Dit artikel bevat een overzicht van de Azure-databaseoplossingen die worden beschreven in Azure Architecture Center.
Apache, Apache® Cassandra® en het Hadoop-logo zijn geregistreerde handelsmerken of handelsmerken van de Apache Software Foundation in de Verenigde Staten en/of andere landen. Er wordt geen goedkeuring door De Apache Software Foundation geïmpliceerd door het gebruik van deze markeringen.
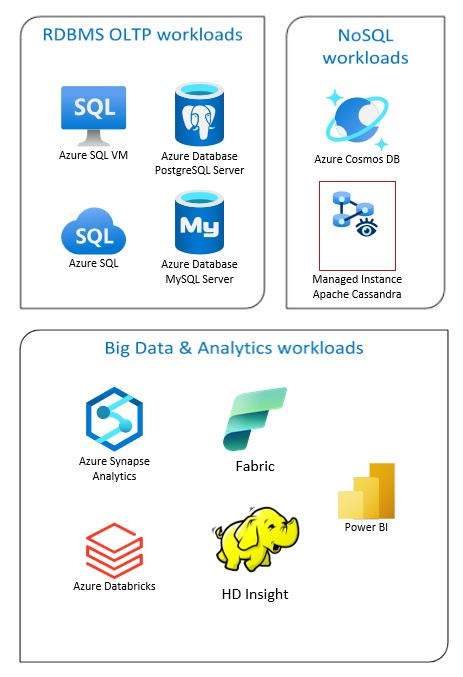
Azure Database-oplossingen omvatten traditionele relationele databasebeheersystemen (RDBMS en OLTP), big data- en analyseworkloads (inclusief OLAP) en NoSQL-workloads.
RDBMS-workloads omvatten online transaction processing (OLTP) en online analytical processing (OLAP). Gegevens uit meerdere bronnen in de organisatie kunnen worden samengevoegd in een datawarehouse. U kunt een ETL-proces (extraheren, transformeren en laden) of ELT-proces (EXTRAHEREN, laden en transformeren) gebruiken om de brongegevens te verplaatsen en transformeren. Zie Relationele databases verkennen in Azure voor meer informatie over RDBMS-databases.
Een big data-architectuur is ontworpen om de opname, verwerking en analyse van grote of complexe gegevens af te handelen. Big data-oplossingen omvatten doorgaans een grote hoeveelheid relationele en niet-relationele gegevens, die niet geschikt zijn voor het opslaan van traditionele RDBMS-systemen. Deze omvatten doorgaans oplossingen zoals Data Lakes, Delta Lakes en lakehouses. Zie meer informatie in Het ontwerp van analysearchitectuur.
NoSQL-databases worden door elkaar aangeduid als niet-relationele, NoSQL-DB's of niet-SQL om te benadrukken dat ze grote hoeveelheden snel veranderende, ongestructureerde gegevens kunnen verwerken. Ze slaan geen gegevens op in tabellen, rijen en kolommen, zoals (SQL)-databases. Zie NoSQL-gegevens en wat zijn NoSQL-databases? voor meer informatie over geen SQL DB-databases.
Dit artikel bevat resources voor meer informatie over Azure-databases. Hierin worden paden beschreven voor het implementeren van de architecturen die voldoen aan uw behoeften en aanbevolen procedures om rekening mee te houden bij het ontwerpen van uw oplossingen.
Er zijn veel architecturen die u kunt tekenen om te voldoen aan de behoeften van uw database. We bieden ook oplossingsideeën waarmee u verder kunt bouwen, inclusief koppelingen naar alle onderdelen die u nodig hebt.
Meer informatie over databases in Azure
Wanneer u aan de slag gaat met mogelijke architecturen voor uw oplossing, is het essentieel dat u het juiste gegevensarchief kiest. Als u geen kennis hebt met databases in Azure, is Microsoft Learn de beste plek om te beginnen. Dit gratis online platform biedt video's en zelfstudies voor praktische training. Microsoft Learn biedt leertrajecten die zijn gebaseerd op uw functie, zoals ontwikkelaar of gegevensanalist.
U kunt beginnen met een algemene beschrijving van de verschillende databases in Azure en het gebruik ervan. U kunt ook door Azure-gegevensmodules bladeren en een benadering voor gegevensopslag kiezen in Azure. Deze artikelen helpen u inzicht te krijgen in uw keuzes in Azure-gegevensoplossingen en te leren waarom sommige oplossingen worden aanbevolen in specifieke scenario's.
Hier volgen enkele Learn-modules die nuttig kunnen zijn:
- Uw migratie naar Azure ontwerpen
- Azure SQL Database implementeren
- Azure-database- en analyseservices verkennen
- Azure SQL Database beveiligen
- Azure Cosmos DB
- Azure Database for PostgreSQL
- Azure Database for MySQL
- SQL Server op Azure-VM's
Pad naar productie
Als u opties wilt vinden die nuttig zijn voor het omgaan met relationele gegevens, kunt u deze resources overwegen:
- Zie Analytics in Azure voor meer informatie over resources voor het verzamelen van gegevens uit meerdere bronnen en het toepassen van gegevenstransformaties binnen de gegevenspijplijnen.
- Zie Online analytical processing voor meer informatie over OLAP, waarin grote zakelijke databases worden ingedeeld en complexe analyses worden ondersteund.
- Zie Online transactieverwerking voor meer informatie over OLTP-systemen voor het vastleggen van zakelijke interacties.
Een niet-relationele database maakt geen gebruik van het tabellaire schema van rijen en kolommen. Zie Niet-relationele gegevens en NoSQL voor meer informatie.
Zie Data Lakes voor meer informatie over data lakes, die een grote hoeveelheid gegevens bevatten in de oorspronkelijke, onbewerkte indeling.
Een big data-architectuur kan gegevensopname, verwerking en analyse verwerken en analyseren die te groot of te complex is voor traditionele databasesystemen. Zie Big data-architecturen en Analytics voor meer informatie.
Een hybride cloud is een IT-omgeving waarin openbare cloud- en on-premises datacenters worden gecombineerd. Zie On-premises gegevensoplossingen uitbreiden naar de cloud of Azure Arc in combinatie met Azure-databases overwegen voor meer informatie.
Azure Cosmos DB is een volledig beheerde NoSQL-databaseservice voor de ontwikkeling van moderne apps. Zie het Azure Cosmos DB-resourcemodel voor meer informatie.
Aanbevolen procedures
Bekijk deze aanbevolen procedures bij het ontwerpen van uw oplossingen.
| Aanbevolen procedures | Beschrijving |
|---|---|
| Patronen voor gegevensbeheer | Gegevensbeheer is het belangrijkste element van cloudtoepassingen. Het beïnvloedt de meeste kwaliteitskenmerken. |
| Patroon Transactionele Postvak UIT met Azure Cosmos DB | Meer informatie over het gebruik van het transactionele postvak UIT-patroon voor betrouwbare berichten en gegarandeerde levering van gebeurtenissen. |
| Gegevens wereldwijd distribueren met Azure Cosmos DB | Om lage latentie en hoge beschikbaarheid te bereiken, moeten sommige toepassingen worden geïmplementeerd in datacenters die zich dicht bij hun gebruikers bevinden. |
| Beveiliging in Azure Cosmos DB | Aanbevolen beveiligingsprocedures helpen databaseschendingen te voorkomen, te detecteren en erop te reageren. |
| Continue back-up met herstel naar een bepaald tijdstip in Azure Cosmos DB | Meer informatie over de functie voor herstel naar een bepaald tijdstip van Azure Cosmos DB. |
| Hoge beschikbaarheid bereiken met Azure Cosmos DB | Azure Cosmos DB biedt meerdere functies en configuratieopties voor hoge beschikbaarheid. |
| Hoge beschikbaarheid voor Azure SQL Database en SQL Managed Instance | De database mag geen single point of failure in uw architectuur zijn. |
Technologieopties
Er zijn veel opties voor technologieën die u kunt gebruiken met Azure Databases. Deze artikelen helpen u bij het kiezen van de beste technologieën voor uw behoeften.
- Een gegevensarchief kiezen
- Een analytische gegevensopslag kiezen in Azure
- Een technologie voor gegevensanalyse kiezen in Azure
- Een batchverwerkingstechnologie kiezen in Azure
- Een big data-opslagtechnologie kiezen in Azure
- Een indelingstechnologie voor gegevenspijplijnen kiezen in Azure
- Een zoekgegevensarchief kiezen in Azure
- Een technologie voor stroomverwerking kiezen in Azure
Blijf op de hoogte met databases
Raadpleeg Azure-updates om up-to-date te blijven met Azure Databases-technologie.
Verwante resources
- Adatum Corporation-scenario voor gegevensbeheer en -analyse in Azure
- Lamna Healthcare-scenario voor gegevensbeheer en analyses in Azure
- Beheer van SQL Server-exemplaren optimaliseren
- Scenario voor relecloud voor gegevensbeheer en analyses in Azure
Voorbeeldoplossingen
Deze oplossingsideeën zijn enkele van de voorbeeldmethoden die u kunt aanpassen aan uw behoeften.
Vergelijkbare databaseproducten
Als u bekend bent met Amazon Web Services (AWS) of Google Cloud, raadpleegt u de volgende vergelijkingen: