Kopiera data från SAP HANA med Azure Data Factory eller Synapse Analytics
GÄLLER FÖR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Den här artikeln beskriver hur du använder kopieringsaktiviteten i Azure Data Factory- och Synapse Analytics-pipelines för att kopiera data från en SAP HANA-databas. Den bygger på översiktsartikeln för kopieringsaktivitet som visar en allmän översikt över kopieringsaktiviteten.
Dricks
Mer information om övergripande stöd för SAP-dataintegreringsscenariot finns i white paper för SAP-dataintegrering med detaljerad introduktion till varje SAP-anslutningsapp, jämförelse och vägledning.
Funktioner som stöds
Den här SAP HANA-anslutningsappen stöds för följande funktioner:
| Funktioner som stöds | IR |
|---|---|
| aktiviteten Kopiera (källa/mottagare) | ② |
| Sökningsaktivitet | ② |
(1) Azure Integration Runtime (2) Lokalt installerad integrationskörning
En lista över datalager som stöds som källor/mottagare av kopieringsaktiviteten finns i tabellen Datalager som stöds.
Mer specifikt stöder den här SAP HANA-anslutningsappen:
- Kopiera data från valfri version av SAP HANA-databasen.
- Kopiera data från HANA-informationsmodeller (till exempel analys- och beräkningsvyer) och rad-/kolumntabeller.
- Kopiera data med grundläggande autentisering eller Windows-autentisering.
- Parallell kopiering från en SAP HANA-källa. Mer information finns i avsnittet Parallellkopia från SAP HANA .
Dricks
Om du vill kopiera data till SAP HANA-datalagret använder du en allmän ODBC-anslutningsapp. Se avsnittet SAP HANA-mottagare med information. Observera att de länkade tjänsterna för SAP HANA-anslutningsappen och ODBC-anslutningsappen har en annan typ och därför inte kan återanvändas.
Förutsättningar
Om du vill använda den här SAP HANA-anslutningsappen måste du:
- Konfigurera en lokalt installerad integrationskörning. Mer information finns i artikeln Om lokalt installerad integrationskörning .
- Installera SAP HANA ODBC-drivrutinen på Integration Runtime-datorn. Du kan ladda ned SAP HANA ODBC-drivrutinen från SAP Software Download Center. Sök med nyckelordet SAP HANA CLIENT för Windows.
Komma igång
Om du vill utföra aktiviteten Kopiera med en pipeline kan du använda något av följande verktyg eller SDK:er:
- Verktyget Kopiera data
- Azure-portalen
- The .NET SDK
- The Python SDK
- Azure PowerShell
- REST-API:et
- Azure Resource Manager-mallen
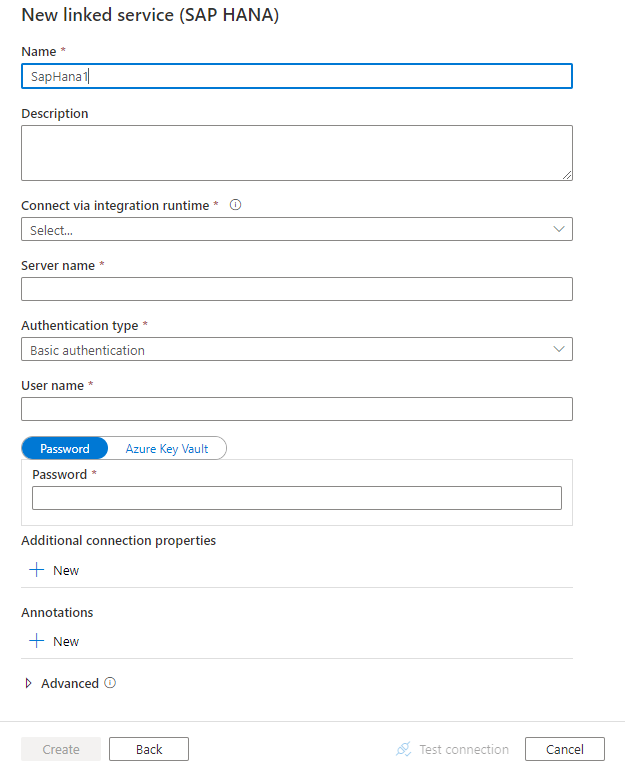
Skapa en länkad tjänst till SAP HANA med hjälp av användargränssnittet
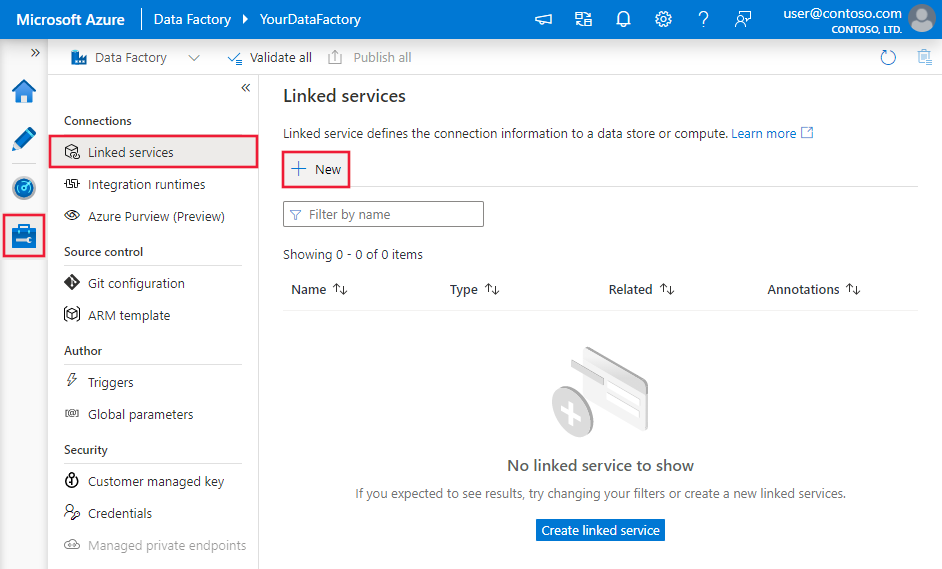
Använd följande steg för att skapa en länkad tjänst till SAP HANA i Användargränssnittet för Azure-portalen.
Bläddra till fliken Hantera i Din Azure Data Factory- eller Synapse-arbetsyta och välj Länkade tjänster och klicka sedan på Ny:
Sök efter SAP och välj SAP HANA-anslutningsappen.

Konfigurera tjänstinformationen, testa anslutningen och skapa den nya länkade tjänsten.
Anslut eller konfigurationsinformation
Följande avsnitt innehåller information om egenskaper som används för att definiera Data Factory-entiteter som är specifika för SAP HANA-anslutningstjänsten.
Länkade tjänstegenskaper
Följande egenskaper stöds för SAP HANA-länkad tjänst:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen måste anges till: SapHana | Ja |
| Connectionstring | Ange information som behövs för att ansluta till SAP HANA med hjälp av antingen grundläggande autentisering eller Windows-autentisering. Se följande exempel. I anslutningssträng är server/port obligatoriskt (standardporten är 30015) och användarnamn och lösenord är obligatoriska när grundläggande autentisering används. Ytterligare avancerade inställningar finns i SAP HANA ODBC-Anslut ionsegenskaper Du kan också placera lösenord i Azure Key Vault och hämta lösenordskonfigurationen från anslutningssträng. Mer information finns i artikeln Lagra autentiseringsuppgifter i Azure Key Vault. |
Ja |
| userName | Ange användarnamn när du använder Windows-autentisering. Exempel: user@domain.com |
Nej |
| password | Ange lösenord för användarkontot. Markera det här fältet som en SecureString för att lagra det på ett säkert sätt eller referera till en hemlighet som lagras i Azure Key Vault. | Nej |
| connectVia | Integration Runtime som ska användas för att ansluta till datalagret. En lokalt installerad integrationskörning krävs enligt vad som anges i Krav. | Ja |
Exempel: Använda grundläggande autentisering
{
"name": "SapHanaLinkedService",
"properties": {
"type": "SapHana",
"typeProperties": {
"connectionString": "SERVERNODE=<server>:<port (optional)>;UID=<userName>;PWD=<Password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exempel: Använda Windows-autentisering
{
"name": "SapHanaLinkedService",
"properties": {
"type": "SapHana",
"typeProperties": {
"connectionString": "SERVERNODE=<server>:<port (optional)>;",
"userName": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Om du använder den länkade SAP HANA-tjänsten med följande nyttolast stöds den fortfarande som den är, medan du rekommenderas att använda den nya framöver.
Exempel:
{
"name": "SapHanaLinkedService",
"properties": {
"type": "SapHana",
"typeProperties": {
"server": "<server>:<port (optional)>",
"authenticationType": "Basic",
"userName": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Egenskaper för datauppsättning
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera datauppsättningar finns i artikeln datauppsättningar . Det här avsnittet innehåller en lista över egenskaper som stöds av SAP HANA-datauppsättningen.
Följande egenskaper stöds för att kopiera data från SAP HANA:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen för datamängden måste anges till: SapHanaTable | Ja |
| schema | Namnet på schemat i SAP HANA-databasen. | Nej (om "fråga" i aktivitetskällan har angetts) |
| table | Namnet på tabellen i SAP HANA-databasen. | Nej (om "fråga" i aktivitetskällan har angetts) |
Exempel:
{
"name": "SAPHANADataset",
"properties": {
"type": "SapHanaTable",
"typeProperties": {
"schema": "<schema name>",
"table": "<table name>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<SAP HANA linked service name>",
"type": "LinkedServiceReference"
}
}
}
Om du använder RelationalTable en typ av datauppsättning stöds den fortfarande i sin form, medan du rekommenderas att använda den nya framöver.
Kopiera egenskaper för aktivitet
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera aktiviteter finns i artikeln Pipelines . Det här avsnittet innehåller en lista över egenskaper som stöds av SAP HANA-källan.
SAP HANA som källa
Dricks
Om du vill mata in data från SAP HANA effektivt med hjälp av datapartitionering kan du läsa mer i avsnittet Parallellkopia från SAP HANA .
Om du vill kopiera data från SAP HANA stöds följande egenskaper i avsnittet kopieringsaktivitetskälla:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen för kopieringsaktivitetskällan måste anges till: SapHanaSource | Ja |
| query | Anger SQL-frågan för att läsa data från SAP HANA-instansen. | Ja |
| partitionOptions | Anger de datapartitioneringsalternativ som används för att mata in data från SAP HANA. Läs mer från avsnittet Parallellkopia från SAP HANA . Tillåtna värden är: Ingen (standard), PhysicalPartitionsOfTable, SapHanaDynamicRange. Läs mer från avsnittet Parallellkopia från SAP HANA . PhysicalPartitionsOfTable kan endast användas vid kopiering av data från en tabell men inte fråga. När ett partitionsalternativ är aktiverat (dvs. inte None), styrs graden av parallellitet för samtidig inläsning av data från SAP HANA av parallelCopies inställningen för kopieringsaktiviteten. |
Falska |
| partition Inställningar | Ange gruppen med inställningarna för datapartitionering. Använd när partitionsalternativet är SapHanaDynamicRange. |
Falska |
| partitionColumnName | Ange namnet på källkolumnen som ska användas av partitionen för parallell kopiering. Om det inte anges identifieras indexet eller den primära nyckeln i tabellen automatiskt och används som partitionskolumn. Använd när partitionsalternativet är SapHanaDynamicRange. Om du använder en fråga för att hämta källdata ansluter du ?AdfHanaDynamicRangePartitionCondition i WHERE-satsen. Se exempel i avsnittet Parallell kopia från SAP HANA . |
Ja när du använder SapHanaDynamicRange partition. |
| packetSize | Anger storleken på nätverkspaketen (i Kilobyte) för att dela upp data till flera block. Om du har stora mängder data att kopiera kan ökad paketstorlek öka läshastigheten från SAP HANA i de flesta fall. Prestandatestning rekommenderas när paketstorleken justeras. | Nej. Standardvärdet är 2 048 (2 MB). |
Exempel:
"activities":[
{
"name": "CopyFromSAPHANA",
"type": "Copy",
"inputs": [
{
"referenceName": "<SAP HANA input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SapHanaSource",
"query": "<SQL query for SAP HANA>"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Om du använder RelationalSource skrivskyddad kopieringskälla stöds den fortfarande som den är, medan du rekommenderas att använda den nya framöver.
Parallell kopia från SAP HANA
SAP HANA-anslutningsappen tillhandahåller inbyggd datapartitionering för att kopiera data från SAP HANA parallellt. Du hittar alternativ för datapartitionering i källtabellen för kopieringsaktiviteten.
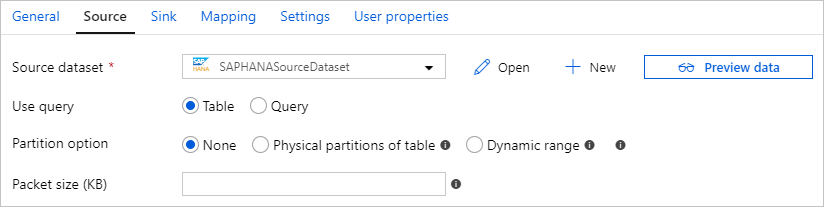
När du aktiverar partitionerad kopia kör tjänsten parallella frågor mot SAP HANA-källan för att hämta data efter partitioner. Den parallella graden styrs av parallelCopies inställningen för kopieringsaktiviteten. Om du till exempel anger parallelCopies till fyra genererar och kör tjänsten samtidigt fyra frågor baserat på ditt angivna partitionsalternativ och inställningar, och varje fråga hämtar en del data från SAP HANA.
Du rekommenderas att aktivera parallell kopiering med datapartitionering, särskilt när du matar in stora mängder data från din SAP HANA. Följande är föreslagna konfigurationer för olika scenarier. När du kopierar data till filbaserat datalager rekommenderar vi att du skriver till en mapp som flera filer (anger endast mappnamn), i vilket fall prestandan är bättre än att skriva till en enda fil.
| Scenario | Föreslagna inställningar |
|---|---|
| Full belastning från en stor tabell. | Partitionsalternativ: Fysiska partitioner i tabellen. Under körningen identifierar tjänsten automatiskt den fysiska partitionstypen för den angivna SAP HANA-tabellen och väljer motsvarande partitionsstrategi: - Intervallpartitionering: Hämta partitionskolumnen och partitionsintervallen som definierats för tabellen och kopiera sedan data efter intervall. - Hashpartitionering: Använd hashpartitionsnyckeln som partitionskolumn och partitionera och kopiera sedan data baserat på intervall som beräknas av tjänsten. - Resursallokeringspartitionering eller Ingen partition: Använd primärnyckel som partitionskolumn och partitionera och kopiera sedan data baserat på intervall som beräknas av tjänsten. |
| Läs in stora mängder data med hjälp av en anpassad fråga. | Partitionsalternativ: Partition med dynamiskt intervall. Fråga: SELECT * FROM <TABLENAME> WHERE ?AdfHanaDynamicRangePartitionCondition AND <your_additional_where_clause>.Partitionskolumn: Ange den kolumn som används för att tillämpa partitionen för dynamiskt intervall. Under körningen beräknar tjänsten först värdeintervallen för den angivna partitionskolumnen genom att jämnt fördela raderna i ett antal bucketar enligt antalet distinkta partitionskolumnvärden, den parallella kopieringsinställningen och ersätter sedan med filtrering av värdeintervallet för partitionskolumnen ?AdfHanaDynamicRangePartitionCondition för varje partition och skickar till SAP HANA.Om du vill använda flera kolumner som partitionskolumn kan du sammanfoga värdena för varje kolumn som en kolumn i frågan och ange den som partitionskolumnen, till exempel SELECT * FROM (SELECT *, CONCAT(<KeyColumn1>, <KeyColumn2>) AS PARTITIONCOLUMN FROM <TABLENAME>) WHERE ?AdfHanaDynamicRangePartitionCondition. |
Exempel: fråga med fysiska partitioner i en tabell
"source": {
"type": "SapHanaSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Exempel: fråga med partition för dynamiskt intervall
"source": {
"type": "SapHanaSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfHanaDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "SapHanaDynamicRange",
"partitionSettings": {
"partitionColumnName": "<Partition_column_name>"
}
}
Datatypsmappning för SAP HANA
När du kopierar data från SAP HANA används följande mappningar från SAP HANA-datatyper till mellanliggande datatyper som används internt i tjänsten. Se Schema- och datatypmappningar för att lära dig mer om hur kopieringsaktivitet mappar källschemat och datatypen till mottagaren.
| SAP HANA-datatyp | Datatyp för interimstjänst |
|---|---|
| ALFANUM | String |
| BIGINT | Int64 |
| BINARY | Byte[] |
| BINTEXT | String |
| BLOB | Byte[] |
| BOOL | Byte |
| CLOB | String |
| DATUM | Datum/tid |
| DECIMAL | Decimal |
| DOUBLE | Dubbel |
| FLYTA | Dubbel |
| INTEGER | Int32 |
| NCLOB | String |
| NVARCHAR | String |
| REAL | Enstaka |
| SECONDDATE | Datum/tid |
| KORTTEXT | String |
| SMALLDECIMAL | Decimal |
| SMALLINT | Int16 |
| STGEOMETRYTYPE | Byte[] |
| STPOINTTYPE | Byte[] |
| TEXT | String |
| TID | TimeSpan |
| TINYINT | Byte |
| VARCHAR | String |
| TIMESTAMP | Datum/tid |
| VARBINARY | Byte[] |
SAP HANA-mottagare
För närvarande stöds inte SAP HANA-anslutningsappen som mottagare, medan du kan använda en allmän ODBC-anslutningsapp med SAP HANA-drivrutin för att skriva data till SAP HANA.
Följ kraven för att konfigurera Lokalt installerad Integration Runtime och installera SAP HANA ODBC-drivrutinen först. Skapa en ODBC-länkad tjänst för att ansluta till ditt SAP HANA-datalager enligt följande exempel och skapa sedan datauppsättning och kopieringsaktivitetsmottagare med ODBC-typ i enlighet med detta. Läs mer i artikeln om ODBC-anslutningsprogram .
{
"name": "SAPHANAViaODBCLinkedService",
"properties": {
"type": "Odbc",
"typeProperties": {
"connectionString": "Driver={HDBODBC};servernode=<HANA server>.clouddatahub-int.net:30015",
"authenticationType": "Basic",
"userName": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Egenskaper för uppslagsaktivitet
Mer information om egenskaperna finns i Sökningsaktivitet.
Relaterat innehåll
En lista över datalager som stöds som källor och mottagare av kopieringsaktiviteten finns i datalager som stöds.