Przetwarzanie języka naturalnego (NLP) ma wiele zastosowań: analizę tonacji, wykrywanie tematów, wykrywanie języka, wyodrębnianie kluczowych fraz i kategoryzacja dokumentów.
W szczególności możesz użyć nlp do:
- Klasyfikowanie dokumentów. Możesz na przykład oznaczyć dokumenty jako poufne lub spamu.
- Wykonaj kolejne przetwarzanie lub wyszukiwanie. W tych celach można użyć danych wyjściowych nlp.
- Podsumuj tekst, identyfikując jednostki, które znajdują się w dokumencie.
- Oznaczanie dokumentów słowami kluczowymi. Dla słów kluczowych nlp może używać zidentyfikowanych jednostek.
- Wykonaj wyszukiwanie oparte na zawartości i pobieranie. Tagowanie sprawia, że ta funkcja jest możliwa.
- Podsumowanie ważnych tematów dokumentu. NlP może łączyć zidentyfikowane jednostki w tematy.
- Kategoryzuj dokumenty na potrzeby nawigacji. W tym celu nlp używa wykrytych tematów.
- Wyliczanie powiązanych dokumentów na podstawie wybranego tematu. W tym celu nlp używa wykrytych tematów.
- Ocenianie tekstu pod kątem tonacji. Korzystając z tej funkcji, można ocenić pozytywny lub negatywny ton dokumentu.
Apache®, Apache Spark i logo płomienia są zastrzeżonymi znakami towarowymi lub znakami towarowymi fundacji Apache Software Foundation w Stany Zjednoczone i/lub innych krajach. Użycie tych znaków nie jest dorozumiane przez fundację Apache Software Foundation.
Potencjalne przypadki użycia
Scenariusze biznesowe, które mogą korzystać z niestandardowej równoważenia obciążenia sieciowego, obejmują:
- Analiza dokumentów dla dokumentów napisanych odręcznie lub utworzonych maszynowo w sektorze finansów, opieki zdrowotnej, handlu detalicznego, instytucji rządowych i innych sektorów.
- Niezależne od branży zadania NLP do przetwarzania tekstu, takie jak rozpoznawanie jednostek nazw (NER), klasyfikacja, podsumowanie i wyodrębnianie relacji. Te zadania automatyzują proces pobierania, identyfikowania i analizowania informacji o dokumencie, takich jak tekst i dane bez struktury. Przykłady tych zadań obejmują modele stratification ryzyka, klasyfikację ontologii i podsumowania sprzedaży detalicznej.
- Pobieranie informacji i tworzenie grafu wiedzy na potrzeby wyszukiwania semantycznego. Ta funkcja umożliwia tworzenie grafów wiedzy medycznej, które obsługują odnajdywanie leków i badania kliniczne.
- Tłumaczenie tekstu dla konwersacyjnych systemów sztucznej inteligencji w aplikacjach przeznaczonych dla klientów w branży handlu detalicznego, finansów, podróży i innych branż.
Platforma Apache Spark jako niestandardowa struktura NLP
Apache Spark jest platformą przetwarzania równoległego, która obsługuje przetwarzanie w pamięci w celu zwiększania wydajności aplikacji do analizy danych big data. Usługi Azure Synapse Analytics, Azure HDInsight i Azure Databricks oferują dostęp do platformy Spark i korzystają z jej mocy obliczeniowej.
W przypadku dostosowanych obciążeń NLP platforma Spark NLP służy jako wydajna struktura do przetwarzania dużej ilości tekstu. Ta biblioteka NLP typu open source udostępnia biblioteki Języka Python, Java i Scala, które oferują pełną funkcjonalność tradycyjnych bibliotek NLP, takich jak spaCy, NLTK, Stanford CoreNLP i Open NLP. Usługa Spark NLP oferuje również funkcje, takie jak sprawdzanie pisowni, analiza tonacji i klasyfikacja dokumentów. Usługa Spark NLP usprawnia poprzednie działania, zapewniając najnowocześniejsze dokładność, szybkość i skalowalność.
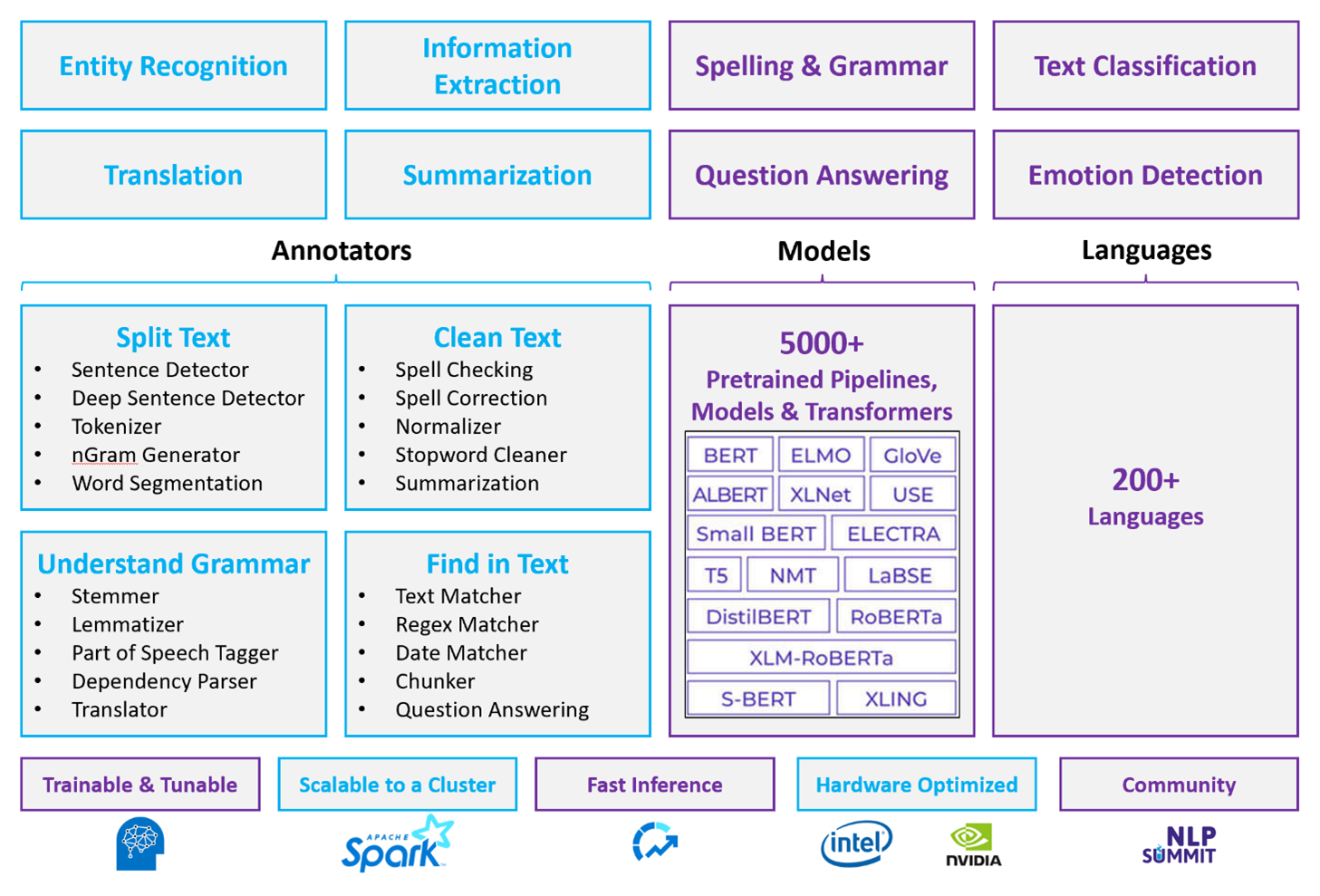
Ostatnie publiczne testy porównawcze pokazują, że platforma Spark NLP jest 38 i 80 razy szybsza niż spaCy, z porównywalną dokładnością trenowania modeli niestandardowych. Spark NLP to jedyna biblioteka typu open source, która może używać rozproszonego klastra Spark. Spark NLP to natywne rozszerzenie spark ML, które działa bezpośrednio na ramkach danych. W związku z tym przyspieszenie klastra powoduje kolejną kolejność wzrostu wydajności. Ponieważ każdy potok równoważenia obciążenia sieciowego platformy Spark jest potokiem spark ML, usługa Spark NLP jest dobrze odpowiednia do tworzenia ujednoliconych potoków nlp i uczenia maszynowego, takich jak klasyfikacja dokumentów, przewidywanie ryzyka i potoki poleceń.
Oprócz doskonałej wydajności usługa Spark NLP zapewnia również najnowocześniejsze dokładność dla rosnącej liczby zadań NLP. Zespół NlP platformy Spark regularnie odczytuje najnowsze istotne dokumenty akademickie i implementuje najnowocześniejsze modele. W ciągu ostatnich dwóch do trzech lat najlepiej działające modele korzystały z uczenia głębokiego. Biblioteka zawiera wstępnie utworzone modele uczenia głębokiego do rozpoznawania jednostek nazwanych, klasyfikacji dokumentów, tonacji i wykrywania emocji oraz wykrywania zdań. Biblioteka zawiera również dziesiątki wstępnie wytrenowanych modeli językowych, które obejmują obsługę osadzania wyrazów, fragmentów, zdań i dokumentów.
Biblioteka ma zoptymalizowane kompilacje pod kątem procesorów CPU, procesorów GPU i najnowszych procesorów Intel Xeon. Możesz skalować procesy trenowania i wnioskowania, aby korzystać z klastrów Spark. Te procesy mogą być uruchamiane w środowisku produkcyjnym na wszystkich popularnych platformach analitycznych.
Wyzwania
- Przetwarzanie kolekcji dokumentów tekstowych w dowolnej formie wymaga znacznej ilości zasobów obliczeniowych. Przetwarzanie jest również czasochłonne. Takie procesy często obejmują wdrażanie obliczeń procesora GPU.
- Bez ustandaryzowanego formatu dokumentu uzyskanie spójnych dokładnych wyników w przypadku korzystania z przetwarzania tekstu w dowolnej formie w celu wyodrębnienia określonych faktów z dokumentu może być trudne. Na przykład pomyśl o tekstowej reprezentacji faktury — może być trudno utworzyć proces, który poprawnie wyodrębnia numer faktury i datę, gdy faktury pochodzą od różnych dostawców.
Kluczowe kryteria wyboru
Na platformie Azure usługi Spark, takie jak Azure Databricks, Azure Synapse Analytics i Azure HDInsight, zapewniają funkcję NLP podczas korzystania z usługi Spark NLP. Usługi Azure Cognitive Services to kolejna opcja funkcji NLP. Aby zdecydować, która usługa ma być używana, należy wziąć pod uwagę następujące pytania:
Czy chcesz używać wstępnie utworzonych lub wstępnie wytrenowanych modeli? Jeśli tak, rozważ użycie interfejsów API, które oferuje usługa Azure Cognitive Services. Możesz też pobrać wybrany model za pomocą usługi Spark NLP.
Czy musisz wytrenować modele niestandardowe względem dużego korpusu danych tekstowych? Jeśli tak, rozważ użycie usług Azure Databricks, Azure Synapse Analytics lub Azure HDInsight z usługą Spark NLP.
Czy potrzebujesz funkcji nlp niskiego poziomu, takich jak tokenizacja, stemming, lemmatization i częstotliwość terminów/odwrotna częstotliwość dokumentu (TF/IDF)? Jeśli tak, rozważ użycie usług Azure Databricks, Azure Synapse Analytics lub Azure HDInsight z usługą Spark NLP. Możesz też użyć biblioteki oprogramowania typu open source w wybranym narzędziu przetwarzania.
Czy potrzebujesz prostych funkcji nlp wysokiego poziomu, takich jak identyfikacja jednostek i intencji, wykrywanie tematów, sprawdzanie pisowni lub analiza tonacji? Jeśli tak, rozważ użycie interfejsów API, które oferuje usługi Cognitive Services. Możesz też pobrać wybrany model za pomocą usługi Spark NLP.
Macierz możliwości
W poniższych tabelach podsumowano kluczowe różnice w możliwościach usług NLP.
Ogólne możliwości
| Możliwość | Usługa Spark (Azure Databricks, Azure Synapse Analytics, Azure HDInsight) z usługą Spark NLP | Azure Cognitive Services |
|---|---|---|
| Udostępnia wstępnie wytrenowane modele jako usługę | Tak | Tak |
| Interfejs API REST | Tak | Tak |
| Możliwości programowania | Python, Scala | Aby uzyskać informacje o obsługiwanych językach, zobacz Dodatkowe zasoby |
| Obsługuje przetwarzanie zestawów danych big data i dużych dokumentów | Tak | Nie. |
Funkcje równoważenia obciążenia sieciowego niskiego poziomu
| Możliwości adnotacji | Usługa Spark (Azure Databricks, Azure Synapse Analytics, Azure HDInsight) z usługą Spark NLP | Azure Cognitive Services |
|---|---|---|
| Detektor zdań | Tak | Nie. |
| Wykrywacz głębokich zdań | Tak | Tak |
| Tokenizer | Tak | Tak |
| Generator N-gram | Tak | Nie. |
| Segmentacja wyrazów | Tak | Tak |
| Stemmer | Tak | Nie. |
| Lemmatizer | Tak | Nie. |
| Tagowanie części mowy | Tak | Nie. |
| Analizator zależności | Tak | Nie. |
| Tłumaczenie | Tak | Nie. |
| Czyszczenie stopwordów | Tak | Nie. |
| Korekta pisowni | Tak | Nie. |
| Normalizer | Tak | Tak |
| Dopasowywanie tekstu | Tak | Nie. |
| TF/IDF | Tak | Nie. |
| Dopasowywanie wyrażeń regularnych | Tak | Osadzony w usłudze Language Understanding Service (LUIS). Nieobsługiwane w usłudze Conversational Language Understanding (CLU), która zastępuje usługę LUIS. |
| Dopasowywanie dat | Tak | Możliwe w usłudze LUIS i clu za pomocą rozpoznawania daty/godziny |
| Fragmentator | Tak | Nie. |
Ogólne możliwości równoważenia obciążenia sieciowego
| Możliwość | Usługa Spark (Azure Databricks, Azure Synapse Analytics, Azure HDInsight) z usługą Spark NLP | Azure Cognitive Services |
|---|---|---|
| Sprawdzanie pisowni | Tak | Nie. |
| Podsumowanie | Tak | Tak |
| Odpowiadanie na pytania | Tak | Tak |
| Wykrywanie tonacji | Tak | Tak |
| Wykrywanie emocji | Tak | Wspiera górnictwo opinii |
| Klasyfikacja tokenów | Tak | Tak, za pośrednictwem modeli niestandardowych |
| Klasyfikacja tekstu | Tak | Tak, za pośrednictwem modeli niestandardowych |
| Reprezentacja tekstu | Tak | Nie. |
| NER | Tak | Tak — analiza tekstu udostępnia zestaw jednostek NER, a modele niestandardowe są w funkcji rozpoznawania jednostek |
| Rozpoznawanie jednostek | Tak | Tak, za pośrednictwem modeli niestandardowych |
| Wykrywanie języka | Tak | Tak |
| Obsługuje języki poza językiem angielskim | Tak, obsługuje ponad 200 języków | Tak, obsługuje ponad 97 języków |
Konfigurowanie usługi Spark NLP na platformie Azure
Aby zainstalować usługę Spark NLP, użyj następującego kodu, ale zastąp <version> ciąg najnowszym numerem wersji. Aby uzyskać więcej informacji, zobacz dokumentację usługi Spark NLP.
# Install Spark NLP from PyPI.
pip install spark-nlp==<version>
# Install Spark NLP from Anacodna or Conda.
conda install -c johnsnowlabs spark-nlp
# Load Spark NLP with Spark Shell.
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with PySpark.
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with Spark Submit.
spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP as an external JAR after compiling and building Spark NLP by using sbt assembly.
spark-shell --jars spark-nlp-assembly-3 <version>.jar
Opracowywanie potoków nlp
W przypadku kolejności wykonywania potoku NLP platforma Spark NLP jest zgodna z tą samą koncepcją programowania co tradycyjne modele uczenia maszynowego spark ML. Jednak usługa Spark NLP stosuje techniki NLP.
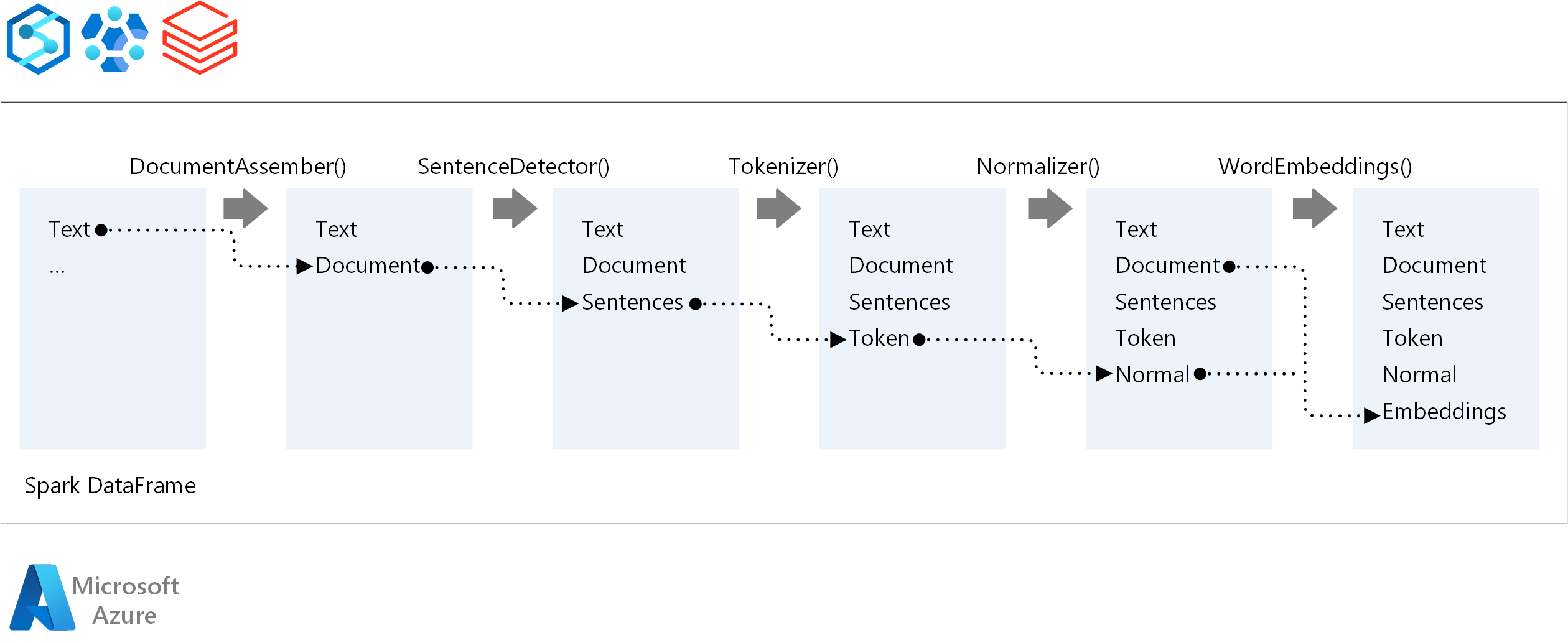
Podstawowe składniki potoku równoważenia obciążenia sieciowego platformy Spark to:
DocumentAssembler: transformator, który przygotowuje dane, zmieniając je w format, który może przetwarzać nlp platformy Spark. Ten etap jest punktem wejścia dla każdego potoku nlp platformy Spark. Usługa DocumentAssembler może odczytywać kolumnę
Stringlub .Array[String]Możesz użyćsetCleanupModepolecenia , aby wstępnie przetworzyć tekst. Domyślnie ten tryb jest wyłączony.SentenceDetector: adnotacja, która wykrywa granice zdań przy użyciu podanego podejścia. Ten adnotacja może zwrócić każde wyodrębnione zdanie w elemencie
Array. Może również zwrócić każde zdanie w innym wierszu, jeśli ustawionoexplodeSentenceswartość true.Tokenizer: adnotacja oddzielającą nieprzetworzone tekst na tokeny lub jednostki, takie jak słowa, liczby i symbole, i zwraca tokeny w
TokenizedSentencestrukturze. Ta klasa nie jest dopasowana. Jeśli pasujesz do tokenizatora, wewnętrznaRuleFactoryużywa konfiguracji wejściowej do konfigurowania reguł tokenizowania. Tokenizer używa otwartych standardów do identyfikowania tokenów. Jeśli ustawienia domyślne nie spełniają Twoich potrzeb, możesz dodać reguły w celu dostosowania tokenizatora.Normalizer: adnotacja, która czyści tokeny. Normalizator wymaga stems. Normalizer używa wyrażeń regularnych i słownika do przekształcania tekstu i usuwania zanieczyszczonych znaków.
WordEmbeddings: adnotacje odnośników mapujące tokeny na wektory.
setStoragePathSłuży do określania niestandardowego słownika wyszukiwania tokenów na potrzeby osadzania. Każdy wiersz słownika musi zawierać token i jego reprezentację wektorową oddzieloną spacjami. Jeśli token nie zostanie znaleziony w słowniku, wynik jest zerowym wektorem tego samego wymiaru.
Równoważenie obciążenia sieciowego platformy Spark używa potoków MLlib platformy Spark, które są obsługiwane natywnie przez platformę MLflow. MLflow to platforma typu open source dla cyklu życia uczenia maszynowego. Jego składniki obejmują:
- Śledzenie mlflow: rejestruje eksperymenty i umożliwia wykonywanie zapytań dotyczących wyników.
- Projekty MLflow: umożliwia uruchamianie kodu nauki o danych na dowolnej platformie.
- Modele MLflow: wdraża modele w różnych środowiskach.
- Rejestr modeli: zarządza modelami przechowywanymi w centralnym repozytorium.
Rozwiązanie MLflow jest zintegrowane w usłudze Azure Databricks. Rozwiązanie MLflow można zainstalować w dowolnym innym środowisku opartym na platformie Spark, aby śledzić eksperymenty i zarządzać nimi. Możesz również użyć rejestru modeli MLflow, aby udostępnić modele do celów produkcyjnych.
Współautorzy
Ten artykuł jest obsługiwany przez firmę Microsoft. Pierwotnie został napisany przez następujących współautorów.
Autorzy zabezpieczeń:
- Moritz Steller | Starszy architekt rozwiązań w chmurze
- Zoiner Tejada | Dyrektor generalny i architekt
Następne kroki
Dokumentacja nlp platformy Spark:
- Równoważenie obciążenia sieciowego platformy Spark
- Ogólna dokumentacja usługi Spark NLP
- Usługa GitHub równoważenia obciążenia sieciowego platformy Spark
- Pokaz równoważenia obciążenia sieciowego platformy Spark
- Potoki równoważenia obciążenia sieciowego platformy Spark
- Adnotacje nlp platformy Spark
- Transformatory NLP platformy Spark
Składniki platformy Azure:
Zasoby platformy Learn:
Powiązane zasoby
- Niestandardowe przetwarzanie języka naturalnego na platformie Azure na dużą skalę
- Wybieranie technologii usług Microsoft Cognitive Services
- Porównanie produktów i technologii uczenia maszynowego firmy Microsoft
- Przepływ uczenia maszynowego i usługa Azure Machine Learning
- Wzbogacanie sztucznej inteligencji przy użyciu obrazów i przetwarzania języka naturalnego w usłudze Azure Cognitive Search
- Analizowanie kanałów informacyjnych za pomocą analizy niemal w czasie rzeczywistym przy użyciu przetwarzania obrazów i języka naturalnego
- Sugerowanie tagów zawartości przy użyciu nlp przy użyciu uczenia głębokiego