Włączanie konfiguracji dostępu do danych
W tym artykule opisano konfiguracje dostępu do danych wykonywane przez administratorów usługi Azure Databricks dla wszystkich magazynów SQL przy użyciu interfejsu użytkownika.
Uwaga
Jeśli obszar roboczy jest włączony dla wykazu aparatu Unity, nie musisz wykonywać kroków opisanych w tym artykule. Katalog aparatu Unity domyślnie obsługuje magazyny SQL.
Usługa Databricks zaleca używanie woluminów wykazu aparatu Unity lub lokalizacji zewnętrznych do łączenia się z magazynem obiektów w chmurze zamiast profilów wystąpień. Wykaz aparatu Unity upraszcza zabezpieczenia i nadzór nad danymi, zapewniając centralne miejsce do administrowania i inspekcji dostępu do danych w wielu obszarach roboczych na twoim koncie. Zobacz Co to jest wykaz aparatu Unity? i Rekomendacje na potrzeby korzystania z lokalizacji zewnętrznych.
Aby skonfigurować wszystkie magazyny SQL przy użyciu interfejsu API REST, zobacz interfejs API usługi SQL Warehouses.
Ważne
Zmiana tych ustawień powoduje ponowne uruchomienie wszystkich uruchomionych magazynów SQL.
Aby zapoznać się z ogólnym omówieniem sposobu włączania dostępu do danych, zobacz Listy kontroli dostępu.
Wymagania
- Aby skonfigurować ustawienia dla wszystkich magazynów SQL, musisz być administratorem obszaru roboczego usługi Azure Databricks.
Konfigurowanie jednostki usługi
Aby skonfigurować dostęp dla magazynów SQL do konta magazynu usługi Azure Data Lake Storage Gen2 przy użyciu jednostek usługi, wykonaj następujące kroki:
Zarejestruj aplikację Microsoft Entra ID (dawniej Azure Active Directory) i zarejestruj następujące właściwości:
- Identyfikator aplikacji (klienta): identyfikator, który jednoznacznie identyfikuje aplikację Microsoft Entra ID (dawniej Azure Active Directory).
- Identyfikator katalogu (dzierżawy): identyfikator, który jednoznacznie identyfikuje wystąpienie identyfikatora entra firmy Microsoft (nazywane identyfikatorem katalogu (dzierżawy) w usłudze Azure Databricks).
- Klucz tajny klienta: wartość wpisu tajnego klienta utworzonego na potrzeby tej rejestracji aplikacji. Aplikacja użyje tego ciągu wpisu tajnego, aby udowodnić swoją tożsamość.
Na koncie magazynu dodaj przypisanie roli dla aplikacji zarejestrowanej w poprzednim kroku, aby zapewnić mu dostęp do konta magazynu.
Utwórz zakres wpisów tajnych opartych na usłudze Azure Key Vault lub zakres wpisu tajnego o zakresie usługi Databricks i zarejestruj wartość właściwości nazwy zakresu:
- Nazwa zakresu: nazwa utworzonego zakresu wpisu tajnego.
W przypadku korzystania z usługi Azure Key Vault przejdź do sekcji Wpisy tajne i Zobacz Tworzenie wpisu tajnego w zakresie opartym na usłudze Azure Key Vault. Następnie użyj klucza tajnego klienta uzyskanego w kroku 1, aby wypełnić pole "wartość" tego wpisu tajnego. Zachowaj rekord wybranej nazwy wpisu tajnego.
- Nazwa wpisu tajnego: nazwa utworzonego wpisu tajnego usługi Azure Key Vault.
W przypadku korzystania z zakresu opartego na usłudze Databricks utwórz nowy wpis tajny przy użyciu interfejsu wiersza polecenia usługi Databricks i użyj go do przechowywania klucza tajnego klienta uzyskanego w kroku 1. Zachowaj rekord klucza tajnego wprowadzonego w tym kroku.
- Klucz tajny: klucz utworzonego wpisu tajnego opartego na usłudze Databricks.
Uwaga
Opcjonalnie możesz utworzyć dodatkowy wpis tajny do przechowywania identyfikatora klienta uzyskanego w kroku 1.
Kliknij swoją nazwę użytkownika na górnym pasku obszaru roboczego i wybierz pozycję Ustawienia z listy rozwijanej.
Kliknij kartę Obliczenia .
Kliknij pozycję Zarządzaj obok pozycji Magazyny SQL.
W polu Konfiguracja dostępu do danych kliknij przycisk Dodaj jednostkę usługi .
Skonfiguruj właściwości konta magazynu usługi Azure Data Lake Storage Gen2.
Kliknij przycisk Dodaj.
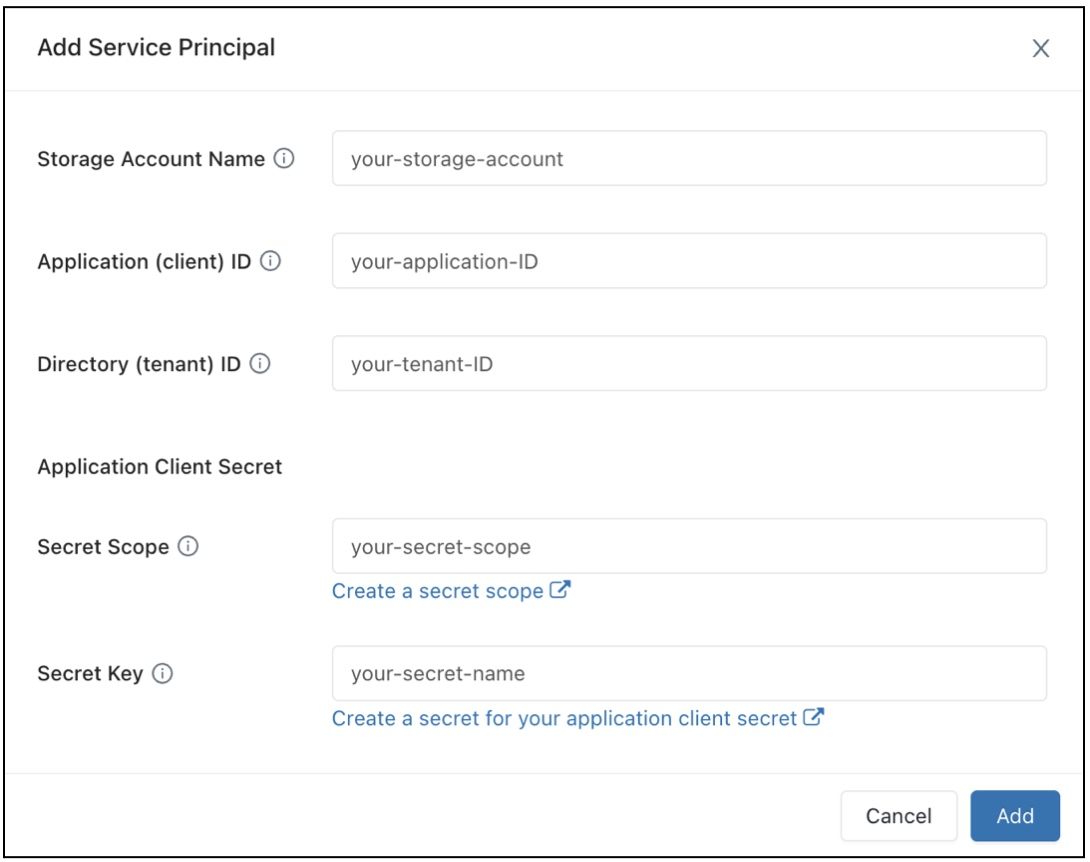
Zobaczysz, że nowe wpisy zostały dodane do pola tekstowego Konfiguracja dostępu do danych.
Kliknij przycisk Zapisz.
Możesz również edytować wpisy w polu tekstowym Konfiguracja dostępu do danych bezpośrednio.
Konfigurowanie właściwości dostępu do danych dla magazynów SQL
Aby skonfigurować wszystkie magazyny z właściwościami dostępu do danych:
Kliknij swoją nazwę użytkownika na górnym pasku obszaru roboczego i wybierz pozycję Ustawienia z listy rozwijanej.
Kliknij kartę Obliczenia .
Kliknij pozycję Zarządzaj obok pozycji Magazyny SQL.
W polu tekstowym Konfiguracja dostępu do danych określ pary klucz-wartość zawierające właściwości magazynu metadanych.
Ważne
Aby ustawić właściwość konfiguracji platformy Spark na wartość wpisu tajnego bez uwidaczniania wartości wpisu tajnego na platformę Spark, ustaw wartość na
{{secrets/<secret-scope>/<secret-name>}}. Zastąp<secret-scope>ciąg zakresem wpisu tajnego i<secret-name>nazwą wpisu tajnego. Wartość musi zaczynać się od i kończyć{{secrets/ciągiem}}. Aby uzyskać więcej informacji na temat tej składni, zobacz Składnia odwoływania się do wpisów tajnych we właściwości konfiguracji platformy Spark lub zmiennej środowiskowej.Kliknij przycisk Zapisz.
Możesz również skonfigurować właściwości dostępu do danych przy użyciu dostawcy narzędzia Terraform usługi Databricks i databricks_sql_global_config.
Obsługiwane właściwości
W przypadku wpisu kończącego się ciągiem
*, obsługiwane są wszystkie właściwości w ramach tego prefiksu.Na przykład wskazuje,
spark.sql.hive.metastore.*że obiespark.sql.hive.metastore.jarsispark.sql.hive.metastore.versionsą obsługiwane, oraz wszelkie inne właściwości rozpoczynające się odspark.sql.hive.metastore.W przypadku właściwości, których wartości zawierają informacje poufne, można przechowywać poufne informacje w wpisie tajnym i ustawić wartość właściwości na nazwę wpisu tajnego przy użyciu następującej składni:
secrets/<secret-scope>/<secret-name>.
Następujące właściwości są obsługiwane w przypadku magazynów SQL:
spark.sql.hive.metastore.*spark.sql.warehouse.dirspark.hadoop.datanucleus.*spark.hadoop.fs.*spark.hadoop.hive.*spark.hadoop.javax.jdo.option.*spark.hive.*
Aby uzyskać więcej informacji na temat ustawiania tych właściwości, zobacz Zewnętrzny magazyn metadanych Programu Hive.