Tworzenie aplikacji Kubernetes dla usługi Azure SQL Database
Dotyczy:![]() Azure SQL Database
Azure SQL Database
Z tego samouczka dowiesz się, jak opracować nowoczesną aplikację przy użyciu języka Python, kontenerów platformy Docker, platformy Kubernetes i usługi Azure SQL Database.
Nowoczesne tworzenie aplikacji ma kilka wyzwań. Od wybrania "stosu" frontonu za pośrednictwem magazynu danych i przetwarzania z kilku konkurencyjnych standardów, zapewniając najwyższy poziom zabezpieczeń i wydajności, deweloperzy są zobowiązani do zapewnienia skalowania aplikacji i zapewniania ich prawidłowego działania i obsługi na wielu platformach. W przypadku tego ostatniego wymagania łączenie aplikacji z technologiami kontenerów, takimi jak Platforma Docker i wdrażanie wielu kontenerów na platformie Kubernetes, jest teraz derigueur w tworzeniu aplikacji.
W tym przykładzie eksplorujemy użycie języka Python, kontenerów platformy Docker i platformy Kubernetes — wszystkie uruchomione na platformie Microsoft Azure. Korzystanie z platformy Kubernetes oznacza, że masz również elastyczność korzystania ze środowisk lokalnych lub nawet innych chmur w celu bezproblemowego i spójnego wdrażania aplikacji oraz umożliwia wdrażanie aplikacji w wielu chmurach w celu uzyskania jeszcze większej odporności. Użyjemy również usługi Microsoft Azure SQL Database na potrzeby skalowalnego, wysoce odpornego i bezpiecznego środowiska do przechowywania i przetwarzania danych. W wielu przypadkach inne aplikacje często używają już usługi Microsoft Azure SQL Database, a ta przykładowa aplikacja może służyć do dalszego używania i wzbogacania tych danych.
Ten przykład jest dość kompleksowy w zakresie, ale używa najprostszej aplikacji, bazy danych i wdrożenia w celu zilustrowania procesu. Możesz dostosować ten przykład, aby był znacznie bardziej niezawodny, nawet wykorzystując najnowsze technologie dla zwracanych danych. Jest to przydatne narzędzie szkoleniowe do tworzenia wzorca dla innych aplikacji.
Używanie przykładowej bazy danych Python, Docker Containers, Kubernetes i AdventureWorksLT
Firma AdventureWorks (fikcyjna) używa bazy danych, która przechowuje dane dotyczące sprzedaży i marketingu, produktów, klientów i produkcji. Zawiera również widoki i procedury składowane, które łączą informacje o produktach, takie jak nazwa produktu, kategoria, cena i krótki opis.
Zespół deweloperów AdventureWorks chce utworzyć weryfikację koncepcji (PoC), która zwraca dane z widoku w AdventureWorksLT bazie danych i udostępnia je jako interfejs API REST. Korzystając z tej weryfikacji koncepcji, zespół deweloperów utworzy bardziej skalowalną i wielochmurową aplikację gotową dla zespołu ds. sprzedaży. Wybrali platformę Microsoft Azure dla wszystkich aspektów wdrażania. W usłudze PoC są używane następujące elementy:
- Aplikacja w języku Python korzystająca z pakietu Platformy Flask na potrzeby bezgłowego wdrażania w Internecie.
- Kontenery platformy Docker na potrzeby izolacji kodu i środowiska przechowywane w prywatnym rejestrze, dzięki czemu cała firma może ponownie używać kontenerów aplikacji w przyszłych projektach, oszczędzając czas i pieniądze.
- Platforma Kubernetes ułatwia wdrażanie i skalowanie oraz pozwala uniknąć blokady platformy.
- Usługa Microsoft Azure SQL Database umożliwia wybór rozmiaru, wydajności, skalowania, automatycznego zarządzania i tworzenia kopii zapasowej, oprócz magazynu i przetwarzania danych relacyjnych na najwyższym poziomie zabezpieczeń.
W tym artykule wyjaśniono proces tworzenia całego projektu weryfikacji koncepcji. Ogólne kroki tworzenia aplikacji to:
- Konfigurowanie wymagań wstępnych
- Tworzenie aplikacji
- Tworzenie kontenera platformy Docker w celu wdrożenia aplikacji i testowania
- Tworzenie rejestru usługi Azure Container Service (ACS) i ładowanie kontenera do rejestru ACS
- Tworzenie środowiska usługi Azure Kubernetes Service (AKS)
- Wdrażanie kontenera aplikacji z rejestru ACS w usłudze AKS
- Testowanie aplikacji
- Czyszczenie
Wymagania wstępne
W tym artykule istnieje kilka wartości, które należy zastąpić. Upewnij się, że te wartości są stale zastępowane dla każdego kroku. Możesz otworzyć edytor tekstów i usunąć te wartości, aby ustawić poprawne wartości podczas pracy z projektem weryfikacji koncepcji:
ReplaceWith_AzureSubscriptionName: zastąp tę wartość nazwą posiadanej subskrypcji platformy Azure.ReplaceWith_PoCResourceGroupName: zastąp tę wartość nazwą grupy zasobów, którą chcesz utworzyć.ReplaceWith_AzureSQLDBServerName: zastąp tę wartość nazwą serwera logicznego usługi Azure SQL Database utworzonego przy użyciu witryny Azure Portal.ReplaceWith_AzureSQLDBSQLServerLoginName: zastąp tę wartość wartością nazwą użytkownika programu SQL Server utworzoną w witrynie Azure Portal.ReplaceWith_AzureSQLDBSQLServerLoginPassword: zastąp tę wartość wartością hasła użytkownika programu SQL Server utworzonego w witrynie Azure Portal.ReplaceWith_AzureSQLDBDatabaseName: zastąp tę wartość nazwą utworzonej bazy danych Azure SQL Database przy użyciu witryny Azure Portal.ReplaceWith_AzureContainerRegistryName: zastąp tę wartość nazwą usługi Azure Container Registry, którą chcesz utworzyć.ReplaceWith_AzureKubernetesServiceName: zastąp tę wartość nazwą usługi Azure Kubernetes Service, którą chcesz utworzyć.
Deweloperzy firmy AdventureWorks używają kombinacji systemów Windows, Linux i Apple do programowania, dlatego używają programu Visual Studio Code jako środowiska i narzędzia git do kontroli źródła, z których oba są uruchamiane międzyplatformowo.
W przypadku weryfikacji koncepcji zespół wymaga następujących wymagań wstępnych:
Python, pip i packages — zespół programistyczny wybiera język programowania Python jako standard dla tej aplikacji internetowej. Obecnie są one używane w wersji 3.9, ale dowolna wersja obsługująca wymagane pakiety poC jest akceptowalna.
- Język Python w wersji 3.9 można pobrać z witryny python.org.
Zespół korzysta z
pyodbcpakietu na potrzeby dostępu do bazy danych.- Pakiet pyodbc można zainstalować za pomocą poleceń pip.
- Może być również potrzebne oprogramowanie sterowników MICROSOFT ODBC, jeśli nie zostało jeszcze zainstalowane.
Zespół używa pakietu do kontrolowania
ConfigParseri ustawiania zmiennych konfiguracji.- Pakiet configparser można zainstalować za pomocą poleceń pip.
Zespół korzysta z pakietu Flask dla interfejsu internetowego dla aplikacji.
- Możesz zainstalować wersję języka Python biblioteki Platformy Flask.
Następnie zespół zainstalował narzędzie interfejsu wiersza polecenia platformy Azure, łatwo zidentyfikowane ze składnią
az. To wieloplatformowe narzędzie umożliwia użycie wiersza polecenia i skryptowego podejścia do weryfikacji koncepcji, dzięki czemu mogą powtarzać kroki w miarę wprowadzania zmian i ulepszeń.- Narzędzie interfejsu wiersza polecenia platformy Azure można pobrać i zainstalować.
Po skonfigurowaniu interfejsu wiersza polecenia platformy Azure zespół loguje się do subskrypcji platformy Azure i ustawia nazwę subskrypcji używaną dla weryfikacji koncepcji. Następnie upewnili się, że serwer usługi Azure SQL Database i baza danych są dostępne dla subskrypcji:
az login az account set --name "ReplaceWith_AzureSubscriptionName" az sql server list az sql db list ReplaceWith_AzureSQLDBDatabaseNameGrupa zasobów platformy Microsoft Azure to logiczny kontener, który zawiera powiązane zasoby dla rozwiązania platformy Azure. Ogólnie rzecz biorąc, zasoby, które współużytkują ten sam cykl życia, są dodawane do tej samej grupy zasobów, dzięki czemu można je łatwo wdrażać, aktualizować i usuwać jako grupę. Grupa zasobów przechowuje metadane dotyczące zasobów i można określić lokalizację dla grupy zasobów.
Grupy zasobów można tworzyć i zarządzać nimi przy użyciu witryny Azure Portal lub interfejsu wiersza polecenia platformy Azure. Mogą być one również używane do grupowania powiązanych zasobów dla aplikacji i dzielenia ich na grupy dla środowiska produkcyjnego i nieprodukcyjnego lub innej preferowanej struktury organizacyjnej.
W poniższym fragmencie kodu można zobaczyć
azpolecenie użyte do utworzenia grupy zasobów. W naszym przykładzie używamy regionu eastusplatformy Azure.az group create --name ReplaceWith_PoCResourceGroupName --location eastusZespół deweloperów tworzy bazę danych Azure SQL Database z zainstalowaną
AdventureWorksLTprzykładową bazą danych przy użyciu uwierzytelnionego logowania SQL.Firma AdventureWorks ustandaryzowała platformę systemu zarządzania relacyjnymi bazami danych programu Microsoft SQL Server, a zespół deweloperów chce używać usługi zarządzanej dla bazy danych, a nie instalować lokalnie. Dzięki usłudze Azure SQL Database ta usługa zarządzana może być całkowicie zgodna z kodem wszędzie tam, gdzie uruchamiają aparat programu SQL Server: lokalnie, w kontenerze, w systemie Linux lub Windows, a nawet w środowisku Internetu rzeczy (IoT).
Podczas tworzenia użyli portalu zarządzania Platformy Azure, aby ustawić zaporę dla aplikacji na lokalną maszynę deweloperzą i zmienili wartość domyślną widoczną tutaj, aby włączyć opcję Zezwalaj na wszystkie usługi platformy Azure, a także pobrali poświadczenia połączenia.
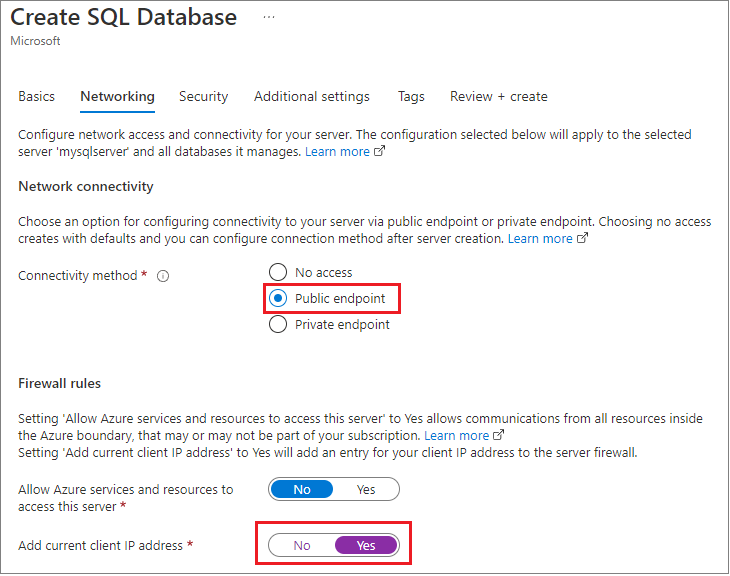
Dzięki temu podejściu baza danych może być dostępna w innym regionie, a nawet w innej subskrypcji.
Zespół skonfigurował logowanie uwierzytelnione w usłudze SQL na potrzeby testowania, ale ponownie podejmie tę decyzję w przeglądzie zabezpieczeń.
Zespół użył przykładowej
AdventureWorksLTbazy danych dla weryfikacji koncepcji przy użyciu tej samej grupy zasobów weryfikacji koncepcji. Nie martw się, na końcu tego samouczka wyczyścimy wszystkie zasoby w tej nowej grupie zasobów weryfikacji koncepcji.Aby wdrożyć usługę Azure SQL Database, możesz użyć witryny Azure Portal. Podczas tworzenia bazy danych Azure SQL Database na karcie Ustawienia dodatkowe dla opcji Użyj istniejących danych wybierz pozycję Przykład.

Na koniec na karcie Tagi nowej bazy danych Azure SQL Database zespół programistyczny dostarczył metadane tagów dla tego zasobu platformy Azure, takie jak Właściciel lub ServiceClass lub WorkloadName.

Tworzenie aplikacji
Następnie zespół deweloperów utworzył prostą aplikację w języku Python, która otwiera połączenie z usługą Azure SQL Database i zwraca listę produktów. Ten kod zostanie zastąpiony bardziej złożonymi funkcjami i może również obejmować więcej niż jedną aplikację wdrożona w zasobnikach Kubernetes w środowisku produkcyjnym w celu uzyskania niezawodnego, opartego na manifeście podejścia do rozwiązań aplikacji.
Zespół utworzył prosty plik tekstowy o nazwie
.envdo przechowywania zmiennych dla połączeń serwera i innych informacji.python-dotenvZa pomocą biblioteki mogą następnie oddzielić zmienne od kodu języka Python. Jest to typowe podejście do przechowywania wpisów tajnych i innych informacji z samego kodu.SQL_SERVER_ENDPOINT = ReplaceWith_AzureSQLDBServerName SQL_SERVER_USERNAME = ReplaceWith_AzureSQLDBSQLServerLoginName SQL_SERVER_PASSWORD = ReplaceWith_AzureSQLDBSQLServerLoginPassword SQL_SERVER_DATABASE = ReplaceWith_AzureSQLDBDatabaseNameUwaga
W celu uproszczenia i jasności ta aplikacja używa pliku konfiguracji odczytywanego z języka Python. Ponieważ kod zostanie wdrożony za pomocą kontenera, informacje o połączeniu mogą być w stanie pochodzić z zawartości. Należy dokładnie rozważyć różne metody pracy z zabezpieczeniami, połączeniami i wpisami tajnymi oraz określić najlepszy poziom i mechanizm, którego należy użyć dla naszej aplikacji. Zawsze wybieraj najwyższy poziom zabezpieczeń, a nawet wiele poziomów, aby zapewnić bezpieczeństwo aplikacji. Istnieje wiele opcji pracy z informacjami tajnymi, takimi jak parametry połączenia i podobne, a poniższa lista zawiera kilka z tych opcji.
Aby uzyskać więcej informacji, zobacz Zabezpieczenia usługi Azure SQL Database.
- Inną metodą pracy z wpisami tajnymi w języku Python jest użycie biblioteki python-secrets.
- Przejrzyj zabezpieczenia i wpisy tajne platformy Docker.
- Przejrzyj wpisy tajne platformy Kubernetes.
- Możesz również dowiedzieć się więcej na temat uwierzytelniania microsoft Entra (dawniej Azure Active Directory).
Następnie zespół napisał aplikację PoC i nazwał ją
app.py.Poniższy skrypt wykonuje następujące kroki:
- Skonfiguruj biblioteki dla konfiguracji i podstawowych interfejsów internetowych.
- Załaduj
.envzmienne z pliku. - Utwórz aplikację Flask-RESTful.
- Uzyskaj informacje o połączeniu z usługą
config.iniAzure SQL Database przy użyciu wartości pliku. - Utwórz połączenie z usługą
config.iniAzure SQL Database przy użyciu wartości plików. - Połączenie do usługi Azure SQL Database przy użyciu
pyodbcpakietu . - Utwórz zapytanie SQL do uruchomienia względem bazy danych.
- Utwórz klasę, która będzie używana do zwracania danych z interfejsu API.
- Ustaw punkt końcowy interfejsu API na klasę
Products. - Na koniec uruchom aplikację na domyślnym porcie platformy Flask 5000.
# Set up the libraries for the configuration and base web interfaces from dotenv import load_dotenv from flask import Flask from flask_restful import Resource, Api import pyodbc # Load the variables from the .env file load_dotenv() # Create the Flask-RESTful Application app = Flask(__name__) api = Api(app) # Get to Azure SQL Database connection information using the config.ini file values server_name = os.getenv('SQL_SERVER_ENDPOINT') database_name = os.getenv('SQL_SERVER_DATABASE') user_name = os.getenv('SQL_SERVER_USERNAME') password = os.getenv('SQL_SERVER_PASSWORD') # Create connection to Azure SQL Database using the config.ini file values ServerName = config.get('Connection', 'SQL_SERVER_ENDPOINT') DatabaseName = config.get('Connection', 'SQL_SERVER_DATABASE') UserName = config.get('Connection', 'SQL_SERVER_USERNAME') PasswordValue = config.get('Connection', 'SQL_SERVER_PASSWORD') # Connect to Azure SQL Database using the pyodbc package # Note: You may need to install the ODBC driver if it is not already there. You can find that at: # https://learn.microsoft.com/sql/connect/odbc/download-odbc-driver-for-sql-server connection = pyodbc.connect(f'Driver=ODBC Driver 17 for SQL Server;Server={ServerName};Database={DatabaseName};uid={UserName};pwd={PasswordValue}') # Create the SQL query to run against the database def query_db(): cursor = connection.cursor() cursor.execute("SELECT TOP (10) [ProductID], [Name], [Description] FROM [SalesLT].[vProductAndDescription] WHERE Culture = 'EN' FOR JSON AUTO;") result = cursor.fetchone() cursor.close() return result # Create the class that will be used to return the data from the API class Products(Resource): def get(self): result = query_db() json_result = {} if (result == None) else json.loads(result[0]) return json_result, 200 # Set the API endpoint to the Products class api.add_resource(Products, '/products') # Start App on default Flask port 5000 if __name__ == "__main__": app.run(debug=True)Sprawdzili, czy ta aplikacja działa lokalnie i zwraca stronę do
http://localhost:5000/products.
Ważne
Podczas tworzenia aplikacji produkcyjnych nie należy używać konta administratora do uzyskiwania dostępu do bazy danych. Aby uzyskać więcej informacji, przeczytaj więcej na temat konfigurowania konta dla aplikacji. Kod w tym artykule jest uproszczony, dzięki czemu można szybko rozpocząć pracę z aplikacjami przy użyciu języków Python i Kubernetes na platformie Azure.
Bardziej realistycznie można użyć użytkownika zawartej bazy danych z uprawnieniami tylko do odczytu lub logowania lub zawartej bazy danych połączonego z tożsamością zarządzaną przypisaną przez użytkownika z uprawnieniami tylko do odczytu.
Aby uzyskać więcej informacji, zapoznaj się z kompletnym przykładem tworzenia interfejsu API przy użyciu języka Python i usługi Azure SQL Database.

Wdrażanie aplikacji w kontenerze platformy Docker
Kontener to zarezerwowana, chroniona przestrzeń w systemie obliczeniowym, która zapewnia izolację i hermetyzację. Aby utworzyć kontener, użyj pliku manifestu, który jest po prostu plikiem tekstowym opisującym pliki binarne i kod, który chcesz zawierać. Za pomocą środowiska uruchomieniowego kontenera (takiego jak Platforma Docker) możesz utworzyć obraz binarny zawierający wszystkie pliki, które chcesz uruchomić i odwołać. W tym miejscu możesz "uruchomić" obraz binarny i jest nazywany kontenerem, do którego można się odwołać, jakby był to system pełnego przetwarzania. Jest to mniejszy, prostszy sposób abstrakcji środowiska i środowiska aplikacji niż używanie pełnej maszyny wirtualnej. Aby uzyskać więcej informacji, zobacz Kontenery i platforma Docker.
Zespół rozpoczął pracę z plikiem DockerFile (manifestem), który warstwuje elementy tego, czego chce użyć zespół. Zaczynają się od podstawowego obrazu języka Python, który ma pyodbc już zainstalowane biblioteki, a następnie uruchamiają wszystkie polecenia niezbędne do przechowywania pliku programu i konfiguracji w poprzednim kroku.
Następujący plik Dockerfile ma następujące kroki:
- Zacznij od pliku binarnego kontenera, który ma już język Python i
pyodbcjest zainstalowany. - Utwórz katalog roboczy dla aplikacji.
- Skopiuj cały kod z bieżącego katalogu do pliku
WORKDIR. - Zainstaluj wymagane biblioteki.
- Po uruchomieniu kontenera uruchom aplikację i otwórz wszystkie porty TCP/IP.
# syntax=docker/dockerfile:1
# Start with a Container binary that already has Python and pyodbc installed
FROM laudio/pyodbc
# Create a Working directory for the application
WORKDIR /flask2sql
# Copy all of the code from the current directory into the WORKDIR
COPY . .
# Install the libraries that are required
RUN pip install -r ./requirements.txt
# Once the container starts, run the application, and open all TCP/IP ports
CMD ["python3", "-m" , "flask", "run", "--host=0.0.0.0"]
Po utworzeniu tego pliku zespół porzucił wiersz polecenia w katalogu kodowania i uruchomił następujący kod, aby utworzyć binarny obraz z manifestu, a następnie kolejne polecenie, aby uruchomić kontener:
docker build -t flask2sql .
docker run -d -p 5000:5000 -t flask2sql
Po raz kolejny zespół przetestuje http://localhost:5000/products link, aby upewnić się, że kontener może uzyskać dostęp do bazy danych i zobaczy następujący zwrot:

Wdrażanie obrazu w rejestrze platformy Docker
Kontener działa teraz, ale jest dostępny tylko na maszynie dewelopera. Zespół deweloperów chce udostępnić ten obraz aplikacji pozostałej części firmy, a następnie na platformie Kubernetes na potrzeby wdrożenia produkcyjnego.
Obszar przechowywania obrazów kontenerów jest nazywany repozytorium i może istnieć zarówno repozytoria publiczne, jak i prywatne dla obrazów kontenerów. W rzeczywistości usługa AdvenureWorks użyła publicznego obrazu dla środowiska języka Python w pliku Dockerfile.
Zespół chce kontrolować dostęp do obrazu i zamiast umieszczać go w Internecie, decyduje, że chce go hostować samodzielnie, ale na platformie Microsoft Azure, gdzie mają pełną kontrolę nad zabezpieczeniami i dostępem. Więcej informacji na temat usługi Microsoft Azure Container Registry można znaleźć tutaj.
Wracając do wiersza polecenia, zespół deweloperów używa az CLI do dodawania usługi rejestru kontenerów, włączania konta administracyjnego, ustawiania go na anonimowe "ściągania" w fazie testowania i ustawiania kontekstu logowania do rejestru:
az acr create --resource-group ReplaceWith_PoCResourceGroupName --name ReplaceWith_AzureContainerRegistryName --sku Standard
az acr update -n ReplaceWith_AzureContainerRegistryName --admin-enabled true
az acr update --name ReplaceWith_AzureContainerRegistryName --anonymous-pull-enabled
az acr login --name ReplaceWith_AzureContainerRegistryName
Ten kontekst będzie używany w kolejnych krokach.
Oznaczanie lokalnego obrazu platformy Docker w celu przygotowania go do przekazania
Następnym krokiem jest wysłanie obrazu kontenera aplikacji lokalnej do usługi Azure Container Registry (ACR), aby była dostępna w chmurze.
- W poniższym przykładowym skry skrycie zespół używa poleceń platformy Docker do wyświetlania listy obrazów na maszynie.
- Używają narzędzia
az CLIdo wyświetlania listy obrazów w usłudze ACR. - Używają polecenia platformy Docker do "tagowania" obrazu z nazwą docelową rekordu ACR utworzonego w poprzednim kroku i ustawiają numer wersji dla odpowiedniej metodyki DevOps.
- Na koniec ponownie wyświetlają informacje o lokalnym obrazie, aby upewnić się, że tag został zastosowany poprawnie.
docker images
az acr list --resource-group ReplaceWith_PoCResourceGroupName --query "[].{acrLoginServer:loginServer}" --output table
docker tag flask2sql ReplaceWith_AzureContainerRegistryName.azurecr.io/azure-flask2sql:v1
docker images
Po zapisaniu i przetestowaniu kodu plik Dockerfile, obraz i kontener są uruchamiane i testowane, konfiguracja usługi ACR oraz wszystkie zastosowane tagi, zespół może przekazać obraz do usługi ACR.
Używają polecenia "push" platformy Docker, aby wysłać plik, a następnie az CLI narzędzie w celu upewnienia się, że obraz został załadowany:
docker push ReplaceWith_AzureContainerRegistryName.azurecr.io/azure-flask2sql:v1
az acr repository list --name ReplaceWith_AzureContainerRegistryName --output table
Wdrażanie na platformie Kubernetes
Zespół może po prostu uruchamiać kontenery i wdrażać aplikację w środowiskach lokalnych i w chmurze. Chcą jednak dodać wiele kopii aplikacji do skalowania i dostępności, dodać inne kontenery wykonujące różne zadania i dodać monitorowanie i instrumentację do całego rozwiązania.
Aby zgrupować kontenery w kompletne rozwiązanie, zespół postanowił użyć rozwiązania Kubernetes. Platforma Kubernetes działa lokalnie i na wszystkich głównych platformach w chmurze. Platforma Microsoft Azure ma kompletne zarządzane środowisko dla platformy Kubernetes o nazwie Azure Kubernetes Service (AKS). Dowiedz się więcej o usłudze AKS z wprowadzeniem do platformy Kubernetes na ścieżce szkoleniowej platformy Azure.
Za pomocą narzędzia zespół dodaje usługę az CLI AKS do tej samej utworzonej wcześniej grupy zasobów. Za pomocą jednego az polecenia zespół programistyczny wykonuje następujące czynności:
- Dodawanie dwóch "węzłów" lub środowisk obliczeniowych w celu zapewnienia odporności w fazie testowania
- Automatyczne generowanie kluczy SSH na potrzeby dostępu do środowiska
- Dołącz usługę ACR utworzoną w poprzednich krokach, aby klaster usługi AKS mógł zlokalizować obrazy, których chcą użyć do wdrożenia
az aks create --resource-group ReplaceWith_PoCResourceGroupName --name ReplaceWith_AzureKubernetesServiceName --node-count 2 --generate-ssh-keys --attach-acr ReplaceWith_AzureContainerRegistryName
Platforma Kubernetes używa narzędzia wiersza polecenia do uzyskiwania dostępu do klastra o nazwie kubectli kontrolowania go. Zespół używa narzędzia do pobierania az CLIkubectl narzędzia i instalowania go:
az aks install-cli
Ponieważ w tej chwili mają połączenie z usługą AKS, mogą poprosić o wysłanie kluczy SSH na potrzeby połączenia, które ma być używane podczas wykonywania kubectl narzędzia:
az aks get-credentials --resource-group ReplaceWith_PoCResourceGroupName --name ReplaceWith_AzureKubernetesServiceName
Te klucze są przechowywane w pliku o nazwie .config w katalogu użytkownika. W przypadku tego zestawu kontekstu zabezpieczeń zespół używa kubectl get nodes polecenia do wyświetlania węzłów w klastrze:
kubectl get nodes
Teraz zespół używa az CLI narzędzia do wyświetlania listy obrazów w usłudze ACR:
az acr list --resource-group ReplaceWith_PoCResourceGroupName --query "[].{acrLoginServer:loginServer}" --output table
Teraz mogą skompilować manifest używany przez platformę Kubernetes do kontrolowania wdrożenia. Jest to plik tekstowy przechowywany w formacie yaml . Oto tekst z adnotacjami flask2sql.yaml w pliku:
apiVersion: apps/v1
# The type of commands that will be sent, along with the name of the deployment
kind: Deployment
metadata:
name: flask2sql
# This section sets the general specifications for the application
spec:
replicas: 1
selector:
matchLabels:
app: flask2sql
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
minReadySeconds: 5
template:
metadata:
labels:
app: flask2sql
spec:
nodeSelector:
"kubernetes.io/os": linux
# This section sets the location of the Image(s) in the deployment, and where to find them
containers:
- name: flask2sql
image: bwoodyflask2sqlacr.azurecr.io/azure-flask2sql:v1
# Recall that the Flask application uses (by default) TCIP/IP port 5000 for access. This line tells Kubernetes that this "pod" uses that address.
ports:
- containerPort: 5000
---
apiVersion: v1
# This is the front-end of the application access, called a "Load Balancer"
kind: Service
metadata:
name: flask2sql
spec:
type: LoadBalancer
# this final step then sets the outside exposed port of the service to TCP/IP port 80, but maps it internally to the app's port of 5000
ports:
- protocol: TCP
port: 80
targetPort: 5000
selector:
app: flask2sql
Po zdefiniowaniu flask2sql.yaml pliku zespół może wdrożyć aplikację w uruchomionym klastrze usługi AKS. Odbywa się to za kubectl apply pomocą polecenia , które, jak pamiętasz, nadal ma kontekst zabezpieczeń dla klastra. Następnie polecenie jest wysyłane, kubectl get service aby obserwować klaster podczas jego kompilowania.
kubectl apply -f flask2sql.yaml
kubectl get service flask2sql --watch
Po kilku chwilach polecenie "watch" zwróci zewnętrzny adres IP. W tym momencie zespół naciska klawisze CTRL-C, aby przerwać polecenie zegarka, i rejestruje zewnętrzny adres IP modułu równoważenia obciążenia.
Testowanie aplikacji
Przy użyciu adresu IP (punktu końcowego) uzyskanego w ostatnim kroku zespół sprawdza, czy dane wyjściowe są takie same jak lokalna aplikacja i kontener platformy Docker:
Czyszczenie
Po utworzeniu, edytowaniu, udokumentowaniu i przetestowaniu aplikacji zespół może teraz "usunąć" aplikację. Zachowując wszystkie elementy w jednej grupie zasobów na platformie Microsoft Azure, wystarczy usunąć grupę zasobów weryfikacji koncepcji przy użyciu az CLI narzędzia :
az group delete -n ReplaceWith_PoCResourceGroupName -y
Uwaga
Jeśli usługa Azure SQL Database została utworzona w innej grupie zasobów i nie jest już potrzebna, możesz usunąć ją za pomocą witryny Azure Portal.
Członek zespołu prowadzący projekt weryfikacji koncepcji używa systemu Microsoft Windows jako stacji roboczej i chce zachować plik wpisów tajnych z platformy Kubernetes, ale usunąć go z systemu jako aktywną lokalizację. Mogą po prostu skopiować plik do pliku tekstowego config.old , a następnie usunąć go:
copy c:\users\ReplaceWith_YourUserName\.kube\config c:\users\ReplaceWith_YourUserName\.kube\config.old
del c:\users\ReplaceWith_YourUserName\.kube\config
Powiązana zawartość
- Omówienie tworzenia aplikacji — SQL Database i SQL Managed Instance
- Połączenie do usługi Azure SQL Database i wykonywania zapytań względem usługi Azure SQL Database przy użyciu języka Python i sterownika pyodbc
- Publikowanie projektu bazy danych dla usługi Azure SQL Database w lokalnym emulatorze
- Przeglądanie przykładów kodu dla usługi Azure SQL Database
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla