Transformering av mottagare i mappning av dataflöde
GÄLLER FÖR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Dataflöden är tillgängliga både i Azure Data Factory och Azure Synapse Pipelines. Den här artikeln gäller för mappning av dataflöden. Om du är nybörjare på transformeringar kan du läsa den inledande artikeln Transformera data med hjälp av ett mappningsdataflöde.
När du är klar med att transformera dina data skriver du dem till ett mållager med hjälp av mottagartransformeringen. Varje dataflöde kräver minst en transformering av mottagare, men du kan skriva till så många mottagare som behövs för att slutföra omvandlingsflödet. Om du vill skriva till ytterligare mottagare skapar du nya strömmar via nya grenar och villkorliga delningar.
Varje mottagartransformering är associerad med exakt ett datamängdsobjekt eller en länkad tjänst. Mottagartransformeringen avgör formen och platsen för de data som du vill skriva till.
Infogade datauppsättningar
När du skapar en transformering av mottagare väljer du om din mottagarinformation definieras i ett datauppsättningsobjekt eller inom mottagartransformeringen. De flesta format är bara tillgängliga i det ena eller det andra. Information om hur du använder en specifik anslutningsapp finns i lämpligt anslutningsdokument.
När ett format stöds för både infogade objekt och i ett datauppsättningsobjekt finns det fördelar med båda. Datamängdsobjekt är återanvändbara entiteter som kan användas i andra dataflöden och aktiviteter som Kopiera. Dessa återanvändbara entiteter är särskilt användbara när du använder ett härdat schema. Datauppsättningar är inte baserade i Spark. Ibland kan du behöva åsidosätta vissa inställningar eller schemaprojektion i mottagartransformeringen.
Infogade datauppsättningar rekommenderas när du använder flexibla scheman, enstaka mottagarinstanser eller parametriserade mottagare. Om mottagaren är kraftigt parametriserad kan du med infogade datamängder inte skapa ett "dummy"-objekt. Infogade datauppsättningar baseras i Spark och deras egenskaper är inbyggda i dataflödet.
Om du vill använda en infogad datauppsättning väljer du önskat format i väljaren För mottagare. I stället för att välja en datauppsättning för mottagare väljer du den länkade tjänst som du vill ansluta till.
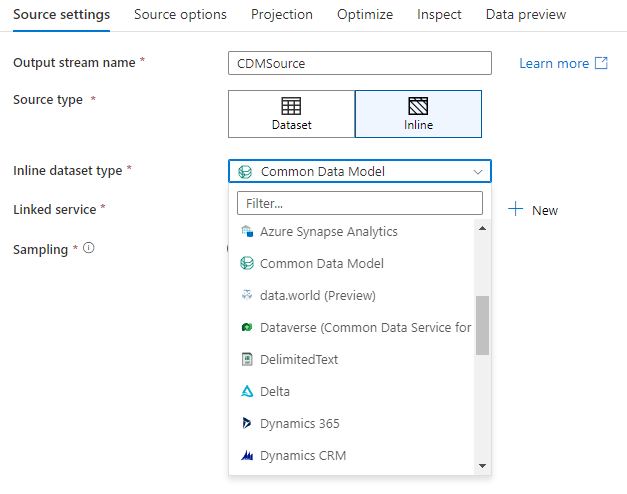
Arbetsyta DB (endast Synapse-arbetsytor)
När du använder dataflöden i Azure Synapse-arbetsytor har du ytterligare ett alternativ för att sänka dina data direkt till en databastyp som finns i Synapse-arbetsytan. Detta minskar behovet av att lägga till länkade tjänster eller datauppsättningar för dessa databaser. De databaser som skapas via Azure Synapse-databasmallarna är också tillgängliga när du väljer Arbetsyta DB.
Kommentar
Azure Synapse Workspace DB-anslutningsappen är för närvarande i offentlig förhandsversion och kan bara fungera med Spark Lake-databaser just nu
Mottagartyper som stöds
Mappning av dataflöde följer en ELT-metod (extract, load, and transform) och fungerar med mellanlagring av datauppsättningar som alla finns i Azure. För närvarande kan följande datauppsättningar användas i en mottagartransformering.
| Koppling | Format | Datauppsättning/infogad |
|---|---|---|
| Azure Blob Storage | Avro Avgränsad text Delta JSON ORC Parkett |
✓/✓ ✓/✓ -/✓ ✓/✓ ✓/✓ ✓/✓ |
| Azure Cosmos DB för NoSQL | ✓/- | |
| Azure Data Lake Storage Gen1 | Avro Avgränsad text JSON ORC Parkett |
✓/- ✓/- ✓/- ✓/✓ ✓/- |
| Azure Data Lake Storage Gen2 | Avro Common Data Model Avgränsad text Delta JSON ORC Parkett |
✓/✓ -/✓ ✓/✓ -/✓ ✓/✓ ✓/✓ ✓/✓ |
| Azure Database for MySQL | ✓/✓ | |
| Azure Database for PostgreSQL | ✓/✓ | |
| Azure-datautforskaren | ✓/✓ | |
| Azure SQL Database | ✓/✓ | |
| Hanterad Azure SQL-instans | ✓/- | |
| Azure Synapse Analytics | ✓/- | |
| Dataverse | ✓/✓ | |
| Dynamics 365 | ✓/✓ | |
| Dynamics CRM | ✓/✓ | |
| Fabric Lakehouse | ✓/✓ | |
| SFTP | Avro Avgränsad text JSON ORC Parkett |
✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ |
| Snowflake | ✓/✓ | |
| SQL Server | ✓/✓ |
Inställningar som är specifika för dessa anslutningsappar finns på fliken Inställningar. Exempel på informations- och dataflödesskript för dessa inställningar finns i anslutningsdokumentationen.
Tjänsten har åtkomst till fler än 90 interna anslutningsappar. Om du vill skriva data till de andra källorna från dataflödet använder du kopieringsaktiviteten för att läsa in dessa data från en mottagare som stöds.
Inställningar för mottagare
När du har lagt till en mottagare konfigurerar du via fliken Mottagare . Här kan du välja eller skapa datauppsättningen som mottagaren skriver till. Utvecklingsvärden för datauppsättningsparametrar kan konfigureras i felsökningsinställningar. (Felsökningsläget måste vara aktiverat.)
I följande video förklaras ett antal olika alternativ för mottagare för textavgränsade filtyper.

Schemaavvikelse: Schemaavvikelse är tjänstens förmåga att internt hantera flexibla scheman i dina dataflöden utan att uttryckligen behöva definiera kolumnändringar. Aktivera Tillåt schemaavvikelse för att skriva ytterligare kolumner ovanpå det som definieras i schemat för mottagardata.
Validera schema: Om valideringsschemat har valts misslyckas dataflödet om någon kolumn i mottagarprojektionen inte hittas i mottagarlagret eller om datatyperna inte matchar. Använd den här inställningen för att framtvinga att mottagarschemat uppfyller kontraktet för din definierade projektion. Det är användbart i scenarier för databasmottagare för att signalera att kolumnnamn eller typer har ändrats.
Cachemottagare
En cachemottagare är när ett dataflöde skriver data till Spark-cachen i stället för ett datalager. Vid mappning av dataflöden kan du referera till dessa data i samma flöde många gånger med hjälp av en cachesökning. Det här är användbart när du vill referera till data som en del av ett uttryck men inte uttryckligen vill koppla kolumnerna till dem. Vanliga exempel där en cachemottagare kan hjälpa till att leta upp ett maxvärde i ett datalager och matcha felkoder till en databas med felmeddelanden.
Om du vill skriva till en cachemottagare lägger du till en mottagartransformering och väljer Cache som mottagartyp. Till skillnad från andra mottagartyper behöver du inte välja en datauppsättning eller länkad tjänst eftersom du inte skriver till ett externt arkiv.
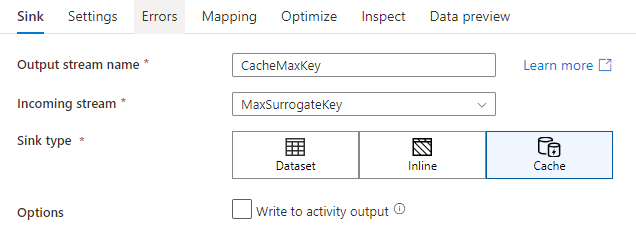
I mottagarinställningarna kan du ange nyckelkolumnerna i cachemottagaren. Dessa används som matchande villkor när du använder lookup() funktionen i en cache-sökning. Om du anger nyckelkolumner kan du inte använda outputs() funktionen i en cachesökning. Mer information om syntaxen för cachesökning finns i cachelagrade sökningar.

Om jag till exempel anger en enda nyckelkolumn column1 i en cachemottagare med namnet cacheExample, skulle anropet cacheExample#lookup() ha en parameter som anger vilken rad i cachemottagaren som ska matchas. Funktionen matar ut en enda komplex kolumn med underkolumner för varje mappad kolumn.
Kommentar
En cachemottagare måste finnas i en helt oberoende dataström från en transformering som refererar till den via en cachesökning. En cachemottagare måste också vara den första mottagaren som skrivs.
Skriv till aktivitetsutdata Den cachelagrade mottagaren kan också skriva utdata till indata för nästa pipelineaktivitet. På så sätt kan du snabbt och enkelt skicka data från dataflödesaktiviteten utan att behöva spara data i ett datalager.
Uppdatera metod
För databasmottagaretyper innehåller fliken Inställningar en "Uppdateringsmetod"-egenskap. Standardvärdet är insert men innehåller även kryssrutealternativ för uppdatering, upsert och borttagning. Om du vill använda dessa ytterligare alternativ måste du lägga till en Alter Row-transformering före mottagare. Med Alter Row kan du definiera villkoren för var och en av databasåtgärderna. Om källan är en inbyggd CDC-aktiveringskälla kan du ange uppdateringsmetoderna utan en Alter Row som ADF redan känner till radmarkörerna för infoga, uppdatera, öka och ta bort.
Fältmappning
På fliken Mappning i mottagaren kan du bestämma vilka inkommande kolumner som ska skrivas på fliken Mappning. Som standard mappas alla indatakolumner, inklusive glidande kolumner. Det här beteendet kallas automatisk mappning.
När du inaktiverar automatisk mappning kan du lägga till antingen fasta kolumnbaserade mappningar eller regelbaserade mappningar. Med regelbaserade mappningar kan du skriva uttryck med mönstermatchning. Mappning mappar logiska och fysiska kolumnnamn. Mer information om regelbaserad mappning finns i Kolumnmönster i mappning av dataflöde.
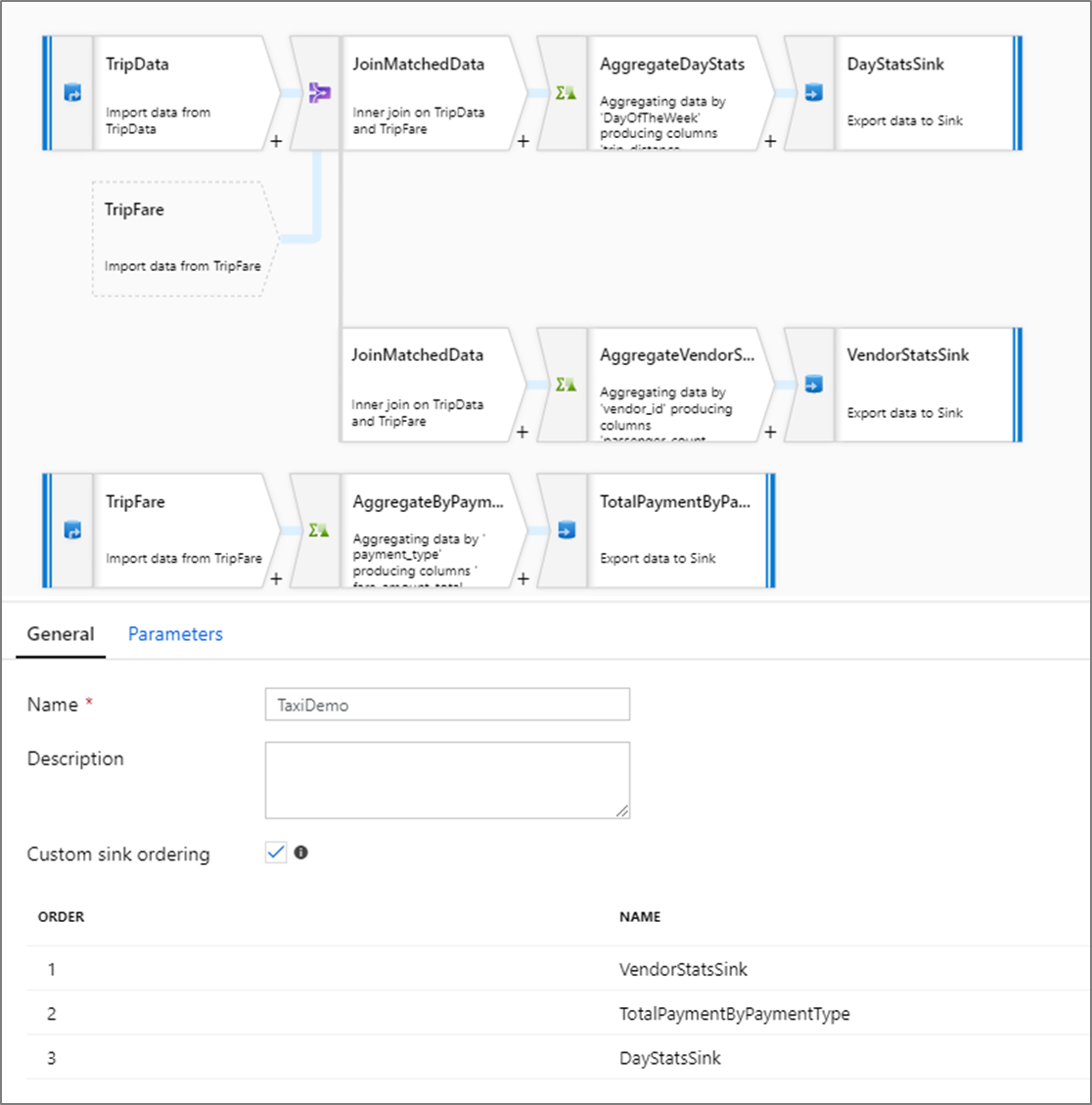
Beställning av anpassad mottagare
Som standard skrivs data till flera mottagare i nondeterministisk ordning. Körningsmotorn skriver data parallellt när omvandlingslogiken har slutförts, och mottagarordningen kan variera för varje körning. Om du vill ange en exakt mottagarordning aktiverar du anpassad mottagarordning på fliken Allmänt i dataflödet. När det är aktiverat skrivs mottagare sekventiellt i ökande ordning.
Kommentar
När du använder cachelagrade sökningar kontrollerar du att din mottagarordning har cachelagrade mottagare inställda på 1, den lägsta (eller första) i ordning.
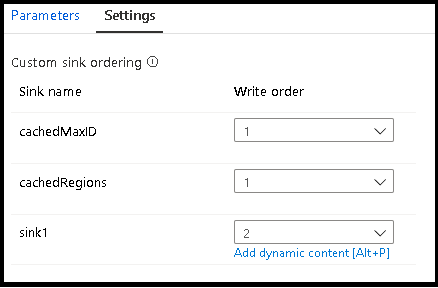
Mottagargrupper
Du kan gruppera mottagare tillsammans genom att använda samma ordernummer för en serie mottagare. Tjänsten behandlar dessa mottagare som grupper som kan köras parallellt. Alternativ för parallell körning visas i pipelinens dataflödesaktivitet.
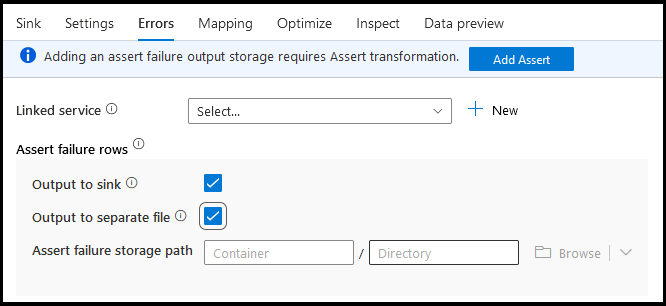
Fel
På fliken för mottagarfel kan du konfigurera felradshantering för att samla in och omdirigera utdata för databasdrivrutinsfel och misslyckade kontroller.
När du skriver till databaser kan vissa rader med data misslyckas på grund av begränsningar som anges av målet. Som standard misslyckas en dataflödeskörning på det första felet som den får. I vissa anslutningsappar kan du välja Fortsätt vid fel som gör att dataflödet kan slutföras även om enskilda rader har fel. För närvarande är den här funktionen endast tillgänglig i Azure SQL Database och Azure Synapse. Mer information finns i felradshantering i Azure SQL DB.
Nedan visas en videoguide om hur du använder radhantering av databasfel automatiskt i din mottagartransformering.
För rader med kontrollfel kan du använda Assert-omvandlingen uppströms i dataflödet och sedan omdirigera misslyckade kontroller till en utdatafil här på fliken för mottagarfel. Du har också ett alternativ här för att ignorera rader med kontrollfel och inte mata ut dessa rader alls till måldatalagret för mottagare.
Förhandsgranskning av data i mottagare
När du hämtar en förhandsgranskning av data i felsökningsläge skrivs inga data till mottagaren. En ögonblicksbild av hur data ser ut returneras, men inget skrivs till målet. Om du vill testa att skriva data till mottagaren kör du en pipelinefelsökning från pipelinearbetsytan.
Dataflödesskript
Exempel
Nedan visas ett exempel på en mottagartransformering och dess dataflödesskript:
sink(input(
movie as integer,
title as string,
genres as string,
year as integer,
Rating as integer
),
allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:false,
updateable:true,
upsertable:false,
keys:['movie'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true,
saveOrder: 1,
errorHandlingOption: 'stopOnFirstError') ~> sink1
Relaterat innehåll
Nu när du har skapat dataflödet lägger du till en dataflödesaktivitet i pipelinen.