W tym artykule opisano alternatywne podejście do projektów magazynu danych nazywanych eksploracyjnymi analizami danych (EDA). Takie podejście może zmniejszyć wyzwania związane z operacjami wyodrębniania, przekształcania, ładowania (ETL). Koncentruje się najpierw na generowaniu szczegółowych informacji biznesowych, a następnie zwraca się do rozwiązywania zadań modelowania i ETL.
Architektura

Pobierz plik programu Visio z tą architekturą.
W przypadku EDA interesuje Cię tylko prawa strona diagramu. Usługa Azure Synapse SQL Serverless jest używana jako aparat obliczeniowy w plikach data lake.
Aby osiągnąć EDA:
- Zapytania T-SQL są uruchamiane bezpośrednio w usłudze Azure Synapse SQL serverless lub Azure Synapse Spark.
- Zapytania są uruchamiane z graficznego narzędzia do wykonywania zapytań, takiego jak Power BI lub Azure Data Studio.
Zalecamy utrwalanie wszystkich danych lakehouse przy użyciu parquet lub delta.
Lewą stronę diagramu (pozyskiwanie danych) można zaimplementować przy użyciu dowolnego narzędzia wyodrębniania, ładowania, przekształcania (ELT). Nie ma to wpływu na EDA.
Elementy
Usługa Azure Synapse Analytics łączy integrację danych, magazynowanie danych przedsiębiorstwa i analizę danych big data za pośrednictwem danych lakehouse. W tym rozwiązaniu:
- Obszar roboczy usługi Azure Synapse promuje współpracę między inżynierami danych, analitykami danych, analitykami danych i specjalistami ds. analizy biznesowej (BI) na potrzeby zadań EDA.
- Bezserwerowe pule SQL usługi Azure Synapse analizują dane bez struktury i częściowo ustrukturyzowane w usłudze Azure Data Lake Storage przy użyciu standardowego języka T-SQL.
- Bezserwerowe pule platformy Apache Spark w usłudze Azure Synapse wykonują eksplorację typu code-first w usłudze Data Lake Storage przy użyciu języków spark, takich jak Spark SQL, PySpark i Scala.
Usługa Azure Data Lake Storage udostępnia magazyn danych, które są następnie analizowane przez bezserwerowe pule SQL usługi Azure Synapse.
Usługa Azure Machine Edukacja udostępnia dane usłudze Azure Synapse Spark.
Usługa Power BI jest używana w tym rozwiązaniu do wykonywania zapytań dotyczących danych w celu wykonania analizy EDA.
Alternatywy
Możesz zastąpić lub uzupełnić pule bezserwerowe usługi Synapse SQL usługą Azure Databricks.
Zamiast używać modelu typu lakehouse z pulami bezserwerowymi usługi Synapse SQL, możesz użyć dedykowanych pul SQL usługi Azure Synapse do przechowywania danych przedsiębiorstwa. Zapoznaj się z przypadkami użycia i zagadnieniami w tym artykule i powiązanymi zasobami, aby zdecydować, która technologia ma być używana.
Szczegóły scenariusza
To rozwiązanie przedstawia implementację podejścia EDA do projektów magazynu danych. Takie podejście może zmniejszyć wyzwania związane z operacjami ETL. Koncentruje się najpierw na generowaniu szczegółowych informacji biznesowych, a następnie zwraca się do rozwiązywania zadań modelowania i ETL.
Potencjalne przypadki użycia
Inne scenariusze, które mogą korzystać z tego wzorca analitycznego:
Analiza preskrypcyjna. Zadaj pytania dotyczące Twoich danych, takich jak Następna najlepsza akcja lub co robimy dalej? Użyj danych, aby być bardziej oparte na danych i mniej oparte na jelitach. Dane mogą być nieustrukturyzowane i pochodzące z wielu źródeł zewnętrznych o różnej jakości. Możesz chcieć użyć danych tak szybko, jak to możliwe, aby ocenić strategię biznesową bez faktycznego ładowania danych do magazynu danych. Dane można usunąć po udzieleniu odpowiedzi na pytania.
Samoobsługowe etL. Wykonaj operacje ETL/ELT podczas wykonywania działań piaskownicy danych (EDA). Przekształć dane i uczynić je cennymi. Może to poprawić skalę deweloperów ETL.
Informacje o eksploracyjnej analizie danych
Zanim przyjrzymy się bliżej sposobie działania EDA, warto podsumować tradycyjne podejście do projektów magazynu danych. Tradycyjne podejście wygląda następująco:
Wymagania dotyczące zbierania. Dokumentowanie, co należy zrobić z danymi.
Modelowanie danych. Określanie sposobu modelowania danych liczbowych i atrybutów na tabele faktów i wymiarów. Tradycyjnie ten krok należy wykonać przed uzyskaniem nowych danych.
ETL. Uzyskaj dane i przemasuj je do modelu danych magazynu danych.
Te kroki mogą potrwać tygodnie, a nawet miesiące. Dopiero wtedy można rozpocząć wykonywanie zapytań o dane i rozwiązywanie problemu biznesowego. Użytkownik widzi wartość tylko po utworzeniu raportów. Architektura rozwiązania zwykle wygląda mniej więcej tak:
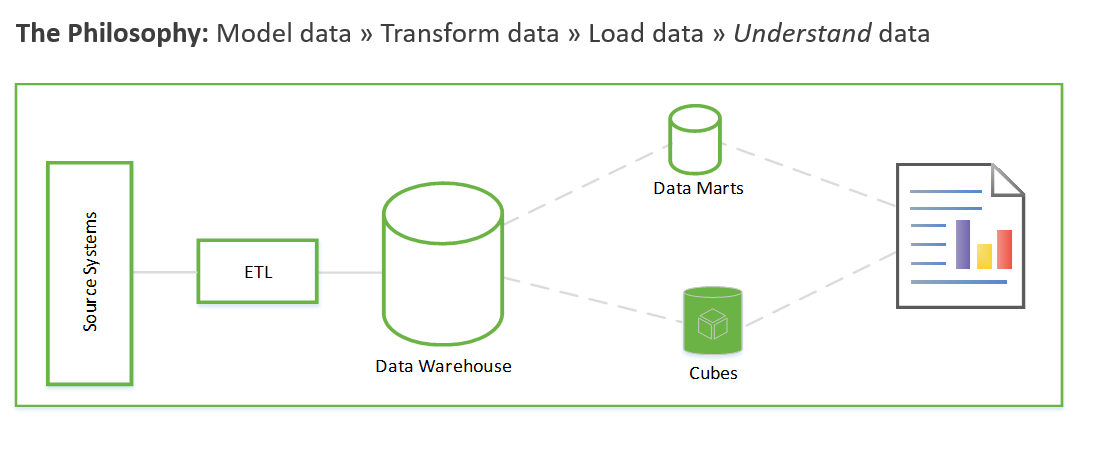
Można to zrobić w inny sposób, który koncentruje się najpierw na generowaniu szczegółowych informacji biznesowych, a następnie zwraca się do rozwiązywania zadań modelowania i ETL. Proces jest podobny do procesów nauki o danych. Wygląda to mniej więcej tak:
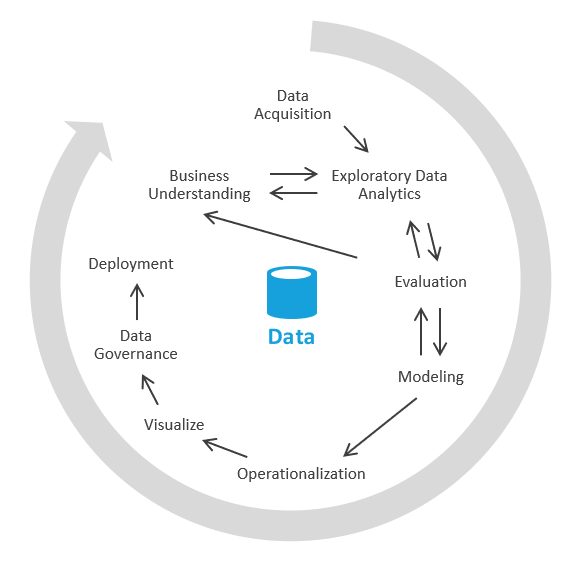
W branży ten proces jest nazywany EDA lub eksploracyjnymi analizami danych.
Oto konkretne kroki:
Pozyskiwanie danych. Najpierw należy określić źródła danych, które należy pozyskać do usługi Data Lake/piaskownicy. Następnie musisz przenieść te dane do obszaru lądowania jeziora. Platforma Azure udostępnia narzędzia, takie jak Azure Data Factory i Azure Logic Apps, które mogą szybko pozyskiwać dane.
Piaskownica danych. Początkowo analityk biznesowy i inżynier, który jest wykwalifikowany w eksploracyjnej analizie danych za pośrednictwem usługi Azure Synapse Analytics bezserwerowej lub podstawowej współpracy z bazą danych SQL. W tej fazie próbują odkryć szczegółowe informacje biznesowe przy użyciu nowych danych. EDA to proces iteracyjny. Może być konieczne pozyskiwanie większej ilości danych, rozmowa z MŚP, zadawanie dodatkowych pytań lub generowanie wizualizacji.
Ocena Po znalezieniu szczegółowych informacji biznesowych należy ocenić, co zrobić z danymi. Możesz chcieć zachować dane w magazynie danych (aby przejść do fazy modelowania). W innych przypadkach możesz zdecydować się na przechowywanie danych w usłudze Data Lake/Lakehouse i używanie ich do analizy predykcyjnej (algorytmy uczenia maszynowego). W innych przypadkach możesz zdecydować się na wypełnienie systemów rekordów nowymi szczegółowymi informacjami. Na podstawie tych decyzji możesz lepiej zrozumieć, co należy zrobić dalej. Może nie być konieczne wykonywanie operacji ETL.
Te metody są podstawą prawdziwej samoobsługowej analizy. Korzystając z usługi Data Lake i narzędzia do wykonywania zapytań, takiego jak bezserwerowa usługa Azure Synapse, która rozumie wzorce zapytań typu data lake, możesz umieścić zasoby danych w rękach osób biznesowych, które rozumieją modicum języka SQL. Możesz radykalnie skrócić czas do wartości przy użyciu tej metody i usunąć niektóre ryzyko związane z inicjatywami dotyczącymi danych firmowych.
Kwestie wymagające rozważenia
Te zagadnienia implementują filary struktury Azure Well-Architected Framework, która jest zestawem wytycznych, które mogą służyć do poprawy jakości obciążenia. Aby uzyskać więcej informacji, zobacz Microsoft Azure Well-Architected Framework.
Dostępność
Pule bezserwerowe usługi Azure Synapse SQL to funkcja typu platforma jako usługa (PaaS), która może spełniać wymagania dotyczące wysokiej dostępności i odzyskiwania po awarii (DR).
Pule bezserwerowe są dostępne na żądanie. Nie wymagają skalowania w górę, w dół ani w dół ani administracji jakiegokolwiek rodzaju. Używają modelu płatności za zapytanie, więc w dowolnym momencie nie ma nieużywanej pojemności. Pule bezserwerowe idealnie nadają się do:
- Ad hoc eksploracji nauki o danych w języku T-SQL.
- Wczesne tworzenie prototypów dla jednostek magazynu danych.
- Definiowanie widoków, których użytkownicy mogą używać, na przykład w usłudze Power BI, w scenariuszach, które mogą tolerować opóźnienie wydajności.
- Eksploracyjna analiza danych.
Operations
Usługa Synapse SQL serverless używa standardowego języka T-SQL do wykonywania zapytań i operacji. Jako narzędzie T-SQL można użyć interfejsu użytkownika obszaru roboczego usługi Synapse, programu Azure Data Studio lub programu SQL Server Management Studio.
Optymalizacja kosztów
Optymalizacja kosztów dotyczy sposobów zmniejszenia niepotrzebnych wydatków i poprawy wydajności operacyjnej. Aby uzyskać więcej informacji, zobacz Omówienie filaru optymalizacji kosztów.
Cennik usługi Data Lake Storage zależy od ilości przechowywanych danych i częstotliwości używania danych. Przykładowe ceny obejmują jeden TB przechowywanych danych z kolejnymi założeniami transakcyjnymi. Jeden TB odnosi się do rozmiaru magazynu data lake, a nie rozmiaru oryginalnej starszej bazy danych.
Pula platformy Azure Synapse Spark opiera się na cenach dotyczących rozmiaru węzła, liczby wystąpień i czasu pracy. W tym przykładzie przyjęto założenie, że jeden mały węzeł obliczeniowy z wykorzystaniem między pięcioma godzinami w tygodniu i 40 godzin miesięcznie.
Bezserwerowa pula SQL usługi Azure Synapse opiera się na cenach przetworzonych danych. W przykładzie przyjęto założenie, że na miesiąc przetwarzane jest 50 KB. Ten rysunek odnosi się do rozmiaru magazynu data lake, a nie rozmiaru oryginalnej starszej bazy danych.
Współautorzy
Ten artykuł jest aktualizowany i obsługiwany przez firmę Microsoft. Pierwotnie został napisany przez następujących współautorów.
Autorzy zabezpieczeń:
- Dave Wentzel | Główny architekt techniczny MTC
Następne kroki
- ścieżki szkoleniowe inżynierowie danych
- Samouczek: rozpoczynanie pracy z usługą Azure Synapse Analytics
- Tworzenie pojedynczej bazy danych — Azure SQL Database
- Architektura usługi Azure Synapse SQL
- Tworzenie konta magazynu dla usługi Azure Data Lake Storage
- Przewodnik Szybki start dotyczący usługi Azure Event Hubs — tworzenie centrum zdarzeń przy użyciu witryny Azure Portal
- Szybki start — tworzenie zadania usługi Stream Analytics przy użyciu witryny Azure Portal
- Szybki start: rozpoczynanie pracy z usługą Azure Machine Edukacja