Wskazówki dotyczące zabezpieczeń na poziomie wiersza w programie Power BI Desktop
Ten artykuł jest przeznaczony dla Ciebie jako modeler danych pracujący z programem Power BI Desktop. Opisuje on dobre rozwiązania projektowe dotyczące wymuszania zabezpieczeń na poziomie wiersza w modelach danych.
Ważne jest, aby zrozumieć wiersze tabeli filtrów zabezpieczeń na poziomie wiersza. Nie można ich skonfigurować w celu ograniczenia dostępu do obiektów modelu, w tym tabel, kolumn lub miar.
Uwaga
W tym artykule nie opisano zabezpieczeń na poziomie wiersza ani sposobu jego konfigurowania. Aby uzyskać więcej informacji, zobacz Ograniczanie dostępu do danych przy użyciu zabezpieczeń na poziomie wiersza dla programu Power BI Desktop.
Ponadto nie obejmuje wymuszania zabezpieczeń na poziomie wiersza w połączeniach na żywo z modelami hostowanymi zewnętrznie za pomocą usług Azure Analysis Services lub SQL Server Analysis Services. W takich przypadkach zabezpieczenia na poziomie wiersza są wymuszane przez usługi Analysis Services. Gdy usługa Power BI łączy się przy użyciu logowania jednokrotnego (SSO), usługi Analysis Services będą wymuszać zabezpieczenia na poziomie wiersza (chyba że konto ma uprawnienia administratora).
Tworzenie ról
Istnieje możliwość utworzenia wielu ról. Jeśli rozważasz wymagania dotyczące uprawnień dla jednego użytkownika raportu, staraj się utworzyć jedną rolę, która przyznaje wszystkie te uprawnienia, zamiast projektu, w którym użytkownik raportu będzie członkiem wielu ról. Jest to spowodowane tym, że użytkownik raportu może mapować na wiele ról, bezpośrednio przy użyciu konta użytkownika lub pośrednio przez członkostwo w grupie zabezpieczeń. Wiele mapowań ról może spowodować nieoczekiwane wyniki.
Gdy użytkownik raportu jest przypisany do wielu ról, filtry zabezpieczeń na poziomie wiersza stają się addytywne. Oznacza to, że użytkownicy raportu mogą wyświetlać wiersze tabeli reprezentujące połączenie tych filtrów. Co więcej, w niektórych scenariuszach nie można zagwarantować, że użytkownik raportu nie widzi wierszy w tabeli. Tak więc, w przeciwieństwie do uprawnień stosowanych do obiektów bazy danych programu SQL Server (i innych modeli uprawnień), zasada "raz odmowa zawsze odmawiana" nie ma zastosowania.
Rozważ model z dwiema rolami: pierwsza rola o nazwie Workers ogranicza dostęp do wszystkich wierszy tabeli Listy płac przy użyciu następującego wyrażenia reguły:
FALSE()
Uwaga
Reguła nie zwróci wierszy tabeli, gdy wyrażenie zwróci wartość FALSE.
Jednak druga rola o nazwie Menedżerowie umożliwia dostęp do wszystkich wierszy tabeli Listy płac przy użyciu następującego wyrażenia reguły:
TRUE()
Należy pamiętać: jeśli użytkownik raportu mapuje obie role, zobaczy wszystkie wiersze tabeli Listy płac .
Optymalizowanie zabezpieczeń na poziomie wiersza
Zabezpieczenia na poziomie wiersza działają przez automatyczne stosowanie filtrów do każdego zapytania języka DAX, a te filtry mogą mieć negatywny wpływ na wydajność zapytań. Dlatego efektywne zabezpieczenia na poziomie wiersza sprowadza się do dobrego projektu modelu. Ważne jest, aby postępować zgodnie ze wskazówkami dotyczącymi projektowania modelu, jak opisano w następujących artykułach:
- Omówienie schematu gwiazdy i znaczenia usługi Power BI
- Wszystkie artykuły ze wskazówkami dotyczącymi relacji znajdują się w dokumentacji wskazówek dotyczących usługi Power BI
Ogólnie rzecz biorąc, często bardziej wydajne jest wymuszanie filtrów zabezpieczeń na poziomie wiersza w tabelach wymiarów, a nie tabel faktów. Ponadto polegaj na dobrze zaprojektowanych relacjach, aby zapewnić propagację filtrów zabezpieczeń na poziomie wiersza do innych tabel modelu. Filtry zabezpieczeń na poziomie wiersza są propagowane tylko za pomocą aktywnych relacji. Dlatego należy unikać używania funkcji JĘZYKA DAX LOOKUPVALUE , gdy relacje modelu mogą osiągnąć ten sam wynik.
Zawsze, gdy filtry zabezpieczeń na poziomie wiersza są wymuszane w tabelach DirectQuery i istnieją relacje z innymi tabelami trybu DirectQuery, pamiętaj, aby zoptymalizować źródłową bazę danych. Może ona obejmować projektowanie odpowiednich indeksów lub używanie utrwanych kolumn obliczeniowych. Aby uzyskać więcej informacji, zobacz Wskazówki dotyczące modelu DirectQuery w programie Power BI Desktop.
Mierzenie wpływu zabezpieczeń na zabezpieczenia na poziomie wiersza
Istnieje możliwość mierzenia wpływu filtrów zabezpieczeń na zabezpieczenia na poziomie wiersza w programie Power BI Desktop przy użyciu Analizator wydajności. Najpierw określ czasy trwania zapytań wizualizacji raportu, gdy zabezpieczenia na poziomie wiersza nie są wymuszane. Następnie użyj polecenia Wyświetl jako na karcie wstążki Modelowanie , aby wymusić zabezpieczenia na poziomie wiersza i określić i porównać czasy trwania zapytań.
Konfigurowanie mapowań ról
Po opublikowaniu w usłudze Power BI należy mapować elementy członkowskie na role semantyczne (wcześniej znane jako zestaw danych). Tylko właściciele modelu semantycznego lub administratorzy obszaru roboczego mogą dodawać członków do ról. Aby uzyskać więcej informacji, zobacz Zabezpieczenia na poziomie wiersza w usłudze Power BI (Zarządzanie zabezpieczeniami w modelu).
Członkowie mogą być kontami użytkowników, grupami zabezpieczeń, grupami dystrybucyjnym lub grupami obsługującymi pocztę. Jeśli to możliwe, zalecamy mapowanie grup zabezpieczeń na semantyczne role modelu. Obejmuje ona zarządzanie członkostwem w grupach zabezpieczeń w usłudze Microsoft Entra ID (wcześniej nazywanym usługą Azure Active Directory). Być może deleguje zadanie do administratorów sieci.
Weryfikowanie ról
Przetestuj każdą rolę, aby upewnić się, że prawidłowo filtruje model. Można to łatwo zrobić za pomocą polecenia Wyświetl jako na karcie wstążki Modelowanie .
Jeśli model ma reguły dynamiczne korzystające z funkcji USERNAME języka DAX, należy przetestować oczekiwane i nieoczekiwane wartości. Podczas osadzania zawartości usługi Power BI — w szczególności przy użyciu scenariusza osadzania dla klientów — logika aplikacji może przekazać dowolną wartość jako obowiązującą nazwę użytkownika tożsamości. Jeśli to możliwe, upewnij się, że przypadkowe lub złośliwe wartości powodują, że filtry nie zwracają żadnych wierszy.
Rozważmy przykład użycia usługi Power BI Embedded, gdzie aplikacja przekazuje rolę zadania użytkownika jako obowiązującą nazwę użytkownika: jest to "Menedżer" lub "Proces roboczy". Menedżerowie widzą wszystkie wiersze, ale pracownicy mogą zobaczyć tylko wiersze, w których wartość kolumny Type to "Internal".
Zdefiniowano następujące wyrażenie reguły:
IF(
USERNAME() = "Worker",
[Type] = "Internal",
TRUE()
)
Problem z tym wyrażeniem reguły polega na tym, że wszystkie wartości, z wyjątkiem procesu roboczego, zwracają wszystkie wiersze tabeli. Dlatego przypadkowa wartość, taka jak "Wrker", przypadkowo zwraca wszystkie wiersze tabeli. W związku z tym bezpieczniej jest napisać wyrażenie, które testuje dla każdej oczekiwanej wartości. W poniższym ulepszonym wyrażeniu reguły nieoczekiwana wartość powoduje, że tabela nie zwraca żadnych wierszy.
IF(
USERNAME() = "Worker",
[Type] = "Internal",
IF(
USERNAME() = "Manager",
TRUE(),
FALSE()
)
)
Projektowanie częściowych zabezpieczeń na poziomie wiersza
Czasami obliczenia wymagają wartości, które nie są ograniczone przez filtry zabezpieczeń na poziomie wiersza. Na przykład raport może wymagać wyświetlenia współczynnika przychodów uzyskanych w regionie sprzedaży użytkownika raportu ze wszystkich uzyskanych przychodów.
Chociaż wyrażenie języka DAX nie może zastąpić zabezpieczeń na poziomie wiersza — w rzeczywistości nie może nawet określić, że zabezpieczenia na poziomie wiersza są wymuszane — można użyć tabeli modelu podsumowania. Tabela modelu podsumowania jest odpytywane w celu pobrania przychodu dla "wszystkich regionów" i nie jest ograniczona przez żadne filtry zabezpieczeń na poziomie wiersza.
Zobaczmy, jak można zaimplementować to wymaganie projektowe. Najpierw należy wziąć pod uwagę następujący projekt modelu:
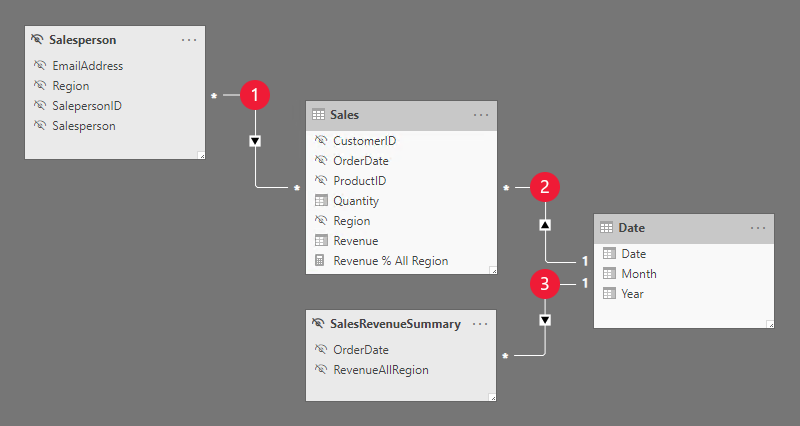
Model składa się z czterech tabel:
- Tabela Salesperson przechowuje jeden wiersz na sprzedawcę. Zawiera on kolumnę EmailAddress , która przechowuje adres e-mail dla każdego sprzedawcy. Ta tabela jest ukryta.
- Tabela Sales (Sprzedaż ) przechowuje jeden wiersz na zamówienie. Obejmuje ona miarę Revenue % All Region (Procent przychodu w całym regionie ), która została zaprojektowana w celu zwrócenia wskaźnika przychodów uzyskanych przez region użytkownika raportu w stosunku do przychodów uzyskanych we wszystkich regionach.
- Tabela Date (Data) przechowuje jeden wiersz na datę i umożliwia filtrowanie i grupowanie roku i miesiąca.
- Tabela obliczeniowa SalesRevenueSummary . Przechowuje całkowity przychód dla każdej daty zamówienia. Ta tabela jest ukryta.
Następujące wyrażenie definiuje tabelę obliczeniową SalesRevenueSummary :
SalesRevenueSummary =
SUMMARIZECOLUMNS(
Sales[OrderDate],
"RevenueAllRegion", SUM(Sales[Revenue])
)
Do tabeli Salesperson jest stosowana następująca reguła zabezpieczeń na poziomie wiersza:
[EmailAddress] = USERNAME()
Każda z trzech relacji modelu jest opisana w poniższej tabeli:
| Relacja | opis |
|---|---|
 |
Istnieje relacja wiele do wielu między tabelami Salesperson i Sales . Reguła zabezpieczeń na poziomie wiersza filtruje kolumnę EmailAddress ukrytej tabeli Salesperson przy użyciu funkcji DAX USERNAME. Wartość kolumny Region (dla użytkownika raportu) jest propagowana do tabeli Sales. |
 |
Istnieje relacja jeden do wielu między tabelami Date i Sales . |
 |
Istnieje relacja jeden do wielu między tabelami Date i SalesRevenueSummary . |
Następujące wyrażenie definiuje miarę Revenue % All Region (Procent przychodu we wszystkich regionach ):
Revenue % All Region =
DIVIDE(
SUM(Sales[Revenue]),
SUM(SalesRevenueSummary[RevenueAllRegion])
)
Uwaga
Należy zachować ostrożność, aby uniknąć ujawniania poufnych faktów. Jeśli w tym przykładzie istnieją tylko dwa regiony, wówczas użytkownik raportu będzie mógł obliczyć przychód dla innego regionu.
Kiedy należy unikać używania zabezpieczeń na poziomie wiersza
Czasami warto unikać używania zabezpieczeń na poziomie wiersza. Jeśli masz tylko kilka uproszczonych reguł zabezpieczeń na poziomie wiersza, które stosują filtry statyczne, rozważ opublikowanie wielu modeli semantycznych. Żaden z semantycznych modeli nie definiuje ról, ponieważ każdy model semantyczny zawiera dane dla określonej grupy odbiorców raportu, która ma te same uprawnienia do danych. Następnie utwórz jeden obszar roboczy dla odbiorców i przypisz uprawnienia dostępu do obszaru roboczego lub aplikacji.
Na przykład firma, która ma tylko dwa regiony sprzedaży, decyduje się opublikować model semantyczny dla każdego regionu sprzedaży w różnych obszarach roboczych. Modele semantyczne nie wymuszają zabezpieczeń na poziomie wiersza. Jednak używają parametrów zapytania do filtrowania danych źródłowych. W ten sposób ten sam model jest publikowany w każdym obszarze roboczym — mają po prostu różne wartości parametrów modelu semantycznego. Sprzedawcy mają przypisany dostęp tylko do jednego z obszarów roboczych (lub opublikowanych aplikacji).
Istnieje kilka zalet związanych z unikaniem zabezpieczeń na poziomie wiersza:
- Zwiększona wydajność zapytań: może to spowodować zwiększenie wydajności z powodu mniejszej liczby filtrów.
- Mniejsze modele: chociaż powoduje to zwiększenie liczby modeli, są one mniejsze. Mniejsze modele mogą poprawić czas odpowiedzi zapytań i odświeżania danych, zwłaszcza jeśli wydajność hostingu ma presję na zasoby. Ponadto łatwiej jest zachować rozmiary modeli poniżej limitów rozmiaru narzuconych przez pojemność. Na koniec łatwiej jest równoważyć obciążenia w różnych pojemnościach, ponieważ można tworzyć obszary robocze w różnych pojemnościach lub przenosić obszary robocze do różnych pojemności.
- Dodatkowe funkcje: można używać funkcji usługi Power BI, które nie działają z zabezpieczeniami na poziomie wiersza, takimi jak Publikowanie w Internecie.
Istnieją jednak wady związane z unikaniem zabezpieczeń na poziomie wiersza:
- Wiele obszarów roboczych: jeden obszar roboczy jest wymagany dla każdej grupy odbiorców raportu. Jeśli aplikacje są publikowane, oznacza to również, że istnieje jedna aplikacja dla odbiorców użytkowników raportu.
- Duplikowanie zawartości: raporty i pulpity nawigacyjne muszą być tworzone w każdym obszarze roboczym. Wymaga to większego nakładu pracy i czasu na skonfigurowanie i konserwację.
- Użytkownicy z wysokimi uprawnieniami: użytkownicy z wysokimi uprawnieniami, którzy należą do wielu odbiorców użytkowników raportów, nie widzą skonsolidowanego widoku danych. Należy otworzyć wiele raportów (z różnych obszarów roboczych lub aplikacji).
Rozwiązywanie problemów z zabezpieczeniami na poziomie wiersza
Jeśli zabezpieczenia na poziomie wiersza generują nieoczekiwane wyniki, sprawdź następujące problemy:
- Istnieją nieprawidłowe relacje między tabelami modelu, jeśli chodzi o mapowania kolumn i kierunki filtrowania. Należy pamiętać, że filtry zabezpieczeń na poziomie wiersza są propagowane tylko za pośrednictwem aktywnych relacji.
- Właściwość Zastosuj filtr zabezpieczeń w obu kierunkach relacji nie jest poprawnie ustawiona. Aby uzyskać więcej informacji, zobacz Dwukierunkowe wskazówki dotyczące relacji.
- Tabele nie zawierają żadnych danych.
- Niepoprawne wartości są ładowane do tabel.
- Użytkownik jest mapowany na wiele ról.
- Model zawiera tabele agregacji, a reguły zabezpieczeń na poziomie wiersza nie filtrują spójnie agregacji i szczegółów. Aby uzyskać więcej informacji, zobacz Używanie agregacji w programie Power BI Desktop (zabezpieczenia na poziomie wiersza dla agregacji).
Jeśli określony użytkownik nie widzi żadnych danych, może to być spowodowane tym, że ich nazwa UPN nie jest przechowywana lub wprowadzana niepoprawnie. Może się to zdarzyć nagle, ponieważ jego konto użytkownika zmieniło się w wyniku zmiany nazwy.
Napiwek
Na potrzeby testowania dodaj miarę zwracającą funkcję JĘZYKA DAX USERNAME . Możesz nazwać to coś takiego jak "KtoTo Jestem". Następnie dodaj miarę do wizualizacji karty w raporcie i opublikuj ją w usłudze Power BI.
Twórcy i odbiorcy z uprawnieniami tylko do odczytu w modelu semantycznym będą mogli wyświetlać tylko dane, które mogą zobaczyć (na podstawie mapowania ról zabezpieczeń na poziomie wiersza).
Gdy użytkownik wyświetla raport w obszarze roboczym lub aplikacji, zabezpieczenia na poziomie wiersza mogą być wymuszane lub nie mogą być wymuszane w zależności od uprawnień modelu semantycznego. Z tego powodu ważne jest, aby użytkownicy zawartości i twórcy mieli uprawnienia tylko do odczytu w bazowym modelu semantycznym, gdy zabezpieczenia na poziomie wiersza muszą być wymuszane. Aby uzyskać szczegółowe informacje o regułach uprawnień określających, czy zabezpieczenia na poziomie wiersza są wymuszane, zobacz artykuł Report consumer security planning (Planowanie zabezpieczeń użytkowników raportów).
Powiązana zawartość
Aby uzyskać więcej informacji związanych z tym artykułem, zapoznaj się z następującymi zasobami:
- Zabezpieczenia na poziomie wiersza w usłudze Power BI
- Ograniczanie dostępu do danych przy użyciu zabezpieczeń na poziomie wiersza dla programu Power BI Desktop
- Relacje modelu w programie Power BI Desktop
- Planowanie implementacji usługi Power BI: Raportowanie planowania zabezpieczeń użytkowników
- Pytania? Spróbuj zadać Społeczność usługi Power BI
- Sugestie? Współtworzenie pomysłów na ulepszanie usługi Power BI
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla