Migracja urządzeń StorSimple 1200 do usługi Azure File Sync
Seria StorSimple 1200 to urządzenie wirtualne, które jest uruchamiane w lokalnym centrum danych. Istnieje możliwość migracji danych z tego urządzenia do środowiska Azure File Sync. Azure File Sync jest domyślną i strategiczną długoterminową usługą platformy Azure, do którą można migrować urządzenia StorSimple. Ten artykuł zawiera niezbędne kroki wiedzy i migracji w tle dla pomyślnej migracji do Azure File Sync.
Uwaga
Usługa StorSimple (w tym storSimple Menedżer urządzeń dla serii 8000 i 1200 oraz StorSimple Data Manager) osiągnęła koniec wsparcia. Koniec wsparcia dla usługi StorSimple został opublikowany w 2019 r. na stronach zasad lifecycle firmy Microsoft i usługi Azure Communications . Dodatkowe powiadomienia zostały wysłane pocztą e-mail i opublikowane na Azure Portal i w omówieniu usługi StorSimple. Aby uzyskać dodatkowe informacje, skontaktuj się z pomoc techniczna firmy Microsoft.
Dotyczy
| Typ udziału plików | SMB | NFS |
|---|---|---|
| Udziały plików w warstwie Standardowa (GPv2), LRS/ZRS | ||
| Udziały plików w warstwie Standardowa (GPv2), GRS/GZRS | ||
| Udziały plików w warstwie Premium (FileStorage), LRS/ZRS |
Azure File Sync
Azure File Sync to usługa w chmurze firmy Microsoft oparta na dwóch głównych składnikach:
- Synchronizacja plików i obsługa warstw w chmurze.
- Udziały plików jako magazyn natywny na platformie Azure, do których można uzyskać dostęp za pośrednictwem wielu protokołów, takich jak SMB i REST plików. Udział plików platformy Azure jest porównywalny z udziałem plików w systemie Windows Server, który można natywnie zainstalować jako dysk sieciowy. Obsługuje ważne aspekty wierności plików, takie jak atrybuty, uprawnienia i znaczniki czasu. W przeciwieństwie do usługi StorSimple do interpretowania plików i folderów przechowywanych w chmurze nie jest wymagana żadna aplikacja/usługa. Idealne i najbardziej elastyczne podejście do przechowywania danych serwera plików ogólnego przeznaczenia i niektórych danych aplikacji w chmurze.
Ten artykuł koncentruje się na krokach migracji. Jeśli przed migracją chcesz dowiedzieć się więcej o Azure File Sync, zalecamy następujące artykuły:
Cele migracji
Celem jest zagwarantowanie integralności danych produkcyjnych i zagwarantowania dostępności. Ten ostatni wymaga minimalnego czasu przestoju, dzięki czemu może mieścić się w oknach konserwacji lub tylko nieznacznie przekraczać zwykłe okna obsługi.
Ścieżka migracji usługi StorSimple 1200 do Azure File Sync
Do uruchomienia agenta Azure File Sync jest wymagany lokalny system Windows Server. System Windows Server może być co najmniej serwerem 2012R2, ale najlepiej jest windows Server 2019.
Istnieje wiele alternatywnych ścieżek migracji i utworzenie zbyt długiego artykułu w celu udokumentowania ich wszystkich i zilustrowania, dlaczego stwarzają one ryzyko lub wady trasy, zalecamy zastosowanie najlepszych rozwiązań w tym artykule.
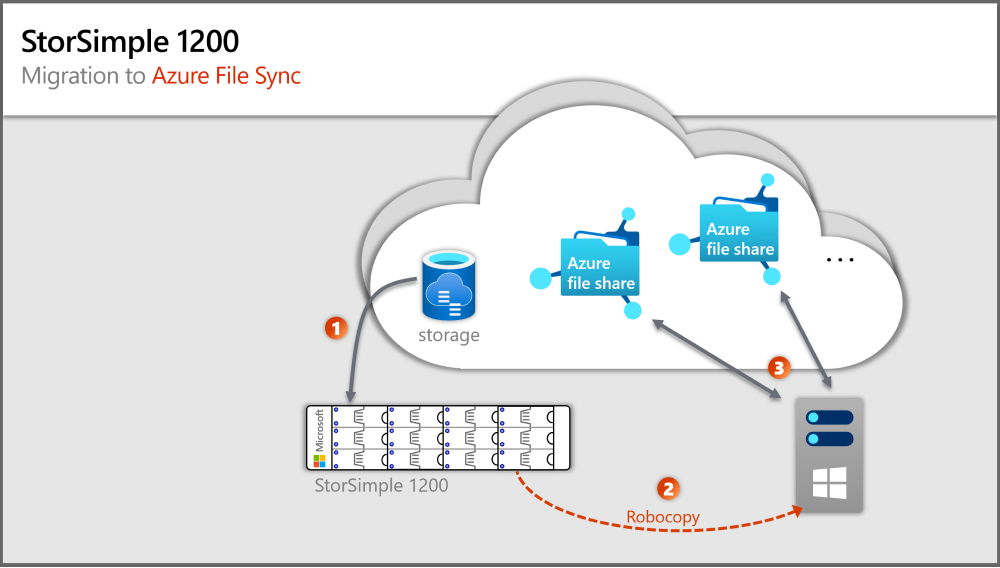
Poprzedni obraz przedstawia kroki odpowiadające sekcjom w tym artykule.
Krok 1. Aprowizuj lokalny system Windows Server i magazyn
- Utwórz system Windows Server 2019 — co najmniej 2012R2 — jako maszynę wirtualną lub serwer fizyczny. Klaster trybu failover systemu Windows Server jest również obsługiwany.
- Aprowizuj lub dodaj magazyn dołączony bezpośrednio (DAS w porównaniu z serwerem NAS, który nie jest obsługiwany). Rozmiar magazynu systemu Windows Server musi być równy lub większy niż rozmiar dostępnej pojemności wirtualnego urządzenia StorSimple 1200.
Krok 2. Konfigurowanie magazynu systemu Windows Server
W tym kroku zamapujesz strukturę magazynu StorSimple (woluminy i udziały) na strukturę magazynu systemu Windows Server. Jeśli planujesz wprowadzić zmiany w strukturze magazynu, co oznacza liczbę woluminów, skojarzenie folderów danych z woluminami lub strukturę podfolderu powyżej lub poniżej bieżących udziałów SMB/NFS, nadszedł czas, aby wziąć pod uwagę te zmiany. Zmiana struktury plików i folderów po skonfigurowaniu Azure File Sync jest kłopotliwa i należy unikać. W tym artykule przyjęto założenie, że mapujesz 1:1, więc podczas wykonywania kroków opisanych w tym artykule należy wziąć pod uwagę zmiany mapowania.
- Żadne dane produkcyjne nie powinny znajdować się na woluminie systemowym systemu Windows Server. Obsługa warstw w chmurze nie jest obsługiwana w woluminach systemowych. Ta funkcja jest jednak wymagana w przypadku migracji, a także operacji ciągłych jako zamiany urządzenia StorSimple.
- Aprowizuj tę samą liczbę woluminów w systemie Windows Server, co na urządzeniu wirtualnym StorSimple 1200.
- Skonfiguruj wymagane role, funkcje i ustawienia systemu Windows Server. Zalecamy skorzystanie z aktualizacji systemu Windows Server, aby zapewnić bezpieczeństwo i aktualność systemu operacyjnego. Podobnie zalecamy skorzystanie z usługi Microsoft Update, aby zapewnić aktualność aplikacji firmy Microsoft, w tym agenta Azure File Sync.
- Przed przeczytaniem poniższych kroków nie należy konfigurować żadnych folderów ani udziałów.
Krok 3. Wdrażanie pierwszego zasobu Azure File Sync w chmurze
Do wykonania tego kroku potrzebne są poświadczenia subskrypcji platformy Azure.
Podstawowy zasób do skonfigurowania dla Azure File Sync jest nazywany usługą synchronizacji magazynu. Zalecamy wdrożenie tylko jednego dla wszystkich serwerów, które synchronizują ten sam zestaw plików teraz lub w przyszłości. Utwórz wiele usług synchronizacji magazynu tylko wtedy, gdy masz różne zestawy serwerów, które nigdy nie mogą wymieniać danych. Na przykład mogą istnieć serwery, które nigdy nie muszą synchronizować tego samego udziału plików platformy Azure. W przeciwnym razie najlepszym rozwiązaniem jest użycie pojedynczej usługi synchronizacji magazynu.
Wybierz region platformy Azure dla usługi synchronizacji magazynu, który znajduje się blisko twojej lokalizacji. Wszystkie inne zasoby w chmurze muszą być wdrażane w tym samym regionie. Aby uprościć zarządzanie, utwórz nową grupę zasobów w ramach subskrypcji, w ramach którego znajdują się zasoby synchronizacji i magazynu.
Aby uzyskać więcej informacji, zobacz sekcję dotyczącą wdrażania usługi synchronizacji magazynu w artykule dotyczącym wdrażania Azure File Sync. Postępuj zgodnie z tą sekcją artykułu. W kolejnych krokach będą dostępne linki do innych sekcji artykułu.
Krok 4. Dopasowanie lokalnej struktury woluminów i folderów do zasobów Azure File Sync i udziałów plików platformy Azure
W tym kroku określisz, ile potrzebnych udziałów plików platformy Azure. Pojedyncze wystąpienie systemu Windows Server (lub klaster) może synchronizować maksymalnie 30 udziałów plików platformy Azure.
Być może masz więcej folderów na woluminach, które obecnie udostępniasz lokalnie jako udziały SMB użytkownikom i aplikacjom. Najprostszym sposobem na obraz tego scenariusza jest przewidywanie udziału lokalnego, który mapuje 1:1 na udział plików platformy Azure. Jeśli masz wystarczającą liczbę udziałów, poniżej 30 dla pojedynczego wystąpienia systemu Windows Server zalecamy mapowanie 1:1.
Jeśli masz więcej niż 30 udziałów, mapowanie udziału lokalnego 1:1 na udział plików platformy Azure jest często niepotrzebne. Rozważ następujące opcje.
Udostępnianie grupowania
Jeśli na przykład dział kadr ma 15 udziałów, możesz rozważyć przechowywanie wszystkich danych kadr w jednym udziale plików platformy Azure. Przechowywanie wielu udziałów lokalnych w jednym udziale plików platformy Azure nie uniemożliwia tworzenia zwykłych 15 udziałów SMB w lokalnym wystąpieniu systemu Windows Server. Oznacza to tylko, że foldery główne tych 15 udziałów są zorganizowane jako podfoldery w folderze wspólnym. Następnie zsynchronizuj ten wspólny folder z udziałem plików platformy Azure. W ten sposób dla tej grupy udziałów lokalnych jest wymagany tylko jeden udział plików platformy Azure w chmurze.
Synchronizacja woluminów
Azure File Sync obsługuje synchronizowanie katalogu głównego woluminu z udziałem plików platformy Azure. Jeśli zsynchronizujesz katalog główny woluminu, wszystkie podfoldery i pliki będą przechodzić do tego samego udziału plików platformy Azure.
Synchronizowanie katalogu głównego woluminu nie zawsze jest najlepszą opcją. Synchronizacja wielu lokalizacji zapewnia korzyści. Na przykład pomaga zachować mniejszą liczbę elementów na zakres synchronizacji. Testujemy udziały plików platformy Azure i Azure File Sync z 100 milionami elementów (plików i folderów) na udział. Najlepszym rozwiązaniem jest jednak staranie się utrzymać liczbę poniżej 20 milionów lub 30 milionów w jednym udziale. Skonfigurowanie Azure File Sync przy użyciu mniejszej liczby elementów nie jest korzystne tylko w przypadku synchronizacji plików. Mniejsza liczba elementów również przynosi korzyści w takich scenariuszach:
- Wstępne skanowanie zawartości w chmurze może zakończyć się szybciej, co z kolei zmniejsza oczekiwanie na pojawienie się przestrzeni nazw na serwerze włączonym dla Azure File Sync.
- Przywracanie po stronie chmury z migawki udziału plików platformy Azure będzie szybsze.
- Odzyskiwanie po awarii serwera lokalnego może znacznie przyspieszyć.
- Zmiany wprowadzone bezpośrednio w udziale plików platformy Azure (poza synchronizacją) można wykrywać i synchronizować szybciej.
Porada
Jeśli nie wiesz, ile plików i folderów masz, zapoznaj się z narzędziem TreeSize firmy JAM Software GmbH.
Ustrukturyzowane podejście do mapy wdrożenia
Przed wdrożeniem magazynu w chmurze w późniejszym kroku należy utworzyć mapę między folderami lokalnymi i udziałami plików platformy Azure. To mapowanie informuje, ile i które zasoby grupy synchronizacji Azure File Sync aprowizujesz. Grupa synchronizacji łączy udział plików platformy Azure i folder na serwerze razem i ustanawia połączenie synchronizacji.
Aby zdecydować, ile potrzebnych udziałów plików platformy Azure, zapoznaj się z następującymi limitami i najlepszymi rozwiązaniami. Dzięki temu można zoptymalizować mapę.
Serwer, na którym zainstalowano agenta Azure File Sync, może synchronizować się z maksymalnie 30 udziałami plików platformy Azure.
Udział plików platformy Azure jest wdrażany na koncie magazynu. To rozwiązanie sprawia, że konto magazynu jest celem skalowania dla liczb wydajności, takich jak liczba operacji we/wy na sekundę i przepływność.
Zwróć uwagę na ograniczenia liczby operacji we/wy na sekundę konta magazynu podczas wdrażania udziałów plików platformy Azure. Najlepiej mapować udziały plików 1:1 przy użyciu kont magazynu. Jednak może to nie zawsze być możliwe z powodu różnych limitów i ograniczeń, zarówno z organizacji, jak i z platformy Azure. Jeśli nie można mieć tylko jednego udziału plików wdrożonego na jednym koncie magazynu, należy wziąć pod uwagę, które udziały będą wysoce aktywne i które udziały będą mniej aktywne, aby upewnić się, że najgorętsze udziały plików nie zostaną umieszczone na tym samym koncie magazynu.
Jeśli planujesz podnieść aplikację na platformę Azure, która będzie używać natywnie udziału plików platformy Azure, może być potrzebna większa wydajność z udziału plików platformy Azure. Jeśli tego typu użycie jest możliwe, nawet w przyszłości, najlepiej utworzyć pojedynczy standardowy udział plików platformy Azure na własnym koncie magazynu.
Istnieje limit 250 kont magazynu na subskrypcję na region świadczenia usługi Azure.
Porada
Biorąc pod uwagę te informacje, często konieczne jest grupowanie wielu folderów najwyższego poziomu na woluminach w nowy wspólny katalog główny. Następnie zsynchronizuj ten nowy katalog główny i wszystkie foldery zgrupowane w nim do pojedynczego udziału plików platformy Azure. Ta technika pozwala pozostać w granicach 30 synchronizacji udziałów plików platformy Azure na serwer.
To grupowanie w ramach wspólnego katalogu głównego nie ma wpływu na dostęp do danych. Listy ACL pozostają tak, jak są. Musisz dostosować tylko wszystkie ścieżki udziału (takie jak udziały SMB lub NFS), które mogą być dostępne w folderach serwera lokalnego, które zostały teraz zmienione w wspólny katalog główny. Nic innego się nie zmienia.
Ważne
Najważniejszym wektorem skalowania dla Azure File Sync jest liczba elementów (plików i folderów), które należy zsynchronizować. Aby uzyskać więcej szczegółów, przejrzyj cele skalowania Azure File Sync.
Najlepszym rozwiązaniem jest utrzymywanie niskiej liczby elementów na zakres synchronizacji. Jest to ważny czynnik, który należy wziąć pod uwagę podczas mapowania folderów na udziały plików platformy Azure. Azure File Sync jest testowany przy użyciu 100 milionów elementów (plików i folderów) na udział. Ale często najlepiej jest zachować liczbę przedmiotów poniżej 20 milionów lub 30 milionów w jednym udziale. Podziel przestrzeń nazw na wiele udziałów, jeśli zaczniesz przekraczać te liczby. Możesz nadal grupować wiele udziałów lokalnych w tym samym udziale plików platformy Azure, jeśli pozostaniesz mniej więcej poniżej tych liczb. Ta praktyka zapewni Ci miejsce na rozwój.
Istnieje możliwość, że w twojej sytuacji zestaw folderów może logicznie zsynchronizować się z tym samym udziałem plików platformy Azure (przy użyciu nowego wspólnego podejścia do folderu głównego wymienionego wcześniej). Jednak nadal lepiej jest przegrupować foldery, aby synchronizowały się z dwoma, a nie z jednym udziałem plików platformy Azure. Za pomocą tego podejścia można zachować równowagę liczby plików i folderów na udział plików na serwerze. Możesz również podzielić udziały lokalne i zsynchronizować je na więcej serwerów lokalnych, dodając możliwość synchronizacji z 30 więcej udziałów plików platformy Azure na dodatkowy serwer.
Typowe scenariusze i zagadnienia dotyczące synchronizacji plików
| # | Scenariusz synchronizacji | Obsługiwane | Zagadnienia (lub ograniczenia) | Rozwiązanie (lub obejście) |
|---|---|---|---|---|
| 1 | Serwer plików z wieloma dyskami/woluminami i wieloma udziałami do tego samego docelowego udziału plików platformy Azure (konsolidacja) | Nie | Docelowy udział plików platformy Azure (punkt końcowy w chmurze) obsługuje tylko synchronizację z jedną grupą synchronizacji. Grupa synchronizacji obsługuje tylko jeden punkt końcowy serwera na zarejestrowany serwer. |
1) Rozpocznij od zsynchronizowania jednego dysku (woluminu głównego) z docelowym udziałem plików platformy Azure. Rozpoczęcie pracy z największym dyskiem/woluminem pomoże w wymaganiach dotyczących magazynu w środowisku lokalnym. Skonfiguruj warstwę chmury, aby warstwować wszystkie dane do chmury, a tym samym zwolnić miejsce na dysku serwera plików. Przenieś dane z innych woluminów/udziałów do bieżącego woluminu, który jest synchronizowany. Wykonaj kroki jeden po drugim, dopóki wszystkie dane nie będą warstwowe do chmury/zmigrowane. 2) Docelowy jeden wolumin główny (dysk) naraz. Obsługa warstw w chmurze umożliwia warstwowanie wszystkich danych w celu kierowania udziału plików platformy Azure. Usuń punkt końcowy serwera z grupy synchronizacji, ponownie utwórz punkt końcowy przy użyciu następnego woluminu głównego/dysku, synchronizacji i powtórz ten proces. Uwaga: ponowne zainstalowanie agenta może być wymagane. 3) Zaleca się używanie wielu docelowych udziałów plików platformy Azure (tego samego lub innego konta magazynu na podstawie wymagań dotyczących wydajności) |
| 2 | Serwer plików z pojedynczym woluminem i wieloma udziałami do tego samego docelowego udziału plików platformy Azure (konsolidacja) | Tak | Nie można mieć wielu punktów końcowych serwera na zarejestrowany serwer synchronizowany z tym samym docelowym udziałem plików platformy Azure (takim samym jak powyżej) | Synchronizuj katalog główny woluminu z wieloma udziałami lub folderami najwyższego poziomu. Aby uzyskać więcej informacji, zobacz Share grouping concept and Volume sync (Udostępnianie koncepcji grupowania i synchronizacji woluminów ). |
| 3 | Serwer plików z wieloma udziałami i/lub woluminami do wielu udziałów plików platformy Azure w ramach pojedynczego konta magazynu (mapowanie udziału 1:1) | Tak | Pojedyncze wystąpienie systemu Windows Server (lub klaster) może synchronizować maksymalnie 30 udziałów plików platformy Azure. Konto magazynu jest celem skalowania pod kątem wydajności. Liczba operacji we/wy na sekundę i przepływność są współużytkowane między udziałami plików. Zachowaj liczbę elementów na grupę synchronizacji w ciągu 100 milionów elementów (plików i folderów) na udział. Najlepiej jest pozostać poniżej 20 lub 30 milionów na akcję. |
1) Użyj wielu grup synchronizacji (liczba grup synchronizacji = liczba udziałów plików platformy Azure do synchronizacji z). 2) W tym scenariuszu można zsynchronizować tylko 30 udziałów. Jeśli masz więcej niż 30 udziałów na tym serwerze plików, użyj koncepcji grupowania udziałów i synchronizacji woluminu , aby zmniejszyć liczbę folderów głównych lub najwyższego poziomu w źródle. 3) Użyj dodatkowych serwerów File Sync lokalnych i podziel/przenieś dane do tych serwerów, aby obejść ograniczenia dotyczące źródłowego serwera z systemem Windows. |
| 4 | Serwer plików z wieloma udziałami i/lub woluminami do wielu udziałów plików platformy Azure w ramach innego konta magazynu (mapowanie udziału 1:1) | Tak | Pojedyncze wystąpienie systemu Windows Server (lub klaster) może synchronizować maksymalnie 30 udziałów plików platformy Azure (to samo lub inne konto magazynu). Zachowaj liczbę elementów na grupę synchronizacji w ciągu 100 milionów elementów (plików i folderów) na udział. Najlepiej jest pozostać poniżej 20 lub 30 milionów na akcję. |
Takie samo podejście jak powyżej |
| 5 | Wiele serwerów plików z jednym (woluminem głównym lub udziałem) do tego samego docelowego udziału plików platformy Azure (konsolidacja) | Nie | Grupa synchronizacji nie może używać punktu końcowego chmury (udziału plików platformy Azure) już skonfigurowanego w innej grupie synchronizacji. Chociaż grupa synchronizacji może mieć punkty końcowe serwera na różnych serwerach plików, pliki nie mogą być odrębne. |
Postępuj zgodnie ze wskazówkami w scenariuszu nr 1 powyżej z dodatkowym uwzględnieniem określania wartości docelowej dla jednego serwera plików naraz. |
Tworzenie tabeli mapowania

Użyj poprzednich informacji, aby określić, ile potrzebnych udziałów plików platformy Azure i które części istniejących danych zostaną zakończone udziałem plików platformy Azure.
Utwórz tabelę, która rejestruje myśli, aby można je było odwoływać w razie potrzeby. Organizowanie jest ważne, ponieważ można łatwo utracić szczegóły planu mapowania podczas aprowizowania wielu zasobów platformy Azure jednocześnie. Pobierz następujący plik programu Excel, aby użyć go jako szablonu, aby ułatwić tworzenie mapowania.

|
Pobierz szablon mapowania przestrzeni nazw. |
Krok 5. Aprowizuj udziały plików platformy Azure
Udział plików platformy Azure jest przechowywany w chmurze na koncie usługi Azure Storage. W tym miejscu ma zastosowanie kolejny poziom zagadnień dotyczących wydajności.
Jeśli masz bardzo aktywne udziały (udziały używane przez wielu użytkowników i/lub aplikacje), dwa udziały plików platformy Azure mogą osiągnąć limit wydajności konta magazynu.
Najlepszym rozwiązaniem jest wdrożenie kont magazynu z jednym udziałem plików. Możesz połączyć wiele udziałów plików platformy Azure z tym samym kontem magazynu, jeśli masz udziały archiwalne lub spodziewasz się w nich niskiej aktywności dziennej.
Te zagadnienia dotyczą bardziej bezpośredniego dostępu do chmury (za pośrednictwem maszyny wirtualnej platformy Azure) niż do Azure File Sync. Jeśli planujesz używać tylko Azure File Sync tych udziałów, grupowanie kilku na jednym koncie usługi Azure Storage jest w porządku.
Jeśli utworzono listę udziałów, należy zamapować każdy udział na konto magazynu, w którym będzie on znajdować się.
W poprzedniej fazie określono odpowiednią liczbę udziałów. W tym kroku przedstawiono mapowanie kont magazynu na udziały plików. Teraz należy wdrożyć odpowiednią liczbę kont usługi Azure Storage z odpowiednią liczbą udziałów plików platformy Azure.
Upewnij się, że region każdego konta magazynu jest taki sam i jest zgodny z regionem wdrożonego już zasobu usługi synchronizacji magazynu.
Przestroga
Jeśli tworzysz udział plików platformy Azure z limitem 100 TiB, ten udział może używać tylko lokalnie nadmiarowego magazynu lub strefowo nadmiarowych opcji nadmiarowości magazynu. Przed użyciem 100 udziałów plików TiB należy wziąć pod uwagę potrzeby nadmiarowości magazynu.
Udziały plików platformy Azure są domyślnie tworzone z limitem 5 TiB. Wykonaj kroki opisane w temacie Tworzenie udziału plików platformy Azure , aby utworzyć duży udział plików.
Kolejną kwestią podczas wdrażania konta magazynu jest nadmiarowość usługi Azure Storage. Zobacz Opcje nadmiarowości usługi Azure Storage.
Nazwy zasobów są również ważne. Jeśli na przykład pogrupujesz wiele udziałów dla działu kadr na konto magazynu platformy Azure, należy odpowiednio nazwać konto magazynu. Podobnie podczas nadawania nazw udziałom plików platformy Azure należy używać nazw podobnych do używanych dla ich lokalnych odpowiedników.
Ustawienia konta magazynu
Istnieje wiele konfiguracji, które można wykonać na koncie magazynu. Poniższa lista kontrolna powinna być używana dla konfiguracji konta magazynu. Konfigurację sieci można zmienić na przykład po zakończeniu migracji.
- Duże udziały plików: włączone — duże udziały plików zwiększają wydajność i umożliwiają przechowywanie do 100TiB w udziale.
- Zapora i sieci wirtualne: wyłączone — nie konfiguruj żadnych ograniczeń adresów IP ani nie ograniczaj dostępu konta magazynu do określonej sieci wirtualnej. Publiczny punkt końcowy konta magazynu jest używany podczas migracji. Wszystkie adresy IP z maszyn wirtualnych platformy Azure muszą być dozwolone. Najlepiej skonfigurować wszystkie reguły zapory na koncie magazynu po migracji.
- Prywatne punkty końcowe: obsługiwane — można włączyć prywatne punkty końcowe, ale publiczny punkt końcowy jest używany do migracji i musi pozostać dostępny.
Krok 6. Konfigurowanie folderów docelowych systemu Windows Server
W poprzednich krokach rozważasz wszystkie aspekty, które będą określać składniki topologii synchronizacji. Nadszedł czas, aby przygotować serwer do odbierania plików do przekazania.
Utwórz wszystkie foldery, które będą synchronizowane z własnym udziałem plików platformy Azure. Ważne jest, aby postępować zgodnie ze strukturą folderów udokumentowaną wcześniej. Jeśli na przykład podjęto decyzję o zsynchronizowaniu wielu lokalnych udziałów SMB w jednym udziale plików platformy Azure, należy umieścić je w wspólnym folderze głównym na woluminie. Utwórz teraz ten docelowy folder główny na woluminie.
Liczba zaaprowizowanych udziałów plików platformy Azure powinna odpowiadać liczbie folderów utworzonych w tym kroku i liczbie woluminów, które zostaną zsynchronizowane na poziomie głównym.
Krok 7. Wdrażanie agenta Azure File Sync
W tej sekcji zainstalujesz agenta Azure File Sync w wystąpieniu systemu Windows Server.
W przewodniku wdrażania wyjaśniono, że należy wyłączyć konfigurację zwiększonych zabezpieczeń programu Internet Explorer. Ta miara zabezpieczeń nie ma zastosowania w przypadku Azure File Sync. Wyłączenie jej umożliwia uwierzytelnianie na platformie Azure bez żadnych problemów.
Otwórz program PowerShell. Zainstaluj wymagane moduły programu PowerShell przy użyciu następujących poleceń. Pamiętaj, aby zainstalować pełny moduł i dostawcę NuGet po wyświetleniu tego monitu.
Install-Module -Name Az -AllowClobber
Install-Module -Name Az.StorageSync
Jeśli masz jakiekolwiek problemy z dotarciem do Internetu z serwera, nadszedł czas, aby je rozwiązać. Azure File Sync używa dowolnego dostępnego połączenia sieciowego z Internetem. Wymagane jest również połączenie serwera proxy z Internetem. Możesz teraz skonfigurować serwer proxy dla całej maszyny lub podczas instalacji agenta określić serwer proxy, który będzie używany tylko Azure File Sync.
Jeśli skonfigurowanie serwera proxy oznacza, że musisz otworzyć zapory dla serwera, takie podejście może być akceptowalne. Na końcu instalacji serwera po zakończeniu rejestracji serwera raport łączności sieciowej pokaże dokładne adresy URL punktów końcowych na platformie Azure, z którymi Azure File Sync musi komunikować się z wybranym regionem. Raport informuje również, dlaczego komunikacja jest potrzebna. Raport umożliwia zablokowanie zapór wokół serwera pod określonymi adresami URL.
Możesz również zastosować bardziej konserwatywne podejście, w którym nie otwierasz zapór szeroko. Zamiast tego można ograniczyć serwer do komunikowania się z przestrzeniami nazw DNS wyższego poziomu. Aby uzyskać więcej informacji, zobacz Azure File Sync ustawienia serwera proxy i zapory. Postępuj zgodnie z własnymi najlepszymi rozwiązaniami dotyczącymi sieci.
Na końcu kreatora instalacji serwera zostanie otwarty kreator rejestracji serwera. Zarejestruj serwer we wcześniejszym zasobie platformy Azure usługi synchronizacji magazynu.
Te kroki opisano bardziej szczegółowo w przewodniku wdrażania, który zawiera moduły programu PowerShell, które należy zainstalować najpierw: Azure File Sync instalację agenta.
Użyj najnowszego agenta. Możesz pobrać go z Centrum pobierania Microsoft: Azure File Sync Agenta.
Po pomyślnej instalacji i rejestracji serwera możesz potwierdzić, że ten krok został ukończony pomyślnie. Przejdź do zasobu usługi synchronizacji magazynu w Azure Portal. W menu po lewej stronie przejdź do pozycji Zarejestrowane serwery. Zobaczysz tam serwer.
Krok 8. Konfigurowanie synchronizacji
Ten krok wiąże wszystkie zasoby i foldery skonfigurowane w wystąpieniu systemu Windows Server w poprzednich krokach.
- Zaloguj się w witrynie Azure Portal.
- Znajdź zasób usługi synchronizacji magazynu.
- Utwórz nową grupę synchronizacji w ramach zasobu usługi synchronizacji magazynu dla każdego udziału plików platformy Azure. W Azure File Sync terminologii udział plików platformy Azure stanie się punktem końcowym chmury w topologii synchronizacji, którą opisujesz podczas tworzenia grupy synchronizacji. Podczas tworzenia grupy synchronizacji nadaj jej znaną nazwę, aby rozpoznać, który zestaw plików jest tam synchronizowany. Upewnij się, że odwołujesz się do udziału plików platformy Azure o pasującej nazwie.
- Po utworzeniu grupy synchronizacji zostanie wyświetlony wiersz na liście grup synchronizacji. Wybierz nazwę (link), aby wyświetlić zawartość grupy synchronizacji. Udział plików platformy Azure zostanie wyświetlony w obszarze Punkty końcowe chmury.
- Znajdź przycisk Dodaj punkt końcowy serwera . Folder na serwerze lokalnym, który został zaaprowizowany, stanie się ścieżką dla tego punktu końcowego serwera.
Ostrzeżenie
Pamiętaj, aby włączyć obsługę warstw w chmurze! Jest to wymagane, jeśli serwer lokalny nie ma wystarczającej ilości miejsca do przechowywania całkowitego rozmiaru danych w magazynie StorSimple w chmurze. Ustaw zasady obsługi warstw tymczasowo na potrzeby migracji na 99% wolnego miejsca na woluminie.
Powtórz kroki tworzenia grupy synchronizacji i dodawania pasującego folderu serwera jako punktu końcowego serwera dla wszystkich udziałów plików platformy Azure /lokalizacji serwera, które należy skonfigurować do celów synchronizacji.
Krok 9. Kopiowanie plików
Podstawową metodą migracji jest narzędzie RoboCopy z urządzenia wirtualnego StorSimple do systemu Windows Server i Azure File Sync do udziałów plików platformy Azure.
Uruchom pierwszą kopię lokalną do folderu docelowego systemu Windows Server:
- Zidentyfikuj pierwszą lokalizację na wirtualnym urządzeniu StorSimple.
- Zidentyfikuj pasujący folder w systemie Windows Server, który ma już skonfigurowane Azure File Sync.
- Uruchamianie kopii przy użyciu narzędzia RoboCopy
Następujące polecenie narzędzia RoboCopy spowoduje wycofanie plików z usługi Azure Storage StorSimple do lokalnego urządzenia StorSimple, a następnie przeniesienie ich do folderu docelowego systemu Windows Server. System Windows Server zsynchronizuje go z udziałami plików platformy Azure. Ponieważ lokalny wolumin systemu Windows Server jest zapełniony, obsługa warstw w chmurze będzie uruchamiać pliki warstwowe, które zostały już pomyślnie zsynchronizowane. Obsługa warstw w chmurze wygeneruje wystarczającą ilość miejsca, aby kontynuować kopiowanie z urządzenia wirtualnego StorSimple. Obsługa warstw w chmurze sprawdza raz na godzinę, aby zobaczyć, co zostało zsynchronizowane, i zwolnić miejsce na dysku, aby osiągnąć 99% wolnego miejsca na woluminie.
robocopy <SourcePath> <Dest.Path> /MT:20 /R:2 /W:1 /B /MIR /IT /COPY:DATSO /DCOPY:DAT /NP /NFL /NDL /XD "System Volume Information" /UNILOG:<FilePathAndName>
| Przełącznik | Znaczenie |
|---|---|
/MT:n |
Umożliwia wielowątkowe uruchomienie narzędzia Robocopy. Wartość domyślna to n 8. Maksymalna liczba wątków to 128. Chociaż duża liczba wątków pomaga usycać dostępną przepustowość, nie oznacza to, że migracja zawsze będzie szybsza w przypadku większej liczby wątków. Testy z Azure Files wskazują od 8 do 20 pokazuje zrównoważoną wydajność początkowego przebiegu kopiowania. Kolejne /MIR przebiegi są stopniowo dotknięte dostępnym obciążeniem obliczeniowym a dostępną przepustowością sieci. W przypadku kolejnych przebiegów dokładniej dopasuj liczbę wątków do liczby rdzeni procesora i liczby wątków na rdzeń. Zastanów się, czy trzeba zarezerwować rdzenie dla innych zadań serwera produkcyjnego. Testy z Azure Files wykazały, że maksymalnie 64 wątki generują dobrą wydajność, ale tylko wtedy, gdy procesory mogą utrzymać je przy życiu w tym samym czasie. |
/R:n |
Maksymalna liczba ponownych prób dla pliku, którego nie udało się skopiować przy pierwszej próbie. Narzędzie Robocopy spróbuje czasy n przed trwałym niepowodzeniem kopiowania pliku w przebiegu. Możesz zoptymalizować wydajność przebiegu: wybierz wartość dwóch lub trzech, jeśli uważasz, że problemy z przekroczeniem limitu czasu spowodowały błędy w przeszłości. Może to być bardziej powszechne w przypadku łączy sieci WAN. Jeśli uważasz, że plik nie może skopiować, ponieważ był aktywnie używany, wybierz nie ponawianie próby lub wartość jednej z nich. Próba ponownie kilka sekund później może nie być wystarczająca, aby stan w użyciu pliku uległ zmianie. Użytkownicy lub aplikacje przechowujące otwarty plik mogą potrzebować godzin więcej czasu. W takim przypadku zaakceptowanie pliku nie zostało skopiowane i przechwycenie go w jednym z planowanych, kolejnych przebiegów robocopy może zakończyć się pomyślnie skopiowaniem pliku. To pomaga w bieżącym uruchomieniu, aby zakończyć się szybciej bez przedłużania przez wiele ponownych prób, które ostatecznie kończą się w większości błędów kopiowania z powodu plików nadal otwartych obok przekroczenia limitu czasu ponawiania. |
/W:n |
Określa czas, przez który narzędzie Robocopy czeka, zanim podejmie próbę skopiowania pliku, który nie został pomyślnie skopiowany podczas poprzedniej próby. n to liczba sekund oczekiwania między ponowną próbą. /W:njest często używany razem z ./R:n |
/B |
Uruchamia narzędzie Robocopy w tym samym trybie, którego użyłaby aplikacja do tworzenia kopii zapasowych. Ten przełącznik umożliwia narzędziu Robocopy przenoszenie plików, do których bieżący użytkownik nie ma uprawnień. Przełącznik kopii zapasowej zależy od uruchomienia polecenia Robocopy w konsoli z podwyższonym poziomem uprawnień administratora lub w oknie programu PowerShell. Jeśli używasz narzędzia Robocopy do Azure Files, upewnij się, że instalujesz udział plików platformy Azure przy użyciu klucza dostępu konta magazynu a tożsamości domeny. Jeśli tego nie zrobisz, komunikaty o błędach mogą nie być intuicyjnie prowadzące do rozwiązania problemu. |
/MIR |
(Duplikuj źródło do miejsca docelowego) Umożliwia programowi Robocopy kopiowanie tylko różnic między obiektem źródłowym i docelowym. Puste podkatalogi zostaną skopiowane. Elementy (pliki lub foldery), które uległy zmianie lub nie istnieją w miejscu docelowym, zostaną skopiowane. Elementy, które istnieją w miejscu docelowym, ale nie ma ich w źródle, zostaną wyczyszczone (usunięte) z miejsca docelowego. W przypadku korzystania z tego przełącznika dokładnie dopasuj strukturę folderu źródłowego i docelowego. Dopasowanie oznacza skopiowanie z poprawnego poziomu źródła i folderu do pasującego poziomu folderu w obiekcie docelowym. Tylko wtedy tworzenie kopii na zasadzie „nadrobienia zaległości” może zakończyć się powodzeniem. Gdy źródło i cel są niezgodne, użycie /MIR spowoduje usunięcie na dużą skalę i odzyskanie. |
/IT |
Zapewnia zachowanie wierności w pewnych scenariuszach dublowania. Jeśli na przykład plik napotka zmianę listy ACL i aktualizację atrybutu między dwoma przebiegami narzędzia Robocopy, zostanie oznaczony jako ukryty. Bez /ITelementu zmiana listy ACL może zostać pominięta przez narzędzie Robocopy i nie została przeniesiona do lokalizacji docelowej. |
/COPY:[copyflags] |
Wierność kopii pliku. Wartość domyślna: /COPY:DAT. Flagi kopiowania: D= Dane, A= Atrybuty, T= Znaczniki czasu, S= Zabezpieczenia = LISTY ACL NTFS, O= Informacje o właścicielu, U= Informacje o ditinguu. W udziale plików platformy Azure nie można przechowywać informacji o inspekcji. |
/DCOPY:[copyflags] |
Fidelity dla kopii katalogów. Wartość domyślna: /DCOPY:DA. Flagi kopiowania: D= Dane, A= Atrybuty, T= Znaczniki czasu. |
/NP |
Określa brak wyświetlania postępu kopiowania dla każdego pliku i folderu. Wyświetlanie postępu znacznie obniża wydajność kopiowania. |
/NFL |
Określa, że nazwy plików nie są rejestrowane. Poprawia wydajność kopiowania. |
/NDL |
Określa, że nazwy katalogów nie są rejestrowane. Poprawia wydajność kopiowania. |
/XD |
Określa katalogi, które mają być wykluczone. Podczas uruchamiania narzędzia Robocopy w katalogu głównym woluminu rozważ wykluczenie ukrytego System Volume Information folderu. Jeśli są one używane zgodnie z projektem, wszystkie informacje w nim są specyficzne dla dokładnego woluminu dla tego dokładnego systemu i można je ponownie skompilować na żądanie. Kopiowanie tych informacji nie będzie przydatne w chmurze ani kiedy dane są kiedykolwiek kopiowane z powrotem do innego woluminu systemu Windows. Pozostawienie tej zawartości nie powinno być uznawane za utratę danych. |
/UNILOG:<file name> |
Zapisuje stan w pliku dziennika jako Unicode. (Zastępuje istniejący dziennik). |
/L |
Tylko dla przebiegu testu Pliki mają być wyświetlane tylko na liście. Nie zostaną one skopiowane, usunięte ani oznaczone sygnaturą czasową. Często używane w /TEE przypadku danych wyjściowych konsoli. Może być konieczne usunięcie flag z przykładowego skryptu, takiego jak /NP, /NFLi /NDL, w celu uzyskania prawidłowych udokumentowanych wyników testów. |
/LFSM |
Tylko dla miejsc docelowych z magazynem warstwowym. Nieobsługiwane, gdy miejsce docelowe jest zdalnym udziałem SMB. Określa, że narzędzie Robocopy działa w "trybie wolnego miejsca". Ten przełącznik jest przydatny tylko w przypadku obiektów docelowych z magazynem warstwowym, który może zabrakło pojemności lokalnej przed zakończeniem narzędzia Robocopy. Został on dodany specjalnie do użytku z miejscem docelowym z obsługą warstw w chmurze usługi Azure File Sync. Można go używać niezależnie od usługi Azure File Sync. W tym trybie działanie narzędzia Robocopy zostanie wstrzymane za każdym razem, gdy skopiowanie pliku spowodowałoby przekroczenie wartości progowej dla wolnego miejsca na woluminie docelowym. Tę wartość można określić za pomocą /LFSM:n formularza flagi. Parametr n jest określony w bazie 2: nKB, nMBlub nGB. Jeśli /LFSM określono wartość bez jawnej podłogi, podłoga jest ustawiona na 10 procent rozmiaru woluminu docelowego. Tryb wolnego miejsca nie jest zgodny z /MT, /EFSRAWlub /ZB. /B Dodano obsługę systemu Windows Server 2022. Zobacz sekcję Windows Server 2022 i RoboCopy LFSM poniżej, aby uzyskać więcej informacji, w tym szczegółowe informacje o powiązanej usterce i obejście problemu. |
/Z |
Ostrożnie używajKopiuje pliki w trybie ponownego uruchamiania. Ten przełącznik jest zalecany tylko w niestabilnym środowisku sieciowym. Znacznie zmniejsza wydajność kopiowania z powodu dodatkowego rejestrowania. |
/ZB |
Ostrożnie używajUżywa trybu ponownego uruchamiania. W przypadku odmowy dostępu ta opcja używa trybu tworzenia kopii zapasowej. Ta opcja znacznie zmniejsza wydajność kopiowania z powodu tworzenia punktów kontrolnych. |
Ważne
Zalecamy używanie systemu Windows Server 2022. W przypadku korzystania z systemu Windows Server 2019 upewnij się, że zainstalowano najnowszą aktualizację poprawki lub co najmniej aktualizację systemu operacyjnego KB5005103 . Zawiera ważne poprawki dla niektórych scenariuszy robocopy.
Po pierwszym uruchomieniu polecenia RoboCopy użytkownicy i aplikacje nadal uzyskują dostęp do plików i folderów StorSimple i potencjalnie go zmieniają. Możliwe, że narzędzie RoboCopy przetworzyło katalog, przechodzi do następnego, a następnie użytkownik w lokalizacji źródłowej (StorSimple) dodaje, zmienia lub usuwa plik, który nie zostanie teraz przetworzony w tym bieżącym uruchomieniu narzędzia RoboCopy. To jest w porządku.
Pierwszy przebieg polega na przeniesieniu większości danych z powrotem do środowiska lokalnego, do systemu Windows Server i utworzenia kopii zapasowej w chmurze za pośrednictwem Azure File Sync. Może to potrwać długo, w zależności od:
- przepustowość pobierania
- szybkość wycofania usługi StorSimple w chmurze
- przepustowość przekazywania
- liczba elementów (plików i folderów), które muszą zostać przetworzone przez jedną z usług
Po zakończeniu początkowego uruchomienia uruchom ponownie polecenie.
Po raz drugi zakończy się szybciej, ponieważ musi tylko transportować zmiany, które miały miejsce od ostatniego uruchomienia. Te zmiany są prawdopodobnie lokalne w usłudze StorSimple, ponieważ są one najnowsze. To jeszcze bardziej skraca czas, ponieważ potrzeba wycofania z chmury jest ograniczona. Podczas tego drugiego przebiegu nadal nowe zmiany mogą się gromadzić.
Powtórz ten proces, dopóki nie okaże się, że czas potrzebny na ukończenie jest akceptowalnym przestojem.
Jeśli rozważysz akceptowalny przestój i przygotujesz się do przełączenia lokalizacji StorSimple w tryb offline, zrób to teraz: na przykład usuń udział SMB, aby żaden użytkownik nie mógł uzyskać dostępu do folderu lub wykonać inny odpowiedni krok, który uniemożliwia zmianę zawartości w tym folderze w usłudze StorSimple.
Uruchom jedną ostatnią rundę narzędzia RoboCopy. Spowoduje to odebranie wszelkich zmian, które mogły zostać pominięte. Czas wykonywania tego ostatniego kroku zależy od szybkości skanowania narzędzia RoboCopy. Możesz oszacować czas (równy przestój), mierząc czas poprzedniego uruchomienia.
Utwórz udział w folderze systemu Windows Server i ewentualnie dostosuj wdrożenie systemu plików DFS-N, aby wskazywało go. Pamiętaj, aby ustawić te same uprawnienia na poziomie udziału co w udziale SMB usługi StorSimple.
Zakończono migrację udziału/grupy udziałów do wspólnego katalogu głównego lub woluminu. (W zależności od zamapowanego elementu i decyzji, że konieczne jest przejście do tego samego udziału plików platformy Azure).
Możesz spróbować uruchomić kilka z tych kopii równolegle. Zalecamy przetwarzanie zakresu jednego udziału plików platformy Azure naraz.
Ostrzeżenie
Po przeniesieniu wszystkich danych z usługi StorSimple do systemu Windows Server i zakończeniu migracji: wróć do wszystkich grup synchronizacji w Azure Portal i dostosuj wartość procentu wolnego miejsca do warstwowania w chmurze, aby uzyskać lepszą wartość w celu wykorzystania pamięci podręcznej, powiedzmy 20%.
Zasady wolnego miejsca w warstwie chmury działają na poziomie woluminu z potencjalnie wieloma punktami końcowymi serwera synchronizowanymi z nim. Jeśli zapomnisz dostosować wolne miejsce na nawet jednym punkcie końcowym serwera, synchronizacja będzie nadal stosować najbardziej restrykcyjną regułę i spróbuje zachować 99% wolnego miejsca na dysku, co sprawia, że lokalna pamięć podręczna nie działa zgodnie z oczekiwaniami. Chyba że celem jest posiadanie tylko przestrzeni nazw woluminu, który zawiera tylko rzadko używane dane archiwalne.
Rozwiązywanie problemów
Najbardziej prawdopodobnym problemem, który można napotkać, jest to, że polecenie RoboCopy kończy się niepowodzeniem z komunikatem "Wolumin pełny" po stronie systemu Windows Server. W takim przypadku szybkość pobierania jest prawdopodobnie lepsza niż szybkość przekazywania. Obsługa warstw w chmurze działa co godzinę, aby ewakuować zawartość z lokalnego dysku systemu Windows Server, który został zsynchronizowany.
Umożliwiaj synchronizację postępu synchronizacji i zwalnianie miejsca na dysku w warstwie chmury. Możesz zauważyć, że w Eksplorator plików w systemie Windows Server.
Gdy system Windows Server ma wystarczającą ilość dostępnej pojemności, ponowne uruchamianie polecenia rozwiąże problem. Nic się nie łamie, gdy wpadniesz w tę sytuację i możesz iść naprzód z ufnością. Niedogodności związane z ponownym uruchomieniem polecenia są jedyną konsekwencją.
Możesz również napotkać inne problemy Azure File Sync. Jeśli tak się stanie, zobacz przewodnik rozwiązywania problemów Azure File Sync.
Szybkość i szybkość działania danego przebiegu narzędzia RoboCopy będzie zależeć od kilku czynników:
- Liczba operacji we/wy na sekundę w magazynie źródłowym i docelowym
- dostępna przepustowość sieci między źródłem a obiektem docelowym
- możliwość szybkiego przetwarzania plików i folderów w przestrzeni nazw
- liczba zmian między uruchomionymi narzędziem RoboCopy
- rozmiar i liczba plików, które należy skopiować
Zagadnienia dotyczące liczby operacji we/wy na sekundę i przepustowości
W tej kategorii należy wziąć pod uwagę możliwości magazynu źródłowego, magazynu docelowego i sieci łączącej je. Maksymalna możliwa przepływność zależy od najwolniejszego z tych trzech składników. Upewnij się, że infrastruktura sieciowa jest skonfigurowana do obsługi optymalnej szybkości transferu w celu uzyskania najlepszych możliwości.
Przestroga
Podczas kopiowania tak szybko, jak to możliwe, jest często najbardziej pożądane, rozważ wykorzystanie sieci lokalnej i urządzenia NAS dla innych, często krytycznych zadań biznesowych.
Kopiowanie tak szybko, jak to możliwe, może nie być pożądane, gdy istnieje ryzyko, że migracja może monopolizować dostępne zasoby.
- Zastanów się, kiedy najlepiej w twoim środowisku uruchamiać migracje: w ciągu dnia, poza godzinami pracy lub w weekendy.
- Rozważ również użycie funkcji QoS sieci w systemie Windows Server, aby ograniczyć szybkość narzędzia RoboCopy.
- Unikaj niepotrzebnej pracy dla narzędzi migracji.
Narzędzie RoboCopy może wstawić opóźnienia między pakietami, określając /IPG:n przełącznik, w którym n jest mierzony w milisekundach między pakietami RoboCopy. Użycie tego przełącznika może pomóc uniknąć monopolizacji zasobów na urządzeniach ograniczonych przez we/wy i zatłoczonych łączy sieciowych.
/IPG:n Nie można używać do precyzyjnego ograniczania przepustowości sieci do określonych Mb/s. Zamiast tego należy użyć funkcji QoS sieci systemu Windows Server. Narzędzie RoboCopy całkowicie opiera się na protokole SMB dla wszystkich potrzeb sieciowych. Korzystanie z protokołu SMB jest powodem, dla którego narzędzie RoboCopy nie może wpływać na samą przepływność sieci, ale może spowolnić jego użycie.
Podobna linia myślowa ma zastosowanie do liczby operacji we/wy na sekundę obserwowanych na serwerze NAS. Rozmiar klastra na woluminie NAS, rozmiarach pakietów i tablicy innych czynników wpływa na obserwowaną liczbę operacji we/wy na sekundę. Wprowadzenie opóźnienia między pakietami jest często najprostszym sposobem kontrolowania obciążenia na serwerze NAS. Przetestuj wiele wartości, na przykład z około 20 milisekund (n=20) do wielokrotności tej liczby. Po wprowadzeniu opóźnienia możesz ocenić, czy inne aplikacje mogą teraz działać zgodnie z oczekiwaniami. Ta strategia optymalizacji umożliwi znalezienie optymalnej szybkości narzędzia RoboCopy w środowisku.
Szybkość przetwarzania
Narzędzie RoboCopy przejdzie przez przestrzeń nazw, do których jest wskazywana, i ocenia poszczególne pliki i foldery do skopiowania. Każdy plik będzie oceniany podczas początkowej kopii i podczas nadrabiania zaległości. Na przykład powtarzające się uruchomienia narzędzia RoboCopy /MIR względem tych samych lokalizacji źródłowych i docelowych. Te powtarzające się przebiegi są przydatne, aby zminimalizować przestoje dla użytkowników i aplikacji oraz poprawić ogólny współczynnik powodzenia migrowanych plików.
Często domyślnie rozważamy przepustowość jako najbardziej ograniczający czynnik migracji — i to może być prawdziwe. Jednak możliwość wyliczenia przestrzeni nazw może mieć wpływ na całkowity czas kopiowania jeszcze większej liczby przestrzeni nazw z mniejszymi plikami. Należy pamiętać, że kopiowanie 1 TiB małych plików trwa znacznie dłużej niż kopiowanie 1 TiB mniej, ale większych plików, przy założeniu, że wszystkie inne zmienne pozostają takie same. W związku z tym w przypadku migrowania dużej liczby małych plików może wystąpić powolne przesyłanie. Jest to oczekiwane zachowanie.
Przyczyną tej różnicy jest moc obliczeniowa wymagana do przejścia przez przestrzeń nazw. Narzędzie RoboCopy obsługuje kopie wielowątkowe za pośrednictwem parametru /MT:n , w którym n oznacza liczbę wątków do użycia. Dlatego podczas aprowizowania maszyny specjalnie dla narzędzia RoboCopy należy wziąć pod uwagę liczbę rdzeni procesora i ich relację z liczbą wątków, które udostępniają. Najczęściej są to dwa wątki na rdzeń. Liczba rdzeni i wątków maszyny jest ważnym punktem danych, który decyduje o tym, jakie wartości /MT:n wielowątkowe należy określić. Należy również wziąć pod uwagę liczbę zadań RoboCopy, które planujesz uruchomić równolegle na danej maszynie.
Więcej wątków skopiuje nasz przykład 1 TiB małych plików znacznie szybciej niż mniej wątków. Jednocześnie dodatkowa inwestycja zasobów w nasze 1 TiB większych plików może nie przynieść proporcjonalnych korzyści. Duża liczba wątków podejmie próbę skopiowania większej liczby dużych plików za pośrednictwem sieci jednocześnie. To dodatkowe działanie sieciowe zwiększa prawdopodobieństwo ograniczenia przepływności lub liczby operacji we/wy na sekundę magazynu.
Podczas pierwszego narzędzia RoboCopy do pustego miejsca docelowego lub różnicowego przebiegu z dużą częścią zmienionych plików prawdopodobnie przepływność sieci jest ograniczona. Zacznij od dużej liczby wątków dla początkowego przebiegu. Duża liczba wątków, nawet poza aktualnie dostępnymi wątkami na maszynie, pomaga usycać dostępną przepustowość sieci. Kolejne uruchomienia /MIR są stopniowo dotknięte przez przetwarzanie elementów. Mniejsza liczba zmian w różnicowym przebiegu oznacza mniejsze transport danych przez sieć. Szybkość jest teraz bardziej zależna od możliwości przetwarzania elementów przestrzeni nazw niż przenoszenia ich za pośrednictwem łącza sieciowego. W przypadku kolejnych przebiegów dopasuj wartość liczby wątków do liczby rdzeni procesora i liczby wątków na rdzeń. Rozważ, czy rdzenie muszą być zarezerwowane dla innych zadań, które może mieć serwer produkcyjny.
Porada
Reguła kciuka: Pierwsze uruchomienie narzędzia RoboCopy, które spowoduje przeniesienie dużej ilości danych sieci o wyższym opóźnieniu, korzyści wynikające z nadmiernej aprowizacji liczby wątków (/MT:n). Kolejne przebiegi będą kopiować mniej różnic i częściej przechodzisz z ograniczenia przepływności sieci do ograniczenia mocy obliczeniowej. W takich okolicznościach często lepiej jest dopasować liczbę wątków narzędzia RoboCopy do rzeczywiście dostępnych wątków na maszynie. Nadmierna aprowizacja w tym scenariuszu może prowadzić do większej liczby zmian kontekstu w procesorze, co może spowodować spowolnienie kopiowania.
Unikaj niepotrzebnej pracy
Unikaj zmian na dużą skalę w przestrzeni nazw. Na przykład przenoszenie plików między katalogami, zmienianie właściwości na dużą skalę lub zmienianie uprawnień (listy ACL NTFS). Szczególnie zmiany listy ACL mogą mieć duży wpływ, ponieważ często mają kaskadowy wpływ zmian na pliki niższe w hierarchii folderów. Konsekwencje mogą być następujące:
- rozszerzony czas wykonywania zadania RoboCopy, ponieważ każdy plik i folder, którego dotyczy zmiana listy ACL, musi zostać zaktualizowana
- Ponowne kopiowanie przeniesionych wcześniej danych może wymagać ponownego skopiowania. Na przykład należy skopiować więcej danych, gdy struktury folderów zmieniają się po skopiowaniu plików wcześniej. Zadanie RoboCopy nie może "odtworzyć" zmiany przestrzeni nazw. Następne zadanie musi przeczyścić pliki wcześniej przetransportowane do starej struktury folderów i ponownie przekazać pliki w nowej strukturze folderów.
Innym ważnym aspektem jest efektywne użycie narzędzia RoboCopy. W przypadku zalecanego skryptu RoboCopy utworzysz i zapiszesz plik dziennika pod kątem błędów. Mogą wystąpić błędy kopiowania — jest to normalne. Te błędy często sprawiają, że konieczne jest uruchomienie wielu rund narzędzia do kopiowania, takiego jak RoboCopy. Początkowy przebieg, na przykład z serwera NAS do urządzenia DataBox lub serwera do udziału plików platformy Azure. I co najmniej jeden dodatkowy przebieg z przełącznikiem /MIR, aby przechwycić i ponowić próby plików, które nie są kopiowane.
Należy przygotować się do uruchamiania wielu rund narzędzia RoboCopy względem danego zakresu przestrzeni nazw. Kolejne przebiegi zakończą się szybciej, ponieważ mają mniej do skopiowania, ale są coraz bardziej ograniczone przez szybkość przetwarzania przestrzeni nazw. Gdy uruchamiasz wiele rund, możesz przyspieszyć każdą rundę, nie mając narzędzia RoboCopy spróbować nieuzasadnionie ciężko skopiować wszystko w danym przebiegu. Te przełączniki RoboCopy mogą mieć znaczącą różnicę:
/R:nn = częstotliwość ponawiania próby skopiowania pliku, którego działanie zakończyło się niepowodzeniem/W:nn = ile sekund oczekiwania między ponownych próbami
/R:5 /W:5 jest rozsądnym ustawieniem, które można dostosować do swoich potrzeb. W tym przykładzie plik, który zakończył się niepowodzeniem, zostanie ponowiony pięć razy, a pięciosekundowy czas oczekiwania między ponownymi próbami. Jeśli nadal nie można skopiować pliku, następne zadanie narzędzia RoboCopy spróbuje ponownie. Często pliki, które zakończyły się niepowodzeniem, ponieważ są używane lub z powodu problemów z przekroczeniem limitu czasu mogą zostać pomyślnie skopiowane w ten sposób.
Windows Server 2022 i RoboCopy LFSM
Przełącznik /LFSM RoboCopy może służyć do uniknięcia niepowodzenia zadania RoboCopy z powodu błędu pełnego woluminu . Narzędzie RoboCopy zostanie wstrzymane za każdym razem, gdy kopia pliku spowoduje, że wolne miejsce na woluminie docelowym będzie przekraczać wartość "floor".
Użyj narzędzia RoboCopy z systemem Windows Server 2022. Tylko ta wersja narzędzia RoboCopy zawiera ważne poprawki błędów i funkcje, które sprawiają, że przełącznik jest zgodny z dodatkowymi flagami wymaganymi w większości migracji. Na przykład zgodność z flagą /B .
/B uruchamia narzędzie RoboCopy w tym samym trybie, którego będzie używać aplikacja do tworzenia kopii zapasowych. Ten przełącznik umożliwia programowi RoboCopy przenoszenie plików, do których bieżący użytkownik nie ma uprawnień.
Zwykle narzędzie RoboCopy można uruchomić na maszynie źródłowej, docelowej lub trzeciej.
Ważne
Jeśli zamierzasz używać /LFSMnarzędzia , narzędzie RoboCopy musi być uruchomione na docelowym serwerze Azure File Sync systemu Windows Server 2022.
Należy również pamiętać, że w przypadku /LFSM programu należy również użyć ścieżki lokalnej dla lokalizacji docelowej, a nie ścieżki UNC. Na przykład jako ścieżka docelowa należy użyć ścieżki E:\Foldername zamiast ścieżki UNC, takiej jak \\ServerName\FolderName.
Przestroga
Obecnie dostępna wersja narzędzia RoboCopy w systemie Windows Server 2022 zawiera usterkę, która powoduje, że wstrzymanie jest liczone względem liczby błędów na plik. Zastosuj następujące obejście.
Zalecane /R:2 /W:1 flagi zwiększają prawdopodobieństwo niepowodzenia pliku z powodu wywołanej wstrzymania /LFSM . W tym przykładzie plik, który nie został skopiowany po 3 wstrzymaniu, ponieważ /LFSM spowodował wstrzymanie, spowoduje niepoprawne niepowodzenie pliku narzędzia RoboCopy. Obejściem tego problemu jest użycie wyższych wartości dla elementów /R:n i /W:n. Dobrym przykładem jest /R:10 /W:1800 (10 ponownych prób 30 minut każdy). Powinno to dać Azure File Sync czas algorytmu obsługi warstw w celu utworzenia miejsca na woluminie docelowym.
Ta usterka została usunięta, ale poprawka nie jest jeszcze publicznie dostępna. Sprawdź ten akapit pod kątem aktualizacji dotyczących dostępności poprawki i sposobu jej wdrażania.
Uwaga
Nadal masz pytania lub napotkano jakieś problemy?
Jesteśmy tutaj, aby pomóc: 
Odpowiednie linki
Zawartość migracji:
Azure File Sync zawartości: