Typowym problemem, z jakim borykają się organizacje, jest zbieranie danych z wielu źródeł w wielu formatach. Następnie należy przenieść go do co najmniej jednego magazynu danych. Miejsce docelowe może nie być tym samym typem magazynu danych co źródło. Często format jest inny lub dane muszą być ukształtowane lub oczyszczone przed załadowaniem ich do końcowego miejsca docelowego.
Na przestrzeni lat opracowano różne narzędzia, usługi i procesy, aby pomóc w rozwiązywaniu tych problemów. Niezależnie od używanego procesu wspólna potrzeba koordynowania pracy i stosowania pewnego poziomu transformacji danych w potoku danych. W poniższych sekcjach przedstawiono typowe metody używane do wykonywania tych zadań.
Proces wyodrębniania, przekształcania i ładowania (ETL)
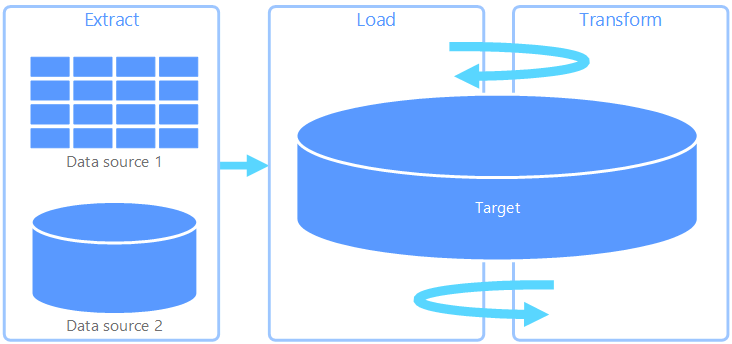
Wyodrębnianie, przekształcanie i ładowanie (ETL) to potok danych używany do zbierania danych z różnych źródeł. Następnie przekształca dane zgodnie z regułami biznesowymi i ładuje je do docelowego magazynu danych. Prace związane z przekształcaniem w technologii ETL odbywają się w wyspecjalizowanym a także często polegają na użyciu tabel przejściowych do tymczasowego przechowywania danych w miarę ich przekształcania i ostatecznie ładowania do miejsca docelowego.

Transformacja danych, która odbywa się zwykle, obejmuje różne operacje, takie jak filtrowanie, sortowanie, agregowanie, łączenie danych, czyszczenie danych, deduplikacja i weryfikowanie danych.
Często trzy fazy ETL są uruchamiane równolegle, aby zaoszczędzić czas. Na przykład podczas wyodrębniania danych proces przekształcania może pracować nad danymi już odebranych i przygotować je do załadowania, a proces ładowania może rozpocząć pracę nad przygotowanymi danymi, zamiast czekać na ukończenie całego procesu wyodrębniania.
Odpowiednie usługi Azure:
Inne narzędzia:
Wyodrębnianie, ładowanie i transformacja (ELT)
Wyodrębnianie, ładowanie i przekształcanie (ELT) różni się od procesu ETL wyłącznie w przypadku, gdy odbywa się transformacja. W potoku ELT transformacja odbywa się w docelowym magazynie danych. Zamiast korzystać z oddzielnego aparatu przekształcania, możliwości przetwarzania docelowego magazynu danych są używane do przekształcania danych. Upraszcza to architekturę, usuwając aparat przekształcania z potoku. Kolejną zaletą tego podejścia jest to, że skalowanie docelowego magazynu danych powoduje również skalowanie wydajności potoku ELT. Jednak ELT działa dobrze tylko wtedy, gdy system docelowy jest wystarczająco zaawansowany, aby efektywnie przekształcać dane.
Typowe przypadki użycia ELT należą do obszaru danych big data. Na przykład możesz zacząć od wyodrębnienia wszystkich danych źródłowych do plików prostych w skalowalnym magazynie, takim jak rozproszony system plików Hadoop, magazyn obiektów blob platformy Azure lub usługa Azure Data Lake Gen 2 (lub kombinacja). Technologie, takie jak Spark, Hive lub Polybase, mogą być następnie używane do wykonywania zapytań dotyczących danych źródłowych. Kluczowym punktem z ELT jest to, że magazyn danych używany do przeprowadzenia transformacji jest tym samym magazynem danych, w którym dane są ostatecznie używane. Ten magazyn danych odczytuje bezpośrednio ze skalowalnego magazynu zamiast ładowania danych do własnego magazynu. Takie podejście pomija krok kopiowania danych obecny w etl, co często może być czasochłonną operacją dla dużych zestawów danych.
W praktyce docelowy magazyn danych to magazyn danych korzystający z klastra Hadoop (przy użyciu programu Hive lub Spark) lub dedykowanych pul SQL w usłudze Azure Synapse Analytics. Ogólnie rzecz biorąc, schemat jest nakładany na dane plików prostych w czasie wykonywania zapytań i przechowywany jako tabela, umożliwiając wykonywanie zapytań dotyczących danych tak jak każda inna tabela w magazynie danych. Są one określane jako tabele zewnętrzne, ponieważ dane nie znajdują się w magazynie zarządzanym przez sam magazyn danych, ale w niektórych zewnętrznych skalowalnych magazynach, takich jak azure data lake store lub Azure Blob Storage.
Magazyn danych zarządza tylko schematem danych i stosuje schemat podczas odczytu. Na przykład klaster Hadoop korzystający z programu Hive opisuje tabelę programu Hive, w której źródło danych jest w rzeczywistości ścieżką do zestawu plików w systemie plików HDFS. W usłudze Azure Synapse technologia PolyBase może osiągnąć ten sam wynik — tworząc tabelę dla danych przechowywanych zewnętrznie w samej bazie danych. Po załadowaniu danych źródłowych dane obecne w tabelach zewnętrznych mogą być przetwarzane przy użyciu możliwości magazynu danych. W scenariuszach danych big data oznacza to, że magazyn danych musi być zdolny do masowego przetwarzania równoległego (MPP), który dzieli dane na mniejsze fragmenty i dystrybuuje przetwarzanie fragmentów między wieloma węzłami równolegle.
Ostatnią fazą potoku ELT jest zwykle przekształcanie danych źródłowych w ostateczny format, który jest bardziej wydajny dla typów zapytań, które muszą być obsługiwane. Na przykład dane mogą być partycjonowane. Ponadto ELT może używać zoptymalizowanych formatów magazynu, takich jak Parquet, które przechowują dane zorientowane na wiersze w sposób kolumnowy i zapewniają zoptymalizowane indeksowanie.
Odpowiednie usługi Azure:
- Dedykowane pule SQL w usłudze Azure Synapse Analytics
- Pule bezserwerowe SQL w usłudze Azure Synapse Analytics
- Usługa HDInsight z programem Hive
- Azure Data Factory
- Magazyny danych w usłudze Power BI
Inne narzędzia:
Przepływ danych i przepływ sterowania
W kontekście potoków danych przepływ sterowania zapewnia uporządkowane przetwarzanie zestawu zadań. Aby wymusić poprawną kolejność przetwarzania tych zadań, używane są ograniczenia pierwszeństwa. Te ograniczenia można traktować jako łączniki na diagramie przepływu pracy, jak pokazano na poniższej ilustracji. Każde zadanie ma wynik, taki jak powodzenie, niepowodzenie lub ukończenie. Każde kolejne zadanie nie inicjuje przetwarzania, dopóki jego poprzednik nie zakończy się jednym z tych wyników.
Przepływy sterowania wykonują przepływy danych jako zadanie. W zadaniu przepływu danych dane są wyodrębniane ze źródła, przekształcenia lub załadowania do magazynu danych. Dane wyjściowe jednego zadania przepływu danych mogą być danymi wejściowymi do następnego zadania przepływu danych, a przepływy danych mogą być uruchamiane równolegle. W przeciwieństwie do przepływów sterowania nie można dodawać ograniczeń między zadaniami w przepływie danych. Można jednak dodać przeglądarkę danych, aby obserwować dane przetwarzane przez każde zadanie.
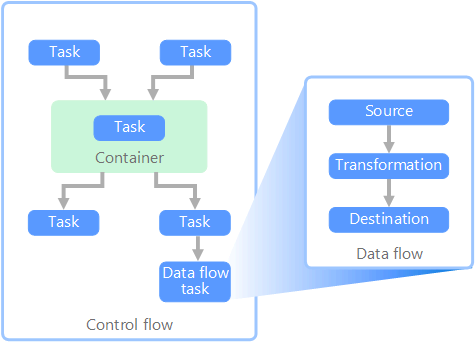
Na powyższym diagramie znajduje się kilka zadań w przepływie sterowania, z których jednym jest zadanie przepływu danych. Jedno z zadań jest zagnieżdżone w kontenerze. Kontenery mogą służyć do zapewnienia struktury zadań, zapewniając jednostkę pracy. Jednym z takich przykładów jest powtarzanie elementów w kolekcji, takich jak pliki w instrukcjach folderu lub bazy danych.
Odpowiednie usługi Azure:
Inne narzędzia:
Wybór technologi
- Magazyny danych przetwarzania transakcji online (OLTP)
- Magazyny danych przetwarzania analitycznego online (OLAP)
- Magazyny danych
- Aranżacja potoku
Współautorzy
Ten artykuł jest obsługiwany przez firmę Microsoft. Pierwotnie został napisany przez następujących współautorów.
Główny autor:
- Raunak Jhawar | Starszy architekt chmury
- Zoiner Tejada | Dyrektor generalny i architekt
Następne kroki
- Integrowanie danych z usługą Azure Data Factory lub potokiem usługi Azure Synapse
- Wprowadzenie do usługi Azure Synapse Analytics
- Organizowanie przenoszenia i przekształcania danych w usłudze Azure Data Factory lub potoku usługi Azure Synapse
Powiązane zasoby
Następujące architektury referencyjne pokazują kompleksowe potoki ELT na platformie Azure: