Uwaga
Ten artykuł opiera się na bibliotece open source hostowanej w witrynie GitHub pod adresem : https://github.com/mspnp/spark-monitoring.
Oryginalna biblioteka obsługuje środowiska Azure Databricks Runtimes 10.x (Spark 3.2.x) i starsze.
Usługa Databricks udostępniła zaktualizowaną wersję do obsługi środowiska Azure Databricks Runtimes 11.0 (Spark 3.3.x) i nowszego w l4jv2 gałęzi pod adresem : https://github.com/mspnp/spark-monitoring/tree/l4jv2.
Należy pamiętać, że wersja 11.0 nie jest zgodna z poprzednimi wersjami ze względu na różne systemy rejestrowania używane w środowiskach Databricks Runtime. Pamiętaj, aby użyć poprawnej kompilacji środowiska Databricks Runtime. Biblioteka i repozytorium GitHub są w trybie konserwacji. Nie ma planów dalszych wydań, a pomoc techniczna dotycząca problemów będzie dostępna tylko w najlepszym celu. Aby uzyskać dodatkowe pytania dotyczące biblioteki lub planu monitorowania i rejestrowania środowisk usługi Azure Databricks, skontaktuj się z .azure-spark-monitoring-help@databricks.com
To rozwiązanie demonstruje wzorce obserwacji i metryki w celu zwiększenia wydajności przetwarzania systemu danych big data, który korzysta z usługi Azure Databricks.
Architektura

Pobierz plik programu Visio z tą architekturą.
Przepływ pracy
Rozwiązanie obejmuje następujące kroki:
Serwer wysyła duży plik GZIP pogrupowany przez klienta do folderu Źródłowego w usłudze Azure Data Lake Storage (ADLS).
Usługa ADLS następnie wysyła pomyślnie wyodrębniony plik klienta do usługi Azure Event Grid, co przekształca dane pliku klienta w kilka komunikatów.
Usługa Azure Event Grid wysyła komunikaty do usługi Azure Queue Storage, która przechowuje je w kolejce.
Usługa Azure Queue Storage wysyła kolejkę do platformy analizy danych usługi Azure Databricks na potrzeby przetwarzania.
Usługa Azure Databricks rozpakuje i przetwarza dane kolejki do przetworzonego pliku, który wysyła z powrotem do usługi ADLS:
Jeśli przetworzony plik jest prawidłowy, znajduje się w folderze Docelowy .
W przeciwnym razie plik zostanie wyświetlony w drzewie Nieprawidłowe foldery. Początkowo plik przechodzi do podfolderu Ponów próbę, a usługa ADLS próbuje ponownie przetwarzać pliki klienta (krok 2). Jeśli para ponownych prób nadal prowadzi do zwracania przetworzonych plików w usłudze Azure Databricks, które nie są prawidłowe, przetworzony plik zostanie wyświetlony w podfolderze Niepowodzenie .
Gdy usługa Azure Databricks rozpakuje i przetwarza dane w poprzednim kroku, wysyła również dzienniki aplikacji i metryki do usługi Azure Monitor na potrzeby magazynu.
Obszar roboczy usługi Azure Log Analytics stosuje zapytania Kusto dotyczące dzienników aplikacji i metryk z usługi Azure Monitor w celu rozwiązywania problemów i szczegółowej diagnostyki.
Elementy
- Usługa Azure Data Lake Storage to zestaw funkcji przeznaczonych do analizy danych big data.
- Usługa Azure Event Grid umożliwia deweloperowi łatwe tworzenie aplikacji z architekturami opartymi na zdarzeniach.
- Azure Queue Storage to usługa do przechowywania dużej liczby komunikatów. Umożliwia dostęp do komunikatów z dowolnego miejsca na świecie za pośrednictwem uwierzytelnionych wywołań przy użyciu protokołu HTTP lub HTTPS. Kolejki umożliwiają tworzenie listy prac w celu asynchronicznego przetwarzania.
- Azure Databricks to platforma analizy danych zoptymalizowana pod kątem platformy w chmurze azure. Jednym z dwóch środowisk usługi Azure Databricks oferuje tworzenie aplikacji intensywnie korzystających z danych jest obszar roboczy usługi Azure Databricks, ujednolicony aparat analityczny oparty na platformie Apache Spark na potrzeby przetwarzania danych na dużą skalę.
- Usługa Azure Monitor zbiera i analizuje dane telemetryczne aplikacji, takie jak metryki wydajności i dzienniki aktywności.
- Azure Log Analytics to narzędzie służące do edytowania i uruchamiania zapytań dzienników z danymi.
Szczegóły scenariusza
Twój zespół programistyczny może używać wzorców obserwacji i metryk, aby znaleźć wąskie gardła i poprawić wydajność systemu danych big data. Twój zespół musi przeprowadzić testowanie obciążenia strumienia metryk na dużą skalę w aplikacji o dużej skali.
Ten scenariusz zawiera wskazówki dotyczące dostrajania wydajności. Ponieważ scenariusz stanowi wyzwanie dla wydajności rejestrowania poszczególnych klientów, korzysta z usługi Azure Databricks, która może niezawodnie monitorować te elementy:
- Metryki aplikacji niestandardowych
- Zdarzenia zapytań przesyłanych strumieniowo
- Komunikaty dziennika aplikacji
Usługa Azure Databricks może wysyłać te dane monitorowania do różnych usług rejestrowania, takich jak Azure Log Analytics.
W tym scenariuszu opisano pozyskiwanie dużego zestawu danych pogrupowanych przez klienta i przechowywanych w pliku archiwum GZIP. Szczegółowe dzienniki są niedostępne z usługi Azure Databricks poza interfejsem użytkownika platformy Apache Spark™ w czasie rzeczywistym, więc twój zespół potrzebuje sposobu przechowywania wszystkich danych dla każdego klienta, a następnie porównywania i porównywania. W przypadku dużego scenariusza danych ważne jest znalezienie optymalnej puli funkcji wykonawczej kombinacji i rozmiaru maszyny wirtualnej w celu uzyskania najszybszego czasu przetwarzania. W tym scenariuszu biznesowym ogólna aplikacja opiera się na szybkości pozyskiwania i wysyłania zapytań, dzięki czemu przepływność systemu nie spada nieoczekiwanie wraz ze wzrostem ilości pracy. Scenariusz musi zagwarantować, że system spełnia umowy dotyczące poziomu usług (SLA) ustanowione z klientami.
Potencjalne przypadki użycia
Scenariusze, które mogą korzystać z tego rozwiązania, obejmują:
- Monitorowanie kondycji systemu.
- Konserwacja wydajności.
- Monitorowanie codziennego użycia systemu.
- Wykrycie trendów, które mogą powodować przyszłe problemy, jeśli nie są ubrane.
Kwestie wymagające rozważenia
Te zagadnienia implementują filary struktury Azure Well-Architected Framework, która jest zestawem wytycznych, które mogą służyć do poprawy jakości obciążenia. Aby uzyskać więcej informacji, zobacz Microsoft Azure Well-Architected Framework.
Podczas rozważania tej architektury należy pamiętać o następujących kwestiach:
Usługa Azure Databricks może automatycznie przydzielić zasoby obliczeniowe niezbędne do dużego zadania, co pozwala uniknąć problemów, które wprowadza inne rozwiązania. Na przykład w przypadku skalowania automatycznego zoptymalizowanego pod kątem usługi Databricks na platformie Apache Spark nadmierne aprowizowanie może spowodować nieoptymalne użycie zasobów. Możesz też nie znać liczby funkcji wykonawczych wymaganych do wykonania zadania.
Komunikat kolejki w usłudze Azure Queue Storage może mieć rozmiar do 64 KB. Kolejka może zawierać miliony komunikatów w kolejce do całkowitego limitu pojemności konta magazynu.
Optymalizacja kosztów
Optymalizacja kosztów dotyczy sposobów zmniejszenia niepotrzebnych wydatków i poprawy wydajności operacyjnej. Aby uzyskać więcej informacji, zobacz Omówienie filaru optymalizacji kosztów.
Skorzystaj z kalkulatora cen platformy Azure, aby oszacować koszt wdrożenia tego rozwiązania.
Wdrażanie tego scenariusza
Uwaga
Opisane tutaj kroki wdrażania dotyczą tylko usług Azure Databricks, Azure Monitor i Azure Log Analytics. Wdrożenie innych składników nie zostało omówione w tym artykule.
Aby uzyskać wszystkie dzienniki i informacje dotyczące procesu, skonfiguruj usługę Azure Log Analytics i bibliotekę monitorowania usługi Azure Databricks. Biblioteka monitorowania przesyła strumieniowo zdarzenia na poziomie platformy Apache Spark i metryki przesyłania strumieniowego ze strukturą platformy Spark z zadań do usługi Azure Monitor. Nie musisz wprowadzać żadnych zmian w kodzie aplikacji dla tych zdarzeń i metryk.
Kroki konfigurowania dostrajania wydajności dla systemu danych big data są następujące:
W witrynie Azure Portal utwórz obszar roboczy usługi Azure Databricks. Skopiuj i zapisz identyfikator subskrypcji platformy Azure (identyfikator GUID), nazwę grupy zasobów, nazwę obszaru roboczego usługi Databricks i adres URL portalu obszaru roboczego do późniejszego użycia.
W przeglądarce internetowej przejdź do adresu URL obszaru roboczego usługi Databricks i wygeneruj osobisty token dostępu usługi Databricks. Skopiuj i zapisz wyświetlony ciąg tokenu (rozpoczynający się od
dapii 32-znakową wartość szesnastkową) do późniejszego użycia.Sklonuj repozytorium GitHub mspnp/spark-monitoring na komputerze lokalnym. To repozytorium zawiera kod źródłowy dla następujących składników:
- Szablon usługi Azure Resource Manager (ARM) do tworzenia obszaru roboczego usługi Azure Log Analytics, który instaluje również wstępnie utworzone zapytania dotyczące zbierania metryk platformy Spark
- Biblioteki monitorowania usługi Azure Databricks
- Przykładowa aplikacja do wysyłania metryk aplikacji i dzienników aplikacji z usługi Azure Databricks do usługi Azure Monitor
Za pomocą polecenia interfejsu wiersza polecenia platformy Azure do wdrażania szablonu usługi ARM utwórz obszar roboczy usługi Azure Log Analytics z wstępnie utworzonymi zapytaniami metryk platformy Spark. Z danych wyjściowych polecenia skopiuj i zapisz wygenerowaną nazwę nowego obszaru roboczego usługi Log Analytics (w formacie spark-monitoring-randomized-string><).
W witrynie Azure Portal skopiuj i zapisz identyfikator i klucz obszaru roboczego usługi Log Analytics do późniejszego użycia.
Zainstaluj środowisko IntelliJ IDEA w wersji Community Edition, zintegrowane środowisko projektowe (IDE), które ma wbudowaną obsługę zestawów Java Development Kit (JDK) i Apache Maven. Dodaj wtyczkę Scala.
Za pomocą środowiska IntelliJ IDEA skompiluj biblioteki monitorowania usługi Azure Databricks. Aby wykonać rzeczywisty krok kompilacji, wybierz pozycję Wyświetl>narzędzie Windows>Maven, aby wyświetlić okno narzędzi Maven, a następnie wybierz pozycję Wykonaj pakiet mvn celu>maven.
Za pomocą narzędzia instalacyjnego pakietu języka Python zainstaluj interfejs wiersza polecenia usługi Azure Databricks i skonfiguruj uwierzytelnianie przy użyciu skopiowanego wcześniej osobistego tokenu dostępu usługi Databricks.
Skonfiguruj obszar roboczy usługi Azure Databricks, modyfikując skrypt inicjowania usługi Databricks przy użyciu skopiowanych wcześniej wartości usługi Databricks i Log Analytics, a następnie za pomocą interfejsu wiersza polecenia usługi Azure Databricks skopiuj skrypt inicjowania i biblioteki monitorowania usługi Azure Databricks do obszaru roboczego usługi Databricks.
W portalu obszaru roboczego usługi Databricks utwórz i skonfiguruj klaster usługi Azure Databricks.
W środowisku IntelliJ IDEA skompiluj przykładową aplikację przy użyciu narzędzia Maven. Następnie w portalu obszaru roboczego usługi Databricks uruchom przykładową aplikację, aby wygenerować przykładowe dzienniki i metryki dla usługi Azure Monitor.
Gdy przykładowe zadanie jest uruchomione w usłudze Azure Databricks, przejdź do witryny Azure Portal, aby wyświetlić typy zdarzeń (dzienniki aplikacji i metryki) w interfejsie usługi Log Analytics:
- Wybierz pozycję Dzienniki niestandardowe tabel,>aby wyświetlić schemat tabeli dla zdarzeń odbiornika platformy Spark (SparkListenerEvent_CL), zdarzeń rejestrowania platformy Spark (SparkLoggingEvent_CL) i metryk platformy Spark (SparkMetric_CL).
- Wybierz pozycję Eksplorator>zapytań Zapisane zapytania>Metryki platformy Spark, aby wyświetlić i uruchomić zapytania dodane podczas tworzenia obszaru roboczego usługi Log Analytics.
Przeczytaj więcej na temat wyświetlania i uruchamiania wstępnie utworzonych i niestandardowych zapytań w następnej sekcji.
Wykonywanie zapytań dotyczących dzienników i metryk w usłudze Azure Log Analytics
Uzyskiwanie dostępu do wstępnie utworzonych zapytań
Poniżej wymieniono wstępnie utworzone nazwy zapytań na potrzeby pobierania metryk platformy Spark.
- % czasu procesora CPU na funkcję wykonawcza
- % deserializacji czasu na funkcję wykonawcczą
- % czasu JVM na wykonawcę
- % serializowania czasu na funkcję wykonawcza
- Rozlane bajty dysku
- Ślady błędów (zły rekord lub nieprawidłowe pliki)
- Bajty odczytu na funkcję wykonawcza systemu plików
- Bajty zapisu w systemie plików na funkcję wykonawczą
- Błędy zadań na zadanie
- Opóźnienie zadania na zadanie (czas trwania wsadu)
- Przepływność zadania
- Uruchamianie funkcji wykonawczych
- Odczytywanie przetasów bajtów
- Przetasuj bajty odczytu na funkcję wykonawcza
- Przetasuj bajty odczytane na dysk na funkcję wykonawcza
- Pamięć bezpośrednia klienta shuffle
- Shuffle Client Memory Per Executor
- Przetaczanie bajtów dysku rozlanych na funkcję wykonawcza
- Shuffle Heap Memory Per Executor
- Przetaczanie bajtów pamięci rozlanych na funkcję wykonawcza
- Opóźnienie etapu na etap (czas trwania etapu)
- Przepływność etapu na etap
- Błędy przesyłania strumieniowego na strumień
- Opóźnienie przesyłania strumieniowego na strumień
- Wiersze wejściowe przepływności przesyłania strumieniowego na sekundę
- Przepływność przesyłania strumieniowego przetworzonych wierszy/s
- Sumowanie wykonywania zadań na hosta
- Czas deserializacji zadania
- Błędy zadań na etap
- Czas obliczeniowy funkcji wykonawczej zadania (czas niesymetryczności danych)
- Odczytane bajty wejściowe zadania
- Opóźnienie zadania na etap (czas trwania zadań)
- Czas serializacji wyników zadania
- Opóźnienie opóźnienia harmonogramu zadań
- Odczytane bajty zadania
- Przetasuj bajty zadania
- Czas odczytu zadania
- Czas zapisu w czasie mieszania zadań
- Przepływność zadania (suma zadań na etap)
- Zadania na wykonawcę (suma zadań na wykonawcę)
- Zadania na etap
Pisanie zapytań niestandardowych
Możesz również napisać własne zapytania w język zapytań Kusto (KQL). Wystarczy wybrać górne środkowe okienko, które można edytować, i dostosować zapytanie w celu spełnienia Twoich potrzeb.
Następujące dwa zapytania ściągają dane ze zdarzeń rejestrowania platformy Spark:
SparkLoggingEvent_CL | where logger_name_s contains "com.microsoft.pnp"
SparkLoggingEvent_CL
| where TimeGenerated > ago(7d)
| project TimeGenerated, clusterName_s, logger_name_s
| summarize Count=count() by clusterName_s, logger_name_s, bin(TimeGenerated, 1h)
Te dwa przykłady to zapytania w dzienniku metryk platformy Spark:
SparkMetric_CL
| where name_s contains "executor.cpuTime"
| extend sname = split(name_s, ".")
| extend executor=strcat(sname[0], ".", sname[1])
| project TimeGenerated, cpuTime=count_d / 100000
SparkMetric_CL
| where name_s contains "driver.jvm.total."
| where executorId_s == "driver"
| extend memUsed_GB = value_d / 1000000000
| project TimeGenerated, name_s, memUsed_GB
| summarize max(memUsed_GB) by tostring(name_s), bin(TimeGenerated, 1m)
Terminologia dotycząca zapytań
W poniższej tabeli opisano niektóre terminy, które są używane podczas tworzenia zapytania dotyczącego dzienników i metryk aplikacji.
| Termin | ID | Uwagi |
|---|---|---|
| Cluster_init | Application ID | |
| Queue | Identyfikator przebiegu | Jeden identyfikator przebiegu jest równy wielu partii. |
| Batch | Identyfikator partii | Jedna partia równa się dwóm zadniom. |
| Zadanie | Identyfikator stanowiska | Jedno zadanie jest równe dwa etapy. |
| Etap | Identyfikator etapu | Jeden etap ma 100–200 identyfikatorów zadań w zależności od zadania (odczyt, shuffle lub zapis). |
| Zadania | Identyfikator zadania | Jedno zadanie jest przypisywane do jednego wykonawcy. Jedno zadanie jest przydzielone do wykonania partitionBy dla jednej partycji. W przypadku około 200 klientów powinno istnieć 200 zadań. |
Poniższe sekcje zawierają typowe metryki używane w tym scenariuszu do monitorowania przepływności systemu, stanu uruchomienia zadania platformy Spark i użycia zasobów systemowych.
Przepływność systemu
| Nazwisko | Miara | Jednostki |
|---|---|---|
| Przepływność strumienia | Średnia szybkość danych wejściowych w średniej szybkości przetwarzania na minutę | Wiersze na minutę |
| Czas trwania zadania | Średni czas trwania zakończonego zadania platformy Spark na minutę | Czasy trwania na minutę |
| Liczba zadań | Średnia liczba zakończonych zadań platformy Spark na minutę | Liczba zadań na minutę |
| Czas trwania etapu | Średni czas trwania ukończonych etapów na minutę | Czasy trwania na minutę |
| Liczba etapów | Średnia liczba ukończonych etapów na minutę | Liczba etapów na minutę |
| Czas trwania zadania | Średni czas trwania zakończonych zadań na minutę | Czasy trwania na minutę |
| Liczba zadań | Średnia liczba ukończonych zadań na minutę | Liczba zadań na minutę |
Stan uruchomienia zadania platformy Spark
| Nazwisko | Miara | Jednostki |
|---|---|---|
| Liczba puli harmonogramu | Liczba unikatowych pul harmonogramu na minutę (liczba kolejek działających) | Liczba pul harmonogramu |
| Liczba uruchomionych funkcji wykonawczych | Liczba uruchomionych funkcji wykonawczych na minutę | Liczba uruchomionych funkcji wykonawczych |
| Ślad błędu | Wszystkie dzienniki błędów z Error poziomem i odpowiadającymi im zadaniami/identyfikatorem etapu (pokazanym w programie thread_name_s) |
Użycie zasobów systemowych
| Nazwisko | Miara | Jednostki |
|---|---|---|
| Średnie użycie procesora CPU na funkcję wykonawcza/ogólną | Procent użycia procesora CPU na funkcję wykonawcza na minutę | % na minutę |
| Średnia używana pamięć bezpośrednia (MB) na hosta | Średnia używana pamięć bezpośrednia na moduły wykonawcze na minutę | MB na minutę |
| Rozlana pamięć na hosta | Średnia ilość rozlanej pamięci na funkcję wykonawcza | MB na minutę |
| Monitorowanie wpływu niesymetryczności danych na czas trwania | Zakres miar i różnica między 70. 90. percentylem a 90. 100. percentylem w czasie trwania zadań | Różnica netto między 100%, 90% i 70%; różnica procentowa między 100%, 90% i 70% |
Zdecyduj, jak powiązać dane wejściowe klienta, które zostały połączone z plikiem archiwum GZIP, do określonego pliku wyjściowego usługi Azure Databricks, ponieważ usługa Azure Databricks obsługuje całą operację wsadową jako jednostkę. W tym miejscu stosujesz stopień szczegółowości do śledzenia. Metryki niestandardowe służą również do śledzenia jednego pliku wyjściowego do oryginalnego pliku wejściowego.
Aby uzyskać bardziej szczegółowe definicje każdej metryki, zobacz Wizualizacje na pulpitach nawigacyjnych w tej witrynie internetowej lub zobacz sekcję Metryki w dokumentacji platformy Apache Spark.
Ocena opcji dostrajania wydajności
Definicja punktu odniesienia
Ty i Twój zespół programistyczny powinni ustanowić punkt odniesienia, aby można było porównać przyszłe stany aplikacji.
Mierzenie wydajności aplikacji ilościowo. W tym scenariuszu kluczowa metryka to opóźnienie zadania, które jest typowe dla większości przetwarzania wstępnego i pozyskiwania danych. Spróbuj przyspieszyć czas przetwarzania danych i skupić się na mierzeniu opóźnienia, jak na poniższym wykresie:
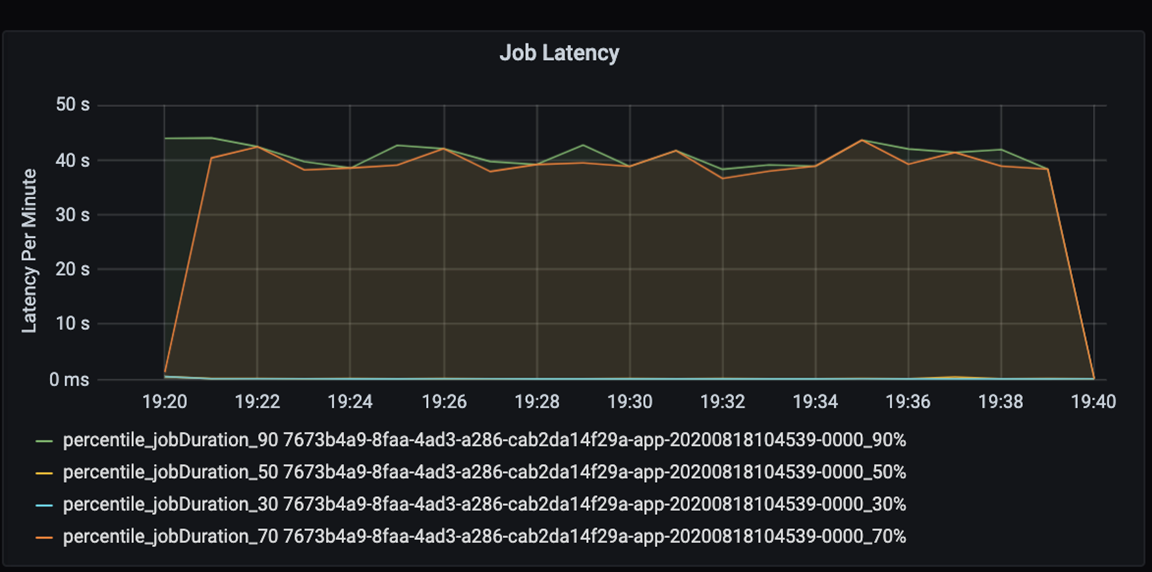
Mierzenie opóźnienia wykonywania zadania: grubszy widok na ogólną wydajność zadania oraz czas trwania wykonywania zadania od początku do ukończenia (czas mikrobajtu). Na powyższym wykresie na znaczniku 19:30 czas trwania zadania trwa około 40 sekund.
Jeśli przyjrzysz się bliżej tym 40 sekundom, zobaczysz poniższe dane dla etapów:
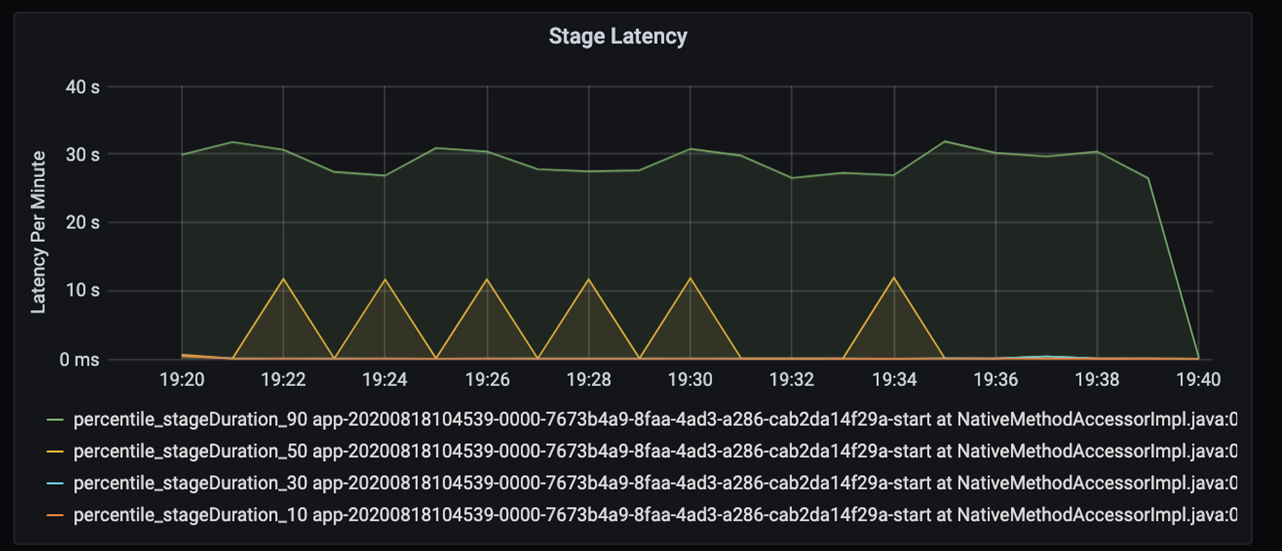
Na znaku 19:30 istnieją dwa etapy: pomarańczowy etap 10 sekund i zielony etap na 30 sekund. Monitoruj, czy skoki etapu, ponieważ skok wskazuje opóźnienie na etapie.
Zbadaj, kiedy określony etap działa powoli. W scenariuszu partycjonowania zazwyczaj istnieją co najmniej dwa etapy: jeden etap odczytu pliku, a drugi etap mieszania, partycjonowania i zapisywania pliku. Jeśli na etapie pisania występuje duże opóźnienie, może wystąpić problem z wąskim gardłem podczas partycjonowania.
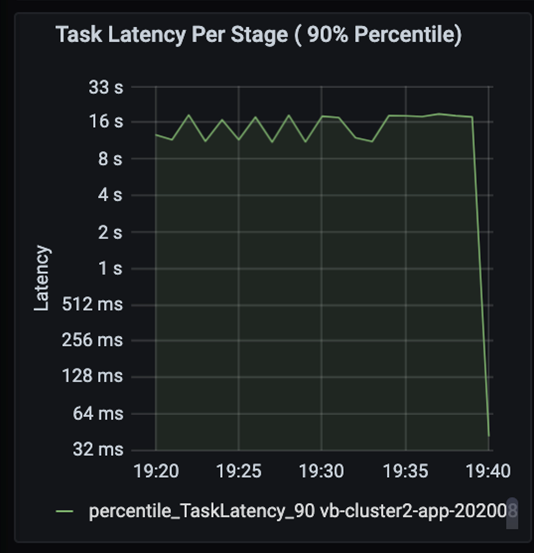
Obserwuj zadania jako etapy w zadaniu wykonywane sekwencyjnie, a wcześniejsze etapy blokują późniejsze etapy. W ramach etapu, jeśli jedno zadanie wykonuje partycję mieszania wolniej niż inne zadania, wszystkie zadania w klastrze muszą czekać na wolniejsze zadanie do zakończenia etapu. Zadania są następnie sposobem monitorowania niesymetryczności danych i możliwych wąskich gardeł. Na powyższym wykresie widać, że wszystkie zadania są równomiernie rozproszone.
Teraz monitoruj czas przetwarzania. Ponieważ masz scenariusz przesyłania strumieniowego, przyjrzyj się przepływności przesyłania strumieniowego.
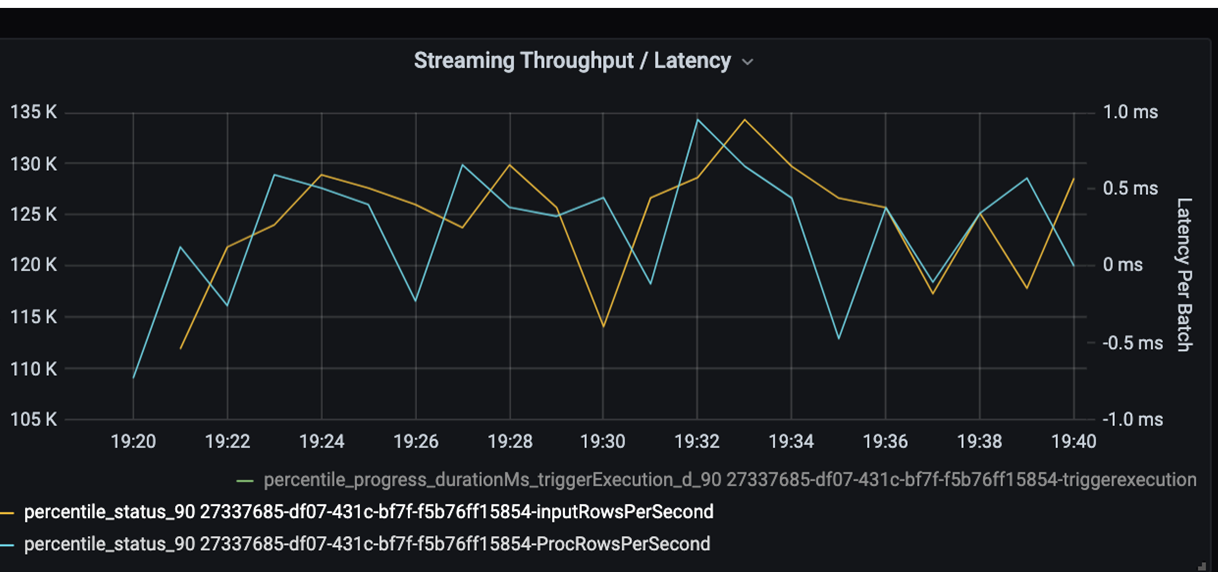
Na powyższym wykresie przepływności przesyłania strumieniowego/opóźnienia wsadowego pomarańczowa linia reprezentuje szybkość wprowadzania (wiersze wejściowe na sekundę). Niebieska linia reprezentuje szybkość przetwarzania (przetworzone wiersze na sekundę). W niektórych punktach szybkość przetwarzania nie przechwytuje szybkości wprowadzania. Potencjalny problem polega na tym, że pliki wejściowe są kumplowane w kolejce.
Ponieważ szybkość przetwarzania nie jest zgodna z szybkością wprowadzania na grafie, należy zwrócić uwagę na poprawę szybkości procesu w celu całkowitego pokrycia szybkości wprowadzania. Jedną z możliwych przyczyn może być nierównowaga danych klientów w każdym kluczu partycji, który prowadzi do wąskiego gardła. Aby uzyskać kolejny krok i potencjalne rozwiązanie, skorzystaj ze skalowalności usługi Azure Databricks.
Badanie partycjonowania
Najpierw zidentyfikuj poprawną liczbę funkcji wykonawczych skalowania potrzebnych w usłudze Azure Databricks. Zastosuj regułę przypisywania każdej partycji z dedykowanym procesorem CPU w uruchomionych funkcjach wykonawczych. Jeśli na przykład masz 200 kluczy partycji, liczba procesorów CPU pomnożona przez liczbę funkcji wykonawczych powinna wynosić 200. (Na przykład osiem procesorów w połączeniu z 25 funkcjami wykonawczych byłoby dobrym dopasowaniem). W przypadku 200 kluczy partycji każdy wykonawca może pracować tylko w jednym zadaniu, co zmniejsza prawdopodobieństwo wąskiego gardła.
Ponieważ w tym scenariuszu występują pewne powolne partycje, należy zbadać wysoką wariancję w czasie trwania zadań. Sprawdź, czy występują skoki czasu trwania zadania. Jedno zadanie obsługuje jedną partycję. Jeśli zadanie wymaga więcej czasu, partycja może być zbyt duża i powodować wąskie gardło.
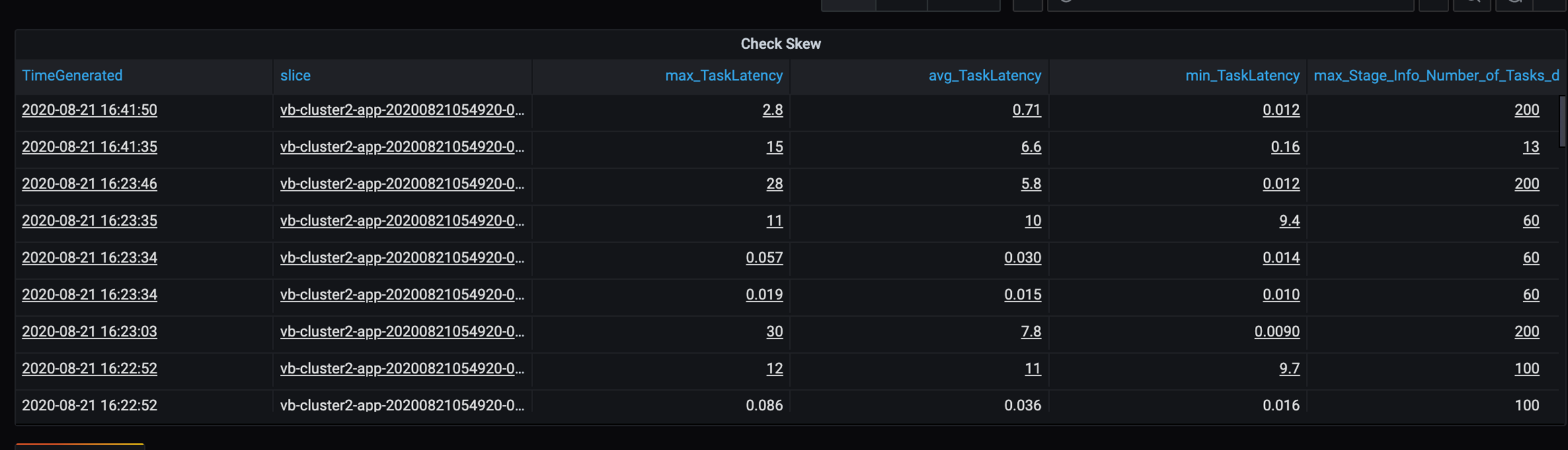
Śledzenie błędów
Dodaj pulpit nawigacyjny do śledzenia błędów, aby można było wykryć błędy danych specyficznych dla klienta. W przypadku przetwarzania wstępnego danych istnieją czasy, w których pliki są uszkodzone, a rekordy w pliku nie są zgodne ze schematem danych. Poniższy pulpit nawigacyjny przechwytuje wiele nieprawidłowych plików i nieprawidłowych rekordów.
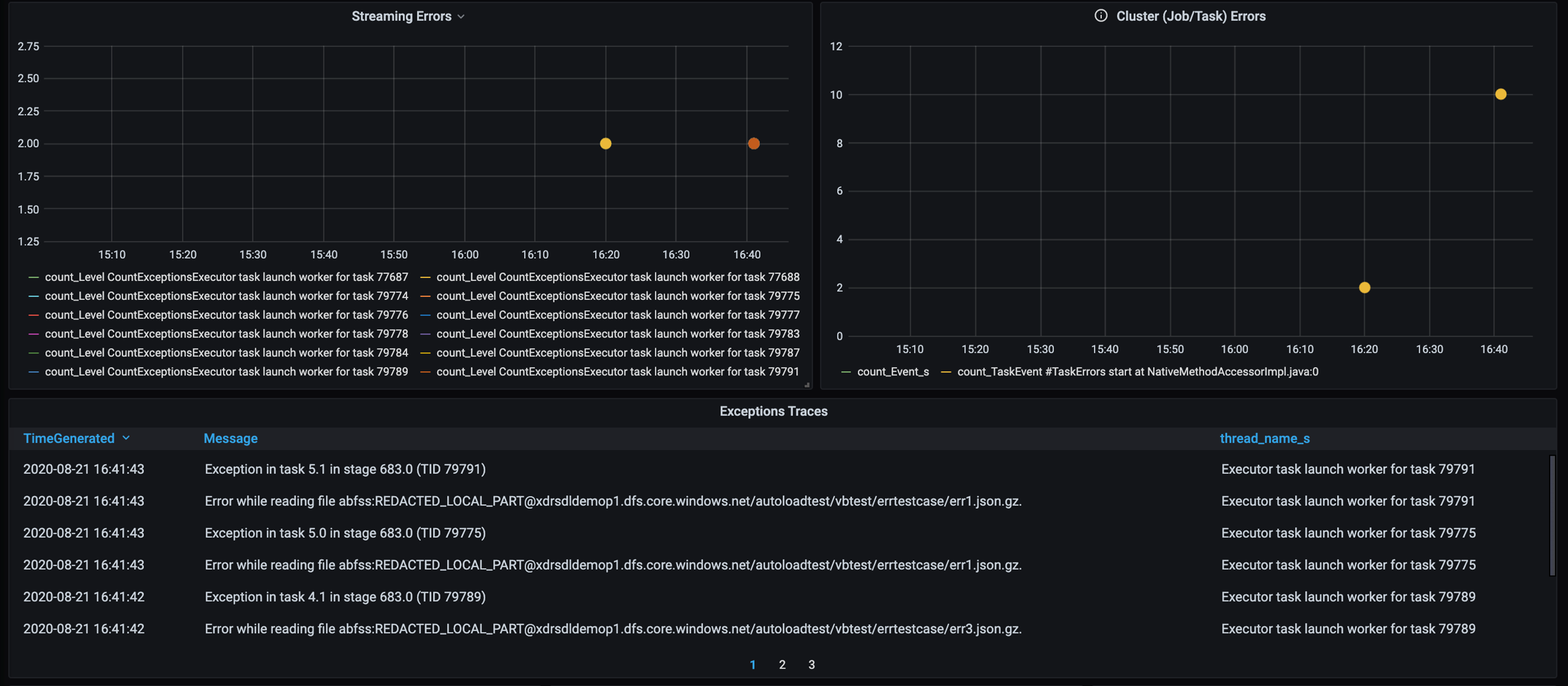
Ten pulpit nawigacyjny wyświetla liczbę błędów, komunikat o błędzie i identyfikator zadania na potrzeby debugowania. W komunikacie można łatwo prześledzić błąd z powrotem do pliku błędu. Podczas odczytywania występuje kilka plików. Przejrzyj górną oś czasu i zbadasz konkretne punkty na wykresie (16:20 i 16:40).
Inne wąskie gardła
Aby uzyskać więcej przykładów i wskazówek, zobacz Rozwiązywanie problemów z wąskimi gardłami wydajności w usłudze Azure Databricks.
Podsumowanie oceny dostrajania wydajności
W tym scenariuszu te metryki zidentyfikowały następujące obserwacje:
- Na wykresie opóźnienia etapu pisanie etapów zajmuje większość czasu przetwarzania.
- Na wykresie opóźnienia zadania opóźnienie zadania jest stabilne.
- Na wykresie przepływności przesyłania strumieniowego szybkość danych wyjściowych jest niższa niż szybkość wprowadzania w niektórych punktach.
- W tabeli czasu trwania zadania występuje wariancja zadań z powodu braku równowagi danych klientów.
- Aby uzyskać zoptymalizowaną wydajność na etapie partycjonowania, liczba funkcji wykonawczych skalowania powinna być zgodna z liczbą partycji.
- Istnieją błędy śledzenia, takie jak nieprawidłowe pliki i nieprawidłowe rekordy.
Aby zdiagnozować te problemy, użyto następujących metryk:
- Opóźnienie zadania
- Opóźnienie etapu
- Opóźnienie zadania
- Przepływność przesyłania strumieniowego
- Czas trwania zadania (maksymalny, średni, min) na etap
- Śledzenie błędów (liczba, komunikat, identyfikator zadania)
Współautorzy
Ten artykuł jest obsługiwany przez firmę Microsoft. Pierwotnie został napisany przez następujących współautorów.
Główny autor:
- David McGhee | Główny menedżer programu
Aby wyświetlić niepubalne profile serwisu LinkedIn, zaloguj się do serwisu LinkedIn.
Następne kroki
- Przeczytaj samouczek usługi Log Analytics.
- Monitorowanie usługi Azure Databricks w obszarze roboczym usługi Azure Log Analytics
- Wdrażanie usługi Azure Log Analytics przy użyciu metryk platformy Spark
- Wzorce obserwacji