Dodawanie zestawu danych profesjonalnych szkoleń głosowych
Gdy wszystko będzie gotowe do utworzenia niestandardowego tekstu na głos mowy dla aplikacji, pierwszym krokiem jest zebranie nagrań audio i skojarzonych skryptów w celu rozpoczęcia trenowania modelu głosu. Aby uzyskać szczegółowe informacje na temat rejestrowania przykładów głosowych, zobacz samouczek. Usługa mowa używa tych danych do tworzenia unikatowego głosu dostrojonego w celu dopasowania głosu do nagrań. Po wytrenowaniu głosu możesz rozpocząć synchronizowanie mowy w aplikacjach.
Wszystkie przekazane dane muszą spełniać wymagania dotyczące wybranego typu danych. Ważne jest, aby poprawnie sformatować dane przed ich przekazaniem, co gwarantuje, że dane będą dokładnie przetwarzane przez usługę Rozpoznawanie mowy. Aby potwierdzić, że dane są poprawnie sformatowane, zobacz Trenowanie typów danych.
Uwaga
- Użytkownicy subskrypcji w warstwie Standardowa (S0) mogą jednocześnie przekazywać pięć plików danych. Jeśli osiągniesz limit, zaczekaj, aż co najmniej jeden z plików danych zakończy importowanie. Następnie spróbuj ponownie.
- Maksymalna liczba plików danych, które mogą być importowane na subskrypcję, to 500 .zip plików dla użytkowników standardowej subskrypcji (S0). Aby uzyskać więcej informacji, zobacz limity przydziału i limity usługi rozpoznawania mowy.
Przekazywanie danych
Gdy wszystko będzie gotowe do przekazania danych, przejdź do karty Przygotowywanie danych treningowych, aby dodać pierwszy zestaw treningowy i przekazać dane. Zestaw szkoleniowy to zestaw wypowiedzi audio i ich skrypty mapowania używane do trenowania modelu głosu. Zestaw szkoleniowy umożliwia organizowanie danych treningowych. Usługa sprawdza gotowość danych dla każdego zestawu treningowego. Możesz zaimportować wiele danych do zestawu treningowego.
Aby przekazać dane szkoleniowe, wykonaj następujące kroki:
- Zaloguj się do programu Speech Studio.
- Wybierz pozycję Niestandardowy głos> Nazwa >projektu Przygotowywanie danych treningowych Przekazywanie danych>.
- W kreatorze Przekazywania danych wybierz typ danych, a następnie wybierz przycisk Dalej.
- Wybierz pliki lokalne z komputera lub wprowadź adres URL usługi Azure Blob Storage, aby przekazać dane.
- W obszarze Określ docelowy zestaw trenowania wybierz istniejący zestaw treningowy lub utwórz nowy. Jeśli utworzono nowy zestaw szkoleniowy, przed kontynuowaniem upewnij się, że jest on wybrany na liście rozwijanej.
- Wybierz Dalej.
- Wprowadź nazwę i opis danych, a następnie wybierz pozycję Dalej.
- Przejrzyj szczegóły przekazywania i wybierz pozycję Prześlij.
Uwaga
Zduplikowane identyfikatory nie są akceptowane. Wypowiedzi o tym samym identyfikatorze zostaną usunięte.
Z trenowania są usuwane zduplikowane nazwy audio. Upewnij się, że wybrane dane nie zawierają tych samych nazw audio w pliku .zip ani w wielu plikach .zip. Jeśli identyfikatory wypowiedzi (w plikach audio lub skryptu) są duplikatami, są odrzucane.
Pliki danych są automatycznie weryfikowane po wybraniu pozycji Prześlij. Walidacja danych obejmuje serię kontroli plików audio w celu zweryfikowania ich formatu, rozmiaru i częstotliwości próbkowania. Jeśli występują jakiekolwiek błędy, napraw je i prześlij ponownie.
Po przekazaniu danych możesz sprawdzić szczegóły w widoku szczegółów zestawu trenowania. Na stronie szczegółów możesz dodatkowo sprawdzić problem z wymową i poziom szumu dla każdego z danych. Wynik wymowy na poziomie zdania waha się od 0 do 100. Wynik poniżej 70 zwykle wskazuje błąd mowy lub niezgodność skryptu. Wypowiedzi o ogólnym wyniku niższym niż 70 zostaną odrzucone. Duży akcent może zmniejszyć wynik wymowy i wpłynąć na wygenerowany głos cyfrowy.
Rozwiązywanie problemów z danymi w trybie online
Po przekazaniu możesz sprawdzić szczegóły danych zestawu treningowego. Przed kontynuowaniem trenowania modelu głosowego należy spróbować rozwiązać wszelkie problemy z danymi.
Możesz identyfikować i rozwiązywać problemy z danymi na wypowiedź w programie Speech Studio.
Na stronie szczegółów przejdź do strony Zaakceptowane dane lub Odrzucone dane . Wybierz poszczególne wypowiedzi, które chcesz zmienić, a następnie wybierz pozycję Edytuj.
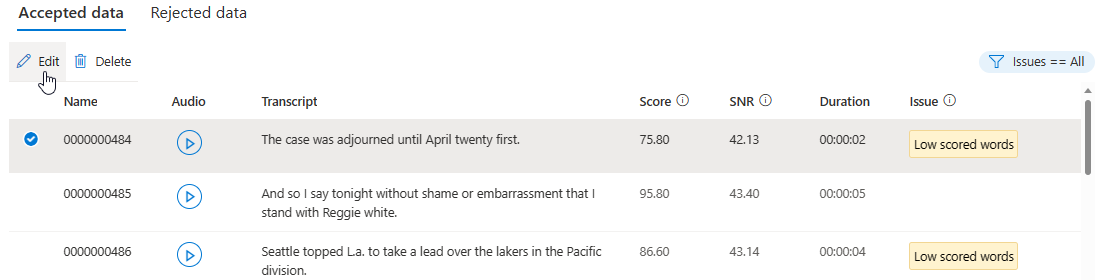
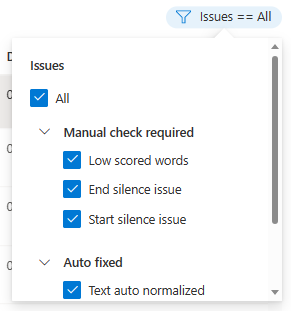
Możesz wybrać, które problemy z danymi mają być wyświetlane na podstawie kryteriów.
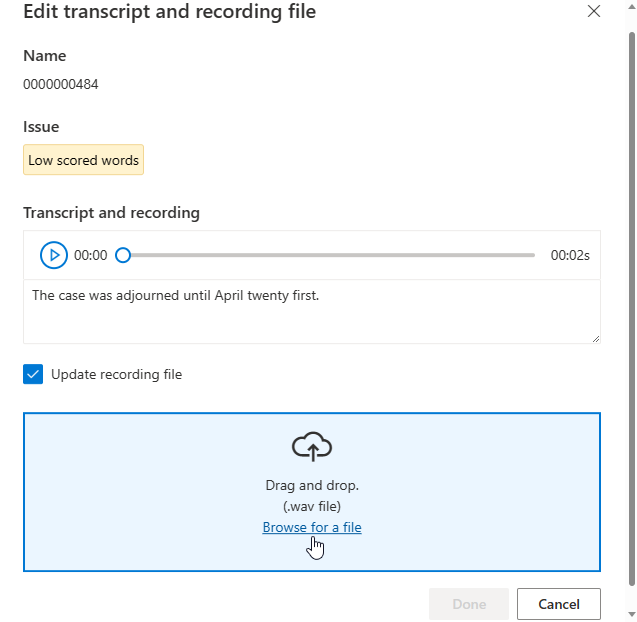
Zostanie wyświetlone okno edycji.
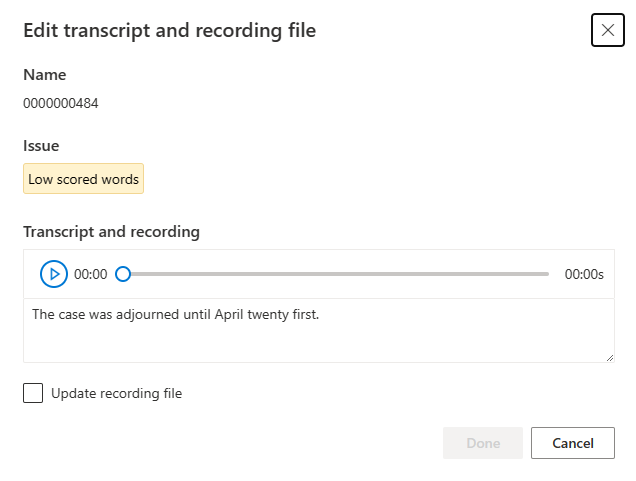
Zaktualizuj plik transkrypcji lub nagrywania zgodnie z opisem problemu w oknie edycji.
Możesz edytować transkrypcję w polu tekstowym, a następnie wybrać pozycję Gotowe
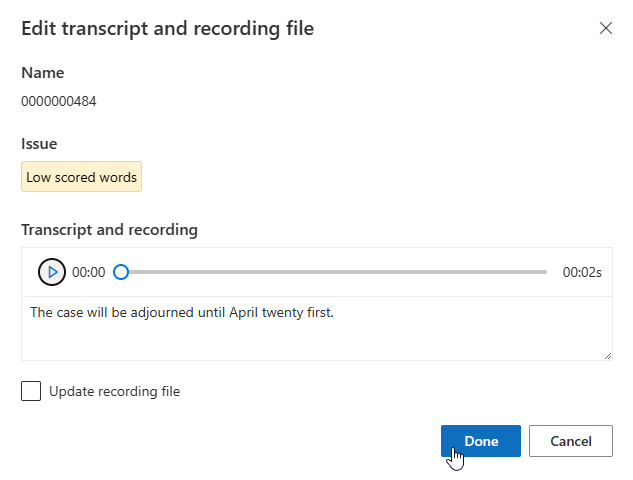
Jeśli chcesz zaktualizować plik nagrywania, wybierz pozycję Aktualizuj plik nagrywania, a następnie przekaż stały plik nagrywania (.wav).
Po wprowadzeniu zmian w danych należy sprawdzić jakość danych, klikając pozycję Analizuj dane przed użyciem tego zestawu danych do trenowania.
Nie można wybrać tego zestawu trenowania dla modelu trenowania przed ukończeniem analizy.
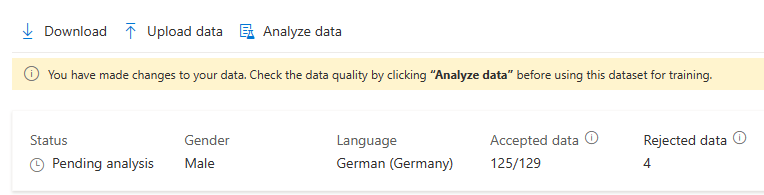
Możesz również usunąć wypowiedzi z problemami, wybierając je i klikając pozycję Usuń.
Typowe problemy z danymi
Problemy są podzielone na trzy typy. Zapoznaj się z poniższymi tabelami, aby sprawdzić odpowiednie typy błędów.
Automatycznie odrzucone
Dane z tymi błędami nie będą używane do trenowania. Zaimportowane dane z błędami zostaną zignorowane, więc nie trzeba ich usuwać. Te błędy danych można naprawić w trybie online lub ponownie przekazać poprawione dane na potrzeby trenowania.
| Kategoria | Nazwa/nazwisko | opis |
|---|---|---|
| Skrypt | Nieprawidłowy separator | Musisz oddzielić identyfikator wypowiedzi i zawartość skryptu znakiem Tab. |
| Skrypt | Nieprawidłowy identyfikator skryptu | Identyfikator wiersza skryptu musi być numeryczny. |
| Skrypt | Zduplikowany skrypt | Każdy wiersz zawartości skryptu musi być unikatowy. Wiersz jest duplikowany za pomocą polecenia {}. |
| Skrypt | Zbyt długi skrypt | Skrypt musi zawierać mniej niż 1000 znaków. |
| Skrypt | Brak pasującego dźwięku | Identyfikator każdej wypowiedzi (każdy wiersz pliku skryptu) musi być zgodny z identyfikatorem dźwięku. |
| Skrypt | Brak prawidłowego skryptu | W tym zestawie danych nie znaleziono prawidłowego skryptu. Napraw wiersze skryptu wyświetlane na liście szczegółowych problemów. |
| Audio | Brak pasującego skryptu | Żadne pliki dźwiękowe nie są zgodne z identyfikatorem skryptu. Nazwa plików .wav musi być zgodna z identyfikatorami w pliku skryptu. |
| Audio | Nieprawidłowy format audio | Format audio plików .wav jest nieprawidłowy. Sprawdź format pliku .wav przy użyciu narzędzia audio, takiego jak SoX. |
| Audio | Niska częstotliwość próbkowania | Częstotliwość próbkowania plików .wav nie może być niższa niż 16 KHz. |
| Audio | Za długi dźwięk | Czas trwania dźwięku jest dłuższy niż 30 sekund. Podziel długi dźwięk na wiele plików. Dobrym pomysłem jest utworzenie wypowiedzi krótszych niż 15 sekund. |
| Audio | Brak prawidłowego dźwięku | W tym zestawie danych nie znaleziono prawidłowego dźwięku. Sprawdź dane audio i przekaż ponownie. |
| Niezgodność | Niska ocena wypowiedzi | Wynik wymowy na poziomie zdania jest niższy niż 70. Przejrzyj skrypt i zawartość audio, aby upewnić się, że są one zgodne. |
Automatyczna naprawa
Następujące błędy są naprawiane automatycznie, ale należy przejrzeć i potwierdzić, że poprawki zostały wykonane poprawnie.
| Kategoria | Nazwa/nazwisko | opis |
|---|---|---|
| Niezgodność | Automatyczne wyciszenie | Wykryto, że cisza rozpoczęcia jest krótsza niż 100 ms i została przedłużona do 100 ms automatycznie. Pobierz znormalizowany zestaw danych i przejrzyj go. |
| Niezgodność | Automatyczne wyciszenie | Wykryto, że cisza końcowa jest krótsza niż 100 ms i została przedłużona do 100 ms automatycznie. Pobierz znormalizowany zestaw danych i przejrzyj go. |
| Skrypt | Auto znormalizowany tekst | Tekst jest automatycznie znormalizowany dla cyfr, symboli i skrótów. Przejrzyj skrypt i dźwięk, aby upewnić się, że są one zgodne. |
Wymagane jest ręczne sprawdzanie
Nierozwiązane błędy wymienione w następnej tabeli mają wpływ na jakość trenowania, ale dane z tymi błędami nie zostaną wykluczone podczas trenowania. W przypadku trenowania o wyższej jakości warto ręcznie naprawić te błędy.
| Kategoria | Nazwa/nazwisko | opis |
|---|---|---|
| Skrypt | Tekst nienormalizowany | Ten skrypt zawiera symbole. Normalizuj symbole, aby pasować do dźwięku. Na przykład normalizuj / ukośnik. |
| Skrypt | Za mało wypowiedzi pytań | Co najmniej 10 procent całkowitych wypowiedzi powinno być zdaniami pytań. Pomaga to modelowi głosowemu prawidłowo wyrazić ton pytania. |
| Skrypt | Za mało wykrzykników wypowiedzi | Co najmniej 10 procent wszystkich wypowiedzi powinno być wykrzyknikami. Pomaga to modelowi głosowemu prawidłowo wyrazić podekscytowany ton. |
| Skrypt | Brak prawidłowej interpunkcji końcowej | Dodaj jedną z następujących wartości na końcu wiersza: pełne zatrzymanie (pół szerokości '.' lub pełnej szerokości '。 '), wykrzyknik (pół szerokości '!' lub pełnowymiarowy '!' ), lub znak zapytania ( pół szerokości '?' lub pełnej szerokości '?'). |
| Audio | Niska częstotliwość próbkowania dla neuronowego głosu | Zaleca się, aby częstotliwość próbkowania plików .wav była 24 KHz lub wyższa do tworzenia neuronowych głosów. Jeśli jest niższa, zostanie ona automatycznie podniesiona do 24 KHz. |
| Objętość | Za mała ilość całkowitego woluminu | Wolumin nie powinien być mniejszy niż -18 dB (10 procent maksymalnego woluminu). Kontrolowanie średniego poziomu głośności w odpowiednim zakresie podczas przygotowywania próbek lub danych. |
| Objętość | Przepełnienie woluminu | Wykryto przepełnienie woluminu o godzinie {}s. Dostosuj sprzęt rejestrujący, aby uniknąć przepełnienia głośności przy szczytowej wartości. |
| Objętość | Rozpocznij problem z milczeniem | Pierwsze 100 ms ciszy nie jest czyste. Zmniejsz poziom podłogi hałasu nagrywania i pozostaw pierwsze 100 ms na początku dyskretnego. |
| Objętość | Problem z milczeniem końcowym | Ostatnie 100 ms ciszy nie jest czyste. Zmniejsz poziom podłogi hałasu nagrywania i pozostaw ostatnie 100 ms na końcu dyskretne. |
| Niezgodność | Wyrazy o niskich wynikach | Przejrzyj skrypt i zawartość audio, aby upewnić się, że są one zgodne, i kontrolować poziom podłogi szumu. Zmniejsz długość długiej ciszy lub podziel dźwięk na wiele wypowiedzi, jeśli jest za długi. |
| Niezgodność | Rozpocznij problem z milczeniem | Przed pierwszym słowem słychać było dodatkowe audio. Przejrzyj skrypt i zawartość audio, aby upewnić się, że są one zgodne, kontrolować poziom podłogi szumu i zrobić pierwsze 100 ms dyskretne. |
| Niezgodność | Problem z milczeniem końcowym | Dodatkowy dźwięk został wysłuchany po ostatnim słowie. Przejrzyj skrypt i zawartość audio, aby upewnić się, że są one zgodne, kontrolować poziom podłogi szumu i zrobić ostatnie 100 ms dyskretne. |
| Niezgodność | Niski współczynnik szumu sygnału | Poziom SNR dźwięku jest niższy niż 20 dB. Zalecane jest co najmniej 35 dB. |
| Niezgodność | Brak dostępnego wyniku | Nie można rozpoznać zawartości mowy w tym dźwięku. Sprawdź dźwięk i zawartość skryptu, aby upewnić się, że dźwięk jest prawidłowy i pasuje do skryptu. |
Następne kroki
Potrzebujesz zestawu danych szkoleniowych, aby utworzyć profesjonalny głos. Zestaw danych szkoleniowych zawiera pliki audio i skryptu. Pliki dźwiękowe są nagrania talentów głosowych odczytujących pliki skryptu. Pliki skryptów są tekstem plików audio.
W tym artykule utworzysz zestaw szkoleniowy i uzyskasz jego identyfikator zasobu. Następnie przy użyciu identyfikatora zasobu można przekazać zestaw plików audio i script.
Tworzenie zestawu treningowego
Aby utworzyć zestaw szkoleniowy, użyj TrainingSets_Create operacji niestandardowego interfejsu API głosu. Skonstruuj treść żądania zgodnie z następującymi instrukcjami:
- Ustaw wymaganą
projectIdwłaściwość. Zobacz Tworzenie projektu. - Ustaw wymaganą
voiceKindwłaściwość naMalelubFemale. Nie można później zmienić rodzaju. - Ustaw wymaganą
localewłaściwość. Powinny to być ustawienia regionalne danych zestawu treningowego. Ustawienia regionalne zestawu szkoleniowego powinny być takie same jak ustawienia regionalne instrukcji zgody. Nie można później zmienić ustawień regionalnych. Tekst na liście ustawień regionalnych mowy można znaleźć tutaj. - Opcjonalnie ustaw
descriptionwłaściwość dla opisu zestawu treningowego. Opis zestawu treningowego można zmienić później.
Utwórz żądanie HTTP PUT przy użyciu identyfikatora URI, jak pokazano w poniższym przykładzie TrainingSets_Create .
- Zastąp
YourResourceKeyciąg kluczem zasobu usługi Mowa. - Zastąp
YourResourceRegionelement regionem zasobu usługi Mowa. - Zastąp
JessicaTrainingSetIdelement wybranym identyfikatorem zestawu treningowego. Identyfikator uwzględniający wielkość liter będzie używany w identyfikatorze URI zestawu treningowego i nie można go później zmienić.
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"description": "300 sentences Jessica data in general style.",
"projectId": "ProjectId",
"locale": "en-US",
"voiceKind": "Female"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/trainingsets/JessicaTrainingSetId?api-version=2023-12-01-preview"
Treść odpowiedzi powinna zostać wyświetlona w następującym formacie:
{
"id": "JessicaTrainingSetId",
"description": "300 sentences Jessica data in general style.",
"projectId": "ProjectId",
"locale": "en-US",
"voiceKind": "Female",
"status": "Succeeded",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Przekazywanie danych zestawu treningowego
Aby przekazać zestaw szkoleniowy audio i skryptów, użyj TrainingSets_UploadData operacji niestandardowego interfejsu API głosu.
Przed wywołaniem tego interfejsu API zapisz pliki nagrywania i skryptów w usłudze Azure Blob. W poniższym przykładzie pliki rejestrowania to https://contoso.blob.core.windows.net/voicecontainer/jessica300/*.wav, pliki skryptu to https://contoso.blob.core.windows.net/voicecontainer/jessica300/*.txt.
Skonstruuj treść żądania zgodnie z następującymi instrukcjami:
- Ustaw wymaganą
kindwłaściwość naAudioAndScript. Rodzaj określa typ zestawu treningowego. - Ustaw wymaganą
audioswłaściwość. W ramachaudioswłaściwości ustaw następujące właściwości:- Ustaw wymaganą
containerUrlwłaściwość na adres URL kontenera usługi Azure Blob Storage, który zawiera pliki audio. Użyj sygnatur dostępu współdzielonego (SAS) dla kontenera z uprawnieniami do odczytu i listy. - Ustaw wymaganą
extensionswłaściwość na rozszerzenia plików audio. - Opcjonalnie ustaw właściwość , aby ustawić
prefixprefiks nazwy obiektu blob.
- Ustaw wymaganą
- Ustaw wymaganą
scriptswłaściwość. W ramachscriptswłaściwości ustaw następujące właściwości:- Ustaw wymaganą
containerUrlwłaściwość na adres URL kontenera usługi Azure Blob Storage, który zawiera pliki skryptów. Użyj sygnatur dostępu współdzielonego (SAS) dla kontenera z uprawnieniami do odczytu i listy. - Ustaw wymaganą
extensionswłaściwość na rozszerzenia plików skryptów. - Opcjonalnie ustaw właściwość , aby ustawić
prefixprefiks nazwy obiektu blob.
- Ustaw wymaganą
Utwórz żądanie HTTP POST przy użyciu identyfikatora URI, jak pokazano w poniższym przykładzie TrainingSets_UploadData .
- Zastąp
YourResourceKeyciąg kluczem zasobu usługi Mowa. - Zastąp
YourResourceRegionelement regionem zasobu usługi Mowa. - Zastąp wartość
JessicaTrainingSetId, jeśli w poprzednim kroku określono inny identyfikator zestawu treningowego.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"kind": "AudioAndScript",
"audios": {
"containerUrl": "https://contoso.blob.core.windows.net/voicecontainer?mySasToken",
"prefix": "jessica300/",
"extensions": [
".wav"
]
},
"scripts": {
"containerUrl": "https://contoso.blob.core.windows.net/voicecontainer?mySasToken",
"prefix": "jessica300/",
"extensions": [
".txt"
]
}
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/trainingsets/JessicaTrainingSetId:upload?api-version=2023-12-01-preview"
Nagłówek odpowiedzi zawiera Operation-Location właściwość . Użyj tego identyfikatora URI, aby uzyskać szczegółowe informacje o operacji TrainingSets_UploadData . Oto przykład nagłówka odpowiedzi:
Operation-Location: https://eastus.api.cognitive.microsoft.com/customvoice/operations/284b7e37-f42d-4054-8fa9-08523c3de345?api-version=2023-12-01-preview
Operation-Id: 284b7e37-f42d-4054-8fa9-08523c3de345