Składnik Importowanie danych
W tym artykule opisano składnik w projektancie usługi Azure Machine Learning.
Ten składnik służy do ładowania danych do potoku uczenia maszynowego z istniejących usług danych w chmurze.
Uwaga
Wszystkie funkcje udostępniane przez ten składnik mogą być wykonywane przez magazyn danych i zestawy danych na stronie docelowej obszaru roboczego. Zalecamy korzystanie z magazynu danych i zestawu danych , które obejmują dodatkowe funkcje, takie jak monitorowanie danych. Aby dowiedzieć się więcej, zobacz artykuł How to Access Data and How to Register Datasets (Jak uzyskiwać dostęp do danych i jak rejestrować zestawy danych ). Po zarejestrowaniu zestawu danych można go znaleźć w kategorii Zestawy danych —>Moje zestawy danych w interfejsie projektanta. Ten składnik jest zarezerwowany dla użytkowników programu Studio (wersja klasyczna) w celu uzyskania znanego środowiska.
Składnik Importuj dane obsługuje odczyt danych z następujących źródeł:
- Adres URL za pośrednictwem protokołu HTTP
- Magazyny w chmurze platformy Azure za pośrednictwem magazynów danych)
- Azure Blob Container
- Udział plików platformy Azure
- Azure Data Lake
- Azure Data Lake Gen2
- Azure SQL Database
- Azure PostgreSQL
Przed rozpoczęciem korzystania z magazynu w chmurze należy najpierw zarejestrować magazyn danych w obszarze roboczym usługi Azure Machine Learning. Aby uzyskać więcej informacji, zobacz Jak uzyskać dostęp do danych.
Po zdefiniowaniu żądanych danych i nawiązaniu połączenia ze źródłem importowanie danych wywnioskuje typ danych każdej kolumny na podstawie wartości, które zawiera, i ładuje dane do potoku projektanta. Dane wyjściowe importu danych to zestaw danych, który może być używany z dowolnym potokiem projektanta.
Jeśli dane źródłowe zostaną zmienione, możesz odświeżyć zestaw danych i dodać nowe dane, ponownie uruchamiając polecenie Importuj dane.
Ostrzeżenie
Jeśli obszar roboczy znajduje się w sieci wirtualnej, musisz skonfigurować magazyny danych tak, aby korzystały z funkcji wizualizacji danych projektanta. Aby uzyskać więcej informacji na temat używania magazynów danych i zestawów danych w sieci wirtualnej, zobacz Używanie Azure Machine Learning studio w sieci wirtualnej platformy Azure.
Jak skonfigurować importowanie danych
Dodaj składnik Importuj dane do potoku. Ten składnik można znaleźć w kategorii Dane wejściowe i wyjściowe w projektancie.
Wybierz składnik, aby otworzyć okienko po prawej stronie.
Wybierz pozycję Źródło danych i wybierz typ źródła danych. Może to być http lub magazyn danych.
Jeśli wybierzesz magazyn danych, możesz wybrać istniejące magazyny danych, które są już zarejestrowane w obszarze roboczym usługi Azure Machine Learning lub utworzyć nowy magazyn danych. Następnie zdefiniuj ścieżkę danych do zaimportowania w magazynie danych. Ścieżkę można łatwo przeglądać, wybierając pozycję Przeglądaj ścieżkę.
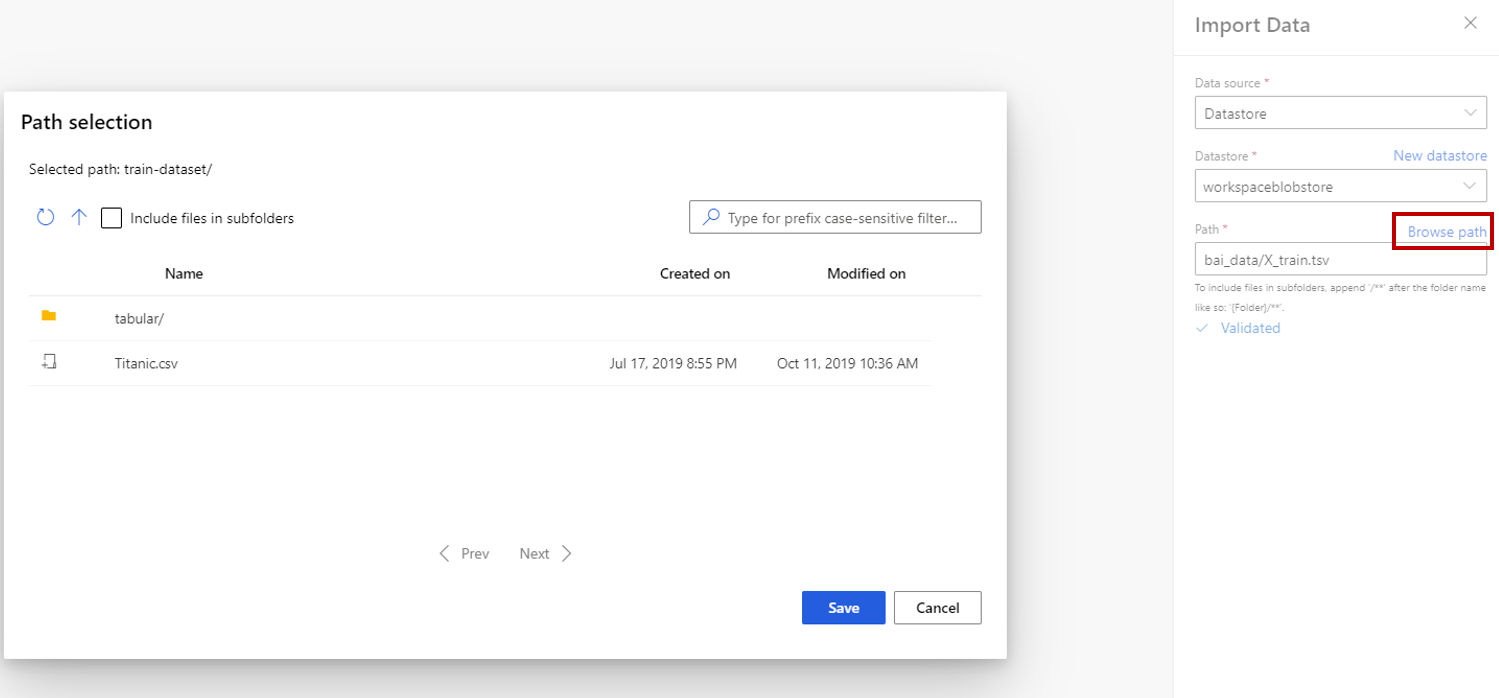
Uwaga
Składnik importu danych jest przeznaczony tylko dla danych tabelarycznych . Jeśli chcesz raz zaimportować wiele plików danych tabelarycznych, wymaga to następujących warunków, w przeciwnym razie wystąpią błędy:
- Aby uwzględnić wszystkie pliki danych w folderze, musisz wprowadzić ciąg
folder_name/**Path. - Wszystkie pliki danych muszą być zakodowane w formacie Unicode-8.
- Wszystkie pliki danych muszą mieć te same numery kolumn i nazwy kolumn.
- Wynikiem importowania wielu plików danych jest łączenie wszystkich wierszy z wielu plików w kolejności.
- Aby uwzględnić wszystkie pliki danych w folderze, musisz wprowadzić ciąg
Wybierz schemat podglądu, aby filtrować kolumny, które chcesz uwzględnić. Możesz również zdefiniować zaawansowane ustawienia, takie jak ogranicznik w opcjach analizowania.
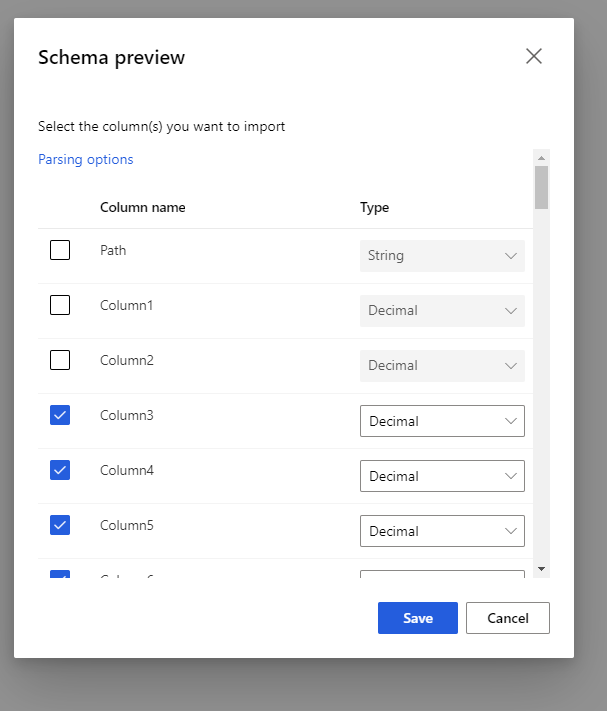
Pole wyboru Ponowne generowanie danych wyjściowych decyduje, czy składnik ma zostać wygenerowany ponownie w czasie wykonywania danych wyjściowych.
Jest on domyślnie niezaznaczony, co oznacza, że jeśli składnik został wykonany z tymi samymi parametrami wcześniej, system ponownie używa danych wyjściowych z ostatniego uruchomienia, aby skrócić czas wykonywania.
W przypadku wybrania tej opcji system ponownie wykonuje składnik w celu ponownego wygenerowania danych wyjściowych. Dlatego wybierz tę opcję, gdy dane bazowe w magazynie są aktualizowane, może pomóc w pobraniu najnowszych danych.
Prześlij potok.
Podczas importowania danych ładuje dane do projektanta, wywnioskuje typ danych każdej kolumny na podstawie wartości, które zawiera, liczbowych lub kategorycznych.
Jeśli nagłówek jest obecny, nagłówek jest używany do nazywania kolumn wyjściowego zestawu danych.
Jeśli w danych nie ma istniejących nagłówków kolumn, nowe nazwy kolumn są generowane przy użyciu formatu col1, col2,... , coln*.

Wyniki
Po zakończeniu importowania kliknij prawym przyciskiem myszy wyjściowy zestaw danych i wybierz pozycję Visualize (Wizualizacja), aby sprawdzić, czy dane zostały pomyślnie zaimportowane.
Jeśli chcesz zapisać dane do ponownego użycia, zamiast importować nowy zestaw danych przy każdym uruchomieniu potoku, wybierz ikonę Zarejestruj zestaw danych na karcie Dane wyjściowe i dzienniki w prawym panelu składnika. Wybierz nazwę zestawu danych. Zapisany zestaw danych zachowuje dane w czasie zapisywania. Zestaw danych nie jest aktualizowany po ponownym uruchomieniu potoku, nawet jeśli zestaw danych w potoku ulegnie zmianie. Może to być przydatne w przypadku tworzenia migawek danych.
Po zaimportowaniu danych może być konieczne kilka dodatkowych przygotowań do modelowania i analizy:
Użyj funkcji Edytuj metadane , aby zmienić nazwy kolumn, obsłużyć kolumnę jako inny typ danych lub wskazać, że niektóre kolumny są etykietami lub funkcjami.
Użyj opcji Wybierz kolumny w zestawie danych , aby wybrać podzbiór kolumn do przekształcenia lub użycia w modelowaniu. Przekształcone lub usunięte kolumny można łatwo ponownie dołączyć do oryginalnego zestawu danych przy użyciu składnika Dodaj kolumny .
Użyj partycji i przykładu , aby podzielić zestaw danych, przeprowadzić próbkowanie lub pobrać pierwsze n wierszy.
Ograniczenia
Ze względu na ograniczenie dostępu do magazynu danych, jeśli potok wnioskowania zawiera składnik Importuj dane , jest automatycznie usuwany po wdrożeniu do punktu końcowego w czasie rzeczywistym.
Następne kroki
Zobacz zestaw składników dostępnych dla usługi Azure Machine Learning.