Samouczek: analizowanie raportów spisu obiektów blob
Dzięki zrozumieniu sposobu przechowywania, organizowania i używania obiektów blob i kontenerów w środowisku produkcyjnym można lepiej zoptymalizować kompromisy między kosztami i wydajnością.
W tym samouczku przedstawiono sposób generowania i wizualizowania statystyk, takich jak wzrost danych w czasie, liczba zmodyfikowanych plików, rozmiary migawek obiektów blob, wzorce dostępu w poszczególnych warstwach oraz sposób dystrybucji danych zarówno obecnie, jak i w czasie (na przykład: dane między warstwami, typami plików, kontenerami i typami obiektów blob).
Ten samouczek zawiera informacje na temat wykonywania następujących czynności:
- Generowanie raportu spisu obiektów blob
- Konfigurowanie obszaru roboczego usługi Synapse
- Konfigurowanie Synapse Studio
- Generowanie danych analitycznych w Synapse Studio
- Wizualizowanie wyników w usłudze Power BI
Wymagania wstępne
Subskrypcja platformy Azure — bezpłatne tworzenie konta
Konto usługi Azure Storage — tworzenie konta magazynu
Upewnij się, że tożsamość użytkownika ma przypisaną rolę Współautor danych obiektu blob usługi Storage .
Generowanie raportu spisu
Włącz raporty spisu obiektów blob dla konta magazynu. Zobacz Włączanie raportów spisu obiektów blob usługi Azure Storage.
Po włączeniu raportów spisu do wygenerowania pierwszego raportu może być konieczne odczekanie do 24 godzin.
Konfigurowanie obszaru roboczego usługi Synapse
Utwórz obszar roboczy Azure Synapse. Zobacz Tworzenie obszaru roboczego Azure Synapse.
Uwaga
W ramach tworzenia obszaru roboczego utworzysz konto magazynu, które ma hierarchiczną przestrzeń nazw. Azure Synapse przechowuje tabele platformy Spark i dzienniki aplikacji na tym koncie. Azure Synapse odnosi się do tego konta jako podstawowego konta magazynu. Aby uniknąć nieporozumień, w tym artykule użyto terminu konto raportu spisu w celu odwoływania się do konta zawierającego raporty spisu.
W obszarze roboczym usługi Synapse przypisz rolę Współautor do tożsamości użytkownika. Zobacz Kontrola dostępu oparta na rolach platformy Azure: rola właściciela dla obszaru roboczego.
Nadaj obszarowi roboczemu usługi Synapse uprawnienie dostępu do raportów spisu na koncie magazynu, przechodząc do konta raportu spisu, a następnie przypisując rolę Współautor danych obiektu blob usługi Storage do tożsamości zarządzanej przez system obszaru roboczego. Zobacz Przypisywanie ról platformy Azure przy użyciu witryny Azure Portal.
Przejdź do podstawowego konta magazynu i przypisz rolę Współautor usługi Blob Storage do tożsamości użytkownika.
Konfigurowanie Synapse Studio
Otwórz obszar roboczy usługi Synapse w Synapse Studio. Zobacz Otwieranie Synapse Studio.
W Synapse Studio upewnij się, że tożsamość ma przypisaną rolę administratora usługi Synapse. Zobacz RBAC usługi Synapse: rola administratora usługi Synapse dla obszaru roboczego.
Utwórz pulę platformy Apache Spark. Zobacz Tworzenie bezserwerowej puli platformy Apache Spark.
Konfigurowanie i uruchamianie przykładowego notesu
W tej sekcji wygenerujesz dane statystyczne, które zostaną zwizualizowane w raporcie. Aby uprościć ten samouczek, w tej sekcji jest używany przykładowy plik konfiguracji i przykładowy notes PySpark. Notes zawiera kolekcję zapytań wykonywanych w programie Azure Synapse Studio.
Modyfikowanie i przekazywanie przykładowego pliku konfiguracji
Pobierz plik BlobInventoryStorageAccountConfiguration.json .
Zaktualizuj następujące symbole zastępcze tego pliku:
Ustaw
storageAccountNamenazwę konta raportu spisu.Ustaw
destinationContainerwartość na nazwę kontenera, który zawiera raporty spisu.Ustaw
blobInventoryRuleNamenazwę reguły raportu spisu, która wygenerowała wyniki, które chcesz przeanalizować.Ustaw
accessKeyklucz konta konta raportu spisu.
Przekaż ten plik do kontenera na podstawowym koncie magazynu określonym podczas tworzenia obszaru roboczego usługi Synapse.
Importowanie przykładowego notesu PySpark
Pobierz przykładowy notes ReportAnalysis.ipynb .
Uwaga
Pamiętaj, aby zapisać ten plik z
.ipynbrozszerzeniem .Otwórz obszar roboczy usługi Synapse w Synapse Studio. Zobacz Otwieranie Synapse Studio.
W Synapse Studio wybierz kartę Programowanie.
Wybierz znak plus (+), aby dodać element.
Wybierz pozycję Importuj, przejdź do pobranego przykładowego pliku, wybierz ten plik i wybierz pozycję Otwórz.
Zostanie wyświetlone okno dialogowe Właściwości .
W oknie dialogowym Właściwości wybierz link Konfiguruj sesję .
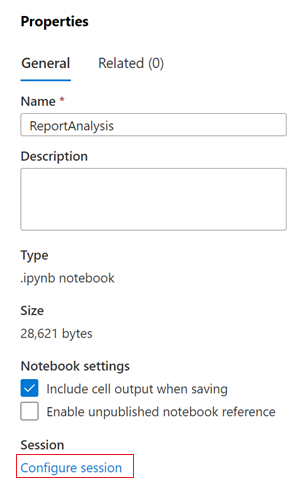
Zostanie otwarte okno dialogowe Konfigurowanie sesji .
Na liście rozwijanej Dołącz do okna dialogowego Konfigurowanie sesji wybierz pulę spark utworzoną wcześniej w tym artykule. Następnie wybierz przycisk Zastosuj .
Modyfikowanie notesu języka Python
W pierwszej komórce notesu języka Python ustaw wartość
storage_accountzmiennej na nazwę podstawowego konta magazynu.Zaktualizuj wartość
container_namezmiennej na nazwę kontenera na koncie określonym podczas tworzenia obszaru roboczego usługi Synapse.Wybierz przycisk Publikuj.
Uruchamianie notesu PySpark
W notesie PySpark wybierz pozycję Uruchom wszystko.
Uruchomienie sesji platformy Spark i kolejne kilka minut na przetworzenie raportów spisu potrwa kilka minut. Pierwsze uruchomienie może zająć trochę czasu, jeśli istnieje wiele raportów spisu do przetworzenia. Kolejne przebiegi będą przetwarzać tylko nowe raporty spisu utworzone od ostatniego uruchomienia.
Uwaga
Jeśli wprowadzisz jakiekolwiek zmiany w notesie, notes będzie uruchomiony, pamiętaj, aby opublikować te zmiany przy użyciu przycisku Publikuj .
Sprawdź, czy notes został uruchomiony pomyślnie, wybierając kartę Dane .
Baza danych o nazwie reportdata powinna pojawić się na karcie Obszar roboczy okienka Dane . Jeśli ta baza danych nie jest wyświetlana, może być konieczne odświeżenie strony internetowej.
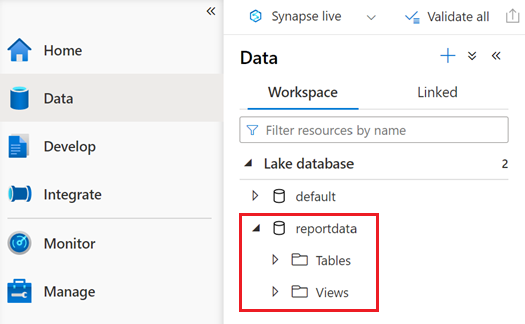
Baza danych zawiera zestaw tabel. Każda tabela zawiera informacje uzyskane przez uruchomienie zapytań z notesu PySpark.
Aby sprawdzić zawartość tabeli, rozwiń folder Tables bazy danych reportdata . Następnie kliknij prawym przyciskiem myszy tabelę, wybierz pozycję Wybierz skrypt SQL, a następnie wybierz pozycję Wybierz 100 pierwszych wierszy.
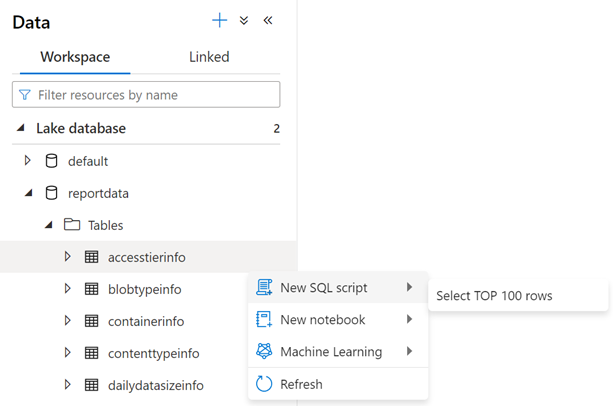
Możesz zmodyfikować zapytanie zgodnie z potrzebami, a następnie wybrać pozycję Uruchom , aby wyświetlić wyniki.
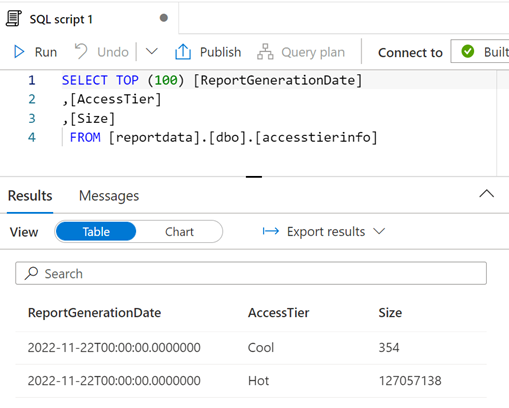
Wizualizacja danych
Pobierz przykładowy plik raportu ReportAnalysis.pbit .
Otwórz program Power BI Desktop. Aby uzyskać wskazówki dotyczące instalacji, zobacz Pobieranie Power BI Desktop.
W usłudze Power BI wybierz pozycję Plik, Otwórz raport, a następnie przeglądaj raporty.
W oknie dialogowym Otwieranie zmień typ pliku na pliki szablonów usługi Power BI (*.pbit)..

Przejdź do lokalizacji pobranego pliku ReportAnalysis.pbit , a następnie wybierz pozycję Otwórz.
Zostanie wyświetlone okno dialogowe z prośbą o podanie nazwy obszaru roboczego usługi Synapse i nazwy bazy danych.
W oknie dialogowym ustaw pole synapse_workspace_name na nazwę obszaru roboczego i ustaw pole database_name na
reportdatawartość . Następnie wybierz przycisk Załaduj .
Zostanie wyświetlony raport zawierający wizualizacje danych pobranych przez notes. Na poniższych ilustracjach przedstawiono typy wykresów i wykresów, które są wyświetlane w tym raporcie.
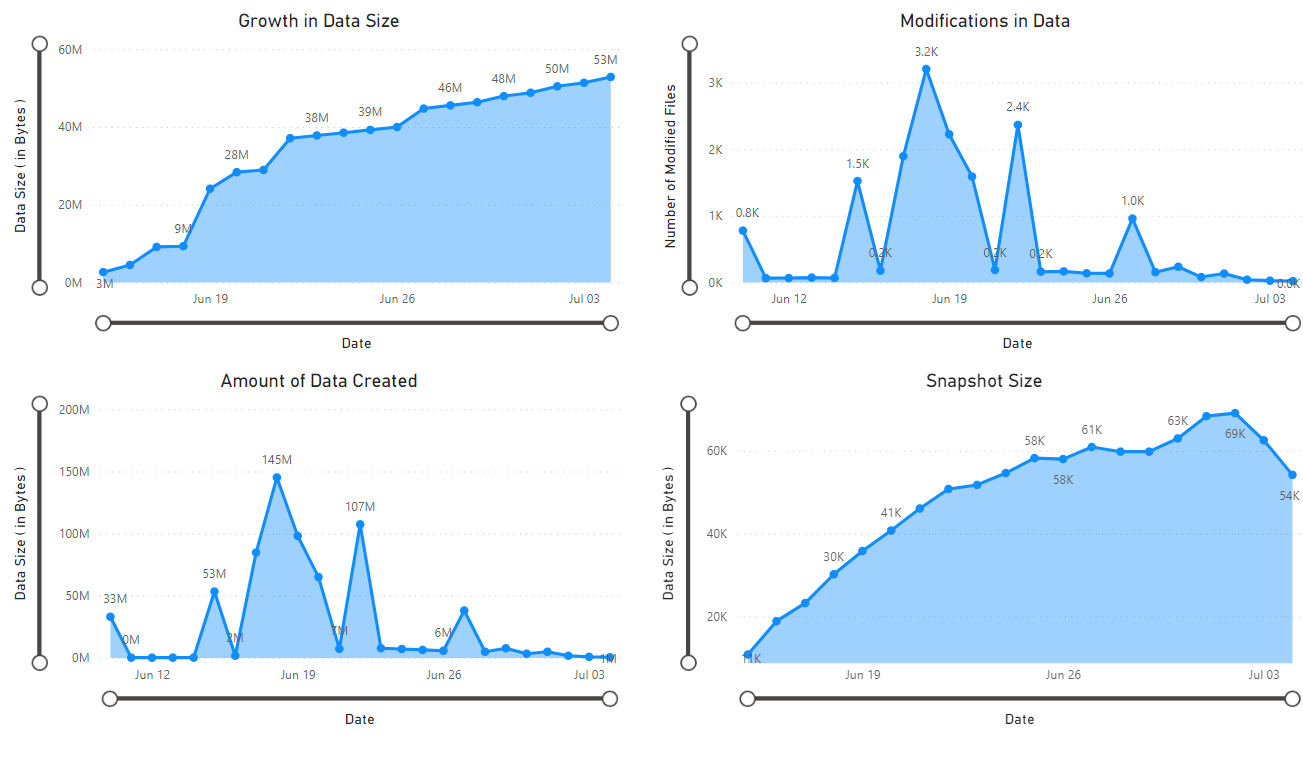
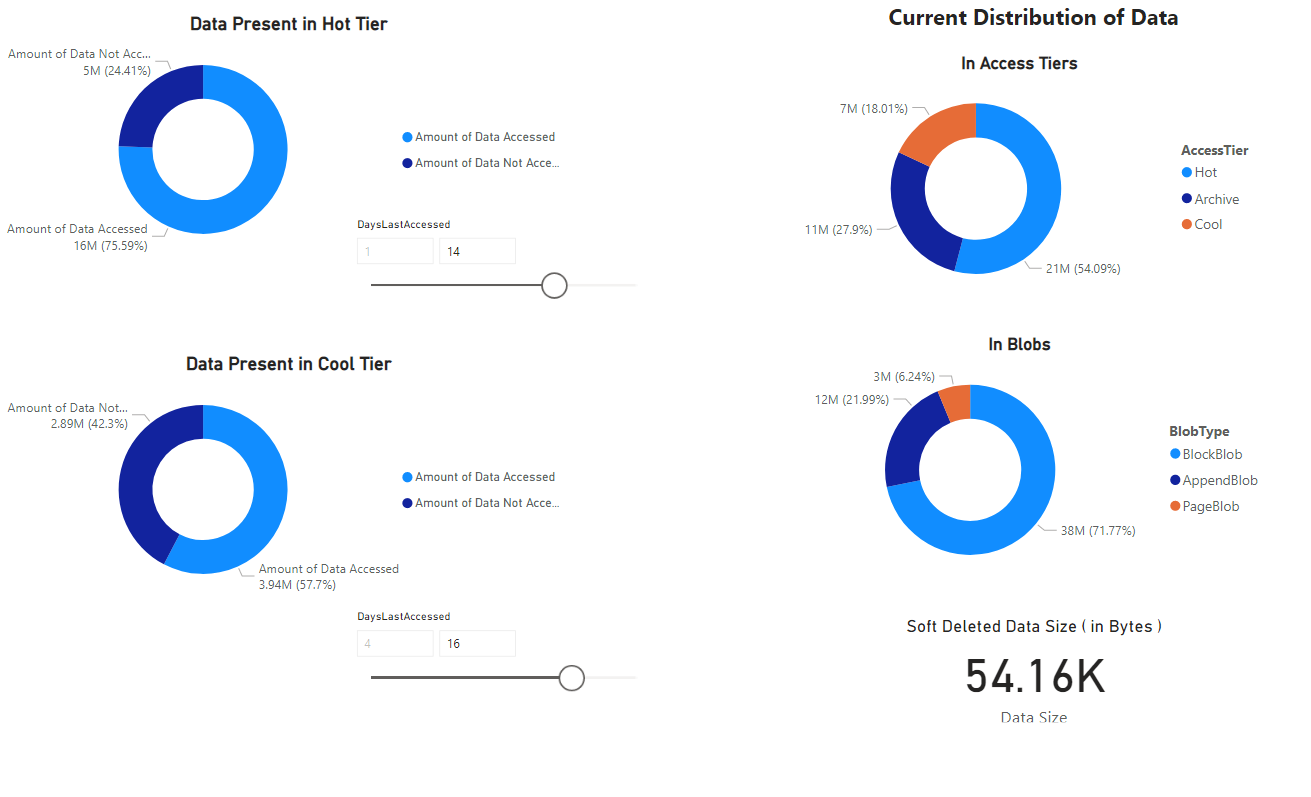
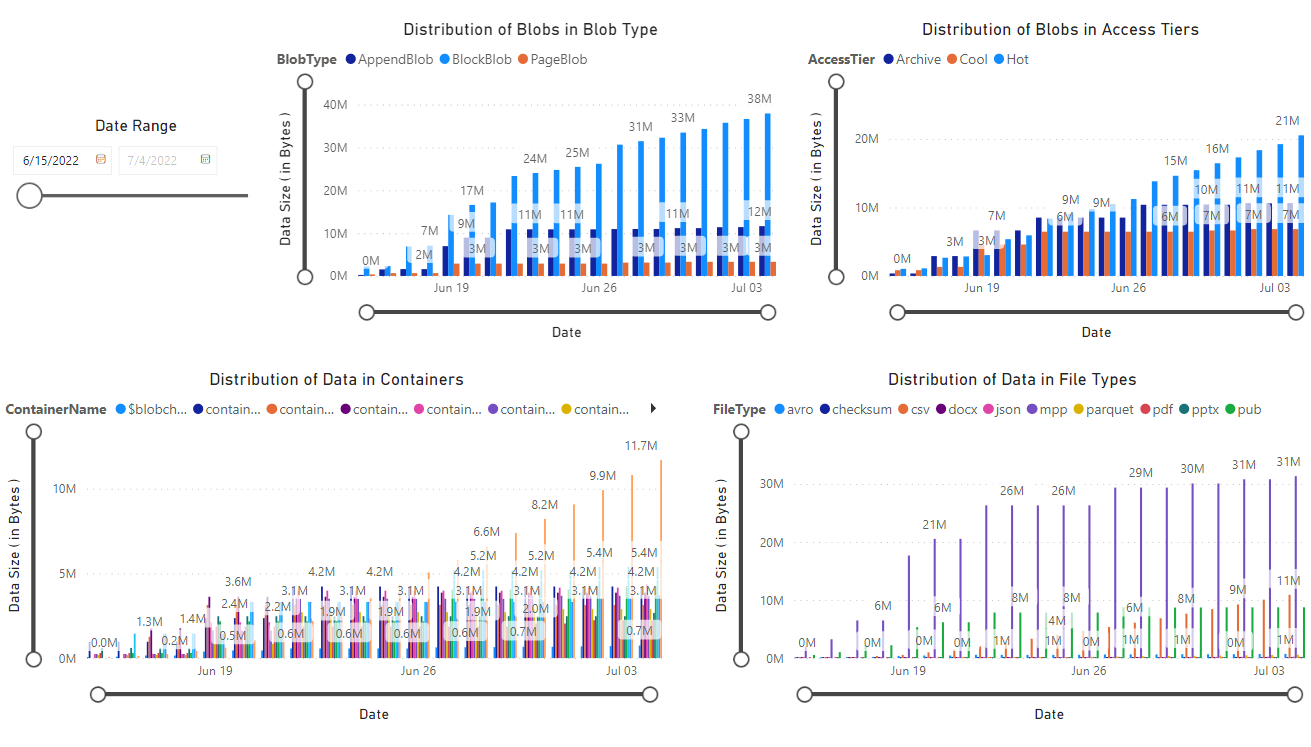
Następne kroki
Skonfiguruj potok Azure Synapse, aby regularnie uruchamiać notes. Dzięki temu można przetwarzać nowe raporty spisu podczas ich tworzenia. Po początkowym uruchomieniu każde z następnych przebiegów będzie analizować dane przyrostowe, a następnie aktualizować tabele przy użyciu wyników tej analizy. Aby uzyskać wskazówki, zobacz Integrowanie z potokami.
Dowiedz się więcej o sposobach analizowania poszczególnych kontenerów na koncie magazynu. Zobacz następujące artykuły:
Samouczek: obliczanie statystyk kontenera przy użyciu usługi Databricks
Dowiedz się więcej o sposobach optymalizacji kosztów na podstawie analizy obiektów blob i kontenerów. Zobacz następujące artykuły:
Planowanie kosztów usługi Azure Blob Storage i zarządzanie nimi
Szacowanie kosztów archiwizacji danych
Optymalizowanie kosztów przez automatyczne zarządzanie cyklem życia danych