Veiledning for DirectQuery-modell i Power BI Desktop
Denne artikkelen retter seg mot datamodellerere som utvikler Power BI DirectQuery-modeller, utviklet ved hjelp av Enten Power BI Desktop eller Power Bi-tjeneste. Den beskriver brukstilfeller, begrensninger og veiledning for DirectQuery. Veiledningen er spesielt utformet for å hjelpe deg med å finne ut om DirectQuery er riktig modus for modellen, og for å forbedre ytelsen til rapportene basert på DirectQuery-modeller. Denne artikkelen gjelder for DirectQuery-modeller som driftes i Power Bi-tjeneste eller rapportserver for Power BI.
Denne artikkelen er ikke ment å gi en fullstendig diskusjon om DirectQuery-modellutforming. Hvis du vil ha en innføring, kan du se DirectQuery-modellene i Power BI Desktop-artikkelen . Hvis du vil ha en dypere diskusjon, kan du se DirectQuery i SQL Server 2016 Analysis Services-hvitboken . Husk at hvitboken beskriver bruk av DirectQuery i SQL Server Analysis Services. Mye av innholdet gjelder imidlertid fortsatt for Power BI DirectQuery-modeller.
Merk
Hvis du vil ha vurderinger når du bruker DirectQuery-lagringsmodus for datavers, kan du se Veiledning for Power BI-modellering for Power Platform.
Denne artikkelen dekker ikke sammensatte modeller direkte. En sammensatt modell består av minst én DirectQuery-kilde, og muligens mer. Veiledningen som er beskrevet i denne artikkelen, er fortsatt relevant – i hvert fall delvis – for sammensatt modellutforming. Konsekvensene av å kombinere importtabeller med DirectQuery-tabeller er imidlertid ikke i omfang for denne artikkelen. Hvis du vil ha mer informasjon, kan du se Bruke sammensatte modeller i Power BI Desktop.
Det er viktig å forstå at DirectQuery-modeller legger en annen arbeidsbelastning på Power BI-miljøet (Power Bi-tjeneste eller rapportserver for Power BI) og også på de underliggende datakildene. Hvis du finner ut at DirectQuery er riktig utformingstilnærming, anbefaler vi at du engasjerer de riktige personene på prosjektet. Vi ser ofte at en vellykket DirectQuery-modelldistribusjon er et resultat av at et team av IT-teknikere jobber tett sammen. Teamet består vanligvis av modellutviklere og kildedatabaseadministratorer. Det kan også involvere dataarkitekter og datalager- og ETL-utviklere. Optimaliseringer må ofte brukes direkte på datakilden for å oppnå gode ytelsesresultater.
Optimaliser datakildeytelse
Relasjonsdatabasekilden kan optimaliseres på flere måter, som beskrevet i følgende punktliste.
Merk
Vi forstår at ikke alle modellerere har tillatelser eller ferdigheter til å optimalisere en relasjonsdatabase. Selv om det er det foretrukne laget for å klargjøre dataene for en DirectQuery-modell, kan noen optimaliseringer også oppnås i modellutformingen, uten å endre kildedatabasen. De beste optimaliseringsresultatene oppnås imidlertid ofte ved å bruke optimaliseringer på kildedatabasen.
Sørg for at dataintegritet er fullført: Det er spesielt viktig at dimensjonstypetabeller inneholder en kolonne med unike verdier (dimensjonsnøkkel) som tilordnes faktatypetabellene. Det er også viktig at dimensjonskolonner av faktatype inneholder gyldige dimensjonsnøkkelverdier. De tillater konfigurering av mer effektive modellrelasjoner som forventer samsvarende verdier på begge sider av relasjoner. Når kildedataene mangler integritet, anbefales det at en «ukjent» dimensjonspost legges til for å reparere dataene effektivt. Du kan for eksempel legge til en rad i produkttabellen for å representere et ukjent produkt, og deretter tilordne den en utenfor rekkeviddenøkkel, for eksempel -1. Hvis rader i Salg-tabellen inneholder en manglende produktnøkkelverdi, kan du erstatte dem med -1. Den sikrer at hver produktnøkkelverdi for salg har en tilsvarende rad i produkttabellen.
Legg til indekser: Definer aktuelle indekser – i tabeller eller visninger – for å støtte effektiv henting av data for forventet filtrering og gruppering av rapportvisualobjekter. For SQL Server-, Azure SQL Database- eller Azure Synapse Analytics-kilder (tidligere SQL Data Warehouse) kan du se SQL Server Index Architecture and Design Guide for nyttig informasjon om veiledning for indeksutforming. For flyktige sql server- eller Azure SQL Database-kilder kan du se Komme i gang med Columnstore for driftsanalyse i sanntid.
Utform distribuerte tabeller: For Azure Synapse Analytics -kilder (tidligere SQL Data Warehouse), som bruker massivt parallellbehandlingsarkitektur (MPP), bør du vurdere å konfigurere store faktatypetabeller som hash-distribuerte tabeller og dimensjonstypetabeller til å replikere på tvers av alle databehandlingsnodene. Hvis du vil ha mer informasjon, kan du se Veiledning for utforming av distribuerte tabeller i Azure Synapse Analytics (tidligere SQL Data Warehouse).
Kontroller at nødvendige datatransformasjoner materialiseres: For SQL Server-relasjonsdatabasekilder (og andre relasjonsdatabasekilder) kan beregnede kolonner legges til i tabeller. Disse kolonnene er basert på et uttrykk, for eksempel Antall multiplisert med Enhetspris. Beregnede kolonner kan beholdes (materialiseres), og noen ganger kan de indekseres, for eksempel vanlige kolonner. Hvis du vil ha mer informasjon, kan du se Indekser på beregnede kolonner.
Vurder også indekserte visninger som kan forhåndssamlede faktatabelldata på et høyere nivå. Hvis salg-tabellen for eksempel lagrer data på ordrelinjenivå, kan du opprette en visning for å oppsummere disse dataene. Visningen kan være basert på en SELECT-setning som grupperer salgstabelldataene etter dato (på månedsnivå), kunde, produkt og summerer målverdier som salg, antall osv. Visningen kan deretter indekseres. Hvis du vil ha SQL Server- eller Azure SQL Database-kilder, kan du se Opprette indekserte visninger.
Materialiser en datotabell: Et vanlig modelleringskrav innebærer å legge til en datotabell for å støtte tidsbasert filtrering. Hvis du vil støtte de kjente tidsbaserte filtrene i organisasjonen, oppretter du en tabell i kildedatabasen og sikrer at den lastes inn med et område med datoer som omfatter faktatabelldatoene. Sørg også for at den inneholder kolonner for nyttige tidsperioder, for eksempel år, kvartal, måned, uke osv.
Optimaliser modellutforming
En DirectQuery-modell kan optimaliseres på mange måter, som beskrevet i følgende punktliste.
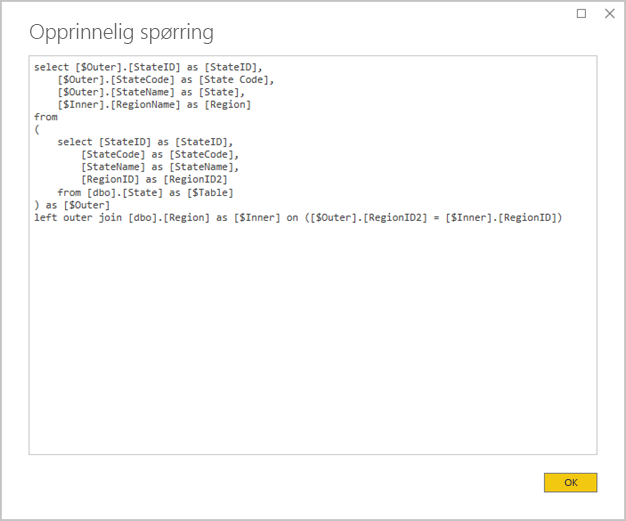
Unngå komplekse Power Query-spørringer: En effektiv modellutforming kan oppnås ved å fjerne behovet for power query-spørringer for å bruke eventuelle transformasjoner. Det betyr at hver spørring tilordnes én enkelt relasjonsdatabasekildetabell eller -visning. Du kan forhåndsvise en representasjon av den faktiske SQL-spørringssetningen for et power query-trinn ved å velge alternativet Vis opprinnelig spørring .
Undersøk bruken av beregnede kolonner og datatypeendringer: DirectQuery-modeller støtter å legge til beregninger og Power Query-trinn for å konvertere datatyper. Bedre ytelse oppnås imidlertid ofte ved å materialisere transformasjonsresultater i den relasjonelle databasekilden, når det er mulig.
Ikke bruk relativ datofiltrering for Power Query: Det er mulig å definere relativ datofiltrering i en Power Query-spørring. Hvis du for eksempel vil hente til salgsordrene som ble opprettet i det siste året (i forhold til dagens dato). Denne typen filter oversettes til en ineffektiv opprinnelig spørring, som følger:
… from [dbo].[Sales] as [_] where [_].[OrderDate] >= convert(datetime2, '2018-01-01 00:00:00') and [_].[OrderDate] < convert(datetime2, '2019-01-01 00:00:00'))En bedre utformingstilnærming er å inkludere relative tidskolonner i datotabellen. Disse kolonnene lagrer forskyvningsverdier i forhold til gjeldende dato. I en RelativeYear-kolonne representerer for eksempel verdien null gjeldende år, -1 representerer forrige år osv. Fortrinnsvis materialiseres RelativeYear-kolonnen i datotabellen. Selv om den er mindre effektiv, kan den også legges til som en modellberegnet kolonne, basert på uttrykket ved hjelp av DAX-funksjonene TODAY og DATE .
Hold målene enkle: I det minste i utgangspunktet anbefales det å begrense mål til enkle aggregater. Mengdefunksjonene inkluderer SUMMER, ANTALL, MIN, MAKS og GJENNOMSNITT. Hvis målene er tilstrekkelig responsive, kan du eksperimentere med mer komplekse mål, men ta hensyn til ytelsen for hver av dem. Selv om CALCULATE DAX-funksjonen kan brukes til å produsere avanserte måluttrykk som manipulerer filterkonteksten, kan de generere dyre opprinnelige spørringer som ikke fungerer bra.
Unngå relasjoner på beregnede kolonner: Modellrelasjoner kan bare relatere én enkelt kolonne i én tabell til én enkelt kolonne i en annen tabell. Noen ganger er det imidlertid nødvendig å relatere tabeller ved hjelp av flere kolonner. Tabellene Salg og Geografi er for eksempel relatert til to kolonner: LandRegion og By. Hvis du vil opprette en relasjon mellom tabellene, kreves det én kolonne, og kolonnen må inneholde unike verdier i Geografi-tabellen . Sammenkobling av land/område og by med bindestrekskilletegn kan oppnå dette resultatet.
Den kombinerte kolonnen kan opprettes med enten en egendefinert Power Query-kolonne eller i modellen som en beregnet kolonne. Det bør imidlertid unngås ettersom beregningsuttrykket bygges inn i kildespørringene. Ikke bare er det ineffektivt, det hindrer vanligvis bruk av indekser. Legg i stedet til materialiserte kolonner i relasjonsdatabasekilden, og vurder å indeksere dem. Du kan også vurdere å legge til surrogatnøkkelkolonner i dimensjonstypetabeller, som er en vanlig praksis i relasjonelle datalagerutforminger.
Det finnes ett unntak fra denne veiledningen, og det gjelder bruken av COMBINEVALUES DAX-funksjonen. Formålet med denne funksjonen er å støtte modellrelasjoner med flere kolonner. I stedet for å generere et uttrykk som relasjonen bruker, genererer den et sql-sammenføyningspredikat med flere kolonner.
Unngå relasjoner i «Unik identifikator»-kolonner: Power BI støtter ikke den unike identifikatoren (GUID)-datatypen. Når du definerer en relasjon mellom kolonner av denne typen, genererer Power BI en kildespørring med en sammenføyning som involverer en avstøpning. Denne datakonverteringen for spørringstid resulterer vanligvis i dårlig ytelse. Inntil dette tilfellet er optimalisert, er den eneste midlertidige løsningen å materialisere kolonner av en alternativ datatype i den underliggende databasen.
Skjul kolonnen på én side med relasjoner: Kolonnen på én side i en relasjon bør være skjult. (Det er vanligvis primærnøkkelkolonnen i dimensjonstypetabeller.) Når den er skjult, er den ikke tilgjengelig i Felter-ruten , og kan derfor ikke brukes til å konfigurere et visualobjekt. Kolonnen på mange sider kan forbli synlig hvis det er nyttig å gruppere eller filtrere rapporter etter kolonneverdiene. Vurder for eksempel en modell der det finnes en relasjon mellom salgs- og produkttabeller . Relasjonskolonnene inneholder produkt-SKU-verdier (lagerføringsenhet). Hvis produkt-SKU må legges til visualobjekter, bør det bare være synlig i Salg-tabellen . Når denne kolonnen brukes til å filtrere eller gruppere i et visualobjekt, genererer Power BI en spørring som ikke trenger å bli med i tabellene Salg og Produkt .
Angi relasjoner for å fremtvinge integritet:Egenskapen Anta referanseintegritet for DirectQuery-relasjoner bestemmer om Power BI genererer kildespørringer ved hjelp av en indre sammenføyning i stedet for en ytre sammenføyning. Det forbedrer vanligvis spørringsytelsen, selv om den avhenger av detaljene i den relasjonelle databasekilden. Hvis du vil ha mer informasjon, kan du se Anta innstillinger for referanseintegritet i Power BI Desktop.
Unngå bruk av toveis relasjonsfiltrering: Bruk av toveis relasjonsfiltrering kan føre til spørringssetninger som ikke fungerer bra. Bruk bare denne relasjonsfunksjonen når det er nødvendig, og det er vanligvis tilfelle når du implementerer en mange-til-mange-relasjon på tvers av en brotabell. Hvis du vil ha mer informasjon, kan du se Relasjoner med mange-mange-kardinalitet i Power BI Desktop.
Begrens parallelle spørringer: Du kan angi maksimalt antall tilkoblinger DirectQuery åpner for hver underliggende datakilde. Den kontrollerer antall spørringer som sendes samtidig til datakilden.
- Innstillingen er bare aktivert når det er minst én DirectQuery-kilde i modellen. Verdien gjelder for alle DirectQuery-kilder, og for eventuelle nye DirectQuery-kilder som er lagt til i modellen.
- Hvis du øker maksimum Koble til ioner per datakildeverdi, sikrer du at flere spørringer (opptil det maksimale antallet som er angitt) kan sendes til den underliggende datakilden, noe som er nyttig når mange visualobjekter er på én enkelt side, eller mange brukere får tilgang til en rapport samtidig. Når maksimalt antall tilkoblinger er nådd, legges ytterligere spørringer i kø til en tilkobling blir tilgjengelig. Hvis du øker denne grensen, blir det mer belastning på den underliggende datakilden, så innstillingen er ikke garantert å forbedre den generelle ytelsen.
- Når modellen publiseres til Power BI, avhenger også det maksimale antallet samtidige spørringer som sendes til den underliggende datakilden, av miljøet. Ulike miljøer (for eksempel Power BI, Power BI Premium eller rapportserver for Power BI) kan legge til forskjellige begrensninger for gjennomstrømming. Hvis du vil ha mer informasjon om kapasitetsressursbegrensninger, kan du se Microsoft Fabric-kapasitetslisenser og konfigurere og administrere kapasiteter i Power BI Premium.
Viktig
Til tider refererer denne artikkelen til Power BI Premium eller dets kapasitetsabonnementer (P SKU-er). Vær oppmerksom på at Microsoft for øyeblikket konsoliderer kjøpsalternativer og trekker tilbake Power BI Premium per kapasitet sKU-er. Nye og eksisterende kunder bør vurdere å kjøpe Fabric-kapasitetsabonnementer (F SKU-er) i stedet.
Hvis du vil ha mer informasjon, kan du se Viktige oppdateringer som kommer til Power BI Premium-lisensiering og vanlige spørsmål om Power BI Premium.
Optimaliser rapportutforminger
Rapporter basert på en Semantisk DirectQuery-modell (tidligere kalt et datasett) kan optimaliseres på mange måter, som beskrevet i følgende punktliste.
- Aktiver teknikker for spørringsreduksjon: Alternativer for Power BI Desktop og Innstillinger inkluderer en side for spørringsreduksjon. Denne siden har tre nyttige alternativer. Det er mulig å deaktivere kryssutheving og kryssfiltrering som standard, selv om det kan overstyres ved å redigere samhandlinger. Det er også mulig å vise en Bruk-knapp på slicere og filtre. Alternativene for slicer eller filter brukes ikke før rapportbrukeren klikker knappen. Hvis du aktiverer disse alternativene, anbefaler vi at du gjør det første gang du oppretter rapporten.
- Bruk filtre først: Når du først utformer rapporter, anbefaler vi at du bruker eventuelle gjeldende filtre – på rapport-, side- eller visuelt nivå – før du tilordner felt til de visuelle feltene. I stedet for å dra i landregionen og salgsmålene, og deretter filtrere etter et bestemt år, bruker du filteret på År-feltet først. Det er fordi hvert trinn i å bygge et visualobjekt sender en spørring, og selv om det er mulig å gjøre en ny endring før den første spørringen er fullført, legger den fortsatt unødvendig belastning på den underliggende datakilden. Ved å bruke filtre tidlig, gjør det vanligvis disse mellomliggende spørringene mindre kostbare og raskere. Hvis du ikke bruker filtre tidlig, kan det føre til at grensen på 1 million rader overskrides, som beskrevet i DirectQuery.
- Begrens antall visualobjekter på en side: Når en rapportside åpnes (og når sidefiltre brukes) oppdateres alle visualobjektene på en side. Det er imidlertid en grense for antall spørringer som kan sendes parallelt, pålagt av Power BI-miljøet og innstillingen Maksimalt Koble til ioner per datakildemodell, som beskrevet ovenfor. Etter hvert som antallet visualobjekter på siden øker, er det større sjanse for at de oppdateres på en seriell måte. Det øker tiden det tar å oppdatere hele siden, og det øker også sjansen for at visualobjekter kan vise inkonsekvente resultater (for flyktige datakilder). Av disse grunnene anbefales det å begrense antall visualobjekter på en side, og i stedet ha mer enklere sider. Hvis du erstatter flere kortvisualobjekter med ett enkelt kort med flere rader, kan det oppnå et lignende sideoppsett.
- Slå av samhandling mellom visualobjekter: Kryssutheving og kryssfiltreringssamhandlinger krever at spørringer sendes til den underliggende kilden. Med mindre disse samhandlingene er nødvendige, anbefales det at de slås av hvis tiden det tar å svare på brukernes valg, vil være urimelig lang. Disse samhandlingene kan slås av, enten for hele rapporten (som beskrevet ovenfor for alternativer for spørringsreduksjon) eller fra sak til sak. Hvis du vil ha mer informasjon, kan du se Hvordan visualobjekter kryssfiltrerer hverandre i en Power BI-rapport.
I tillegg til listen over optimaliseringsteknikker ovenfor, kan hver av følgende rapporteringsfunksjoner bidra til ytelsesproblemer:
Målfiltre: Visualobjekter som inneholder mål (eller aggregater av kolonner) kan ha filtre brukt på disse målene. Visualobjektet nedenfor viser for eksempel Salg etter kategori, men bare for kategorier med mer enn USD 15 millioner av salg.
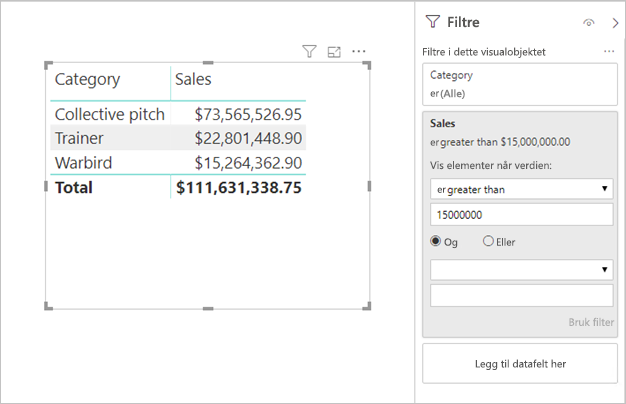
Det kan føre til at to spørringer sendes til den underliggende kilden:
- Den første spørringen henter kategoriene som oppfyller betingelsen (Salg > USD 15 millioner)
- Den andre spørringen henter deretter de nødvendige dataene for visualobjektet, og legger til kategoriene som oppfylte betingelsen i WHERE-setningsdelen
Det fungerer vanligvis fint hvis det finnes hundrevis eller tusenvis av kategorier, som i dette eksemplet. Ytelsen kan imidlertid reduseres hvis antall kategorier er mye større (og faktisk vil spørringen mislykkes hvis det er mer enn 1 million kategorier som oppfyller betingelsen, på grunn av grensen på 1 million rader som er beskrevet ovenfor).
TopN-filtre: Avanserte filtre kan defineres til å filtrere etter bare de øverste (eller nederste) N-verdiene rangert etter et mål. Hvis du for eksempel bare vil vise de fem øverste kategoriene i visualobjektet ovenfor. I likhet med målfiltrene vil det også føre til at to spørringer sendes til den underliggende datakilden. Den første spørringen vil imidlertid returnere alle kategorier fra den underliggende kilden, og deretter bestemmes topp N basert på de returnerte resultatene. Avhengig av kardinaliteten til kolonnen som er involvert, kan det føre til ytelsesproblemer (eller spørringsfeil på grunn av grensen på 1 million rader).
Median: Generelt blir alle aggregasjoner (sum, antall distinkte osv.) overført til den underliggende kilden. Det er imidlertid ikke sant for Median, da dette aggregerte ikke støttes av den underliggende kilden. I slike tilfeller hentes detaljdata fra den underliggende kilden, og Power BI evaluerer medianen fra de returnerte resultatene. Det er greit når medianen skal beregnes over et relativt lite antall resultater, men ytelsesproblemer (eller spørringsfeil på grunn av grensen på 1 million rader) vil oppstå hvis kardinaliteten er stor. Medianland/områdepopulasjon kan for eksempel være rimelig, men median salgspris er kanskje ikke det.
Flervalgsslicere: Hvis du tillater flervalg i slicere og filtre, kan det føre til ytelsesproblemer. Det er fordi når brukeren velger flere slicerelementer (for eksempel å bygge opp til de 10 produktene de er interessert i), resulterer hvert nytt utvalg i en ny spørring som sendes til den underliggende kilden. Selv om brukeren kan velge det neste elementet før spørringen fullføres, resulterer det i ekstra belastning på den underliggende kilden. Denne situasjonen kan unngås ved å vise Bruk-knappen, som beskrevet ovenfor i teknikkene for spørringsreduksjon.
Visuelle totaler: Tabeller og matriser viser totalsummer og delsummer som standard. I mange tilfeller må flere spørringer sendes til den underliggende kilden for å hente verdiene for totalsummene. Den gjelder når du bruker antall distinkte eller medianaggregater, og i alle tilfeller når du bruker DirectQuery over SAP HANA eller SAP Business Warehouse. Slike totalsummer bør slås av (ved hjelp av Format-ruten) om ikke nødvendig.
Konverter til en sammensatt modell
Fordelene med import- og DirectQuery-modeller kan kombineres til én enkelt modell ved å konfigurere lagringsmodusen for modelltabellene. Tabelllagringsmodusen kan være Import eller DirectQuery, eller begge deler, kjent som Dobbel. Når en modell inneholder tabeller med ulike lagringsmoduser, kalles den en sammensatt modell. Hvis du vil ha mer informasjon, kan du se Bruke sammensatte modeller i Power BI Desktop.
Det finnes mange funksjonelle forbedringer og ytelsesforbedringer som kan oppnås ved å konvertere en DirectQuery-modell til en sammensatt modell. En sammensatt modell kan integrere mer enn én DirectQuery-kilde, og den kan også inneholde aggregasjoner. Aggregasjonstabeller kan legges til i DirectQuery-tabeller for å importere en oppsummert representasjon av tabellen. De kan oppnå dramatiske ytelsesforbedringer når visualobjekter spør etter aggregater på høyere nivå. Hvis du vil ha mer informasjon, kan du se Aggregasjoner i Power BI Desktop.
Utdanne brukere
Det er viktig å lære brukerne hvordan de effektivt kan arbeide med rapporter basert på Semantiske DirectQuery-modeller. Rapportforfatterne bør være utdannet på innholdet som er beskrevet i delen Optimaliser rapportutforming .
Vi anbefaler at du informerer rapportforbrukerne om rapportene dine som er basert på Semantiske DirectQuery-modeller. Det kan være nyttig for dem å forstå den generelle dataarkitekturen, inkludert eventuelle relevante begrensninger som er beskrevet i denne artikkelen. La dem få vite at oppdateringssvar og interaktiv filtrering til tider kan gå tregt. Når rapportbrukere forstår hvorfor ytelsesreduksjon skjer, er det mindre sannsynlig at de mister tilliten til rapportene og dataene.
Når du leverer rapporter om flyktige datakilder, må du informere rapportbrukere om bruken av Oppdater-knappen. La dem også få vite at det kan være mulig å se inkonsekvente resultater, og at en oppdatering av rapporten kan løse eventuelle inkonsekvenser på rapportsiden.
Relatert innhold
Hvis du vil ha mer informasjon om DirectQuery, kan du se følgende ressurser:
Tilbakemeldinger
Kommer snart: Gjennom 2024 faser vi ut GitHub Issues som tilbakemeldingsmekanisme for innhold, og erstatter det med et nytt system for tilbakemeldinger. Hvis du vil ha mer informasjon, kan du se: https://aka.ms/ContentUserFeedback.
Send inn og vis tilbakemelding for