Tworzenie aplikacji platformy Apache Spark dla klastra usługi HDInsight przy użyciu zestawu narzędzi Azure Toolkit for Eclipse
Użyj narzędzi HDInsight Tools in Azure Toolkit for Eclipse , aby tworzyć aplikacje platformy Apache Spark napisane w języku Scala i przesyłać je do klastra Spark usługi Azure HDInsight bezpośrednio ze środowiska IDE środowiska Eclipse. Możesz użyć wtyczki HDInsight Tools na kilka różnych sposobów:
- Aby utworzyć i przesłać aplikację Scala Spark w klastrze Spark usługi HDInsight.
- Aby uzyskać dostęp do zasobów klastra Platformy Spark w usłudze Azure HDInsight.
- Aby utworzyć i uruchomić lokalnie aplikację Scala Spark.
Wymagania wstępne
Klaster Apache Spark w usłudze HDInsight. Aby uzyskać instrukcje, zobacz Tworzenie klastra platformy Apache Spark w usłudze Azure HDInsight.
Środowisko IDE środowiska Eclipse. W tym artykule użyto środowiska Eclipse IDE dla deweloperów języka Java.
Instalowanie wymaganych wtyczek
Instalowanie zestawu Azure Toolkit for Eclipse
Aby uzyskać instrukcje dotyczące instalacji, zobacz Instalowanie zestawu narzędzi Azure Toolkit for Eclipse.
Instalowanie wtyczki Scala
Po otwarciu środowiska Eclipse narzędzia HDInsight Tools automatycznie wykrywają, czy zainstalowano wtyczkę Scala. Wybierz przycisk OK , aby kontynuować, a następnie postępuj zgodnie z instrukcjami, aby zainstalować wtyczkę z witryny Eclipse Marketplace. Uruchom ponownie środowisko IDE po zakończeniu instalacji.
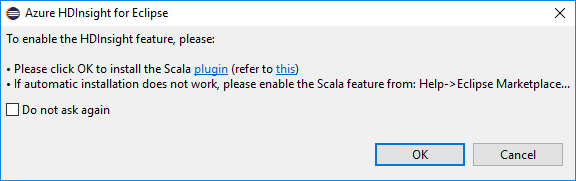
Potwierdzanie wtyczek
Przejdź do pozycji Pomoc>w witrynie Eclipse Marketplace....
Wybierz kartę Zainstalowano.
Powinien zostać wyświetlony co najmniej:
- Zestaw narzędzi Azure Toolkit for Eclipse <w wersji>.
- Wersja> środowiska IDE <języka Scala.
Zaloguj się do Twojej subskrypcji platformy Azure.
Uruchom środowisko ECLIPSE IDE.
Przejdź do okna>Pokaż widok>inny...>Zaloguj się...
W oknie dialogowym Pokaż widok przejdź do usługi Azure Azure>Explorer, a następnie wybierz pozycję Otwórz.

W eksploratorze platformy Azure kliknij prawym przyciskiem myszy węzeł platformy Azure, a następnie wybierz pozycję Zaloguj.
W oknie dialogowym Logowanie do platformy Azure wybierz metodę uwierzytelniania, wybierz pozycję Zaloguj i zakończ proces logowania.
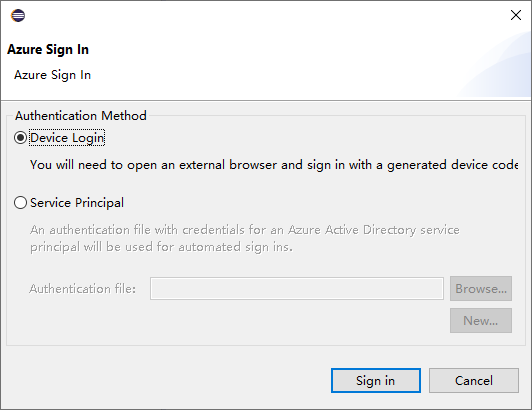
Po zalogowaniu okno dialogowe Subskrypcje zawiera listę wszystkich subskrypcji platformy Azure skojarzonych z poświadczeniami. Naciśnij przycisk Wybierz , aby zamknąć okno dialogowe.
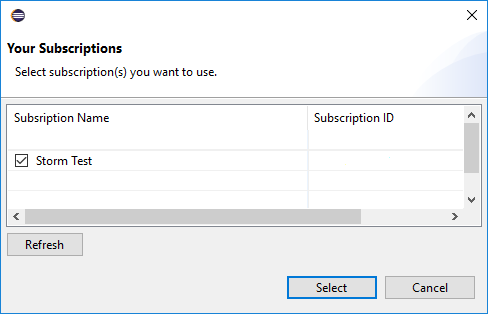
W programie Azure Explorer przejdź do usługi Azure HDInsight, aby wyświetlić klastry Spark usługi>HDInsight w ramach subskrypcji.
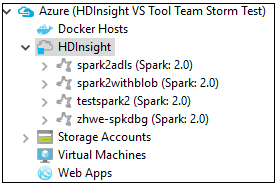
Możesz dodatkowo rozwinąć węzeł nazwy klastra, aby wyświetlić zasoby (na przykład konta magazynu) skojarzone z klastrem.
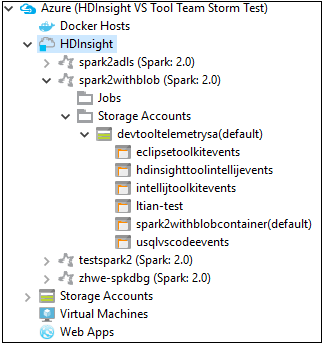
Łączenie klastra
Klaster normalny można połączyć przy użyciu zarządzanej nazwy użytkownika systemu Ambari. Podobnie w przypadku klastra usługi HDInsight przyłączonego do domeny można połączyć za pomocą domeny i nazwy użytkownika, takiej jak user1@contoso.com.
W eksploratorze platformy Azure kliknij prawym przyciskiem myszy pozycję HDInsight, a następnie wybierz pozycję Połącz klaster.
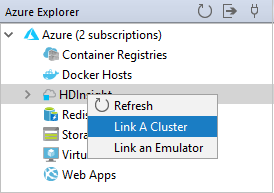
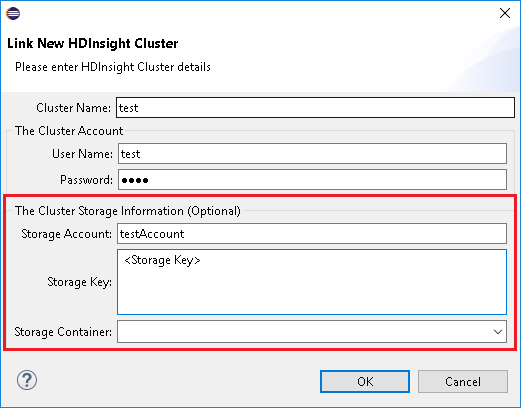
Wprowadź nazwę klastra, nazwę użytkownika i hasło, a następnie wybierz przycisk OK. Opcjonalnie wprowadź wartość Konto magazynu, Klucz magazynu, a następnie wybierz pozycję Kontener magazynu, aby eksplorator magazynu działał w widoku drzewa po lewej stronie

Uwaga
Używamy połączonego klucza magazynu, nazwy użytkownika i hasła, jeśli klaster jest zarówno zalogowany w subskrypcji platformy Azure, jak i połączony klaster.
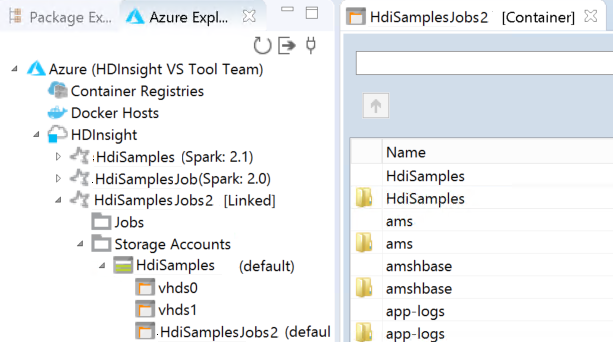
W przypadku tylko użytkownika klawiatury, gdy bieżący fokus znajduje się na kluczu magazynu, należy użyć klawisza Ctrl+TAB , aby skoncentrować się na następnym polu w oknie dialogowym.
Połączony klaster można zobaczyć w usłudze HDInsight. Teraz możesz przesłać aplikację do tego połączonego klastra.
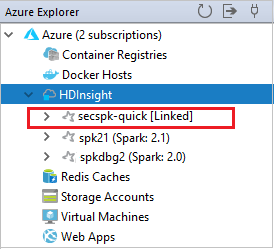
Możesz również odłączyć klaster z poziomu eksploratora platformy Azure.
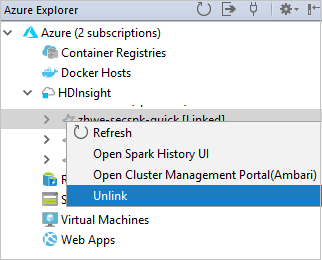
Konfigurowanie projektu Spark Scala dla klastra SPARK w usłudze HDInsight
W obszarze roboczym Eclipse IDE wybierz pozycję Plik>nowy>projekt....
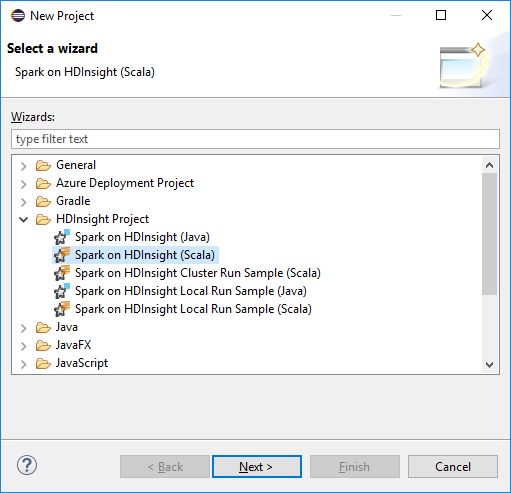
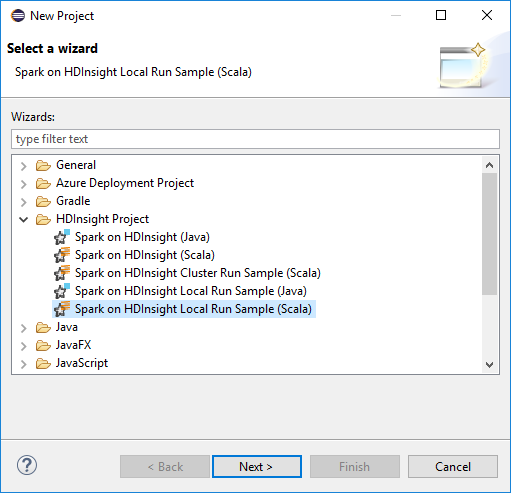
W kreatorze Nowy projekt wybierz pozycję HdInsight Project>Spark w usłudze HDInsight (Scala). Następnie kliknij przycisk Dalej.
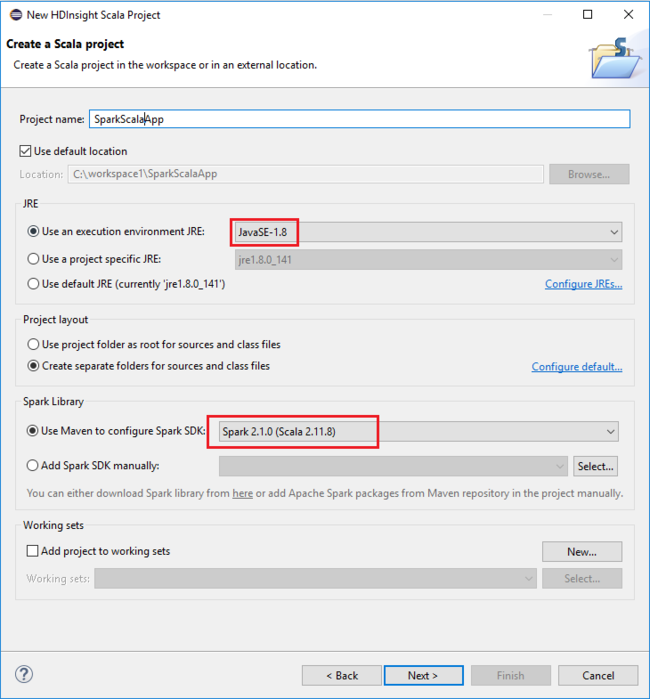
W oknie dialogowym Nowy projekt scala usługi HDInsight podaj następujące wartości, a następnie wybierz pozycję Dalej:
- Wprowadź nazwę dla projektu.
- W obszarze ŚRODOWISKA JRE upewnij się, że ustawienie Użyj środowiska wykonawczego JRE ma wartość JavaSE-1.7 lub nowsza.
- W obszarze Biblioteka platformy Spark możesz wybrać opcję Użyj narzędzia Maven, aby skonfigurować zestaw Spark SDK. Nasze narzędzie integruje odpowiednią wersję zestawu Spark SDK i zestawu Scala SDK. Możesz również ręcznie wybrać opcję Dodaj zestaw SDK platformy Spark, pobrać i dodać zestaw Spark SDK.
W następnym oknie dialogowym przejrzyj szczegóły, a następnie wybierz pozycję Zakończ.
Tworzenie aplikacji Scala dla klastra Spark usługi HDInsight
W Eksploratorze pakietów rozwiń utworzony wcześniej projekt. Kliknij prawym przyciskiem myszy pozycję src, wybierz pozycję Nowy>inny....
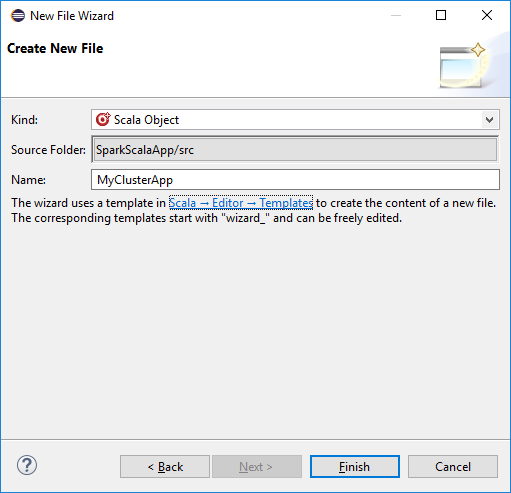
W oknie dialogowym Wybieranie kreatora wybierz pozycję Scala Wizards Scala Object (Kreatorzy>scala). Następnie kliknij przycisk Dalej.
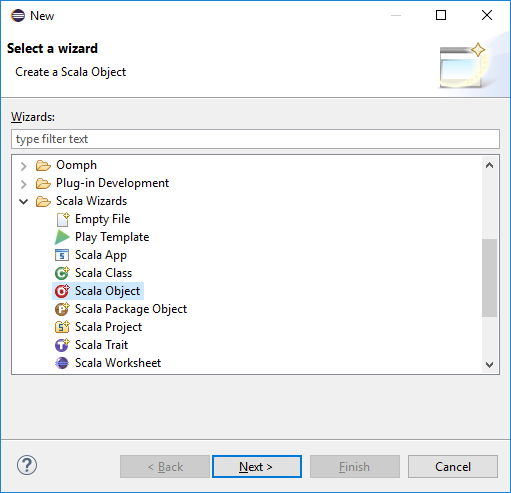
W oknie dialogowym Tworzenie nowego pliku wprowadź nazwę obiektu, a następnie wybierz pozycję Zakończ. Zostanie otwarty edytor tekstów.
W edytorze tekstów zastąp bieżącą zawartość poniższym kodem:
import org.apache.spark.SparkConf import org.apache.spark.SparkContext object MyClusterApp{ def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("MyClusterApp") val sc = new SparkContext(conf) val rdd = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows that have only one digit in the seventh column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasbs:///HVACOut") } }Uruchom aplikację w klastrze spark usługi HDInsight:
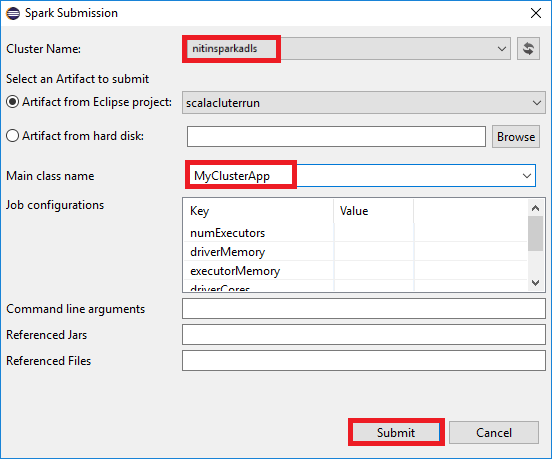
a. W Eksploratorze pakietów kliknij prawym przyciskiem myszy nazwę projektu, a następnie wybierz pozycję Prześlij aplikację Spark do usługi HDInsight.
b. W oknie dialogowym Przesyłanie platformy Spark podaj następujące wartości, a następnie wybierz pozycję Prześlij:
W polu Nazwa klastra wybierz klaster SPARK usługi HDInsight, na którym chcesz uruchomić aplikację.
Wybierz artefakt z projektu Eclipse lub wybierz go z dysku twardego. Wartość domyślna zależy od elementu, który klikniesz prawym przyciskiem myszy w Eksploratorze pakietów.
Na liście rozwijanej Nazwa klasy Main kreator przesyłania wyświetla wszystkie nazwy obiektów z projektu. Wybierz lub wprowadź ten, który chcesz uruchomić. Jeśli wybrano artefakt z dysku twardego, musisz ręcznie wprowadzić nazwę klasy głównej.
Ponieważ kod aplikacji w tym przykładzie nie wymaga żadnych argumentów wiersza polecenia ani odwołaj się do żądań JAR lub plików, możesz pozostawić pozostałe pola tekstowe puste.
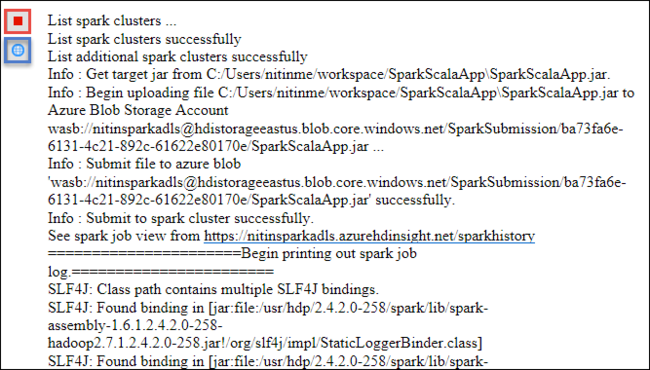
Karta Przesyłanie platformy Spark powinna rozpocząć wyświetlanie postępu. Aplikację można zatrzymać, wybierając czerwony przycisk w oknie Przesyłanie platformy Spark. Możesz również wyświetlić dzienniki dla tej konkretnej aplikacji, wybierając ikonę globusa (oznaczona niebieskim polem na obrazie).
Uzyskiwanie dostępu do klastrów Platformy Spark w usłudze HDInsight i zarządzanie nimi przy użyciu narzędzi HDInsight w zestawie narzędzi Azure Toolkit for Eclipse
Różne operacje można wykonywać przy użyciu narzędzi USŁUGI HDInsight, w tym uzyskiwania dostępu do danych wyjściowych zadania.
Uzyskiwanie dostępu do widoku zadania
W programie Azure Explorer rozwiń węzeł HDInsight, a następnie nazwę klastra Spark, a następnie wybierz pozycję Zadania.
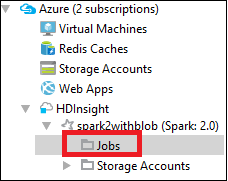
Wybierz węzeł Zadania. Jeśli wersja języka Java jest niższa niż 1.8, narzędzia HDInsight Tools automatycznie przypominają o zainstalowaniu wtyczki E(fx)clipse . Wybierz przycisk OK , aby kontynuować, a następnie postępuj zgodnie z kreatorem, aby zainstalować go z witryny Eclipse Marketplace i ponownie uruchomić środowisko Eclipse.
Otwórz widok zadania w węźle Zadania . W okienku po prawej stronie na karcie Widok zadania platformy Spark są wyświetlane wszystkie aplikacje, które zostały uruchomione w klastrze. Wybierz nazwę aplikacji, dla której chcesz wyświetlić więcej szczegółów.

Następnie możesz wykonać dowolną z tych akcji:
Zatrzymaj wskaźnik myszy na grafie zadania. Wyświetla podstawowe informacje o uruchomionym zadaniu. Wybierz wykres zadania i zobaczysz etapy i informacje generowane przez każde zadanie.
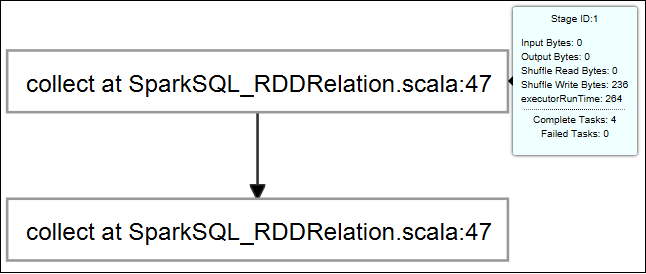
Wybierz kartę Dziennik , aby wyświetlić często używane dzienniki, w tym Driver Stderr, Driver Stdout i Directory Info.

Otwórz interfejs użytkownika historii platformy Spark i interfejs użytkownika usługi Apache Hadoop YARN (na poziomie aplikacji), wybierając hiperlinki w górnej części okna.
Uzyskiwanie dostępu do kontenera magazynu dla klastra
W programie Azure Explorer rozwiń węzeł główny usługi HDInsight , aby wyświetlić listę dostępnych klastrów spark usługi HDInsight.
Rozwiń nazwę klastra, aby wyświetlić konto magazynu i domyślny kontener magazynu dla klastra.
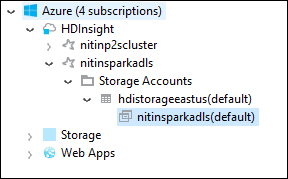
Wybierz nazwę kontenera magazynu skojarzona z klastrem. W okienku po prawej stronie kliknij dwukrotnie folder HVACOut . Otwórz jeden z plików części, aby wyświetlić dane wyjściowe aplikacji.
Uzyskiwanie dostępu do serwera historii platformy Spark
W eksploratorze platformy Azure kliknij prawym przyciskiem myszy nazwę klastra Spark, a następnie wybierz pozycję Otwórz interfejs użytkownika historii platformy Spark. Po wyświetleniu monitu wprowadź poświadczenia administratora dla klastra. Określono je podczas aprowizacji klastra.
Na pulpicie nawigacyjnym serwera historii platformy Spark użyjesz nazwy aplikacji, aby wyszukać właśnie uruchomioną aplikację. W poprzednim kodzie należy ustawić nazwę aplikacji przy użyciu polecenia
val conf = new SparkConf().setAppName("MyClusterApp"). Dlatego nazwa aplikacji platformy Spark to MyClusterApp.
Uruchamianie portalu Apache Ambari
W eksploratorze platformy Azure kliknij prawym przyciskiem myszy nazwę klastra Spark, a następnie wybierz polecenie Otwórz portal zarządzania klastrem (Ambari).
Po wyświetleniu monitu wprowadź poświadczenia administratora dla klastra. Określono je podczas aprowizacji klastra.
Zarządzanie subskrypcjami platformy Azure
Domyślnie narzędzie HDInsight w zestawie narzędzi Azure Toolkit for Eclipse wyświetla listę klastrów Spark ze wszystkich subskrypcji platformy Azure. W razie potrzeby możesz określić subskrypcje, dla których chcesz uzyskać dostęp do klastra.
W eksploratorze platformy Azure kliknij prawym przyciskiem myszy węzeł główny platformy Azure , a następnie wybierz pozycję Zarządzaj subskrypcjami.
W oknie dialogowym wyczyść pola wyboru subskrypcji, do której nie chcesz uzyskać dostępu, a następnie wybierz pozycję Zamknij. Możesz również wybrać pozycję Wyloguj się , jeśli chcesz wylogować się z subskrypcji platformy Azure.
Lokalne uruchamianie aplikacji Spark Scala
Narzędzia HDInsight Tools w zestawie narzędzi Azure Toolkit for Eclipse umożliwiają uruchamianie aplikacji Spark Scala lokalnie na stacji roboczej. Zazwyczaj te aplikacje nie potrzebują dostępu do zasobów klastra, takich jak kontener magazynu, i można je uruchamiać i testować lokalnie.
Warunek wstępny
Podczas uruchamiania lokalnej aplikacji Spark Scala na komputerze z systemem Windows może wystąpić wyjątek, jak wyjaśniono w artykule SPARK-2356. Ten wyjątek występuje, ponieważ w systemie Windows brakuje WinUtils.exe .
Aby rozwiązać ten błąd, musisz Winutils.exe do lokalizacji, takiej jak C:\WinUtils\bin, a następnie dodać zmienną środowiskową HADOOP_HOME i ustawić wartość zmiennej na C\WinUtils.
Uruchamianie lokalnej aplikacji Spark Scala
Uruchom środowisko Eclipse i utwórz projekt. W oknie dialogowym Nowy projekt wybierz następujące opcje, a następnie wybierz przycisk Dalej.
W kreatorze Nowy projekt wybierz pozycję HdInsight Project>Spark on HDInsight Local Run Sample (Scala). Następnie kliknij przycisk Dalej.
Aby podać szczegóły projektu, wykonaj kroki od 3 do 6 z wcześniejszej sekcji Konfigurowanie projektu Spark Scala dla klastra Spark w usłudze HDInsight.
Szablon dodaje przykładowy kod (LogQuery) w folderze src , który można uruchomić lokalnie na komputerze.
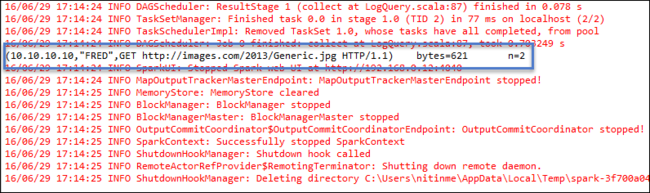
Kliknij prawym przyciskiem myszy pozycję LogQuery.scala i wybierz polecenie Uruchom jako>1 aplikację scala. Dane wyjściowe podobne do tych są wyświetlane na karcie Konsola :
Rola tylko dla czytelnika
Gdy użytkownicy przesyłają zadanie do klastra z uprawnieniami roli tylko dla czytelnika, wymagane są poświadczenia systemu Ambari.
Łączenie klastra z menu kontekstowego
Zaloguj się przy użyciu konta roli tylko dla czytelnika.
W programie Azure Explorer rozwiń węzeł HDInsight, aby wyświetlić klastry usługi HDInsight , które znajdują się w twojej subskrypcji. Klastry oznaczone jako "Role:Reader" mają uprawnienia tylko do roli tylko czytelnika.

Kliknij prawym przyciskiem myszy klaster z uprawnieniem tylko do odczytu. Wybierz pozycję Połącz ten klaster z menu kontekstowego, aby połączyć klaster. Wprowadź nazwę użytkownika i hasło systemu Ambari.

Jeśli klaster zostanie pomyślnie połączony, usługa HDInsight zostanie odświeżona. Etap klastra zostanie połączony.
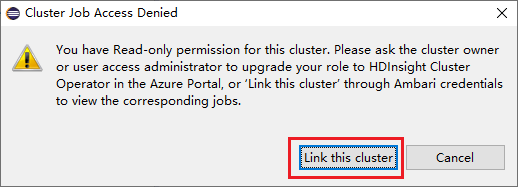
Łączenie klastra przez rozwinięcie węzła Zadania
Kliknij węzeł Zadania , zostanie wyświetlone okno Odmowa dostępu do zadań klastra .
Kliknij pozycję Połącz ten klaster , aby połączyć klaster.
Łączenie klastra z okna przesyłania platformy Spark
Utwórz projekt usługi HDInsight.
Kliknij prawym przyciskiem myszy pakiet. Następnie wybierz pozycję Prześlij aplikację Spark do usługi HDInsight.
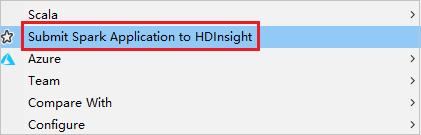
Wybierz klaster z uprawnieniem tylko do odczytu dla nazwy klastra. Zostanie wyświetlony komunikat ostrzegawczy. Możesz kliknąć pozycję Połącz ten klaster, aby połączyć klaster .
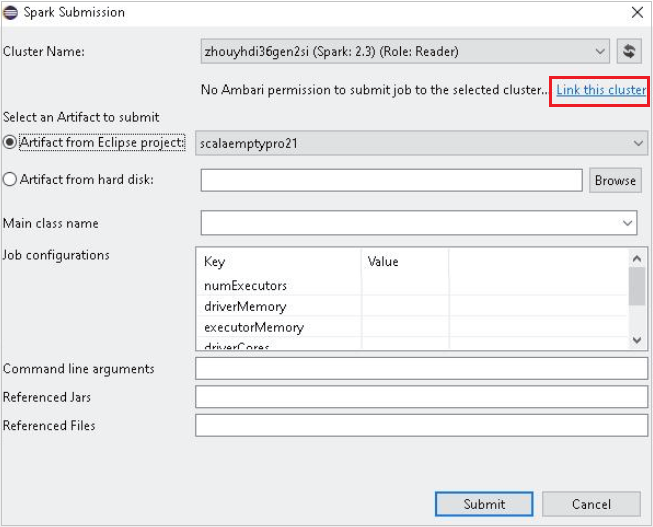
Wyświetlanie kont magazynu
W przypadku klastrów z uprawnieniami tylko do odczytu kliknij węzeł Konta magazynu, zostanie wyświetlone okno Odmowa dostępu do magazynu.
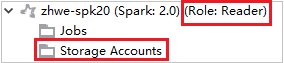
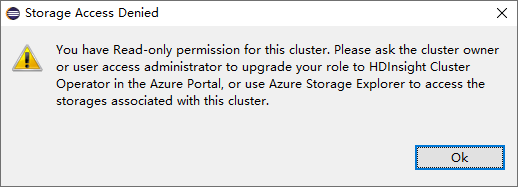
W przypadku połączonych klastrów kliknij węzeł Konta magazynu, zostanie wyświetlone okno Odmowa dostępu do magazynu.

Znane problemy
W przypadku korzystania z linku do klastra zalecamy podanie poświadczeń magazynu.
Istnieją dwa tryby przesyłania zadań. Jeśli poświadczenie magazynu zostanie podane, tryb wsadowy będzie używany do przesyłania zadania. W przeciwnym razie zostanie użyty tryb interaktywny. Jeśli klaster jest zajęty, może zostać wyświetlony poniższy błąd.


Zobacz też
Scenariusze
- Platforma Apache Spark z usługą BI: wykonywanie interaktywnej analizy danych przy użyciu platformy Spark w usłudze HDInsight z narzędziami analizy biznesowej
- Platforma Apache Spark z Edukacja maszyny: używanie platformy Spark w usłudze HDInsight do analizowania temperatury budynku przy użyciu danych HVAC
- Platforma Apache Spark z Edukacja maszynowymi: przewidywanie wyników inspekcji żywności za pomocą platformy Spark w usłudze HDInsight
- Analiza dzienników witryn internetowych przy użyciu platformy Apache Spark w usłudze HDInsight
Tworzenie i uruchamianie aplikacji
- Tworzenie autonomicznych aplikacji przy użyciu języka Scala
- Zdalne uruchamianie zadań w klastrze Apache Spark przy użyciu programu Apache Livy
Narzędzia i rozszerzenia
- Tworzenie i przesyłanie aplikacji Spark Scala za pomocą zestawu narzędzi Azure Toolkit for IntelliJ
- Zdalne debugowanie aplikacji Platformy Apache Spark za pośrednictwem sieci VPN przy użyciu zestawu narzędzi Azure Toolkit for IntelliJ
- Zdalne debugowanie aplikacji Platformy Apache Spark za pośrednictwem protokołu SSH za pomocą zestawu narzędzi Azure Toolkit for IntelliJ
- Używanie notesów Apache Zeppelin z klastrem Apache Spark w usłudze HDInsight
- Jądra dostępne dla notesu Jupyter w klastrze Apache Spark dla usługi HDInsight
- Używanie pakietów zewnętrznych z notesami Jupyter Notebook
- Instalacja oprogramowania Jupyter na komputerze i nawiązywanie połączenia z klastrem Spark w usłudze HDInsight