Bearbeta textfiler med fast längd med dataflöden för Data Factory-mappning
GÄLLER FÖR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Genom att mappa dataflöden i Microsoft Azure Data Factory kan du transformera data från textfiler med fast bredd. I följande uppgift definierar vi en datauppsättning för en textfil utan avgränsare och konfigurerar sedan delsträngsdelningar baserat på ordningstal.
Skapa en pipeline
Välj +Ny pipeline för att skapa en ny pipeline.
Lägg till en dataflödesaktivitet som ska användas för bearbetning av filer med fast bredd:
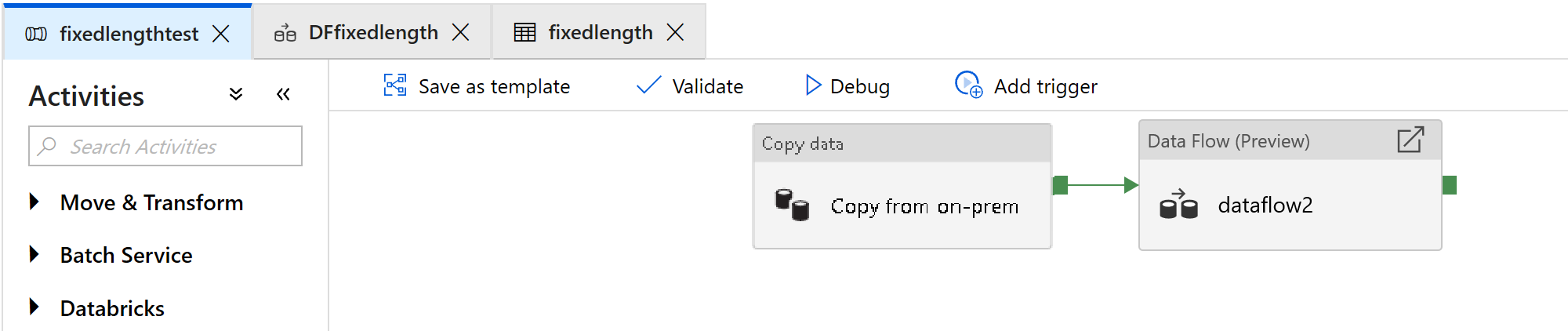
I dataflödesaktiviteten väljer du Nytt mappningsdataflöde.
Lägg till en transformering av källa, härledd kolumn, välj och mottagare:
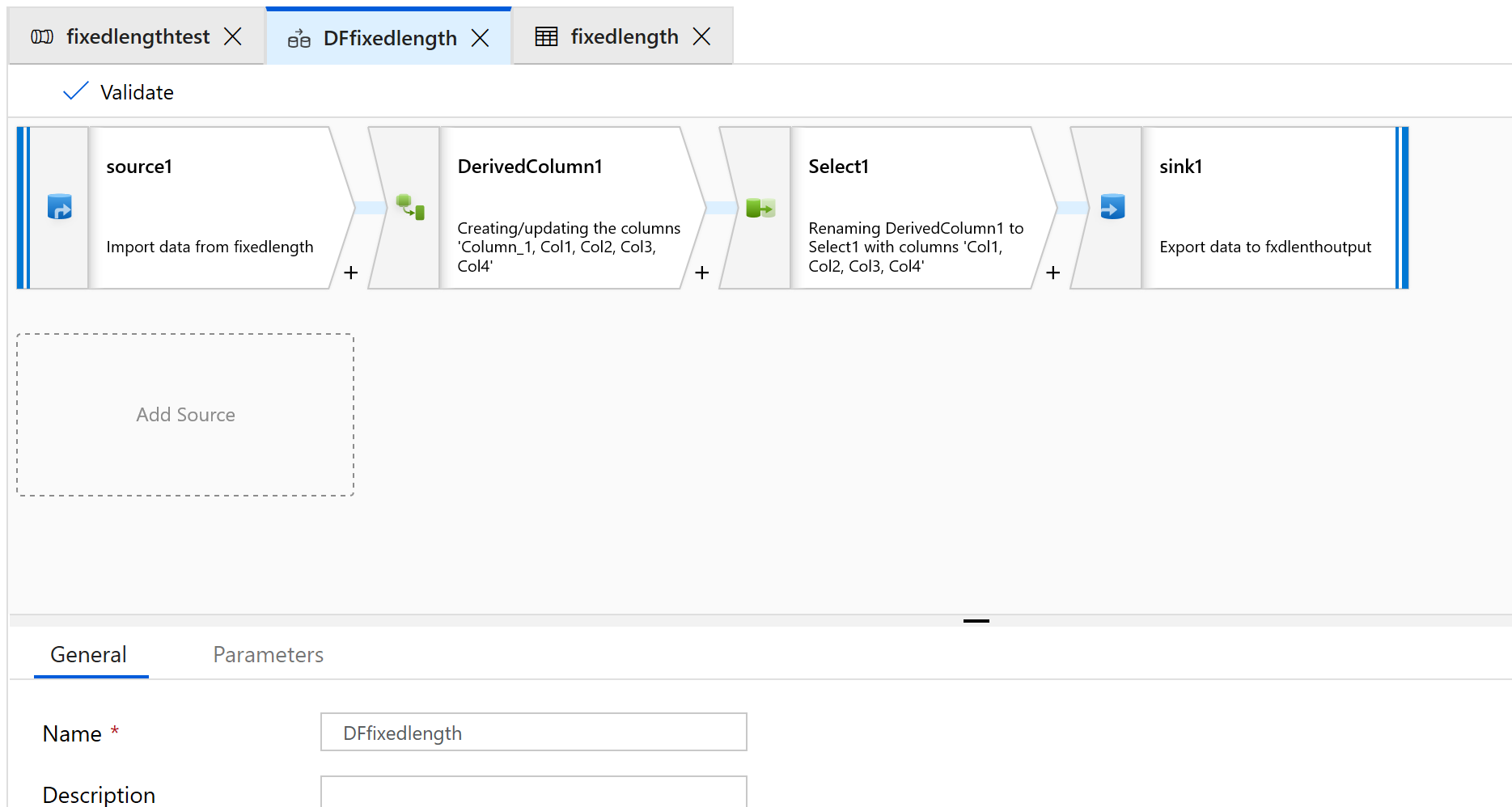
Konfigurera källtransformeringen så att den använder en ny datauppsättning, som kommer att vara av typen Avgränsad text.
Ange inte någon kolumn avgränsare eller rubriker.
Nu ska vi ange fältstartpunkter och längder för innehållet i den här filen:
1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468På fliken Projektion i källtransformeringen bör du se en strängkolumn med namnet Column_1.
Skapa en ny kolumn i kolumnen Härledd.
Vi ger kolumnerna enkla namn som col1.
I uttrycksverktyget skriver du följande:
substring(Column_1,1,4)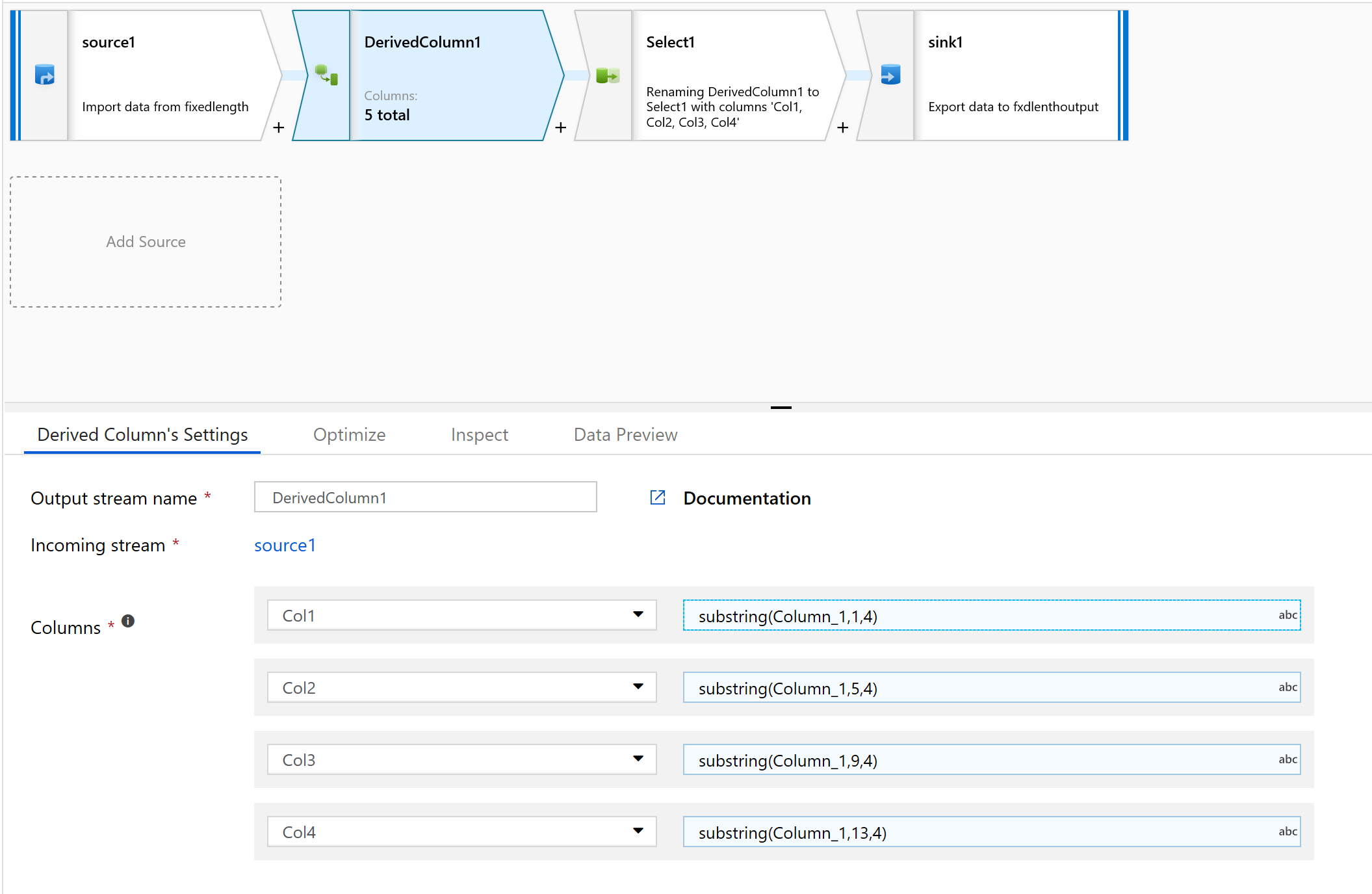
Upprepa steg 10 för alla kolumner som du behöver parsa.
Välj fliken Inspektera för att se de nya kolumnerna som ska genereras:
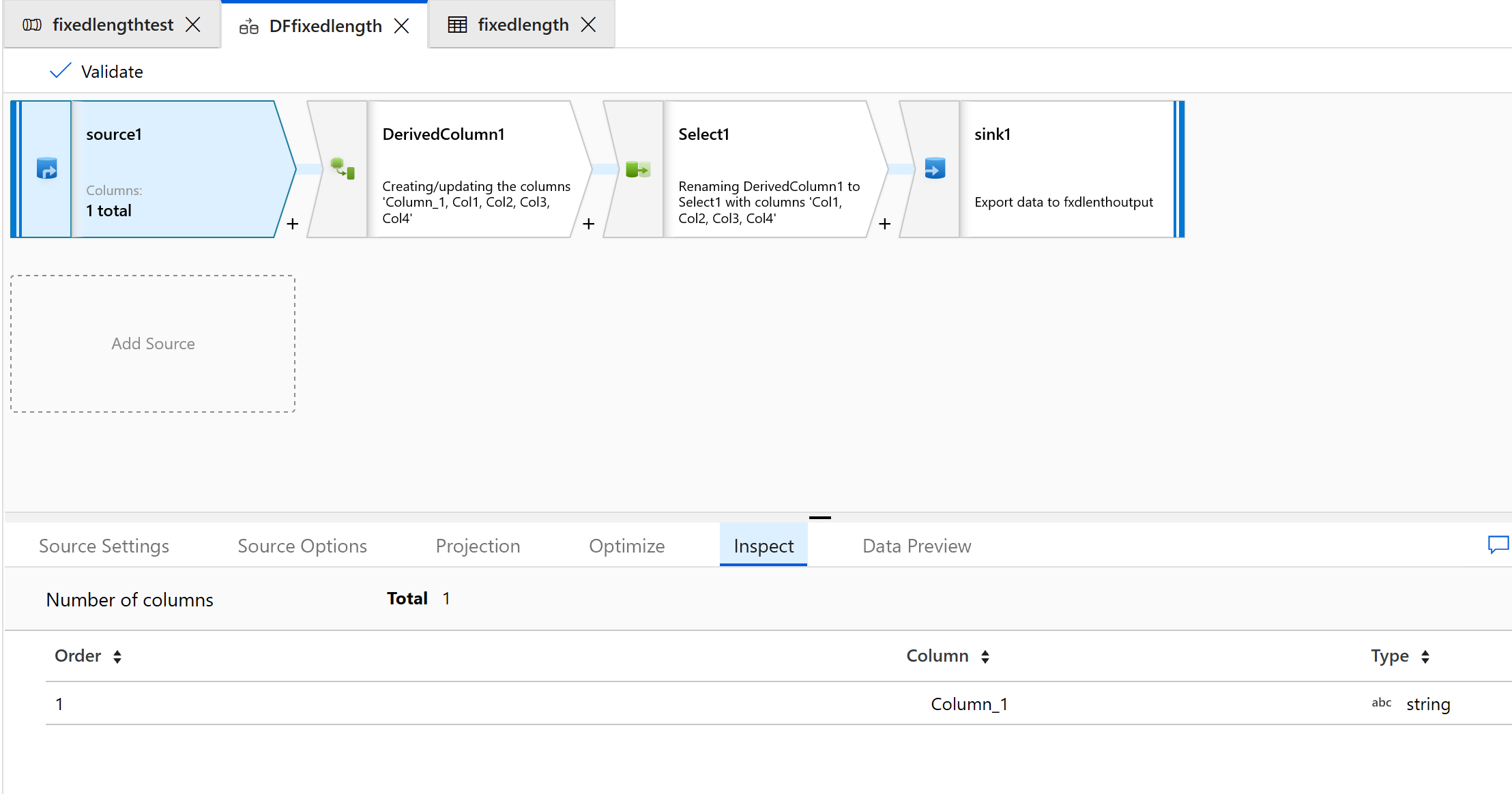
Använd välj transformering för att ta bort någon av de kolumner som du inte behöver för transformering:
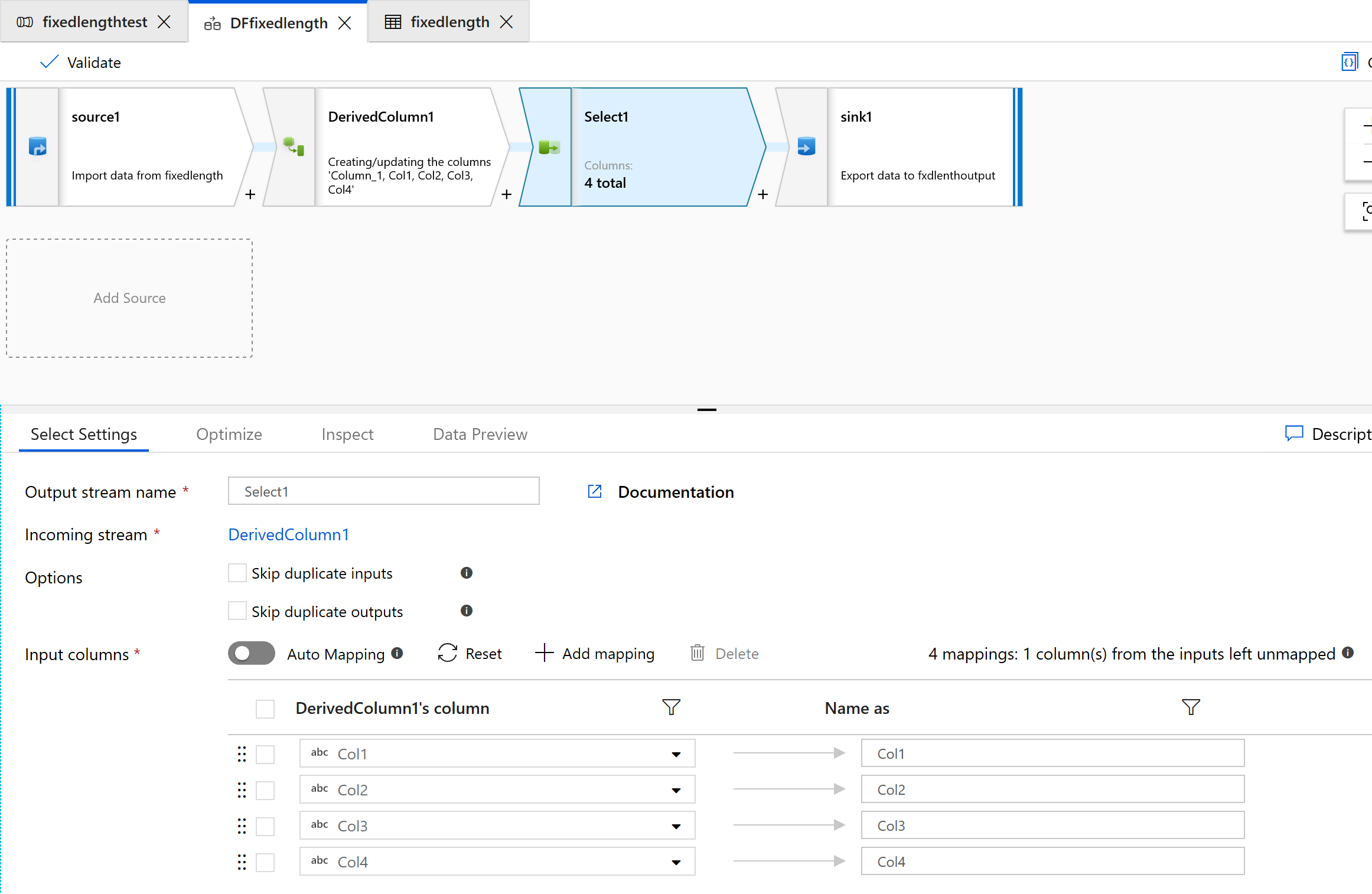
Använd Mottagare för att mata ut data till en mapp:
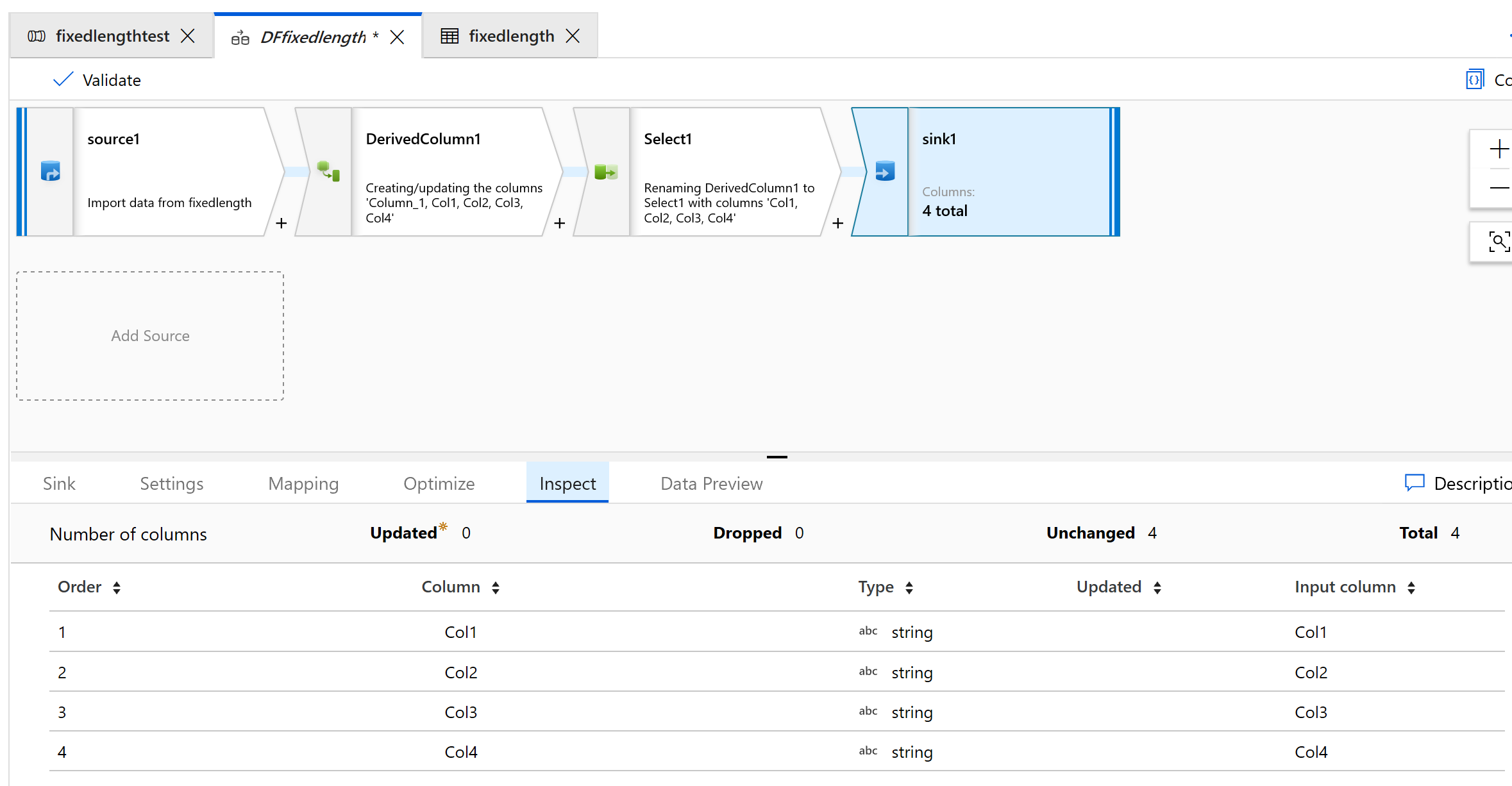
Så här ser utdata ut:
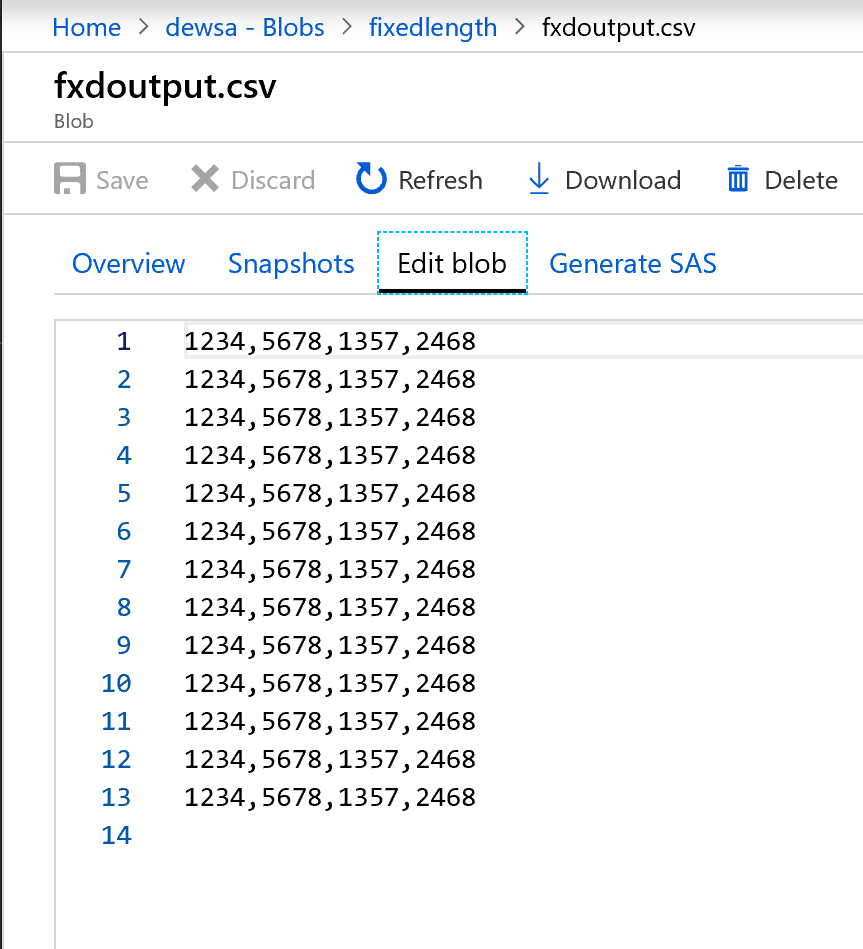
Data med fast bredd delas nu upp med fyra tecken vardera och tilldelas till Col1, Col2, Col3, Col4 och så vidare. Baserat på föregående exempel delas data upp i fyra kolumner.
Relaterat innehåll
- Skapa resten av dataflödeslogik med hjälp av omvandlingar av dataflöden.