Azure HDInsight'ta Apache Ambari ile Apache Hive'ı iyileştirme
Apache Ambari, HDInsight kümelerini yönetmek ve izlemek için bir web arabirimidir. Ambari Web kullanıcı arabirimine giriş için bkz . Apache Ambari Web kullanıcı arabirimini kullanarak HDInsight kümelerini yönetme.
Aşağıdaki bölümlerde genel Apache Hive performansını iyileştirmeye yönelik yapılandırma seçenekleri açıklanmaktadır.
- Hive yapılandırma parametrelerini değiştirmek için Hizmetler kenar çubuğundan Hive'ı seçin.
- Yapılandırmalar sekmesine gidin.
Hive yürütme altyapısını ayarlama
Hive iki yürütme altyapısı sağlar: Apache Hadoop MapReduce ve Apache TEZ. Tez, MapReduce'tan daha hızlıdır. HDInsight Linux kümeleri, varsayılan yürütme altyapısı olarak Tez'e sahiptir. Yürütme altyapısını değiştirmek için:
Hive Yapılandırmaları sekmesinde, filtre kutusuna yürütme altyapısı yazın.
optimization özelliğinin varsayılan değeri Tez'dir.

Eşleyicileri ayarlama
Hadoop, tek bir dosyayı birden çok dosyaya bölmeye (eşlemeye) ve sonuçta elde edilen dosyaları paralel olarak işlemeye çalışır. Eşleyicilerin sayısı bölme sayısına bağlıdır. Aşağıdaki iki yapılandırma parametresi, Tez yürütme altyapısı için bölme sayısını yönlendirir:
tez.grouping.min-size: Varsayılan değeri 16 MB (16.777.216 bayt) olan gruplandırılmış bölmenin boyutuna ilişkin alt sınır.tez.grouping.max-size: Varsayılan değeri 1 GB (1.073.741.824 bayt) olan gruplandırılmış bölme boyutu üst sınırı.
Performans yönergeleri olarak, gecikme süresini iyileştirmek için bu parametrelerin her ikisini de düşürerek daha fazla aktarım hızına yükseltin.
Örneğin, 128 MB veri boyutu için dört eşleyici görevi ayarlamak için her iki parametreyi de 32 MB (33.554.432 bayt) olarak ayarlayabilirsiniz.
Sınır parametrelerini değiştirmek için Tez hizmetinin Yapılandırmalar sekmesine gidin. Genel panelini genişletin ve ve
tez.grouping.min-sizeparametrelerini buluntez.grouping.max-size.Her iki parametreyi de 33.554.432 bayt (32 MB) olarak ayarlayın.

Bu değişiklikler sunucu genelindeki tüm Tez işlerini etkiler. En iyi sonucu almak için uygun parametre değerlerini seçin.
Azaltıcıları ayarlama
Apache ORC ve Snappy yüksek performans sunar. Ancak Hive varsayılan olarak çok az azaltıcıya sahip olabilir ve bu da performans sorunlarına neden olabilir.
Örneğin, 50 GB giriş veri boyutunuz olduğunu varsayalım. Snappy sıkıştırmalı ORC biçimindeki veriler 1 GB'tır. Hive, gereken azaltıcı sayısını şu şekilde tahmin eder: (eşleyicilere giriş bayt sayısı / hive.exec.reducers.bytes.per.reducer).
Varsayılan ayarlarda bu örnek dört azaltıcıdır.
parametresi, hive.exec.reducers.bytes.per.reducer azaltıcı başına işlenen bayt sayısını belirtir. Varsayılan değer 64 MB'tır. Bu değerin aşağı ayarlanması paralelliği artırır ve performansı artırabilir. Bu ayarın çok düşük olması da çok fazla azaltıcıya neden olabilir ve bu da performansı olumsuz etkileyebilir. Bu parametre, belirli veri gereksinimlerinize, sıkıştırma ayarlarınıza ve diğer çevresel faktörlere dayanır.
Parametresini değiştirmek için Hive Yapılandırmaları sekmesine gidin ve Ayarlar sayfasında Azaltıcı Başına Veri parametresini bulun.
Değeri 128 MB (134.217.728 bayt) olarak değiştirmek için Düzenle'yi seçin ve ardından kaydetmek için Enter tuşuna basın.
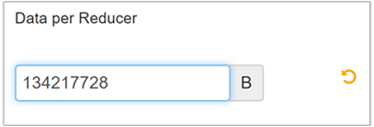
1.024 MB giriş boyutu ve azaltıcı başına 128 MB veri verildiğinde sekiz azaltıcı vardır (1024/128).
Azaltıcı Başına Veri parametresi için yanlış bir değer, çok sayıda azaltıcıya neden olabilir ve sorgu performansını olumsuz etkileyebilir. En fazla azaltıcı sayısını sınırlamak için uygun bir değere ayarlayın
hive.exec.reducers.max. Varsayılan değer 1009'dur.
Paralel yürütmeyi etkinleştirme
Hive sorgusu bir veya daha fazla aşamada yürütülür. Bağımsız aşamalar paralel olarak çalıştırılabilirse, bu sorgu performansını artırır.
Paralel sorgu yürütmeyi etkinleştirmek için Hive Yapılandırma sekmesine gidin ve özelliğini arayın
hive.exec.parallel. Varsayılan değer olarak yanlış kullanılır. Değeri true olarak değiştirin ve enter tuşuna basarak değeri kaydedin.Paralel çalıştırılacak iş sayısını sınırlamak için özelliğini değiştirin
hive.exec.parallel.thread.number. Varsayılan değer 8'dir.
Vektörleştirmeyi etkinleştirme
Hive, verileri satır satır işler. Vektörleştirme, Hive'ı tek seferde bir satır yerine 1.024 satırlık bloklar halinde verileri işlemeye yönlendirir. Vektörleştirme yalnızca ORC dosya biçimi için geçerlidir.
Vektörleştirilmiş sorgu yürütmeyi etkinleştirmek için Hive Yapılandırmaları sekmesine gidin ve parametresini
hive.vectorized.execution.enabledarayın. Hive 0.13.0 veya üzeri için varsayılan değer doğrudur.Sorgunun azaltma tarafında vektörleştirilmiş yürütmeyi etkinleştirmek için parametresini
hive.vectorized.execution.reduce.enabledtrue olarak ayarlayın. Varsayılan değer olarak yanlış kullanılır.
Maliyet tabanlı iyileştirmeyi (CBO) etkinleştirme
Hive, varsayılan olarak en uygun sorgu yürütme planını bulmak için bir dizi kural izler. Maliyet tabanlı iyileştirme (CBO), sorgu yürütmek için birden çok planı değerlendirir. Her plana bir maliyet atar ve ardından sorgu yürütmek için en ucuz planı belirler.
CBO'yı etkinleştirmek için Hive>Yapılandırmaları'na> gidin Ayarlar Maliyet Tabanlı İyileştiriciyi Etkinleştir'i bulun ve iki durumlu düğmeyi Açık olarak değiştirin.

Aşağıdaki ek yapılandırma parametreleri, CBO etkinleştirildiğinde Hive sorgu performansını artırır:
hive.compute.query.using.statsTrue olarak ayarlandığında Hive, gibi
count(*)basit sorguları yanıtlamak için meta veri deposunda depolanan istatistikleri kullanır.
hive.stats.fetch.column.statsSütun istatistikleri, CBO etkinleştirildiğinde oluşturulur. Hive, sorguları iyileştirmek için meta veri deposunda depolanan sütun istatistiklerini kullanır. Sütun sayısı yüksek olduğunda her sütun için sütun istatistiklerini getirme işlemi daha uzun sürer. False olarak ayarlandığında, bu ayar meta veri deposundan sütun istatistiklerini getirmeyi devre dışı bırakır.
hive.stats.fetch.partition.statsSatır sayısı, veri boyutu ve dosya boyutu gibi temel bölüm istatistikleri meta veri deposunda depolanır. true olarak ayarlanırsa bölüm istatistikleri meta veri deposundan getirilir. False olduğunda, dosya boyutu dosya sisteminden getirilir. Satır sayısı da satır şemasından getirilir.
Daha fazla bilgi için Azure'da Analiz Blogu'ndaki Hive Maliyet Tabanlı İyileştirme blog gönderisine bakın
Ara sıkıştırmayı etkinleştirme
Eşleme görevleri, azaltıcı görevler tarafından kullanılan ara dosyalar oluşturur. Ara sıkıştırma, ara dosya boyutunu küçültür.
Hadoop işleri genellikle G/Ç performans sorunlarına neden olur. Verilerin sıkıştırılması G/Ç ve genel ağ aktarımını hızlandırabilir.
Kullanılabilir sıkıştırma türleri şunlardır:
| Biçimlendir | Araç | Algoritma | Dosya Uzantısı | Bölünebilir mi? |
|---|---|---|---|---|
| Gzip | Gzip | DEFLATE | .gz |
Hayır |
| Bzip2 | Bzip2 | Bzip2 | .bz2 |
Yes |
| LZO | Lzop |
LZO | .lzo |
Evet, dizinlenmişse |
| Çabuk | Yok | Çabuk | Çabuk | Hayır |
Genel bir kural olarak, sıkıştırma yöntemi splittable'ın olması önemlidir, aksi takdirde birkaç eşleyici oluşturulur. Giriş verileri metinse en bzip2 iyi seçenektir. ORC biçimi için Snappy en hızlı sıkıştırma seçeneğidir.
Ara sıkıştırmayı etkinleştirmek için Hive Yapılandırmaları sekmesine gidin ve parametresini
hive.exec.compress.intermediatetrue olarak ayarlayın. Varsayılan değer olarak yanlış kullanılır.
Not
Ara dosyaları sıkıştırmak için, codec'in yüksek sıkıştırma çıkışı olmasa bile daha düşük CPU maliyetine sahip bir sıkıştırma codec'i seçin.
Ara sıkıştırma codec'ini ayarlamak için veya
mapred-site.xmldosyasına özel özelliğimapred.map.output.compression.codechive-site.xmlekleyin.Özel ayar eklemek için:
a. Hive>Yapılandırmaları>Gelişmiş>Özel hive-sitesine gidin.
b. Özel hive-site bölmesinin alt kısmındaki Özellik Ekle... öğesini seçin.
c. Özellik Ekle penceresinde anahtar olarak ve
org.apache.hadoop.io.compress.SnappyCodecdeğer olarak girinmapred.map.output.compression.codec.d. Ekle'yi seçin.
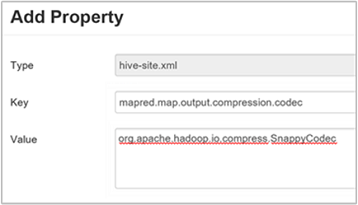
Bu ayar, Snappy sıkıştırmasını kullanarak ara dosyayı sıkıştırır. Özellik eklendikten sonra Özel hive-site bölmesinde görünür.
Not
Bu yordam dosyayı değiştirir
$HADOOP_HOME/conf/hive-site.xml.
Son çıkışı sıkıştır
Son Hive çıkışı da sıkıştırılabilir.
Son Hive çıkışını sıkıştırmak için Hive Yapılandırmaları sekmesine gidin ve parametresini
hive.exec.compress.outputtrue olarak ayarlayın. Varsayılan değer olarak yanlış kullanılır.Çıkış sıkıştırma codec'ini seçmek için, özel özelliği önceki bölümün 3. adımında açıklandığı gibi Özel hive-site bölmesine ekleyin
mapred.output.compression.codec.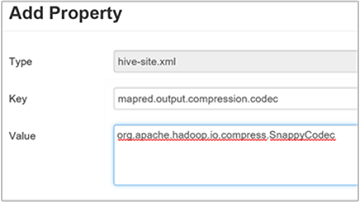
Kurgusal yürütmeyi etkinleştirme
Tahmini yürütme, yavaş çalışan görev izleyicisini algılamak ve reddetmek için belirli sayıda yinelenen görevi başlatır. Tek tek görev sonuçlarını iyileştirerek genel iş yürütmeyi geliştirirken.
Büyük miktarda giriş içeren uzun süre çalışan MapReduce görevleri için tahmini yürütme açık olmamalıdır.
Tahmini yürütmeyi etkinleştirmek için Hive Yapılandırmaları sekmesine gidin ve parametresini
hive.mapred.reduce.tasks.speculative.executiontrue olarak ayarlayın. Varsayılan değer olarak yanlış kullanılır.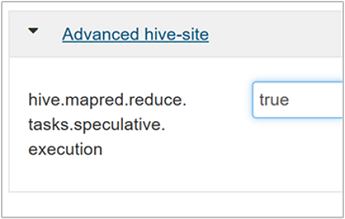
Dinamik bölümleri ayarlama
Hive, her bölümü önceden tanımlamadan bir tabloya kayıt eklerken dinamik bölümler oluşturulmasına olanak tanır. Bu özellik güçlü bir özelliktir. Ancak çok sayıda bölüm oluşturulmasına neden olabilir. Ve her bölüm için çok sayıda dosya.
Hive'ın dinamik bölümler
hive.exec.dynamic.partitionyapması için parametre değeri true (varsayılan) olmalıdır.Dinamik bölüm modunu katı olarak değiştirin. Katı modda en az bir bölümün statik olması gerekir. Bu ayar WHERE yan tümcesinde bölüm filtresi olmayan sorguları engeller, yani tüm bölümleri tarayen sorguları kesin olarak engeller. Hive Yapılandırmaları sekmesine gidin ve katı olarak ayarlayın
hive.exec.dynamic.partition.mode. Varsayılan değer çekişsizdir.Oluşturulacak dinamik bölüm sayısını sınırlamak için parametresini
hive.exec.max.dynamic.partitionsdeğiştirin. Varsayılan değer 5000'dir.Düğüm başına toplam dinamik bölüm sayısını sınırlamak için öğesini değiştirin
hive.exec.max.dynamic.partitions.pernode. Varsayılan değer 2000'dir.
Yerel modu etkinleştirme
Yerel mod, Hive'ın bir işin tüm görevlerini tek bir makinede gerçekleştirmesini sağlar. Veya bazen tek bir işlemde. Bu ayar, giriş verileri küçükse sorgu performansını artırır. Sorgular için görevleri başlatma yükü, genel sorgu yürütmesinin önemli bir yüzdesini tüketir.
Yerel modu etkinleştirmek için Ara sıkıştırmayı hive.exec.mode.local.auto etkinleştir bölümünün 3. adımında açıklandığı gibi parametresini Özel hive-site paneline ekleyin.

Tek MapReduce MultiGROUP BY ayarlama
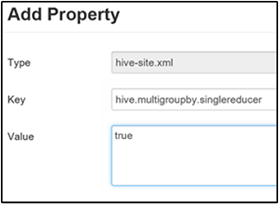
Bu özellik true olarak ayarlandığında, ortak gruplandırma anahtarları olan multiGROUP BY sorgusu tek bir MapReduce işi oluşturur.
Bu davranışı etkinleştirmek için Ara sıkıştırmayı hive.multigroupby.singlereducer etkinleştir bölümünün 3. adımında açıklandığı gibi parametresini Özel hive-site bölmesine ekleyin.
Ek Hive iyileştirmeleri
Aşağıdaki bölümlerde, ayarlayabileceğiniz Hive ile ilgili ek iyileştirmeler açıklanmaktadır.
Birleştirme iyileştirmeleri
Hive'daki varsayılan birleştirme türü karışık birleştirmedir. Hive'da özel eşleyiciler girişi okur ve bir birleştirme anahtarı/değer çiftini ara bir dosyaya yayar. Hadoop bu çiftleri bir karıştırma aşamasında sıralar ve birleştirir. Bu karıştırma aşaması pahalıdır. Verilerinize göre doğru birleştirmeyi seçmek performansı önemli ölçüde artırabilir.
| Birleştirme Türü | Ne zaman | Nasıl? | Hive ayarları | Açıklamalar |
|---|---|---|---|---|
| Birleştirmeyi Karıştır |
|
|
Önemli bir Hive ayarı gerekmez | Her seferinde çalışır |
| Harita Katılımı |
|
|
hive.auto.confvert.join=true |
Hızlı, ancak sınırlı |
| Birleştirme Demetlerini Sırala | Her iki tablo da şu şekildeyse:
|
Her işlem:
|
hive.auto.convert.sortmerge.join=true |
Verimli |
Yürütme altyapısı iyileştirmeleri
Hive yürütme altyapısını iyileştirmeye yönelik ek öneriler:
| Ayar | Önerilir | HDInsight Varsayılanı |
|---|---|---|
hive.mapjoin.hybridgrace.hashtable |
True = daha güvenli, daha yavaş; false = daha hızlı | yanlış |
tez.am.resource.memory.mb |
Çoğu için 4 GB üst sınır | Otomatik Ayarlı |
tez.session.am.dag.submit.timeout.secs |
300+ | 300 |
tez.am.container.idle.release-timeout-min.millis |
20000+ | 10000 |
tez.am.container.idle.release-timeout-max.millis |
40000+ | 20000 |