Arkiverad viktig information
Sammanfattning
Azure HDInsight är en av de mest populära tjänsterna bland företagskunder för analys med öppen källkod i Azure. Prenumerera på viktig information om HDInsight för uppdaterad information om HDInsight och alla HDInsight-versioner.
Om du vill prenumerera klickar du på knappen "watch" i banderollen och ser upp för HDInsight-versioner.
Versionsinformation
Utgivningsdatum: 15 februari 2024
Den här versionen gäller för HDInsight 4.x- och 5.x-versioner. HDInsight-versionen kommer att vara tillgänglig för alla regioner under flera dagar. Den här versionen gäller för 2401250802. Hur kontrollerar du avbildningsnumret?
HDInsight använder sig av säkra distributionsmetoder, vilket innebär gradvis regiondistribution. Det kan ta upp till 10 arbetsdagar innan en ny version eller en ny version är tillgänglig i alla regioner.
OS-versioner
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Kommentar
Ubuntu 18.04 stöds under Extended Security Maintenance (ESM) av Azure Linux-teamet för Azure HDInsight juli 2023 och senare.
För arbetsbelastningsspecifika versioner, se
Nya funktioner
- Apache Ranger-stöd för Spark SQL i Spark 3.3.0 (HDInsight version 5.1) med Enterprise-säkerhetspaket. Läs mer om den här.
Åtgärdade problem
- Säkerhetskorrigeringar från Ambari- och Oozie-komponenter
 Kommer snart
Kommer snart
- Virtuella datorer i Basic- och Standard A-serien dras tillbaka.
- Den 31 augusti 2024 drar vi tillbaka virtuella datorer i Basic- och Standard A-serien. Innan det datumet måste du migrera dina arbetsbelastningar till virtuella datorer i Av2-serien, vilket ger mer minne per vCPU och snabbare lagring på solid state-enheter (SSD).
- För att undvika tjänststörningar migrerar du dina arbetsbelastningar från virtuella datorer i Basic- och Standard A-serien till virtuella datorer i Av2-serien före den 31 augusti 2024.
Kontakta Azure Support om du har fler frågor.
Du kan alltid fråga oss om HDInsight i Azure HDInsight – Microsoft Q&A
Vi lyssnar: Du är välkommen att lägga till fler idéer och andra ämnen här och rösta på dem – HDInsight-idéer och följ oss för fler uppdateringar om AzureHDInsight Community
Kommentar
Vi rekommenderar kunder att använda till de senaste versionerna av HDInsight-avbildningar när de får det bästa av öppen källkod uppdateringar, Azure-uppdateringar och säkerhetskorrigeringar. Mer information finns i Metodtips.
Nästa steg
- Azure HDInsight: Vanliga frågor och svar
- Konfigurera uppdateringsschema för operativsystemet för Linux-baserade HDInsight-kluster
- Föregående versionsanteckning
Azure HDInsight är en av de mest populära tjänsterna bland företagskunder för analys med öppen källkod i Azure. Om du vill prenumerera på viktig information kan du titta på versioner på den här GitHub-lagringsplatsen.
Utgivningsdatum: 10 januari 2024
Den här snabbkorrigeringsversionen gäller för HDInsight 4.x- och 5.x-versioner. HDInsight-versionen kommer att vara tillgänglig för alla regioner under flera dagar. Den här versionen gäller för 2401030422. Hur kontrollerar du avbildningsnumret?
HDInsight använder sig av säkra distributionsmetoder, vilket innebär gradvis regiondistribution. Det kan ta upp till 10 arbetsdagar innan en ny version eller en ny version är tillgänglig i alla regioner.
OS-versioner
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Kommentar
Ubuntu 18.04 stöds under Extended Security Maintenance (ESM) av Azure Linux-teamet för Azure HDInsight juli 2023 och senare.
För arbetsbelastningsspecifika versioner, se
Åtgärdade problem
- Säkerhetskorrigeringar från Ambari- och Oozie-komponenter
Kommer snart
- Virtuella datorer i Basic- och Standard A-serien dras tillbaka.
- Den 31 augusti 2024 drar vi tillbaka virtuella datorer i Basic- och Standard A-serien. Innan det datumet måste du migrera dina arbetsbelastningar till virtuella datorer i Av2-serien, vilket ger mer minne per vCPU och snabbare lagring på solid state-enheter (SSD).
- För att undvika tjänststörningar migrerar du dina arbetsbelastningar från virtuella datorer i Basic- och Standard A-serien till virtuella datorer i Av2-serien före den 31 augusti 2024.
Kontakta Azure Support om du har fler frågor.
Du kan alltid fråga oss om HDInsight i Azure HDInsight – Microsoft Q&A
Vi lyssnar: Du är välkommen att lägga till fler idéer och andra ämnen här och rösta på dem – HDInsight-idéer och följ oss för fler uppdateringar om AzureHDInsight Community
Kommentar
Vi rekommenderar kunder att använda till de senaste versionerna av HDInsight-avbildningar när de får det bästa av öppen källkod uppdateringar, Azure-uppdateringar och säkerhetskorrigeringar. Mer information finns i Metodtips.
Utgivningsdatum: 26 oktober 2023
Den här versionen gäller för HDInsight 4.x och 5.x HDInsight-versionen kommer att vara tillgänglig för alla regioner under flera dagar. Den här versionen gäller för 2310140056. Hur kontrollerar du avbildningsnumret?
HDInsight använder sig av säkra distributionsmetoder, vilket innebär gradvis regiondistribution. Det kan ta upp till 10 arbetsdagar innan en ny version eller en ny version är tillgänglig i alla regioner.
OS-versioner
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
För arbetsbelastningsspecifika versioner, se
Nyheter
HDInsight meddelar allmän tillgänglighet för HDInsight 5.1 från och med den 1 november 2023. Den här versionen ger en fullständig stackuppdatering av de öppen källkod komponenterna och integreringarna från Microsoft.
- De senaste versionerna med öppen källkod – HDInsight 5.1 levereras med den senaste stabila versionen med öppen källkod. Kunder kan dra nytta av alla senaste öppen källkod funktioner, Prestandaförbättringar för Microsoft och Buggkorrigeringar.
- Secure – De senaste versionerna levereras med de senaste säkerhetskorrigeringarna, både säkerhetskorrigeringar med öppen källkod och säkerhetsförbättringar från Microsoft.
- Lägre TCO – Med prestandaförbättringar kan kunderna sänka driftskostnaderna, tillsammans med förbättrad autoskalning.
Klusterbehörigheter för säker lagring
- Kunder kan ange (när klustret skapas) om en säker kanal ska användas för HDInsight-klusternoder för att ansluta lagringskontot.
Skapa HDInsight-kluster med anpassade virtuella nätverk.
- För att förbättra den övergripande säkerhetsstatusen för HDInsight-kluster måste HDInsight-kluster som använder anpassade virtuella nätverk se till att användaren måste ha behörighet att
Microsoft Network/virtualNetworks/subnets/join/actionutföra skapandeåtgärder. Kunden kan stöta på fel vid skapande om den här kontrollen inte är aktiverad.
- För att förbättra den övergripande säkerhetsstatusen för HDInsight-kluster måste HDInsight-kluster som använder anpassade virtuella nätverk se till att användaren måste ha behörighet att
ABFS-kluster som inte är ESP-kluster [klusterbehörigheter för läsbart ord]
- ABFS-kluster som inte är ESP-kluster hindrar icke-Hadoop-gruppanvändare från att köra Hadoop-kommandon för lagringsåtgärder. Den här ändringen förbättrar klustrets säkerhetsstatus.
Uppdatering av infogad kvot.
- Nu kan du begära kvotökning direkt från sidan Min kvot, med det direkta API-anropet är det mycket snabbare. Om API-anropet misslyckas kan du skapa en ny supportbegäran om kvotökning.
Kommer snart
Maxlängden för klusternamnet kommer att ändras till 45 tecken från 59 tecken för att förbättra säkerheten för kluster. Den här ändringen distribueras till alla regioner som startar den kommande versionen.
Virtuella datorer i Basic- och Standard A-serien dras tillbaka.
- Den 31 augusti 2024 drar vi tillbaka virtuella datorer i Basic- och Standard A-serien. Innan det datumet måste du migrera dina arbetsbelastningar till virtuella datorer i Av2-serien, vilket ger mer minne per vCPU och snabbare lagring på solid state-enheter (SSD).
- För att undvika tjänststörningar migrerar du dina arbetsbelastningar från virtuella datorer i Basic- och Standard A-serien till virtuella datorer i Av2-serien före den 31 augusti 2024.
Kontakta Azure Support om du har fler frågor.
Du kan alltid fråga oss om HDInsight i Azure HDInsight – Microsoft Q&A
Vi lyssnar: Du är välkommen att lägga till fler idéer och andra ämnen här och rösta på dem – HDInsight-idéer och följ oss för fler uppdateringar om AzureHDInsight Community
Kommentar
Den här versionen behandlar följande CVE:er som släpptes av MSRC den 12 september 2023. Åtgärden är att uppdatera till den senaste avbildningen 2308221128 eller 2310140056. Kunderna uppmanas att planera i enlighet med detta.
| CVE | Allvarlighet | CVE-rubrik | Anmärkning |
|---|---|---|---|
| CVE-2023-38156 | Viktigt! | Höjning av sårbarhet för privilegier av Azure HDInsight Apache Ambari | Ingår i avbildning 2308221128 eller 2310140056 |
| CVE-2023-36419 | Viktigt! | Höjning av sårbarhet för privilegier av Azure HDInsight Apache Oozie schemaläggare för arbetsflöde | Tillämpa Skriptåtgärd på dina kluster eller uppdatera till 2310140056 avbildning |
Kommentar
Vi rekommenderar kunder att använda till de senaste versionerna av HDInsight-avbildningar när de får det bästa av öppen källkod uppdateringar, Azure-uppdateringar och säkerhetskorrigeringar. Mer information finns i Metodtips.
Utgivningsdatum: 7 september 2023
Den här versionen gäller för HDInsight 4.x och 5.x HDInsight-versionen kommer att vara tillgänglig för alla regioner under flera dagar. Den här versionen gäller för 2308221128. Hur kontrollerar du avbildningsnumret?
HDInsight använder sig av säkra distributionsmetoder, vilket innebär gradvis regiondistribution. Det kan ta upp till 10 arbetsdagar innan en ny version eller en ny version är tillgänglig i alla regioner.
OS-versioner
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
För arbetsbelastningsspecifika versioner, se
Viktigt!
Den här versionen behandlar följande CVE:er som släpptes av MSRC den 12 september 2023. Åtgärden är att uppdatera till den senaste 2308221128. Kunderna uppmanas att planera i enlighet med detta.
| CVE | Allvarlighet | CVE-rubrik | Anmärkning |
|---|---|---|---|
| CVE-2023-38156 | Viktigt! | Höjning av sårbarhet för privilegier av Azure HDInsight Apache Ambari | Ingår i 2308221128 bild |
| CVE-2023-36419 | Viktigt! | Höjning av sårbarhet för privilegier av Azure HDInsight Apache Oozie schemaläggare för arbetsflöde | Tillämpa skriptåtgärd på dina kluster |
Kommer snart
- Maxlängden för klusternamnet kommer att ändras till 45 tecken från 59 tecken för att förbättra säkerheten för kluster. Ändringen kommer att genomföras senast den 30 september 2023.
- Klusterbehörigheter för säker lagring
- Kunder kan ange (när klustret skapas) om en säker kanal ska användas för HDInsight-klusternoder för att kontakta lagringskontot.
- Uppdatering av infogad kvot.
- Begärandekvoter ökar direkt från sidan Min kvot, vilket blir ett direkt API-anrop, vilket är snabbare. Om APdI-anropet misslyckas måste kunderna skapa en ny supportbegäran om kvotökning.
- Skapa HDInsight-kluster med anpassade virtuella nätverk.
- För att förbättra den övergripande säkerhetsstatusen för HDInsight-kluster måste HDInsight-kluster som använder anpassade virtuella nätverk se till att användaren måste ha behörighet att
Microsoft Network/virtualNetworks/subnets/join/actionutföra skapandeåtgärder. Kunderna skulle behöva planera i enlighet med detta eftersom den här ändringen skulle vara en obligatorisk kontroll för att undvika klusterskapandefel före den 30 september 2023.
- För att förbättra den övergripande säkerhetsstatusen för HDInsight-kluster måste HDInsight-kluster som använder anpassade virtuella nätverk se till att användaren måste ha behörighet att
- Virtuella datorer i Basic- och Standard A-serien dras tillbaka.
- Den 31 augusti 2024 drar vi tillbaka virtuella datorer i Basic- och Standard A-serien. Innan det datumet måste du migrera dina arbetsbelastningar till virtuella datorer i Av2-serien, vilket ger mer minne per vCPU och snabbare lagring på solid state-enheter (SSD). För att undvika tjänststörningar migrerar du dina arbetsbelastningar från virtuella datorer i Basic- och Standard A-serien till virtuella datorer i Av2-serien före den 31 augusti 2024.
- ABFS-kluster som inte är ESP-kluster [Klusterbehörigheter för Läsbart ord]
- Planera att införa en ändring i ABFS-kluster som inte är ESP-kluster, vilket hindrar icke-Hadoop-gruppanvändare från att köra Hadoop-kommandon för lagringsåtgärder. Den här ändringen för att förbättra klustrets säkerhetsstatus. Kunderna måste planera för uppdateringar före 30 september 2023.
Kontakta Azure Support om du har fler frågor.
Du kan alltid fråga oss om HDInsight i Azure HDInsight – Microsoft Q&A
Du är välkommen att lägga till fler förslag och idéer och andra ämnen här och rösta på dem - HDInsight Community (azure.com).
Kommentar
Vi rekommenderar kunder att använda till de senaste versionerna av HDInsight-avbildningar när de får det bästa av öppen källkod uppdateringar, Azure-uppdateringar och säkerhetskorrigeringar. Mer information finns i Metodtips.
Utgivningsdatum: 25 juli 2023
Den här versionen gäller för HDInsight 4.x och 5.x HDInsight-versionen kommer att vara tillgänglig för alla regioner under flera dagar. Den här versionen gäller för 2307201242. Hur kontrollerar du avbildningsnumret?
HDInsight använder sig av säkra distributionsmetoder, vilket innebär gradvis regiondistribution. Det kan ta upp till 10 arbetsdagar innan en ny version eller en ny version är tillgänglig i alla regioner.
OS-versioner
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
För arbetsbelastningsspecifika versioner, se
 Vad är det senaste
Vad är det senaste
- HDInsight 5.1 stöds nu med ESP-kluster.
- Uppgraderad version av Ranger 2.3.0 och Oozie 5.2.1 är nu en del av HDInsight 5.1
- Spark 3.3.1-klustret (HDInsight 5.1) levereras med Hive Warehouse Anslut or (HWC) 2.1, som fungerar tillsammans med klustret Interaktiv fråga (HDInsight 5.1).
- Ubuntu 18.04 stöds under ESM (utökat säkerhetsunderhåll) av Azure Linux-teamet för Azure HDInsight juli 2023 och senare.
Viktigt!
Den här versionen behandlar följande CVE:er som släpptes av MSRC den 8 augusti 2023. Åtgärden är att uppdatera till den senaste avbildningen 2307201242. Kunderna uppmanas att planera i enlighet med detta.
| CVE | Allvarlighet | CVE-rubrik |
|---|---|---|
| CVE-2023-35393 | Viktigt! | Sårbarhet för Azure Apache Hive-förfalskning |
| CVE-2023-35394 | Viktigt! | Sårbarhet för förfalskning av Azure HDInsight Jupyter Notebook |
| CVE-2023-36877 | Viktigt! | Azure Apache Oozie Spoofing Vulnerability |
| CVE-2023-36881 | Viktigt! | Azure Apache Ambari Spoofing Vulnerability |
| CVE-2023-38188 | Viktigt! | Sårbarhet för Azure Apache Hadoop-förfalskning |
Kommer snart
- Maxlängden för klusternamnet kommer att ändras till 45 tecken från 59 tecken för att förbättra säkerheten för kluster. Kunder måste planera för uppdateringarna före den 30 september 2023.
- Klusterbehörigheter för säker lagring
- Kunder kan ange (när klustret skapas) om en säker kanal ska användas för HDInsight-klusternoder för att kontakta lagringskontot.
- Uppdatering av infogad kvot.
- Begärandekvoter ökar direkt från sidan Min kvot, vilket blir ett direkt API-anrop, vilket är snabbare. Om API-anropet misslyckas måste kunderna skapa en ny supportbegäran om kvotökning.
- Skapa HDInsight-kluster med anpassade virtuella nätverk.
- För att förbättra den övergripande säkerhetsstatusen för HDInsight-kluster måste HDInsight-kluster som använder anpassade virtuella nätverk se till att användaren måste ha behörighet att
Microsoft Network/virtualNetworks/subnets/join/actionutföra skapandeåtgärder. Kunderna skulle behöva planera i enlighet med detta eftersom den här ändringen skulle vara en obligatorisk kontroll för att undvika klusterskapandefel före den 30 september 2023.
- För att förbättra den övergripande säkerhetsstatusen för HDInsight-kluster måste HDInsight-kluster som använder anpassade virtuella nätverk se till att användaren måste ha behörighet att
- Virtuella datorer i Basic- och Standard A-serien dras tillbaka.
- Den 31 augusti 2024 drar vi tillbaka virtuella datorer i Basic- och Standard A-serien. Innan det datumet måste du migrera dina arbetsbelastningar till virtuella datorer i Av2-serien, vilket ger mer minne per vCPU och snabbare lagring på solid state-enheter (SSD). För att undvika tjänststörningar migrerar du dina arbetsbelastningar från virtuella datorer i Basic- och Standard A-serien till virtuella datorer i Av2-serien före den 31 augusti 2024.
- ABFS-kluster som inte är ESP-kluster [Klusterbehörigheter för Läsbart ord]
- Planera att införa en ändring i ABFS-kluster som inte är ESP-kluster, vilket hindrar icke-Hadoop-gruppanvändare från att köra Hadoop-kommandon för lagringsåtgärder. Den här ändringen för att förbättra klustrets säkerhetsstatus. Kunder måste planera för uppdateringarna före den 30 september 2023.
Kontakta Azure Support om du har fler frågor.
Du kan alltid fråga oss om HDInsight i Azure HDInsight – Microsoft Q&A
Du är välkommen att lägga till fler förslag och idéer och andra ämnen här och rösta på dem - HDInsight Community (azure.com) och följ oss för fler uppdateringar på Twitter
Kommentar
Vi rekommenderar kunder att använda till de senaste versionerna av HDInsight-avbildningar när de får det bästa av öppen källkod uppdateringar, Azure-uppdateringar och säkerhetskorrigeringar. Mer information finns i Metodtips.
Utgivningsdatum: 08 maj 2023
Den här versionen gäller för HDInsight 4.x- och 5.x HDInsight-versionen är tillgänglig för alla regioner under flera dagar. Den här versionen gäller för 2304280205. Hur kontrollerar du avbildningsnumret?
HDInsight använder sig av säkra distributionsmetoder, vilket innebär gradvis regiondistribution. Det kan ta upp till 10 arbetsdagar innan en ny version eller en ny version är tillgänglig i alla regioner.
OS-versioner
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
För arbetsbelastningsspecifika versioner, se
![]()
Azure HDInsight 5.1 har uppdaterats med
- Apache HBase 2.4.11
- Apache Phoenix 5.1.2
- Apache Hive 3.1.2
- Apache Spark 3.3.1
- Apache Tez 0.9.1
- Apache Zeppelin 0.10.1
- Apache Livy 0.5
- Apache Kafka 3.2.0
Kommentar
- Alla komponenter är integrerade med Hadoop 3.3.4 & ZK 3.6.3
- Alla ovan uppgraderade komponenter är nu tillgängliga i icke-ESP-kluster för offentlig förhandsversion.
![]()
Förbättrad autoskalning för HDInsight
Azure HDInsight har gjort betydande förbättringar av stabilitet och svarstid för autoskalning. De viktigaste ändringarna omfattar förbättrad feedbackloop för skalningsbeslut, betydande förbättringar av svarstiden för skalning och stöd för återtagande av de inaktiverade noderna, Läs mer om förbättringarna, hur du konfigurerar och migrerar klustret till förbättrad autoskalning. Den förbättrade autoskalningsfunktionen är tillgänglig från och med den 17 maj 2023 i alla regioner som stöds.
Azure HDInsight ESP för Apache Kafka 2.4.1 är nu allmänt tillgängligt.
Azure HDInsight ESP för Apache Kafka 2.4.1 har varit i offentlig förhandsversion sedan april 2022. Efter anmärkningsvärda förbättringar av CVE-korrigeringar och stabilitet blir Azure HDInsight ESP Kafka 2.4.1 nu allmänt tillgänglig och redo för produktionsarbetsbelastningar. Läs mer om hur du konfigurerar och migrerar.
Kvothantering för HDInsight
HDInsight allokerar för närvarande kvoten till kundprenumerationer på regional nivå. Kärnorna som allokeras till kunder är generiska och klassificeras inte på vm-familjenivå (till exempel
Dv2,Ev3,Eav4osv.).HDInsight introducerade en förbättrad vy som ger en detaljerad och klassificering av kvoter för virtuella datorer på familjenivå. Med den här funktionen kan kunderna visa aktuella och återstående kvoter för en region på vm-familjenivå. Med den förbättrade vyn har kunderna bättre synlighet, för planeringskvoter och en bättre användarupplevelse. Den här funktionen är för närvarande tillgänglig i HDInsight 4.x och 5.x för EUAP-regionen USA, östra. Andra regioner att följa senare.
Mer information finns i Planera klusterkapacitet i Azure HDInsight | Microsoft Learn
![]()
- Polen, centrala
- Den maximala längden på klusternamnet ändras till 45 från 59 tecken för att förbättra klusters säkerhetsstatus.
- Klusterbehörigheter för säker lagring
- Kunder kan ange (när klustret skapas) om en säker kanal ska användas för HDInsight-klusternoder för att kontakta lagringskontot.
- Uppdatering av infogad kvot.
- Begärandekvoter ökar direkt från sidan Min kvot, vilket är ett direkt API-anrop, vilket är snabbare. Om API-anropet misslyckas måste kunderna skapa en ny supportbegäran om kvotökning.
- Skapa HDInsight-kluster med anpassade virtuella nätverk.
- För att förbättra den övergripande säkerhetsstatusen för HDInsight-kluster måste HDInsight-kluster som använder anpassade virtuella nätverk se till att användaren måste ha behörighet att
Microsoft Network/virtualNetworks/subnets/join/actionutföra skapandeåtgärder. Kunderna skulle behöva planera i enlighet med detta eftersom detta skulle vara en obligatorisk kontroll för att undvika klusterskapandefel.
- För att förbättra den övergripande säkerhetsstatusen för HDInsight-kluster måste HDInsight-kluster som använder anpassade virtuella nätverk se till att användaren måste ha behörighet att
- Virtuella datorer i Basic- och Standard A-serien dras tillbaka.
- Den 31 augusti 2024 drar vi tillbaka virtuella datorer i Basic- och Standard A-serien. Innan det datumet måste du migrera dina arbetsbelastningar till virtuella datorer i Av2-serien, vilket ger mer minne per vCPU och snabbare lagring på solid state-enheter (SSD). För att undvika tjänststörningar migrerar du dina arbetsbelastningar från virtuella datorer i Basic- och Standard A-serien till virtuella datorer i Av2-serien före den 31 augusti 2024.
- Icke-ESP ABFS-kluster [Klusterbehörigheter för world readable]
- Planera att införa en ändring i ABFS-kluster som inte är ESP-kluster, vilket hindrar icke-Hadoop-gruppanvändare från att köra Hadoop-kommandon för lagringsåtgärder. Den här ändringen för att förbättra klustrets säkerhetsstatus. Kunderna måste planera för uppdateringarna.
Utgivningsdatum: 28 februari 2023
Den här versionen gäller för HDInsight 4.0. och 5.0, 5.1. HDInsight-versionen är tillgänglig för alla regioner under flera dagar. Den här versionen gäller för 2302250400. Hur kontrollerar du avbildningsnumret?
HDInsight använder sig av säkra distributionsmetoder, vilket innebär gradvis regiondistribution. Det kan ta upp till 10 arbetsdagar innan en ny version eller en ny version är tillgänglig i alla regioner.
OS-versioner
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
För arbetsbelastningsspecifika versioner, se
Viktigt!
Microsoft har utfärdat CVE-2023-23408, som är fast i den aktuella versionen och kunderna uppmanas att uppgradera sina kluster till den senaste avbildningen.
![]()
HDInsight 5.1
Vi har börjat lansera en ny version av HDInsight 5.1. Alla nya versioner med öppen källkod har lagts till som inkrementella versioner i HDInsight 5.1.
Mer information finns i HDInsight 5.1.0-versionen
![]()
Kafka 3.2.0-uppgradering (förhandsversion)
- Kafka 3.2.0 innehåller flera viktiga nya funktioner/förbättringar.
- Uppgraderad Zookeeper till 3.6.3
- Stöd för Kafka Flöden
- Starkare leveransgarantier för Kafka-producenten aktiverade som standard.
log4j1.x ersattes medreload4j.- Skicka ett tips till partitionsledaren för att återställa partitionen.
JoinGroupRequestochLeaveGroupRequesthar en orsak bifogad.- Antal mått för broker har lagts till8.
- Speglingsförbättringar
Maker2.
HBase 2.4.11-uppgradering (förhandsversion)
- Den här versionen har nya funktioner, till exempel tillägg av nya typer av cachelagringsmekanismer för blockcache, möjligheten att ändra
hbase:meta tableoch visahbase:metatabellen från HBase WEB-användargränssnittet.
Phoenix 5.1.2-uppgradering (förhandsversion)
- Phoenix-versionen uppgraderades till 5.1.2 i den här versionen. Den här uppgraderingen omfattar Phoenix Query Server. Phoenix Query Server proxyservrar standard Phoenix JDBC-drivrutin och ger ett bakåtkompatibelt trådprotokoll för att anropa den JDBC-drivrutinen.
Ambari-CV:er
- Flera Ambari-CV:er är fasta.
Kommentar
ESP stöds inte för Kafka och HBase i den här versionen.
![]()
Supporten för Azure HDInsight-kluster upphör den 2.4 februari 10 februari 2024. Mer information finns i Spark-versioner som stöds i Azure HDInsight
Vad händer härnäst?
- Autoskalning
- Autoskalning med förbättrad svarstid och flera förbättringar
- Ändringsbegränsning för klusternamn
- Den maximala längden på klusternamnet ändras till 45 från 59 i Offentliga, Azure Kina och Azure Government.
- Klusterbehörigheter för säker lagring
- Kunder kan ange (när klustret skapas) om en säker kanal ska användas för HDInsight-klusternoder för att kontakta lagringskontot.
- Icke-ESP ABFS-kluster [Klusterbehörigheter för world readable]
- Planera att införa en ändring i ABFS-kluster som inte är ESP-kluster, vilket hindrar icke-Hadoop-gruppanvändare från att köra Hadoop-kommandon för lagringsåtgärder. Den här ändringen för att förbättra klustrets säkerhetsstatus. Kunderna måste planera för uppdateringarna.
- Uppgraderingar med öppen källkod
- Apache Spark 3.3.0 och Hadoop 3.3.4 är under utveckling på HDInsight 5.1 och innehåller flera viktiga nya funktioner, prestanda och andra förbättringar.
Kommentar
Vi rekommenderar kunder att använda till de senaste versionerna av HDInsight-avbildningar när de får det bästa av öppen källkod uppdateringar, Azure-uppdateringar och säkerhetskorrigeringar. Mer information finns i Metodtips.
Utgivningsdatum: 12 december 2022
Den här versionen gäller för HDInsight 4.0. och 5.0 HDInsight-versionen görs tillgänglig för alla regioner under flera dagar.
HDInsight använder sig av säkra distributionsmetoder, vilket innebär gradvis regiondistribution. Det kan ta upp till 10 arbetsdagar innan en ny version eller en ny version är tillgänglig i alla regioner.
OS-versioner
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
För arbetsbelastningsspecifika versioner, se här.
![]()
- Log Analytics – Kunder kan aktivera klassisk övervakning för att få den senaste OMS-versionen 14.19. Om du vill ta bort gamla versioner inaktiverar och aktiverar du klassisk övervakning.
- Automatisk utloggning av användargränssnittet i Ambari på grund av inaktivitet. Mer information finns här
- Spark – En ny och optimerad version av Spark 3.1.3 ingår i den här versionen. Vi testade Apache Spark 3.1.2 (tidigare version) och Apache Spark 3.1.3 (aktuell version) med hjälp av TPC-DS-riktmärket. Testet utfördes med E8 V3 SKU för Apache Spark på 1 TB arbetsbelastning. Apache Spark 3.1.3 (aktuell version) överträffade Apache Spark 3.1.2 (tidigare version) med över 40 % i den totala frågekörningen för TPC-DS-frågor med samma maskinvaruspecifikationer. Microsoft Spark-teamet har lagt till optimeringar som är tillgängliga i Azure Synapse med Azure HDInsight. Mer information finns i Påskynda dina dataarbetsbelastningar med prestandauppdateringar till Apache Spark 3.1.2 i Azure Synapse
![]()
- Qatar, centrala
- Tyskland, norra
![]()
HDInsight har flyttat från Azul Zulu Java JDK 8 till
Adoptium Temurin JDK 8, som stöder högkvalitativa TCK-certifierade körningar och tillhörande teknik för användning i Java-ekosystemet.HDInsight har migrerat till
reload4j. Ändringarnalog4jgäller för- Apache Hadoop
- Apache Zookeeper
- Apache Oozie
- Apache Ranger
- Apache Sqoop
- Apache Pig
- Apache Ambari
- Apache Kafka
- Apache Spark
- Apache Zeppelin
- Apache Livy
- Apache Rubix
- Apache Hive
- Apache Tez
- Apache HBase
- OMI
- Apache Pheonix
![]()
HDInsight implementerar TLS1.2 framöver och tidigare versioner uppdateras på plattformen. Om du kör program ovanpå HDInsight och de använder TLS 1.0 och 1.1 uppgraderar du till TLS 1.2 för att undvika avbrott i tjänsterna.
Mer information finns i Så här aktiverar du TLS (Transport Layer Security)
![]()
Stöd upphör för Azure HDInsight-kluster på Ubuntu 16.04 LTS från och med den 30 november 2022. HDInsight börjar släppa klusteravbildningar med Ubuntu 18.04 från den 27 juni 2021. Vi rekommenderar att våra kunder som kör kluster med Ubuntu 16.04 ska återskapa sina kluster med de senaste HDInsight-avbildningarna senast den 30 november 2022.
Mer information om hur du kontrollerar Ubuntu-versionen av klustret finns här
Kör kommandot "lsb_release -a" i terminalen.
Om värdet för egenskapen "Beskrivning" i utdata är "Ubuntu 16.04 LTS" gäller den här uppdateringen för klustret.
![]()
- Stöd för Tillgänglighetszoner val för Kafka- och HBase-kluster (skrivåtkomst).
Felkorrigeringar med öppen källkod
Hive-buggkorrigeringar
| Felkorrigeringar | Apache JIRA |
|---|---|
| HIVE-26127 | INSERT OVERWRITE-fel – Filen hittades inte |
| HIVE-24957 | Felaktiga resultat när underfrågor har COALESCE i korrelationspredikat |
| HIVE-24999 | HiveSubQueryRemoveRule genererar en ogiltig plan för IN-underfrågor med flera korrelationer |
| HIVE-24322 | Om det finns en direkt infogning måste försöks-ID:t kontrolleras när manifestet läss |
| HIVE-23363 | Uppgradera DataNucleus-beroende till 5.2 |
| HIVE-26412 | Skapa gränssnitt för att hämta tillgängliga platser och lägga till standard |
| HIVE-26173 | Uppgradera derbyt till 10.14.2.0 |
| HIVE-25920 | Bump Xerce2 till 2.12.2. |
| HIVE-26300 | Uppgradera Jacksons databindningsversion till 2.12.6.1+ för att undvika CVE-2020-36518 |
Utgivningsdatum: 2022-08-10
Den här versionen gäller för HDInsight 4.0. HDInsight-versionen görs tillgänglig för alla regioner under flera dagar.
HDInsight använder sig av säkra distributionsmetoder, vilket innebär gradvis regiondistribution. Det kan ta upp till 10 arbetsdagar innan en ny version eller en ny version är tillgänglig i alla regioner.
![]()
Ny funktion
1. Koppla externa diskar i HDI Hadoop/Spark-kluster
HDInsight-klustret levereras med fördefinierat diskutrymme baserat på SKU. Det här utrymmet kanske inte räcker i stora jobbscenarier.
Med den här nya funktionen kan du lägga till fler diskar i klustret, som används som lokal katalog för nodhanteraren. Lägg till antalet diskar i arbetsnoder när HIVE- och Spark-kluster skapas, medan de valda diskarna ingår i nodhanterarens lokala kataloger.
Kommentar
De tillagda diskarna konfigureras endast för lokala nodhanterares kataloger.
Mer information finns här
2. Selektiv loggningsanalys
Selektiv loggningsanalys är nu tillgänglig i alla regioner för offentlig förhandsversion. Du kan ansluta klustret till en log analytics-arbetsyta. När du är aktiverad kan du se loggar och mått som HDInsight-säkerhetsloggar, Yarn Resource Manager, systemmått osv. Du kan övervaka arbetsbelastningar och se hur de påverkar klusterstabiliteten. Med selektiv loggning kan du aktivera/inaktivera alla tabeller eller aktivera selektiva tabeller på log analytics-arbetsytan. Du kan justera källtypen för varje tabell eftersom en tabell har flera källor i den nya versionen av Genèveövervakning.
- Genèveövervakningssystemet använder mdsd(MDS-daemon) som är en övervakningsagent och flytande för insamling av loggar med enhetligt loggningslager.
- Selektiv loggning använder skriptåtgärd för att inaktivera/aktivera tabeller och deras loggtyper. Eftersom det inte öppnar några nya portar eller ändrar någon befintlig säkerhetsinställning finns det därför inga säkerhetsändringar.
- Skriptåtgärden körs parallellt på alla angivna noder och ändrar konfigurationsfilerna för att inaktivera/aktivera tabeller och deras loggtyper.
Mer information finns här
![]()
Åtgärdat
Log Analytics
Log Analytics som är integrerat med Azure HDInsight som kör OMS version 13 kräver en uppgradering till OMS version 14 för att tillämpa de senaste säkerhetsuppdateringarna. Kunder som använder äldre version av klustret med OMS version 13 måste installera OMS version 14 för att uppfylla säkerhetskraven. (Så här kontrollerar du den aktuella versionen och installerar 14)
Så här kontrollerar du din aktuella OMS-version
- Logga in på klustret med hjälp av SSH.
- Kör följande kommando i SSH-klienten.
sudo /opt/omi/bin/ominiserver/ --version

Uppgradera OMS-versionen från 13 till 14
- Logga in på Azure-portalen
- I resursgruppen väljer du HDInsight-klusterresursen
- Välj Skriptåtgärder
- I åtgärdspanelen Skicka skript väljer du Skripttyp som anpassad
- Klistra in följande länk i rutan Bash-skript-URL https://hdiconfigactions.blob.core.windows.net/log-analytics-patch/OMSUPGRADE14.1/omsagent-vulnerability-fix-1.14.12-0.sh
- Välj Nodtyp(er)
- Välj Skapa
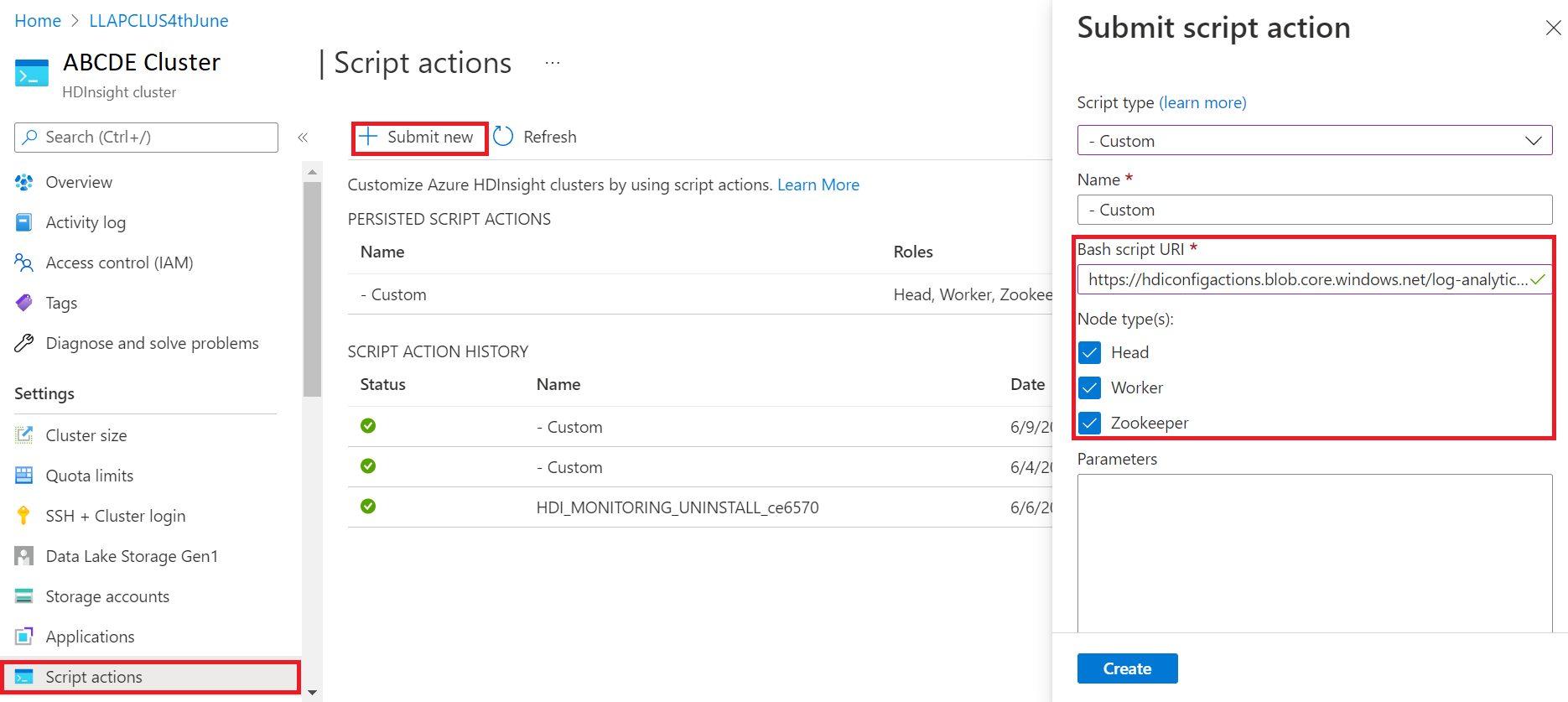
Kontrollera att korrigeringen har installerats med hjälp av följande steg:
Logga in på klustret med hjälp av SSH.
Kör följande kommando i SSH-klienten.
sudo /opt/omi/bin/ominiserver/ --version
Andra felkorrigeringar
- Yarn-loggens CLI kunde inte hämta loggarna om någon
TFileär skadad eller tom. - Det gick inte att lösa fel med ogiltig information om tjänstens huvudnamn när OAuth-token hämtades från Azure Active Directory.
- Förbättrad tillförlitlighet för att skapa kluster när över 100 arbetsnoder konfigureras.
Felkorrigeringar med öppen källkod
Felkorrigeringar för TEZ
| Felkorrigeringar | Apache JIRA |
|---|---|
| Tez-byggfel: FileSaver.js hittades inte | TEZ-4411 |
Fel FS-undantag när lager och scratchdir finns på olika FS |
TEZ-4406 |
| TezUtils.createConfFromByteString på Konfiguration större än 32 MB kastar com.google.protobuf.CodedInputStream undantag | TEZ-4142 |
| TezUtils::createByteStringFromConf bör använda snappy i stället för DeflaterOutputStream | TEZ-4113 |
| Uppdatera protobuf-beroendet till 3.x | TEZ-4363 |
Hive-buggkorrigeringar
| Felkorrigeringar | Apache JIRA |
|---|---|
| Perf-optimeringar i ORC-delningsgenerering | HIVE-21457 |
| Undvik att läsa tabellen som ACID när tabellnamnet börjar med "delta", men tabellen är inte transaktionell och BI Split Strategy används | HIVE-22582 |
| Ta bort ett FS#exists-anrop från AcidUtils#getLogicalLength | HIVE-23533 |
| Vektoriserad OrcAcidRowBatchReader.computeOffset och bucketoptimering | HIVE-17917 |
Kända problem
HDInsight är kompatibelt med Apache HIVE 3.1.2. På grund av en bugg i den här versionen visas Hive-versionen som 3.1.0 i hive-gränssnitt. Funktionen påverkas dock inte.
Utgivningsdatum: 2022-08-10
Den här versionen gäller för HDInsight 4.0. HDInsight-versionen görs tillgänglig för alla regioner under flera dagar.
HDInsight använder sig av säkra distributionsmetoder, vilket innebär gradvis regiondistribution. Det kan ta upp till 10 arbetsdagar innan en ny version eller en ny version är tillgänglig i alla regioner.
![]()
Ny funktion
1. Koppla externa diskar i HDI Hadoop/Spark-kluster
HDInsight-klustret levereras med fördefinierat diskutrymme baserat på SKU. Det här utrymmet kanske inte räcker i stora jobbscenarier.
Med den här nya funktionen kan du lägga till fler diskar i klustret, som ska användas som lokal katalog för nodhanteraren. Lägg till antalet diskar i arbetsnoder när HIVE- och Spark-kluster skapas, medan de valda diskarna ingår i nodhanterarens lokala kataloger.
Kommentar
De tillagda diskarna konfigureras endast för lokala nodhanterares kataloger.
Mer information finns här
2. Selektiv loggningsanalys
Selektiv loggningsanalys är nu tillgänglig i alla regioner för offentlig förhandsversion. Du kan ansluta klustret till en log analytics-arbetsyta. När du är aktiverad kan du se loggar och mått som HDInsight-säkerhetsloggar, Yarn Resource Manager, systemmått osv. Du kan övervaka arbetsbelastningar och se hur de påverkar klusterstabiliteten. Med selektiv loggning kan du aktivera/inaktivera alla tabeller eller aktivera selektiva tabeller på log analytics-arbetsytan. Du kan justera källtypen för varje tabell eftersom en tabell har flera källor i den nya versionen av Genèveövervakning.
- Genèveövervakningssystemet använder mdsd(MDS-daemon) som är en övervakningsagent och flytande för insamling av loggar med enhetligt loggningslager.
- Selektiv loggning använder skriptåtgärd för att inaktivera/aktivera tabeller och deras loggtyper. Eftersom det inte öppnar några nya portar eller ändrar någon befintlig säkerhetsinställning finns det därför inga säkerhetsändringar.
- Skriptåtgärden körs parallellt på alla angivna noder och ändrar konfigurationsfilerna för att inaktivera/aktivera tabeller och deras loggtyper.
Mer information finns här
![]()
Åtgärdat
Log Analytics
Log Analytics som är integrerat med Azure HDInsight som kör OMS version 13 kräver en uppgradering till OMS version 14 för att tillämpa de senaste säkerhetsuppdateringarna. Kunder som använder äldre version av klustret med OMS version 13 måste installera OMS version 14 för att uppfylla säkerhetskraven. (Så här kontrollerar du den aktuella versionen och installerar 14)
Så här kontrollerar du din aktuella OMS-version
- Logga in på klustret med hjälp av SSH.
- Kör följande kommando i SSH-klienten.
sudo /opt/omi/bin/ominiserver/ --version
Uppgradera OMS-versionen från 13 till 14
- Logga in på Azure-portalen
- I resursgruppen väljer du HDInsight-klusterresursen
- Välj Skriptåtgärder
- I åtgärdspanelen Skicka skript väljer du Skripttyp som anpassad
- Klistra in följande länk i rutan Bash-skript-URL https://hdiconfigactions.blob.core.windows.net/log-analytics-patch/OMSUPGRADE14.1/omsagent-vulnerability-fix-1.14.12-0.sh
- Välj Nodtyp(er)
- Välj Skapa
Kontrollera att korrigeringen har installerats med hjälp av följande steg:
Logga in på klustret med hjälp av SSH.
Kör följande kommando i SSH-klienten.
sudo /opt/omi/bin/ominiserver/ --version
Andra felkorrigeringar
- Yarn-loggens CLI kunde inte hämta loggarna om någon
TFileär skadad eller tom. - Det gick inte att lösa fel med ogiltig information om tjänstens huvudnamn när OAuth-token hämtades från Azure Active Directory.
- Förbättrad tillförlitlighet för att skapa kluster när över 100 arbetsnoder konfigureras.
Felkorrigeringar med öppen källkod
Felkorrigeringar för TEZ
| Felkorrigeringar | Apache JIRA |
|---|---|
| Tez-byggfel: FileSaver.js hittades inte | TEZ-4411 |
Fel FS-undantag när lager och scratchdir finns på olika FS |
TEZ-4406 |
| TezUtils.createConfFromByteString på Konfiguration större än 32 MB kastar com.google.protobuf.CodedInputStream undantag | TEZ-4142 |
| TezUtils::createByteStringFromConf bör använda snappy i stället för DeflaterOutputStream | TEZ-4113 |
| Uppdatera protobuf-beroendet till 3.x | TEZ-4363 |
Hive-buggkorrigeringar
| Felkorrigeringar | Apache JIRA |
|---|---|
| Perf-optimeringar i ORC-delningsgenerering | HIVE-21457 |
| Undvik att läsa tabellen som ACID när tabellnamnet börjar med "delta", men tabellen är inte transaktionell och BI Split Strategy används | HIVE-22582 |
| Ta bort ett FS#exists-anrop från AcidUtils#getLogicalLength | HIVE-23533 |
| Vektoriserad OrcAcidRowBatchReader.computeOffset och bucketoptimering | HIVE-17917 |
Kända problem
HDInsight är kompatibelt med Apache HIVE 3.1.2. På grund av en bugg i den här versionen visas Hive-versionen som 3.1.0 i hive-gränssnitt. Funktionen påverkas dock inte.
Utgivningsdatum: 2022-06-03
Den här versionen gäller för HDInsight 4.0. HDInsight-versionen görs tillgänglig för alla regioner under flera dagar. Utgivningsdatumet här anger det första regionversionsdatumet. Om du inte ser följande ändringar väntar du tills versionen är live i din region under flera dagar.
Viktig information
Hive Warehouse Anslut or (HWC) på Spark v3.1.2
Med Hive Warehouse Anslut or (HWC) kan du dra nytta av de unika funktionerna i Hive och Spark för att skapa kraftfulla stordataprogram. HWC stöds för närvarande endast för Spark v2.4. Den här funktionen lägger till affärsvärde genom att tillåta ACID-transaktioner i Hive-tabeller med Spark. Den här funktionen är användbar för kunder som använder både Hive och Spark i sin dataegendom. Mer information finns i Apache Spark & Hive – Hive Warehouse Anslut or – Azure HDInsight | Microsoft Docs
Ambari
- Förbättringar av skalning och etablering
- HDI-hive är nu kompatibelt med OSS version 3.1.2
HDI Hive 3.1-versionen uppgraderas till OSS Hive 3.1.2. Den här versionen har alla korrigeringar och funktioner som är tillgängliga i öppen källkod Hive 3.1.2-version.
Kommentar
Spark
- Om du använder Azure-användargränssnittet för att skapa Spark-kluster för HDInsight visas en annan version av Spark 3.1 i listrutan. (HDI 5.0) tillsammans med de äldre versionerna. Den här versionen är en ny version av Spark 3.1. (HDI 4.0). Det här är bara en ändring på användargränssnittsnivå som inte påverkar något för befintliga användare och användare som redan använder ARM-mallen.
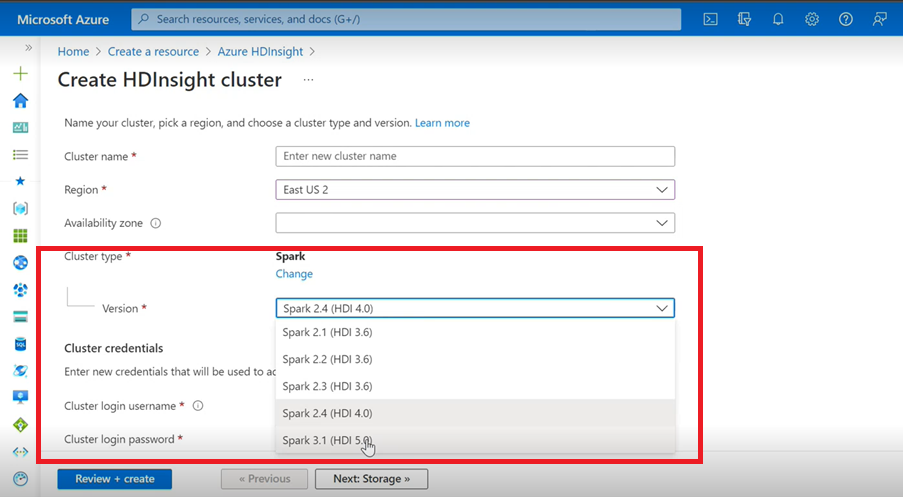
Kommentar
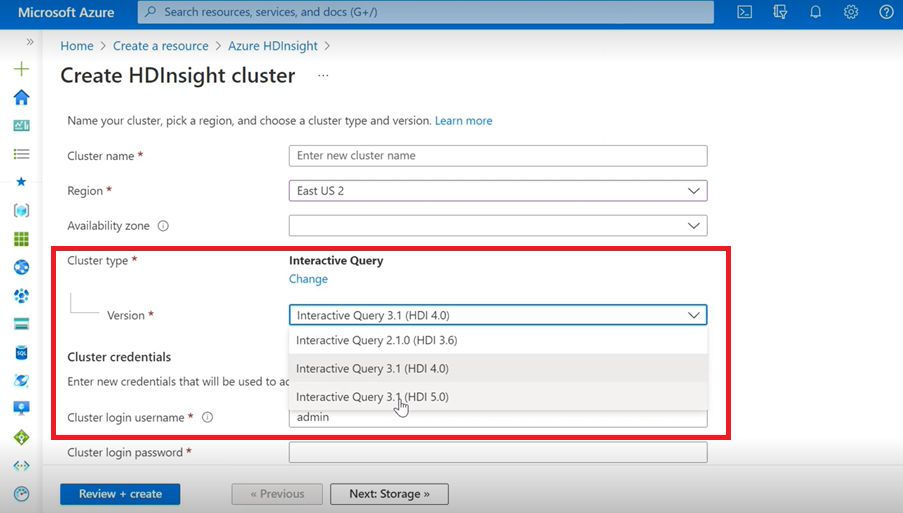
Interaktiv fråga
- Om du skapar ett Interaktiv fråga kluster ser du i listrutan en annan version som Interaktiv fråga 3.1 (HDI 5.0).
- Om du ska använda Spark 3.1-versionen tillsammans med Hive som kräver ACID-stöd måste du välja den här versionen Interaktiv fråga 3.1 (HDI 5.0).
Felkorrigeringar för TEZ
| Felkorrigeringar | Apache JIRA |
|---|---|
| TezUtils.createConfFromByteString på Konfiguration större än 32 MB kastar com.google.protobuf.CodedInputStream undantag | TEZ-4142 |
| TezUtils createByteStringFromConf bör använda snappy i stället för DeflaterOutputStream | TEZ-4113 |
HBase-felkorrigeringar
| Felkorrigeringar | Apache JIRA |
|---|---|
TableSnapshotInputFormat bör använda ReadType.STREAM för genomsökning HFiles |
HBASE-26273 |
| Lägg till alternativ för att inaktivera scanMetrics i TableSnapshotInputFormat | HBASE-26330 |
| Korrigering för ArrayIndexOutOfBoundsException när balancer körs | HBASE-22739 |
Hive-buggkorrigeringar
| Felkorrigeringar | Apache JIRA |
|---|---|
| NPE vid infogning av data med "distribuera efter"-sats med optimering av dynpartsortering | HIVE-18284 |
| MSCK REPAIR-kommandot med partitionsfiltrering misslyckas när partitioner släpps | HIVE-23851 |
| Fel undantag utlöses om kapacitet<=0 | HIVE-25446 |
| Stöd för parallell belastning för HastTables – gränssnitt | HIVE-25583 |
| Inkludera MultiDelimitSerDe i HiveServer2 som standard | HIVE-20619 |
| Ta bort glassfish.jersey- och mssql-jdbc-klasser från jdbc-fristående jar | HIVE-22134 |
| Null-pekarfel vid körning av komprimering mot en MM-tabell. | HIVE-21280 |
Hive-fråga med stor storlek via knox misslyckas med bruten pipe-skrivning misslyckades |
HIVE-22231 |
| Lägga till möjlighet för användare att ange bindningsanvändare | HIVE-21009 |
| Implementera UDF för att tolka datum/tidsstämpel med hjälp av dess interna representation och hybridkalendern Gregorian-Julian | HIVE-22241 |
| Beeline-alternativ för att visa/inte visa körningsrapport | HIVE-22204 |
| Tez: SplitGenerator försöker leta efter planfiler, som inte finns för Tez | HIVE-22169 |
Ta bort dyr loggning från LLAP-cachen hotpath |
HIVE-22168 |
| UDF: FunctionRegistry synkroniseras på klassen org.apache.hadoop.hive.ql.udf.UDFType | HIVE-22161 |
| Förhindra att tillägg för frågeroutning skapas om egenskapen är inställd på false | HIVE-22115 |
| Ta bort synkronisering mellan frågor för partition-eval | HIVE-22106 |
| Hoppa över att konfigurera hive scratch dir under planeringen | HIVE-21182 |
| Hoppa över att skapa scratch dirs för tez om RPC är på | HIVE-21171 |
växla Hive UDF:er för att använda Re2J regex-motorn |
HIVE-19661 |
| Migrerade klustrade tabeller med bucketing_version 1 på hive 3 använder bucketing_version 2 för infogningar | HIVE-22429 |
| Bucketing: Bucketing version 1 partitionerar data felaktigt | HIVE-21167 |
| Lägga till ASF-licenshuvud i den nyligen tillagda filen | HIVE-22498 |
| Förbättringar av schemaverktyget för att stödja mergeCatalog | HIVE-22498 |
| Hive med TEZ UNION ALL och UDTF resulterar i dataförlust | HIVE-21915 |
| Dela upp textfiler även om sidhuvud/sidfot finns | HIVE-21924 |
| MultiDelimitSerDe returnerar fel resultat i den senaste kolumnen när den inlästa filen har fler kolumner än den som finns i tabellschemat | HIVE-22360 |
| LLAP extern klient – Behöver minska LlapBaseInputFormat#getSplits() fotavtryck | HIVE-22221 |
| Kolumnnamn med reserverat nyckelord tas inte upp när frågan inklusive koppling i tabellen med maskkolumnen skrivs om (Zoltan Matyus via Zoltan Haindrich) | HIVE-22208 |
Förhindra LLAP-avstängning på AMReporter relaterad RuntimeException |
HIVE-22113 |
| LLAP-statustjänstdrivrutinen kan fastna med fel Yarn-app-ID | HIVE-21866 |
| OperationManager.queryIdOperation rensar inte flera queryIds korrekt | HIVE-22275 |
| Om du tar ned en nodhanterare blockeras omstarten av LLAP-tjänsten | HIVE-22219 |
| StackOverflowError när du släpper många partitioner | HIVE-15956 |
| Åtkomstkontrollen misslyckades när en tillfällig katalog tas bort | HIVE-22273 |
| Åtgärda fel resultat/ArrayOutOfBound-undantag i vänster yttre kartkopplingar vid specifika gränsvillkor | HIVE-22120 |
| Ta bort taggen distributionshantering från pom.xml | HIVE-19667 |
| Parsningstiden kan vara hög om det finns djupt kapslade underfrågor | HIVE-21980 |
FÖR ALTER TABLE t SET TBLPROPERTIES ('EXTERNAL'='TRUE'); TBL_TYPE attributändringar som inte återspeglar för icke-CAPS |
HIVE-20057 |
JDBC: Hive Anslut ion shades log4j interfaces |
HIVE-18874 |
Uppdatera url:er för lagringsplats i poms - gren 3.1-version |
HIVE-21786 |
DBInstall tester som har brutits på master och branch-3.1 |
HIVE-21758 |
| Inläsning av data i en bucketad tabell ignorerar partitionsspecifikationer och läser in data i standardpartitionen | HIVE-21564 |
| Frågor med kopplingsvillkor med tidsstämpel eller tidsstämpel med lokal tidszonsliteral genererar SemanticException | HIVE-21613 |
| Analysera beräkningsstatistik för kolumnledighet bakom mellanlagringsdir på HDFS | HIVE-21342 |
| Inkompatibel ändring i Hive-bucketberäkning | HIVE-21376 |
| Ange en reservauktoriserare när ingen annan auktoriserare används | HIVE-20420 |
| Vissa alterPartitions-anrop genererar "NumberFormatException: null" | HIVE-18767 |
| HiveServer2: Förautentiserat ämne för http-transport behålls inte under hela http-kommunikationen i vissa fall | HIVE-20555 |
Utgivningsdatum: 2022-03-10
Den här versionen gäller för HDInsight 4.0. HDInsight-versionen görs tillgänglig för alla regioner under flera dagar. Utgivningsdatumet här anger det första regionversionsdatumet. Om du inte ser följande ändringar väntar du tills versionen är live i din region under flera dagar.
Operativsystemversionerna för den här versionen är:
- HDInsight 4.0: Ubuntu 18.04.5
Spark 3.1 är nu allmänt tillgängligt
Spark 3.1 är nu allmänt tillgängligt i HDInsight 4.0-versionen. Den här versionen innehåller
- Adaptiv frågekörning,
- Konvertera sorteringskoppling till sändningshashkoppling,
- Spark Catalyst Optimizer,
- Dynamisk partitionsrensning,
- Kunder kommer att kunna skapa nya Spark 3.1-kluster och inte Spark 3.0-kluster (förhandsversion).
Mer information finns i Apache Spark 3.1 är nu allmänt tillgängligt i HDInsight – Microsoft Tech Community.
En fullständig lista över förbättringar finns i viktig information om Apache Spark 3.1.
Mer information om migrering finns i migreringsguiden .
Kafka 2.4 är nu allmänt tillgänglig
Kafka 2.4.1 är nu allmänt tillgänglig. Mer information finns i Viktig information om Kafka 2.4.1. Andra funktioner inkluderar MirrorMaker 2-tillgänglighet, ny måttkategori AtMinIsr-ämnespartition, förbättrad starttid för asynkrona asynkrona på begäran mmap av indexfiler, Fler konsumentmått för att observera beteende för användarmätning.
Map Datatype i HWC stöds nu i HDInsight 4.0
Den här versionen innehåller stöd för Map Datatype för HWC 1.0 (Spark 2.4) via spark-shell-programmet och alla andra spark-klienter som HWC stöder. Följande förbättringar ingår som andra datatyper:
En användare kan
- Skapa en Hive-tabell med alla kolumner som innehåller kartdatatyp, infoga data i den och läs resultatet från den.
- Skapa en Apache Spark-dataram med karttyp och gör batch-/stream-läsningar och skrivningar.
Nya regioner
HDInsight har nu utökat sin geografiska närvaro till två nya regioner: Kina, östra 3 och Kina, norra 3.
OSS-bakåtportningsändringar
OSS-backportar som ingår i Hive, inklusive HWC 1.0 (Spark 2.4) som stöder kartdatatyp.
Här är OSS-bakåtporterade Apache JIRA:er för den här versionen:
| Påverkad funktion | Apache JIRA |
|---|---|
| Metaarkivsdirigering av SQL-frågor med IN/(NOT IN) ska delas baserat på maximala parametrar som tillåts av SQL DB | HIVE-25659 |
Uppgradera log4j 2.16.0 till 2.17.0 |
HIVE-25825 |
Uppdatera Flatbuffer version |
HIVE-22827 |
| Stöd för mappning av datatyp internt i pilformat | HIVE-25553 |
| EXTERN LLAP-klient – Hantera kapslade värden när den överordnade structen är null | HIVE-25243 |
| Uppgradera pilversionen till 0.11.0 | HIVE-23987 |
Utfasningsmeddelanden
Skalningsuppsättningar för virtuella Azure-datorer i HDInsight
HDInsight använder inte längre Skalningsuppsättningar för virtuella Azure-datorer för att etablera klustren, ingen icke-bakåtkompatibel ändring förväntas. Befintliga HDInsight-kluster på vm-skalningsuppsättningar har ingen inverkan. Nya kluster på de senaste bilderna använder inte längre vm-skalningsuppsättningar.
Skalning av Azure HDInsight HBase-arbetsbelastningar stöds nu endast med manuell skalning
Från och med den 1 mars 2022 stöder HDInsight endast manuell skalning för HBase. Det påverkar inte kluster som körs. Nya HBase-kluster kan inte aktivera schemabaserad autoskalning. Mer information om hur du manuellt skalar ditt HBase-kluster finns i vår dokumentation om manuellt skalning av Azure HDInsight-kluster
Utgivningsdatum: 2021-02-27
Den här versionen gäller för HDInsight 4.0. HDInsight-versionen görs tillgänglig för alla regioner under flera dagar. Utgivningsdatumet här anger det första regionversionsdatumet. Om du inte ser följande ändringar väntar du tills versionen är live i din region under flera dagar.
Operativsystemversionerna för den här versionen är:
- HDInsight 4.0: Ubuntu 18.04.5 LTS
HDInsight 4.0-avbildningen har uppdaterats för att minska Log4j sårbarheten enligt beskrivningen i Microsofts svar på CVE-2021-44228 Apache Log4j 2.
Kommentar
- Alla HDI 4.0-kluster som skapats efter den 27 dec 2021 00:00 UTC skapas med en uppdaterad version av avbildningen som minskar säkerhetsriskerna
log4j. Därför behöver kunderna inte korrigera/starta om dessa kluster. - För nya HDInsight 4.0-kluster som skapats mellan den 16 december 2021 kl. 01:15 UTC och 27 dec 2021 00:00 UTC, HDInsight 3.6 eller i fästa prenumerationer efter den 16 december 2021 korrigeringen tillämpas automatiskt inom den timme då klustret skapas, men kunderna måste sedan starta om sina noder för att korrigeringen ska slutföras (med undantag för Kafka-hanteringsnoder. startas om automatiskt).
Utgivningsdatum: 2021-07-27
Den här versionen gäller för både HDInsight 3.6 och HDInsight 4.0. HDInsight-versionen görs tillgänglig för alla regioner under flera dagar. Utgivningsdatumet här anger det första regionversionsdatumet. Om du inte ser följande ändringar väntar du tills versionen är live i din region om flera dagar.
Operativsystemversionerna för den här versionen är:
- HDInsight 3.6: Ubuntu 16.04.7 LTS
- HDInsight 4.0: Ubuntu 18.04.5 LTS
Nya funktioner
Azure HDInsight-stöd för begränsad offentlig Anslut ivitet är allmänt tillgängligt den 15 oktober 2021
Azure HDInsight har nu stöd för begränsad offentlig anslutning i alla regioner. Nedan visas några av de viktigaste höjdpunkterna i den här funktionen:
- Möjlighet att omvända resursprovidern till klusterkommunikation så att den är utgående från klustret till resursprovidern
- Stöd för att ta med egna Private Link-aktiverade resurser (till exempel lagring, SQL, nyckelvalv) för HDInsight-kluster för att endast komma åt resurserna via privata nätverk
- Inga offentliga IP-adresser är resursetablerade
Med den här nya funktionen kan du också hoppa över tjänsttaggreglerna för inkommande nätverkssäkerhetsgrupp (NSG) för HDInsight-hanterings-IP-adresser. Läs mer om att begränsa offentlig anslutning
Azure HDInsight-stöd för Azure Private Link är allmänt tillgängligt den 15 oktober 2021
Nu kan du använda privata slutpunkter för att ansluta till dina HDInsight-kluster via privat länk. Privat länk kan användas i scenarier mellan virtuella nätverk där VNET-peering inte är tillgängligt eller aktiverat.
Med Azure Private Link kan du komma åt Azure PaaS Services (till exempel Azure Storage och SQL Database) och Azure-värdbaserade kundägda/partnertjänster via en privat slutpunkt i ditt virtuella nätverk.
Trafik mellan ditt virtuella nätverk och tjänsten färdas i Microsofts stamnätverk. Det är inte längre nödvändigt att exponera tjänsten i det offentliga Internet.
Låt mer vid aktivera privat länk.
Ny Azure Monitor-integreringsupplevelse (förhandsversion)
Den nya Azure Monitor-integreringen kommer att vara förhandsversion i USA, östra och Europa, västra med den här versionen. Läs mer om den nya Azure Monitor-upplevelsen här.
Inaktualitet
HDInsight 3.6-versionen är inaktuell från och med den 1 oktober 2022.
Funktionalitetsförändringar
HDInsight-Interaktiv fråga stöder endast schemabaserad autoskalning
I takt med att kundscenarierna blir mer mogna och olika har vi identifierat vissa begränsningar med Interaktiv fråga (LLAP) belastningsbaserad autoskalning. Dessa begränsningar orsakas av typen av LLAP-frågedynamik, problem med framtida precision för belastningsförutsägelse och problem i LLAP-schemaläggarens uppgiftsdistribution. På grund av dessa begränsningar kan användarna se sina frågor köras långsammare i LLAP-kluster när autoskalning är aktiverat. Effekten på prestanda kan uppväga kostnadsfördelarna med autoskalning.
Från och med juli 2021 stöder Interaktiv fråga-arbetsbelastningen i HDInsight endast schemabaserad autoskalning. Du kan inte längre aktivera belastningsbaserad autoskalning på nya Interaktiv fråga kluster. Befintliga kluster som körs kan fortsätta att köras med de kända begränsningar som beskrivs ovan.
Microsoft rekommenderar att du flyttar till en schemabaserad autoskalning för LLAP. Du kan analysera klustrets aktuella användningsmönster via Grafana Hive-instrumentpanelen. Mer information finns i Skala Azure HDInsight-kluster automatiskt.
Kommande ändringar
Följande ändringar sker i kommande versioner.
Den inbyggda LLAP-komponenten i ESP Spark-klustret tas bort
HDInsight 4.0 ESP Spark-kluster har inbyggda LLAP-komponenter som körs på båda huvudnoderna. LLAP-komponenterna i ESP Spark-klustret lades ursprungligen till för HDInsight 3.6 ESP Spark, men har inget verkligt användarfall för HDInsight 4.0 ESP Spark. I nästa version som schemaläggs i sep 2021 tar HDInsight bort den inbyggda LLAP-komponenten från HDInsight 4.0 ESP Spark-klustret. Den här ändringen hjälper till att avlasta huvudnodens arbetsbelastning och undvika förvirring mellan ESP Spark- och ESP Interactive Hive-klustertypen.
Ny region
- Västra USA 3
JioIndien, västra- Australien, centrala
Ändring av komponentversion
Följande komponentversion har ändrats med den här versionen:
- ORC-version från 1.5.1 till 1.5.9
Du hittar de aktuella komponentversionerna för HDInsight 4.0 och HDInsight 3.6 i det här dokumentet.
Bakåtporterade JIRA:er
Här är de bakåtporterade Apache JIRA:erna för den här versionen:
| Påverkad funktion | Apache JIRA |
|---|---|
| Datum/tidsstämpel | HIVE-25104 |
| HIVE-24074 | |
| HIVE-22840 | |
| HIVE-22589 | |
| HIVE-22405 | |
| HIVE-21729 | |
| HIVE-21291 | |
| HIVE-21290 | |
| UDF | HIVE-25268 |
| HIVE-25093 | |
| HIVE-22099 | |
| HIVE-24113 | |
| HIVE-22170 | |
| HIVE-22331 | |
| ORC | HIVE-21991 |
| HIVE-21815 | |
| HIVE-21862 | |
| Tabellschema | HIVE-20437 |
| HIVE-22941 | |
| HIVE-21784 | |
| HIVE-21714 | |
| HIVE-18702 | |
| HIVE-21799 | |
| HIVE-21296 | |
| Arbetsbelastningshantering | HIVE-24201 |
| Packning | HIVE-24882 |
| HIVE-23058 | |
| HIVE-23046 | |
| Materialiserad vy | HIVE-22566 |
Priskorrigering för virtuella HDInsight-datorer Dv2
Ett prisfel korrigerades den 25 april 2021 för VM-serien Dv2 i HDInsight. Prisfelet resulterade i en reducerad avgift på vissa kunders fakturor före den 25 april, och med korrigeringen matchar priserna nu vad som hade annonserats på HDInsight-prissidan och HDInsight-priskalkylatorn. Prisfelet påverkade kunder i följande regioner som använde Dv2 virtuella datorer:
- Kanada, centrala
- Kanada, östra
- Asien, östra
- Sydafrika, norra
- Sydostasien
- Förenade Arabemiraten, centrala
Från och med den 25 april 2021 kommer det korrigerade beloppet för de virtuella datorerna Dv2 att finnas på ditt konto. Kundmeddelanden skickades till prenumerationsägare före ändringen. Du kan använda priskalkylatorn, hdinsight-prissidan eller bladet Skapa HDInsight-kluster i Azure-portalen för att se de korrigerade kostnaderna för Dv2 virtuella datorer i din region.
Ingen annan åtgärd krävs från dig. Priskorrigeringen gäller endast för användning den 25 april 2021 eller senare i de angivna regionerna och inte för användning före detta datum. För att säkerställa att du har den mest högpresterande och kostnadseffektiva lösningen rekommenderar vi att du granskar priser, VCPU och RAM för dina Dv2 kluster och jämför specifikationerna med Dv2 de Ev3 virtuella datorerna för att se om din lösning skulle ha nytta av att använda en av de nyare VM-serierna.
Utgivningsdatum: 2021-06-02
Den här versionen gäller för både HDInsight 3.6 och HDInsight 4.0. HDInsight-versionen görs tillgänglig för alla regioner under flera dagar. Utgivningsdatumet här anger det första regionversionsdatumet. Om du inte ser följande ändringar väntar du tills versionen är live i din region om flera dagar.
Operativsystemversionerna för den här versionen är:
- HDInsight 3.6: Ubuntu 16.04.7 LTS
- HDInsight 4.0: Ubuntu 18.04.5 LTS
Nya funktioner
Uppgradering av operativsystemversion
Som du refererar till i Ubuntus lanseringscykel når Ubuntu 16.04-kärnan End of Life (EOL) i april 2021. Vi började lansera den nya HDInsight 4.0-klusteravbildningen som körs på Ubuntu 18.04 med den här versionen. Nyligen skapade HDInsight 4.0-kluster körs på Ubuntu 18.04 som standard när de är tillgängliga. Befintliga kluster på Ubuntu 16.04 körs som de är med fullständigt stöd.
HDInsight 3.6 fortsätter att köras på Ubuntu 16.04. Den ändras till Grundläggande support (från Standard support) från och med den 1 juli 2021. Mer information om datum och supportalternativ finns i Azure HDInsight-versioner. Ubuntu 18.04 stöds inte för HDInsight 3.6. Om du vill använda Ubuntu 18.04 måste du migrera dina kluster till HDInsight 4.0.
Du måste släppa och återskapa dina kluster om du vill flytta befintliga HDInsight 4.0-kluster till Ubuntu 18.04. Planera att skapa eller återskapa dina kluster när Ubuntu 18.04-supporten blir tillgänglig.
När du har skapat det nya klustret kan du SSH till klustret och köra sudo lsb_release -a det för att kontrollera att det körs på Ubuntu 18.04. Vi rekommenderar att du testar dina program i dina testprenumerationer först innan du går över till produktion.
Skalningsoptimeringar på HBase-accelererade skrivkluster
HDInsight har gjort vissa förbättringar och optimeringar av skalning för HBase-accelererade skrivaktiverade kluster. Läs mer om HBase-accelererad skrivning.
Inaktualitet
Ingen utfasning i den här versionen.
Funktionalitetsförändringar
Inaktivera Stardard_A5 VM-storlek som huvudnod för HDInsight 4.0
HDInsight-klustrets huvudnod ansvarar för att initiera och hantera klustret. Standard_A5 VM-storlek har tillförlitlighetsproblem som huvudnod för HDInsight 4.0. Från och med den här versionen kan kunderna inte skapa nya kluster med Standard_A5 VM-storlek som huvudnod. Du kan använda andra virtuella datorer med två kärnor som E2_v3 eller E2s_v3. Befintliga kluster körs som de är. En virtuell dator med fyra kärnor rekommenderas starkt för Head Node för att säkerställa hög tillgänglighet och tillförlitlighet för dina HDInsight-produktionskluster.
Nätverksgränssnittsresursen visas inte för kluster som körs på skalningsuppsättningar för virtuella Azure-datorer
HDInsight migreras gradvis till skalningsuppsättningar för virtuella Azure-datorer. Nätverksgränssnitt för virtuella datorer är inte längre synliga för kunder för kluster som använder skalningsuppsättningar för virtuella Azure-datorer.
Kommande ändringar
Följande ändringar sker i kommande versioner.
HDInsight-Interaktiv fråga stöder endast schemabaserad autoskalning
I takt med att kundscenarierna blir mer mogna och olika har vi identifierat vissa begränsningar med Interaktiv fråga (LLAP) belastningsbaserad autoskalning. Dessa begränsningar orsakas av typen av LLAP-frågedynamik, problem med framtida precision för belastningsförutsägelse och problem i LLAP-schemaläggarens uppgiftsdistribution. På grund av dessa begränsningar kan användarna se sina frågor köras långsammare i LLAP-kluster när autoskalning är aktiverat. Effekten på prestanda kan uppväga kostnadsfördelarna med autoskalning.
Från och med juli 2021 stöder Interaktiv fråga-arbetsbelastningen i HDInsight endast schemabaserad autoskalning. Du kan inte längre aktivera autoskalning för nya Interaktiv fråga kluster. Befintliga kluster som körs kan fortsätta att köras med de kända begränsningar som beskrivs ovan.
Microsoft rekommenderar att du flyttar till en schemabaserad autoskalning för LLAP. Du kan analysera klustrets aktuella användningsmönster via Grafana Hive-instrumentpanelen. Mer information finns i Skala Azure HDInsight-kluster automatiskt.
Namngivning av virtuella datorer ändras den 1 juli 2021
HDInsight använder nu virtuella Azure-datorer för att etablera klustret. Tjänsten migreras gradvis till skalningsuppsättningar för virtuella Azure-datorer. Den här migreringen ändrar FQDN-namnformatet för klustervärdnamn och talen i värdnamnet garanteras inte i följd. Om du vill hämta FQDN-namnen för varje nod läser du Hitta värdnamnen för klusternoder.
Flytta till skalningsuppsättningar för virtuella Azure-datorer
HDInsight använder nu virtuella Azure-datorer för att etablera klustret. Tjänsten migreras gradvis till skalningsuppsättningar för virtuella Azure-datorer. Hela processen kan ta månader. När dina regioner och prenumerationer har migrerats körs nyligen skapade HDInsight-kluster på vm-skalningsuppsättningar utan kundåtgärder. Ingen icke-bakåtkompatibel ändring förväntas.
Utgivningsdatum: 2021-03-24
Nya funktioner
Förhandsversion av Spark 3.0
HDInsight har lagt till Stöd för Spark 3.0.0 i HDInsight 4.0 som förhandsversion.
Förhandsversion av Kafka 2.4
HDInsight har lagt till Kafka 2.4.1-stöd för HDInsight 4.0 som förhandsversionsfunktion.
Eav4-series support
HDInsight har lagt till Eav4-series-stöd i den här versionen.
Flytta till skalningsuppsättningar för virtuella Azure-datorer
HDInsight använder nu virtuella Azure-datorer för att etablera klustret. Tjänsten migreras gradvis till skalningsuppsättningar för virtuella Azure-datorer. Hela processen kan ta månader. När dina regioner och prenumerationer har migrerats körs nyligen skapade HDInsight-kluster på vm-skalningsuppsättningar utan kundåtgärder. Ingen icke-bakåtkompatibel ändring förväntas.
Inaktualitet
Ingen utfasning i den här versionen.
Funktionalitetsförändringar
Standardklusterversionen ändras till 4.0
Standardversionen av HDInsight-klustret ändras från 3.6 till 4.0. Mer information om tillgängliga versioner finns i tillgängliga versioner. Läs mer om vad som är nytt i HDInsight 4.0.
Standardstorlekar för kluster-VM ändras till Ev3-series
Standardstorlekarna för kluster-VM ändras från D-serien till Ev3-series. Den här ändringen gäller för huvudnoder och arbetsnoder. Om du vill undvika att den här ändringen påverkar dina testade arbetsflöden anger du de VM-storlekar som du vill använda i ARM-mallen.
Nätverksgränssnittsresursen visas inte för kluster som körs på skalningsuppsättningar för virtuella Azure-datorer
HDInsight migreras gradvis till skalningsuppsättningar för virtuella Azure-datorer. Nätverksgränssnitt för virtuella datorer är inte längre synliga för kunder för kluster som använder skalningsuppsättningar för virtuella Azure-datorer.
Kommande ändringar
Följande ändringar sker i kommande versioner.
HDInsight-Interaktiv fråga stöder endast schemabaserad autoskalning
I takt med att kundscenarierna blir mer mogna och olika har vi identifierat vissa begränsningar med Interaktiv fråga (LLAP) belastningsbaserad autoskalning. Dessa begränsningar orsakas av typen av LLAP-frågedynamik, problem med framtida precision för belastningsförutsägelse och problem i LLAP-schemaläggarens uppgiftsdistribution. På grund av dessa begränsningar kan användarna se sina frågor köras långsammare i LLAP-kluster när autoskalning är aktiverat. Prestandapåverkan kan uppväga kostnadsfördelarna med autoskalning.
Från och med juli 2021 stöder Interaktiv fråga-arbetsbelastningen i HDInsight endast schemabaserad autoskalning. Du kan inte längre aktivera autoskalning för nya Interaktiv fråga kluster. Befintliga kluster som körs kan fortsätta att köras med de kända begränsningar som beskrivs ovan.
Microsoft rekommenderar att du flyttar till en schemabaserad autoskalning för LLAP. Du kan analysera klustrets aktuella användningsmönster via Grafana Hive-instrumentpanelen. Mer information finns i Skala Azure HDInsight-kluster automatiskt.
Uppgradering av operativsystemversion
HDInsight-kluster körs för närvarande på Ubuntu 16.04 LTS. Som du refererar till i Ubuntus lanseringscykel kommer Ubuntu 16.04-kerneln att nå End of Life (EOL) i april 2021. Vi börjar lansera den nya HDInsight 4.0-klusteravbildningen som körs på Ubuntu 18.04 i maj 2021. Nyligen skapade HDInsight 4.0-kluster körs på Ubuntu 18.04 som standard när de är tillgängliga. Befintliga kluster på Ubuntu 16.04 körs som de är med fullständigt stöd.
HDInsight 3.6 fortsätter att köras på Ubuntu 16.04. Den kommer att nå slutet av standardsupporten senast den 30 juni 2021 och kommer att ändras till Grundläggande support från och med den 1 juli 2021. Mer information om datum och supportalternativ finns i Azure HDInsight-versioner. Ubuntu 18.04 stöds inte för HDInsight 3.6. Om du vill använda Ubuntu 18.04 måste du migrera dina kluster till HDInsight 4.0.
Du måste släppa och återskapa dina kluster om du vill flytta befintliga kluster till Ubuntu 18.04. Planera att skapa eller återskapa klustret när Ubuntu 18.04-supporten blir tillgänglig. Vi skickar ett nytt meddelande när den nya avbildningen blir tillgänglig i alla regioner.
Vi rekommenderar starkt att du testar dina skriptåtgärder och anpassade program som distribueras på gränsnoder på en virtuell Ubuntu 18.04-dator (VM) i förväg. Du kan skapa en virtuell Ubuntu Linux-dator på 18.04-LTS och sedan skapa och använda ett SSH-nyckelpar (Secure Shell) på den virtuella datorn för att köra och testa dina skriptåtgärder och anpassade program som distribueras på gränsnoder.
Inaktivera Stardard_A5 VM-storlek som huvudnod för HDInsight 4.0
HDInsight-klustrets huvudnod ansvarar för att initiera och hantera klustret. Standard_A5 VM-storlek har tillförlitlighetsproblem som huvudnod för HDInsight 4.0. Från och med nästa version i maj 2021 kommer kunderna inte att kunna skapa nya kluster med Standard_A5 VM-storlek som huvudnod. Du kan använda andra virtuella datorer med två kärnor som E2_v3 eller E2s_v3. Befintliga kluster körs som de är. En virtuell dator med fyra kärnor rekommenderas starkt för Head Node för att säkerställa hög tillgänglighet och tillförlitlighet för dina HDInsight-produktionskluster.
Felkorrigeringar
HDInsight fortsätter att förbättra klustrets tillförlitlighet och prestanda.
Ändring av komponentversion
Stöd har lagts till för Spark 3.0.0 och Kafka 2.4.1 som förhandsversion. Du hittar de aktuella komponentversionerna för HDInsight 4.0 och HDInsight 3.6 i det här dokumentet.
Utgivningsdatum: 2021-02-05
Den här versionen gäller för både HDInsight 3.6 och HDInsight 4.0. HDInsight-versionen görs tillgänglig för alla regioner under flera dagar. Utgivningsdatumet här anger det första regionversionsdatumet. Om du inte ser följande ändringar väntar du tills versionen är live i din region om flera dagar.
Nya funktioner
Stöd för Dav4-serien
HDInsight har lagt till stöd för Dav4-serien i den här versionen. Läs mer om Dav4-serien här.
Kafka REST Proxy GA
Med Kafka REST Proxy kan du interagera med ditt Kafka-kluster via ett REST API via HTTPS. Kafka REST Proxy är allmänt tillgänglig från och med den här versionen. Läs mer om Kafka REST Proxy här.
Flytta till skalningsuppsättningar för virtuella Azure-datorer
HDInsight använder nu virtuella Azure-datorer för att etablera klustret. Tjänsten migreras gradvis till skalningsuppsättningar för virtuella Azure-datorer. Hela processen kan ta månader. När dina regioner och prenumerationer har migrerats körs nyligen skapade HDInsight-kluster på vm-skalningsuppsättningar utan kundåtgärder. Ingen icke-bakåtkompatibel ändring förväntas.
Inaktualitet
Inaktiverade VM-storlekar
Från och med den 9 januari 2021 blockerar HDInsight alla kunder som skapar kluster med hjälp av storlekar för standand_A8, standand_A9, standand_A10 och standand_A11 virtuella datorer. Befintliga kluster körs som de är. Överväg att flytta till HDInsight 4.0 för att undvika eventuella system-/supportavbrott.
Funktionalitetsförändringar
Standardstorleken för kluster-VM ändras till Ev3-series
Vm-standardstorlekarna för kluster ändras från D-serien till Ev3-series. Den här ändringen gäller för huvudnoder och arbetsnoder. Om du vill undvika att den här ändringen påverkar dina testade arbetsflöden anger du de VM-storlekar som du vill använda i ARM-mallen.
Nätverksgränssnittsresursen visas inte för kluster som körs på skalningsuppsättningar för virtuella Azure-datorer
HDInsight migreras gradvis till skalningsuppsättningar för virtuella Azure-datorer. Nätverksgränssnitt för virtuella datorer är inte längre synliga för kunder för kluster som använder skalningsuppsättningar för virtuella Azure-datorer.
Kommande ändringar
Följande ändringar sker i kommande versioner.
Standardklusterversionen ändras till 4.0
Från och med februari 2021 ändras standardversionen av HDInsight-klustret från 3.6 till 4.0. Mer information om tillgängliga versioner finns i tillgängliga versioner. Läs mer om vad som är nytt i HDInsight 4.0.
Uppgradering av operativsystemversion
HDInsight uppgraderar os-versionen från Ubuntu 16.04 till 18.04. Uppgraderingen slutförs före april 2021.
HDInsight 3.6 upphör den 30 juni 2021
HDInsight 3.6 upphör med supporten. Från och med den 30 juni 2021 kan kunderna inte skapa nya HDInsight 3.6-kluster. Befintliga kluster körs som de är utan stöd från Microsoft. Överväg att flytta till HDInsight 4.0 för att undvika eventuella system-/supportavbrott.
Ändring av komponentversion
Ingen komponentversionsändring för den här versionen. Du hittar de aktuella komponentversionerna för HDInsight 4.0 och HDInsight 3.6 i det här dokumentet.
Utgivningsdatum: 2020-01-18
Den här versionen gäller för både HDInsight 3.6 och HDInsight 4.0. HDInsight-versionen görs tillgänglig för alla regioner under flera dagar. Utgivningsdatumet här anger det första regionversionsdatumet. Om du inte ser följande ändringar väntar du tills versionen är live i din region om flera dagar.
Nya funktioner
Automatisk nyckelrotation för kundhanterad nyckelkryptering i vila
Från och med den här versionen kan kunder använda Azure KeyValut versionslösa url:er för krypteringsnycklar för kundhanterad nyckelkryptering i vila. HDInsight roterar automatiskt nycklarna när de upphör att gälla eller ersätts med nya versioner. Läs mer här.
Möjlighet att välja olika storlekar på virtuella Zookeeper-datorer för Spark-, Hadoop- och ML-tjänster
HDInsight har tidigare inte stöd för anpassning av Zookeeper-nodstorlek för klustertyperna Spark, Hadoop och ML Services. Standardvärdet är A2_v2/A2 virtuella datorstorlekar, som tillhandahålls kostnadsfritt. I den här versionen kan du välja en zookeeper-storlek för virtuella datorer som passar bäst för ditt scenario. Zookeeper-noder med en annan storlek på den virtuella datorn än A2_v2/A2 debiteras. A2_v2 och virtuella A2-datorer tillhandahålls fortfarande kostnadsfritt.
Flytta till skalningsuppsättningar för virtuella Azure-datorer
HDInsight använder nu virtuella Azure-datorer för att etablera klustret. Från och med den här versionen migreras tjänsten gradvis till skalningsuppsättningar för virtuella Azure-datorer. Hela processen kan ta månader. När dina regioner och prenumerationer har migrerats körs nyligen skapade HDInsight-kluster på vm-skalningsuppsättningar utan kundåtgärder. Ingen icke-bakåtkompatibel ändring förväntas.
Inaktualitet
Utfasning av HDInsight 3.6 ML Services-kluster
HDInsight 3.6 ML Services-klustertypen upphör senast den 31 december 2020. Kunder kommer inte att kunna skapa nya 3,6 ML Services-kluster efter den 31 december 2020. Befintliga kluster körs som de är utan stöd från Microsoft. Kontrollera att stödet upphör att gälla för HDInsight-versioner och klustertyper här.
Inaktiverade VM-storlekar
Från och med den 16 november 2020 blockerar HDInsight nya kunder som skapar kluster med hjälp av standand_A8, standand_A9, standand_A10 och standand_A11 VM-storlekar. Befintliga kunder som har använt dessa VM-storlekar under de senaste tre månaderna påverkas inte. Från och med den 9 januari 2021 blockerar HDInsight alla kunder som skapar kluster med hjälp av storlekar för standand_A8, standand_A9, standand_A10 och standand_A11 virtuella datorer. Befintliga kluster körs som de är. Överväg att flytta till HDInsight 4.0 för att undvika eventuella system-/supportavbrott.
Funktionalitetsförändringar
Lägg till NSG-regelkontroll före skalningsåtgärd
HDInsight har lagt till nätverkssäkerhetsgrupper (NSG:er) och användardefinierade vägar (UDR) som kontrollerar med skalningsåtgärden. Samma validering görs för klusterskalning förutom när klustret skapas. Den här valideringen hjälper till att förhindra oförutsägbara fel. Om valideringen inte godkänns misslyckas skalningen. Mer information om hur du konfigurerar NSG:er och UDR:er på rätt sätt finns i IP-adresser för HDInsight-hantering.
Ändring av komponentversion
Ingen komponentversionsändring för den här versionen. Du hittar de aktuella komponentversionerna för HDInsight 4.0 och HDInsight 3.6 i det här dokumentet.
Utgivningsdatum: 2020-09-09
Den här versionen gäller för både HDInsight 3.6 och HDInsight 4.0. HDInsight-versionen görs tillgänglig för alla regioner under flera dagar. Utgivningsdatumet här anger det första regionversionsdatumet. Om du inte ser följande ändringar väntar du tills versionen är live i din region om flera dagar.
Nya funktioner
HDInsight Identity Broker (HIB) är nu GA
HDInsight Identity Broker (HIB) som aktiverar OAuth-autentisering för ESP-kluster är nu allmänt tillgängligt med den här versionen. HIB-kluster som skapas efter den här versionen har de senaste HIB-funktionerna:
- Hög tillgänglighet (HA)
- Stöd för multifaktorautentisering (MFA)
- Federerade användare loggar in utan synkronisering av lösenordshash till AAD-DS Mer information finns i HIB-dokumentationen.
Flytta till skalningsuppsättningar för virtuella Azure-datorer
HDInsight använder nu virtuella Azure-datorer för att etablera klustret. Från och med den här versionen migreras tjänsten gradvis till skalningsuppsättningar för virtuella Azure-datorer. Hela processen kan ta månader. När dina regioner och prenumerationer har migrerats körs nyligen skapade HDInsight-kluster på vm-skalningsuppsättningar utan kundåtgärder. Ingen icke-bakåtkompatibel ändring förväntas.
Inaktualitet
Utfasning av HDInsight 3.6 ML Services-kluster
HDInsight 3.6 ML Services-klustertypen upphör senast den 31 december 2020. Kunderna skapar inte nya 3,6 ML Services-kluster efter den 31 december 2020. Befintliga kluster körs som de är utan stöd från Microsoft. Kontrollera att stödet upphör att gälla för HDInsight-versioner och klustertyper här.
Inaktiverade VM-storlekar
Från och med den 16 november 2020 blockerar HDInsight nya kunder som skapar kluster med hjälp av standand_A8, standand_A9, standand_A10 och standand_A11 VM-storlekar. Befintliga kunder som har använt dessa VM-storlekar under de senaste tre månaderna påverkas inte. Från och med den 9 januari 2021 blockerar HDInsight alla kunder som skapar kluster med hjälp av storlekar för standand_A8, standand_A9, standand_A10 och standand_A11 virtuella datorer. Befintliga kluster körs som de är. Överväg att flytta till HDInsight 4.0 för att undvika eventuella system-/supportavbrott.
Funktionalitetsförändringar
Ingen beteendeförändring för den här versionen.
Kommande ändringar
Följande ändringar sker i kommande versioner.
Möjlighet att välja olika storlekar på virtuella Zookeeper-datorer för Spark-, Hadoop- och ML-tjänster
HDInsight stöder idag inte anpassning av Zookeeper-nodstorleken för klustertyperna Spark, Hadoop och ML Services. Standardvärdet är A2_v2/A2 virtuella datorstorlekar, som tillhandahålls kostnadsfritt. I den kommande versionen kan du välja en storlek på en virtuell Zookeeper-dator som passar bäst för ditt scenario. Zookeeper-noder med en annan storlek på den virtuella datorn än A2_v2/A2 debiteras. A2_v2 och virtuella A2-datorer tillhandahålls fortfarande kostnadsfritt.
Standardklusterversionen ändras till 4.0
Från och med februari 2021 ändras standardversionen av HDInsight-klustret från 3.6 till 4.0. Mer information om tillgängliga versioner finns i versioner som stöds. Läs mer om vad som är nytt i HDInsight 4.0
HDInsight 3.6 upphör den 30 juni 2021
HDInsight 3.6 upphör med supporten. Från och med den 30 juni 2021 kan kunderna inte skapa nya HDInsight 3.6-kluster. Befintliga kluster körs som de är utan stöd från Microsoft. Överväg att flytta till HDInsight 4.0 för att undvika eventuella system-/supportavbrott.
Felkorrigeringar
HDInsight fortsätter att förbättra klustrets tillförlitlighet och prestanda.
Åtgärda problem med att starta om virtuella datorer i klustret
Problemet med att starta om virtuella datorer i klustret har åtgärdats. Du kan använda PowerShell eller REST API för att starta om noder i klustret igen.
Ändring av komponentversion
Ingen komponentversionsändring för den här versionen. Du hittar de aktuella komponentversionerna för HDInsight 4.0 och HDInsight 3.6 i det här dokumentet.
Utgivningsdatum: 2020-08-08
Den här versionen gäller för både HDInsight 3.6 och HDInsight 4.0. HDInsight-versionen görs tillgänglig för alla regioner under flera dagar. Utgivningsdatumet här anger det första regionversionsdatumet. Om du inte ser följande ändringar väntar du tills versionen är live i din region om flera dagar.
Nya funktioner
Privata HDInsight-kluster utan offentlig IP-adress och privat länk (förhandsversion)
HDInsight har nu stöd för att skapa kluster utan offentlig IP-adress och åtkomst till privata länkar till klustren i förhandsversionen. Kunder kan använda de nya avancerade nätverksinställningarna för att skapa ett helt isolerat kluster utan offentlig IP-adress och använda sina egna privata slutpunkter för att komma åt klustret.
Flytta till skalningsuppsättningar för virtuella Azure-datorer
HDInsight använder nu virtuella Azure-datorer för att etablera klustret. Från och med den här versionen migreras tjänsten gradvis till skalningsuppsättningar för virtuella Azure-datorer. Hela processen kan ta månader. När dina regioner och prenumerationer har migrerats körs nyligen skapade HDInsight-kluster på vm-skalningsuppsättningar utan kundåtgärder. Ingen icke-bakåtkompatibel ändring förväntas.
Inaktualitet
Utfasning av HDInsight 3.6 ML Services-kluster
HDInsight 3.6 ML Services-klustertypen upphör senast den 31 december 2020. Kunderna skapar inte nya 3.6 ML Services-kluster efter det. Befintliga kluster körs som de är utan stöd från Microsoft. Kontrollera att stödet upphör att gälla för HDInsight-versioner och klustertyper här.
Funktionalitetsförändringar
Ingen beteendeförändring för den här versionen.
Kommande ändringar
Följande ändringar sker i kommande versioner.
Möjlighet att välja olika storlekar på virtuella Zookeeper-datorer för Spark-, Hadoop- och ML-tjänster
HDInsight stöder idag inte anpassning av Zookeeper-nodstorleken för klustertyperna Spark, Hadoop och ML Services. Standardvärdet är A2_v2/A2 virtuella datorstorlekar, som tillhandahålls kostnadsfritt. I den kommande versionen kan du välja en storlek på en virtuell Zookeeper-dator som passar bäst för ditt scenario. Zookeeper-noder med en annan storlek på den virtuella datorn än A2_v2/A2 debiteras. A2_v2 och virtuella A2-datorer tillhandahålls fortfarande kostnadsfritt.
Felkorrigeringar
HDInsight fortsätter att förbättra klustrets tillförlitlighet och prestanda.
Ändring av komponentversion
Ingen komponentversionsändring för den här versionen. Du hittar de aktuella komponentversionerna för HDInsight 4.0 och HDInsight 3.6 i det här dokumentet.
Utgivningsdatum: 2020-09-28
Den här versionen gäller för både HDInsight 3.6 och HDInsight 4.0. HDInsight-versionen görs tillgänglig för alla regioner under flera dagar. Utgivningsdatumet här anger det första regionversionsdatumet. Om du inte ser följande ändringar väntar du tills versionen är live i din region om flera dagar.
Nya funktioner
Autoskalning för Interaktiv fråga med HDInsight 4.0 är nu allmänt tillgänglig
Automatisk skalning för Interaktiv fråga klustertyp är nu allmänt tillgänglig (GA) för HDInsight 4.0. Alla Interaktiv fråga 4.0-kluster som skapats efter den 27 augusti 2020 har GA-stöd för automatisk skalning.
HBase-kluster stöder Premium ADLS Gen2
HDInsight stöder nu Premium ADLS Gen2 som primärt lagringskonto för HDInsight HBase 3.6- och 4.0-kluster. Tillsammans med accelererade skrivningar kan du få bättre prestanda för dina HBase-kluster.
Kafka-partitionsdistribution på Azure-feldomäner
En feldomän är en logisk gruppering av underliggande maskinvara i ett Azure-datacenter. Varje feldomän delar en gemensam strömkälla och nätverksbrytare. Innan HDInsight Kafka kan lagra alla partitionsrepliker i samma feldomän. Från och med den här versionen stöder HDInsight nu automatiskt distribution av Kafka-partitioner baserat på Azure-feldomäner.
Kryptering vid överföring
Kunder kan aktivera kryptering under överföring mellan klusternoder med IPSec-kryptering med plattformshanterade nycklar. Det här alternativet kan aktiveras när klustret skapas. Se mer information om hur du aktiverar kryptering under överföring.
Kryptering på värden
När du aktiverar kryptering på värden krypteras data som lagras på den virtuella datorvärden i vila och flöden krypteras till lagringstjänsten. Från den här versionen kan du aktivera kryptering på värden på temporär datadisk när du skapar klustret. Kryptering på värden stöds endast på vissa VM-SKU:er i begränsade regioner. HDInsight stöder följande nodkonfiguration och SKU:er. Se mer information om hur du aktiverar kryptering på värden.
Flytta till skalningsuppsättningar för virtuella Azure-datorer
HDInsight använder nu virtuella Azure-datorer för att etablera klustret. Från och med den här versionen migreras tjänsten gradvis till skalningsuppsättningar för virtuella Azure-datorer. Hela processen kan ta månader. När dina regioner och prenumerationer har migrerats körs nyligen skapade HDInsight-kluster på vm-skalningsuppsättningar utan kundåtgärder. Ingen icke-bakåtkompatibel ändring förväntas.
Inaktualitet
Ingen utfasning för den här versionen.
Funktionalitetsförändringar
Ingen beteendeförändring för den här versionen.
Kommande ändringar
Följande ändringar sker i kommande versioner.
Möjlighet att välja olika Zookeeper SKU för Spark-, Hadoop- och ML-tjänster
HDInsight har idag inte stöd för att ändra klustertyperna Zookeeper SKU för Spark, Hadoop och ML Services. Den använder A2_v2/A2 SKU för Zookeeper-noder och kunderna debiteras inte för dem. I den kommande versionen kan kunder ändra Zookeeper SKU för Spark-, Hadoop- och ML-tjänster efter behov. Zookeeper-noder med annan SKU än A2_v2/A2 debiteras. Standard-SKU:n är fortfarande A2_V2/A2 och kostnadsfritt.
Felkorrigeringar
HDInsight fortsätter att förbättra klustrets tillförlitlighet och prestanda.
Ändring av komponentversion
Ingen komponentversionsändring för den här versionen. Du hittar de aktuella komponentversionerna för HDInsight 4.0 och HDInsight 3.6 i det här dokumentet.
Utgivningsdatum: 2020-08-09
Den här versionen gäller endast för HDInsight 4.0. HDInsight-versionen görs tillgänglig för alla regioner under flera dagar. Utgivningsdatumet här anger det första regionversionsdatumet. Om du inte ser följande ändringar väntar du tills versionen är live i din region om flera dagar.
Nya funktioner
Stöd för SparkCruise
SparkCruise är ett system för automatisk återanvändning av beräkningar för Spark. Den väljer vanliga underuttryck att materialisera baserat på den tidigare frågearbetsbelastningen. SparkCruise materialiserar dessa underuttryck som en del av frågebearbetning och återanvändning av beräkningar tillämpas automatiskt i bakgrunden. Du kan dra nytta av SparkCruise utan att ändra Spark-koden.
Stöd för Hive View för HDInsight 4.0
Apache Ambari Hive View är utformad för att hjälpa dig att skapa, optimera och köra Hive-frågor från webbläsaren. Hive View stöds internt för HDInsight 4.0-kluster från och med den här versionen. Det gäller inte för befintliga kluster. Du behöver släppa och återskapa klustret för att få den inbyggda Hive-vyn.
Stöd för Tez-vy för HDInsight 4.0
Apache Tez-vyn används för att spåra och felsöka körningen av Hive Tez-jobbet. Tez-vyn stöds internt för HDInsight 4.0 från och med den här versionen. Det gäller inte för befintliga kluster. Du måste släppa och återskapa klustret för att få den inbyggda Tez-vyn.
Inaktualitet
Utfasning av Spark 2.1 och 2.2 i HDInsight 3.6 Spark-kluster
Från och med den 1 juli 2020 kan kunderna inte skapa nya Spark-kluster med Spark 2.1 och 2.2 på HDInsight 3.6. Befintliga kluster körs som de är utan stöd från Microsoft. Överväg att flytta till Spark 2.3 på HDInsight 3.6 senast den 30 juni 2020 för att undvika eventuella system-/supportavbrott.
Utfasning av Spark 2.3 i HDInsight 4.0 Spark-kluster
Från och med den 1 juli 2020 kan kunderna inte skapa nya Spark-kluster med Spark 2.3 på HDInsight 4.0. Befintliga kluster körs som de är utan stöd från Microsoft. Överväg att flytta till Spark 2.4 på HDInsight 4.0 den 30 juni 2020 för att undvika potentiella system-/supportavbrott.
Utfasning av Kafka 1.1 i HDInsight 4.0 Kafka-kluster
Från och med den 1 juli 2020 kommer kunderna inte att kunna skapa nya Kafka-kluster med Kafka 1.1 på HDInsight 4.0. Befintliga kluster körs som de är utan stöd från Microsoft. Överväg att flytta till Kafka 2.1 på HDInsight 4.0 den 30 juni 2020 för att undvika potentiella system-/supportavbrott.
Funktionalitetsförändringar
Ändring av Ambari-stackversion
I den här versionen ändras Ambari-versionen från 2.x.x.x till 4.1. Du kan verifiera stackversionen (HDInsight 4.1) i Ambari: Ambari-användarversioner >> .
Kommande ändringar
Inga kommande icke-bakåtkompatibla ändringar som du behöver vara uppmärksam på.
Felkorrigeringar
HDInsight fortsätter att förbättra klustrets tillförlitlighet och prestanda.
Nedan är JIRA:erna tillbaka portade för Hive:
Nedan är JIRA:erna tillbaka portade för HBase:
Ändring av komponentversion
Ingen komponentversionsändring för den här versionen. Du hittar de aktuella komponentversionerna för HDInsight 4.0 och HDInsight 3.6 i det här dokumentet.
Kända problem
Ett problem har åtgärdats i Azure-portalen, där användarna fick ett fel när de skapade ett Azure HDInsight-kluster med hjälp av en SSH-autentiseringstyp av offentlig nyckel. När användarna klickade på Granska + skapa får de felet "Får inte innehålla tre tecken i följd från SSH-användarnamnet". Det här problemet har åtgärdats, men det kan kräva att du uppdaterar webbläsarens cacheminne genom att trycka på CTRL + F5 för att läsa in den korrigerade vyn. Lösningen på det här problemet var att skapa ett kluster med en ARM-mall.
Utgivningsdatum: 2020-07-13
Den här versionen gäller både för HDInsight 3.6 och 4.0. HDInsight-versionen görs tillgänglig för alla regioner under flera dagar. Utgivningsdatumet här anger det första regionversionsdatumet. Om du inte ser följande ändringar väntar du tills versionen är live i din region om flera dagar.
Nya funktioner
Support för Customer Lockbox för Microsoft Azure
Azure HDInsight har nu stöd för Azure Customer Lockbox. Det ger ett gränssnitt för kunder att granska och godkänna eller avvisa begäranden om åtkomst till kunddata. Den används när Microsofts tekniker behöver komma åt kunddata under en supportbegäran. Mer information finns i Customer Lockbox för Microsoft Azure.
Tjänstslutpunktsprinciper för lagring
Kunder kan nu använda tjänstslutpunktsprinciper (SEP) i HDInsight-klustrets undernät. Läs mer om azure-tjänstslutpunktsprincip.
Inaktualitet
Utfasning av Spark 2.1 och 2.2 i HDInsight 3.6 Spark-kluster
Från och med den 1 juli 2020 kan kunderna inte skapa nya Spark-kluster med Spark 2.1 och 2.2 på HDInsight 3.6. Befintliga kluster körs som de är utan stöd från Microsoft. Överväg att flytta till Spark 2.3 på HDInsight 3.6 senast den 30 juni 2020 för att undvika eventuella system-/supportavbrott.
Utfasning av Spark 2.3 i HDInsight 4.0 Spark-kluster
Från och med den 1 juli 2020 kan kunderna inte skapa nya Spark-kluster med Spark 2.3 på HDInsight 4.0. Befintliga kluster körs som de är utan stöd från Microsoft. Överväg att flytta till Spark 2.4 på HDInsight 4.0 den 30 juni 2020 för att undvika potentiella system-/supportavbrott.
Utfasning av Kafka 1.1 i HDInsight 4.0 Kafka-kluster
Från och med den 1 juli 2020 kommer kunderna inte att kunna skapa nya Kafka-kluster med Kafka 1.1 på HDInsight 4.0. Befintliga kluster körs som de är utan stöd från Microsoft. Överväg att flytta till Kafka 2.1 på HDInsight 4.0 den 30 juni 2020 för att undvika potentiella system-/supportavbrott.
Funktionalitetsförändringar
Inga beteendeändringar du behöver vara uppmärksam på.
Kommande ändringar
Följande ändringar sker i kommande versioner.
Möjlighet att välja olika Zookeeper SKU för Spark-, Hadoop- och ML-tjänster
HDInsight har idag inte stöd för att ändra klustertyperna Zookeeper SKU för Spark, Hadoop och ML Services. Den använder A2_v2/A2 SKU för Zookeeper-noder och kunderna debiteras inte för dem. I den kommande versionen kommer kunderna att kunna ändra Zookeeper SKU för Spark, Hadoop och ML Services efter behov. Zookeeper-noder med annan SKU än A2_v2/A2 debiteras. Standard-SKU:n är fortfarande A2_V2/A2 och kostnadsfritt.
Felkorrigeringar
HDInsight fortsätter att förbättra klustrets tillförlitlighet och prestanda.
Problem med Hive Warehouse-Anslut eller har åtgärdats
Det uppstod ett problem för användning av Hive Warehouse-anslutningsappen i den tidigare versionen. Problemet har åtgärdats.
Zeppelin-anteckningsboken trunkerar inledande nollor har åtgärdats
Zeppelin trunkerade felaktigt inledande nollor i tabellutdata för Strängformat. Vi har åtgärdat det här problemet i den här versionen.
Ändring av komponentversion
Ingen komponentversionsändring för den här versionen. Du hittar de aktuella komponentversionerna för HDInsight 4.0 och HDInsight 3.6 i det här dokumentet.
Utgivningsdatum: 2020-06-11
Den här versionen gäller både för HDInsight 3.6 och 4.0. HDInsight-versionen görs tillgänglig för alla regioner under flera dagar. Utgivningsdatumet här anger det första regionversionsdatumet. Om du inte ser följande ändringar väntar du tills versionen är live i din region om flera dagar.
Nya funktioner
Flytta till skalningsuppsättningar för virtuella Azure-datorer
HDInsight använder virtuella Azure-datorer för att etablera klustret nu. Från den här versionen börjar nya HDInsight-kluster använda skalningsuppsättningen för virtuella Azure-datorer. Förändringen lanseras gradvis. Du bör inte förvänta dig någon icke-bakåtkompatibel ändring. Läs mer om skalningsuppsättningar för virtuella Azure-datorer.
Starta om virtuella datorer i HDInsight-kluster
I den här versionen stöder vi omstart av virtuella datorer i HDInsight-kluster för att starta om noder som inte svarar. För närvarande kan du bara göra det via API, PowerShell och CLI-stöd är på väg. Mer information om API :et finns i det här dokumentet.
Inaktualitet
Utfasning av Spark 2.1 och 2.2 i HDInsight 3.6 Spark-kluster
Från och med den 1 juli 2020 kan kunderna inte skapa nya Spark-kluster med Spark 2.1 och 2.2 på HDInsight 3.6. Befintliga kluster körs som de är utan stöd från Microsoft. Överväg att flytta till Spark 2.3 på HDInsight 3.6 senast den 30 juni 2020 för att undvika eventuella system-/supportavbrott.
Utfasning av Spark 2.3 i HDInsight 4.0 Spark-kluster
Från och med den 1 juli 2020 kan kunderna inte skapa nya Spark-kluster med Spark 2.3 på HDInsight 4.0. Befintliga kluster körs som de är utan stöd från Microsoft. Överväg att flytta till Spark 2.4 på HDInsight 4.0 den 30 juni 2020 för att undvika potentiella system-/supportavbrott.
Utfasning av Kafka 1.1 i HDInsight 4.0 Kafka-kluster
Från och med den 1 juli 2020 kommer kunderna inte att kunna skapa nya Kafka-kluster med Kafka 1.1 på HDInsight 4.0. Befintliga kluster körs som de är utan stöd från Microsoft. Överväg att flytta till Kafka 2.1 på HDInsight 4.0 den 30 juni 2020 för att undvika potentiella system-/supportavbrott.
Funktionalitetsförändringar
Storleksändring för ESP Spark-klusterhuvudnod
Minsta tillåtna huvudnodstorlek för ESP Spark-kluster ändras till Standard_D13_V2. Virtuella datorer med låg kärnor och minne som huvudnod kan orsaka PROBLEM med ESP-kluster på grund av relativt låg processor- och minneskapacitet. Från och med lanseringen använder du SKU:er som är högre än Standard_D13_V2 och Standard_E16_V3 som huvudnod för ESP Spark-kluster.
En virtuell dator med minst 4 kärnor krävs för huvudnoden
En virtuell dator med minst 4 kärnor krävs för head node för att säkerställa hög tillgänglighet och tillförlitlighet för HDInsight-kluster. Från och med den 6 april 2020 kan kunderna bara välja en virtuell dator med 4 kärnor eller högre som huvudnod för de nya HDInsight-klustren. Befintliga kluster kommer att fortsätta köras som förväntat.
Nodetableringsändring för klusterarbetare
När 80 % av arbetsnoderna är klara går klustret in i driftfasen. I det här skedet kan kunder utföra alla dataplansåtgärder som att köra skript och jobb. Men kunder kan inte utföra någon kontrollplansåtgärd som att skala upp/ned. Endast borttagning stöds.
Efter driftfasen väntar klustret ytterligare 60 minuter på de återstående 20 % arbetsnoderna. I slutet av den här 60-minutersperioden flyttas klustret till körningsfasen , även om alla arbetsnoder fortfarande inte är tillgängliga. När ett kluster har körts kan du använda det som vanligt. Både kontrollplansåtgärder som att skala upp/ned och dataplansåtgärder som att köra skript och jobb accepteras. Om vissa av de begärda arbetsnoderna inte är tillgängliga markeras klustret som delvis lyckat. Du debiteras för de noder som har distribuerats.
Skapa nytt huvudnamn för tjänsten via HDInsight
Tidigare, när klustret skapades, kan kunderna skapa ett nytt huvudnamn för tjänsten för att få åtkomst till det anslutna ADLS Gen 1-kontot i Azure-portalen. Från och med den 15 juni 2020 är det inte möjligt att skapa det nya tjänstens huvudnamn i arbetsflödet för att skapa HDInsight. Endast befintligt huvudnamn för tjänsten stöds. Se Skapa tjänstens huvudnamn och certifikat med Hjälp av Azure Active Directory.
Tidsgräns för skriptåtgärder när kluster skapas
HDInsight har stöd för att köra skriptåtgärder med klusterskapande. Från den här versionen måste alla skriptåtgärder med klusterskapande slutföras inom 60 minuter, annars överskrids tidsgränsen. Skriptåtgärder som skickas till kluster som körs påverkas inte. Läs mer här.
Kommande ändringar
Inga kommande icke-bakåtkompatibla ändringar som du behöver vara uppmärksam på.
Felkorrigeringar
HDInsight fortsätter att förbättra klustrets tillförlitlighet och prestanda.
Ändring av komponentversion
HBase 2.0 till 2.1.6
HBase-versionen uppgraderas från version 2.0 till 2.1.6.
Spark 2.4.0 till 2.4.4
Spark-versionen uppgraderas från version 2.4.0 till 2.4.4.
Kafka 2.1.0 till 2.1.1
Kafka-versionen uppgraderas från version 2.1.0 till 2.1.1.
Du hittar de aktuella komponentversionerna för HDInsight 4.0 ad HDInsight 3.6 i det här dokumentet
Kända problem
Problem med Hive Warehouse Anslut eller
Det finns ett problem för Hive Warehouse Anslut eller i den här versionen. Korrigeringen tas med i nästa version. Befintliga kluster som skapats före den här versionen påverkas inte. Undvik att släppa och återskapa klustret om det är möjligt. Öppna supportärende om du behöver ytterligare hjälp med detta.
Utgivningsdatum: 2020-01-09
Den här versionen gäller både för HDInsight 3.6 och 4.0. HDInsight-versionen görs tillgänglig för alla regioner under flera dagar. Utgivningsdatumet här anger det första regionversionsdatumet. Om du inte ser följande ändringar väntar du tills versionen är live i din region om flera dagar.
Nya funktioner
Tvingande TLS 1.2
Transport Layer Security (TLS) och Secure Sockets Layer (SSL) är kryptografiska protokoll som ger kommunikationssäkerhet över ett datornätverk. Läs mer om TLS. HDInsight använder TLS 1.2 på offentliga HTTP-slutpunkter, men TLS 1.1 stöds fortfarande för bakåtkompatibilitet.
Med den här versionen kan kunder välja TLS 1.2 endast för alla anslutningar via den offentliga klusterslutpunkten. För att stödja detta introduceras den nya egenskapen minSupportedTlsVersion och kan anges när klustret skapas. Om egenskapen inte har angetts stöder klustret fortfarande TLS 1.0, 1.1 och 1.2, vilket är samma sak som dagens beteende. Kunder kan ange värdet för den här egenskapen till "1.2", vilket innebär att klustret endast stöder TLS 1.2 och senare. Mer information finns i Transport Layer Security.
Ta med din egen nyckel för diskkryptering
Alla hanterade diskar i HDInsight skyddas med Azure Storage Service Encryption (SSE). Data på dessa diskar krypteras av Microsoft-hanterade nycklar som standard. Från och med den här versionen kan du använda BYOK (Bring Your Own Key) för diskkryptering och hantera den med hjälp av Azure Key Vault. BYOK-kryptering är en konfiguration i ett steg när klustret skapas utan någon annan kostnad. Registrera bara HDInsight som en hanterad identitet med Azure Key Vault och lägg till krypteringsnyckeln när du skapar klustret. Mer information finns i Diskkryptering av kundhanterad nyckel.
Inaktualitet
Inga utfasningar för den här versionen. Information om hur du gör dig redo för kommande utfasningar finns i Kommande ändringar.
Funktionalitetsförändringar
Inga beteendeändringar för den här versionen. Information om hur du gör dig redo för kommande ändringar finns i Kommande ändringar.
Kommande ändringar
Följande ändringar sker i kommande versioner.
Utfasning av Spark 2.1 och 2.2 i HDInsight 3.6 Spark-kluster
Från och med den 1 juli 2020 kommer kunderna inte att kunna skapa nya Spark-kluster med Spark 2.1 och 2.2 i HDInsight 3.6. Befintliga kluster kommer att köras i befintligt skick utan stöd från Microsoft. Överväg att flytta till Spark 2.3 på HDInsight 3.6 den 30 juni 2020 för att undvika potentiella system-/supportavbrott.
Utfasning av Spark 2.3 i HDInsight 4.0 Spark-kluster
Från och med den 1 juli 2020 kommer kunderna inte att kunna skapa nya Spark-kluster med Spark 2.3 i HDInsight 4.0. Befintliga kluster kommer att köras i befintligt skick utan stöd från Microsoft. Överväg att flytta till Spark 2.4 på HDInsight 4.0 den 30 juni 2020 för att undvika potentiella system-/supportavbrott.
Utfasning av Kafka 1.1 i HDInsight 4.0 Kafka-kluster
Från och med den 1 juli 2020 kommer kunderna inte att kunna skapa nya Kafka-kluster med Kafka 1.1 på HDInsight 4.0. Befintliga kluster kommer att köras i befintligt skick utan stöd från Microsoft. Överväg att flytta till Kafka 2.1 på HDInsight 4.0 den 30 juni 2020 för att undvika potentiella system-/supportavbrott. För mer information, se Migrera Apache Kafka-arbetsbelastningar till Azure HDInsight 4.0.
HBase 2.0 till 2.1.6
I den kommande versionen av HDInsight 4.0 uppgraderas HBase-versionen från version 2.0 till 2.1.6
Spark 2.4.0 till 2.4.4
I den kommande versionen av HDInsight 4.0 uppgraderas Spark-versionen från version 2.4.0 till 2.4.4
Kafka 2.1.0 till 2.1.1
I den kommande versionen av HDInsight 4.0 uppgraderas Kafka-versionen från version 2.1.0 till 2.1.1
En virtuell dator med minst 4 kärnor krävs för huvudnoden
En virtuell dator med minst 4 kärnor krävs för head node för att säkerställa hög tillgänglighet och tillförlitlighet för HDInsight-kluster. Från och med den 6 april 2020 kan kunderna bara välja en virtuell dator med 4 kärnor eller högre som huvudnod för de nya HDInsight-klustren. Befintliga kluster kommer att fortsätta köras som förväntat.
Ändra storlek på ESP Spark-klusternoder
I den kommande versionen ändras den minsta tillåtna nodstorleken för ESP Spark-klustret till Standard_D13_V2. Virtuella datorer i en serie kan orsaka PROBLEM med ESP-kluster på grund av relativt låg processor- och minneskapacitet. Virtuella datorer i A-serien kommer att bli inaktuella för att skapa nya ESP-kluster.
Flytta till skalningsuppsättningar för virtuella Azure-datorer
HDInsight använder nu virtuella Azure-datorer för att etablera klustret. I den kommande versionen använder HDInsight skalningsuppsättningar för virtuella Azure-datorer i stället. Läs mer om skalningsuppsättningar för virtuella Azure-datorer.
Felkorrigeringar
HDInsight fortsätter att förbättra klustrets tillförlitlighet och prestanda.
Ändring av komponentversion
Ingen komponentversionsändring för den här versionen. Du hittar de aktuella komponentversionerna för HDInsight 4.0 ad HDInsight 3.6 här.
Utgivningsdatum: 2019-12-17
Den här versionen gäller både för HDInsight 3.6 och 4.0.
Nya funktioner
Tjänsttaggar
Tjänsttaggar förenklar säkerheten för virtuella Azure-datorer och virtuella Azure-nätverk genom att du enkelt kan begränsa nätverksåtkomsten till Azure-tjänsterna. Du kan använda tjänsttaggar i nätverkssäkerhetsgruppens regler (NSG) för att tillåta eller neka trafik till en specifik Azure-tjänst globalt eller per Azure-region. Azure tillhandahåller underhåll av IP-adresser som ligger till grund för varje tagg. HDInsight-tjänsttaggar för nätverkssäkerhetsgrupper (NSG:er) är grupper med IP-adresser för hälso- och hanteringstjänster. Dessa grupper hjälper till att minimera komplexiteten för skapande av säkerhetsregler. HDInsight-kunder kan aktivera tjänsttagg via Azure-portalen, PowerShell och REST API. Mer information finns i Tjänsttaggar för nätverkssäkerhetsgrupp (NSG) för Azure HDInsight.
Anpassad Ambari-databas
Med HDInsight kan du nu använda din egen SQL DB för Apache Ambari. Du kan konfigurera den här anpassade Ambari DB från Azure-portalen eller via Resource Manager-mallen. Med den här funktionen kan du välja rätt SQL DB för dina bearbetnings- och kapacitetsbehov. Du kan också uppgradera enkelt för att matcha kraven på affärstillväxt. Mer information finns i Konfigurera HDInsight-kluster med en anpassad Ambari DB.

Inaktualitet
Inga utfasningar för den här versionen. Information om hur du gör dig redo för kommande utfasningar finns i Kommande ändringar.
Funktionalitetsförändringar
Inga beteendeändringar för den här versionen. Information om hur du gör dig redo för kommande beteendeändringar finns i Kommande ändringar.
Kommande ändringar
Följande ändringar sker i kommande versioner.
TLS (Transport Layer Security) 1.2-tillämpning
Transport Layer Security (TLS) och Secure Sockets Layer (SSL) är kryptografiska protokoll som ger kommunikationssäkerhet över ett datornätverk. Mer information finns i Transport Layer Security. Azure HDInsight-kluster accepterar TLS 1.2-anslutningar på offentliga HTTPS-slutpunkter, men TLS 1.1 stöds fortfarande för bakåtkompatibilitet med äldre klienter.
Från och med nästa version kan du välja att använda och konfigurera dina nya HDInsight-kluster så att de endast accepterar TLS 1.2-anslutningar.
Senare under året, från och med 2020-06-30, tillämpar Azure HDInsight TLS 1.2 eller senare versioner för alla HTTPS-anslutningar. Kontrollera att alla dina klienter kan hantera TLS 1.2 eller senare versioner.
Flytta till skalningsuppsättningar för virtuella Azure-datorer
HDInsight använder nu virtuella Azure-datorer för att etablera klustret. Från och med februari 2020 (exakt datum meddelas senare) använder HDInsight skalningsuppsättningar för virtuella Azure-datorer i stället. Läs mer om skalningsuppsättningar för virtuella Azure-datorer.
Ändra storlek på ESP Spark-klusternoder
I den kommande versionen:
- Den minsta tillåtna nodstorleken för ESP Spark-klustret ändras till Standard_D13_V2.
- Virtuella datorer i A-serien kommer att bli inaktuella för att skapa nya ESP-kluster, eftersom virtuella datorer i A-serien kan orsaka ESP-klusterproblem på grund av relativt låg processor- och minneskapacitet.
HBase 2.0 till 2.1
I den kommande versionen av HDInsight 4.0 uppgraderas HBase-versionen från version 2.0 till 2.1.
Felkorrigeringar
HDInsight fortsätter att förbättra klustrets tillförlitlighet och prestanda.
Ändring av komponentversion
Vi har utökat HDInsight 3.6-supporten till den 31 december 2020. Mer information finns i HDInsight-versioner som stöds.
Ingen komponentversion ändras för HDInsight 4.0.
Apache Zeppelin på HDInsight 3.6: 0.7.0-->0.7.3.
Du hittar de senaste komponentversionerna från det här dokumentet.
Nya regioner
Förenade Arabemiraten, norra
Hanterings-IP-adresserna för UAE North är: 65.52.252.96 och 65.52.252.97.
Utgivningsdatum: 2019-07-11
Den här versionen gäller både för HDInsight 3.6 och 4.0.
Nya funktioner
HDInsight Identity Broker (HIB) (förhandsversion)
HDInsight Identity Broker (HIB) gör det möjligt för användare att logga in på Apache Ambari med multifaktorautentisering (MFA) och hämta nödvändiga Kerberos-biljetter utan att behöva lösenordshashvärden i Azure Active Directory-domän Services (AAD-DS). För närvarande är HIB endast tillgängligt för kluster som distribueras via EN ARM-mall (Azure Resource Management).
Kafka REST API Proxy (förhandsversion)
Kafka REST API Proxy tillhandahåller en klicksdistribution av REST-proxy med hög tillgänglighet med Kafka-kluster via säker Azure AD-auktorisering och OAuth-protokoll.
Autoskala
Autoskalning för Azure HDInsight är nu allmänt tillgängligt i alla regioner för Apache Spark- och Hadoop-klustertyper. Den här funktionen gör det möjligt att hantera arbetsbelastningar för stordataanalys på ett mer kostnadseffektivt och produktivt sätt. Nu kan du optimera användningen av dina HDInsight-kluster och bara betala för det du behöver.
Beroende på dina behov kan du välja mellan inläsningsbaserad och schemabaserad autoskalning. Belastningsbaserad autoskalning kan skala upp och ned klusterstorleken baserat på aktuella resursbehov, medan schemabaserad autoskalning kan ändra klusterstorleken baserat på ett fördefinierat schema.
Autoskalningsstöd för HBase- och LLAP-arbetsbelastningar är också offentlig förhandsversion. Mer information finns i Skala Azure HDInsight-kluster automatiskt.
HDInsight-accelererade skrivningar för Apache HBase
Accelererade skrivningar använder Azure Premium SSD-hanterade diskar för att förbättra prestanda hos Apache HBase Write Ahead Log (WAL). Mer information finns i Azure HDInsight – Accelererade skrivningar för Apache HBase.
Anpassad Ambari-databas
HDInsight erbjuder nu en ny kapacitet som gör det möjligt för kunder att använda sin egen SQL DB för Ambari. Nu kan kunderna välja rätt SQL DB för Ambari och enkelt uppgradera den baserat på deras egna krav på affärstillväxt. Distributionen görs med en Azure Resource Manager-mall. Mer information finns i Konfigurera HDInsight-kluster med en anpassad Ambari DB.
Virtuella datorer i F-serien är nu tillgängliga med HDInsight
Virtuella datorer i F-serien (VM) är ett bra val för att komma igång med HDInsight med krav på lätt bearbetning. Med ett lägre listpris per timme är F-serien det bästa värdet i prisprestanda i Azure-portföljen baserat på Azure Compute Unit (ACU) per vCPU. Mer information finns i Välja rätt VM-storlek för ditt Azure HDInsight-kluster.
Inaktualitet
Utfasning av virtuella datorer i G-serien
Från den här versionen erbjuds inte längre virtuella datorer i G-serien i HDInsight.
Dv1 utfasning av virtuell dator
Från den här versionen är användningen av Dv1 virtuella datorer med HDInsight inaktuell. Alla kundförfrågningar för Dv1 kommer att hanteras Dv2 automatiskt. Det finns ingen prisskillnad mellan Dv1 och Dv2 virtuella datorer.
Funktionalitetsförändringar
Ändra storlek på klusterhanterad disk
HDInsight tillhandahåller hanterat diskutrymme med klustret. Från den här versionen ändras den hanterade diskstorleken för varje nod i det nya skapade klustret till 128 GB.
Kommande ändringar
Följande ändringar sker i de kommande versionerna.
Flytta till skalningsuppsättningar för virtuella Azure-datorer
HDInsight använder nu virtuella Azure-datorer för att etablera klustret. Från och med december använder HDInsight skalningsuppsättningar för virtuella Azure-datorer i stället. Läs mer om skalningsuppsättningar för virtuella Azure-datorer.
HBase 2.0 till 2.1
I den kommande versionen av HDInsight 4.0 uppgraderas HBase-versionen från version 2.0 till 2.1.
Utfasning av virtuella datorer i A-serien för ESP-kluster
Virtuella datorer i A-serien kan orsaka PROBLEM med ESP-kluster på grund av relativt låg processor- och minneskapacitet. I den kommande versionen kommer virtuella datorer i A-serien att bli inaktuella för att skapa nya ESP-kluster.
Felkorrigeringar
HDInsight fortsätter att förbättra klustrets tillförlitlighet och prestanda.
Ändring av komponentversion
Det finns ingen komponentversionsändring för den här versionen. Du hittar de aktuella komponentversionerna för HDInsight 4.0 och HDInsight 3.6 här.
Utgivningsdatum: 2019-08-07
Komponentversioner
De officiella Apache-versionerna av alla HDInsight 4.0-komponenter finns nedan. De komponenter som visas är versioner av de senaste stabila versionerna som är tillgängliga.
- Apache Ambari 2.7.1
- Apache Hadoop 3.1.1
- Apache HBase 2.0.0
- Apache Hive 3.1.0
- Apache Kafka 1.1.1, 2.1.0
- Apache Mahout 0.9.0+
- Apache Oozie 4.2.0
- Apache Phoenix 4.7.0
- Apache Pig 0.16.0
- Apache Ranger 0.7.0
- Apache Slider 0.92.0
- Apache Spark 2.3.1, 2.4.0
- Apache Sqoop 1.4.7
- Apache TEZ 0.9.1
- Apache Zeppelin 0.8.0
- Apache ZooKeeper 3.4.6
Senare versioner av Apache-komponenter paketeras ibland i HDP-distributionen utöver de versioner som anges ovan. I det här fallet visas dessa senare versioner i tabellen Technical Previews och bör inte ersätta Apache-komponentversionerna av listan ovan i en produktionsmiljö.
Information om Apache-korrigering
Mer information om korrigeringar som är tillgängliga i HDInsight 4.0 finns i korrigeringslistan för varje produkt i tabellen nedan.
| Produktnamn | Korrigeringsinformation |
|---|---|
| Ambari | Ambari-korrigeringsinformation |
| Hadoop | Information om Hadoop-korrigering |
| HBase | HBase-korrigeringsinformation |
| Hive | Den här versionen ger Hive 3.1.0 inga fler Apache-korrigeringar. |
| Kafka | Den här versionen ger Kafka 1.1.1 inga fler Apache-korrigeringar. |
| Oozie | Oozie-korrigeringsinformation |
| Phoenix | Korrigeringsinformation för Phoenix |
| Pig | Information om griskorrigering |
| Ranger | Information om Ranger-korrigering |
| Spark | Information om Spark-korrigering |
| Sqoop | Den här versionen ger Sqoop 1.4.7 inga fler Apache-korrigeringar. |
| Tez | Den här versionen innehåller Tez 0.9.1 utan fler Apache-korrigeringar. |
| Zeppelin | Den här versionen ger Zeppelin 0.8.0 inga fler Apache-korrigeringar. |
| Zookeeper | Korrigeringsinformation för Zookeeper |
Åtgärdat vanliga sårbarheter och exponeringar
Mer information om säkerhetsproblem som har lösts i den här versionen finns i Hortonworks fasta vanliga sårbarheter och exponeringar för HDP 3.0.1.
Kända problem
Replikeringen bryts för Säker HBase med standardinstallation
Gör följande för HDInsight 4.0:
Aktivera kommunikation mellan kluster.
Logga in på den aktiva huvudnoden.
Ladda ned ett skript för att aktivera replikering med följande kommando:
sudo wget https://raw.githubusercontent.com/Azure/hbase-utils/master/replication/hdi_enable_replication.shSkriv kommandot
sudo kinit <domainuser>.Skriv följande kommando för att köra skriptet:
sudo bash hdi_enable_replication.sh -m <hn*> -s <srclusterdns> -d <dstclusterdns> -sp <srcclusterpasswd> -dp <dstclusterpasswd> -copydata
För HDInsight 3.6
Logga in på aktiv HMaster ZK.
Ladda ned ett skript för att aktivera replikering med följande kommando:
sudo wget https://raw.githubusercontent.com/Azure/hbase-utils/master/replication/hdi_enable_replication.shSkriv kommandot
sudo kinit -k -t /etc/security/keytabs/hbase.service.keytab hbase/<FQDN>@<DOMAIN>.Ange följande kommando:
sudo bash hdi_enable_replication.sh -s <srclusterdns> -d <dstclusterdns> -sp <srcclusterpasswd> -dp <dstclusterpasswd> -copydata
Phoenix Sqlline slutar fungera efter migrering av HBase-kluster till HDInsight 4.0
Använd följande steg:
- Släpp följande Phoenix-tabeller:
SYSTEM.FUNCTIONSYSTEM.SEQUENCESYSTEM.STATSSYSTEM.MUTEXSYSTEM.CATALOG
- Om du inte kan ta bort någon av tabellerna startar du om HBase för att rensa eventuella anslutningar till tabellerna.
- Kör
sqlline.pyigen. Phoenix återskapar alla tabeller som togs bort i steg 1. - Återskapa Phoenix-tabeller och vyer för dina HBase-data.
Phoenix Sqlline slutar fungera efter replikering av HBase Phoenix-metadata från HDInsight 3.6 till 4.0
Använd följande steg:
- Innan du utför replikeringen går du till mål 4.0-klustret och kör
sqlline.py. Det här kommandot genererar Phoenix-tabeller somSYSTEM.MUTEXochSYSTEM.LOGsom bara finns i 4.0. - Släpp följande tabeller:
SYSTEM.FUNCTIONSYSTEM.SEQUENCESYSTEM.STATSSYSTEM.CATALOG
- Starta HBase-replikeringen
Inaktualitet
Apache Storm- och ML-tjänster är inte tillgängliga i HDInsight 4.0.
Utgivningsdatum: 2019-04-14
Nya funktioner
De nya uppdateringarna och funktionerna hör till följande kategorier:
Uppdatera Hadoop och andra projekt med öppen källkod – Förutom över 1 000 felkorrigeringar i 20+ projekt med öppen källkod innehåller den här uppdateringen en ny version av Spark (2.3) och Kafka (1.0).
Uppdatera R Server 9.1 till Machine Learning Services 9.3 – Med den här versionen ger vi dataexperter och tekniker det bästa av öppen källkod förbättrade med algoritmiska innovationer och enkel driftsättning, alla tillgängliga på det språk de föredrar med Apache Sparks hastighet. Den här versionen utökar de funktioner som erbjuds i R Server med extra stöd för Python, vilket leder till att klusternamnet ändras från R Server till ML Services.
Stöd för Azure Data Lake Storage Gen2 – HDInsight stöder förhandsversionen av Azure Data Lake Storage Gen2. I de tillgängliga regionerna kan kunderna välja ett ADLS Gen2-konto som primärt eller sekundärt arkiv för sina HDInsight-kluster.
HDInsight Enterprise Security Package Uppdateringar (förhandsversion) – (förhandsversion) Stöd för tjänstslutpunkter för virtuellt nätverk för Azure Blob Storage, ADLS Gen1, Azure Cosmos DB och Azure DB.
Komponentversioner
De officiella Apache-versionerna av alla HDInsight 3.6-komponenter visas nedan. Alla komponenter som anges här är officiella Apache-versioner av de senaste stabila versionerna som är tillgängliga.
Apache Hadoop 2.7.3
Apache HBase 1.1.2
Apache Hive 1.2.1
Apache Hive 2.1.0
Apache Kafka 1.0.0
Apache Mahout 0.9.0+
Apache Oozie 4.2.0
Apache Phoenix 4.7.0
Apache Pig 0.16.0
Apache Ranger 0.7.0
Apache Slider 0.92.0
Apache Spark 2.2.0/2.3.0
Apache Sqoop 1.4.6
Apache Storm 1.1.0
Apache TEZ 0.7.0
Apache Zeppelin 0.7.3
Apache ZooKeeper 3.4.6
Senare versioner av några Apache-komponenter paketeras ibland i HDP-distributionen utöver de versioner som anges ovan. I det här fallet visas dessa senare versioner i tabellen Technical Previews och bör inte ersätta Apache-komponentversionerna av listan ovan i en produktionsmiljö.
Information om Apache-korrigering
Hadoop
Den här versionen innehåller Hadoop Common 2.7.3 och följande Apache-korrigeringar:
HADOOP-13190: Mention LoadBalancingKMSClientProvider i KMS HA-dokumentationen.
HADOOP-13227: AsyncCallHandler bör använda en händelsedriven arkitektur för att hantera asynkrona anrop.
HADOOP-14104: Klienten bör alltid fråga namenode för kms-providersökvägen.
HADOOP-14799: Uppdatera nimbus-jose-jwt till 4.41.1.
HADOOP-14814: Åtgärda inkompatibel API-ändring på FsServerDefaults till HADOOP-14104.
HADOOP-14903: Lägg uttryckligen till json-smart i pom.xml.
HADOOP-15042: Azure PageBlobInputStream.skip() kan returnera negativt värde när numberOfPagesRemaining är 0.
HADOOP-15255: Stöd för konvertering av versaler/gemener för gruppnamn i LdapGroupsMapping.
HADOOP-15265: undanta json-smart explicit från hadoop-auth pom.xml.
HDFS-7922: ShortCircuitCache#close släpper inte ScheduledThreadPoolExecutors.
HDFS-8496: Anropa stopWriter() med FSDatasetImpl lås kan blockera andra trådar (cmccabe).
HDFS-10267: Extra "synkroniserad" på FsDatasetImpl#recoverAppend och FsDatasetImpl#recoverClose.
HDFS-10489: Inaktuell dfs.encryption.key.provider.uri för HDFS-krypteringszoner.
HDFS-11384: Lägg till alternativ för balancer för att sprida getBlocks-anrop för att undvika NameNodes rpc. CallQueueLength-topp.
HDFS-11689: Nytt undantag som utlöses av
DFSClient%isHDFSEncryptionEnabledtrasighackyhive-kod.HDFS-11711: DN bör inte ta bort blocket På undantaget "För många öppna filer".
HDFS-12347: TestBalancerRPCDelay#testBalancerRPCDelay misslyckas ofta.
HDFS-12781: När
Datanodedu är nere genererar fliken INamenodeanvändargränssnittetDatanodevarningsmeddelande.HDFS-13054: Hantera PathIsNotEmptyDirectoryException i
DFSClientborttagningsanropet.HDFS-13120: Ögonblicksbildsdiff kan skadas efter sammanfogning.
YARN-3742: YARN RM stängs av om
ZKClienttidsgränsen uppnås.YARN-6061: Lägg till en UncaughtExceptionHandler för kritiska trådar i RM.
YARN-7558: kommandot yarn logs kan inte hämta loggar för containrar som körs om UI-autentisering är aktiverat.
YARN-7697: Det går inte att hämta loggar för det färdiga programmet trots att loggaggregeringen är klar.
HDP 2.6.4 tillhandahöll Hadoop Common 2.7.3 och följande Apache-korrigeringar:
HADOOP-13700: Ta bort ej inläst
IOExceptionfrån TrashPolicy#initiera och #getInstance signaturer.HADOOP-13709: Möjlighet att rensa underprocesser som skapas av Shell när processen avslutas.
HADOOP-14059: skrivfel i
s3afelmeddelandet rename(self, subdir).HADOOP-14542: Lägg till IOUtils.cleanupWithLogger som accepterar slf4j-logger-API.
HDFS-9887: Tidsgränser för WebHdfs-socket ska vara konfigurerbara.
HDFS-9914: Åtgärda konfigurerbar Tidsgräns för webhDFS-anslutning/läsning.
MAPREDUCE-6698: Öka tidsgränsen för TestUnnecessaryBlockingOnHist oryFileInfo.testTwoThreadsQueryingDifferentJobOfSameUser.
YARN-4550: Vissa tester i TestContainerLanch misslyckas i en språkmiljö som inte är engelsk.
YARN-4717: TestResourceLocalizationService.testPublicResourceInitializesLocalDir misslyckas tillfälligt på grund av IllegalArgumentException från rensning.
YARN-5042: Montera /sys/fs/cgroup i Docker-containrar som skrivskyddad montering.
YARN-5318: Åtgärda tillfälligt testfel för TestRMAdminService#te stRefreshNodesResourceWithFileSystemBasedConfigurationProvider.
YARN-5641: Localizer lämnar kvar tarballs när containern är klar.
YARN-6004: Refactor TestResourceLocalizationService#testDownloadingResourcesOnContainer så att det är färre än 150 rader.
YARN-6078: Containrar som fastnat i lokaliseringstillstånd.
YARN-6805: NPE i LinuxContainerExecutor på grund av null PrivilegedOperationException-slutkod.
HBase
Den här versionen innehåller HBase 1.1.2 och följande Apache-korrigeringar.
HBASE-13376: Förbättringar av stokastisk lastbalanserare.
HBASE-13716: Sluta använda Hadoops FSConstants.
HBASE-13848: Åtkomst till InfoServer SSL-lösenord via API för autentiseringsprovider.
HBASE-13947: Använd MasterServices i stället för Server i AssignmentManager.
HBASE-14135: HBase Backup/Restore Phase 3: Sammanfoga säkerhetskopieringsbilder.
HBASE-14473: Beräkningsregionlokalitet parallellt.
HBASE-14517: Visa
regionserver'sversion på huvudstatussidan.HBASE-14606: TestSecureLoadIncrementalHFiles-tester överskrides i trunk build på apache.
HBASE-15210: Ångra aggressiv lastbalanserare med tiotals rader per millisekunder.
HBASE-15515: Förbättra LocalityBasedCandidateGenerator i Balancer.
HBASE-15615: Fel vilotid när
RegionServerCallabledu behöver försöka igen.HBASE-16135: PeerClusterZnode under rs av borttagen peer kanske aldrig tas bort.
HBASE-16570: Beräkningsregionlokalitet parallellt vid start.
HBASE-16810: HBase Balancer genererar ArrayIndexOutOfBoundsException när
regionserversär i /hbase/tömmer znode och tas bort.HBASE-16852: TestDefaultCompactSelection misslyckades på branch-1.3.
HBASE-17387: Minska omkostnaderna för undantagsrapporten i RegionActionResult för multi().
HBASE-17850: Reparationsverktyg för säkerhetskopieringssystem.
HBASE-17931: Tilldela systemtabeller till servrar med högsta version.
HBASE-18083: Gör stora/små filrengöringstrådsnummer konfigurerbara i HFileCleaner.
HBASE-18084: Förbättra CleanerChore för att rensa från katalogen, vilket förbrukar mer diskutrymme.
HBASE-18164: Mycket snabbare lokalitetskostnadsfunktion och kandidatgenerator.
HBASE-18212: I fristående läge med det lokala filsystemets HBase-loggar Varningsmeddelande: Det gick inte att anropa metoden "unbuffer" i klassen org.apache.hadoop.fs.FSDataInputStream.
HBASE-18808: Ineffektiv konfigurationskontroll i BackupLogCleaner#getDeletableFiles().
HBASE-19052: FixedFileTrailer bör känna igen Klassen CellComparatorImpl i branch-1.x.
HBASE-19065: HRegion#bulkLoadHFiles() bör vänta tills samtidig region#flush() har slutförts.
HBASE-19285: Lägg till histogram för svarstid per tabell.
HBASE-19393: HTTP 413 FULL head vid åtkomst till HBase-användargränssnittet med hjälp av SSL.
HBASE-19395: [branch-1] TestEndToEndSplitTransaction.testMasterOpsWhileSplitting misslyckas med NPE.
HBASE-19421: branch-1 kompileras inte mot Hadoop 3.0.0.
HBASE-19934: HBaseSnapshotException när läsrepliker aktiveras och ögonblicksbilder online tas efter regiondelning.
HBASE-20008: [backport] NullPointerException när du återställer en ögonblicksbild efter delning av en region.
Hive
Den här versionen innehåller Hive 1.2.1 och Hive 2.1.0 utöver följande korrigeringar:
Hive 1.2.1 Apache-korrigeringar:
HIVE-10697: ObjectInspectorConvertors#UnionConvertor utför en felaktig konvertering.
HIVE-11266: antal(*) fel resultat baserat på tabellstatistik för externa tabeller.
HIVE-12245: Stöd för kolumnkommentare för en HBase-backad tabell.
HIVE-12315: Åtgärda Vektoriserad dubbeldelning med noll.
HIVE-12360: Felaktig sök i okomprimerad ORC med predikat pushdown.
HIVE-12378: Undantag på HBaseSerDe.serialisera binärt fält.
HIVE-12785: Visa med uniontyp och UDF till structen är bruten.
HIVE-14013: Beskriv tabellen visar inte unicode korrekt.
HIVE-14205: Hive stöder inte unionstyp med AVRO-filformat.
HIVE-14421: FS.deleteOnExit innehåller referenser till _tmp_space.db filer.
HIVE-15563: Ignorera undantaget för olaglig åtgärdstillståndsövergång i SQLOperation.runQuery för att exponera verkligt undantag.
HIVE-15680: Felaktiga resultat när hive.optimize.index.filter=true och samma ORC-tabell refereras två gånger i frågan, i MR-läge.
HIVE-15883: HBase-mappad tabell i Hive insert misslyckas för decimal.
HIVE-16232: Stöd för statistikberäkning för kolumner i QuotedIdentifier.
HIVE-16828: Med CBO aktiverat genererar Frågan i partitionerade vyer IndexOutOfBoundException.
HIVE-17013: Ta bort begäran med en underfråga baserat på välj över en vy.
HIVE-17063: Det går inte att infoga överskrivningspartition i en extern tabell när partitionen släpps först.
HIVE-17259: Hive JDBC känner inte igen UNIONTYPE-kolumner.
HIVE-17419: ANALYSERA TABELL... KOMMANDOT COMPUTE STATISTICS FOR COLUMNS (BERÄKNINGSSTATISTIK FÖR KOLUMNER) visar beräknad statistik för maskerade tabeller.
HIVE-17530: ClassCastException när du konverterar
uniontype.HIVE-17621: Hive-site-inställningar ignoreras under delningsberäkning av HCatInputFormat.
HIVE-17636: Lägg till multiple_agg.q-test för
blobstores.HIVE-17729: Lägg till databas- och förklara relaterade blobarkivtester.
HIVE-17731: Lägg till ett bakåtalternativ
compatför externa användare i HIVE-11985.HIVE-17803: Med Pig multi-query kommer 2 HCatStorers som skriver till samma tabell att trampa på varandras utdata.
HIVE-17829: ArrayIndexOutOfBoundsException – HBASE-backade tabeller med Avro-schema i
Hive2.HIVE-17845: infogning misslyckas om måltabellkolumner inte är gemener.
HIVE-17900: Analysera statistik för kolumner som utlöses av Compactor genererar felaktigt SQL med > en partitionskolumn.
HIVE-18026: Konfigurationsoptimering av Hive webhcat-huvudnamn.
HIVE-18031: Stöd för replikering för alter database-åtgärden.
HIVE-18090: Sura pulsslag misslyckas när metaarkivet är anslutet via hadoop-autentiseringsuppgifter.
HIVE-18189: Hive-frågan returnerar fel resultat när du anger hive.groupby.orderby.position.alias till true.
HIVE-18258: Vektorisering: Reduce-Side GROUP BY MERGEPARTIAL med duplicerade kolumner är bruten.
HIVE-18293: Hive kan inte komprimera tabeller som finns i en mapp som inte ägs av identitet som kör HiveMetaStore.
HIVE-18327: Ta bort det onödiga HiveConf-beroendet för MiniHiveKdc.
HIVE-18341: Lägg till stöd för repl-inläsning för att lägga till "raw"-namnrymd för TDE med samma krypteringsnycklar.
HIVE-18352: Introducera ett METADATAONLY-alternativ när du gör REPL DUMP för att tillåta integrering av andra verktyg.
HIVE-18353: CompactorMR ska anropa jobclient.close() för att utlösa rensning.
HIVE-18390: IndexOutOfBoundsException när du kör frågor mot en partitionerad vy i ColumnPruner.
HIVE-18429: Komprimering bör hantera ett ärende när det inte ger några utdata.
HIVE-18447: JDBC: Ge JDBC-användare ett sätt att skicka cookieinformation via anslutningssträng.
HIVE-18460: Komprimeraren skickar inte tabellegenskaper till Orc-skrivaren.
HIVE-18467: stöd för hela lagerdumpen/belastningen + skapa/släppa databashändelser (Anishek Agarwal, granskad av Sankar Hariappan).
HIVE-18551: Vectorization: VectorMapOperator försöker skriva för många vektorkolumner för Hybrid Grace.
HIVE-18587: Infoga DML-händelse kan försöka beräkna en kontrollsumma för kataloger.
HIVE-18613: Utöka JsonSerDe för att stödja BINÄR typ.
HIVE-18626: Repl load "with"-satsen skickar inte konfiguration till uppgifter.
HIVE-18660: PCR skiljer inte mellan partitioner och virtuella kolumner.
HIVE-18754: REPL STATUS bör ha stöd för "with"-satsen.
HIVE-18754: REPL STATUS bör ha stöd för "with"-satsen.
HIVE-18788: Rensa indata i JDBC PreparedStatement.
HIVE-18794: Repl load "with"-satsen skickar inte konfiguration till uppgifter för tabeller som inte är partitionstabeller.
HIVE-18808: Gör komprimering mer robust när statistikuppdateringen misslyckas.
HIVE-18817: ArrayIndexOutOfBounds-undantag vid läsning av ACID-tabellen.
HIVE-18833: Automatisk sammanslagning misslyckas när "infoga i katalogen som orcfile".
HIVE-18879: Tillåt inte inbäddade element i UDFXPathUtil måste fungera om xercesImpl.jar i klassökvägen.
HIVE-18907: Skapa verktyg för att åtgärda problem med acid key-index från HIVE-18817.
Hive 2.1.0 Apache-korrigeringar:
HIVE-14013: Beskriv tabellen visar inte unicode korrekt.
HIVE-14205: Hive stöder inte unionstyp med AVRO-filformat.
HIVE-15563: Ignorera undantaget för olaglig åtgärdstillståndsövergång i SQLOperation.runQuery för att exponera verkligt undantag.
HIVE-15680: Felaktiga resultat när hive.optimize.index.filter=true och samma ORC-tabell refereras två gånger i frågan, i MR-läge.
HIVE-15883: HBase-mappad tabell i Hive insert misslyckas för decimal.
HIVE-16757: Ta bort anrop till inaktuella AbstractRelNode.getRows.
HIVE-16828: Med CBO aktiverat genererar Frågan i partitionerade vyer IndexOutOfBoundException.
HIVE-17063: Det går inte att infoga överskrivningspartition i en extern tabell när partitionen släpps först.
HIVE-17259: Hive JDBC känner inte igen UNIONTYPE-kolumner.
HIVE-17530: ClassCastException när du konverterar
uniontype.HIVE-17600: Gör OrcFile's enforceBufferSize användaruppsättningsbar.
HIVE-17601: Förbättra felhanteringen i LlapServiceDriver.
HIVE-17613: ta bort objektpooler för korta allokeringar med samma tråd.
HIVE-17617: Sammanslagning av en tom resultatuppsättning bör innehålla gruppering av den tomma gruppuppsättningen.
HIVE-17621: Hive-site-inställningar ignoreras under delningsberäkning av HCatInputFormat.
HIVE-17629: CachedStore: Har en godkänd/inte godkänd konfiguration som tillåter selektiv cachelagring av tabeller/partitioner och tillåter läsning under förvarning.
HIVE-17636: Lägg till multiple_agg.q-test för
blobstores.HIVE-17702: felaktig isRepeating handling in decimal reader in ORC.
HIVE-17729: Lägg till databas- och förklara relaterade blobarkivtester.
HIVE-17731: Lägg till ett bakåtalternativ
compatför externa användare i HIVE-11985.HIVE-17803: Med Pig multi-query kommer 2 HCatStorers som skriver till samma tabell att trampa på varandras utdata.
HIVE-17845: infogning misslyckas om måltabellkolumner inte är gemener.
HIVE-17900: Analysera statistik för kolumner som utlöses av Compactor genererar felaktigt SQL med > en partitionskolumn.
HIVE-18006: Optimera minnesfotavtrycket för HLLDenseRegister.
HIVE-18026: Konfigurationsoptimering av Hive webhcat-huvudnamn.
HIVE-18031: Stöd för replikering för alter database-åtgärden.
HIVE-18090: Sura pulsslag misslyckas när metaarkivet är anslutet via hadoop-autentiseringsuppgifter.
HIVE-18189: Order by position fungerar inte när
cboär inaktiverat.HIVE-18258: Vektorisering: Reduce-Side GROUP BY MERGEPARTIAL med duplicerade kolumner är bruten.
HIVE-18269: LLAP: Snabb
llapio med pipeline för långsam bearbetning kan leda till OOM.HIVE-18293: Hive kan inte komprimera tabeller som finns i en mapp som inte ägs av identitet som kör HiveMetaStore.
HIVE-18318: LLAP-postläsaren bör kontrollera avbrott även när blockeringen inte blockeras.
HIVE-18326: LLAP Tez-schemaläggare – endast föregripa uppgifter om det finns ett beroende mellan dem.
HIVE-18327: Ta bort det onödiga HiveConf-beroendet för MiniHiveKdc.
HIVE-18331: Lägg till omlogin när TGT upphör att gälla och viss loggning/lambda.
HIVE-18341: Lägg till stöd för repl-inläsning för att lägga till "raw"-namnrymd för TDE med samma krypteringsnycklar.
HIVE-18352: Introducera ett METADATAONLY-alternativ när du gör REPL DUMP för att tillåta integrering av andra verktyg.
HIVE-18353: CompactorMR ska anropa jobclient.close() för att utlösa rensning.
HIVE-18384: ConcurrentModificationException i
log4j2.xbiblioteket.HIVE-18390: IndexOutOfBoundsException när du kör frågor mot en partitionerad vy i ColumnPruner.
HIVE-18447: JDBC: Ge JDBC-användare ett sätt att skicka cookieinformation via anslutningssträng.
HIVE-18460: Komprimeraren skickar inte tabellegenskaper till Orc-skrivaren.
HIVE-18462: (Förklara formaterad för frågor med kartkoppling har columnExprMap med oformaterat kolumnnamn).
HIVE-18467: stöder hela lagerdumpen/belastningen + skapa/släppa databashändelser.
HIVE-18488: LLAP ORC-läsare saknar några null-kontroller.
HIVE-18490: Fråga med EXISTS och NOT EXISTS med icke-equi-predikat kan ge fel resultat.
HIVE-18506: LlapBaseInputFormat – negativt matrisindex.
HIVE-18517: Vectorization: Fix VectorMapOperator to accept VRBs and check vectorized flag correctly to support LLAP Cachelagring).
HIVE-18523: Åtgärda sammanfattningsrad om det inte finns några indata.
HIVE-18528: Aggregerad statistik i ObjectStore får fel resultat.
HIVE-18530: Replikeringen bör hoppa över MM-tabellen (för tillfället).
HIVE-18548: Åtgärda
log4jimport.HIVE-18551: Vectorization: VectorMapOperator försöker skriva för många vektorkolumner för Hybrid Grace.
HIVE-18577: SemanticAnalyzer.validate har några meningslösa metaarkivanrop.
HIVE-18587: Infoga DML-händelse kan försöka beräkna en kontrollsumma för kataloger.
HIVE-18597: LLAP: Paketera
log4j2alltid API-jar-filen förorg.apache.log4j.HIVE-18613: Utöka JsonSerDe för att stödja BINÄR typ.
HIVE-18626: Repl load "with"-satsen skickar inte konfiguration till uppgifter.
HIVE-18643: sök inte efter arkiverade partitioner för ACID ops.
HIVE-18660: PCR skiljer inte mellan partitioner och virtuella kolumner.
HIVE-18754: REPL STATUS bör ha stöd för "with"-satsen.
HIVE-18788: Rensa indata i JDBC PreparedStatement.
HIVE-18794: Repl load "with"-satsen skickar inte konfiguration till uppgifter för tabeller som inte är partitionstabeller.
HIVE-18808: Gör komprimering mer robust när statistikuppdateringen misslyckas.
HIVE-18815: Ta bort oanvänd funktion i HPL/SQL.
HIVE-18817: ArrayIndexOutOfBounds-undantag vid läsning av ACID-tabellen.
HIVE-18833: Automatisk sammanslagning misslyckas när "infoga i katalogen som orcfile".
HIVE-18879: Tillåt inte inbäddade element i UDFXPathUtil måste fungera om xercesImpl.jar i klassökvägen.
HIVE-18944: Placering av grupperingsuppsättningar anges felaktigt under DPP.
Kafka
Den här versionen innehåller Kafka 1.0.0 och följande Apache-korrigeringar.
KAFKA-4827: Kafka connect: error with special characters in connector name.
KAFKA-6118: Tillfälligt fel i kafka.api.SaslScramSslEndToEndAuthorizationTest.testTwoConsumersWithDifferentSaslCredentials.
KAFKA-6156: JmxReporter kan inte hantera katalogsökvägar i Windows-format.
KAFKA-6164: ClientQuotaManager-trådar förhindrar avstängning vid fel vid inläsning av loggar.
KAFKA-6167: Tidsstämpel på streams-katalogen innehåller ett kolon, vilket är ett olagligt tecken.
KAFKA-6179: RecordQueue.clear() rensar inte MinTimestampTrackers underhållslista.
KAFKA-6185: Väljare minnesläcka med hög sannolikhet för OOM om det finns en nedkonvertering.
KAFKA-6190: GlobalKTable slutför aldrig återställningen när transaktionsmeddelanden används.
KAFKA-6210: IllegalArgumentException om 1.0.0 används för inter.broker.protocol.version eller log.message.format.version.
KAFKA-6214: Om du använder väntelägesrepliker med ett lagringsutrymme för minnestillstånd kraschar Flöden.
KAFKA-6215: Kafka Flöden Test misslyckas i bagageutrymmet.
KAFKA-6238: Problem med protokollversion vid tillämpning av en löpande uppgradering till 1.0.0.
KAFKA-6260: AbstractCoordinator hanterar inte tydligt NULL-undantag.
KAFKA-6261: Begärandeloggning utlöser undantag om acks=0.
KAFKA-6274: Förbättra
KTableautogenererade namn i källtillståndsarkivet.
Mahout
I HDP-2.3.x och 2.4.x synkroniserade vi i stället för att skicka en specifik Apache-version av Mahout till en viss revisionspunkt på Apache Mahout-trunken. Den här revisionspunkten är efter 0.9.0-versionen, men före 0.10.0-versionen. Detta ger ett stort antal felkorrigeringar och funktionella förbättringar jämfört med 0.9.0-versionen, men ger en stabil version av Mahout-funktionen innan den fullständiga konverteringen till nya Spark-baserade Mahout i 0.10.0.
Revisionspunkten som valts för Mahout i HDP 2.3.x och 2.4.x kommer från grenen "mahout-0.10.x" i Apache Mahout från och med den 19 december 2014, revision 0f037cb03e77c096 i GitHub.
I HDP-2.5.x och 2.6.x tog vi bort biblioteket "commons-httpclient" från Mahout eftersom vi ser det som ett föråldrat bibliotek med möjliga säkerhetsproblem och uppgraderade Hadoop-Client i Mahout till version 2.7.3, samma version som används i HDP-2.5. Som ett resultat:
Tidigare kompilerade Mahout-jobb måste kompileras om i HDP-2.5- eller 2.6-miljön.
Det finns en liten möjlighet att vissa Mahout-jobb kan stöta på "ClassNotFoundException" eller "kunde inte läsa in klass"-fel relaterade till "org.apache.commons.httpclient", "net.java.dev.jets3t" eller relaterade klassnamnsprefix. Om de här felen inträffar kan du överväga om du vill installera de jar-filer som behövs i din klassökväg för jobbet manuellt, om risken för säkerhetsproblem i det föråldrade biblioteket är acceptabel i din miljö.
Det finns en ännu mindre möjlighet att vissa Mahout-jobb kan stöta på krascher i Mahouts hbase-klientkodanrop till de hadoop-vanliga biblioteken på grund av problem med binär kompatibilitet. Tyvärr finns det inget sätt att lösa det här problemet förutom att återgå till HDP-2.4.2-versionen av Mahout, som kan ha säkerhetsproblem. Återigen bör detta vara ovanligt och kommer sannolikt inte att inträffa i någon given Mahout-jobbsvit.
Oozie
Den här versionen ger Oozie 4.2.0 följande Apache-korrigeringar.
OOZIE-2571: Lägg till egenskapen spark.scala.binary.version Maven så att Scala 2.11 kan användas.
OOZIE-2606: Ställ in spark.yarn.jars för att fixa Spark 2.0 med Oozie.
OOZIE-2658: --driver-class-path kan skriva över klassökvägen i SparkMain.
OOZIE-2787: Oozie distribuerar programburken två gånger så att spark-jobbet misslyckas.
OOZIE-2792:
Hive2åtgärden parsar inte Spark-program-ID från loggfilen korrekt när Hive är på Spark.OOZIE-2799: Ange loggplats för spark sql på hive.
OOZIE-2802: Spark-åtgärdsfel på Spark 2.1.0 på grund av dubbletten
sharelibs.OOZIE-2923: Förbättra Spark-alternativens parsning.
OOZIE-3109: SCA: Cross-Site Scripting: Reflected.
OOZIE-3139: Oozie validerar arbetsflödet felaktigt.
OOZIE-3167: Uppgradera tomcat-versionen på grenen Oozie 4.3.
Phoenix
Den här versionen innehåller Phoenix 4.7.0 och följande Apache-korrigeringar:
PHOENIX-1751: Utför aggregeringar, sortering osv., i preScannerNext i stället för postScannerOpen.
PHOENIX-2714: Korrigera byteuppskattning i BaseResultIterators och exponera som gränssnitt.
PHOENIX-2724: Frågan med ett stort antal guideposter är långsammare jämfört med ingen statistik.
PHOENIX-2855: Lösning För att öka tidsintervallet serialiseras inte för HBase 1.2.
PHOENIX-3023: Långsam prestanda när gränsfrågor körs parallellt som standard.
PHOENIX-3040: Använd inte guideposter för att köra frågor seriellt.
PHOENIX-3112: Partiell radgenomsökning hanteras inte korrekt.
PHOENIX-3240: ClassCastException från Pig loader.
PHOENIX-3452: NULLS FIRST/NULL LAST ska inte påverka om GROUP BY är ordningsbevarande.
PHOENIX-3469: Felaktig sorteringsordning för DESC-primärnyckel för NULLS LAST/NULLS FIRST.
PHOENIX-3789: Kör indexunderhållsanrop mellan regioner i postBatchMutateIndispensably.
PHOENIX-3865: IS NULL returnerar inte rätt resultat när den första kolumnfamiljen inte filtreras mot.
PHOENIX-4290: Fullständig tabellsökning som utförs för DELETE med tabell med oföränderliga index.
PHOENIX-4373: Den lokala indexvariabellängdsnyckeln kan ha avslutande nullvärden vid uppsertning.
PHOENIX-4466: java.lang.RuntimeException: svarskod 500 – Köra ett spark-jobb för att ansluta till Phoenix-frågeservern och läsa in data.
PHOENIX-4489: HBase Anslut ion läcka i Phoenix MR Jobs.
PHOENIX-4525: Heltalsspill i GroupBy-körning.
PHOENIX-4560: ORDER BY med GROUP BY fungerar inte om det finns WHERE på
pkkolumnen.PHOENIX-4586: UPSERT SELECT tar inte hänsyn till jämförelseoperatorer för underfrågor.
PHOENIX-4588: Klona uttryck också, om dess barn har Determinism.PER_INVOCATION.
Pig
Den här versionen ger Pig 0.16.0 följande Apache-korrigeringar.
Ranger
Den här versionen innehåller Ranger 0.7.0 och följande Apache-korrigeringar:
RANGER-1805: Kodförbättring för att följa bästa praxis i js.
RANGER-1960: Ta hänsyn till ögonblicksbildens tabellnamn för borttagning.
RANGER-1982: Felförbättring för analysmått för Ranger Admin och Ranger KMS.
RANGER-1984: HBase-granskningsloggposter kanske inte visar alla taggar som är associerade med den använda kolumnen.
RANGER-1988: Åtgärda osäker slumpmässighet.
RANGER-1990: Lägg till enkelriktad SSL MySQL-support i Ranger Admin.
RANGER-2006: Åtgärda problem som identifierats av statisk kodanalys i ranger
usersyncförldapsynkroniseringskälla.RANGER-2008: Principutvärderingen misslyckas för principvillkor för flera ledningar.
Skjutreglage
Den här versionen ger Slider 0.92.0 inga fler Apache-korrigeringar.
Spark
Den här versionen innehåller Spark 2.3.0 och följande Apache-korrigeringar:
SPARK-13587: Stöd virtualenv i pyspark.
SPARK-19964: Undvik att läsa från fjärrlagringsplatser i SparkSubmitSuite.
SPARK-22882: ML-test för strukturerad direktuppspelning: ml.classification.
SPARK-22915: Direktuppspelningstester för spark.ml.feature, från N till Z.
SPARK-23020: Åtgärda ytterligare ett lopp i det processbaserade starttestet.
SPARK-23040: Returnerar avbrottsbar iterator för shuffle-läsare.
SPARK-23173: Undvik att skapa skadade parquet-filer när du läser in data från JSON.
SPARK-23264: Åtgärda scala. MatchError i literals.sql.out.
SPARK-23288: Åtgärda utdatamått med parquet-mottagare.
SPARK-23329: Åtgärda dokumentation om trigonometriska funktioner.
SPARK-23406: Aktivera stream-stream-självkopplingar för branch-2.3.
SPARK-23434: Spark bör inte varna "metadatakatalog" för en HDFS-filsökväg.
SPARK-23436: Härled partitionen som Datum endast om den kan överföras till Datum.
SPARK-23457: Registrera lyssnare av slutförda uppgifter först i ParquetFileFormat.
SPARK-23462: Förbättra felmeddelandet om saknade fält i StructType.
SPARK-23490: Kontrollera storage.locationUri med befintlig tabell i CreateTable.
SPARK-23524: Stora lokala blandningsblock bör inte kontrolleras för skada.
SPARK-23525: Stöd för ALTER TABLE CHANGE COLUMN COMMENT för extern hive-tabell.
SPARK-23553: Tester bör inte förutsätta standardvärdet "spark.sql.sources.default".
SPARK-23569: Tillåt att pandas_udf fungerar med skrivkommentarer i Python3-format.
SPARK-23570: Lägg till Spark 2.3.0 i HiveExternalCatalogVersionsSuite.
SPARK-23598: Gör metoder i BufferedRowIterator offentliga för att undvika körningsfel för en stor fråga.
SPARK-23599: Lägg till en UUID-generator från Pseudo-Random Numbers.
SPARK-23599: Använd RandomUUIDGenerator i Uuid-uttryck.
SPARK-23601: Ta bort
.md5filer från versionen.SPARK-23608: Lägg till synkronisering i SHS mellan funktionerna attachSparkUI och detachSparkUI för att undvika samtidiga ändringsproblem för Jetty-hanterare.
SPARK-23614: Åtgärda felaktigt återanvändningsutbyte när cachelagring används.
SPARK-23623: Undvik samtidig användning av cachelagrade konsumenter i CachedKafkaConsumer (branch-2.3).
SPARK-23624: Revidera dokumentet om metod pushFilters i Datasource V2.
SPARK-23628: calculateParamLength ska inte returnera 1 + antal uttryck.
SPARK-23630: Tillåt att användarens hadoop-konfigurationsanpassningar börjar gälla.
SPARK-23635: Spark executor env-variabel skrivs över med samma namn som variabeln AM env.
SPARK-23637: Yarn kan allokera fler resurser om samma köre avlivas flera gånger.
SPARK-23639: Hämta token före init-metaarkivklienten i SparkSQL CLI.
SPARK-23642: AccumulatorV2-underklassen isZero
scaladocfix.SPARK-23644: Använd absolut sökväg för REST-anrop i SHS.
SPARK-23645: Lägg till dokument RE "pandas_udf" med nyckelords args.
SPARK-23649: Hoppar över tecken som inte tillåts i UTF-8.
SPARK-23658: InProcessAppHandle använder fel klass i getLogger.
SPARK-23660: Åtgärda undantag i yarnklusterläge när programmet avslutades snabbt.
SPARK-23670: Åtgärda minnesläcka på SparkPlanGraphWrapper.
SPARK-23671: Åtgärda villkor för att aktivera SHS-trådpoolen.
SPARK-23691: Använd sql_conf i PySpark-tester där det är möjligt.
SPARK-23695: Åtgärda felmeddelandet för Kinesis-strömningstester.
SPARK-23706: spark.conf.get(value, default=None) ska producera None i PySpark.
SPARK-23728: Åtgärda ML-tester med förväntade undantag som kör strömningstester.
SPARK-23729: Respektera URI-fragment vid matchning av globs.
SPARK-23759: Det går inte att binda Spark-användargränssnittet till ett specifikt värdnamn/IP-adress.
SPARK-23760: CodegenContext.withSubExprEliminationExprs bör spara/återställa CSE-tillståndet korrekt.
SPARK-23769: Ta bort kommentarer som inaktiverar
Scalastylekontrollen i onödan.SPARK-23788: Åtgärda ras i StreamingQuerySuite.
SPARK-23802: PropagateEmptyRelation kan lämna frågeplanen i olöst tillstånd.
SPARK-23806: Broadcast.unpersist kan orsaka allvarliga undantag när det används med dynamisk allokering.
SPARK-23808: Ställ in standard spark-session i spark-sessioner med endast test.
SPARK-23809: Active SparkSession bör anges av getOrCreate.
SPARK-23816: Avlivade uppgifter bör ignorera FetchFailures.
SPARK-23822: Förbättra felmeddelandet för parquet-schemamatchningar.
SPARK-23823: Behåll ursprunget i transformExpression.
SPARK-23827: StreamingJoinExec bör se till att indata partitioneras i ett visst antal partitioner.
SPARK-23838: Sql-frågan som körs visas som "slutförd" på fliken SQL.
SPARK-23881: Fix flaky test JobCancellationSuite." avbrottsbar iterator för shuffle-läsare".
Sqoop
Den här versionen innehåller Sqoop 1.4.6 utan fler Apache-korrigeringar.
Storm
Den här versionen innehåller Storm 1.1.1 och följande Apache-korrigeringar:
STORM-2652: Undantag som genereras i JmsSpout open-metoden.
STORM-2841: testNoAcksIfFlushFails UT misslyckas med NullPointerException.
STORM-2854: Exponera IEventLogger för att göra händelseloggen pluggbar.
STORM-2870: FileBasedEventLogger läcker icke-daemon ExecutorService, vilket förhindrar att processen slutförs.
STORM-2960: Bättre att betona vikten av att konfigurera rätt OS-konto för Storm-processer.
Tez
Den här versionen innehåller Tez 0.7.0 och följande Apache-korrigeringar:
- TEZ-1526: LoadingCache för TezTaskID långsamt för stora jobb.
Zeppelin
Den här versionen ger Zeppelin 0.7.3 inga fler Apache-korrigeringar.
ZEPPELIN-3072: Zeppelin-användargränssnittet blir långsamt/svarar inte om det finns för många notebook-filer.
ZEPPELIN-3129: Zeppelin-användargränssnittet loggar inte ut i IE.
ZEPPELIN-903: Ersätt CXF med
Jersey2.
ZooKeeper
Den här versionen innehåller ZooKeeper 3.4.6 och följande Apache-korrigeringar:
ZOOKEEPER-1256: ClientPortBindTest misslyckas på macOS X.
ZOOKEEPER-1901: [JDK8] Sortera underordnade för jämförelse i AsyncOps-tester.
ZOOKEEPER-2423: Uppgradera Netty-versionen på grund av säkerhetsrisker (CVE-2014-3488).
ZOOKEEPER-2693: DOS-attack på wchp/wchc fyra bokstavsord (4lw).
ZOOKEEPER-2726: Patch introducerar ett potentiellt konkurrenstillstånd.
Åtgärdat vanliga sårbarheter och exponeringar
Det här avsnittet beskriver alla vanliga sårbarheter och exponeringar (CVE) som behandlas i den här versionen.
CVE-2017-7676
| Sammanfattning: Apache Ranger-principutvärdering ignorerar tecken efter jokertecken för "*" |
|---|
| Allvarlighetsgrad: Kritisk |
| Leverantör: Hortonworks |
| Versioner som påverkas: HDInsight 3.6-versioner inklusive Apache Ranger-versioner 0.5.x/0.6.x/0.7.0 |
| Användare som påverkas: Miljöer som använder Ranger-principer med tecken efter jokertecken – till exempel my*test, test*.txt |
| Effekt: Principresursmatchare ignorerar tecken efter jokertecknet *, vilket kan leda till oavsiktligt beteende. |
| Korrigeringsinformation: Ranger-principresursmatcharen uppdaterades för att hantera jokerteckenmatchningar korrekt. |
| Rekommenderad åtgärd: Uppgradera till HDI 3.6 (med Apache Ranger 0.7.1+). |
CVE-2017-7677
| Sammanfattning: Apache Ranger Hive Authorizer bör söka efter RWX-behörighet när extern plats har angetts |
|---|
| Allvarlighetsgrad: Kritisk |
| Leverantör: Hortonworks |
| Versioner som påverkas: HDInsight 3.6-versioner inklusive Apache Ranger-versioner 0.5.x/0.6.x/0.7.0 |
| Användare som påverkas: Miljöer som använder extern plats för Hive-tabeller |
| Effekt: I miljöer som använder extern plats för hive-tabeller bör Apache Ranger Hive Authorizer söka efter RWX-behörighet för den externa plats som anges för att skapa tabellen. |
| Korrigeringsinformation: Ranger Hive Authorizer uppdaterades för att hantera behörighetskontrollen på rätt sätt med den externa platsen. |
| Rekommenderad åtgärd: Användare bör uppgradera till HDI 3.6 (med Apache Ranger 0.7.1+). |
CVE-2017-9799
| Sammanfattning: Potentiell körning av kod som fel användare i Apache Storm |
|---|
| Allvarlighetsgrad: Viktigt |
| Leverantör: Hortonworks |
| Versioner som påverkas: HDP 2.4.0, HDP-2.5.0, HDP-2.6.0 |
| Användare som påverkas: Användare som använder Storm i säkert läge och använder blobarkiv för att distribuera topologibaserade artefakter eller använda blobarkivet för att distribuera topologiresurser. |
| Effekt: I vissa situationer och konfigurationer av storm är det teoretiskt möjligt för ägaren av en topologi att lura övervakaren att starta en arbetare som en annan, icke-rotanvändare. I värsta fall kan detta leda till säkra autentiseringsuppgifter för den andra användaren som komprometteras. Den här säkerhetsrisken gäller endast för Apache Storm-installationer med säkerhet aktiverat. |
| Åtgärd: Uppgradera till HDP-2.6.2.1 eftersom det för närvarande inte finns några lösningar. |
CVE-2016-4970
| Sammanfattning: handler/ssl/OpenSslEngine.java i Netty 4.0.x före 4.0.37. Final och 4.1.x före 4.1.1. Final gör det möjligt för fjärranslutna angripare att orsaka en Denial of Service (oändlig loop) |
|---|
| Allvarlighetsgrad: Måttlig |
| Leverantör: Hortonworks |
| Versioner som påverkas: HDP 2.x.x sedan 2.3.x |
| Användare som påverkas: Alla användare som använder HDFS. |
| Effekt: Effekten är låg eftersom Hortonworks inte använder OpenSslEngine.java direkt i Hadoop-kodbasen. |
| Rekommenderad åtgärd: Uppgradera till HDP 2.6.3. |
CVE-2016-8746
| Sammanfattning: Problem med matchning av Apache Ranger-sökväg i principutvärdering |
|---|
| Allvarlighetsgrad: Normal |
| Leverantör: Hortonworks |
| Versioner som påverkas: Alla HDP 2.5-versioner inklusive Apache Ranger-versionerna 0.6.0/0.6.1/0.6.2 |
| Användare som påverkas: Alla användare av verktyget för rangerprincipadministratör. |
| Effekt: Ranger-principmotorn matchar felaktigt sökvägar under vissa villkor när en princip innehåller jokertecken och rekursiva flaggor. |
| Åtgärda detaljer: Fast principutvärderingslogik |
| Rekommenderad åtgärd: Användare bör uppgradera till HDP 2.5.4+ (med Apache Ranger 0.6.3+) eller HDP 2.6+ (med Apache Ranger 0.7.0+) |
CVE-2016-8751
| Sammanfattning: Problem med att lagra apache ranger-skript mellan webbplatser |
|---|
| Allvarlighetsgrad: Normal |
| Leverantör: Hortonworks |
| Versioner som påverkas: Alla HDP 2.3/2.4/2.5-versioner inklusive Apache Ranger-versioner 0.5.x/0.6.0/0.6.1/0.6.2 |
| Användare som påverkas: Alla användare av verktyget för rangerprincipadministratör. |
| Effekt: Apache Ranger är sårbar för ett lagrat skript mellan webbplatser när anpassade principvillkor anges. Administratörsanvändare kan lagra vissa godtyckliga JavaScript-kod som körs när vanliga användare loggar in och kommer åt principer. |
| Korrigeringsinformation: Logik har lagts till för att sanera användarindata. |
| Rekommenderad åtgärd: Användare bör uppgradera till HDP 2.5.4+ (med Apache Ranger 0.6.3+) eller HDP 2.6+ (med Apache Ranger 0.7.0+) |
Problem med support har åtgärdats
Problem som har åtgärdats representerar valda problem som tidigare loggats via Hortonworks Support, men som nu åtgärdas i den aktuella versionen. Dessa problem kan ha rapporterats i tidigare versioner i avsnittet Kända problem. vilket innebär att de rapporterades av kunder eller identifierades av Hortonworks kvalitetstekniker.
Felaktiga resultat
| Fel-ID | Apache JIRA | Sammanfattning |
|---|---|---|
| BUG-100019 | YARN-8145 | yarn rmadmin -getGroups returnerar inte uppdaterade grupper för användare |
| BUG-100058 | PHOENIX-2645 | Jokertecken matchar inte nya tecken |
| BUG-100266 | PHOENIX-3521, PHOENIX-4190 | Resultat fel med lokala index |
| BUGG-88774 | HIVE-17617, HIVE-18413, HIVE-18523 | query36 misslyckas, radantalet matchar inte |
| BUG-89765 | HIVE-17702 | felaktig isRepeating-hantering i decimalläsare i ORC |
| BUG-92293 | HADOOP-15042 | Azure PageBlobInputStream.skip() kan returnera negativt värde när numberOfPagesRemaining är 0 |
| BUG-92345 | ATLAS-2285 | Användargränssnitt: Namn på sparad sökning med datumattribut. |
| BUG-92563 | HIVE-17495, HIVE-18528 | Aggregerad statistik i ObjectStore får fel resultat |
| BUG-92957 | HIVE-11266 | count(*) fel resultat baserat på tabellstatistik för externa tabeller |
| BUG-93097 | RANGER-1944 | Åtgärdsfiltret för administratörsgranskning fungerar inte |
| BUG-93335 | HIVE-12315 | vectorization_short_regress.q har fel resultatproblem för en dubbel beräkning |
| BUG-93415 | HIVE-18258, HIVE-18310 | Vektorisering: Reduce-Side GROUP BY MERGEPARTIAL med duplicerade kolumner är bruten |
| BUG-93939 | ATLAS-2294 | Extra parametern "description" har lagts till när du skapar en typ |
| BUG-94007 | PHOENIX-1751, PHOENIX-3112 | Phoenix-frågor returnerar Null-värden på grund av partiella HBase-rader |
| BUG-94266 | HIVE-12505 | Det går inte att ta bort vissa befintliga filer i samma krypterade zon utan att infoga överskrivning i samma krypterade zon |
| BUG-94414 | HIVE-15680 | Felaktiga resultat när hive.optimize.index.filter=true och samma ORC-tabell refereras två gånger i frågan |
| BUG-95048 | HIVE-18490 | Fråga med EXISTS och NOT EXISTS med icke-equi-predikat kan ge fel resultat |
| BUG-95053 | PHOENIX-3865 | IS NULL returnerar inte korrekta resultat när den första kolumnfamiljen inte filtreras mot |
| BUG-95476 | RANGER-1966 | Principmotorinitiering skapar inte kontextberikare i vissa fall |
| BUG-95566 | SPARK-23281 | Frågan ger resultat i felaktig ordning när en sammansatt order by-sats refererar till både ursprungliga kolumner och alias |
| BUG-95907 | PHOENIX-3451, PHOENIX-3452, PHOENIX-3469, PHOENIX-4560 | Åtgärda problem med ORDER BY ASC när frågan har sammansättning |
| BUG-96389 | PHOENIX-4586 | UPSERT SELECT tar inte hänsyn till jämförelseoperatorer för underfrågor. |
| BUG-96602 | HIVE-18660 | PCR skiljer inte mellan partitioner och virtuella kolumner |
| BUG-97686 | ATLAS-2468 | [Grundläggande sökning] Problem med OR-fall när NEQ används med numeriska typer |
| BUG-97708 | HIVE-18817 | ArrayIndexOutOfBounds-undantag vid läsning av ACID-tabellen. |
| BUG-97864 | HIVE-18833 | Automatisk sammanfogning misslyckas när "infoga i katalogen som orcfile" |
| BUG-97889 | RANGER-2008 | Principutvärderingen misslyckas för principvillkor med flera ledningar. |
| BUG-98655 | RANGER-2066 | HBase-kolumnfamiljens åtkomst auktoriseras av en taggad kolumn i kolumnfamiljen |
| BUG-99883 | HIVE-19073, HIVE-19145 | StatsOptimizer kan mangla konstanta kolumner |
Övrigt
| Fel-ID | Apache JIRA | Sammanfattning |
|---|---|---|
| BUG-100267 | HBASE-17170 | HBase försöker också göra om DoNotRetryIOException på grund av klassinläsningsskillnader. |
| BUG-92367 | YARN-7558 | Kommandot "yarn logs" kan inte hämta loggar för containrar som körs om UI-autentisering är aktiverat. |
| BUG-93159 | OOZIE-3139 | Oozie validerar arbetsflödet felaktigt |
| BUG-93936 | ATLAS-2289 | Inbäddad start-/stoppkod för kafka/zookeeper-server som ska flyttas från KafkaNotification-implementeringen |
| BUG-93942 | ATLAS-2312 | Använd ThreadLocal DateFormat-objekt för att undvika samtidig användning från flera trådar |
| BUG-93946 | ATLAS-2319 | Användargränssnitt: Ta bort en tagg som vid 25+ position i tagglistan i både flat- och trädstruktur behöver uppdateras för att ta bort taggen från listan. |
| BUG-94618 | YARN-5037, YARN-7274 | Möjlighet att inaktivera elasticitet på lövkönivå |
| BUG-94901 | HBASE-19285 | Lägga till histogram för svarstid per tabell |
| BUG-95259 | HADOOP-15185, HADOOP-15186 | Uppdatera adls anslutningsappen för att använda den aktuella versionen av ADLS SDK |
| BUG-95619 | HIVE-18551 | Vektorisering: VectorMapOperator försöker skriva för många vektorkolumner för Hybrid Grace |
| BUG-97223 | SPARK-23434 | Spark bör inte varna "metadatakatalog" för en HDFS-filsökväg |
Prestanda
| Fel-ID | Apache JIRA | Sammanfattning |
|---|---|---|
| BUG-83282 | HBASE-13376, HBASE-14473, HBASE-15210, HBASE-15515, HBASE-16570, HBASE-16810, HBASE-18164 | Snabb lokaliseringsberäkning i balancer |
| BUG-91300 | HBASE-17387 | Minska kostnaderna för undantagsrapport i RegionActionResult för multi() |
| BUG-91804 | TEZ-1526 | LoadingCache för TezTaskID långsamt för stora jobb |
| BUG-92760 | ACCUMULO-4578 | Avbryt komprimeringsåtgärden FATE släpper inte namnområdeslåset |
| BUG-93577 | RANGER-1938 | Solr for Audit-konfigurationen använder inte DocValues effektivt |
| BUG-93910 | HIVE-18293 | Hive kan inte komprimera tabeller som finns i en mapp som inte ägs av identitet som kör HiveMetaStore |
| BUG-94345 | HIVE-18429 | Komprimering bör hantera ett skiftläge när det inte ger några utdata |
| BUG-94381 | HADOOP-13227, HDFS-13054 | Hantering av RequestHedgingProxyProvider RetryAction-ordning: FÖRSÖK << igen FAILOVER_AND_RETRY. |
| BUG-94432 | HIVE-18353 | CompactorMR ska anropa jobclient.close() för att utlösa rensning |
| BUG-94869 | PHOENIX-4290, PHOENIX-4373 | Begärd rad som inte ligger inom intervallet för Get on HRegion för den lokala indexerade saltade Phoenix-tabellen. |
| BUG-94928 | HDFS-11078 | Åtgärda NPE i LazyPersistFileScrubber |
| BUG-94964 | HIVE-18269, HIVE-18318, HIVE-18326 | Flera LLAP-korrigeringar |
| BUG-95669 | HIVE-18577, HIVE-18643 | När du kör uppdaterings-/borttagningsfrågan i ACID-partitionerad tabell läser HS2 alla varje partition. |
| BUG-96390 | HDFS-10453 | ReplicationMonitor-tråden kan fastna länge på grund av loppet mellan replikeringen och ta bort samma fil i ett stort kluster. |
| BUG-96625 | HIVE-16110 | Återgå till "Vectorization: Support 2 Value CASE WHEN instead of fallback to VectorUDFAdaptor" (Återställning till VectorUDFAdaptor) |
| BUG-97109 | HIVE-16757 | Användning av inaktuella getRows() i stället för ny estimateRowCount(RelMetadataQuery...) har allvarliga prestandaeffekter |
| BUG-97110 | PHOENIX-3789 | Köra anrop för indexunderhåll mellan regioner i postBatchMutateIndispensably |
| BUG-98833 | YARN-6797 | TimelineWriter förbrukar inte postsvaret helt |
| BUG-98931 | ATLAS-2491 | Uppdatera Hive-kroken för att använda Atlas v2-meddelanden |
Potentiell dataförlust
| Fel-ID | Apache JIRA | Sammanfattning |
|---|---|---|
| BUG-95613 | HBASE-18808 | Ineffektiv konfigurationskontroll BackupLogCleaner#getDeletableFiles() |
| BUG-97051 | HIVE-17403 | Felsammanfogning för ohanterade tabeller och transaktionstabeller |
| BUG-97787 | HIVE-18460 | Komprimatorn skickar inte tabellegenskaper till Orc-skrivaren |
| BUG-97788 | HIVE-18613 | Utöka JsonSerDe för att stödja BINÄR typ |
Frågefel
| Fel-ID | Apache JIRA | Sammanfattning |
|---|---|---|
| BUG-100180 | CALCITE-2232 | Kontrollfel på AggregatePullUpConstantsRule vid justering av aggregerade index |
| BUG-100422 | HIVE-19085 | FastHiveDecimal abs(0) anger tecken till +ve |
| BUG-100834 | PHOENIX-4658 | IllegalStateException: requestSeek kan inte anropas på ReverseKeyValueHeap |
| BUG-102078 | HIVE-17978 | TPCDS-frågor 58 och 83 genererar undantag i vektorisering. |
| BUG-92483 | HIVE-17900 | analysera statistik på kolumner som utlöses av Compactor genererar felformad SQL med > 1 partitionskolumn |
| BUG-93135 | HIVE-15874, HIVE-18189 | Hive-fråga returnerar fel resultat när du anger hive.groupby.orderby.position.alias till true |
| BUG-93136 | HIVE-18189 | Order efter position fungerar inte när cbo är inaktiverat |
| BUG-93595 | HIVE-12378, HIVE-15883 | HBase-mappad tabell i Hive-infogning misslyckas för decimaler och binära kolumner |
| BUG-94007 | PHOENIX-1751, PHOENIX-3112 | Phoenix-frågor returnerar Null-värden på grund av partiella HBase-rader |
| BUG-94144 | HIVE-17063 | infoga överskrivningspartition i en extern tabell misslyckas när släpppartitionen först |
| BUG-94280 | HIVE-12785 | Visa med uniontyp och UDF för att "kasta" structen är bruten |
| BUG-94505 | PHOENIX-4525 | Heltalsspill i GroupBy-körning |
| BUG-95618 | HIVE-18506 | LlapBaseInputFormat – negativt matrisindex |
| BUG-95644 | HIVE-9152 | CombineHiveInputFormat: Hive-frågan misslyckas i Tez med java.lang.IllegalArgumentException-undantag |
| BUG-96762 | PHOENIX-4588 | Klona uttryck även om dess underordnade har Determinism.PER_INVOCATION |
| BUG-97145 | HIVE-12245, HIVE-17829 | Stödkolumnkommentar för en HBase-stödd tabell |
| BUG-97741 | HIVE-18944 | Placering av grupperingsuppsättningar anges felaktigt under DPP |
| BUG-98082 | HIVE-18597 | LLAP: Paketera alltid API-jar-filen log4j2 för org.apache.log4j |
| BUG-99849 | Ej tillämpligt | Skapa en ny tabell från en filguide försöker använda standarddatabasen |
Säkerhet
| Fel-ID | Apache JIRA | Sammanfattning |
|---|---|---|
| BUG-100436 | RANGER-2060 | Knox proxy med knox-sso fungerar inte för ranger |
| BUG-101038 | SPARK-24062 | Zeppelin %Spark-tolken "Anslut ion vägrade"-fel: "En hemlig nyckel måste anges..." fel i HiveThriftServer |
| BUG-101359 | ACCUMULO-4056 | Uppdatera versionen av commons-collection till 3.2.2 när den släpps |
| BUG-54240 | HIVE-18879 | Tillåt inte inbäddade element i UDFXPathUtil måste fungera om xercesImpl.jar i classpath |
| BUG-79059 | OOZIE-3109 | Escape-loggströmningens HTML-specifika tecken |
| BUG-90041 | OOZIE-2723 | JSON.org licensen är nu CatX |
| BUG-93754 | RANGER-1943 | Ranger Solr-auktorisering hoppas över när samlingen är tom eller null |
| BUG-93804 | HIVE-17419 | ANALYSERA TABELL... KOMMANDOT COMPUTE STATISTICS FOR COLUMNS (BERÄKNINGSSTATISTIK FÖR KOLUMNER) visar beräknad statistik för maskerade tabeller |
| BUG-94276 | ZEPPELIN-3129 | Zeppelin-användargränssnittet loggar inte ut i IE |
| BUG-95349 | ZOOKEEPER-1256, ZOOKEEPER-1901 | Uppgradera netty |
| BUG-95483 | Ej tillämpligt | Korrigering för CVE-2017-15713 |
| BUG-95646 | OOZIE-3167 | Uppgradera tomcat-versionen på grenen Oozie 4.3 |
| BUG-95823 | Ej tillämpligt | Knox:Uppgradera Beanutils |
| BUG-95908 | RANGER-1960 | HBase-autentisering tar inte hänsyn till tabellnamnområdet vid borttagning av ögonblicksbilder |
| BUG-96191 | FALCON-2322, FALCON-2323 | Uppgradera Jackson- och Spring-versioner för att undvika säkerhetsrisker |
| BUG-96502 | RANGER-1990 | Lägg till enkelriktad SSL MySQL-stöd i Ranger Admin |
| BUG-96712 | FLUME-3194 | uppgradera derby till den senaste versionen (1.14.1.0) |
| BUG-96713 | FLUME-2678 | Uppgradera xalan till 2.7.2 för att ta hand om CVE-2014-0107-sårbarhet |
| BUG-96714 | FLUME-2050 | Uppgradera till log4j2 (när GA) |
| BUG-96737 | Ej tillämpligt | Använda Java io-filsystemmetoder för att komma åt lokala filer |
| BUG-96925 | Ej tillämpligt | Uppgradera Tomcat från 6.0.48 till 6.0.53 i Hadoop |
| BUG-96977 | FLUME-3132 | Uppgradera beroenden för tomcat-bibliotek jasper |
| BUG-97022 | HADOOP-14799, HADOOP-14903, HADOOP-15265 | Uppgradera Nimbus-JOSE-JWT-biblioteket med version ovan 4.39 |
| BUG-97101 | RANGER-1988 | Åtgärda osäker slumpmässighet |
| BUG-97178 | ATLAS-2467 | Beroendeuppgradering för Spring och nimbus-jose-jwt |
| BUG-97180 | Ej tillämpligt | Uppgradera Nimbus-jose-jwt |
| BUG-98038 | HIVE-18788 | Rensa indata i JDBC PreparedStatement |
| BUG-98353 | HADOOP-13707 | Återställ "Om kerberos är aktiverat medan HTTP SPNEGO inte har konfigurerats kan vissa länkar inte nås" |
| BUG-98372 | HBASE-13848 | Åtkomst till InfoServer SSL-lösenord via API för autentiseringsprovider |
| BUG-98385 | ATLAS-2500 | Lägg till fler rubriker i Atlas-svaret. |
| BUG-98564 | HADOOP-14651 | Uppdatera okhttp-versionen till 2.7.5 |
| BUG-99440 | RANGER-2045 | Hive-tabellkolumner utan explicit tillåtna principer visas med kommandot "desc table" |
| BUG-99803 | Ej tillämpligt | Oozie bör inaktivera dynamisk HBase-klassinläsning |
Stabilitet
| Fel-ID | Apache JIRA | Sammanfattning |
|---|---|---|
| BUG-100040 | ATLAS-2536 | NPE i Atlas Hive Hook |
| BUG-100057 | HIVE-19251 | ObjectStore.getNextNotification med LIMIT bör använda mindre minne |
| BUG-100072 | HIVE-19130 | NPE utlöses när REPL LOAD tillämpad släpppartitionshändelse. |
| BUG-100073 | Ej tillämpligt | för många close_wait anslutningar från hiveserver till datanod |
| BUG-100319 | HIVE-19248 | REPL LOAD utlöser inget fel om filkopian misslyckas. |
| BUG-100352 | Ej tillämpligt | CLONE – RM rensar logikgenomsökningar/register-znode för ofta |
| BUG-100427 | HIVE-19249 | Replikering: WITH-satsen skickar inte konfigurationen till Uppgift korrekt i alla fall |
| BUG-100430 | HIVE-14483 | java.lang.ArrayIndexOutOfBoundsException org.apache.orc.impl.TreeReaderFactory$BytesColumnVectorUtil.commonReadByteArrays |
| BUG-100432 | HIVE-19219 | Inkrementell REPL DUMP bör utlösa fel om begärda händelser rensas. |
| BUG-100448 | SPARK-23637, SPARK-23802, SPARK-23809, SPARK-23816, SPARK-23822, SPARK-23823, SPARK-23838, SPARK-23881 | Uppdatera Spark2 till 2.3.0+ (4/11) |
| BUG-100740 | HIVE-16107 | JDBC: HttpClient bör försöka igen en gång till på NoHttpResponseException |
| BUG-100810 | HIVE-19054 | Hive Functions-replikering misslyckas |
| BUG-100937 | MAPREDUCE-6889 | Lägg till Job#close API för att stänga av MR-klienttjänster. |
| BUG-101065 | ATLAS-2587 | Ange läs-ACL för /apache_atlas/active_server_info znode i HA för Knox att proxy ska läsas. |
| BUG-101093 | STORM-2993 | Storm HDFS-bult kastar ClosedChannelException när principen för tidsrotation används |
| BUG-101181 | Ej tillämpligt | PhoenixStorageHandler hanterar inte AND i predikat korrekt |
| BUG-101266 | PHOENIX-4635 | HBase Anslut ion läcka i org.apache.phoenix.hive.mapreduce.PhoenixInputFormat |
| BUG-101458 | HIVE-11464 | ursprungsinformation saknas om det finns flera utdata |
| BUG-101485 | Ej tillämpligt | hive metastore thrift api är långsamt och orsakar klienten timeout |
| BUG-101628 | HIVE-19331 | Hive-inkrementell replikering till molnet misslyckades. |
| BUG-102048 | HIVE-19381 | Hive-funktionsreplikering till molnet misslyckas med FunctionTask |
| BUG-102064 | Ej tillämpligt | Hive Replication-tester \[ onprem to onprem \] misslyckades i ReplCopyTask |
| BUG-102137 | HIVE-19423 | Hive Replication-tester \[ Onprem to Cloud \] misslyckades i ReplCopyTask |
| BUG-102305 | HIVE-19430 | HS2- och hive-metaarkivet OOM dumpar |
| BUG-102361 | Ej tillämpligt | flera infogningsresultat i enkel infogning som replikeras till hive-målklustret ( onprem - s3 ) |
| BUG-87624 | Ej tillämpligt | Aktivering av stormhändelseloggning gör att arbetare kontinuerligt dör |
| BUG-88929 | HBASE-15615 | Fel vilotid när RegionServerCallable behöver försöka igen |
| BUG-89628 | HIVE-17613 | ta bort objektpooler för korta allokeringar med samma tråd |
| BUG-89813 | Ej tillämpligt | SCA: Kodkorrigering: Icke-synkroniserad metod åsidosätter synkroniserad metod |
| BUG-90437 | ZEPPELIN-3072 | Zeppelin-användargränssnittet blir långsamt/svarar inte om det finns för många notebook-filer |
| BUG-90640 | HBASE-19065 | HRegion#bulkLoadHFiles() bör vänta tills samtidig region#flush() har slutförts |
| BUG-91202 | HIVE-17013 | Ta bort begäran med en underfråga baserat på val över en vy |
| BUG-91350 | KNOX-1108 | NiFiHaDispatch reder inte över |
| BUG-92054 | HIVE-13120 | sprida doA vid generering av ORC-delningar |
| BUG-92373 | FALCON-2314 | Bump TestNG-version till 6.13.1 för att undvika BeanShell-beroende |
| BUG-92381 | Ej tillämpligt | testContainerLogsWithNewAPI och testContainerLogsWithOldAPI UT misslyckas |
| BUG-92389 | STORM-2841 | testNoAcksIfFlushFails UT misslyckas med NullPointerException |
| BUG-92586 | SPARK-17920, SPARK-20694, SPARK-21642, SPARK-22162, SPARK-22289, SPARK-22373, SPARK-22495, SPARK-22574, SPARK-22591, SPARK-22595, SPARK-22601, SPARK-22603, SPARK-22607, SPARK-22635, SPARK-22637, SPARK-22653, SPARK-22654, SPARK-22686, SPARK-22688, SPARK-22817, SPARK-22862, SPARK-22889, SPARK-22972, SPARK-22975, SPARK-22982, SPARK-22983, SPARK-22984, SPARK-23001, SPARK-23038, SPARK-23095 | Uppdatera Spark2 uppdaterad till 2.2.1 (16 januari) |
| BUG-92680 | ATLAS-2288 | NoClassDefFoundError-undantag vid körning av import-hive-skript när hbase-tabellen skapas via Hive |
| BUG-92760 | ACCUMULO-4578 | Avbryt komprimeringsåtgärden FATE släpper inte namnområdeslåset |
| BUG-92797 | HDFS-10267, HDFS-8496 | Minska datanodlåskonkurrationerna i vissa användningsfall |
| BUG-92813 | FLUME-2973 | Dödläge i hdfs-mottagare |
| BUG-92957 | HIVE-11266 | count(*) fel resultat baserat på tabellstatistik för externa tabeller |
| BUG-93018 | ATLAS-2310 | I HA omdirigerar den passiva noden begäran med fel URL-kodning |
| BUG-93116 | RANGER-1957 | Ranger Usersync synkroniserar inte användare eller grupper regelbundet när inkrementell synkronisering är aktiverad. |
| BUG-93361 | HIVE-12360 | Felaktig sök i okomprimerad ORC med predikatnedtryckning |
| BUG-93426 | CALCITE-2086 | HTTP/413 under vissa omständigheter på grund av stora auktoriseringshuvuden |
| BUG-93429 | PHOENIX-3240 | ClassCastException från Pig-inläsaren |
| BUG-93485 | Ej tillämpligt | can't get table mytestorg.apache.hadoop.hive.ql.metadata.InvalidTableException: Tabellen hittades inte när du kör analysera tabell på kolumner i LLAP |
| BUG-93512 | PHOENIX-4466 | java.lang.RuntimeException: svarskod 500 – Köra ett Spark-jobb för att ansluta till Phoenix-frågeservern och läsa in data |
| BUG-93550 | Ej tillämpligt | Zeppelin %spark.r fungerar inte med spark1 på grund av skalningsversionsmatchning |
| BUG-93910 | HIVE-18293 | Hive kan inte komprimera tabeller som finns i en mapp som inte ägs av identitet som kör HiveMetaStore |
| BUG-93926 | ZEPPELIN-3114 | Notebook-filer och tolkar sparas inte i zeppelin efter >1d-stresstestning |
| BUG-93932 | ATLAS-2320 | klassificering "*" med frågan genererar 500 Internt serverfel. |
| BUG-93948 | YARN-7697 | NM slutar med OOM på grund av läckage i loggaggregering (del 1) |
| BUG-93965 | ATLAS-2229 | DSL-sökning: orderby icke-strängattribut genererar undantag |
| BUG-93986 | YARN-7697 | NM slutar fungera med OOM på grund av läckage i loggaggregering (del 2) |
| BUG-94030 | ATLAS-2332 | Det går inte att skapa en typ med attribut med kapslad insamlingsdatatyp |
| BUG-94080 | YARN-3742, YARN-6061 | Båda RM är i vänteläge i ett säkert kluster |
| BUG-94081 | HIVE-18384 | ConcurrentModificationException i log4j2.x biblioteket |
| BUG-94168 | Ej tillämpligt | Yarn RM går ner med Service Registry är i fel tillstånd FEL |
| BUG-94330 | HADOOP-13190, HADOOP-14104, HADOOP-14814, HDFS-10489, HDFS-11689 | HDFS bör ha stöd för flera KMS Uris |
| BUG-94345 | HIVE-18429 | Komprimering bör hantera ett skiftläge när det inte ger några utdata |
| BUG-94372 | ATLAS-2229 | DSL-fråga: hive_table namn = ["t1","t2"] genererar ogiltigt DSL-frågefel |
| BUG-94381 | HADOOP-13227, HDFS-13054 | Hantering av RequestHedgingProxyProvider RetryAction-ordning: FÖRSÖK << igen FAILOVER_AND_RETRY. |
| BUG-94432 | HIVE-18353 | CompactorMR ska anropa jobclient.close() för att utlösa rensning |
| BUG-94575 | SPARK-22587 | Spark-jobbet misslyckas om fs.defaultFS och program jar är olika URL |
| BUG-94791 | SPARK-22793 | Minnesläcka i Spark Thrift Server |
| BUG-94928 | HDFS-11078 | Åtgärda NPE i LazyPersistFileScrubber |
| BUG-95013 | HIVE-18488 | LLAP ORC-läsare saknar några null-kontroller |
| BUG-95077 | HIVE-14205 | Hive stöder inte unionstyp med AVRO-filformat |
| BUG-95200 | HDFS-13061 | SaslDataTransferClient#checkTrustAndSend bör inte lita på en delvis betrodd kanal |
| BUG-95201 | HDFS-13060 | Lägga till en BlacklistBasedTrustedChannelResolver för TrustedChannelResolver |
| BUG-95284 | HBASE-19395 | [branch-1] TestEndToEndSplitTransaction.testMasterOpsWhileSplitting misslyckas med NPE |
| BUG-95301 | HIVE-18517 | Vektorisering: Åtgärda VectorMapOperator för att acceptera VRB:er och kontrollera den vektoriserade flaggan korrekt för att stödja LLAP-Cachelagring |
| BUG-95542 | HBASE-16135 | PeerClusterZnode under rs av borttagen peer kanske aldrig tas bort |
| BUG-95595 | HIVE-15563 | Ignorera undantaget för tillståndsövergång för olaglig åtgärd i SQLOperation.runQuery för att exponera verkligt undantag. |
| BUG-95596 | YARN-4126, YARN-5750 | TestClientRMService misslyckas |
| BUG-96019 | HIVE-18548 | Åtgärda log4j import |
| BUG-96196 | HDFS-13120 | Ögonblicksbildsdiff kan skadas efter sammanfogning |
| BUG-96289 | HDFS-11701 | NPE från den olösta värden orsakar permanenta DFSInputStream-fel |
| BUG-96291 | STORM-2652 | Undantag som genereras i öppen JmsSpout-metod |
| BUG-96363 | HIVE-18959 | Undvik att skapa en extra pool med trådar i LLAP |
| BUG-96390 | HDFS-10453 | ReplicationMonitor-tråden kan fastna länge på grund av kapplöpningen mellan replikering och borttagning av samma fil i ett stort kluster. |
| BUG-96454 | YARN-4593 | Deadlock i AbstractService.getConfig() |
| BUG-96704 | FALCON-2322 | ClassCastException när du skickarAndSchedule-feed |
| BUG-96720 | SKJUTREGLAGE-1262 | Skjutreglagets functests misslyckas i Kerberized miljön |
| BUG-96931 | SPARK-23053, SPARK-23186, SPARK-23230, SPARK-23358, SPARK-23376, SPARK-23391 | Uppdatera Spark2 uppdaterad (19 feb) |
| BUG-97067 | HIVE-10697 | ObjectInspectorConvertors#UnionConvertor utför en felaktig konvertering |
| BUG-97244 | KNOX-1083 | HttpClient-standardtimeout bör vara ett förnuftigt värde |
| BUG-97459 | ZEPPELIN-3271 | Alternativ för att inaktivera scheduler |
| BUG-97511 | KNOX-1197 | AnonymousAuthFilter läggs inte till när autentisering=Anonym i tjänsten |
| BUG-97601 | HIVE-17479 | Mellanlagringskataloger rensas inte för uppdaterings-/borttagningsfrågor |
| BUG-97605 | HIVE-18858 | Systemegenskaper i jobbkonfigurationen har inte lösts när mr-jobbet skickas |
| BUG-97674 | OOZIE-3186 | Oozie kan inte använda konfiguration länkad med jceks://file/... |
| BUG-97743 | Ej tillämpligt | java.lang.NoClassDefFoundError-undantag vid distribution av stormtopologi |
| BUG-97756 | PHOENIX-4576 | Korrigering av LocalIndexSplitMergeIT-tester misslyckas |
| BUG-97771 | HDFS-11711 | DN bör inte ta bort blocket På undantagsfelet "För många öppna filer" |
| BUG-97869 | KNOX-1190 | Knox SSO-stöd för Google OIDC är brutet. |
| BUG-97879 | PHOENIX-4489 | HBase Anslut ion läcka i Phoenix MR Jobs |
| BUG-98392 | RANGER-2007 | ranger-tagsyncs Kerberos-biljett kan inte förnyas |
| BUG-98484 | Ej tillämpligt | Hive-inkrementell replikering till molnet fungerar inte |
| BUG-98533 | HBASE-19934, HBASE-20008 | Återställningen av HBase-ögonblicksbilden misslyckas på grund av ett null-pekarfel |
| BUG-98555 | PHOENIX-4662 | NullPointerException i TableResultIterator.java vid cacheåterslutning |
| BUG-98579 | HBASE-13716 | Sluta använda Hadoops FSConstants |
| BUG-98705 | KNOX-1230 | Många samtidiga begäranden som Knox orsakar URL-mangling |
| BUG-98983 | KNOX-1108 | NiFiHaDispatch reder inte över |
| BUG-99107 | HIVE-19054 | Funktionsreplikering ska använda "hive.repl.replica.functions.root.dir" som rot |
| BUG-99145 | RANGER-2035 | Fel vid åtkomst till servicedefs med tom implClass med Oracle-serverdel |
| BUG-99160 | SKJUTREGLAGE-1259 | Skjutreglaget fungerar inte i miljöer med flera hem |
| BUG-99239 | ATLAS-2462 | Sqoop-import för alla tabeller genererar NPE utan tabell som anges i kommandot |
| BUG-99301 | ATLAS-2530 | Newline i början av namnattributet för en hive_process och hive_column_lineage |
| BUG-99453 | HIVE-19065 | Kompatibilitetskontrollen för metaarkivklienten bör innehålla syncMetaStoreClient |
| BUG-99521 | Ej tillämpligt | ServerCache för HashJoin återskapas inte när iteratorer är på nytt underbyggda |
| BUG-99590 | PHOENIX-3518 | Minnesläcka i RenewLeaseTask |
| BUG-99618 | SPARK-23599, SPARK-23806 | Uppdatera Spark2 till 2.3.0+ (3/28) |
| BUG-99672 | ATLAS-2524 | Hive-hook med V2-meddelanden – felaktig hantering av åtgärden "alter view as" |
| BUG-99809 | HBASE-20375 | Ta bort användningen av getCurrentUserCredentials i modulen hbase-spark |
Support
| Fel-ID | Apache JIRA | Sammanfattning |
|---|---|---|
| BUG-87343 | HIVE-18031 | Stöd för replikering för alter database-åtgärden. |
| BUG-91293 | RANGER-2060 | Knox proxy med knox-sso fungerar inte för ranger |
| BUG-93116 | RANGER-1957 | Ranger Usersync synkroniserar inte användare eller grupper regelbundet när inkrementell synkronisering är aktiverad. |
| BUG-93577 | RANGER-1938 | Solr for Audit-konfigurationen använder inte DocValues effektivt |
| BUG-96082 | RANGER-1982 | Felförbättring för analysmått för Ranger Admin och Ranger Kms |
| BUG-96479 | HDFS-12781 | När Datanode du är nere genererar fliken I Namenode användargränssnittet Datanode varningsmeddelande. |
| BUG-97864 | HIVE-18833 | Automatisk sammanfogning misslyckas när "infoga i katalogen som orcfile" |
| BUG-98814 | HDFS-13314 | NameNode bör eventuellt avslutas om FsImage skadas |
Uppgradera
| Fel-ID | Apache JIRA | Sammanfattning |
|---|---|---|
| BUG-100134 | SPARK-22919 | Återställa "Bump Apache httpclient-versioner" |
| BUG-95823 | Ej tillämpligt | Knox:Uppgradera Beanutils |
| BUG-96751 | KNOX-1076 | Uppdatera nimbus-jose-jwt till 4.41.2 |
| BUG-97864 | HIVE-18833 | Automatisk sammanfogning misslyckas när "infoga i katalogen som orcfile" |
| BUG-99056 | HADOOP-13556 | Ändra Configuration.getPropsWithPrefix till att använda getProps i stället för iterator |
| BUG-99378 | ATLAS-2461, ATLAS-2554 | Migreringsverktyg för att exportera Atlas-data i Titan Graph DB |
Användbarhet
| Fel-ID | Apache JIRA | Sammanfattning |
|---|---|---|
| BUG-100045 | HIVE-19056 | IllegalArgumentException i FixAcidKeyIndex när ORC-filen har 0 rader |
| BUG-100139 | KNOX-1243 | Normalisera de nödvändiga DN:er som är konfigurerade i KnoxToken tjänsten |
| BUG-100570 | ATLAS-2557 | Korrigering för att tillåta hadoop-grupper lookupldap när grupper från UGI har angetts felaktigt eller inte är tomma |
| BUG-100646 | ATLAS-2102 | Förbättringar av Atlas-användargränssnittet: Sidan Sökresultat |
| BUG-100737 | HIVE-19049 | Lägg till stöd för Alter table add columns for Druid (Lägg till stöd för Alter table add columns for Druid) |
| BUG-100750 | KNOX-1246 | Uppdatera tjänstkonfigurationen Knox för att stödja de senaste konfigurationerna för Ranger. |
| BUG-100965 | ATLAS-2581 | Regression med V2 Hive-hook-meddelanden: Flytta tabell till en annan databas |
| BUG-84413 | ATLAS-1964 | Användargränssnitt: Stöd för att beställa kolumner i söktabellen |
| BUG-90570 | HDFS-11384, HDFS-12347 | Lägg till alternativ för balancer för att sprida getBlocks-anrop för att undvika NameNodes rpc. CallQueueLength-topp |
| BUG-90584 | HBASE-19052 | FixedFileTrailer bör känna igen klassen CellComparatorImpl i branch-1.x |
| BUG-90979 | KNOX-1224 | Knox Proxy HADispatcher för att stödja Atlas i HA. |
| BUG-91293 | RANGER-2060 | Knox proxy med knox-sso fungerar inte för ranger |
| BUG-92236 | ATLAS-2281 | Spara filterfrågor för tagg/typ-attribut med null-/inte null-filter. |
| BUG-92238 | ATLAS-2282 | Sparad favoritsökning visas bara vid uppdatering efter att den har skapats när det finns över 25 favoritsökningar. |
| BUG-92333 | ATLAS-2286 | Den färdiga typen "kafka_topic" bör inte deklarera attributet ämne som unikt |
| BUG-92678 | ATLAS-2276 | Sökvägsvärdet för entiteten hdfs_path typ är inställt på gemener från hive-bridge. |
| BUG-93097 | RANGER-1944 | Åtgärdsfiltret för administratörsgranskning fungerar inte |
| BUG-93135 | HIVE-15874, HIVE-18189 | Hive-fråga returnerar fel resultat när du anger hive.groupby.orderby.position.alias till true |
| BUG-93136 | HIVE-18189 | Order efter position fungerar inte när cbo är inaktiverat |
| BUG-93387 | HIVE-17600 | Gör OrcFile's "enforceBufferSize" användaruppsättningsbar. |
| BUG-93495 | RANGER-1937 | Ranger tagsync bör bearbeta ENTITY_CREATE meddelande för att stödja atlasimportfunktionen |
| BUG-93512 | PHOENIX-4466 | java.lang.RuntimeException: svarskod 500 – Köra ett Spark-jobb för att ansluta till Phoenix-frågeservern och läsa in data |
| BUG-93801 | HBASE-19393 | HTTP 413 FULL head vid åtkomst till HBase-användargränssnittet med hjälp av SSL. |
| BUG-93804 | HIVE-17419 | ANALYSERA TABELL... KOMMANDOT COMPUTE STATISTICS FOR COLUMNS (BERÄKNINGSSTATISTIK FÖR KOLUMNER) visar beräknad statistik för maskerade tabeller |
| BUG-93932 | ATLAS-2320 | klassificering "*" med frågan genererar 500 Internt serverfel. |
| BUG-93933 | ATLAS-2286 | Den färdiga typen "kafka_topic" bör inte deklarera attributet ämne som unikt |
| BUG-93938 | ATLAS-2283, ATLAS-2295 | Användargränssnittsuppdateringar för klassificeringar |
| BUG-93941 | ATLAS-2296, ATLAS-2307 | Grundläggande sökförbättring för att eventuellt undanta undertypsentiteter och underklassificeringstyper |
| BUG-93944 | ATLAS-2318 | Användargränssnitt: När du klickar på den underordnade taggen två gånger markeras den överordnade taggen |
| BUG-93946 | ATLAS-2319 | Användargränssnitt: Ta bort en tagg som vid 25+ position i tagglistan i både flat- och trädstruktur behöver uppdateras för att ta bort taggen från listan. |
| BUG-93977 | HIVE-16232 | Stöd för statistikberäkning för kolumnen i QuotedIdentifier |
| BUG-94030 | ATLAS-2332 | Det går inte att skapa en typ med attribut med kapslad insamlingsdatatyp |
| BUG-94099 | ATLAS-2352 | Atlas-servern ska tillhandahålla konfiguration för att ange giltighet för Kerberos-delegeringToken |
| BUG-94280 | HIVE-12785 | Visa med uniontyp och UDF för att "kasta" structen är bruten |
| BUG-94332 | SQOOP-2930 | Utökning av Sqoop-jobb som inte överskrider de sparade jobbens allmänna egenskaper |
| BUG-94428 | Ej tillämpligt | DataplaneStöd för Profiler Agent REST API Knox |
| BUG-94514 | ATLAS-2339 | Användargränssnitt: Ändringar i "kolumner" i grundläggande sökresultatvy påverkar även DSL. |
| BUG-94515 | ATLAS-2169 | Borttagningsbegäran misslyckas när hård borttagning har konfigurerats |
| BUG-94518 | ATLAS-2329 | Atlas UI Flera hovrar visas om användaren klickar på en annan tagg som är felaktig |
| BUG-94519 | ATLAS-2272 | Spara tillståndet för de kolumner som dras med hjälp av spara sök-API. |
| BUG-94627 | HIVE-17731 | lägga till ett bakåtalternativ compat för externa användare i HIVE-11985 |
| BUG-94786 | HIVE-6091 | Tomma pipeout filer skapas för att skapa/stänga anslutningen |
| BUG-94793 | HIVE-14013 | Beskriv tabellen visar inte unicode korrekt |
| BUG-94900 | OOZIE-2606, OOZIE-2658, OOZIE-2787, OOZIE-2802 | Ställ in spark.yarn.jars för att åtgärda Spark 2.0 med Oozie |
| BUG-94901 | HBASE-19285 | Lägga till histogram för svarstid per tabell |
| BUG-94908 | ATLAS-1921 | Användargränssnitt: Sök med entitets- och egenskapsattribut: Användargränssnittet utför inte intervallkontroll och tillåter att värden utanför gränserna anges för integral- och flyttaldatatyper. |
| BUG-95086 | RANGER-1953 | förbättring av användargruppssidans lista |
| BUG-95193 | SKJUTREGLAGE-1252 | Skjutreglaget misslyckas med SSL-valideringsfel med Python 2.7.5-58 |
| BUG-95314 | YARN-7699 | queueUsagePercentage kommer som INF för getApp REST API-anrop |
| BUG-95315 | HBASE-13947, HBASE-14517, HBASE-17931 | Tilldela systemtabeller till servrar med högsta version |
| BUG-95392 | ATLAS-2421 | Meddelandeuppdateringar för att stödja V2-datastrukturer |
| BUG-95476 | RANGER-1966 | Principmotorinitiering skapar inte kontextberikare i vissa fall |
| BUG-95512 | HIVE-18467 | stöd för hela lagerdumpen/belastningen + skapa/släppa databashändelser |
| BUG-95593 | Ej tillämpligt | Utöka Oozie DB-verktyg för att stödja Spark2sharelib skapandet |
| BUG-95595 | HIVE-15563 | Ignorera undantaget för tillståndsövergång för olaglig åtgärd i SQLOperation.runQuery för att exponera verkligt undantag. |
| BUG-95685 | ATLAS-2422 | Exportera: Stöd för typbaserad export |
| BUG-95798 | PHOENIX-2714, PHOENIX-2724, PHOENIX-3023, PHOENIX-3040 | Använd inte guideposter för att köra frågor seriellt |
| BUG-95969 | HIVE-16828, HIVE-17063, HIVE-18390 | Partitionerad vy misslyckas med FAILED: IndexOutOfBoundsException Index: 1, Storlek: 1 |
| BUG-96019 | HIVE-18548 | Åtgärda log4j import |
| BUG-96288 | HBASE-14123, HBASE-14135, HBASE-17850 | Backport HBase Backup/Restore 2.0 |
| BUG-96313 | KNOX-1119 | Pac4J OAuth/OpenID-huvudkontot måste vara konfigurerbart |
| BUG-96365 | ATLAS-2442 | Användare med skrivskyddad behörighet på entitetsresurs kan inte utföra grundläggande sökning |
| BUG-96479 | HDFS-12781 | När Datanode du är nere genererar fliken I Namenode användargränssnittet Datanode varningsmeddelande. |
| BUG-96502 | RANGER-1990 | Lägg till enkelriktad SSL MySQL-stöd i Ranger Admin |
| BUG-96718 | ATLAS-2439 | Uppdatera Sqoop-kroken för att använda V2-meddelanden |
| BUG-96748 | HIVE-18587 | infoga DML-händelse kan försöka beräkna en kontrollsumma på kataloger |
| BUG-96821 | HBASE-18212 | I fristående läge med lokala HBase-loggar varningsmeddelande: Det gick inte att anropa metoden "unbuffer" i class org.apache.hadoop.fs.FSDataInputStream |
| BUG-96847 | HIVE-18754 | REPL-STATUS bör ha stöd för "with"-satsen |
| BUG-96873 | ATLAS-2443 | Samla in obligatoriska entitetsattribut i utgående DELETE-meddelanden |
| BUG-96880 | SPARK-23230 | När hive.default.fileformat är andra typer av filtyper orsakar skapa-tabellen textfile ett serde fel |
| BUG-96911 | OOZIE-2571, OOZIE-2792, OOZIE-2799, OOZIE-2923 | Förbättra Tolkning av Spark-alternativ |
| BUG-97100 | RANGER-1984 | HBase-granskningsloggposter kanske inte visar alla taggar som är associerade med den använda kolumnen |
| BUG-97110 | PHOENIX-3789 | Köra anrop för indexunderhåll mellan regioner i postBatchMutateIndispensably |
| BUG-97145 | HIVE-12245, HIVE-17829 | Stödkolumnkommentar för en HBase-stödd tabell |
| BUG-97409 | HADOOP-15255 | Stöd för konvertering av versaler/gemener för gruppnamn i LdapGroupsMapping |
| BUG-97535 | HIVE-18710 | utöka inheritPerms till ACID i Hive 2.X |
| BUG-97742 | OOZIE-1624 | Exkluderingsmönster för sharelib JAR:er |
| BUG-97744 | PHOENIX-3994 | Index-RPC-prioriteten är fortfarande beroende av kontrollantfabriksegenskapen i hbase-site.xml |
| BUG-97787 | HIVE-18460 | Komprimatorn skickar inte tabellegenskaper till Orc-skrivaren |
| BUG-97788 | HIVE-18613 | Utöka JsonSerDe för att stödja BINÄR typ |
| BUG-97899 | HIVE-18808 | Gör komprimering mer robust när statistikuppdateringen misslyckas |
| BUG-98038 | HIVE-18788 | Rensa indata i JDBC PreparedStatement |
| BUG-98383 | HIVE-18907 | Skapa verktyg för att åtgärda problem med acid key-index från HIVE-18817 |
| BUG-98388 | RANGER-1828 | Bra kodningspraxis – lägg till fler rubriker i ranger |
| BUG-98392 | RANGER-2007 | ranger-tagsyncs Kerberos-biljett kan inte förnyas |
| BUG-98533 | HBASE-19934, HBASE-20008 | Återställningen av HBase-ögonblicksbilden misslyckas på grund av ett null-pekarfel |
| BUG-98552 | HBASE-18083, HBASE-18084 | Gör stora/små filer rena trådnummer konfigurerbara i HFileCleaner |
| BUG-98705 | KNOX-1230 | Många samtidiga begäranden som Knox orsakar URL-mangling |
| BUG-98711 | Ej tillämpligt | NiFi-sändning kan inte använda dubbelriktad SSL utan service.xml ändringar |
| BUG-98880 | OOZIE-3199 | Låt systemegenskapsbegränsning konfigureras |
| BUG-98931 | ATLAS-2491 | Uppdatera Hive-kroken för att använda Atlas v2-meddelanden |
| BUG-98983 | KNOX-1108 | NiFiHaDispatch reder inte över |
| BUG-99088 | ATLAS-2511 | Ange alternativ för selektiv import av databas/tabeller från Hive till Atlas |
| BUG-99154 | OOZIE-2844, OOZIE-2845, OOZIE-2858, OOZIE-2885 | Spark-frågan misslyckades med undantaget "java.io.FileNotFoundException: hive-site.xml (nekad behörighet)" |
| BUG-99239 | ATLAS-2462 | Sqoop-import för alla tabeller genererar NPE utan tabell som anges i kommandot |
| BUG-99636 | KNOX-1238 | Åtgärda custom truststore-Inställningar för gateway |
| BUG-99650 | KNOX-1223 | Zeppelins Knox proxy omdirigerar inte /api/ticket som förväntat |
| BUG-99804 | OOZIE-2858 | HiveMain, ShellMain och SparkMain bör inte skriva över egenskaper och konfigurationsfiler lokalt |
| BUG-99805 | OOZIE-2885 | Att köra Spark-åtgärder bör inte behöva Hive på klassökvägen |
| BUG-99806 | OOZIE-2845 | Ersätt reflektionsbaserad kod, som anger variabeln i HiveConf |
| BUG-99807 | OOZIE-2844 | Öka stabiliteten för Oozie-åtgärder när log4j.properties saknas eller inte kan läsas |
| RMP-9995 | AMBARI-22222 | Växla druid till att använda katalogen /var/druid i stället för /apps/druid på den lokala disken |
Förändringar i beteende
| Apache-komponent | Apache JIRA | Sammanfattning | Detaljer |
|---|---|---|---|
| Spark 2.3 | Saknas | Ändringar som dokumenteras i Viktig information om Apache Spark | - Det finns ett "Utfasning" dokument och en "Ändra beteende" guide, https://spark.apache.org/releases/spark-release-2-3-0.html#deprecations – För SQL-delen finns det en annan detaljerad "Migreringsguide" (från 2.2 till 2.3), https://spark.apache.org/docs/latest/sql-programming-guide.html#upgrading-from-spark-sql-22-to-23| |
| Spark | HIVE-12505 | Spark-jobbet har slutförts, men det finns ett fullständigt fel för HDFS-diskkvoten | Scenario: Köra infogad överskrivning när en kvot har angetts i papperskorgen för den användare som kör kommandot. Tidigare beteende: Jobbet lyckas även om det inte går att flytta data till papperskorgen. Resultatet kan felaktigt innehålla några av de data som tidigare fanns i tabellen. Nytt beteende: När flytten till papperskorgen misslyckas tas filerna bort permanent. |
| Kafka 1.0 | Saknas | Ändringar som dokumenteras i Viktig information om Apache Spark | https://kafka.apache.org/10/documentation.html#upgrade_100_notable |
| Hive/Ranger | En annan ranger hive-princip som krävs för INSERT OVERWRITE | Scenario: En annan ranger hive-princip som krävs för INSERT OVERWRITE Tidigare beteende: Hive INSERT OVERWRITE-frågor lyckas som vanligt. Nytt beteende: Hive INSERT OVERWRITE-frågor misslyckas oväntat efter uppgradering till HDP-2.6.x med felet: Fel vid kompilering av instruktion: MISSLYCKADES: HiveAccessControlException-behörighet nekad: användaren jdoe har inte skrivbehörighet för /tmp/*(state=42000,code=40000) Från och med HDP-2.6.0 kräver Hive INSERT OVERWRITE-frågor en Ranger URI-princip för att tillåta skrivåtgärder, även om användaren har skrivbehörighet beviljad via HDFS-principen. Lösning/förväntad kundåtgärd: 1. Skapa en ny princip under Hive-lagringsplatsen. 2. I listrutan där du ser Databasen väljer du URI. 3. Uppdatera sökvägen (exempel: /tmp/*) 4. Lägg till användare och grupp och spara. 5. Försök infoga frågan igen. |
|
| HDFS | Saknas | HDFS bör ha stöd för flera KMS Uris |
Tidigare beteende: egenskapen dfs.encryption.key.provider.uri användes för att konfigurera KMS-providersökvägen. Nytt beteende: dfs.encryption.key.provider.uri är nu inaktuell till förmån för hadoop.security.key.provider.path för att konfigurera KMS-providersökvägen. |
| Zeppelin | ZEPPELIN-3271 | Alternativ för att inaktivera scheduler | Komponent påverkad: Zeppelin-Server Föregående beteende: I tidigare versioner av Zeppelin fanns det inget alternativ för att inaktivera scheduler. Nytt beteende: Som standard ser användarna inte längre schemaläggaren eftersom den är inaktiverad som standard. Lösning/Förväntad kundåtgärd: Om du vill aktivera scheduler måste du lägga till azeppelin.notebook.cron.enable med värdet true under den anpassade zeppelin-webbplatsen i Zeppelin-inställningarna från Ambari. |
Kända problem
HDInsight-integrering med ADLS Gen 2 Det finns två problem med HDInsight ESP-kluster som använder Azure Data Lake Storage Gen 2 med användarkataloger och behörigheter:
Hemkataloger för användare skapas inte på huvudnod 1. Som en lösning skapar du katalogerna manuellt och ändrar ägarskapet till respektive användares UPN.
Behörigheter för katalogen /hdp är för närvarande inte inställda på 751. Detta måste anges till
chmod 751 /hdp chmod –R 755 /hdp/apps
Spark 2.3
[SPARK-23523][SQL] Felaktigt resultat som orsakas av regeln OptimizeMetadataOnlyQuery
[SPARK-23406] Buggar i stream-stream-självkopplingar
Spark-exempelanteckningsböcker är inte tillgängliga när Azure Data Lake Storage (Gen2) är standardlagring av klustret.
Enterprise Security Package
- Spark Thrift Server accepterar inte anslutningar från ODBC-klienter.
Lösningssteg:
- Vänta i ungefär 15 minuter efter att klustret har skapats.
- Kontrollera om det finns hivesampletable_policy i ranger-användargränssnittet.
- Starta om Spark-tjänsten. STS-anslutningen bör fungera nu.
- Spark Thrift Server accepterar inte anslutningar från ODBC-klienter.
Lösningssteg:
Lösning för fel vid ranger-tjänstkontroll
RANGER-1607: Lösning för Ranger-tjänstkontrollfel vid uppgradering till HDP 2.6.2 från tidigare HDP-versioner.
Kommentar
Endast när Ranger är SSL aktiverat.
Det här problemet uppstår när du försöker uppgradera till HDP-2.6.1 från tidigare HDP-versioner via Ambari. Ambari använder ett curl-anrop för att göra en tjänstkontroll till Ranger-tjänsten i Ambari. Om JDK-versionen som används av Ambari är JDK-1.7 misslyckas curl-anropet med felet nedan:
curl: (35) error:14077410:SSL routines:SSL23_GET_SERVER_HELLO:sslv3 alert handshake failureOrsaken till det här felet är att tomcat-versionen som används i Ranger är Tomcat-7.0.7*. Användning av JDK-1.7 står i konflikt med standard chiffer som anges i Tomcat-7.0.7*.
Du kan lösa problemet på två sätt:
Uppdatera JDK:t som används i Ambari från JDK-1.7 till JDK-1.8 (se avsnittet Ändra JDK-versionen i Ambari-referensguiden).
Om du vill fortsätta att stödja en JDK-1.7-miljö:
Lägg till egenskapen ranger.tomcat.ciphers i avsnittet ranger-admin-site i Ambari Ranger-konfigurationen med värdet nedan:
SSL_RSA_WITH_RC4_128_MD5, SSL_RSA_WITH_RC4_128_SHA, TLS_RSA_WITH_AES_128_CBC_SHA, SSL_RSA_WITH_3DES_EDE_CBC_SHA
Om din miljö har konfigurerats för Ranger-KMS lägger du till egenskapen ranger.tomcat.ciphers i avsnittet theranger-kms-site i Ambari Ranger-konfigurationen med värdet nedan:
SSL_RSA_WITH_RC4_128_MD5, SSL_RSA_WITH_RC4_128_SHA, TLS_RSA_WITH_AES_128_CBC_SHA, SSL_RSA_WITH_3DES_EDE_CBC_SHA
Kommentar
De antecknade värdena är arbetsexempel och kanske inte tyder på din miljö. Se till att det sätt som du anger dessa egenskaper på matchar hur din miljö har konfigurerats.
RangerUI: Escape of policy condition text angiven i principformuläret
Komponent som påverkas: Ranger
Beskrivning av problemet
Om en användare vill skapa en princip med anpassade principvillkor och uttrycket eller texten innehåller specialtecken fungerar inte principframtvingandet. Specialtecken konverteras till ASCII innan principen sparas i databasen.
Specialtecken: & <> " ' '
Villkoret tags.attributes['type']='abc' konverteras till följande när principen har sparats.
tags.attds[' dsds'] =' cssdfs'
Du kan se principvillkoret med dessa tecken genom att öppna principen i redigeringsläge.
Lösning
Alternativ nr 1: Skapa/uppdatera princip via Ranger REST API
REST-URL: http://< host>:6080/service/plugins/policies
Skapa en princip med principvillkor:
I följande exempel skapas en princip med taggar som "tags-test" och tilldelas den till en offentlig grupp med principvillkoret astags.attr['type']=='abc' genom att välja alla hive-komponentbehörigheter som att välja, uppdatera, skapa, släppa, ändra, indexera, låsa, allt.
Exempel:
curl -H "Content-Type: application/json" -X POST http://localhost:6080/service/plugins/policies -u admin:admin -d '{"policyType":"0","name":"P100","isEnabled":true,"isAuditEnabled":true,"description":"","resources":{"tag":{"values":["tags-test"],"isRecursive":"","isExcludes":false}},"policyItems":[{"groups":["public"],"conditions":[{"type":"accessed-after-expiry","values":[]},{"type":"tag-expression","values":["tags.attr['type']=='abc'"]}],"accesses":[{"type":"hive:select","isAllowed":true},{"type":"hive:update","isAllowed":true},{"type":"hive:create","isAllowed":true},{"type":"hive:drop","isAllowed":true},{"type":"hive:alter","isAllowed":true},{"type":"hive:index","isAllowed":true},{"type":"hive:lock","isAllowed":true},{"type":"hive:all","isAllowed":true}]}],"denyPolicyItems":[],"allowExceptions":[],"denyExceptions":[],"service":"tagdev"}'Uppdatera befintlig princip med principvillkor:
I följande exempel uppdateras principen med taggar som "tags-test" och tilldelar den till "offentlig" grupp med principvillkoret astags.attr['type']=='abc' genom att välja alla hive-komponentbehörigheter som att välja, uppdatera, skapa, släppa, ändra, indexera, låsa, alla.
REST-URL: http://< host-name>:6080/service/plugins/policies/<policy-id>
Exempel:
curl -H "Content-Type: application/json" -X PUT http://localhost:6080/service/plugins/policies/18 -u admin:admin -d '{"id":18,"guid":"ea78a5ed-07a5-447a-978d-e636b0490a54","isEnabled":true,"createdBy":"Admin","updatedBy":"Admin","createTime":1490802077000,"updateTime":1490802077000,"version":1,"service":"tagdev","name":"P0101","policyType":0,"description":"","resourceSignature":"e5fdb911a25aa7f77af5a9546938d9ed","isAuditEnabled":true,"resources":{"tag":{"values":["tags"],"isExcludes":false,"isRecursive":false}},"policyItems":[{"accesses":[{"type":"hive:select","isAllowed":true},{"type":"hive:update","isAllowed":true},{"type":"hive:create","isAllowed":true},{"type":"hive:drop","isAllowed":true},{"type":"hive:alter","isAllowed":true},{"type":"hive:index","isAllowed":true},{"type":"hive:lock","isAllowed":true},{"type":"hive:all","isAllowed":true}],"users":[],"groups":["public"],"conditions":[{"type":"ip-range","values":["tags.attributes['type']=abc"]}],"delegateAdmin":false}],"denyPolicyItems":[],"allowExceptions":[],"denyExceptions":[],"dataMaskPolicyItems":[],"rowFilterPolicyItems":[]}'Alternativ 2: Tillämpa JavaScript-ändringar
Steg för att uppdatera JS-filen:
Ta reda på PermissionList.js under /usr/hdp/current/ranger-admin
Ta reda på definitionen av funktionen renderPolicyCondtion (rad nr: 404).
Ta bort följande rad från den funktionen, d.v.s. under visningsfunktionen(rad nr: 434)
val = _.escape(val);//Rad nr:460
När du har tagit bort ovanstående rad kan du med Ranger-användargränssnittet skapa principer med principvillkor som kan innehålla specialtecken och principutvärderingen lyckas för samma princip.
HDInsight-integrering med ADLS Gen 2: Problem med användarkataloger och behörigheter med ESP-kluster 1. Hemkataloger för användare skapas inte på huvudnod 1. Lösningen är att skapa dessa manuellt och ändra ägarskapet till respektive användares UPN. 2. Behörigheter för /hdp är för närvarande inte inställda på 751. Detta måste anges till a. chmod 751 /hdp b. chmod –R 755 /hdp/apps
Inaktualitet
OMS-portalen: Vi har tagit bort länken från HDInsight-resurssidan som pekade på OMS-portalen. Azure Monitor-loggarna använde ursprungligen en egen portal som kallas OMS-portalen för att hantera konfigurationen och analysera insamlade data. Alla funktioner från den här portalen har flyttats till Azure-portalen där den fortsätter att utvecklas. HDInsight har föråldrat stödet för OMS-portalen. Kunder använder HDInsight Azure Monitor-loggintegrering i Azure-portalen.
Spark 2.3:Spark Release 2.3.0 utfasningar
Uppgradering
Alla dessa funktioner är tillgängliga i HDInsight 3.6. Om du vill hämta den senaste versionen av Spark, Kafka och R Server (Machine Learning Services) väljer du versionen Spark, Kafka, ML Services när du skapar ett HDInsight 3.6-kluster. För att få stöd för ADLS kan du välja ADLS-lagringstyp som ett alternativ. Befintliga kluster uppgraderas inte automatiskt till dessa versioner.
Alla nya kluster som skapats efter juni 2018 kommer automatiskt att få över 1 000 felkorrigeringar i alla projekt med öppen källkod. Följ den här guiden för metodtips för att uppgradera till en nyare HDInsight-version.