprette hardkodede ADF- eller SSIS-pakker.
Inntaksrammeverket ble utformet for å forenkle prosessen med å håndtere oppstrøms kildeskjemaendringer også. Det er enkelt å oppdatere konfigurasjonsdata – manuelt eller automatisk, når skjemaendringer oppdages for å hente inn nylig tilføyde attributter i kildesystemet.
Orkestreringsrammeverk
Vi utviklet et orkestreringsrammeverk for å operasjonalisere og orkestrere datasamlebåndene våre. Den bruker en datadrevet utforming som avhenger av et sett med konfigurasjonstabeller. Disse tabellene lagrer metadata som beskriver datasamlebåndavhengigheter og hvordan du tilordner kildedata til måldatastrukturer. Investeringen i å utvikle dette adaptive rammeverket har siden betalt for seg selv; det er ikke lenger et krav om å hardkode hver databevegelse.
Lagring av data
En datainnsjø kan lagre store mengder rådata for senere bruk sammen med oppsamling av datatransformasjoner.
Hos Microsoft bruker vi ADLS Gen2 som vår eneste kilde til sannhet. Den lagrer rådata sammen med trinnvise data og produksjonsklare data. Den gir en svært skalerbar og kostnadseffektiv datainnsjøløsning for analyse av store data. Ved å kombinere kraften i et filsystem med høy ytelse med massiv skala, er det optimalisert for dataanalysearbeidsbelastninger, noe som akselererer tiden til innsikt.
ADLS Gen2 gir det beste fra to verdener: det er BLOB-lagring og et filsystem med høy ytelse, som vi konfigurerer med finkornede tilgangstillatelser.
Raffinerte data lagres deretter i en relasjonsdatabase for å levere et høytytende, svært skalerbart datalager for virksomhetsmodeller, med sikkerhet, styring og administrerbarhet. Emnespesifikke datamarts lagres i Azure Synapse Analytics, som lastes inn av Azure Databricks- eller Polybase T-SQL-spørringer.
Databruk
I rapporteringslaget bruker forretningstjenester virksomhetsdata hentet fra datalageret. De får også tilgang til data direkte i datasjøen for ad hoc-analyse eller datavitenskapsoppgaver.
Finkornede tillatelser håndheves på alle lag: i datasjøen, virksomhetsmodeller og BI-semantiske modeller. Tillatelsene sikrer at dataforbrukere bare kan se dataene de har tilgangsrettigheter til.
Hos Microsoft bruker vi Power BI-rapporter og -instrumentbord og sideformaterte Power BI-rapporter. Noen rapporterings- og ad hoc-analyser utføres i Excel – spesielt for økonomisk rapportering.
Vi publiserer dataordlister, som gir referanseinformasjon om datamodellene våre. De gjøres tilgjengelige for brukerne våre, slik at de kan oppdage informasjon om BI-plattformen vår. Ordlister utformer dokumentmodell, og gir beskrivelser om enheter, formater, struktur, dataavstamming, relasjoner og beregninger. Vi bruker Azure Data Catalog til å gjøre datakildene våre lett synlige og forståelige.
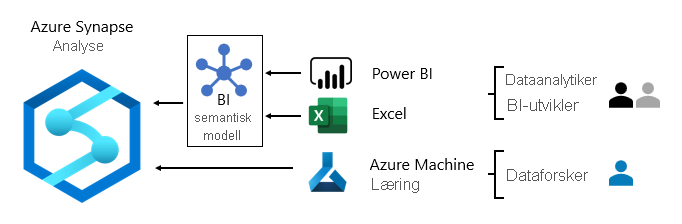
Vanligvis varierer mønstre for dataforbruk basert på rolle:
- Dataanalytikere kobler direkte til semantiske kjernemodeller for BI. Når semantiske kjernemodeller for BI inneholder alle data og logikk de trenger, bruker de live-tilkoblinger til å opprette Power BI-rapporter og instrumentbord. Når de trenger å utvide modellene med avdelingsdata, oppretter de sammensatte Power BI-modeller. Hvis det er behov for rapporter i regnearkstil, bruker de Excel til å produsere rapporter basert på semantiske kjernemodeller for BI eller semantiske modeller for avdelings-BI.
- BI-utviklere og driftsrapportforfattere kobler direkte til bedriftsmodeller. De bruker Power BI Desktop til å opprette analyserapporter for direkte tilkobling. De kan også redigere bi-rapporter av driftstype som Paginerte Power BI-rapporter, og skrive opprinnelige SQL-spørringer for å få tilgang til data fra Azure Synapse Analytics enterprise-modeller ved hjelp av T-SQL- eller Power BI-semantiske modeller ved hjelp av DAX eller MDX.
- Dataforskere kobler direkte til data i datasjøen. De bruker Azure Databricks og Python-notatblokker til å utvikle ML-modeller, som ofte er eksperimentelle og krever spesialferdigheter for produksjonsbruk.
Relatert innhold
Hvis du vil ha mer informasjon om denne artikkelen, kan du se følgende ressurser:
- Veikart for stoffadopsjon: Kompetansesenteret
- Enterprise BI i Azure med Azure Synapse Analytics
- Spørsmål? Prøv å spørre Power BI-fellesskap
- Forslag? Bidra med ideer for å forbedre Power BI
Profesjonelle tjenester
Sertifiserte Power BI-partnere er tilgjengelige for å hjelpe organisasjonen med å lykkes når du konfigurerer en coe. De kan gi deg kostnadseffektiv opplæring eller en revisjon av dataene dine. Hvis du vil engasjere en Power BI-partner, kan du gå til Partnerportalen for Power BI.
Du kan også engasjere deg med erfarne konsulentpartnere. De kan hjelpe deg med å vurdere, evaluere eller implementere Power BI.
Tilbakemeldinger
Kommer snart: Gjennom 2024 faser vi ut GitHub Issues som tilbakemeldingsmekanisme for innhold, og erstatter det med et nytt system for tilbakemeldinger. Hvis du vil ha mer informasjon, kan du se: https://aka.ms/ContentUserFeedback.
Send inn og vis tilbakemelding for