Den här artikeln beskriver en alternativ metod för informationslagerprojekt som kallas undersökande dataanalys (EDA). Den här metoden kan minska utmaningarna med ETL-åtgärder (extract, transform, load). Den fokuserar först på att generera affärsinsikter och vänder sig sedan till att lösa modellerings- och ETL-uppgifter.
Arkitektur

Ladda ned en Visio-fil med den här arkitekturen.
För EDA bryr du dig bara om diagrammets högra sida. Azure Synapse SQL serverless används som beräkningsmotor över data lake-filerna.
Så här utför du EDA:
- T-SQL-frågor körs direkt i Azure Synapse SQL serverlös eller Azure Synapse Spark.
- Frågor körs från ett grafiskt frågeverktyg som Power BI eller Azure Data Studio.
Vi rekommenderar att du bevarar alla lakehouse-data med hjälp av Parquet eller Delta.
Du kan implementera diagrammets vänstra sida (datainmatning) med hjälp av valfritt elt-verktyg (extract, load, transform). Det har ingen effekt på EDA.
Komponenter
Azure Synapse Analytics kombinerar dataintegrering, informationslager för företag och stordataanalys över lakehouse-data. I den här lösningen:
- En Azure Synapse-arbetsyta främjar samarbete mellan datatekniker, dataforskare, dataanalytiker och BI-proffs (Business Intelligence) för EDA-uppgifter.
- Azure Synapse-serverlösa SQL-pooler analyserar ostrukturerade och halvstrukturerade data i Azure Data Lake Storage med hjälp av standard-T-SQL.
- Azure Synapse-serverlösa Apache Spark-pooler gör kodexemplen i Data Lake Storage med hjälp av Spark-språk som Spark SQL, PySpark och Scala.
Azure Data Lake Storage tillhandahåller lagring för data som sedan analyseras av Azure Synapse serverlösa SQL-pooler.
Azure Machine Learning tillhandahåller data till Azure Synapse Spark.
Power BI används i den här lösningen för att fråga efter data för att utföra EDA.
Alternativ
Du kan ersätta eller komplettera Synapse SQL-serverlösa pooler med Azure Databricks.
I stället för att använda en lakehouse-modell med Synapse SQL-serverlösa pooler kan du använda dedikerade SQL-pooler i Azure Synapse för att lagra företagsdata. Granska användningsfallen och övervägandena i den här artikeln och relaterade resurser för att avgöra vilken teknik som ska användas.
Information om scenario
Den här lösningen visar en implementering av EDA-metoden för informationslagerprojekt. Den här metoden kan minska utmaningarna med ETL-åtgärder. Den fokuserar först på att generera affärsinsikter och vänder sig sedan till att lösa modellerings- och ETL-uppgifter.
Potentiella användningsfall
Andra scenarier som kan dra nytta av det här analysmönstret:
Preskriptiv analys. Ställ frågor om dina data, till exempel Nästa bästa åtgärd, eller vad gör vi härnäst? Använd data för att vara mer datadrivna och mindre tarmdrivna. Data kan vara ostrukturerade och från många externa källor av varierande kvalitet. Du kanske vill använda data så snabbt som möjligt för att utvärdera din affärsstrategi utan att faktiskt läsa in data i ett informationslager. Du kan ta bort data när du har besvarat dina frågor.
Självbetjänings-ETL. Gör ETL/ELT när du utför dina EDA-aktiviteter (datasandboxning). Transformera data och göra dem värdefulla. Detta kan förbättra ETL-utvecklarnas skala.
Om undersökande dataanalys
Innan vi tittar närmare på hur EDA fungerar är det värt att sammanfatta den traditionella metoden för informationslagerprojekt. Den traditionella metoden ser ut så här:
Kravinsamling. Dokumentera vad du ska göra med data.
Datamodellering. Bestäm hur du modellerar numeriska data och tillskriver data i fakta- och dimensionstabeller. Traditionellt gör du det här steget innan du hämtar nya data.
ETL. Hämta data och massera in dem i informationslagrets datamodell.
De här stegen kan ta veckor eller till och med månader. Först då kan du börja köra frågor mot data och lösa affärsproblemet. Användaren ser endast värdet när rapporterna har skapats. Lösningsarkitekturen ser vanligtvis ut ungefär så här:
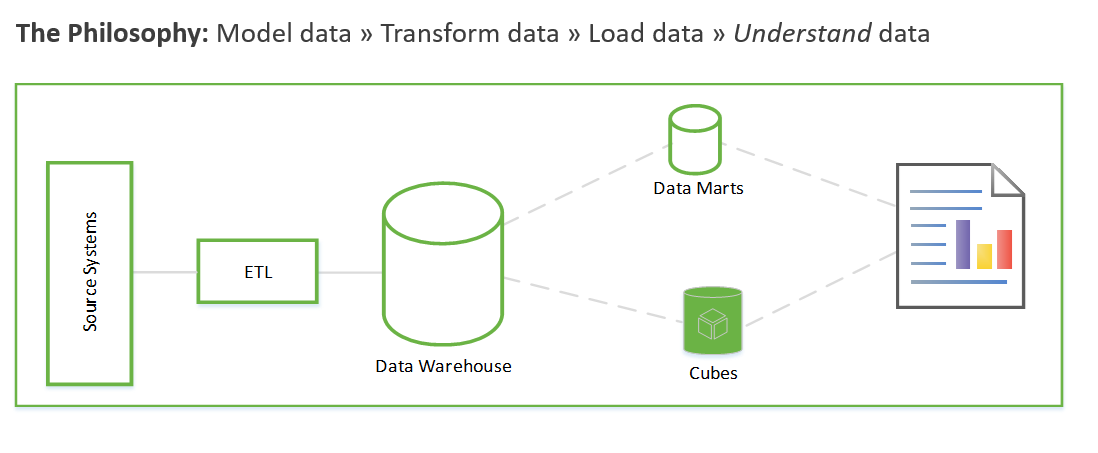
Du kan göra detta på ett annat sätt som fokuserar först på att generera affärsinsikter och sedan övergår till att lösa modellerings- och ETL-uppgifter. Processen liknar datavetenskapsprocesser. Det ser ut ungefär så här:
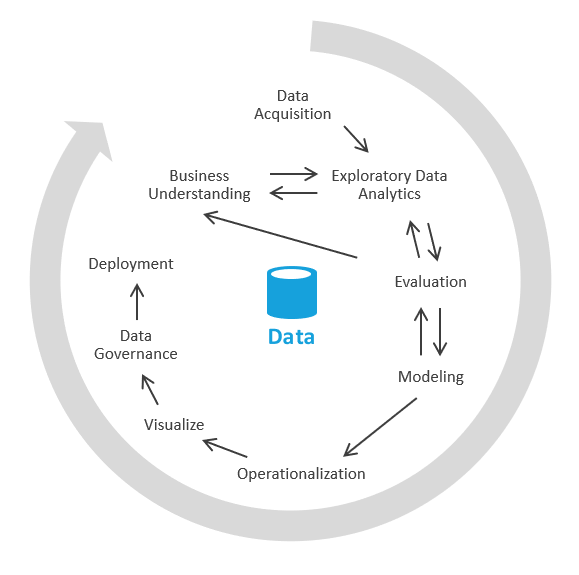
I branschen kallas den här processen EDA eller undersökande dataanalys.
Här är stegen:
Datainsamling. Först måste du ta reda på vilka datakällor du behöver mata in i din datasjö/sandbox-miljö. Sedan måste du föra in dessa data i landningsområdet för din sjö. Azure tillhandahåller verktyg som Azure Data Factory och Azure Logic Apps som snabbt kan mata in data.
Datasandning. Till en början arbetar en affärsanalytiker och en ingenjör som är skicklig på undersökande dataanalys via Azure Synapse Analytics serverlös eller grundläggande SQL tillsammans. Under den här fasen försöker de avslöja affärsinsikten med hjälp av nya data. EDA är en iterativ process. Du kan behöva mata in mer data, prata med små och medelstora företag, ställa fler frågor eller generera visualiseringar.
Utvärdering. När du har hittat affärsinsikten måste du utvärdera vad du ska göra med data. Du kanske vill spara data i informationslagret (så att du går över till modelleringsfasen). I andra fall kan du välja att behålla data i datasjön/lakehouse och använda dem för förutsägelseanalys (maskininlärningsalgoritmer). I andra fall kan du bestämma dig för att återfylla dina postsystem med de nya insikterna. Baserat på dessa beslut kan du få en bättre förståelse för vad du behöver göra härnäst. Du kanske inte behöver göra ETL.
Dessa metoder är kärnan i sann självbetjäningsanalys. Genom att använda datasjön och ett frågeverktyg som Azure Synapse serverlöst som förstår data lake-frågemönster, kan du lägga dina datatillgångar i händerna på affärsmän som förstår ett minimum av SQL. Du kan radikalt förkorta tiden till värde med hjälp av den här metoden och ta bort en del av risken som är associerad med företagets datainitiativ.
Att tänka på
Dessa överväganden implementerar grundpelarna i Azure Well-Architected Framework, som är en uppsättning vägledande grundsatser som kan användas för att förbättra kvaliteten på en arbetsbelastning. Mer information finns i Microsoft Azure Well-Architected Framework.
Tillgänglighet
Azure Synapse SQL-serverlösa pooler är en paaS-funktion (plattform som en tjänst) som kan uppfylla dina krav på hög tillgänglighet (HA) och haveriberedskap (DR).
Serverlösa pooler är tillgängliga på begäran. De kräver inte skalning upp, ned, in eller ut eller administration av något slag. De använder en modell med betalning per fråga, så det finns ingen outnyttjad kapacitet när som helst. Serverlösa pooler är idealiska för:
- Ad hoc-datavetenskapsutforskningar i T-SQL.
- Tidiga prototyper för informationslagerentiteter.
- Definiera vyer som konsumenter kan använda, till exempel i Power BI, för scenarier som kan tolerera prestandafördröjning.
- Undersökande dataanalys.
Operations
Synapse SQL serverless använder standard-T-SQL för frågor och åtgärder. Du kan använda Synapse-arbetsytans användargränssnitt, Azure Data Studio eller SQL Server Management Studio som T-SQL-verktyg.
Kostnadsoptimering
Kostnadsoptimering handlar om att titta på sätt att minska onödiga utgifter och förbättra drifteffektiviteten. Mer information finns i Översikt över kostnadsoptimeringspelare.
Prissättningen för Data Lake Storage beror på hur mycket data du lagrar och hur ofta du använder data. Exempelpriset innehåller en TB data som lagras, med ytterligare transaktionsantaganden. Den enda TB:en refererar till storleken på datasjön, inte storleken på den ursprungliga äldre databasen.
Azure Synapse Spark-poolpriser baseras på nodstorlek, antal instanser och drifttid. Exemplet förutsätter en liten beräkningsnod med användning mellan fem timmar per vecka och 40 timmar per månad.
Azure Synapse serverlös SQL-pool baserar prissättningen på TB för data som bearbetas. Exemplet förutsätter att 50 TB bearbetas per månad. Den här bilden refererar till storleken på datasjön, inte storleken på den ursprungliga äldre databasen.
Deltagare
Den här artikeln uppdateras och underhålls av Microsoft. Det har ursprungligen skrivits av följande medarbetare.
Huvudsakliga författare:
- Dave Wentzel | Teknisk huvudarkitekt för MTC
Nästa steg
- Dataingenjör utbildningsvägar
- Självstudie: Kom igång med Azure Synapse Analytics
- Skapa en enkel databas – Azure SQL Database
- Azure Synapse SQL-arkitektur
- Skapa ett lagringskonto för Azure Data Lake Storage
- Snabbstart för Azure Event Hubs – Skapa en händelsehubb med hjälp av Azure-portalen
- Snabbstart – Skapa ett Stream Analytics-jobb med hjälp av Azure-portalen
- Snabbstart: Kom igång med Azure Machine Learning