Prognozowanie na dużą skalę: wiele modeli i trenowanie rozproszone
Ten artykuł dotyczy trenowania modeli prognozowania dużych ilości danych historycznych. Instrukcje i przykłady dotyczące modeli prognozowania trenowania w rozwiązaniu AutoML można znaleźć w artykule dotyczącym konfigurowania rozwiązania AutoML na potrzeby prognozowania szeregów czasowych.
Dane szeregów czasowych mogą być duże ze względu na liczbę serii w danych, liczbę obserwacji historycznych lub obie. Wiele modeli i hierarchicznych szeregów czasowych ( HTS) to rozwiązania skalowania dla poprzedniego scenariusza, w których dane składają się z dużej liczby szeregów czasowych. W takich przypadkach może być korzystne dla dokładności modelu i skalowalności partycjonowania danych w grupach i trenowania dużej liczby niezależnych modeli równolegle w grupach. Z drugiej strony istnieją scenariusze, w których jedna lub niewielka liczba modeli o wysokiej pojemności jest lepsza. Rozproszone cele trenowania sieci rozproszonej sieci rozproszonej w tym przypadku. W pozostałej części artykułu zapoznamy się z pojęciami dotyczącymi tych scenariuszy.
Wiele modeli
Wiele składników modeli w rozwiązaniu AutoML umożliwia równoległe trenowanie milionów modeli i zarządzanie nimi. Załóżmy na przykład, że masz historyczne dane sprzedaży dla dużej liczby sklepów. Wiele modeli umożliwia uruchamianie równoległych zadań trenowania automatycznego uczenia maszynowego dla każdego magazynu, jak na poniższym diagramie:

Wiele modeli składnik trenowania stosuje model automl zamiatanie i wybór niezależnie do każdego magazynu w tym przykładzie. Ta niezależność modelu ułatwia skalowalność i może przynieść korzyści z dokładności modelu, zwłaszcza gdy sklepy mają rozbieżną dynamikę sprzedaży. Jednak pojedyncze podejście modelu może przynieść dokładniejsze prognozy, gdy istnieją typowe dynamiki sprzedaży. Aby uzyskać więcej informacji na temat tego przypadku, zobacz sekcję trenowania rozproszonej sieci rozproszonej sieci rozproszonej.
Można skonfigurować partycjonowanie danych, ustawienia rozwiązania AutoML dla modeli oraz stopień równoległości dla wielu zadań trenowania modeli. Przykłady można znaleźć w naszej sekcji przewodnika dotyczącej wielu składników modeli.
Prognozowanie hierarchicznych szeregów czasowych
Szeregi czasowe w aplikacjach biznesowych często mają zagnieżdżone atrybuty, które tworzą hierarchię. Atrybuty geografii i katalogu produktów są często zagnieżdżone, na przykład. Rozważmy przykład, w którym hierarchia ma dwa atrybuty geograficzne, identyfikator stanu i magazynu oraz dwa atrybuty produktu, kategorię i jednostkę SKU:

Ta hierarchia jest pokazana na poniższym diagramie:

Co ważne, ilości sprzedaży na poziomie liścia (SKU) sumują się do zagregowanych ilości sprzedaży na poziomie stanu i całkowitej sprzedaży. Metody prognozowania hierarchicznego zachowują te właściwości agregacji podczas prognozowania ilości sprzedanej na dowolnym poziomie hierarchii. Prognozy z tą właściwością są spójne w odniesieniu do hierarchii.
Rozwiązanie AutoML obsługuje następujące funkcje dla hierarchicznych szeregów czasowych (HTS):
- Trenowanie na dowolnym poziomie hierarchii. W niektórych przypadkach dane na poziomie liści mogą być hałaśliwe, ale agregacje mogą być bardziej podatne na prognozowanie.
- Pobieranie prognoz punktów na dowolnym poziomie hierarchii. Jeśli poziom prognozy jest "niższy" od poziomu trenowania, prognozy na poziomie trenowania są rozagregowane za pośrednictwem średnich proporcji historycznych lub proporcji średnich historycznych. Prognozy poziomu szkolenia są sumowane zgodnie ze strukturą agregacji, gdy poziom prognozy jest "wyższy" od poziomu trenowania.
- Pobieranie prognoz kwantylu/probabilistycznych dla poziomów na poziomie lub "poniżej" poziomu trenowania. Bieżące możliwości modelowania obsługują rozagregowanie prognoz probabilistycznych.
Składniki HTS w rozwiązaniu AutoML są oparte na wielu modelach, więc HTS udostępnia skalowalne właściwości wielu modeli. Przykłady można znaleźć w naszej sekcji przewodnika dotyczącej składników HTS.
Trenowanie rozproszonej sieci rozproszonej sieci rozproszonej (wersja zapoznawcza)
Ważne
Ta funkcja jest obecnie w publicznej wersji zapoznawczej. Ta wersja zapoznawcza jest udostępniana bez umowy dotyczącej poziomu usług i nie zalecamy korzystania z niej w przypadku obciążeń produkcyjnych. Niektóre funkcje mogą być nieobsługiwane lub ograniczone.
Aby uzyskać więcej informacji, zobacz Uzupełniające warunki korzystania z wersji zapoznawczych platformy Microsoft Azure.
Scenariusze danych z dużą ilością historycznych obserwacji i/lub dużą liczbą powiązanych szeregów czasowych mogą korzystać ze skalowalnego, pojedynczego modelu. W związku z tym rozwiązanie AutoML obsługuje rozproszone trenowanie i wyszukiwanie modeli na modelach sieci konwolucyjnej (TCN), które są typem głębokiej sieci neuronowej (DNN) dla danych szeregów czasowych. Aby uzyskać więcej informacji na temat klasy modelu TCN rozwiązania AutoML, zobacz nasz artykuł dotyczący nazwy sieci rozproszonej.
Trenowanie rozproszonej sieci rozproszonej sieci rozproszonej zapewnia skalowalność przy użyciu algorytmu partycjonowania danych, który uwzględnia granice szeregów czasowych. Na poniższym diagramie przedstawiono prosty przykład z dwoma partycjami:
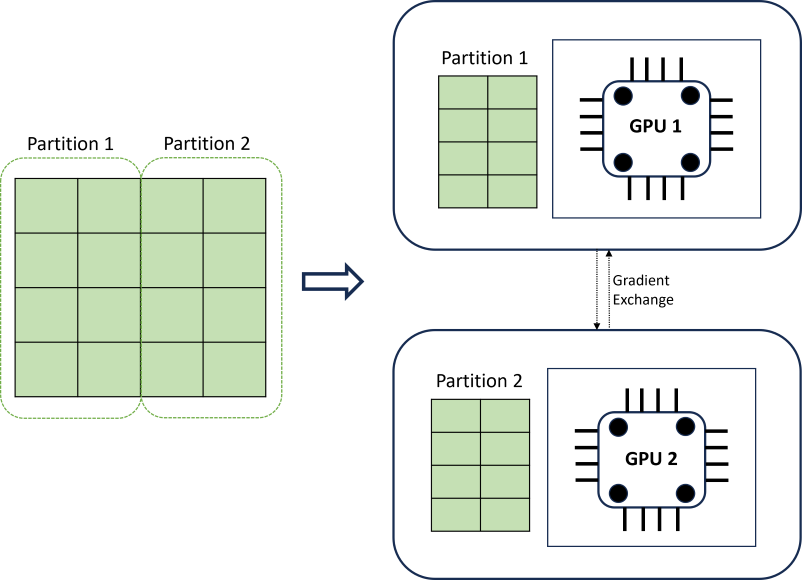
Podczas trenowania moduły ładującego dane sieci rozproszonej na każdym obciążeniu obliczeniowym są tylko tym, co muszą wykonać iterację propagacji wstecznej; cały zestaw danych nigdy nie jest odczytywany do pamięci. Partycje są dalej dystrybuowane między wieloma rdzeniami obliczeniowymi (zwykle procesorami GPU) w wielu węzłach w celu przyspieszenia trenowania. Koordynacja między obliczeniami jest zapewniana przez platformę Horovod .
Następne kroki
- Dowiedz się więcej o sposobie konfigurowania rozwiązania AutoML do trenowania modelu prognozowania szeregów czasowych.
- Dowiedz się, jak rozwiązanie AutoML używa uczenia maszynowego do tworzenia modeli prognozowania.
- Dowiedz się więcej o modelach uczenia głębokiego na potrzeby prognozowania w rozwiązaniu AutoML