Rozwiązywanie problemów z wydajnością inteligentnych Szczegółowe informacje — Azure SQL Database i Azure SQL Managed Instance
Dotyczy:![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Ta strona zawiera informacje na temat problemów z wydajnością usługi Azure SQL Database i usługi Azure SQL Managed Instance wykrytych za pośrednictwem dziennika zasobów inteligentnego Szczegółowe informacje. Metryki i dzienniki zasobów można przesyłać strumieniowo do dzienników usługi Azure Monitor, usługi Azure Event Hubs, usługi Azure Storage lub rozwiązania innej firmy na potrzeby niestandardowych funkcji raportowania i alertów devOps.
Uwaga
Aby uzyskać szybki przewodnik rozwiązywania problemów z wydajnością przy użyciu inteligentnego Szczegółowe informacje, zobacz zalecany schemat blokowy rozwiązywania problemów w tym dokumencie.
Inteligentne szczegółowe informacje to funkcja w wersji zapoznawczej, niedostępna w następujących regionach: Europa Zachodnia, Europa Północna, Zachodnie stany USA 1 i Wschodnie stany USA 1.
Wykrywalne wzorce wydajności bazy danych
Inteligentne Szczegółowe informacje automatycznie wykrywa problemy z wydajnością na podstawie czasów oczekiwania, błędów lub limitów czasu wykonywania zapytań. Inteligentne Szczegółowe informacje dane wyjściowe wykryły wzorce wydajności w dzienniku zasobów. Wzorce wydajności wykrywalne są podsumowane w poniższej tabeli.
| Wykrywalne wzorce wydajności | Azure SQL Database | Wystąpienie zarządzane Azure SQL |
|---|---|---|
| Osiąganie limitów zasobów | Użycie dostępnych zasobów (DTU), wątków procesu roboczego bazy danych lub sesji logowania bazy danych dostępnych w monitorowanej subskrypcji osiągnęło limity zasobów. Ma to wpływ na wydajność. | Użycie zasobów procesora CPU osiąga limity zasobów. Ma to wpływ na wydajność bazy danych. |
| Zwiększenie obciążenia | Wykryto wzrost obciążenia lub ciągłą akumulację obciążenia w bazie danych. Ma to wpływ na wydajność. | Wykryto wzrost obciążenia. Ma to wpływ na wydajność bazy danych. |
| Wykorzystanie pamięci | Pracownicy, którzy zażądali dotacji pamięci, muszą czekać na alokacje pamięci przez statystycznie znaczne ilości czasu lub zwiększyć akumulację procesów roboczych, które zażądały dotacji pamięci. Ma to wpływ na wydajność. | Pracownicy, którzy zażądali dotacji na pamięć, oczekują na alokacje pamięci przez statystycznie znaczną ilość czasu. Ma to wpływ na wydajność bazy danych. |
| Blokowanie | Wykryto nadmierne blokowanie bazy danych wpływające na wydajność. | Wykryto nadmierne blokowanie bazy danych wpływające na wydajność bazy danych. |
| Zwiększona wartość MAXDOP | Maksymalny stopień równoległości (MAXDOP) zmienił się na wydajność wykonywania zapytań. Ma to wpływ na wydajność. | Maksymalny stopień równoległości (MAXDOP) zmienił się na wydajność wykonywania zapytań. Ma to wpływ na wydajność. |
| Rywalizacja o strony | Wiele wątków próbuje jednocześnie uzyskać dostęp do tych samych stron buforu danych w pamięci, co zwiększa czas oczekiwania i powoduje rywalizację o strony. Ma to wpływ na wydajność. | Wiele wątków próbuje jednocześnie uzyskać dostęp do tych samych stron buforu danych w pamięci, co zwiększa czas oczekiwania i powoduje rywalizację o strony. Ma to wpływ na wydajność bazy danych. |
| Brak indeksu | Wykryto brak indeksu wpływającego na wydajność. | Wykryto brak indeksu wpływającego na wydajność bazy danych. |
| Nowe zapytanie | Wykryto nowe zapytanie wpływające na ogólną wydajność. | Wykryto nowe zapytanie wpływające na ogólną wydajność bazy danych. |
| Zwiększona statystyka oczekiwania | Wykryto zwiększone czasy oczekiwania bazy danych wpływające na wydajność. | Wykryto zwiększone czasy oczekiwania bazy danych wpływające na wydajność bazy danych. |
| Rywalizacja o bazę danych TempDB | Wiele wątków próbuje uzyskać dostęp do tego samego tempdb zasobu, co wąskie gardło. Ma to wpływ na wydajność. |
Wiele wątków próbuje uzyskać dostęp do tego samego tempdb zasobu, co wąskie gardło. Ma to wpływ na wydajność bazy danych. |
| Brak jednostek DTU puli elastycznej | Niedobór dostępnych jednostek eDTU w elastycznej puli ma wpływ na wydajność. | Usługa Azure SQL Managed Instance jest niedostępna, ponieważ używa modelu rdzeni wirtualnych. |
| Regresja planu | Wykryto nowy plan lub zmianę obciążenia istniejącego planu. Ma to wpływ na wydajność. | Wykryto nowy plan lub zmianę obciążenia istniejącego planu. Ma to wpływ na wydajność bazy danych. |
| Zmiana wartości konfiguracji w zakresie bazy danych | Wykryto zmianę konfiguracji bazy danych wpływającą na wydajność bazy danych. | Wykryto zmianę konfiguracji bazy danych wpływającą na wydajność bazy danych. |
| Powolny klient | Powolny klient aplikacji nie może używać danych wyjściowych z bazy danych wystarczająco szybko. Ma to wpływ na wydajność. | Powolny klient aplikacji nie może używać danych wyjściowych z bazy danych wystarczająco szybko. Ma to wpływ na wydajność bazy danych. |
| Obniżanie warstwy cenowej | Akcja obniżania poziomu cenowego zmniejszyła dostępne zasoby. Ma to wpływ na wydajność. | Akcja obniżania poziomu cenowego zmniejszyła dostępne zasoby. Ma to wpływ na wydajność bazy danych. |
Napiwek
W przypadku ciągłej optymalizacji wydajności baz danych włącz automatyczne dostrajanie. Ta wbudowana funkcja analizy stale monitoruje bazę danych, automatycznie dostraja indeksy i stosuje poprawki planu wykonywania zapytań.
W poniższej sekcji opisano bardziej szczegółowo wykrywalne wzorce wydajności.
Osiąganie limitów zasobów
Co się dzieje
Ten wykrywalny wzorzec wydajności łączy problemy z wydajnością związane z osiągnięciem dostępnych limitów zasobów, limitów procesów roboczych i limitów sesji. Po wykryciu tego problemu z wydajnością pole opisu dziennika diagnostycznego wskazuje, czy problem z wydajnością jest związany z limitami zasobów, procesów roboczych lub sesji.
Zasoby w usłudze Azure SQL Database są zwykle określane jako zasoby jednostek DTU lub rdzeni wirtualnych, a zasoby w usłudze Azure SQL Managed Instance są nazywane zasobami rdzeni wirtualnych. Wzorzec osiągania limitów zasobów jest rozpoznawany, gdy wykryte obniżenie wydajności zapytań jest spowodowane osiągnięciem dowolnego z mierzonych limitów zasobów.
Zasób limitów sesji określa liczbę dostępnych jednoczesnych logowań do bazy danych. Ten wzorzec wydajności jest rozpoznawany, gdy aplikacje połączone z bazami danych osiągnęły liczbę dostępnych współbieżnych logowań do bazy danych. Jeśli aplikacje próbują używać większej liczby sesji niż są dostępne w bazie danych, wydajność zapytań będzie miała wpływ.
Osiągnięcie limitów procesów roboczych jest konkretnym przypadkiem osiągnięcia limitów zasobów, ponieważ dostępne procesy robocze nie są liczone w użyciu jednostek DTU ani rdzeni wirtualnych. Osiągnięcie limitów procesów roboczych w bazie danych może spowodować wzrost czasu oczekiwania specyficznego dla zasobów, co powoduje obniżenie wydajności zapytań.
Rozwiązywanie problemów
Dziennik diagnostyczny generuje skróty zapytań zapytań, które miały wpływ na wydajność i procent użycia zasobów. Te informacje mogą służyć jako punkt wyjścia do optymalizacji obciążenia bazy danych. W szczególności można zoptymalizować zapytania wpływające na obniżenie wydajności, dodając indeksy. Możesz też zoptymalizować aplikacje z bardziej równomiernym rozkładem obciążeń. Jeśli nie możesz zmniejszyć obciążeń lub dokonać optymalizacji, rozważ zwiększenie warstwy cenowej subskrypcji bazy danych w celu zwiększenia ilości dostępnych zasobów.
Jeśli osiągnięto dostępne limity sesji, możesz zoptymalizować aplikacje, zmniejszając liczbę logowań w bazie danych. Jeśli nie możesz zmniejszyć liczby logowań z aplikacji do bazy danych, rozważ zwiększenie warstwy cenowej subskrypcji bazy danych. Możesz też podzielić bazę danych na wiele baz danych i przenieść je na bardziej zrównoważoną dystrybucję obciążenia.
Aby uzyskać więcej sugestii dotyczących rozwiązywania limitów sesji, zobacz Jak radzić sobie z limitami maksymalnej liczby logowań. Zobacz Omówienie limitów zasobów na serwerze , aby uzyskać informacje o limitach na poziomie serwera i subskrypcji.
Wzrost obciążenia
Co się dzieje
Ten wzorzec wydajności identyfikuje problemy spowodowane wzrostem obciążenia lub, w jego poważniejszej postaci, stosem obciążenia.
To wykrywanie jest wykonywane za pomocą kombinacji kilku metryk. Mierzona podstawowa metryka wykrywa wzrost obciążenia w porównaniu z poprzednim punktem odniesienia obciążenia. Druga forma wykrywania opiera się na mierzeniu dużego wzrostu liczby aktywnych wątków roboczych, które są wystarczająco duże, aby wpłynąć na wydajność zapytań.
W bardziej poważnej formie obciążenie może stale stosować się ze względu na niezdolność bazy danych do obsługi obciążenia. Wynikiem jest stale rosnący rozmiar obciążenia, który jest warunkiem stosu obciążenia. Ze względu na ten warunek czas oczekiwania na wykonanie obciążenia rośnie. Ten warunek reprezentuje jeden z najpoważniejszych problemów z wydajnością bazy danych. Ten problem jest wykrywany przez monitorowanie wzrostu liczby przerwanych wątków roboczych.
Rozwiązywanie problemów
Dziennik diagnostyczny generuje liczbę zapytań, których wykonanie zwiększyło się, a skrót zapytania zapytania z największym wzrostem obciążenia. Te informacje mogą służyć jako punkt wyjścia do optymalizacji obciążenia. Zapytanie zidentyfikowane jako największy współautor wzrostu obciążenia jest szczególnie przydatne jako punkt początkowy.
Możesz rozważyć równomierne dystrybuowanie obciążeń do bazy danych. Rozważ optymalizację zapytania, które ma wpływ na wydajność, dodając indeksy. Obciążenie można również dystrybuować między wiele baz danych. Jeśli te rozwiązania nie są możliwe, rozważ zwiększenie warstwy cenowej subskrypcji bazy danych, aby zwiększyć ilość dostępnych zasobów.
Wykorzystanie pamięci
Co się dzieje
Ten wzorzec wydajności wskazuje spadek wydajności bieżącej bazy danych spowodowany przez wykorzystanie pamięci lub w poważniejszej postaci stanu stosu pamięci w porównaniu z poprzednim siedmiodniowym punktem odniesienia wydajności.
Ciśnienie pamięci określa warunek wydajności, w którym istnieje duża liczba wątków roboczych żądających dotacji pamięci. Duża ilość powoduje wysokie wykorzystanie pamięci, w którym baza danych nie może efektywnie przydzielić pamięci do wszystkich procesów roboczych, które go żądają. Jedną z najczęstszych przyczyn tego problemu jest ilość pamięci dostępnej dla bazy danych z jednej strony. Z drugiej strony wzrost obciążenia powoduje wzrost liczby wątków roboczych i wykorzystanie pamięci.
Bardziej dotkliwą formą ciśnienia pamięci jest stan stosu pamięci. Ten warunek wskazuje, że większa liczba wątków roboczych żąda dotacji pamięci niż w przypadku zapytań zwalniających pamięć. Ta liczba wątków roboczych żądających dotacji pamięci może również stale rosnąć (stosy), ponieważ aparat bazy danych nie może efektywnie przydzielić pamięci, aby zaspokoić zapotrzebowanie. Warunek stosu pamięci reprezentuje jeden z najpoważniejszych problemów z wydajnością bazy danych.
Rozwiązywanie problemów
Dziennik diagnostyczny generuje szczegóły magazynu obiektów pamięci za pomocą urzędnika (czyli wątku roboczego) oznaczonego jako najwyższy powód wysokiego użycia pamięci i odpowiednich sygnatur czasowych. Te informacje mogą służyć jako podstawa rozwiązywania problemów.
Możesz zoptymalizować lub usunąć zapytania związane z urzędami pracy z najwyższym użyciem pamięci. Możesz również upewnić się, że nie wysyłasz zapytań dotyczących danych, których nie planujesz używać. Dobrym rozwiązaniem jest zawsze użycie klauzuli WHERE w zapytaniach. Ponadto zalecamy utworzenie indeksów nieklastrowanych w celu wyszukiwania danych, a nie ich skanowania.
Możesz również zmniejszyć obciążenie, optymalizując lub dystrybuując je w wielu bazach danych. Możesz też dystrybuować obciążenie między wiele baz danych. Jeśli te rozwiązania nie są możliwe, rozważ zwiększenie warstwy cenowej bazy danych w celu zwiększenia ilości zasobów pamięci dostępnych dla bazy danych.
Aby uzyskać dodatkowe sugestie dotyczące rozwiązywania problemów, zobacz Medytacja grantów pamięci: tajemniczy odbiorca pamięci programu SQL Server o wielu nazwach. Aby uzyskać więcej informacji na temat błędów braku pamięci w usłudze Azure SQL Database, zobacz Rozwiązywanie problemów z błędami braku pamięci w usłudze Azure SQL Database.
Blokowanie
Co się dzieje
Ten wzorzec wydajności wskazuje spadek wydajności bieżącej bazy danych, w którym wykryto nadmierne blokowanie bazy danych w porównaniu z poprzednim siedmiodniowym punktem odniesienia wydajności.
W nowoczesnych systemach RDBMS blokowanie jest niezbędne do implementowania wielowątkowych systemów, w których wydajność jest zmaksymalizowana przez uruchamianie wielu równoczesnych procesów roboczych i równoległych transakcji bazy danych tam, gdzie to możliwe. Blokowanie w tym kontekście odnosi się do wbudowanego mechanizmu dostępu, w którym tylko jedna transakcja może uzyskiwać wyłączny dostęp do wierszy, stron, tabel i plików, które są wymagane, a nie konkurować z inną transakcją dla zasobów. Gdy transakcja, która zablokowała zasoby do użycia, zostanie zwolniona blokada tych zasobów, co umożliwia innym transakcjom dostęp do wymaganych zasobów. Aby uzyskać więcej informacji na temat blokowania, zobacz Blokowanie aparatu bazy danych.
Jeśli transakcje wykonywane przez aparat SQL czekają przez dłuższy czas na dostęp do zasobów zablokowanych do użycia, ten czas oczekiwania powoduje spowolnienie wydajności wykonywania obciążenia.
Rozwiązywanie problemów
Dane wyjściowe dziennika diagnostycznego blokują szczegóły, których można użyć jako podstawy do rozwiązywania problemów. Możesz przeanalizować zgłoszone zapytania blokujące, czyli zapytania, które wprowadzają obniżenie wydajności blokowania, i je usunąć. W niektórych przypadkach można pomyślnie zoptymalizować zapytania blokujące.
Najprostszym i najbezpieczniejszym sposobem rozwiązania problemu jest utrzymywanie krótkich transakcji i zmniejszenie śladu blokady najdroższych zapytań. Można podzielić dużą partię operacji na mniejsze operacje. Dobrym rozwiązaniem jest zmniejszenie śladu blokady zapytania przez zapewnienie możliwie jak największej wydajności zapytania. Zmniejsz duże skanowania, ponieważ zwiększają one szanse na zakleszczenia i niekorzystnie wpływają na ogólną wydajność bazy danych. W przypadku zidentyfikowanych zapytań, które powodują blokowanie, można utworzyć nowe indeksy lub dodać kolumny do istniejącego indeksu, aby uniknąć skanowania tabeli.
Aby uzyskać więcej sugestii, zobacz:
- Omówienie i rozwiązywanie problemów z blokowaniem usługi Azure SQL
- Jak rozwiązać problemy z blokowaniem spowodowane eskalacją blokady w programie SQL Server
Zwiększona wartość MAXDOP
Co się dzieje
Ten wykrywalny wzorzec wydajności wskazuje warunek, w którym wybrany plan wykonywania zapytania został zrównoleglizowany bardziej niż powinien. Optymalizator zapytań może zwiększyć wydajność obciążenia, wykonując zapytania równolegle, aby przyspieszyć działanie tam, gdzie to możliwe. W niektórych przypadkach równoległe procesy robocze przetwarzające zapytanie poświęcają więcej czasu na siebie, aby synchronizować i scalać wyniki w porównaniu z wykonywaniem tego samego zapytania z mniejszą liczbą równoległych procesów roboczych, a nawet w niektórych przypadkach w porównaniu z pojedynczym wątkiem roboczym.
System ekspertów analizuje bieżącą wydajność bazy danych w porównaniu z okresem odniesienia. Określa, czy wcześniej uruchomione zapytanie działa wolniej niż wcześniej, ponieważ plan wykonywania zapytania jest bardziej równoległy niż powinien.
Opcja konfiguracji serwera MAXDOP służy do kontrolowania, ile rdzeni procesora CPU może służyć do równoległego wykonywania tego samego zapytania.
Rozwiązywanie problemów
Dziennik diagnostyczny generuje skróty zapytań związane z zapytaniami, dla których czas trwania wykonywania wzrósł, ponieważ zostały one zrównoleglizowane bardziej niż powinny. Dziennik generuje również czas oczekiwania CXP. Tym razem reprezentuje czas, gdy jeden wątek organizatora/koordynatora (wątek 0) czeka na zakończenie wszystkich innych wątków przed scaleniem wyników i przejściem do przodu. Ponadto dziennik diagnostyki generuje czas oczekiwania, przez które zapytania o niskiej wydajności oczekiwały ogólnie. Te informacje mogą służyć jako podstawa rozwiązywania problemów.
Najpierw zoptymalizuj lub uprość złożone zapytania. Dobrym rozwiązaniem jest podzielenie długich zadań wsadowych na mniejsze. Ponadto upewnij się, że utworzono indeksy do obsługi zapytań. Można również ręcznie wymusić maksymalny stopień równoległości (MAXDOP) dla zapytania oznaczonego jako niska wydajność. Aby skonfigurować tę operację przy użyciu języka T-SQL, zobacz Konfigurowanie opcji konfiguracji serwera MAXDOP.
Ustawienie opcji konfiguracji serwera MAXDOP na zero (0) jako wartość domyślną oznacza, że baza danych może używać wszystkich dostępnych rdzeni procesora CPU do równoległości wątków do wykonywania pojedynczego zapytania. Ustawienie parametru MAXDOP na jeden (1) oznacza, że tylko jeden rdzeń może być używany do wykonywania pojedynczego zapytania. W praktyce oznacza to, że równoległość jest wyłączona. W zależności od wielkości liter, dostępnych rdzeni bazy danych i informacji dziennika diagnostycznego można dostroić opcję MAXDOP do liczby rdzeni używanych do równoległego wykonywania zapytań, które mogą rozwiązać problem w Twoim przypadku.
Rywalizacja o strony
Co się dzieje
Ten wzorzec wydajności wskazuje na spadek wydajności bieżącego obciążenia bazy danych z powodu rywalizacji o stronicowanie w porównaniu z poprzednim siedmiodniowym punktem odniesienia obciążenia.
Zatrzaski to lekkie mechanizmy synchronizacji używane do włączania wielowątków. Gwarantują one spójność struktur w pamięci, które obejmują indeksy, strony danych i inne struktury wewnętrzne.
Dostępnych jest wiele typów zatrzasków. Dla uproszczenia zatrzaski buforu są używane do ochrony stron w pamięci w puli buforów. Zatrzaski we/wy są używane do ochrony stron, które nie zostały jeszcze załadowane do puli buforów. Za każdym razem, gdy dane są zapisywane lub odczytywane ze strony w puli buforów, wątek procesu roboczego musi najpierw uzyskać zatrzask buforu dla strony. Za każdym razem, gdy wątek procesu roboczego próbuje uzyskać dostęp do strony, która nie jest jeszcze dostępna w puli buforów w pamięci, żądanie we/wy jest wykonywane w celu załadowania wymaganych informacji z magazynu. Ta sekwencja zdarzeń wskazuje na poważniejszą formę obniżenia wydajności.
Rywalizacja o zatrzasanie strony występuje, gdy wiele wątków jednocześnie próbuje uzyskać zatrzaski w tej samej strukturze w pamięci, co wprowadza zwiększony czas oczekiwania na wykonanie zapytania. W przypadku rywalizacji we/wy pagelatch, gdy dane muszą być dostępne z magazynu, ten czas oczekiwania jest jeszcze większy. Może to znacząco wpłynąć na wydajność obciążenia. Rywalizacja pagelatch jest najbardziej typowym scenariuszem wątków oczekujących na siebie i konkurowania o zasoby w wielu systemach procesora CPU.
Rozwiązywanie problemów
Szczegóły rywalizacji w dzienniku diagnostycznym są wyświetlane na stronie. Te informacje mogą służyć jako podstawa rozwiązywania problemów.
Ponieważ stronicowanie jest mechanizmem kontroli wewnętrznej, automatycznie określa, kiedy ich używać. Decyzje dotyczące aplikacji, w tym projektowania schematu, mogą mieć wpływ na zachowanie strony z powodu deterministycznego zachowania zatrzaśnięć.
Jedną z metod obsługi rywalizacji o zatrzaśnięć jest zastąpienie klucza indeksu sekwencyjnego kluczem niekweseryjnym, aby równomiernie rozłożyć wstawki w zakresie indeksu. Zazwyczaj kolumna wiodąca w indeksie dystrybuuje obciążenie proporcjonalnie. Inną metodą do rozważenia jest partycjonowanie tabel. Tworzenie schematu partycjonowania skrótów z obliczoną kolumną w tabeli partycjonowanej jest typowym podejściem do ograniczania nadmiernej rywalizacji o zatrzasanie. W przypadku rywalizacji we/wy pagelatch wprowadzenie indeksów pomaga wyeliminować ten problem z wydajnością.
Aby uzyskać więcej informacji, zobacz Diagnozowanie i rozwiązywanie problemów z zatrzaśnięciami w programie SQL Server (pobieranie plików PDF).
Brak indeksu
Co się dzieje
Ten wzorzec wydajności wskazuje spadek wydajności bieżącego obciążenia bazy danych w porównaniu z poprzednim siedmiodniowym punktem odniesienia z powodu braku indeksu.
Indeks służy do przyspieszenia wydajności zapytań. Zapewnia szybki dostęp do danych tabeli, zmniejszając liczbę stron zestawu danych, które muszą być odwiedzane lub skanowane.
Określone zapytania, które spowodowały obniżenie wydajności, są identyfikowane za pomocą tego wykrywania, dla którego tworzenie indeksów byłoby korzystne dla wydajności.
Rozwiązywanie problemów
Dziennik diagnostyczny generuje skróty zapytań dla zapytań, które zostały zidentyfikowane w celu wpływu na wydajność obciążenia. Możesz tworzyć indeksy dla tych zapytań. Możesz również zoptymalizować lub usunąć te zapytania, jeśli nie są one wymagane. Dobrym rozwiązaniem w zakresie wydajności jest unikanie wykonywania zapytań dotyczących danych, których nie używasz.
Napiwek
Czy wiesz, że wbudowana analiza może automatycznie zarządzać indeksami o najlepszej wydajności dla baz danych?
W przypadku optymalizacji ciągłej wydajności zalecamy włączenie automatycznego dostrajania. Ta unikatowa wbudowana funkcja analizy stale monitoruje bazę danych i automatycznie tworzy indeksy dla baz danych.
Nowe zapytanie
Co się dzieje
Ten wzorzec wydajności wskazuje, że nowe zapytanie jest wykrywane, że działa słabo i wpływa na wydajność obciążenia w porównaniu z siedmiodniowym punktem odniesienia wydajności.
Pisanie zapytania o dobrej wydajności czasami może być trudnym zadaniem. Aby uzyskać więcej informacji na temat pisania zapytań, zobacz Pisanie zapytań SQL. Aby zoptymalizować istniejącą wydajność zapytań, zobacz Dostrajanie zapytań.
Rozwiązywanie problemów
Dziennik diagnostyczny generuje informacje o maksymalnie dwóch nowych zapytaniach zużywających procesor CPU, w tym skróty zapytań. Ponieważ wykryte zapytanie wpływa na wydajność obciążenia, możesz zoptymalizować zapytanie. Dobrym rozwiązaniem jest pobranie tylko danych, których potrzebujesz. Zalecamy również używanie zapytań z klauzulą WHERE. Zalecamy również uproszczenie złożonych zapytań i podzielenie ich na mniejsze zapytania. Innym dobrym rozwiązaniem jest podzielenie dużych zapytań wsadowych na mniejsze zapytania wsadowe. Wprowadzenie indeksów dla nowych zapytań jest zazwyczaj dobrym rozwiązaniem w celu wyeliminowania tego problemu z wydajnością.
W usłudze Azure SQL Database rozważ użycie szczegółowych informacji o wydajności zapytań.
Zwiększona statystyka oczekiwania
Co się dzieje
Ten wykrywalny wzorzec wydajności wskazuje spadek wydajności obciążenia, w którym zidentyfikowano zapytania o niskiej wydajności w porównaniu z poprzednim siedmiodniowym punktem odniesienia obciążenia.
W takim przypadku system nie może sklasyfikować zapytań o niskiej wydajności w ramach innych standardowych kategorii wydajności wykrywalnych, ale wykrył statystykę oczekiwania odpowiedzialną za regresję. W związku z tym uwzględnia je jako zapytania ze zwiększonymi statystykami oczekiwania, gdzie uwidoczniona jest również statystyka oczekiwania odpowiedzialna za regresję.
Rozwiązywanie problemów
Dziennik diagnostyczny generuje informacje o zwiększonym czasie oczekiwania i skrótach zapytań dotyczących zapytań, których dotyczy problem.
Ponieważ system nie może pomyślnie zidentyfikować głównej przyczyny dla zapytań o niskiej wydajności, informacje diagnostyczne są dobrym punktem wyjścia do ręcznego rozwiązywania problemów. Możesz zoptymalizować wydajność tych zapytań. Dobrym rozwiązaniem jest pobranie tylko danych, których potrzebujesz, oraz uproszczenie i podzielenie złożonych zapytań na mniejsze.
Aby uzyskać więcej informacji na temat optymalizowania wydajności zapytań, zobacz Dostrajanie zapytań.
Rywalizacja o bazę danych TempDB
Co się dzieje
Ten wykrywalny wzorzec wydajności wskazuje stan wydajności bazy danych, w którym istnieje wąskie gardło wątków próbujących uzyskać dostęp tempdb do zasobów. (Ten warunek nie jest związany z operacjami we/wy). Typowy scenariusz dla tego problemu z wydajnością to setki współbieżnych zapytań, które tworzą, używają, a następnie upuszczają małe tempdb tabele. System wykrył, że liczba współbieżnych zapytań używających tych samych tempdb tabel wzrosła o wystarczające znaczenie statystyczne, aby wpłynąć na wydajność bazy danych w porównaniu z poprzednim siedmiodniowym punktem odniesienia wydajności.
Rozwiązywanie problemów
Dziennik diagnostyczny generuje tempdb szczegóły rywalizacji. Możesz użyć tych informacji jako punktu wyjścia do rozwiązywania problemów. Istnieją dwie rzeczy, które można realizować, aby złagodzić ten rodzaj rywalizacji i zwiększyć przepływność ogólnego obciążenia: możesz przestać korzystać z tabel tymczasowych. Można również użyć tabel zoptymalizowanych pod kątem pamięci.
Aby uzyskać więcej informacji, zobacz Wprowadzenie do tabel zoptymalizowanych pod kątem pamięci.
Brak jednostek DTU puli elastycznej
Co się dzieje
Ten wykrywalny wzorzec wydajności wskazuje spadek wydajności bieżącego obciążenia bazy danych w porównaniu z poprzednim siedmiodniowym punktem odniesienia. Wynika to z niedoboru dostępnych jednostek DTU w elastycznej puli subskrypcji.
Zasoby elastycznej puli platformy Azure są używane jako pula dostępnych zasobów współużytkowanych między wieloma bazami danych na potrzeby skalowania. Jeśli dostępne zasoby eDTU w elastycznej puli nie są wystarczająco duże, aby obsługiwać wszystkie bazy danych w puli, wykryto problem z wydajnością niedoboru jednostek DTU puli elastycznej.
Rozwiązywanie problemów
Dziennik diagnostyczny generuje informacje dotyczące elastycznej puli, wyświetla listę najważniejszych baz danych zużywających jednostki DTU i udostępnia procent jednostek DTU puli używanych przez bazę danych zużywających najwyższe użycie.
Ponieważ ten warunek wydajności jest związany z wieloma bazami danych korzystającymi z tej samej puli jednostek eDTU w elastycznej puli, kroki rozwiązywania problemów koncentrują się na najważniejszych bazach danych zużywających jednostki DTU. Możesz zmniejszyć obciążenie baz danych zużywających najwięcej zasobów, co obejmuje optymalizację zapytań zużywających najwięcej na tych bazach danych. Możesz również upewnić się, że nie wysyłasz zapytań dotyczących danych, których nie używasz. Innym podejściem jest zoptymalizowanie aplikacji przy użyciu najważniejszych baz danych korzystających z jednostek DTU i ponowne dystrybuowanie obciążenia między wieloma bazami danych.
Jeśli nie jest możliwe zmniejszenie i optymalizacja bieżącego obciążenia w bazach danych zużywających jednostki DTU, rozważ zwiększenie warstwy cenowej elastycznej puli. Taki wzrost powoduje zwiększenie dostępnych jednostek DTU w elastycznej puli.
Regresja planu
Co się dzieje
Ten wykrywalny wzorzec wydajności określa warunek, w którym baza danych korzysta z nieoptymalnego planu wykonywania zapytań. Nieoptymalny plan zwykle powoduje zwiększone wykonywanie zapytań, co prowadzi do dłuższego czasu oczekiwania dla bieżących i innych zapytań.
Aparat bazy danych określa plan wykonywania zapytań z najmniejszym kosztem wykonywania zapytania. W miarę zmiany typu zapytań i obciążeń czasami istniejące plany nie są już wydajne lub być może aparat bazy danych nie dokonał dobrej oceny. W ramach korekty plany wykonywania zapytań można wymusić ręcznie.
Ten wykrywalny wzorzec wydajności łączy trzy różne przypadki regresji planu: nową regresję planu, starą regresję planu i istniejące plany zmienione obciążenie. Określony typ regresji planu, który wystąpił, znajduje się we właściwości szczegółów w dzienniku diagnostycznym.
Nowy warunek regresji planu odnosi się do stanu, w którym aparat bazy danych rozpoczyna wykonywanie nowego planu wykonywania zapytania, który nie jest tak wydajny, jak stary plan. Stary warunek regresji planu odnosi się do stanu, gdy aparat bazy danych przełącza się z używania nowego, bardziej wydajnego planu do starego planu, który nie jest tak wydajny, jak nowy plan. Istniejące plany zmieniły regresję obciążenia odnoszą się do stanu, w którym stare i nowe plany są stale alternatywne, a równowaga będzie bardziej skierowana do planu o niskiej wydajności.
Aby uzyskać więcej informacji na temat regresji planu, zobacz Co to jest regresja planu w programie SQL Server?.
Rozwiązywanie problemów
Dziennik diagnostyczny generuje skróty zapytania, identyfikator dobrego planu, identyfikator złego planu i identyfikatory zapytań. Te informacje mogą służyć jako podstawa rozwiązywania problemów.
Możesz przeanalizować, który plan działa lepiej dla określonych zapytań, które można zidentyfikować przy użyciu podanych skrótów zapytań. Po ustaleniu, który plan działa lepiej w przypadku zapytań, możesz ręcznie wymusić jego działanie.
Aby uzyskać więcej informacji, zobacz Dowiedz się, jak program SQL Server uniemożliwia regresje planu.
Napiwek
Czy wiesz, że wbudowana funkcja analizy może automatycznie zarządzać najlepszymi planami wykonywania zapytań dla baz danych?
W przypadku optymalizacji ciągłej wydajności zalecamy włączenie automatycznego dostrajania. Ta wbudowana funkcja analizy stale monitoruje bazę danych i automatycznie dostraja i tworzy najlepsze plany wykonywania zapytań dla baz danych.
Zmiana wartości konfiguracji w zakresie bazy danych
Co się dzieje
Ten wykrywalny wzorzec wydajności wskazuje warunek, w którym zmiana konfiguracji w zakresie bazy danych powoduje regresję wydajności wykrytą w porównaniu z zachowaniem obciążenia bazy danych z ostatnich siedmiu dni. Ten wzorzec oznacza, że ostatnia zmiana w konfiguracji o zakresie bazy danych nie wydaje się być korzystna dla wydajności bazy danych.
Zmiany konfiguracji w zakresie bazy danych można ustawić dla każdej pojedynczej bazy danych. Ta konfiguracja jest używana w poszczególnych przypadkach, aby zoptymalizować pojedynczą wydajność bazy danych. Dla każdej pojedynczej bazy danych można skonfigurować następujące opcje: MAXDOP, LEGACY_CARDINALITY_ESTIMATION, PARAMETER_SNIFFING, QUERY_OPTIMIZER_HOTFIXES i CLEAR PROCEDURE_CACHE.
Rozwiązywanie problemów
Dziennik diagnostyczny generuje zmiany konfiguracji w zakresie bazy danych, które zostały ostatnio wprowadzone, które spowodowały obniżenie wydajności w porównaniu z poprzednim siedmiodniowym zachowaniem obciążenia. Możesz przywrócić zmiany konfiguracji w poprzednich wartościach. Można również dostroić wartość według wartości do momentu osiągnięcia żądanego poziomu wydajności. Wartości konfiguracji zakresu bazy danych można skopiować z podobnej bazy danych z zadowalającą wydajnością. Jeśli nie możesz rozwiązać problemów z wydajnością, przywróć wartości domyślne i spróbuj dostroić poczynając od tego punktu odniesienia.
Aby uzyskać więcej informacji na temat optymalizowania konfiguracji opartej na zakresie bazy danych i składni języka T-SQL w zakresie zmiany konfiguracji, zobacz Alter database-scoped configuration (Transact-SQL).
Powolny klient
Co się dzieje
Ten wykrywalny wzorzec wydajności wskazuje warunek, w którym klient korzystający z bazy danych nie może używać danych wyjściowych z bazy danych tak szybko, jak baza danych wysyła wyniki. Ponieważ baza danych nie przechowuje wyników wykonanych zapytań w buforze, spowalnia i czeka, aż klient będzie korzystać z przesłanych danych wyjściowych zapytania przed kontynuowaniem. Ten warunek może być również związany z siecią, która nie jest wystarczająco szybka, aby przesyłać dane wyjściowe z bazy danych do klienta zużywanego.
Ten warunek jest generowany tylko wtedy, gdy zostanie wykryta regresja wydajności w porównaniu z zachowaniem obciążenia bazy danych z ostatnich siedmiu dni. Ten problem z wydajnością jest wykrywany tylko wtedy, gdy statystycznie znaczący spadek wydajności występuje w porównaniu z poprzednim zachowaniem wydajności.
Rozwiązywanie problemów
Ten wykrywalny wzorzec wydajności wskazuje warunek po stronie klienta. Rozwiązywanie problemów jest wymagane w aplikacji po stronie klienta lub w sieci po stronie klienta. Dziennik diagnostyki generuje skróty zapytań i czas oczekiwania, które wydają się czekać najbardziej, aż klient będzie ich używać w ciągu ostatnich dwóch godzin. Te informacje mogą służyć jako podstawa rozwiązywania problemów.
Możesz zoptymalizować wydajność aplikacji pod kątem użycia tych zapytań. Możesz również rozważyć możliwe problemy z opóźnieniem sieci. Ponieważ problem z obniżeniem wydajności był oparty na zmianie w punkcie odniesienia wydajności z ostatnich siedmiu dni, możesz sprawdzić, czy ostatnie zmiany stanu aplikacji lub sieci spowodowały to zdarzenie regresji wydajności.
Obniżanie warstwy cenowej
Co się dzieje
Ten wykrywalny wzorzec wydajności wskazuje warunek, w którym warstwa cenowa subskrypcji bazy danych została obniżona. Ze względu na zmniejszenie ilości zasobów (DTU) dostępnych dla bazy danych system wykrył spadek wydajności bieżącej bazy danych w porównaniu z poprzednim siedmiodniowym punktem odniesienia.
Ponadto może istnieć warunek, w którym warstwa cenowa subskrypcji bazy danych została obniżona, a następnie uaktualniona do wyższej warstwy w krótkim czasie. Wykrywanie tego tymczasowego obniżenia wydajności jest zwracane w sekcji szczegółów dziennika diagnostyki jako obniżenie warstwy cenowej i uaktualnienie.
Rozwiązywanie problemów
Jeśli obniżono warstwę cenową, a zatem dostępne jednostki DTU i są zadowalające z wydajnością, nie trzeba nic robić. Jeśli obniżysz warstwę cenową i nie masz pewności co do wydajności bazy danych, zmniejsz obciążenia bazy danych lub rozważ zwiększenie warstwy cenowej na wyższy poziom.
Zalecany przepływ rozwiązywania problemów
Postępuj zgodnie z schematem blokowym, aby uzyskać zalecane podejście do rozwiązywania problemów z wydajnością przy użyciu inteligentnego Szczegółowe informacje.
Uzyskaj dostęp do inteligentnych Szczegółowe informacje za pośrednictwem witryny Azure Portal, przechodząc do usługi Azure SQL Analytics. Spróbuj zlokalizować przychodzący alert dotyczący wydajności i wybierz go. Zidentyfikuj, co się dzieje na stronie wykrywania. Obserwuj podaną główną przyczynę problemu, tekst zapytania, trendy czasu zapytania i ewolucję incydentu. Spróbuj rozwiązać ten problem, korzystając z zalecenia Intelligent Szczegółowe informacje w celu ograniczenia problemu z wydajnością.
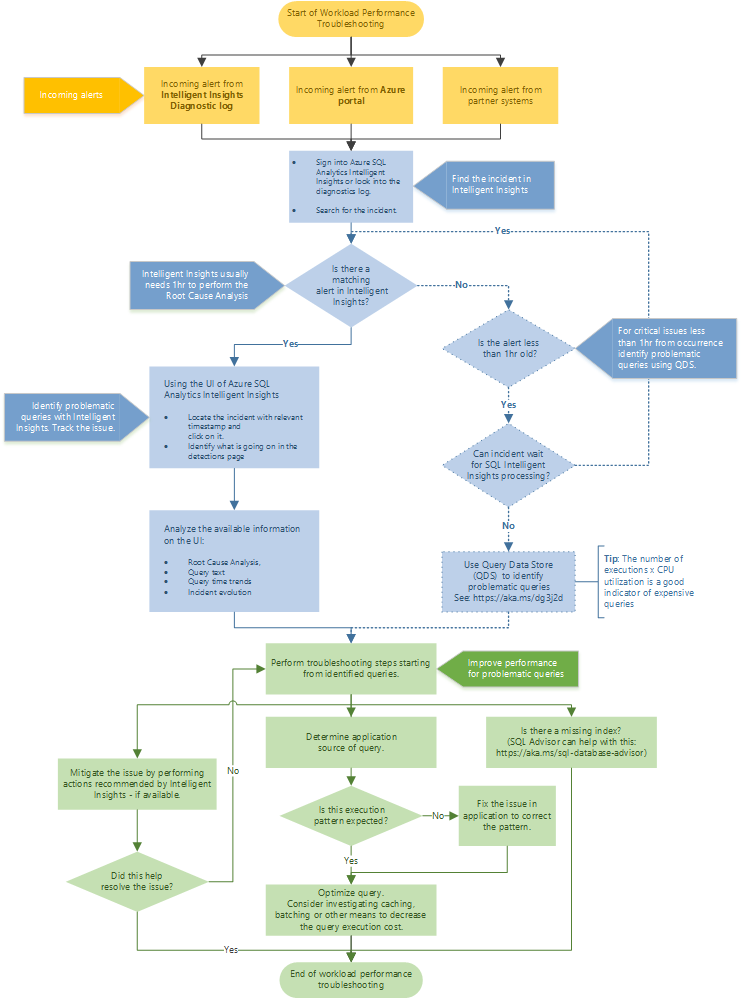
Napiwek
Wybierz schemat blokowy, aby pobrać wersję pliku PDF.
Inteligentne Szczegółowe informacje zwykle potrzebuje jednej godziny czasu, aby przeprowadzić analizę głównej przyczyny problemu z wydajnością. Jeśli nie możesz zlokalizować problemu w inteligentnym Szczegółowe informacje i ma to kluczowe znaczenie dla Ciebie, użyj magazynu zapytań, aby ręcznie zidentyfikować główną przyczynę problemu z wydajnością. (Zazwyczaj te problemy mają mniej niż jedną godzinę). Aby uzyskać więcej informacji, zobacz Monitorowanie wydajności przy użyciu magazynu zapytań.
Następne kroki
- Poznaj pojęcia dotyczące inteligentnych Szczegółowe informacje.
- Użyj dziennika diagnostyki wydajności inteligentnego Szczegółowe informacje.
- Monitorowanie przy użyciu usługi Azure SQL Analytics.
- Dowiedz się, jak zbierać i wykorzystywać dane dzienników z zasobów platformy Azure.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla