AI med dataflöden
Den här artikeln visar hur du kan använda artificiell intelligens (AI) med dataflöden. I den här artikeln beskrivs:
- Cognitive Services
- Automatiserad maskininlärning
- Azure Machine Learning-integrering
Cognitive Services i Power BI
Med Cognitive Services i Power BI kan du använda olika algoritmer från Azure Cognitive Services för att utöka dina data i självbetjäningsdataförberedelser för dataflöden.
De tjänster som stöds idag är attitydanalys, extrahering av nyckelfraser, språkidentifiering och bildtaggning. Omvandlingarna körs på Power BI-tjänst och kräver ingen Azure Cognitive Services-prenumeration. Den här funktionen kräver Power BI Premium.
Aktivera AI-funktioner
Kognitiva tjänster stöds för Premium-kapacitetsnoder EM2, A2 eller P1 och andra noder med fler resurser. Kognitiva tjänster är också tillgängliga med en PPU-licens (Premium Per User). En separat AI-arbetsbelastning på kapaciteten används för att köra kognitiva tjänster. Innan du använder kognitiva tjänster i Power BI måste AI-arbetsbelastningen aktiveras i kapacitetsinställningarna i administratörsportalen. Du kan aktivera AI-arbetsbelastningen i avsnittet arbetsbelastningar och definiera den maximala mängd minne som du vill att den här arbetsbelastningen ska förbruka. Den rekommenderade minnesgränsen är 20 %. Om du överskrider den här gränsen blir frågan långsammare.

Kom igång med Cognitive Services i Power BI
Cognitive Services-transformeringar är en del av självbetjäningsdataförberedelser för dataflöden. Om du vill utöka dina data med Cognitive Services börjar du med att redigera ett dataflöde.

Välj knappen Alla insikter i det övre menyfliksområdet i Power Query-redigeraren.

I popup-fönstret väljer du den funktion som du vill använda och de data som du vill transformera. Det här exemplet poängsätter sentimentet för en kolumn som innehåller granskningstext.

LanguageISOCode är en valfri inmatning för att ange språket för texten. Den här kolumnen förväntar sig en ISO-kod. Du kan använda en kolumn som indata för LanguageISOCode, eller så kan du använda en statisk kolumn. I det här exemplet anges språket som engelska (en) för hela kolumnen. Om du lämnar den här kolumnen tom identifierar Power BI automatiskt språket innan du tillämpar funktionen. Välj sedan Anropa.

När du har anropat funktionen läggs resultatet till som en ny kolumn i tabellen. Omvandlingen läggs också till som ett tillämpat steg i frågan.

Om funktionen returnerar flera utdatakolumner lägger funktionen till en ny kolumn med en rad med flera utdatakolumner.
Använd alternativet expandera för att lägga till ett eller båda värdena som kolumner i dina data.

Tillgängliga funktioner
I det här avsnittet beskrivs tillgängliga funktioner i Cognitive Services i Power BI.
Identifiera språk
Funktionen för språkidentifiering utvärderar textindata och returnerar språknamnet och ISO-identifieraren för varje kolumn. Den här funktionen är användbar för datakolumner som samlar in godtycklig text, där språket är okänt. Funktionen förväntar sig data i textformat som indata.
Textanalysen kan identifiera upp till 120 språk. Mer information finns i Vad är språkidentifiering i Azure Cognitive Service for Language.
Extrahera nyckelfraser
Funktionen Extrahering av nyckelfraser utvärderar ostrukturerad text och returnerar för varje textkolumn en lista med nyckelfraser. Funktionen kräver en textkolumn som indata och accepterar en valfri indata för LanguageISOCode. Mer information finns i Komma igång.
Extrahering av nyckelfraser fungerar bäst när du ger den större textbitar att arbeta med, mittemot attitydanalys. Attitydanalys presterar bättre på mindre textblock. För att få bästa resultat från båda åtgärder kan du överväga att omstrukturera indata på ett lämpligt sätt.
Poängsentiment
Funktionen Poängsentiment utvärderar textindata och returnerar en attitydpoäng för varje dokument, från 0 (negativ) till 1 (positiv). Den här funktionen är användbar för att identifiera positiva och negativa sentiment i sociala medier, kundrecensioner och diskussionsforum.
Textanalys använder en klassificering i maskininlärningsalgoritmen för att generera ett attitydpoäng mellan 0 och 1. Poäng närmare 1 indikerar positiv attityd. Poäng närmare 0 indikerar negativ attityd. Modellen är förtränad med en omfattande texttext med attitydassociationer. För närvarande går det inte att tillhandahålla egna träningsdata. Modellen använder en kombination av metoder under textanalys, inklusive textbearbetning, ordklassanalys, ordplacering och ordassociationer. Mer information om algoritmen finns i Machine Learning och Textanalys.
Attitydanalys utförs på hela indatakolumnen, i stället för att extrahera sentiment för en viss tabell i texten. I praktiken finns det en tendens att bedömningsnoggrannheten förbättras när dokument innehåller en eller två meningar snarare än ett stort textblock. Under en utvärderingsfas för objektivitet avgör modellen om en indatakolumn som helhet är objektiv eller innehåller attityd. En indatakolumn som mestadels är objektiv går inte vidare till sentimentidentifieringsfrasen, vilket resulterar i 0,50 poäng, utan ytterligare bearbetning. För indatakolumner som fortsätter i pipelinen genererar nästa fas en poäng som är större eller mindre än 0,50, beroende på graden av attityd som identifieras i indatakolumnen.
Attitydanalys stöder för närvarande engelska, tyska, spanska och franska. Övriga språk är i förhandsversion. Mer information finns i Vad är språkidentifiering i Azure Cognitive Service for Language.
Tagga bilder
Funktionen Taggbilder returnerar taggar baserade på mer än 2 000 igenkännliga objekt, levande varelser, landskap och åtgärder. När taggar är tvetydiga eller inte allmänt kända ger utdata "tips" för att klargöra innebörden av taggen i samband med en känd inställning. Taggar är inte ordnade som taxonomi och det finns inga arvshierarkier. En samling innehållstaggar utgör grunden för en ”bildbeskrivning” som visas som språk som kan läsas av människor som är formaterade i fullständiga meningar.
När du har laddat upp en bild eller angett en bild-URL Visuellt innehåll algoritmer ut taggar baserat på objekt, levande varelser och åtgärder som identifieras i bilden. Taggar är inte begränsade till huvudföremålet på bilden, som till exempel en person i förgrunden, utan finns även för saker som bakgrund (inomhus eller utomhus), möbler, verktyg, växter, djur, accessoarer, saker och så vidare.
Den här funktionen kräver en bild-URL eller en abase-64-kolumn som indata. För närvarande stöder bildtaggning engelska, spanska, japanska, portugisiska och förenklad kinesiska. Mer information finns i ComputerVision Interface.
Automatiserad maskininlärning i Power BI
Automatisk maskininlärning (AutoML) för dataflöden gör det möjligt för affärsanalytiker att träna, validera och anropa maskininlärningsmodeller (ML) direkt i Power BI. Den innehåller en enkel upplevelse för att skapa en ny ML-modell där analytiker kan använda sina dataflöden för att ange indata för att träna modellen. Tjänsten extraherar automatiskt de mest relevanta funktionerna, väljer en lämplig algoritm och justerar och validerar ML-modellen. När en modell har tränats genererar Power BI automatiskt en prestandarapport som innehåller resultatet av valideringen. Modellen kan sedan anropas på alla nya eller uppdaterade data i dataflödet.
Automatiserad maskininlärning är endast tillgängligt för dataflöden som finns på Power BI Premium- och Embedded-kapaciteter.
Arbeta med AutoML
Maskininlärning och AI ser en aldrig tidigare skådad ökning i popularitet från branscher och vetenskapliga forskningsområden. Företag letar också efter sätt att integrera dessa nya tekniker i sin verksamhet.
Dataflöden erbjuder dataförberedelser med självbetjäning för stordata. AutoML är integrerat i dataflöden och gör att du kan använda din dataförberedelse för att skapa maskininlärningsmodeller direkt i Power BI.
AutoML i Power BI gör det möjligt för dataanalytiker att använda dataflöden för att skapa maskininlärningsmodeller med en förenklad upplevelse med bara Power BI-kunskaper. Power BI automatiserar det mesta av datavetenskapen bakom skapandet av ML-modellerna. Den har skyddsräcken för att säkerställa att modellen som produceras har god kvalitet och ger insyn i den process som används för att skapa din ML-modell.
AutoML stöder skapandet av modeller för binär förutsägelse, klassificering och regression för dataflöden. Dessa funktioner är typer av övervakade maskininlärningstekniker, vilket innebär att de lär sig av kända resultat från tidigare observationer för att förutsäga resultatet av andra observationer. Indatasemantikmodellen för träning av en AutoML-modell är en uppsättning rader som är märkta med kända resultat.
AutoML i Power BI integrerar automatiserad ML från Azure Machine Learning för att skapa dina ML-modeller. Du behöver dock ingen Azure-prenumeration för att använda AutoML i Power BI. Power BI-tjänst hanterar helt och hållet processen för träning och värd för ML-modellerna.
När en ML-modell har tränats genererar AutoML automatiskt en Power BI-rapport som förklarar ml-modellens sannolika prestanda. AutoML betonar förklaringen genom att markera viktiga påverkare bland dina indata som påverkar de förutsägelser som returneras av din modell. Rapporten innehåller även viktiga mått för modellen.
Andra sidor i den genererade rapporten visar den statistiska sammanfattningen av modellen och träningsinformationen. Den statistiska sammanfattningen är av intresse för användare som vill se standarddatavetenskapsmåtten för modellprestanda. Träningsinformationen sammanfattar alla iterationer som kördes för att skapa din modell med tillhörande modelleringsparametrar. Den beskriver också hur varje indata användes för att skapa ML-modellen.
Du kan sedan tillämpa ML-modellen på dina data för bedömning. När dataflödet uppdateras uppdateras dina data med förutsägelser från ML-modellen. Power BI innehåller också en individualiserad förklaring för varje specifik förutsägelse som ML-modellen producerar.
Skapa en maskininlärningsmodell
I det här avsnittet beskrivs hur du skapar en AutoML-modell.
Dataförberedelse för att skapa en ML-modell
Om du vill skapa en maskininlärningsmodell i Power BI måste du först skapa ett dataflöde för data som innehåller information om historiska resultat, som används för att träna ML-modellen. Du bör också lägga till beräknade kolumner för alla affärsmått som kan vara starka prediktorer för det resultat som du försöker förutsäga. Mer information om hur du konfigurerar dataflödet finns i Konfigurera och använda ett dataflöde.
AutoML har specifika datakrav för träning av en maskininlärningsmodell. Dessa krav beskrivs i följande avsnitt, baserat på respektive modelltyp.
Konfigurera ML-modellindata
Om du vill skapa en AutoML-modell väljer du ML-ikonen i kolumnen Åtgärder i dataflödestabellen och väljer Lägg till en maskininlärningsmodell.
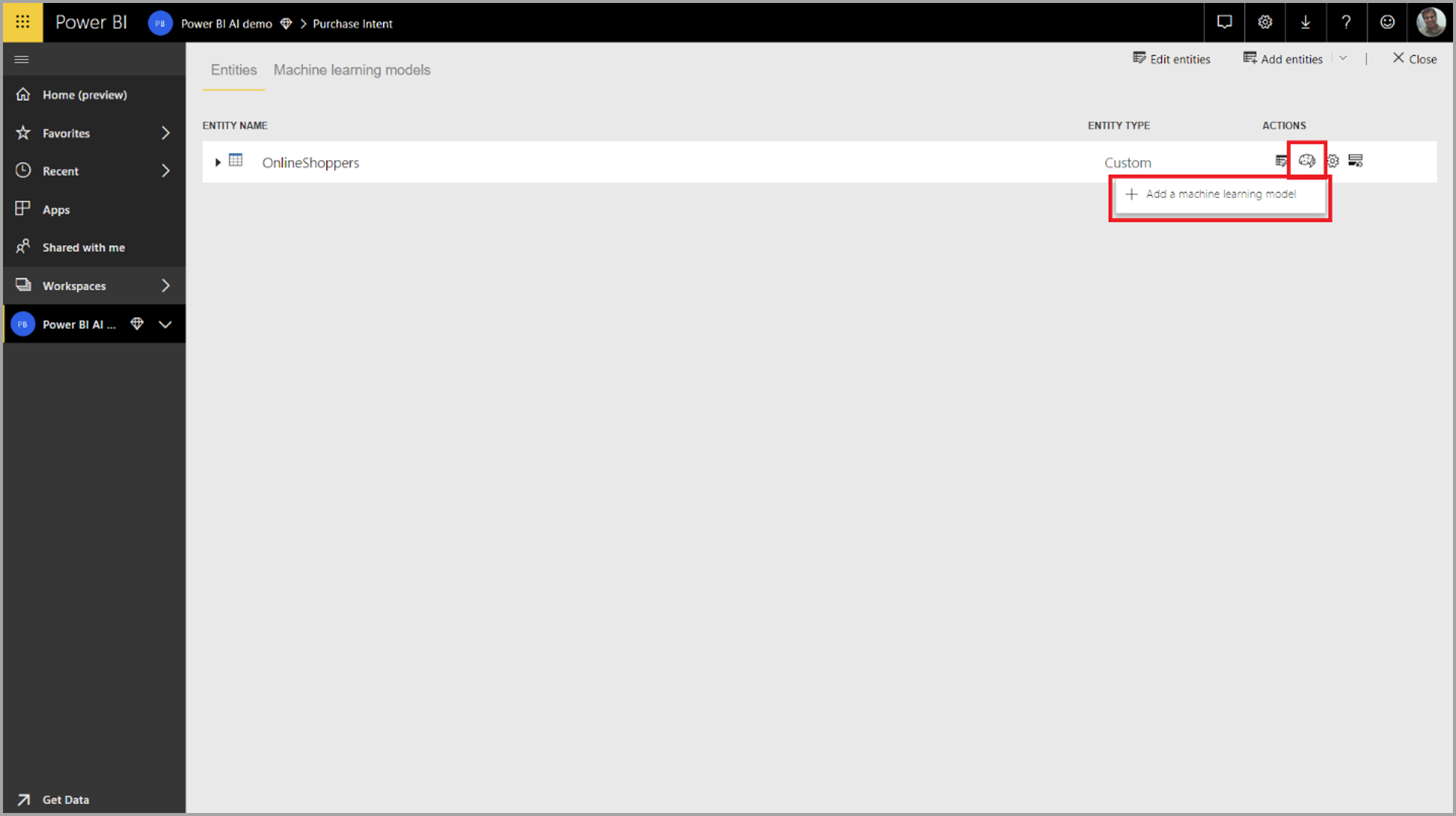
En förenklad upplevelse startar, som består av en guide som vägleder dig genom processen att skapa ML-modellen. Guiden innehåller följande enkla steg.
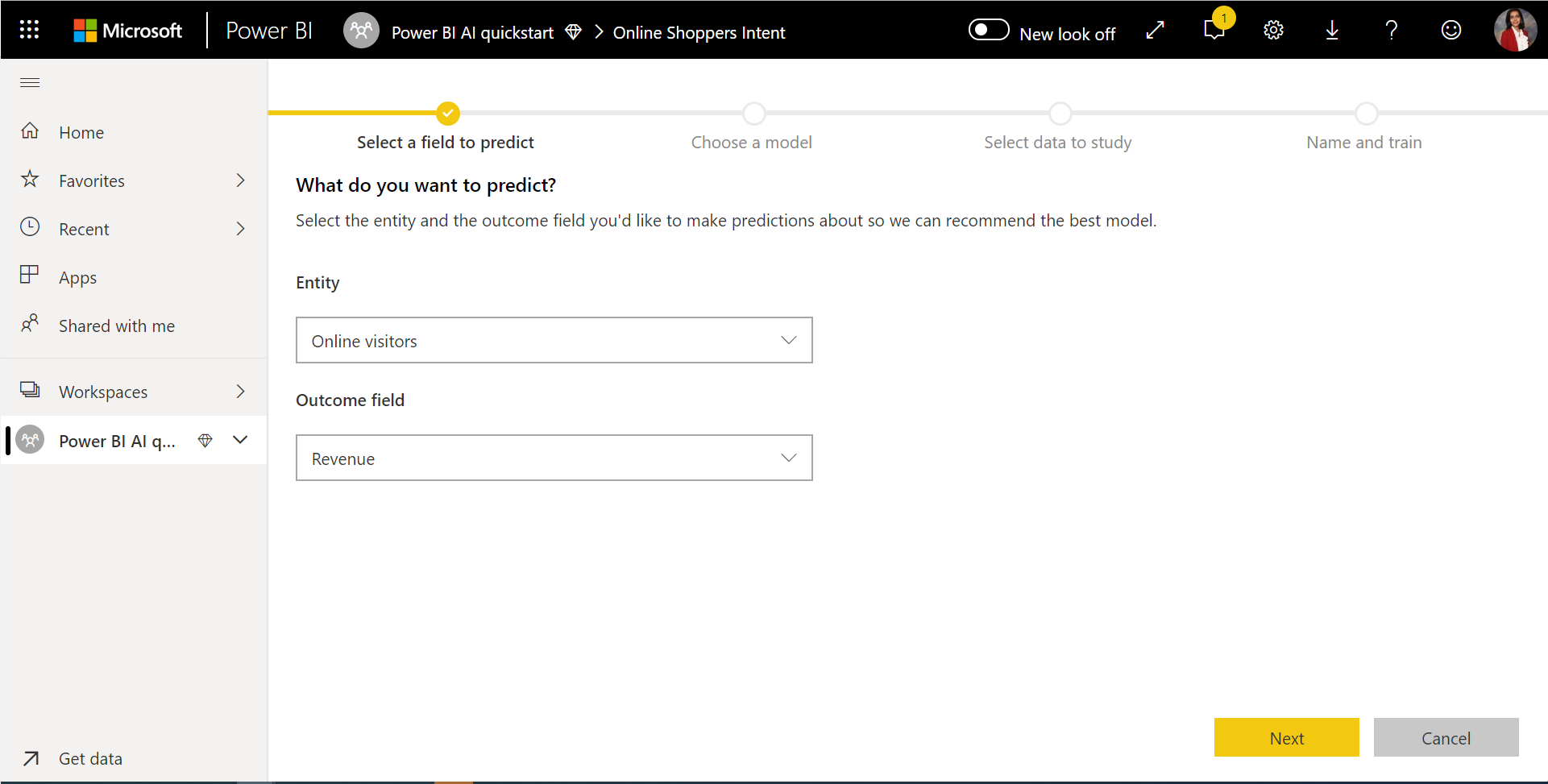
1. Välj tabellen med historiska data och välj den resultatkolumn som du vill ha en förutsägelse för
Resultatkolumnen identifierar etikettattributet för träning av ML-modellen, som visas i följande bild.
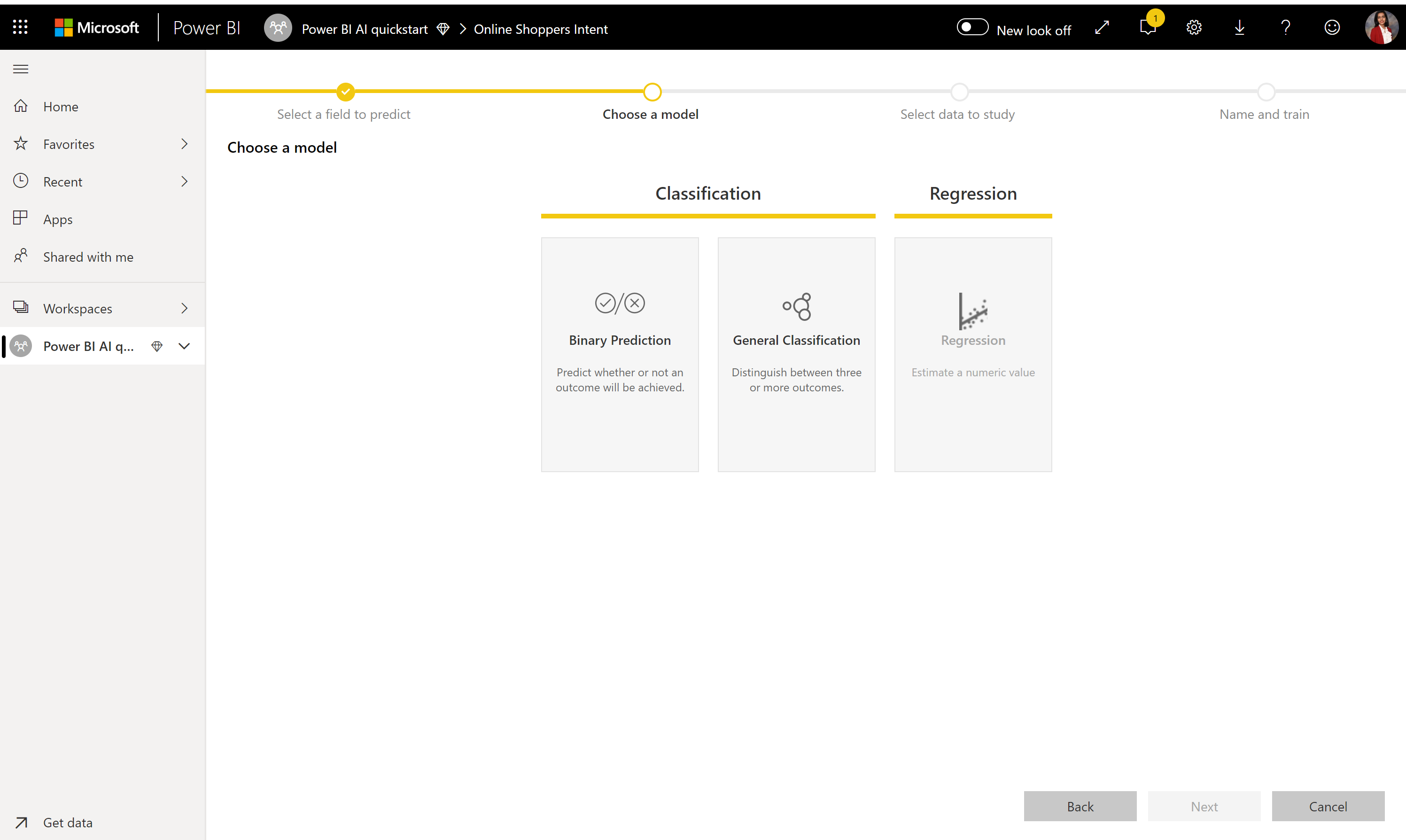
2. Välj en modelltyp
När du anger resultatkolumnen analyserar AutoML etikettdata för att rekommendera den mest sannolika ML-modelltypen som kan tränas. Du kan välja en annan modelltyp som visas i följande bild genom att klicka på Välj en modell.
Kommentar
Vissa modelltyper kanske inte stöds för de data som du har valt och därför inaktiveras de. I föregående exempel inaktiveras Regression eftersom en textkolumn har valts som resultatkolumn.
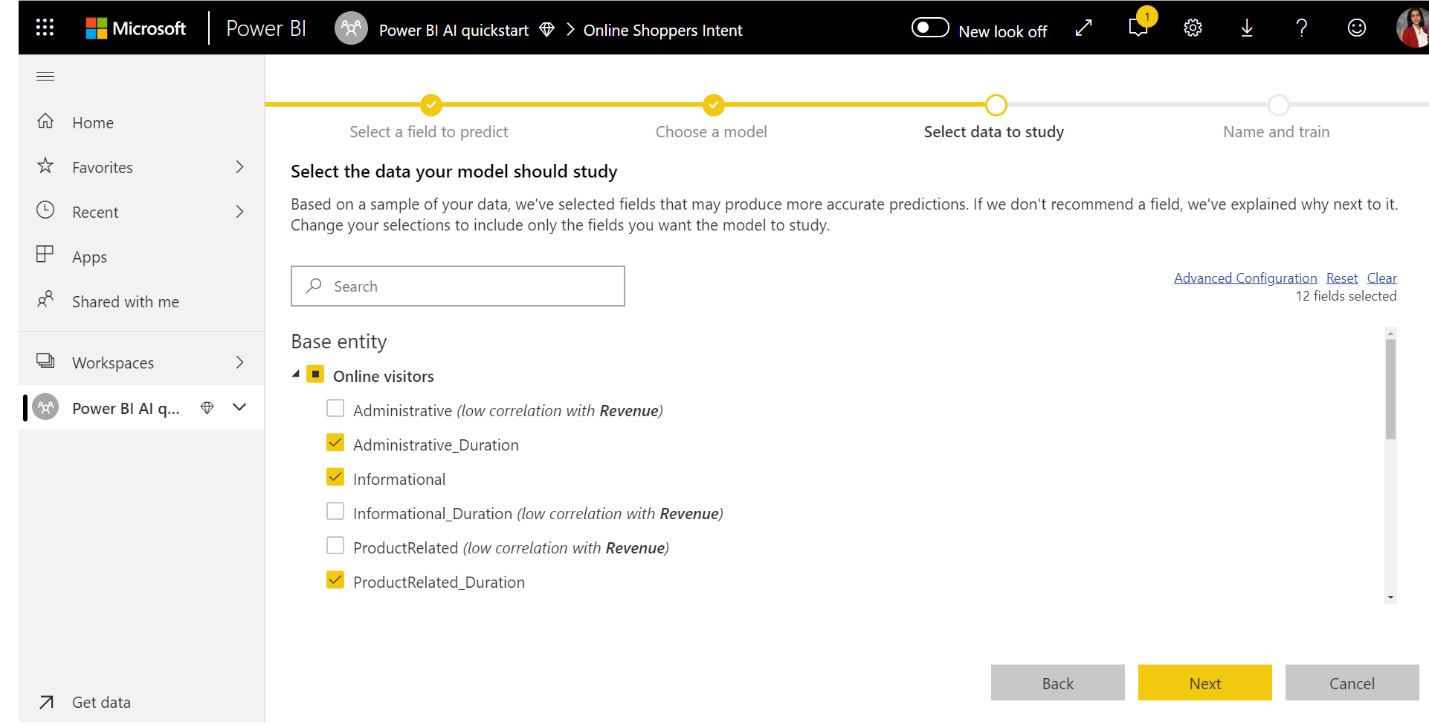
3. Välj de indata som du vill att modellen ska använda som förutsägande signaler
AutoML analyserar ett exempel på den valda tabellen för att föreslå de indata som kan användas för träning av ML-modellen. Förklaringar ges bredvid kolumner som inte är markerade. Om en viss kolumn har för många distinkta värden eller bara ett värde, eller låg eller hög korrelation med utdatakolumnen, rekommenderas det inte.
Indata som är beroende av utfallskolumnen (eller etikettkolumnen) bör inte användas för träning av ML-modellen, eftersom de påverkar dess prestanda. Sådana kolumner flaggas som "misstänkt hög korrelation med utdatakolumnen". Att introducera dessa kolumner i träningsdata orsakar etikettläckage, där modellen presterar bra på validerings- eller testdata men inte kan matcha den prestandan när den används i produktion för bedömning. Etikettläckage kan vara ett möjligt problem i AutoML-modeller när träningsmodellens prestanda är för bra för att vara sant.
Den här funktionsrekommendationsfunktionen baseras på ett exempel på data, så du bör granska de indata som används. Du kan ändra valen så att de endast innehåller de kolumner som du vill att modellen ska studera. Du kan också markera alla kolumner genom att markera kryssrutan bredvid tabellnamnet.
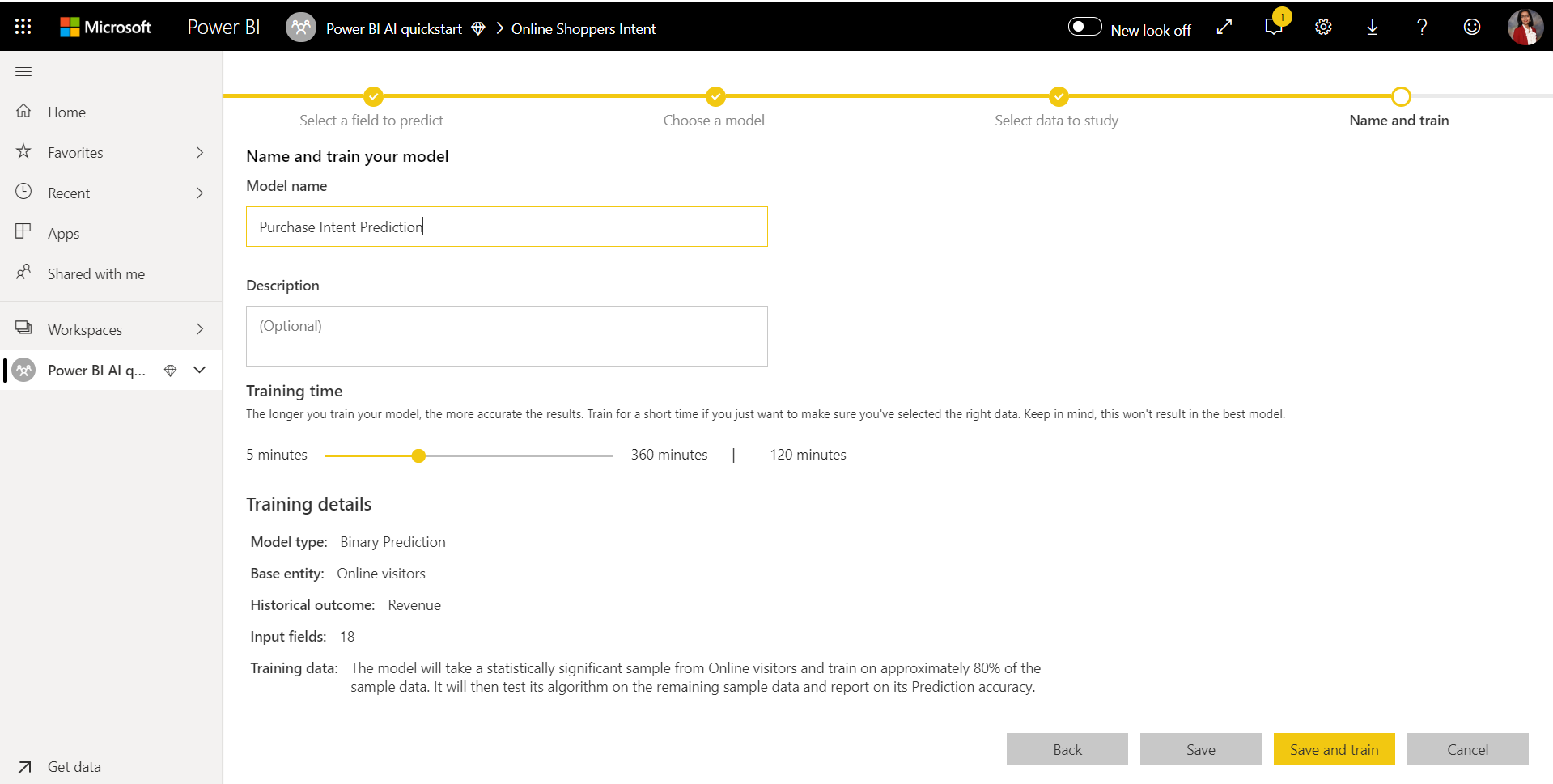
4. Namnge din modell och spara konfigurationen
I det sista steget kan du namnge modellen, välja Spara och välja vilken som börjar träna ML-modellen. Du kan välja att minska träningstiden för att se snabba resultat eller öka den tid som ägnas åt träning för att få den bästa modellen.
ML-modellträning
Träning av AutoML-modeller är en del av dataflödesuppdateringen. AutoML förbereder först dina data för träning. AutoML delar upp historiska data som du tillhandahåller i tränings- och testningssemantiska modeller. Testsemantikmodellen är en holdout-uppsättning som används för att validera modellens prestanda efter träning. Dessa uppsättningar realiseras som tabeller för träning och testning i dataflödet. AutoML använder korsvalidering för modellverifieringen.
Därefter analyseras varje indatakolumn och imputation tillämpas, vilket ersätter eventuella saknade värden med ersatta värden. Ett par olika imputationsstrategier används av AutoML. För indataattribut som behandlas som numeriska funktioner används medelvärdet av kolumnvärdena för imputation. För indataattribut som behandlas som kategoriska funktioner använder AutoML läget för kolumnvärdena för imputation. AutoML-ramverket beräknar medelvärdet och läget för värden som används för imputation på den delsamplade träningssemantikmodellen.
Sedan tillämpas sampling och normalisering på dina data efter behov. För klassificeringsmodeller kör AutoML indata genom stratifierad sampling och balanserar klasserna för att säkerställa att radantalet är lika för alla.
AutoML tillämpar flera transformeringar på varje vald indatakolumn baserat på dess datatyp och statistiska egenskaper. AutoML använder dessa transformeringar för att extrahera funktioner som används för träning av ML-modellen.
Träningsprocessen för AutoML-modeller består av upp till 50 iterationer med olika modelleringsalgoritmer och inställningar för hyperparameter för att hitta modellen med bästa prestanda. Träningen kan avslutas tidigt med mindre iterationer om AutoML märker att ingen prestandaförbättring observeras. AutoML utvärderar prestanda för var och en av dessa modeller genom att validera med holdout-testsemantikmodellen. Under det här utbildningssteget skapar AutoML flera pipelines för träning och validering av dessa iterationer. Processen för att utvärdera modellernas prestanda kan ta tid, allt från flera minuter till ett par timmar, upp till den träningstid som konfigurerats i guiden. Den tid det tar beror på storleken på din semantiska modell och de tillgängliga kapacitetsresurserna.
I vissa fall kan den slutliga modellen som genereras använda ensembleinlärning, där flera modeller används för att ge bättre förutsägelseprestanda.
Förklaring av AutoML-modell
När modellen har tränats analyserar AutoML relationen mellan indatafunktionerna och modellutdata. Den utvärderar omfattningen av ändringen av modellutdata för holdout-testsemantikmodellen för varje indatafunktion. Den här relationen kallas funktionsvikt. Den här analysen sker som en del av uppdateringen när träningen har slutförts. Därför kan uppdateringen ta längre tid än den träningstid som konfigurerats i guiden.
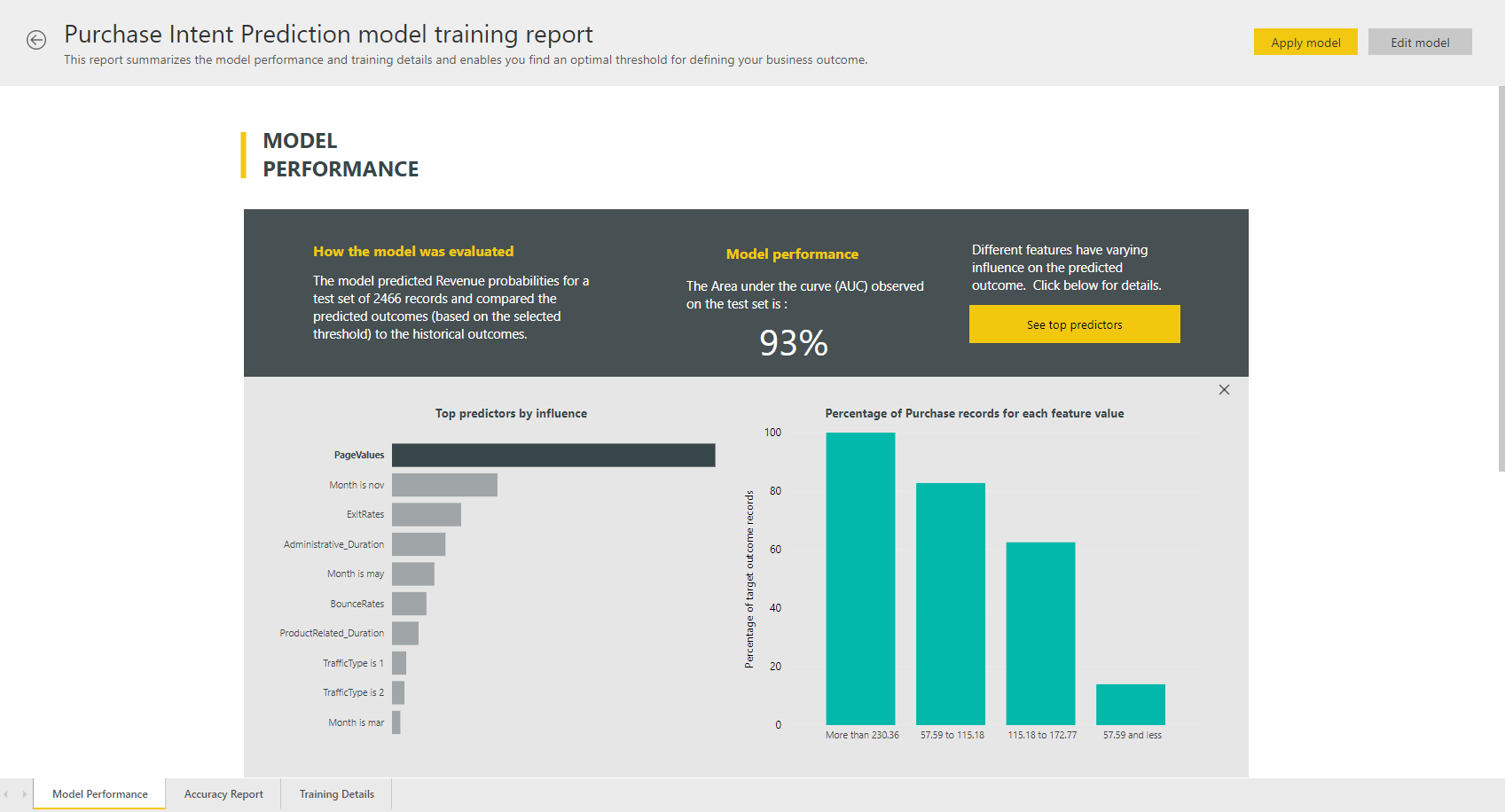
AutoML-modellrapport
AutoML genererar en Power BI-rapport som sammanfattar modellens prestanda under valideringen, tillsammans med den globala funktionsvikten. Den här rapporten kan nås från fliken Machine Learning-modeller när dataflödesuppdateringen har slutförts. Rapporten sammanfattar resultaten från att tillämpa ML-modellen på holdout-testdata och jämföra förutsägelserna med de kända utfallsvärdena.
Du kan granska modellrapporten för att förstå dess prestanda. Du kan också verifiera att de viktigaste påverkarna i modellen överensstämmer med affärsinsikterna om de kända resultaten.
De diagram och mått som används för att beskriva modellens prestanda i rapporten beror på modelltypen. Dessa prestandadiagram och mått beskrivs i följande avsnitt.
Andra sidor i rapporten kan beskriva statistiska mått om modellen ur ett datavetenskapsperspektiv. Rapporten Binär förutsägelse innehåller till exempel ett vinstdiagram och modellens ROC-kurva.
Rapporterna innehåller också en sida med träningsinformation som innehåller en beskrivning av hur modellen tränades och ett diagram som beskriver modellprestandan för var och en av iterationskörningarna.
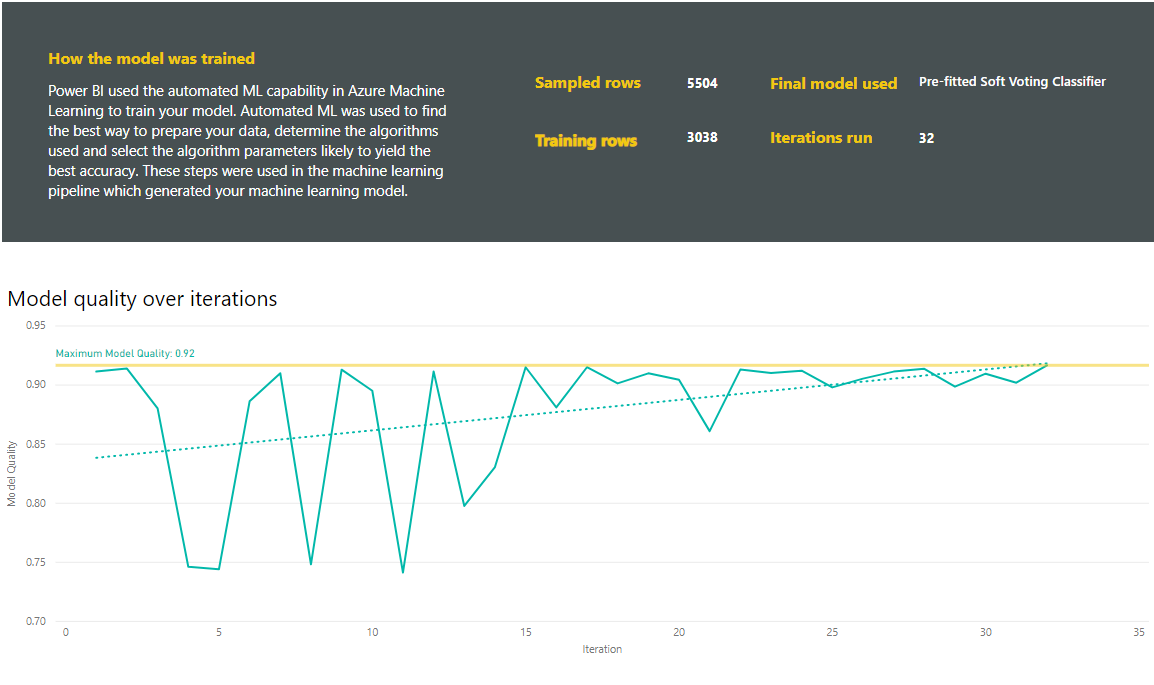
Ett annat avsnitt på den här sidan beskriver den identifierade typen av indatakolumn och imputationsmetod som används för att fylla saknade värden. Den innehåller även de parametrar som används av den slutliga modellen.
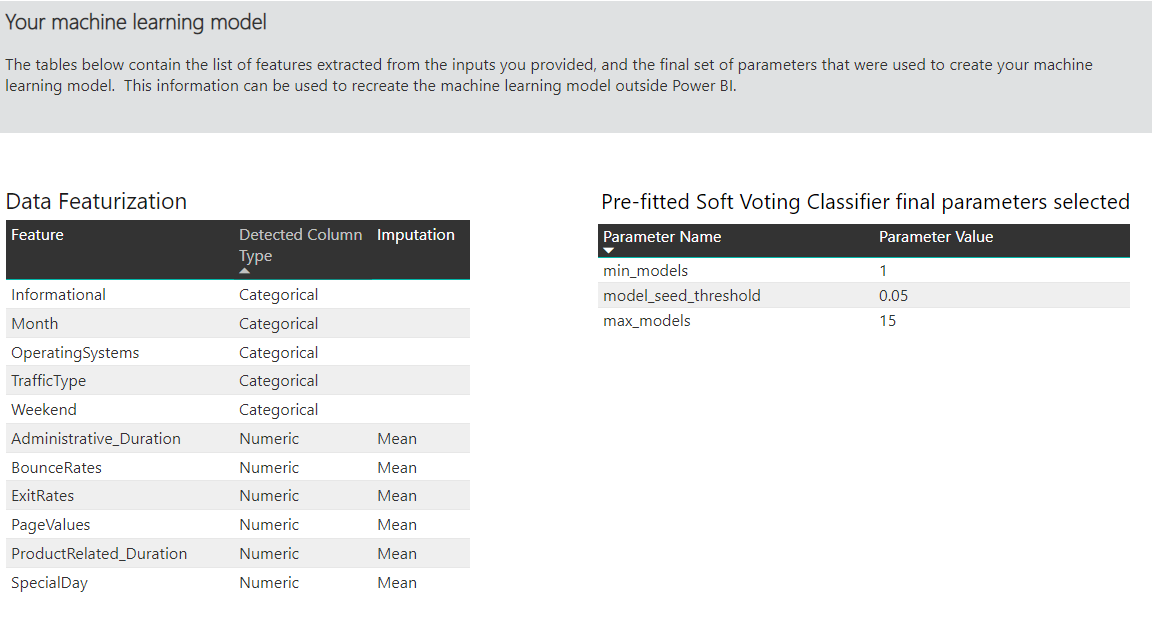
Om modellen som skapas använder ensembleinlärning innehåller sidan Träningsinformation även ett diagram som visar vikten för varje komponentmodell i ensemblen och dess parametrar.

Tillämpa AutoML-modellen
Om du är nöjd med prestandan för ml-modellen som skapats kan du tillämpa den på nya eller uppdaterade data när dataflödet uppdateras. I modellrapporten väljer du knappen Använd i det övre högra hörnet eller knappen Använd ML-modell under åtgärder på fliken Machine Learning-modeller .
Om du vill tillämpa ML-modellen måste du ange namnet på den tabell som den måste tillämpas på och ett prefix för de kolumner som ska läggas till i den här tabellen för modellutdata. Standardprefixet för kolumnnamnen är modellnamnet. Funktionen Apply kan innehålla fler parametrar som är specifika för modelltypen.
Genom att tillämpa ML-modellen skapas två nya dataflödestabeller som innehåller förutsägelser och individualiserade förklaringar för varje rad som den poängsätter i utdatatabellen. Om du till exempel använder PurchaseIntent-modellen på tabellen OnlineShoppers genererar utdata tabellerna OnlineShoppers enriched PurchaseIntent och OnlineShoppers enriched PurchaseIntent explanations. För varje rad i den berikade tabellen delas Förklaringarna upp i flera rader i tabellen med berikade förklaringar baserat på indatafunktionen. Ett ExplanationIndex hjälper till att mappa raderna från tabellen med berikade förklaringar till raden i berikad tabell.
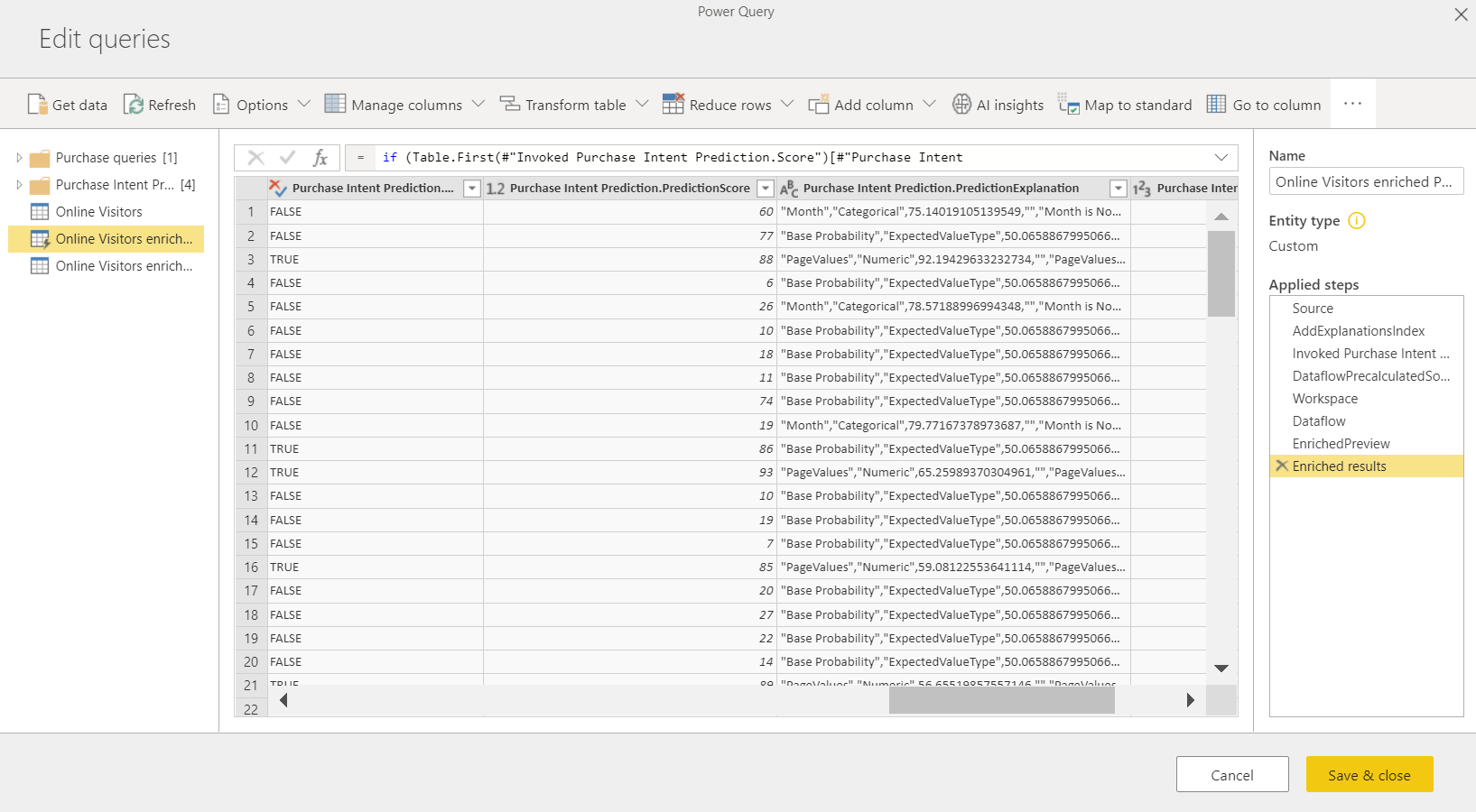
Du kan också använda valfri Power BI AutoML-modell för tabeller i alla dataflöden på samma arbetsyta med hjälp av Alla insikter i PQO-funktionswebbläsaren. På så sätt kan du använda modeller som skapats av andra på samma arbetsyta utan att nödvändigtvis vara ägare till det dataflöde som har modellen. Power Query identifierar alla Power BI ML-modeller på arbetsytan och exponerar dem som dynamiska Power Query-funktioner. Du kan anropa dessa funktioner genom att komma åt dem från menyfliksområdet i Power Query-redigeraren eller genom att anropa M-funktionen direkt. Den här funktionen stöds för närvarande endast för Power BI-dataflöden och för Power Query Online i Power BI-tjänst. Den här processen skiljer sig från att använda ML-modeller i ett dataflöde med hjälp av AutoML-guiden. Det finns ingen förklaringstabell som skapats med den här metoden. Om du inte är ägare till dataflödet kan du inte komma åt modellträningsrapporter eller träna om modellen. Om källmodellen redigeras genom att lägga till eller ta bort indatakolumner eller om modellen eller källdataflödet tas bort, skulle det här beroende dataflödet brytas.

När du har tillämpat modellen håller AutoML alltid dina förutsägelser uppdaterade när dataflödet uppdateras.
Om du vill använda insikter och förutsägelser från ML-modellen i en Power BI-rapport kan du ansluta till utdatatabellen från Power BI Desktop med hjälp av anslutningsappen för dataflöden .
Modeller för binär förutsägelse
Modeller för binär förutsägelse, mer formellt kallade binära klassificeringsmodeller, används för att klassificera en semantisk modell i två grupper. De används för att förutsäga händelser som kan ha ett binärt utfall. Till exempel om en försäljningsmöjlighet konverteras, om ett konto kommer att omvandlas, om en faktura kommer att betalas i tid, om en transaktion är bedräglig och så vidare.
Utdata från en modell för binär förutsägelse är en sannolikhetspoäng som identifierar sannolikheten för att målresultatet uppnås.
Träna en modell för binär förutsägelse
Förutsättningar:
- Minst 20 rader med historiska data krävs för varje utfallsklass
Processen för att skapa en modell för binär förutsägelse följer samma steg som andra AutoML-modeller, som beskrivs i föregående avsnitt, Konfigurera ML-modellens indata. Den enda skillnaden är i steget Välj en modell där du kan välja det målresultatvärde som du är mest intresserad av. Du kan också ange egna etiketter för de resultat som ska användas i den automatiskt genererade rapporten som sammanfattar resultatet av modellverifieringen.

Modellrapport för binär förutsägelse
Modellen binär förutsägelse ger som utdata en sannolikhet att en rad uppnår målresultatet. Rapporten innehåller ett utsnitt för sannolikhetströskelvärdet, vilket påverkar hur poängen är större och mindre än sannolikhetströskeln tolkas.
Rapporten beskriver modellens prestanda när det gäller sanna positiva identifieringar, falska positiva identifieringar, sanna negativa och falska negativa värden. True Positives och True Negatives är korrekt förutsagda utfall för de två klasserna i utfallsdata. Falska positiva identifieringar är rader som förutsades ha målresultat men som faktiskt inte gjorde det. Omvänt är Falska negativa rader rader som hade målresultat men som förutsades som inte dem.
Mått, till exempel Precision och Recall, beskriver sannolikhetströskelns effekt på de förutsagda utfallen. Du kan använda utsnittet för sannolikhetströskel för att välja ett tröskelvärde som uppnår en balanserad kompromiss mellan Precision och Recall.

Rapporten innehåller också ett analysverktyg för kostnads-förmån som hjälper till att identifiera den delmängd av befolkningen som ska riktas för att ge den högsta vinsten. Med tanke på en uppskattad enhetskostnad för mål och en enhet drar nytta av att uppnå ett målresultat försöker Cost-Benefit-analysen maximera vinsten. Du kan använda det här verktyget för att välja ditt sannolikhetströskelvärde baserat på den maximala punkten i diagrammet för att maximera vinsten. Du kan också använda diagrammet för att beräkna vinsten eller kostnaden för ditt val av sannolikhetströskel.

Sidan Noggrannhetsrapport i modellrapporten innehåller diagrammet Kumulativa vinster och modellens ROC-kurva. Dessa data ger statistiska mått på modellens prestanda. Rapporterna innehåller beskrivningar av de diagram som visas.
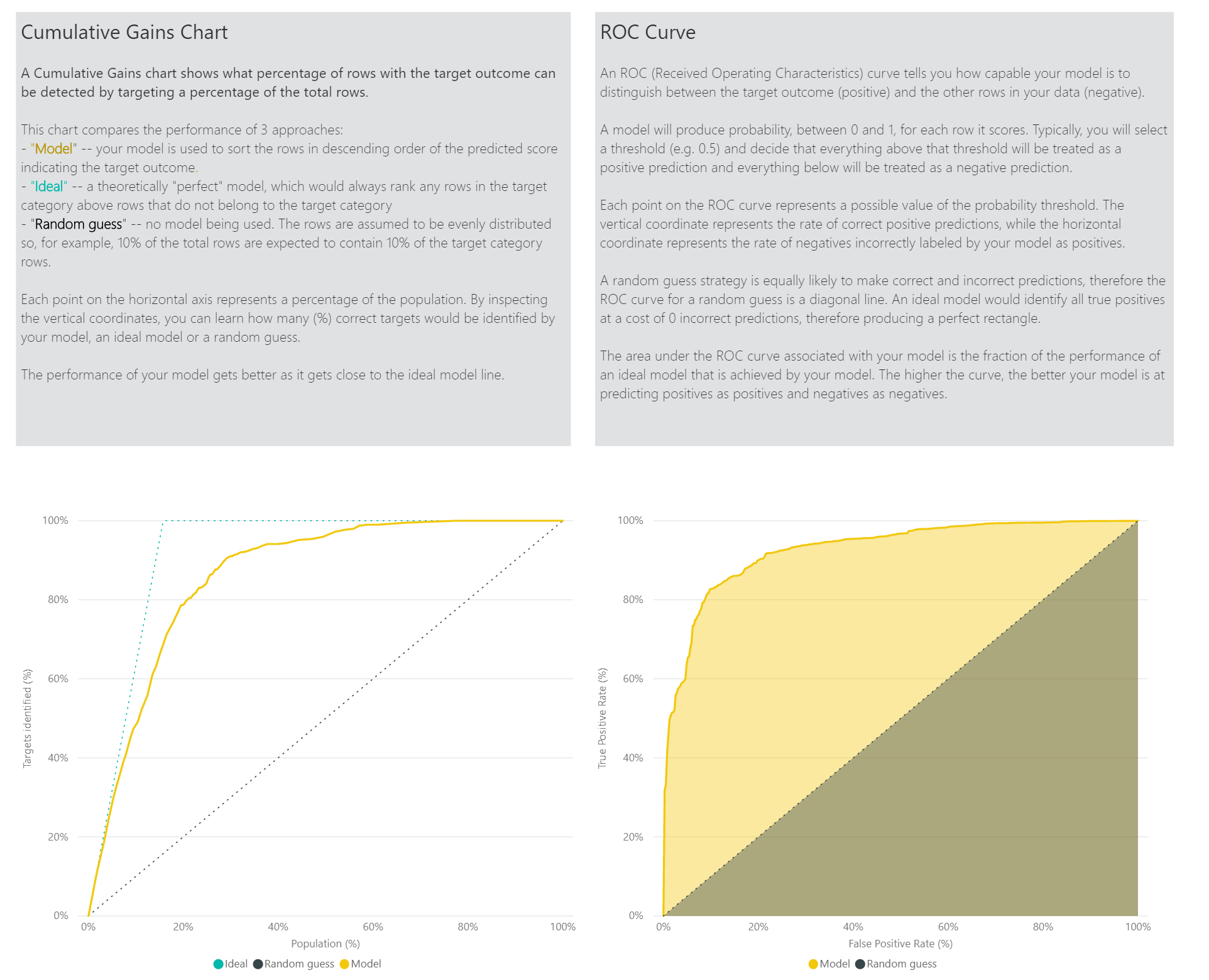
Använda en modell för binär förutsägelse
Om du vill använda en modell för binär förutsägelse måste du ange tabellen med de data som du vill tillämpa förutsägelserna från ML-modellen på. Andra parametrar är prefixet för utdatakolumnens namn och sannolikhetströskeln för klassificering av det förväntade resultatet.
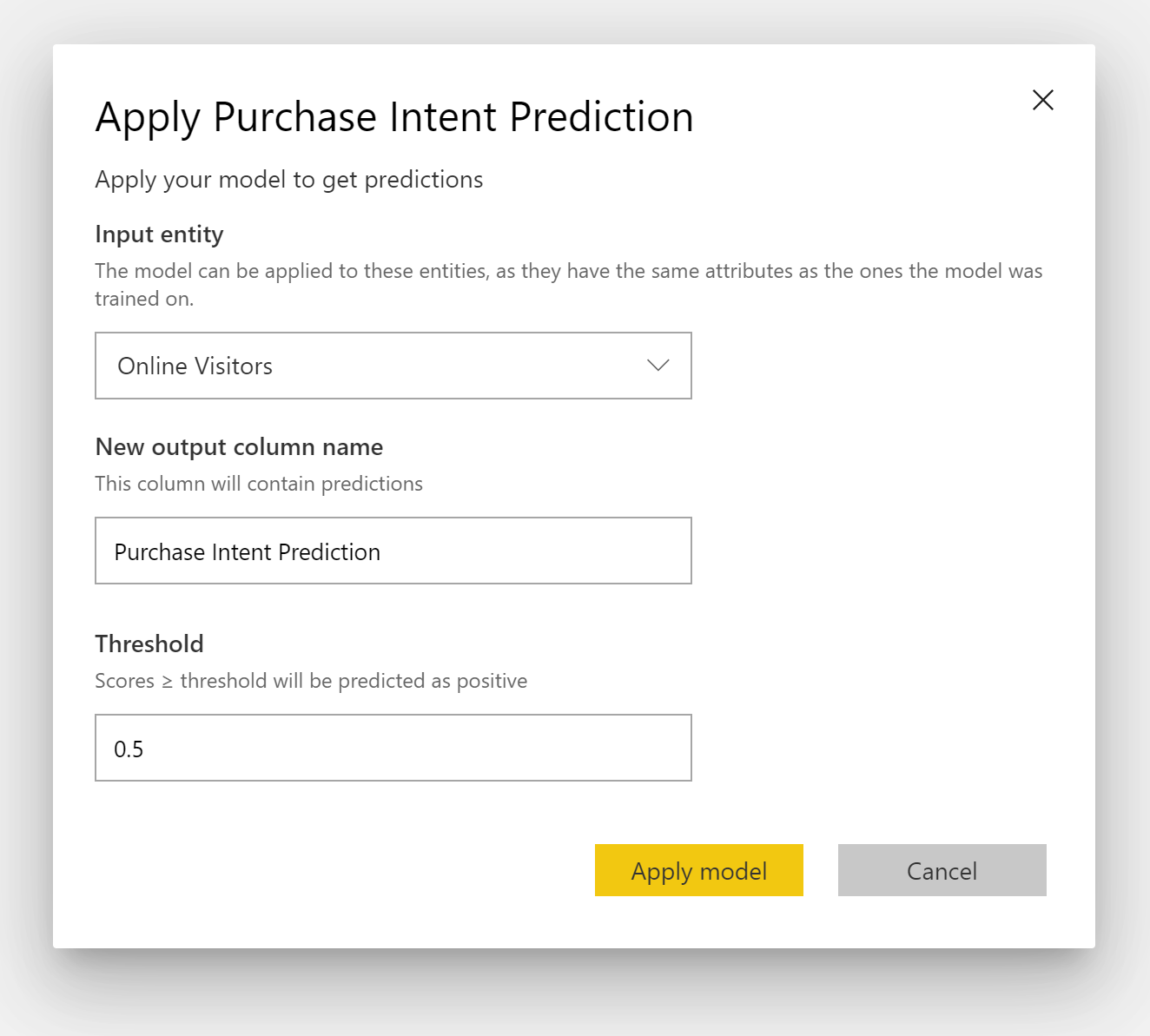
När en modell för binär förutsägelse tillämpas lägger den till fyra utdatakolumner i den berikade utdatatabellen: Outcome, PredictionScore, PredictionExplanation och ExplanationIndex. Kolumnnamnen i tabellen har prefixet angivet när modellen tillämpas.
PredictionScore är en procentuell sannolikhet som identifierar sannolikheten för att målresultatet uppnås.
Kolumnen Outcome (Utfall) innehåller etiketten för förutsagt utfall. Poster med sannolikheter som överskrider tröskelvärdet förutsägs som sannolika att uppnå målresultatet och är märkta som True. Poster som är mindre än tröskelvärdet förutsägs som osannolika att uppnå resultatet och är märkta som False.
Kolumnen PredictionExplanation innehåller en förklaring med den specifika påverkan som indatafunktionerna hade på PredictionScore.
Klassificeringsmodeller
Klassificeringsmodeller används för att klassificera en semantisk modell i flera grupper eller klasser. De används för att förutsäga händelser som kan ha ett av flera möjliga resultat. Till exempel om en kund sannolikt har ett högt, medelhögt eller lågt livslängdsvärde. De kan också förutsäga om risken för standard är hög, måttlig, låg och så vidare.
Utdata från en klassificeringsmodell är en sannolikhetspoäng som identifierar sannolikheten för att en rad uppnår kriterierna för en viss klass.
Träna en klassificeringsmodell
Indatatabellen som innehåller dina träningsdata för en klassificeringsmodell måste ha en sträng eller heltalskolumn som resultatkolumn, som identifierar tidigare kända resultat.
Förutsättningar:
- Minst 20 rader med historiska data krävs för varje utfallsklass
Processen för att skapa en klassificeringsmodell följer samma steg som andra AutoML-modeller, som beskrivs i föregående avsnitt, Konfigurera ML-modellindata.
Rapport om klassificeringsmodell
Power BI skapar klassificeringsmodellens rapport genom att tillämpa ML-modellen på holdout-testdata. Sedan jämförs den förutsagda klassen för en rad med den faktiska kända klassen.
Modellrapporten innehåller ett diagram som innehåller uppdelningen av korrekt och felaktigt klassificerade rader för varje känd klass.
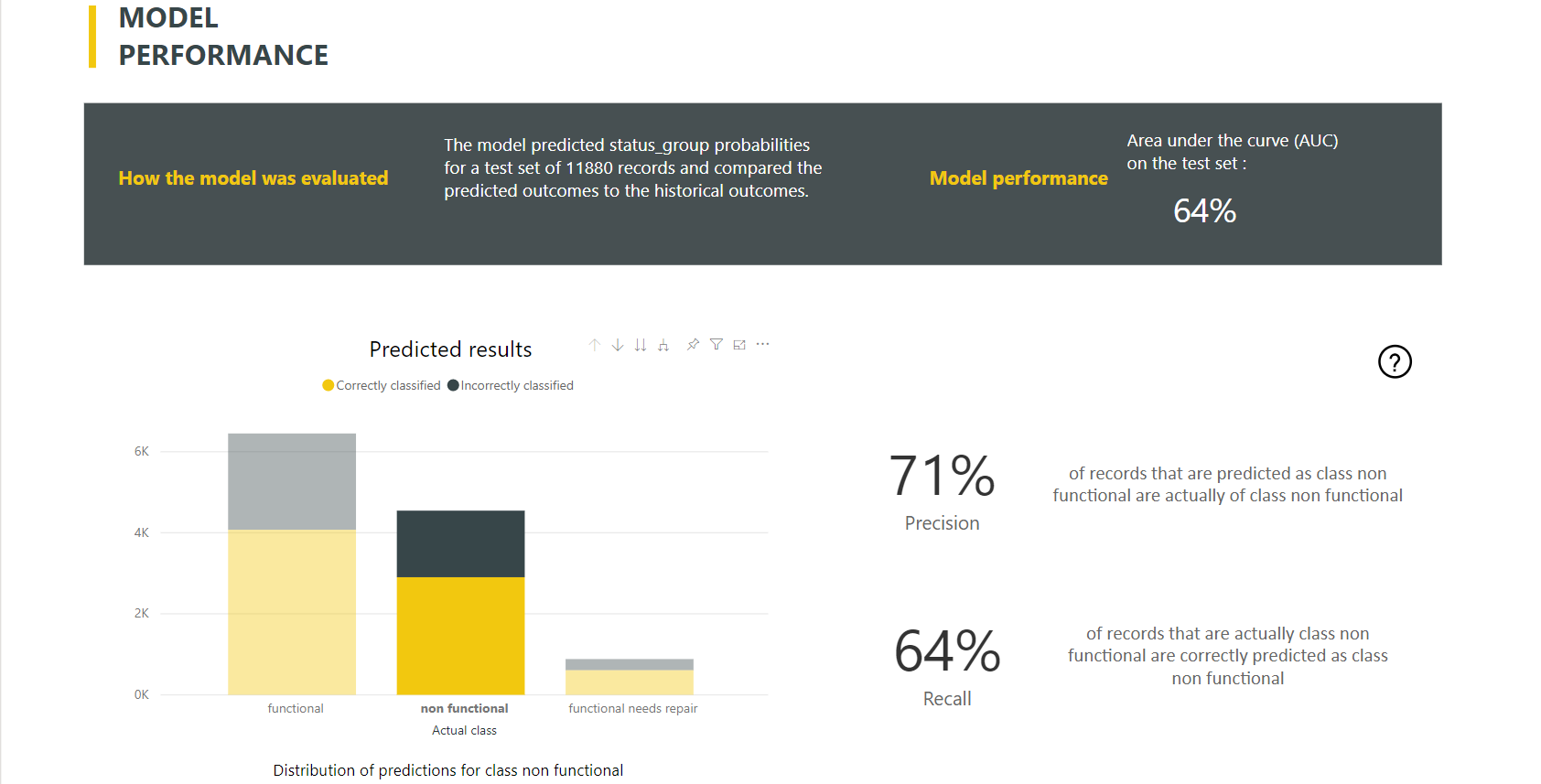
En ytterligare klassspecifik åtgärd för ökad detaljnivå möjliggör en analys av hur förutsägelserna för en känd klass distribueras. Den här analysen visar de andra klasser där rader i den kända klassen sannolikt kommer att vara felklassificerade.
Modellförklaringen i rapporten innehåller även de främsta prediktorerna för varje klass.
Klassificeringsmodellens rapport innehåller även en sida med träningsinformation som liknar sidorna för andra modelltyper, enligt beskrivningen tidigare, i AutoML-modellrapporten.
Tillämpa en klassificeringsmodell
Om du vill använda en ML-klassificeringsmodell måste du ange tabellen med indata och prefixet för utdatakolumnens namn.
När en klassificeringsmodell tillämpas lägger den till fem utdatakolumner i den berikade utdatatabellen: ClassificationScore, ClassificationResult, ClassificationExplanation, ClassProbabilities och ExplanationIndex. Kolumnnamnen i tabellen har prefixet angivet när modellen tillämpas.
Kolumnen ClassProbabilities innehåller listan över sannolikhetspoäng för raden för varje möjlig klass.
ClassificationScore är sannolikheten i procent, vilket identifierar sannolikheten för att en rad uppnår kriterierna för en viss klass.
Kolumnen ClassificationResult innehåller den mest sannolika förutsagda klassen för raden.
Kolumnen ClassificationExplanation innehåller en förklaring med den specifika påverkan som indatafunktionerna hade på ClassificationScore.
Regressionsmodeller
Regressionsmodeller används för att förutsäga ett numeriskt värde och kan användas i scenarier som att bestämma:
- De intäkter som sannolikt kommer att realiseras från en försäljningsaffär.
- Livslängdsvärdet för ett konto.
- Beloppet för en kundfaktura som sannolikt kommer att betalas
- Det datum då en faktura kan betalas och så vidare.
Utdata från en regressionsmodell är det förutsagda värdet.
Träna en regressionsmodell
Indatatabellen som innehåller träningsdata för en regressionsmodell måste ha en numerisk kolumn som resultatkolumn, som identifierar de kända utfallsvärdena.
Förutsättningar:
- Minst 100 rader med historiska data krävs för en regressionsmodell.
Processen för att skapa en regressionsmodell följer samma steg som andra AutoML-modeller, som beskrivs i föregående avsnitt, Konfigurera ML-modellindata.
Regressionsmodellrapport
Precis som de andra AutoML-modellrapporterna baseras Regression-rapporten på resultaten från att tillämpa modellen på holdout-testdata.
Modellrapporten innehåller ett diagram som jämför de förutsagda värdena med de faktiska värdena. I det här diagrammet anger avståndet från diagonalen felet i förutsägelsen.
Diagrammet över residualfel visar fördelningen av procentandelen genomsnittligt fel för olika värden i holdout-testsemantikmodellen. Den vågräta axeln representerar medelvärdet av det faktiska värdet för gruppen. Storleken på bubblan visar frekvensen eller antalet värden i det intervallet. Den lodräta axeln är det genomsnittliga residualfelet.
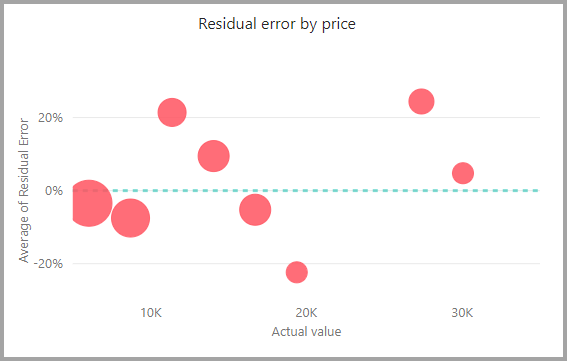
Regressionsmodellrapporten innehåller även en sida med träningsinformation som rapporter för andra modelltyper, enligt beskrivningen i föregående avsnitt, AutoML-modellrapport.
Tillämpa en regressionsmodell
Om du vill använda en Regression ML-modell måste du ange tabellen med indata och prefixet för utdatakolumnens namn.
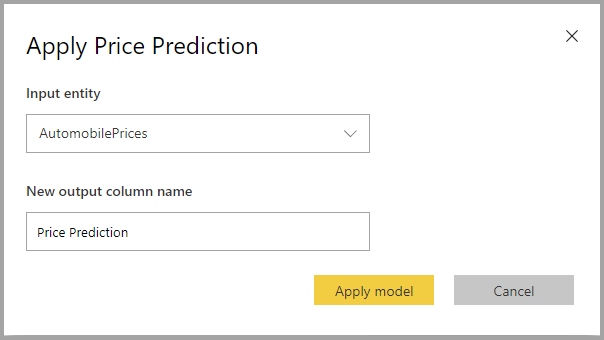
När en regressionsmodell tillämpas lägger den till tre utdatakolumner i den berikade utdatatabellen: RegressionResult, RegressionExplanation och ExplanationIndex. Kolumnnamnen i tabellen har prefixet angivet när modellen tillämpas.
Kolumnen RegressionResult innehåller det förutsagda värdet för raden baserat på indatakolumnerna. Kolumnen RegressionExplanation innehåller en förklaring med den specifika påverkan som indatafunktionerna hade på RegressionResult.
Azure Machine Learning-integrering i Power BI
Många organisationer använder maskininlärningsmodeller för bättre insikter och förutsägelser om sin verksamhet. Du kan använda maskininlärning med dina rapporter, instrumentpaneler och andra analyser för att få dessa insikter. Möjligheten att visualisera och anropa insikter från dessa modeller kan bidra till att sprida dessa insikter till de företagsanvändare som behöver dem mest. Power BI gör det nu enkelt att införliva insikterna från modeller som finns i Azure Machine Learning med hjälp av enkla punkt- och klickgester.
Om du vill använda den här funktionen kan en dataexpert bevilja åtkomst till Azure Machine Learning-modellen till BI-analytikern med hjälp av Azure-portalen. I början av varje session identifierar Power Query sedan alla Azure Machine Learning-modeller som användaren har åtkomst till och exponerar dem som dynamiska Power Query-funktioner. Användaren kan sedan anropa dessa funktioner genom att komma åt dem från menyfliksområdet i Power Query-redigeraren eller genom att anropa M-funktionen direkt. Power BI batchar också automatiskt åtkomstbegäranden när du anropar Azure Machine Learning-modellen för en uppsättning rader för att uppnå bättre prestanda.
Den här funktionen stöds för närvarande endast för Power BI-dataflöden och för Power Query online i Power BI-tjänst.
Mer information om dataflöden finns i Introduktion till dataflöden och dataförberedelser med självbetjäning.
Mer information om Azure Machine Learning finns i:
- Översikt: Vad är Azure Machine Learning?
- Snabbstarter och självstudier för Azure Machine Learning: Dokumentation om Azure Machine Learning
Bevilja åtkomst till Azure Machine Learning-modellen till en Power BI-användare
För att få åtkomst till en Azure Machine Learning-modell från Power BI måste användaren ha läsbehörighet till Azure-prenumerationen och Machine Learning-arbetsytan.
Stegen i den här artikeln beskriver hur du ger en Power BI-användare åtkomst till en modell som finns i Azure Machine Learning-tjänsten för att få åtkomst till den här modellen som en Power Query-funktion. Mer information finns i Tilldela Azure-roller med Azure-portalen.
Logga in på Azure-portalen.
Gå till sidan Prenumerationer . Du hittar sidan Prenumerationer via listan Alla tjänster i navigeringsfönstrets meny i Azure-portalen.

Välj din prenumeration.

Välj Åtkomstkontroll (IAM) och välj sedan knappen Lägg till .

Välj Läsare som roll. Välj sedan den Power BI-användare som du vill bevilja åtkomst till Azure Machine Learning-modellen till.

Välj Spara.
Upprepa steg tre till sex för att ge läsare åtkomst till användaren för den specifika arbetsytan för maskininlärning som är värd för modellen.




Schemaidentifiering för maskininlärningsmodeller
Dataexperter använder främst Python för att utveckla och till och med distribuera sina maskininlärningsmodeller för maskininlärning. Dataexperten måste uttryckligen generera schemafilen med hjälp av Python.
Den här schemafilen måste ingå i den distribuerade webbtjänsten för maskininlärningsmodeller. Om du vill generera schemat för webbtjänsten automatiskt måste du ange ett exempel på indata/utdata i inmatningsskriptet för den distribuerade modellen. Mer information finns i Distribuera och poängsätta en maskininlärningsmodell med hjälp av en onlineslutpunkt. Länken innehåller exempelinmatningsskriptet med instruktioner för schemagenereringen.
Mer specifikt refererar funktionerna @input_schema och @output_schema i postskriptet till indata- och utdataexempelformaten i variablerna input_sample och output_sample. Funktionerna använder dessa exempel för att generera en OpenAPI-specifikation (Swagger) för webbtjänsten under distributionen.
De här instruktionerna för schemagenerering genom att uppdatera inmatningsskriptet måste också tillämpas på modeller som skapats med hjälp av automatiserade maskininlärningsexperiment med Azure Machine Learning SDK.
Kommentar
Modeller som skapats med hjälp av det visuella Azure Machine Learning-gränssnittet stöder för närvarande inte schemagenerering, men kommer att göra det i efterföljande versioner.
Anropa Azure Machine Learning-modellen i Power BI
Du kan anropa valfri Azure Machine Learning-modell som du har beviljats åtkomst till direkt från Power Query-redigeraren i ditt dataflöde. För att få åtkomst till Azure Machine Learning-modellerna väljer du knappen Redigera tabell för den tabell som du vill utöka med insikter från din Azure Machine Learning-modell, som du ser i följande bild.

Om du väljer knappen Redigera tabell öppnas Power Query-redigeraren för tabellerna i dataflödet.

Välj knappen Alla insikter i menyfliksområdet och välj sedan mappen Azure Machine Learning Models i navigeringsfönstrets meny. Alla Azure Machine Learning-modeller som du har åtkomst till visas här som Power Query-funktioner. Dessutom mappas indataparametrarna för Azure Machine Learning-modellen automatiskt som parametrar för motsvarande Power Query-funktion.
Om du vill anropa en Azure Machine Learning-modell kan du ange någon av den valda tabellens kolumner som indata från listrutan. Du kan också ange ett konstant värde som ska användas som indata genom att växla kolumnikonen till vänster om indatadialogrutan.

Välj Anropa för att visa förhandsversionen av Azure Machine Learning-modellens utdata som en ny kolumn i tabellen. Modellanropet visas som ett tillämpat steg för frågan.

Om modellen returnerar flera utdataparametrar grupperas de som en rad i utdatakolumnen. Du kan expandera kolumnen för att skapa enskilda utdataparametrar i separata kolumner.

När du har sparat dataflödet anropas modellen automatiskt när dataflödet uppdateras för alla nya eller uppdaterade rader i tabellen.
Beaktanden och begränsningar
- Dataflöden Gen2 integreras för närvarande inte med automatiserad maskininlärning.
- AI-insikter (Cognitive Services- och Azure Machine Learning-modeller) stöds inte på datorer med konfiguration av proxyautentisering.
- Azure Machine Learning-modeller stöds inte för gästanvändare.
- Det finns några kända problem med att använda gateway med AutoML och Cognitive Services. Om du behöver använda en gateway rekommenderar vi att du skapar ett dataflöde som importerar nödvändiga data via gatewayen först. Skapa sedan ett annat dataflöde som refererar till det första dataflödet för att skapa eller tillämpa dessa modeller och AI-funktioner.
- Om AI-arbetet med dataflöden misslyckas kan du behöva aktivera Snabb kombination när du använder AI med dataflöden. När du har importerat tabellen och innan du börjar lägga till AI-funktioner väljer du Alternativ i menyfliksområdet Start. I fönstret som visas markerar du kryssrutan bredvid Tillåt att du kombinerar data från flera källor för att aktivera funktionen och väljer sedan OK för att spara ditt val. Sedan kan du lägga till AI-funktioner i ditt dataflöde.
Relaterat innehåll
Den här artikeln innehåller en översikt över Automatiserad maskininlärning för dataflöden i Power BI-tjänst. Följande artiklar kan också vara användbara.
- Självstudie: Skapa en Maskininlärningsmodell i Power BI
- Självstudie: Använda Cognitive Services i Power BI
Följande artiklar innehåller mer information om dataflöden och Power BI:
- Introduktion till dataflöden och dataförberedelser via självbetjäning
- Skapa ett dataflöde
- Konfigurera och använda ett dataflöde
- Konfigurera dataflödeslagring för användning av Azure Data Lake Gen 2
- Premium-funktioner i dataflöden
- Överväganden och begränsningar för dataflöden
- Metodtips för dataflöden
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för