Rozproszone buforowanie (tworzenie aplikacji w chmurze Real-World za pomocą platformy Azure)
Autor : Rick Anderson, Tom Dykstra
Pobierz naprawę projektu lub pobierz książkę elektroniczną
Książka elektroniczna Building Real World Cloud Apps with Azure (Tworzenie rzeczywistych aplikacji w chmurze za pomocą platformy Azure ) jest oparta na prezentacji opracowanej przez Scotta Guthrie. Wyjaśniono w nim 13 wzorców i rozwiązań, które mogą pomóc w pomyślnym tworzeniu aplikacji internetowych dla chmury. Aby uzyskać informacje na temat książki e-book, zobacz pierwszy rozdział.
W poprzednim rozdziale opatrzono obsługę błędów przejściowych i wspomniano o buforowaniu jako strategii wyłącznika. Ten rozdział zawiera więcej informacji o buforowaniu, w tym o tym, kiedy należy z niego korzystać, o typowych wzorcach dotyczących korzystania z niego i o sposobie implementowania go na platformie Azure.
Co to jest rozproszone buforowanie
Pamięć podręczna zapewnia dostęp o wysokiej przepływności i małych opóźnieniach do często używanych danych aplikacji przez przechowywanie danych w pamięci. W przypadku aplikacji w chmurze najbardziej przydatnym typem pamięci podręcznej jest rozproszona pamięć podręczna, co oznacza, że dane nie są przechowywane w pamięci pojedynczego serwera internetowego, ale w innych zasobach w chmurze, a buforowane dane są udostępniane wszystkim serwerom internetowym aplikacji (lub innym maszynom wirtualnym w chmurze używanym przez aplikację).
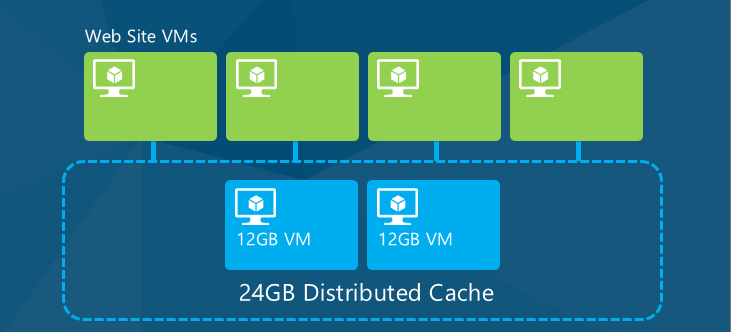
Gdy aplikacja jest skalowana przez dodanie lub usunięcie serwerów albo gdy serwery zostaną zastąpione z powodu uaktualnień lub błędów, buforowane dane pozostają dostępne dla każdego serwera, na który jest uruchomiona aplikacja.
Dzięki unikaniu dostępu do danych o dużym opóźnieniu trwałego magazynu danych buforowanie może znacznie poprawić czas odpowiedzi aplikacji. Na przykład pobieranie danych z pamięci podręcznej jest znacznie szybsze niż pobieranie ich z relacyjnej bazy danych.
Zaletą buforowania jest zmniejszenie ruchu do trwałego magazynu danych, co może spowodować obniżenie kosztów w przypadku naliczania opłat za ruch wychodzący danych dla trwałego magazynu danych.
Kiedy należy używać rozproszonego buforowania
Buforowanie działa najlepiej w przypadku obciążeń aplikacji, które odczytują więcej niż zapisu danych, a model danych obsługuje organizację klucz/wartość używaną do przechowywania i pobierania danych w pamięci podręcznej. Jest to również bardziej przydatne, gdy użytkownicy aplikacji udostępniają wiele typowych danych; Na przykład pamięć podręczna nie zapewnia tak wielu korzyści, jeśli każdy użytkownik zazwyczaj pobiera dane unikatowe dla tego użytkownika. Przykładem, w którym buforowanie może być bardzo korzystne, jest katalog produktów, ponieważ dane nie zmieniają się często, a wszyscy klienci patrzą na te same dane.
Korzyść buforowania staje się coraz bardziej wymierna, tym większa skala aplikacji, ponieważ limity przepływności i opóźnienia trwałego magazynu danych stają się bardziej ograniczeniem ogólnej wydajności aplikacji. Można jednak zaimplementować buforowanie z innych powodów niż również wydajność. W przypadku danych, które nie muszą być całkowicie aktualne, gdy są wyświetlane użytkownikowi, dostęp do pamięci podręcznej może służyć jako wyłącznik, gdy trwały magazyn danych nie odpowiada lub jest niedostępny.
Popularne strategie populacji pamięci podręcznej
Aby móc pobierać dane z pamięci podręcznej, musisz najpierw je przechowywać. Istnieje kilka strategii pobierania potrzebnych danych w pamięci podręcznej:
Na żądanie/odkładanie do pamięci podręcznej
Aplikacja próbuje pobrać dane z pamięci podręcznej, a gdy pamięć podręczna nie zawiera danych ("miss"), aplikacja przechowuje dane w pamięci podręcznej, aby była dostępna po następnym uruchomieniu. Następnym razem, gdy aplikacja spróbuje pobrać te same dane, znajdzie to, czego szuka w pamięci podręcznej (trafienie). Aby zapobiec pobieraniu buforowanych danych, które uległy zmianie w bazie danych, należy unieważnić pamięć podręczną podczas wprowadzania zmian w magazynie danych.
Wypychanie danych w tle
Usługi w tle wypychają dane do pamięci podręcznej zgodnie z regularnym harmonogramem, a aplikacja zawsze ściąga z pamięci podręcznej. Takie podejście doskonale sprawdza się w przypadku źródeł danych o dużym opóźnieniu, które nie wymagają zawsze zwracania najnowszych danych.
Wyłącznik
Aplikacja zwykle komunikuje się bezpośrednio z trwałym magazynem danych, ale gdy trwały magazyn danych ma problemy z dostępnością, aplikacja pobiera dane z pamięci podręcznej. Dane mogły zostać umieszczone w pamięci podręcznej przy użyciu strategii wypychania danych w tle lub z odkładania do pamięci podręcznej. Jest to strategia obsługi błędów, a nie strategia zwiększająca wydajność.
Aby zachować bieżące dane w pamięci podręcznej, można usuwać powiązane wpisy pamięci podręcznej, gdy aplikacja tworzy, aktualizuje lub usuwa dane. Jeśli aplikacja jest w porządku, aby czasami pobierać dane, które są nieco nieaktualne, możesz opierać się na konfigurowalnym czasie wygaśnięcia, aby ustawić limit, jak stare dane pamięci podręcznej mogą być.
Możesz skonfigurować bezwzględne wygaśnięcie (czas od utworzenia elementu pamięci podręcznej) lub przesuwanie wygaśnięcia (czas od czasu ostatniego uzyskania dostępu do elementu pamięci podręcznej). Wygaśnięcie bezwzględne jest używane, gdy zależysz od mechanizmu wygasania pamięci podręcznej, aby zapobiec zbyt przestarzałym danym. W aplikacji Fix It ręcznie eksmitujemy przestarzałe elementy pamięci podręcznej i użyjemy przesuwanego wygaśnięcia, aby zachować najświeższe dane w pamięci podręcznej. Niezależnie od wybranych zasad wygasania pamięć podręczna automatycznie eksmituje najstarsze elementy (najmniej ostatnio używane lub LRU), gdy zostanie osiągnięty limit pamięci pamięci pamięci.
Przykładowy kod z odkładania do pamięci podręcznej dla aplikacji Fix It
W poniższym przykładowym kodzie najpierw sprawdzamy pamięć podręczną podczas pobierania zadania Naprawa. Jeśli zadanie zostanie znalezione w pamięci podręcznej, zwrócimy je; Jeśli nie zostanie znaleziona, pobierzemy ją z bazy danych i zapiszemy ją w pamięci podręcznej. Zmiany wprowadzone w celu dodania buforowania do FindTaskByIdAsync metody zostały wyróżnione.
public async Task<FixItTask> FindTaskByIdAsync(int id)
{
FixItTask fixItTask = null;
Stopwatch timespan = Stopwatch.StartNew();
string hitMiss = "Hit";
try
{
fixItTask = (FixItTask)cache.Get(id.ToString());
if (fixItTask == null)
{
fixItTask = await db.FixItTasks.FindAsync(id);
cache.Put(id.ToString(), fixItTask);
hitMiss = "Miss";
}
timespan.Stop();
log.TraceApi("SQL Database", "FixItTaskRepository.FindTaskByIdAsync", timespan.Elapsed,
"cache {0}, id={1}", hitMiss, id);
}
catch (Exception e)
{
log.Error(e, "Error in FixItTaskRepository.FindTaskByIdAsynx(id={0})", id);
}
return fixItTask;
}
Podczas aktualizowania lub usuwania zadania Fix It należy unieważnić (usunąć) buforowane zadanie. W przeciwnym razie przyszłe próby odczytania tego zadania będą nadal pobierać stare dane z pamięci podręcznej.
public async Task UpdateAsync(FixItTask taskToSave)
{
Stopwatch timespan = Stopwatch.StartNew();
try
{
cache.Remove(taskToSave.FixItTaskId.ToString());
db.Entry(taskToSave).State = EntityState.Modified;
await db.SaveChangesAsync();
timespan.Stop();
log.TraceApi("SQL Database", "FixItTaskRepository.UpdateAsync", timespan.Elapsed, "taskToSave={0}", taskToSave);
}
catch (Exception e)
{
log.Error(e, "Error in FixItTaskRepository.UpdateAsync(taskToSave={0})", taskToSave);
}
}
Są to przykłady ilustrujące prosty kod buforowania; Buforowanie nie zostało zaimplementowane w projekcie fix it do pobrania.
Usługi buforowania platformy Azure
Platforma Azure oferuje następujące usługi buforowania: Azure Redis Cache i Azure Managed Cache. Usługa Azure Redis Cache jest oparta na popularnej pamięci podręcznej Redis Cache open source i jest pierwszym wyborem w przypadku większości scenariuszy buforowania.
ASP.NET stan sesji przy użyciu dostawcy pamięci podręcznej
Jak wspomniano w rozdziale najlepszych rozwiązań dotyczących tworzenia aplikacji internetowych, najlepszym rozwiązaniem jest unikanie korzystania ze stanu sesji. Jeśli aplikacja wymaga stanu sesji, najlepszym rozwiązaniem jest uniknięcie domyślnego dostawcy w pamięci, ponieważ nie włącza skalowania w poziomie (wiele wystąpień serwera internetowego). Dostawca stanu sesji ASP.NET SQL Server umożliwia lokacji działającej na wielu serwerach sieci Web korzystanie ze stanu sesji, ale wiąże się z dużymi kosztami opóźnień w porównaniu z dostawcą w pamięci. Najlepszym rozwiązaniem, jeśli musisz użyć stanu sesji, jest użycie dostawcy pamięci podręcznej, takiego jak dostawca stanu sesji dla usługi Azure Cache.
Podsumowanie
Wiesz już, jak aplikacja Fix It może zaimplementować buforowanie w celu zwiększenia czasu odpowiedzi i skalowalności oraz umożliwienia aplikacji dalszego reagowania na operacje odczytu, gdy baza danych jest niedostępna. W następnym rozdziale pokażemy, jak jeszcze bardziej zwiększyć skalowalność i sprawić, że aplikacja będzie nadal reagować na operacje zapisu.
Zasoby
Aby uzyskać więcej informacji na temat buforowania, zobacz następujące zasoby.
Dokumentacja
- Azure Cache. Oficjalna dokumentacja MSDN dotycząca buforowania na platformie Azure.
- Wzorce i praktyki firmy Microsoft — wskazówki dotyczące platformy Azure. Zobacz Wskazówki dotyczące buforowania i wzorzec Cache-Aside.
- Awaria: wskazówki dotyczące odpornych architektur w chmurze. Oficjalny dokument Marc Mercuri, Ulrich Homann i Andrew Townhill. Zobacz sekcję dotyczącą buforowania.
- Najlepsze rozwiązania dotyczące projektowania usług Large-Scale na platformie Azure Cloud Services. W. Biały dokument Marka Simmsa i Michaela Thomassy'ego. Zobacz sekcję dotyczącą buforowania rozproszonego.
- Rozproszone buforowanie na ścieżce do skalowalności. Starszy artykuł (2009) MAGAZYNU MSDN, ale wyraźnie napisane wprowadzenie do rozproszonego buforowania w ogóle; bardziej szczegółowo niż sekcje buforowania w oficjalnych dokumentach FailSafe i Best Practices.The More depth than the caching sections of the FailSafe and Best Practices (Szczegółowe informacje na temat buforowania) w dokumentach dotyczących bezpieczeństwa i najlepszych rozwiązań.
Filmy wideo
- FailSafe: tworzenie skalowalnych, odpornych Cloud Services. Dziewięć części serii Ulrich Homann, Marc Mercuri i Mark Simms. Przedstawia 400-poziomowy widok tworzenia architektury aplikacji w chmurze. Ta seria koncentruje się na teorii i przyczynach; Aby uzyskać więcej informacji na temat instrukcji, zobacz Building Big series by Mark Simms. Zobacz dyskusję na temat buforowania w odcinku 3, począwszy od 1:24:14.
- Tworzenie dużych: wnioski wyciągnięte z klientów platformy Azure — część I. Simon Davies omawia rozproszone buforowanie począwszy od 46:00. Podobnie jak w przypadku serii Failsafe, ale zawiera bardziej szczegółowe instrukcje. Prezentacja została przedstawiona 31 października 2012 r., więc nie obejmuje ona usługi buforowania Web Apps w Azure App Service, która została wprowadzona w 2013 r.
Przykład kodu
- Podstawy usługi w chmurze na platformie Azure. Przykładowa aplikacja, która implementuje rozproszone buforowanie. Zobacz towarzyszący wpis w blogu Cloud Service Fundamentals — Caching Basics (Podstawy usługi w chmurze — podstawy buforowania).
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla