Obsługa błędów przejściowych (tworzenie aplikacji w chmurze Real-World za pomocą platformy Azure)
Autor: Rick Anderson, Tom Dykstra
Pobierz poprawkę projektu lub pobierz książkę elektroniczną
Książka elektroniczna Building Real World Cloud Apps with Azure (Tworzenie rzeczywistych aplikacji w chmurze za pomocą usługi Azure ) opiera się na prezentacji opracowanej przez Scotta Guthrie'ego. Wyjaśniono w nim 13 wzorców i praktyk, które mogą pomóc w pomyślnym tworzeniu aplikacji internetowych dla chmury. Aby uzyskać informacje o książce elektronicznej, zobacz pierwszy rozdział.
Podczas projektowania rzeczywistej aplikacji w chmurze należy pomyśleć o tym, jak obsługiwać tymczasowe przerwy w działaniu usługi. Ten problem jest niezwykle ważny w aplikacjach w chmurze, ponieważ zależysz od połączeń sieciowych i usług zewnętrznych. Często można uzyskać niewielkie usterki, które są zwykle samonaprawiania, a jeśli nie jesteś przygotowany do obsługi ich inteligentnie, spowodują one złe doświadczenie dla klientów.
Przyczyny przejściowych błędów
W środowisku chmury okaże się, że niepowodzenie i porzucanie Połączenia z bazą danych następuje okresowo. Jest to częściowo spowodowane tym, że przechodzisz przez więcej modułów równoważenia obciążenia w porównaniu ze środowiskiem lokalnym, w którym serwer internetowy i serwer bazy danych mają bezpośrednie połączenie fizyczne. Ponadto czasami, gdy zależysz od usługi z wieloma dzierżawami, zobaczysz wywołania usługi są wolniejsze lub przekroczono limit czasu, ponieważ ktoś inny, kto korzysta z usługi, mocno go uderza. W innych przypadkach możesz być użytkownikiem, który zbyt często osiąga usługę, a usługa celowo ogranicza połączenia — w celu uniemożliwienia negatywnego wpływu na inne dzierżawy usługi.
Użyj inteligentnej logiki ponawiania/wycofywania, aby ograniczyć wpływ błędów przejściowych
Zamiast zgłaszać wyjątek i wyświetlać stronę niedostępną lub błędną dla klienta, możesz rozpoznać błędy, które są zazwyczaj przejściowe, i automatycznie ponowić próbę wykonania operacji, która spowodowała błąd, w nadziei, że przed długim upływem czasu zakończysz sukcesem. W większości przypadków operacja zakończy się pomyślnie podczas drugiej próby i odzyskasz sprawę po błędzie bez świadomości klienta, że wystąpił problem.
Istnieje kilka sposobów implementowania logiki ponawiania inteligentnego ponawiania.
Grupa Microsoft Patterns & Practices ma przejściowy blok aplikacji obsługujący błędy, który wykonuje wszystko, jeśli używasz ADO.NET na potrzeby dostępu SQL Database (a nie za pośrednictwem programu Entity Framework). Po prostu ustawisz zasady dla ponownych prób — ile razy ponowisz próbę zapytania lub polecenia i ile czasu oczekiwania między próbami — i opakuj kod SQL w bloku przy użyciu .
public void HandleTransients() { var connStr = "some database"; var _policy = RetryPolicy.Create < SqlAzureTransientErrorDetectionStrategy( retryCount: 3, retryInterval: TimeSpan.FromSeconds(5)); using (var conn = new ReliableSqlConnection(connStr, _policy)) { // Do SQL stuff here. } }TfH obsługuje również usługę Azure In-Role Cache i Service Bus.
W przypadku korzystania z platformy Entity Framework zwykle nie pracujesz bezpośrednio z połączeniami SQL, więc nie można używać tego pakietu Wzorce i praktyki, ale program Entity Framework 6 kompiluje ten rodzaj logiki ponawiania prób bezpośrednio w strukturze. W podobny sposób określisz strategię ponawiania, a następnie program EF używa tej strategii za każdym razem, gdy uzyskuje dostęp do bazy danych.
Aby użyć tej funkcji w aplikacji Fix It, wystarczy dodać klasę, która pochodzi z dbConfiguration i włączyć logikę ponawiania.
// EF follows a Code based Configuration model and will look for a class that // derives from DbConfiguration for executing any Connection Resiliency strategies public class EFConfiguration : DbConfiguration { public EFConfiguration() { AddExecutionStrategy(() => new SqlAzureExecutionStrategy()); } }W przypadku SQL Database wyjątków, które platforma identyfikuje jako typowe błędy przejściowe, kod pokazany nakazuje ef ponawianie próby wykonania operacji do 3 razy, z wykładniczym opóźnieniem wycofywania między ponownymi próbami i maksymalnym opóźnieniem wynoszącym 5 sekund. Wycofywanie wykładnicze oznacza, że po każdym nieudanym ponowieniu próby będzie czekać dłuższy okres czasu, zanim spróbujesz ponownie. Jeśli trzy próby w wierszu nie powiedzą się, zgłosi wyjątek. W poniższej sekcji o wyłącznikach wyjaśniono, dlaczego chcesz wycofać wykładniczą i ograniczoną liczbę ponownych prób.
Podobne problemy mogą wystąpić podczas korzystania z usługi Azure Storage, ponieważ aplikacja Fix It działa w przypadku obiektów blob, a interfejs API klienta magazynu platformy .NET już implementuje ten sam rodzaj logiki. Po prostu określ zasady ponawiania prób lub nawet nie musisz tego robić, jeśli są zadowoleni z ustawień domyślnych.
Wyłączniki automatyczne
Istnieje kilka powodów, dla których nie chcesz ponawiać prób zbyt wiele razy przez zbyt długi okres:
- Zbyt wielu użytkowników stale ponawia próbę ponawiania żądań, które zakończyły się niepowodzeniem, może obniżyć środowisko innych użytkowników. Jeśli miliony osób wykonuje powtarzające się żądania ponawiania prób, możesz wiązać kolejki wysyłania usług IIS i uniemożliwić aplikacji obsługę żądań obsługi, które w przeciwnym razie może obsłużyć pomyślnie.
- Jeśli wszyscy ponawiają próbę z powodu awarii usługi, może istnieć tak wiele żądań w kolejce, że usługa zostanie zalana po rozpoczęciu odzyskiwania.
- Jeśli błąd jest spowodowany ograniczaniem przepustowości i istnieje przedział czasu używany przez usługę do ograniczania przepustowości, dalsze ponawianie prób może przesunąć to okno i spowodować kontynuowanie ograniczania przepustowości.
- Być może użytkownik oczekuje na renderowanie strony internetowej. Dokonywanie ludzi czeka zbyt długo może być bardziej irytujące, że stosunkowo szybko doradzając im, aby spróbować ponownie później.
Wycofywanie wykładnicze rozwiązuje niektóre z tych problemów, ograniczając częstotliwość ponawiania prób, które usługa może pobrać z aplikacji. Należy jednak również mieć wyłączniki: oznacza to, że w określonym progu ponawiania próby aplikacja przestaje ponawiać próbę i podejmuje inne działania, takie jak jedna z następujących czynności:
- Powrót niestandardowy. Jeśli nie możesz uzyskać ceny akcji od Reutersa, może możesz go uzyskać od Bloomberga; lub jeśli nie możesz pobrać danych z bazy danych, być może możesz pobrać je z pamięci podręcznej.
- Niepowodzenie dyskretne. Jeśli to, czego potrzebujesz z usługi, nie jest wszystkie lub nic dla aplikacji, po prostu zwróć wartość null, gdy nie możesz pobrać danych. Jeśli wyświetlasz zadanie Fix It, a usługa Blob Service nie odpowiada, możesz wyświetlić szczegóły zadania bez obrazu.
- Szybkie niepowodzenie. Błąd użytkownika, aby uniknąć zalewania usługi żądaniami ponawiania, które mogą spowodować przerwy w działaniu usługi dla innych użytkowników lub rozszerzyć okno ograniczania przepustowości. Możesz wyświetlić przyjazny komunikat "spróbuj ponownie później".
Nie ma żadnych zasad ponawiania prób w jednym rozmiarze. Możesz ponowić próbę więcej razy i poczekać dłużej w procesie procesu roboczego w tle asynchronicznym niż w synchronicznej aplikacji internetowej, w której użytkownik oczekuje na odpowiedź. Możesz poczekać dłużej między ponowną próbą usługi relacyjnej bazy danych niż w przypadku usługi pamięci podręcznej. Poniżej przedstawiono kilka przykładowych zalecanych zasad ponawiania prób, aby określić, jak mogą się różnić liczby. ("Fast First" oznacza brak opóźnień przed pierwszym ponowieniu próby.
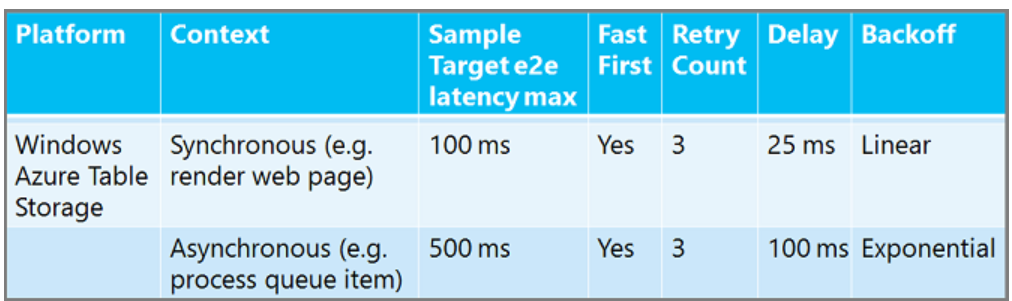
Aby uzyskać wskazówki dotyczące zasad ponawiania prób SQL Database, zobacz Rozwiązywanie problemów z błędami przejściowymi i błędami połączenia w celu SQL Database.
Podsumowanie
Strategia ponawiania/wycofywania może pomóc w usuwaniu tymczasowych błędów niewidocznych dla klienta przez większość czasu, a firma Microsoft udostępnia struktury, których można użyć, aby zminimalizować pracę wdrażającą strategię niezależnie od tego, czy używasz ADO.NET, platformy Entity Framework, czy usługi Azure Storage.
W następnym rozdziale przyjrzymy się, jak poprawić wydajność i niezawodność przy użyciu rozproszonego buforowania.
Zasoby
Więcej informacji można znaleźć w następujących zasobach:
Dokumentacja
- Najlepsze rozwiązania dotyczące projektowania usług Large-Scale na platformie Azure Cloud Services. Oficjalny dokument Marka Simmsa i Michaela Thomassy'ego. Podobnie jak w serii Failsafe, ale zawiera więcej szczegółów instrukcji. Zobacz sekcję Telemetria i diagnostyka.
- Niepowodzenie: wskazówki dotyczące odpornych architektur chmury. Oficjalny dokument Marc Mercuri, Ulrich Homann i Andrew Townhill. Wersja strony internetowej serii wideo FailSafe.
- Wzorce i praktyki firmy Microsoft — wskazówki dotyczące platformy Azure. Zobacz Wzorzec ponawiania prób, wzorzec nadzorcy agenta harmonogramu.
- Entity Framework — odporność połączenia/logika ponawiania prób. Jak używać i dostosowywać funkcję obsługi błędów przejściowych w programie Entity Framework 6.
- Odporność połączenia i przechwytywanie poleceń za pomocą programu Entity Framework w aplikacji MVC ASP.NET. Czwarty w dziewiątej części serii samouczków pokazuje, jak skonfigurować funkcję odporności połączeń EF 6 dla SQL Database.
Filmy wideo
- FailSafe: tworzenie skalowalnych, odpornych Cloud Services. Dziewięć części serii Ulrich Homann, Marc Mercuri i Mark Simms. Przedstawia pojęcia wysokiego poziomu i zasady architektury w bardzo dostępny i interesujący sposób, z historiami pochodzącymi z zespołu doradczego klienta firmy Microsoft (CAT) z rzeczywistymi klientami. Zobacz dyskusję wyłączników w odcinku 3 począwszy od 40:55.
- Tworzenie dużych: wnioski zdobyte od klientów platformy Azure — część II. Mark Simms mówi o projektowaniu pod kątem awarii, obsługi błędów przejściowych i instrumentacji wszystkiego.
Przykład kodu
- Podstawy usługi w chmurze na platformie Azure. Przykładowa aplikacja utworzona przez zespół doradczy klienta platformy Microsoft Azure, która pokazuje, jak używać bloku obsługi błędów przejściowych biblioteki przedsiębiorstwa (TFH). Aby uzyskać więcej informacji, zobacz Cloud Service Fundamentals Data Access Layer – Transient Fault Handling (Warstwa dostępu do danych w aplikacji Cloud Service Fundamentals — obsługa błędów przejściowych). Serwer TFH jest zalecany do uzyskiwania dostępu do bazy danych przy użyciu ADO.NET bezpośrednio (bez korzystania z programu Entity Framework).
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla