具有數據流的 AI
本文說明如何將人工智慧 (AI) 與數據流搭配使用。 本文章說明:
- 認知服務
- 自動化機器學習
- Azure 機器學習 整合
Power BI 中的認知服務
使用 Power BI 中的認知服務,您可以從 Azure 認知服務套用不同的演算法,以在數據流的自助數據準備中擴充您的數據。
目前支持的服務包括 情感分析、 關鍵詞組擷取、 語言偵測和 影像標記。 轉換會在 Power BI 服務 上執行,而且不需要 Azure 認知服務訂用帳戶。 此功能需要Power BI 進階版。
啟用 AI 功能
認知服務支援 進階版 容量節點 EM2、A2 或 P1 和其他具有更多資源的節點。 認知服務也可搭配 進階版 每位使用者 (PPU) 授權使用。 容量上的個別 AI 工作負載可用來執行認知服務。 在 Power BI 中使用認知服務之前,必須在 管理員 入口網站的 [容量] 設定中啟用 AI 工作負載。 您可以在 [工作負載] 區段中開啟 AI 工作負載。
![管理員 入口網站的螢幕快照,其中顯示 [容量] 設定。](media/service-cognitive-services/cognitive-services-01.png)
在 Power BI 中開始使用認知服務
認知服務轉換是數據流自助數據準備的一部分。 若要使用認知服務擴充您的數據,請從編輯數據流開始。
選取 Power Query 編輯器 頂端功能區中的 [AI 見解] 按鈕。
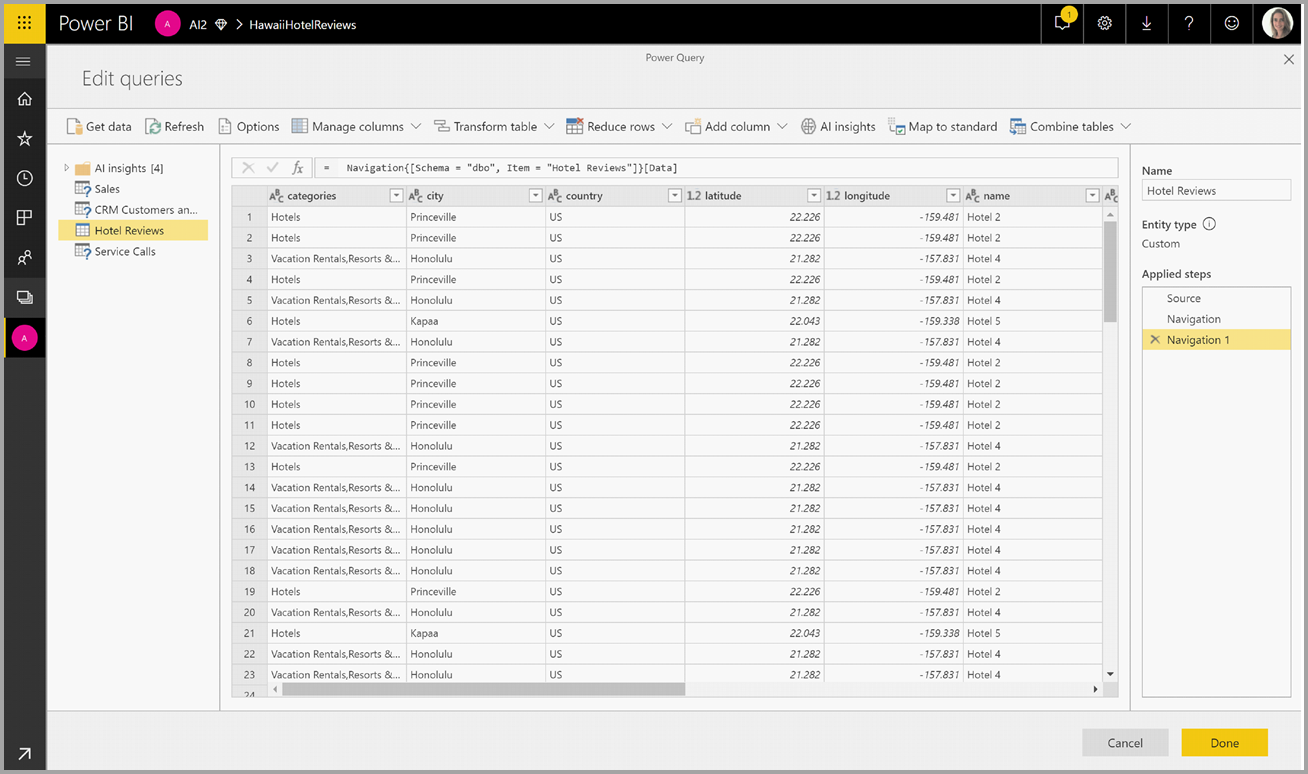
在彈出視窗中,選取您想要使用的函式,以及您想要轉換的數據。 此範例會為包含檢閱文字的數據行情感評分。
![[叫用函式] 對話框的螢幕快照,其中顯示已選取 CognitiveServices.ScoreSentiment。](media/service-cognitive-services/cognitive-services-04.png)
LanguageISOCode 是指定文字語言的選擇性輸入。 此資料行需要 ISO 程式代碼。 您可以使用數據行作為 LanguageISOCode 的輸入,也可以使用靜態數據行。 在此範例中,語言會指定為整個數據行的英文 (en)。 如果您將此數據行保留空白,Power BI 會在套用函式之前自動偵測語言。 接下來,選取 [ 叫用]。
![[叫用函式] 對話框的螢幕快照,其中顯示已選取 CognitiveServices.ScoreSentiment 並設定為 LanguageIsoCode。](media/service-cognitive-services/cognitive-services-05.png)
叫用函式之後,結果會新增為數據表的新數據行。 轉換也會新增為查詢中已套用的步驟。
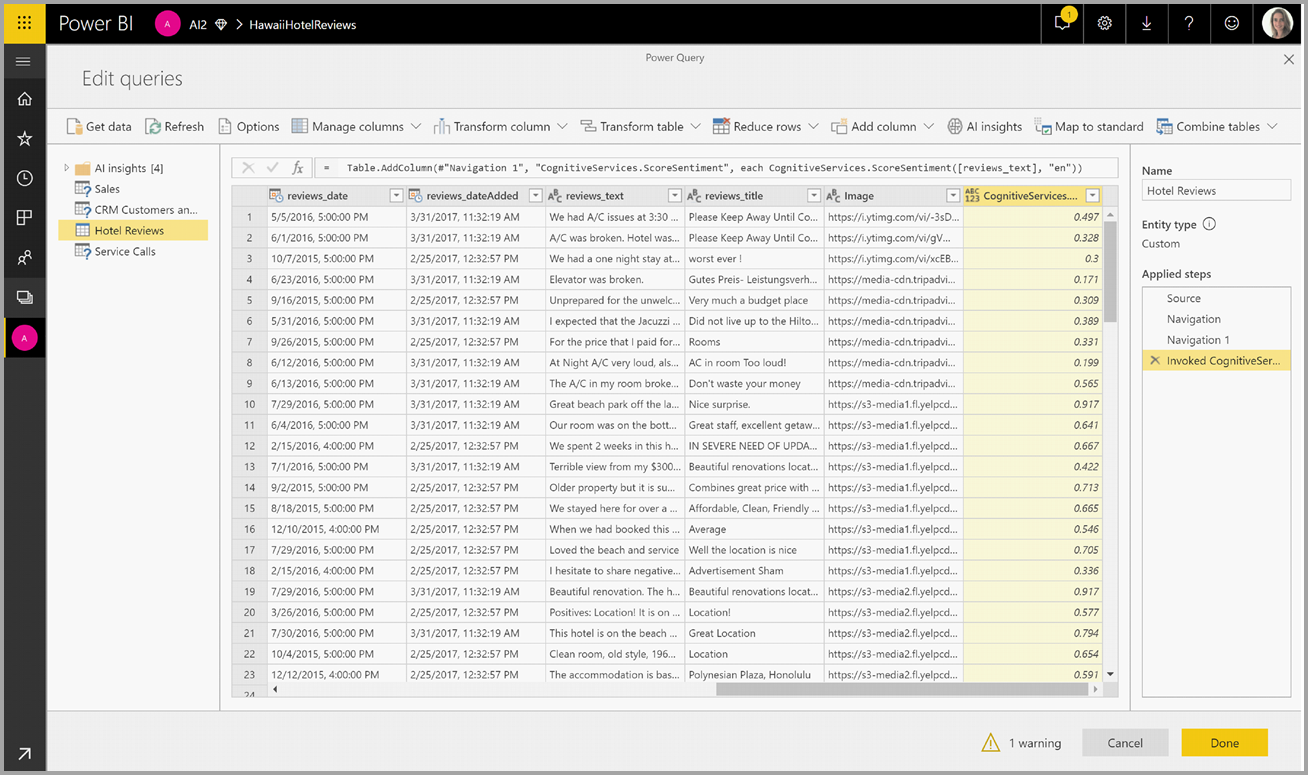
如果函式傳回多個輸出數據行,則叫用函式會新增具有多個輸出數據行數據列的新數據行。
使用 expand 選項,將一或兩個值新增為數據行。

可用的函數
本節說明 Power BI 中認知服務中可用的函式。
偵測語言
語言偵測函式會評估文字輸入,並針對每個數據行傳回語言名稱和 ISO 識別碼。 此函式適用於收集任意文字的數據行,其中語言未知。 函式預期文字格式為輸入的數據。
文字分析 最多可辨識 120 種語言。 如需詳細資訊,請參閱 什麼是 Azure 認知服務中適用於語言的語言偵測。
擷取關鍵詞組
關鍵片語擷 取 函式會評估非結構化文字,並針對每個文字數據行傳回關鍵片語清單。 函式需要文字數據行做為輸入,並接受 LanguageISOCode 的選擇性輸入。 如需詳細資訊,請參閱 開始使用。
關鍵片語擷取最適合當您提供較大的文字區塊來處理時,與情感分析相反。 情感分析在較小的文字區塊上執行得更好。 若要從這兩個作業中取得最佳結果,請考慮據以重建輸入。
評分情感
評分 情感 函式會評估文字輸入,並傳回每個檔的情感分數,範圍從0(負數)到1(正數)。 此功能有助於偵測社交媒體、客戶評論和討論論壇中的正面和負面情緒。
文字分析 使用機器學習分類演算法來產生介於 0 到 1 之間的情感分數。 接近 1 的分數表示正面情緒。 接近 0 的分數表示負面情緒。 此模型會使用具有情感關聯的廣泛文字主體預先定型。 目前無法提供您自己的訓練數據。 此模型會在文字分析期間使用技術的組合,包括文字處理、語音部分分析、文字放置和文字關聯。 如需演算法的詳細資訊,請參閱 機器學習 和 文字分析。
情感分析是在整個輸入數據行上執行,而不是擷取文字中特定數據表的情感。 在實務上,當檔包含一或兩個句子,而不是大量的文字區塊時,評分精確度會有所改善。 在客觀評估階段,模型會判斷整個輸入數據行是否為客觀或包含情感。 大部分是客觀的輸入數據行不會進展至情感偵測片語,導致0.50分數,不會進一步處理。 對於在管線中繼續的輸入數據行,下一個階段會根據輸入數據行中偵測到的情感程度,產生大於或小於0.50的分數。
情感分析目前支援英文、德文、西班牙文和法文。 其他語言處於預覽狀態。 如需詳細資訊,請參閱 什麼是 Azure 認知服務中適用於語言的語言偵測。
標記影像
標記 影像 函式會根據超過 2,000 個可辨識的物件、活體、風景和動作來傳回標記。 當卷標模棱兩可或不常見的知識時,輸出會提供「提示」來釐清已知設定內容中標記的意義。 標記不會組織為分類法,而且沒有任何繼承階層存在。 內容標記的集合會形成影像 「描述」的基礎,該影像會顯示為完整句子中格式化的人類可讀語言。
上傳影像或指定影像 URL 之後,電腦視覺 演算法會根據影像中識別的物件、活體和動作來輸出標記。 標記不限於主要主題,例如前景的人,但也包括設置(室內或戶外)、傢俱、工具、植物、動物、配件、小工具等。
此函式需要影像 URL 或 abase-64 數據行做為輸入。 目前,影像標記支援英文、西班牙文、日文、葡萄牙文和簡體中文。 如需詳細資訊,請參閱 ComputerVision 介面。
Power BI 中的自動化機器學習
數據流的自動化機器學習 (AutoML) 可讓商務分析師直接在Power BI中定型、驗證及叫用機器學習服務模型。 其中包含建立新 ML 模型的簡單體驗,讓分析師可以使用其數據流來指定定型模型的輸入數據。 服務會自動擷取最相關的功能、選取適當的演算法,以及微調和驗證 ML 模型。 定型模型之後,Power BI 會自動產生包含驗證結果的效能報告。 然後,可以在數據流內的任何新或更新數據上叫用模型。
自動化機器學習僅適用於 Power BI 進階版 和 Embedded 容量上裝載的數據流。
使用 AutoML
機器學習和 AI 正從產業和科學研究領域看到前所未有的受歡迎程度上升。 企業也在尋找將這些新技術整合到其營運中的方法。
數據流為巨量數據提供自助數據準備。 AutoML 已整合到數據流中,並可讓您直接在 Power BI 內使用數據準備來建置機器學習模型。
Power BI 中的 AutoML 可讓數據分析師只使用 Power BI 技能,利用簡化的體驗來建置機器學習模型。 Power BI 會將建立 ML 模型背後的大部分數據科學自動化。 它有護欄,以確保產生的模型具有良好的品質,並提供用來建立 ML 模型之程式的可見度。
AutoML 支援為數據流建立 二進位預測、 分類和 回歸模型 。 這些功能是受監督機器學習技術的類型,這表示它們會從過去觀察的已知結果中學習,以預測其他觀察的結果。 用來定型 AutoML 模型的輸入語意模型是一組標示為已知結果的數據列。
Power BI 中的 AutoML 會從 Azure 機器學習 整合自動化 ML,以建立 ML 模型。 不過,您不需要 Azure 訂用帳戶才能在 Power BI 中使用 AutoML。 Power BI 服務 會完全管理定型和裝載 ML 模型的程式。
定型 ML 模型之後,AutoML 會自動產生 Power BI 報表,說明 ML 模型的可能效能。 AutoML 強調可解釋性,方法是在影響模型所傳回預測的輸入中強調關鍵影響因素。 報表也包含模型的主要計量。
所產生報表的其他頁面會顯示模型的統計摘要和定型詳細數據。 統計摘要對想要查看模型效能的標準數據科學量值的用戶感興趣。 定型詳細數據摘要說明執行以建立模型的所有反覆專案,以及相關聯的模型參數。 它也會描述每個輸入如何用來建立 ML 模型。
然後,您可以將 ML 模型套用至數據以進行評分。 重新整理數據流時,您的數據會以ML模型的預測進行更新。 Power BI 也包含 ML 模型產生之每個特定預測的個別說明。
建立機器學習模型
本節說明如何建立 AutoML 模型。
建立 ML 模型的數據準備
若要在 Power BI 中建立機器學習模型,您必須先為包含歷程記錄結果資訊的數據建立數據流,以用於定型 ML 模型。 您也應該針對任何可能強式預測結果的商務計量新增匯出數據行,以取得您嘗試預測的結果。 如需設定數據流的詳細資訊,請參閱 設定及取用數據流。
AutoML 具有定型機器學習模型的特定數據需求。 下列各節會根據各自的模型類型來說明這些需求。
設定 ML 模型輸入
若要建立 AutoML 模型,請在數據流數據表的 [動作] 資料行中選取 ML 圖示,然後選取 [新增機器學習模型]。
![在數據流實體上醒目提示的 [新增機器學習模型動作] 螢幕快照。](media/service-machine-learning-automated/automated-machine-learning-power-bi-02.png)
簡化的體驗啟動,由精靈組成,可引導您完成建立 ML 模型的程式。 精靈包含下列簡單步驟。
1.選取具有歷程記錄數據的數據表,然後選擇您想要預測的結果數據行
結果數據行會識別用於定型 ML 模型的標籤屬性,如下圖所示。
![[選取要預測的欄位] 頁面的螢幕快照。](media/service-machine-learning-automated/automated-machine-learning-power-bi-03.png)
2.選擇模型類型
當您指定結果數據行時,AutoML 會分析標籤數據,以建議可定型的最有可能 ML 模型類型。 您可以按兩下 [選擇模型] 來挑選不同的模型類型,如下圖所示。
![顯示 [選擇模型] 頁面的螢幕快照。](media/service-machine-learning-automated/automated-machine-learning-power-bi-04.png)
注意
您選取的數據可能不支援某些模型類型,因此會停用。 在上一個範例中,由於已選取文字數據行做為結果數據行,因此會停用回歸。
3.選取您想要模型用來作為預測訊號的輸入
AutoML 會分析所選數據表的範例,以建議可用於定型 ML 模型的輸入。 未選取的數據行旁邊會提供說明。 如果特定數據行有太多相異值或只有一個值,或輸出數據行的低或高相互關聯,則不建議這麼做。
任何相依於結果數據行(或標籤數據行)的輸入都不應該用於定型 ML 模型,因為它們會影響其效能。 這類數據行會標示為「與輸出數據行有可疑的高關聯性」。 在定型數據中引進這些數據行會導致卷標外泄,其中模型在驗證或測試數據上表現良好,但在生產環境中用於評分時,無法比對該效能。 當定型模型效能太好,無法正確時,AutoML 模型中的標籤漏可能是可能的問題。
這項功能建議是以數據的範例為基礎,因此您應該檢閱所使用的輸入。 您可以變更選取範圍,只包含您想要模型研究的數據行。 您也可以選取資料表名稱旁的複選框,以選取所有數據行。
![[選取要研究的數據] 頁面的螢幕快照。](media/service-machine-learning-automated/automated-machine-learning-power-bi-05.png)
4.為您的模型命名並儲存設定
在最後一個步驟中,您可以命名模型、選取 [ 儲存],然後選擇開始定型 ML 模型。 您可以選擇減少定型時間,以查看快速結果,或增加定型中花費的時間量,以取得最佳模型。
![顯示 [名稱] 和 [訓練] 頁面的螢幕快照。](media/service-machine-learning-automated/automated-machine-learning-power-bi-06.png)
ML 模型定型
AutoML 模型的定型是數據流重新整理的一部分。 AutoML 會先準備您的數據以進行定型。 AutoML 會將您提供的歷史數據分割成定型和測試語意模型。 測試語意模型是一個鑒效組,用於在定型之後驗證模型效能。 這些集合會實現為 數據流中的定型和測試 數據表。 AutoML 會針對模型驗證使用交叉驗證。
接下來,會分析每個輸入數據行並套用插補,以取代值取代任何遺漏值。 AutoML 會使用幾個不同的插補策略。 對於被視為數值特徵的輸入屬性,數據行值的平均值會用於插補。 針對被視為類別特徵的輸入屬性,AutoML 會使用數據行值的模式進行插補。 AutoML 架構會計算子取樣定型語意模型上用於插補的值平均值和模式。
然後,取樣和正規化會視需要套用至您的數據。 針對分類模型,AutoML 會透過分層取樣執行輸入數據,並平衡類別,以確保所有數據列計數都相等。
AutoML 會根據其數據類型和統計屬性,在每個選取的輸入數據行上套用數個轉換。 AutoML 會使用這些轉換來擷取用於定型 ML 模型的功能。
AutoML 模型的定型程式包含最多 50 個具有不同模型演算法和超參數設定的反覆專案,以找出效能最佳的模型。 如果 AutoML 注意到沒有觀察到效能改善,定型可能會以較少的反覆專案提早結束。 AutoML 會使用鑒效組測試語意模型來評估每個模型的效能。 在此定型步驟中,AutoML 會建立數個管線來定型和驗證這些反覆專案。 評估模型效能的程式可能需要一些時間,從幾分鐘到數小時,到精靈中設定的定型時間。 所花費的時間取決於您的語意模型大小和可用的容量資源。
在某些情況下,產生的最終模型可能會使用合奏學習,其中會使用多個模型來提供更佳的預測效能。
AutoML 模型可解釋性
定型模型之後,AutoML 會分析輸入特徵與模型輸出之間的關聯性。 它會評估每個輸入功能之鑒效組測試語意模型的模型輸出變更程度。 此關聯性稱為 特徵重要性。 此分析會在定型完成之後,作為重新整理的一部分進行。 因此,您的重新整理可能需要比精靈中所設定的定型時間還要長。
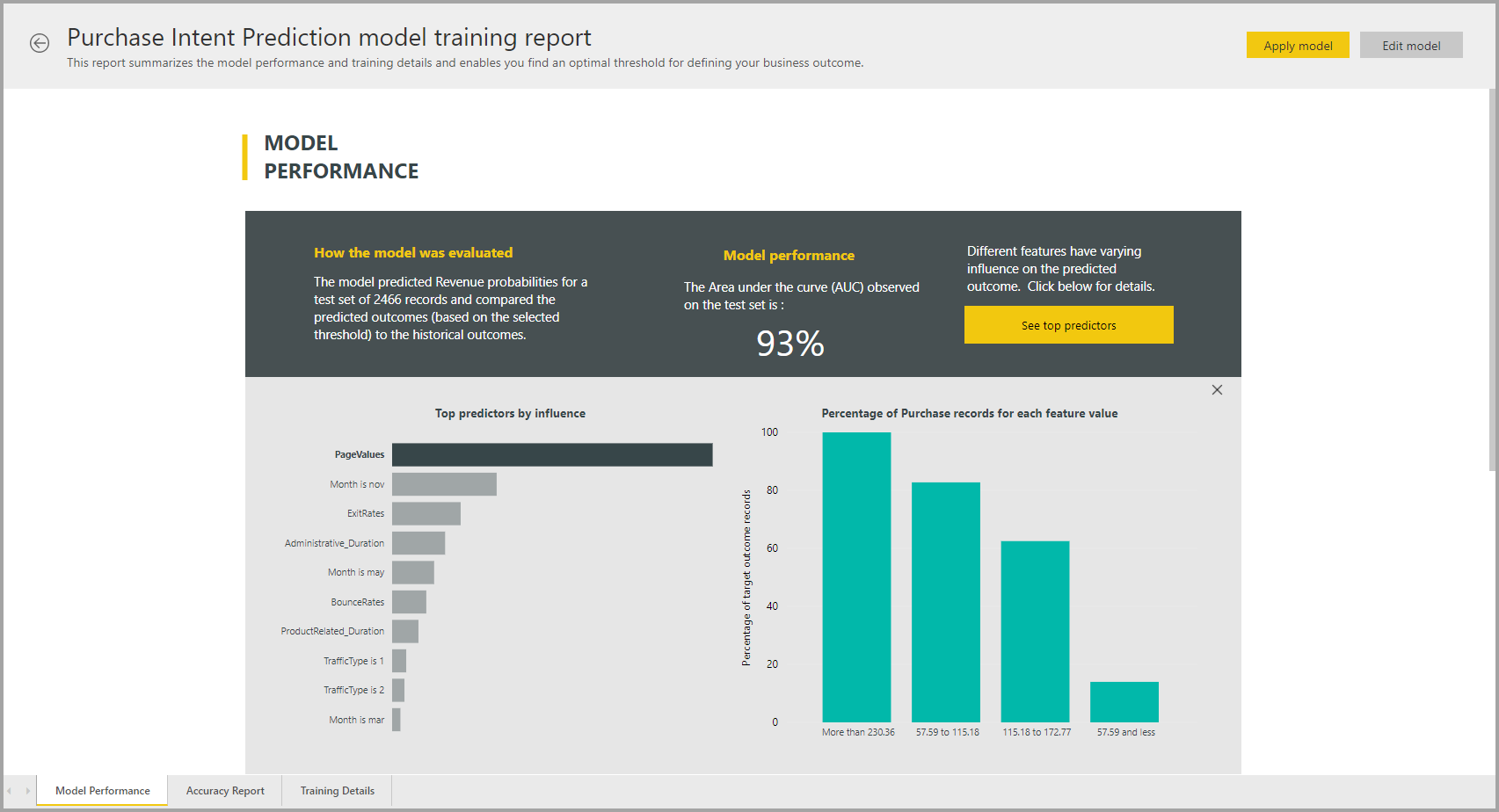
AutoML 模型報告
AutoML 會產生 Power BI 報表,其摘要說明驗證期間模型的效能,以及全域特徵重要性。 在數據流重新整理成功之後,可以從 [機器學習 模型] 索引卷標存取此報表。 報告摘要說明將 ML 模型套用至鑒效組測試數據,以及比較預測與已知結果值的結果。
您可以檢閱模型報告以瞭解其效能。 您也可以驗證模型的主要影響因素是否符合有關已知結果的商業見解。
用來描述報表中模型效能的圖表和量值取決於模型類型。 下列各節將說明這些效能圖表和量值。
報表中的其他頁面可能會從數據科學的觀點描述模型的相關統計量值。 例如, 二進位預測 報告包含模型的增益圖和 ROC 曲線。
這些報表也包含訓練 詳細 數據頁面,其中包含模型定型方式的描述,以及描述每個反覆項目執行之模型效能的圖表。
![模型報表上 [訓練詳細數據] 頁面的螢幕快照。](media/service-machine-learning-automated/automated-machine-learning-power-bi-08.png)
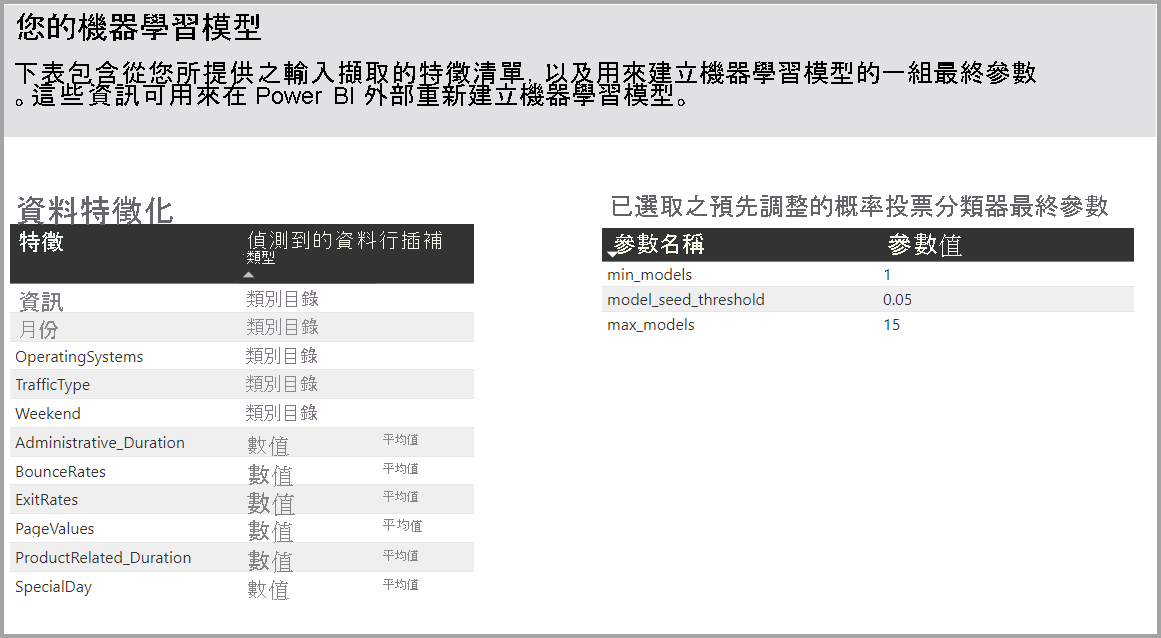
此頁面的另一個區段描述用來填滿遺漏值的輸入數據行和插補方法的偵測到類型。 它也包含最終模型所使用的參數。
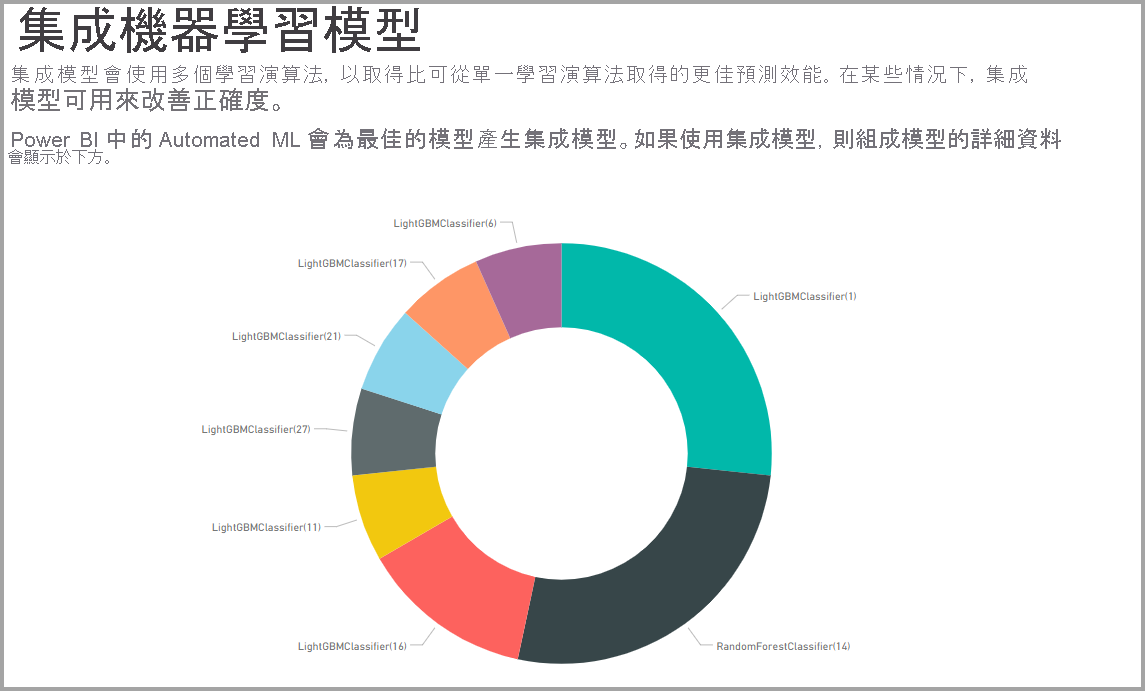
如果產生的模型使用合奏學習,則 [ 定型詳細數據 ] 頁面也會包含圖表,其中顯示合奏及其參數中每個構成模型的權數。
套用 AutoML 模型
如果您滿意所建立 ML 模型的效能,您可以在重新整理資料流時將其套用至新的或更新的數據。 在模型報表中,選取右上角的 [套用] 按鈕,或 [機器學習 模型] 索引標籤中動作下的 [套用 ML 模型] 按鈕。
若要套用 ML 模型,您必須指定它必須套用的數據表名稱,以及將新增至此數據表之模型輸出之數據行的前置詞。 數據行名稱的預設前置詞是模型名稱。 Apply 函式可能包含模型類型特定的更多參數。
套用 ML 模型會建立兩個新的數據流數據表,其中包含輸出數據表中每個數據列的預測和個別化說明。 例如,如果您將 PurchaseIntent 模型套用至 OnlineShoppers 數據表,輸出會產生 OnlineShoppers 擴充的 PurchaseIntent 和 OnlineShoppers 擴充的 PurchaseIntent 說明 數據表。 針對擴充數據表中的每個數據列,[ 說明 ] 會根據輸入功能細分為擴充說明數據表中的多個數據列。 ExplanationIndex 有助於將擴充說明數據表中的數據列對應至擴充數據表中的數據列。
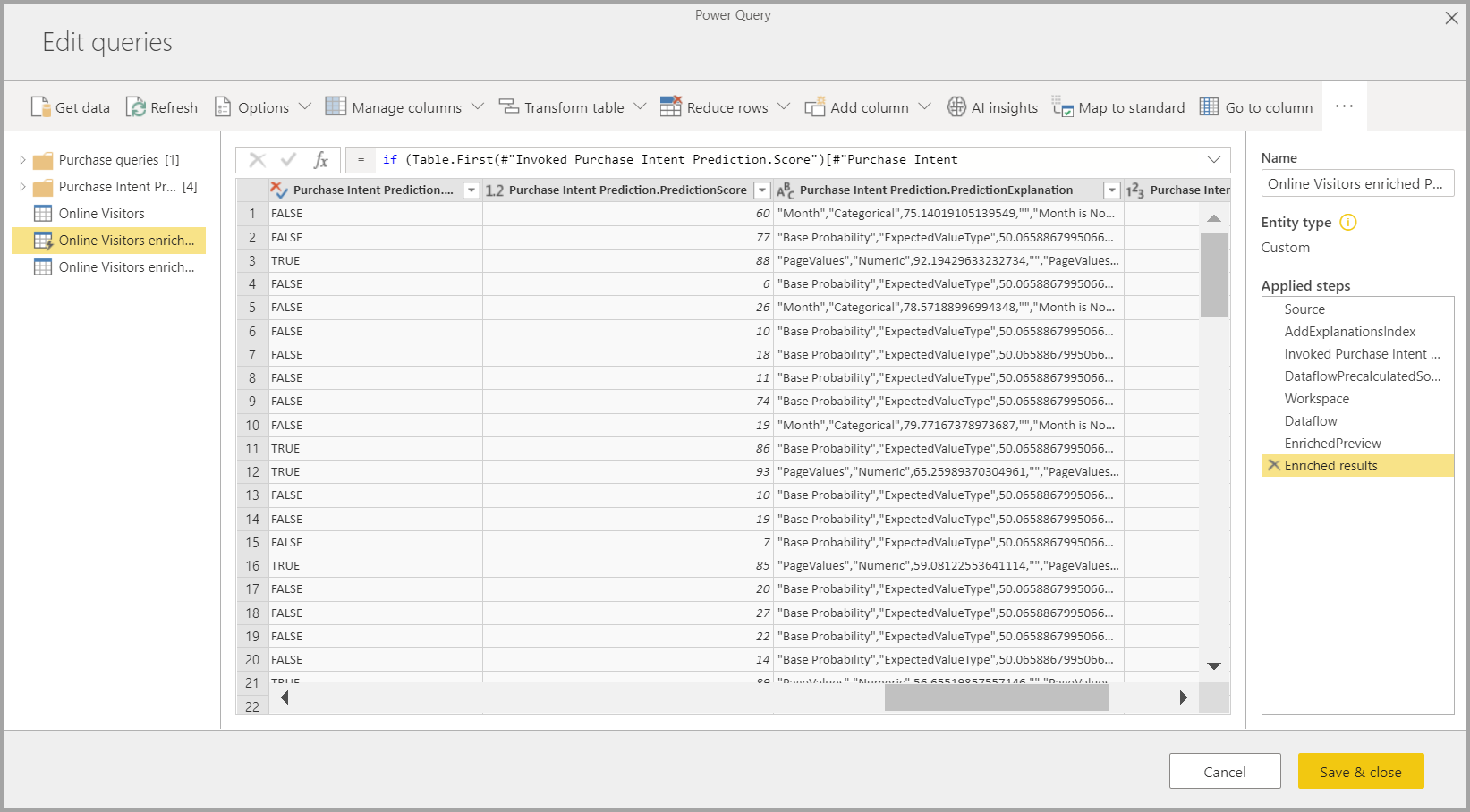
您也可以使用 PQO 函式瀏覽器中的 AI 見解,將任何 Power BI AutoML 模型套用至相同工作區中任何數據流中的數據表。 如此一來,您就可以使用其他人在相同工作區中建立的模型,而不一定是具有模型的數據流擁有者。 Power Query 會探索工作區中的所有 Power BI ML 模型,並將其公開為動態 Power Query 函式。 您可以從功能區存取 Power Query 編輯器 或直接叫用 M 函式,以叫用這些函式。 此功能目前僅支援 Power BI 數據流和 Power BI 服務 中的 Power Query Online。 此程式與使用 AutoML 精靈在數據流中套用 ML 模型不同。 沒有使用這個方法建立的說明數據表。 除非您是數據流的擁有者,否則您無法存取模型定型報表或重新定型模型。 此外,如果藉由新增或移除輸入數據行或模型或來源數據流來編輯來源模型,則此相依數據流將會中斷。
![[AI 深入解析] 對話框的螢幕快照,其中醒目提示 Power BI 機器學習 模型。](media/service-machine-learning-automated/automated-machine-learning-power-bi-20.png)
套用模型之後,每當重新整理數據流時,AutoML 一律會保持預測最新狀態。
若要使用 Power BI 報表中 ML 模型的深入解析和預測,您可以使用數據流連接器從 Power BI Desktop 連線到輸出數據表。
二進位預測模型
二元預測模型,更正式稱為 二元分類模型,可用來將語意模型分類成兩個群組。 它們可用來預測可產生二進位結果的事件。 例如,銷售商機是否會轉換、帳戶是否會變換、發票是否會準時支付、交易是否為詐騙等。
二元預測模型的輸出是機率分數,可識別目標結果將達成的可能性。
定型二進位預測模型
必要條件:
- 每個結果類別至少需要 20 個數據列的歷史數據
二元預測模型的建立程式會遵循與其他 AutoML 模型相同的步驟,如上一節 <設定 ML 模型輸入>中所述。 唯一的差異在於 選擇模型 步驟,您可以在其中選取您最感興趣的目標結果值。 您也可以為自動產生的報表中用來摘要模型驗證結果的結果提供易記標籤。
![[選擇二進位預測的模型] 頁面螢幕快照。](media/service-machine-learning-automated/automated-machine-learning-power-bi-12.png)
二進位預測模型報告
二元預測模型會產生輸出,這是數據列將達成目標結果的機率。 此報表包含機率臨界值的交叉分析篩選器,其會影響分數的更大和小於機率臨界值的解譯方式。
報告描述模型的效能,以 真判、誤判、真負數和誤判。 True Positives 和 True Negatives 是正確預測結果數據中兩個類別的結果。 誤判是預測有目標結果但實際上沒有的數據列。 相反地,False Negatives 是具有目標結果但預測為非目標結果的數據列。
量值,例如精確度和召回率,描述機率臨界值對預測結果的影響。 您可以使用機率臨界值交叉分析篩選器來選取臨界值,以達到有效位數與召回率之間的平衡妥協。
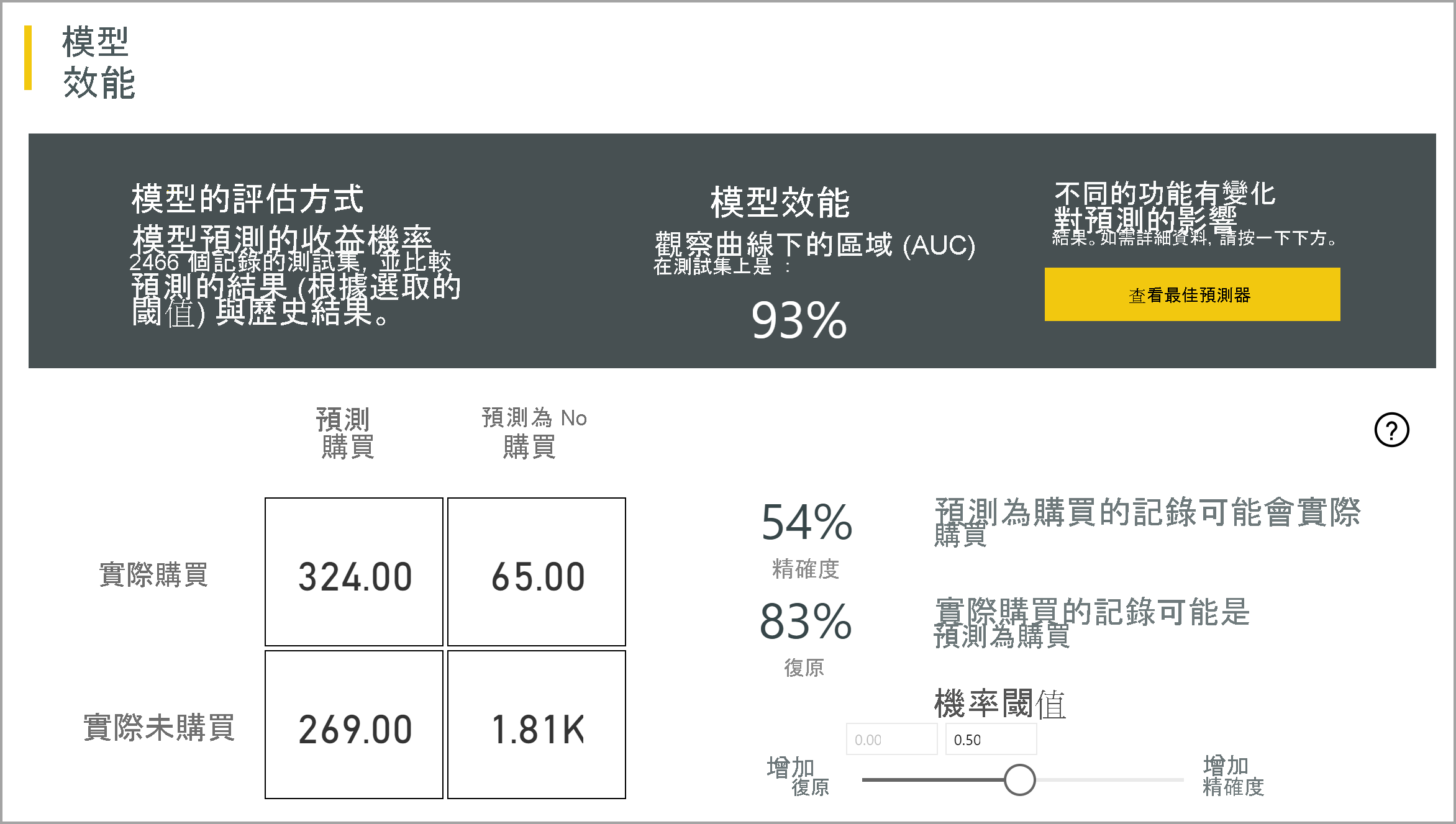
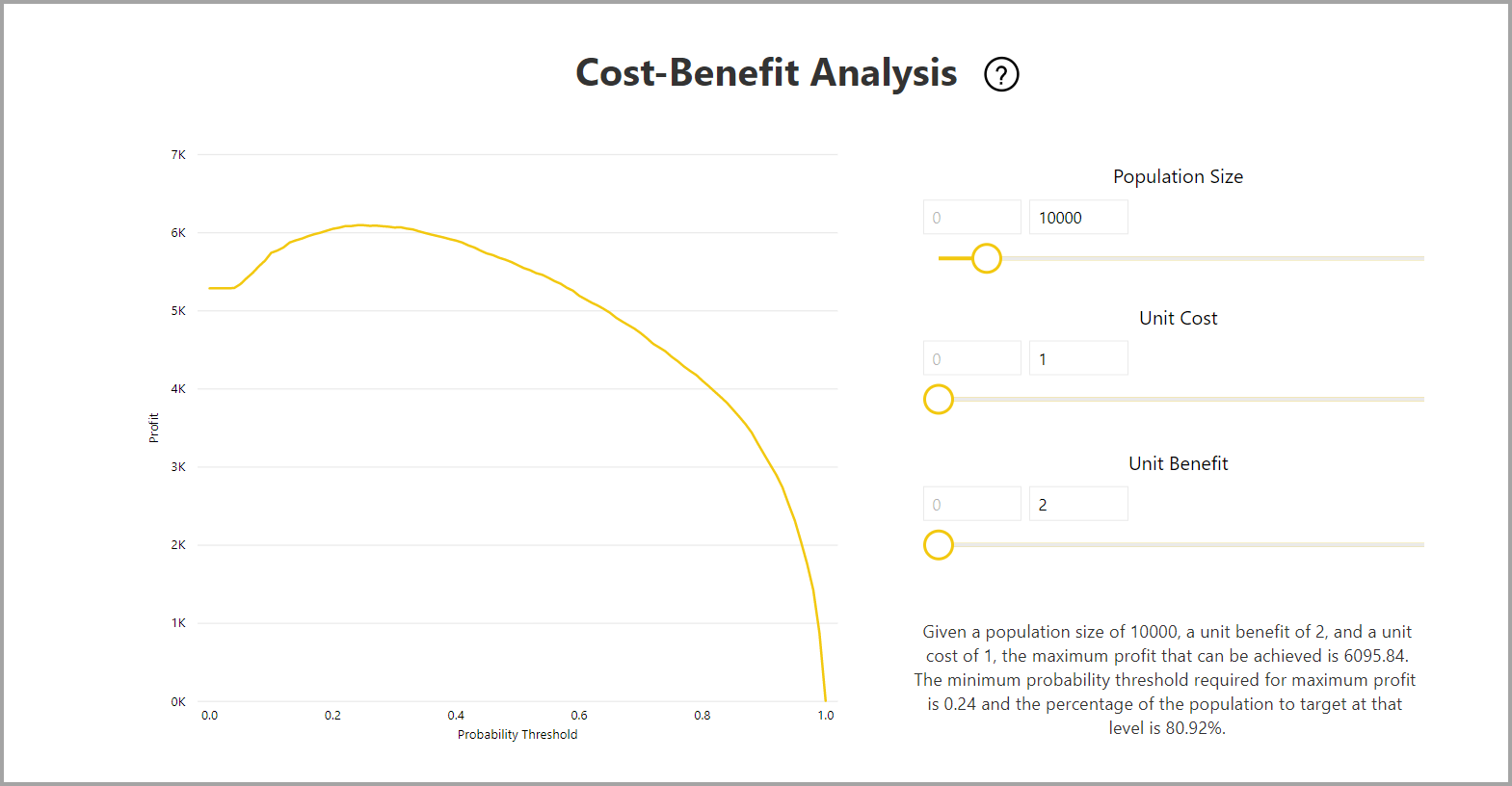
報告也包含 Cost-Benefit 分析工具,可協助識別應以產生最高利潤為目標的人口子集。 假設目標的預估單位成本,以及達成目標結果的單位效益,Cost-Benefit 分析會嘗試將利潤最大化。 您可以使用此工具,根據圖表中的最大點來挑選機率閾值,以最大化收益。 您也可以使用圖表來計算所選機率閾值的利潤或成本。
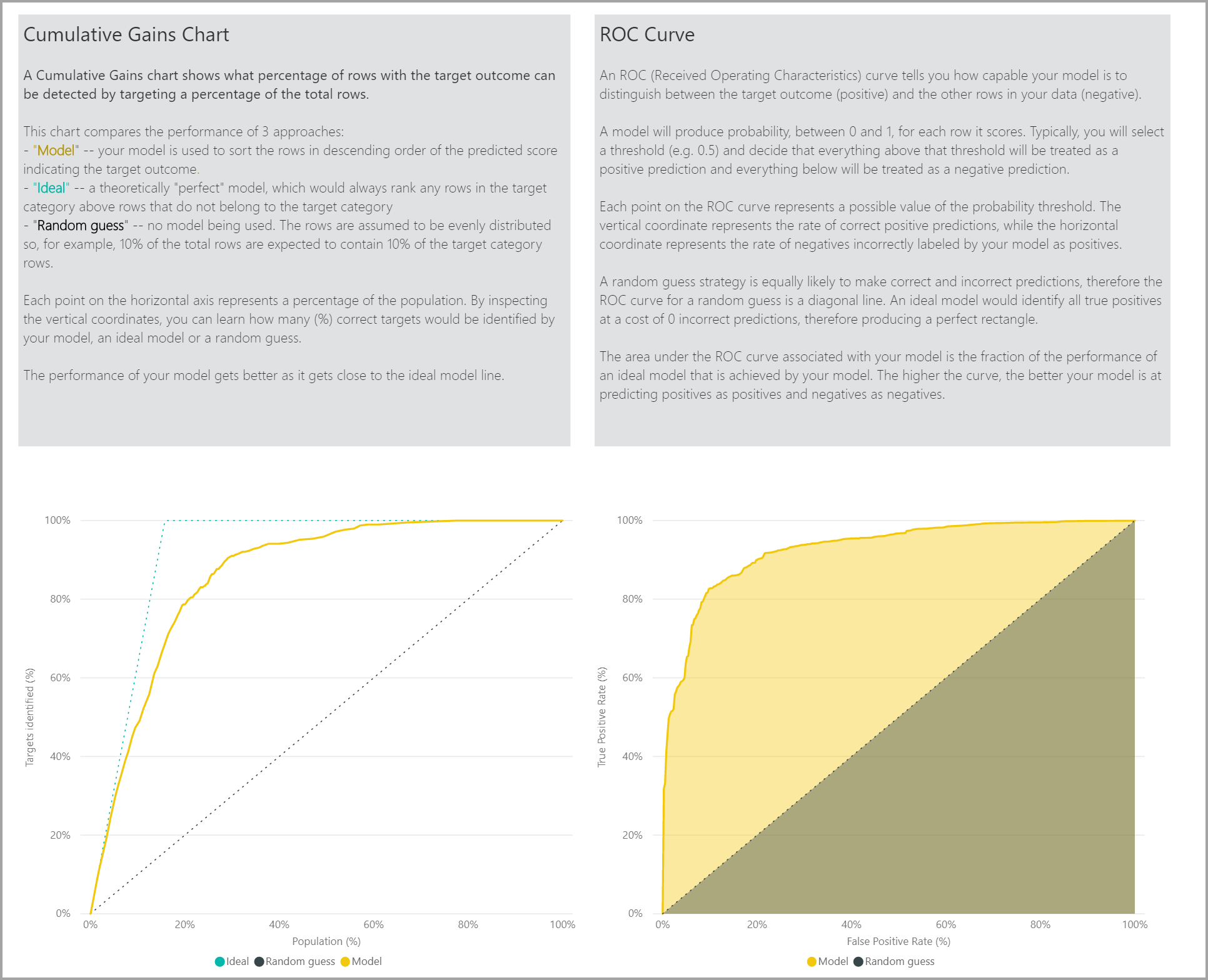
模型報表的 [精確度報告] 頁面包含模型的累積收益圖表和 ROC 曲線。 此數據會提供模型效能的統計量值。 這些報表包含所顯示圖表的描述。
套用二進位預測模型
若要套用二進位預測模型,您必須使用您想要從 ML 模型套用預測的數據來指定數據表。 其他參數包括輸出數據行名稱前置詞,以及分類預測結果的機率臨界值。
![[套用購買意圖預測] 對話框的螢幕快照。](media/service-machine-learning-automated/automated-machine-learning-power-bi-16.png)
套用二進位預測模型時,會將四個輸出數據行新增至擴充的輸出數據表:Result、PredictionScore、PredictionExplanation 和 ExplanationIndex。 在套用模型時,數據表中的數據行名稱具有指定的前置詞。
PredictionScore 是百分比機率,可識別目標結果將達成的可能性。
[結果] 資料行包含預測的結果標籤。 超過臨界值的記錄會預測為可能達到目標結果,並標示為 True。 小於閾值的記錄會預測為不太可能達到結果,且標示為 False。
PredictionExplanation 數據行包含說明,其中包含輸入特徵對 PredictionScore 的特定影響。
分類模型
分類模型可用來將語意模型分類成多個群組或類別。 它們可用來預測可以有多個可能結果的其中一個事件。 例如,客戶是否可能具有高、中或低存留期值。 它們也可以預測預設的風險是否很高、中度、低等。
分類模型的輸出是機率分數,可識別數據列將達到指定類別準則的可能性。
定型分類模型
包含分類模型定型數據的輸入數據表,必須具有字串或整數數據行做為結果數據行,以識別過去的已知結果。
必要條件:
- 每個結果類別至少需要 20 個數據列的歷史數據
分類模型的建立程式會遵循與其他 AutoML 模型相同的步驟,如上一節 <設定 ML 模型輸入>中所述。
分類模型報表
Power BI 會將 ML 模型套用至鑒效組測試數據,以建立分類模型報表。 然後,它會比較數據列的預測類別與實際的已知類別。
模型報表包含圖表,其中包含每個已知類別正確且未正確分類的數據列明細。
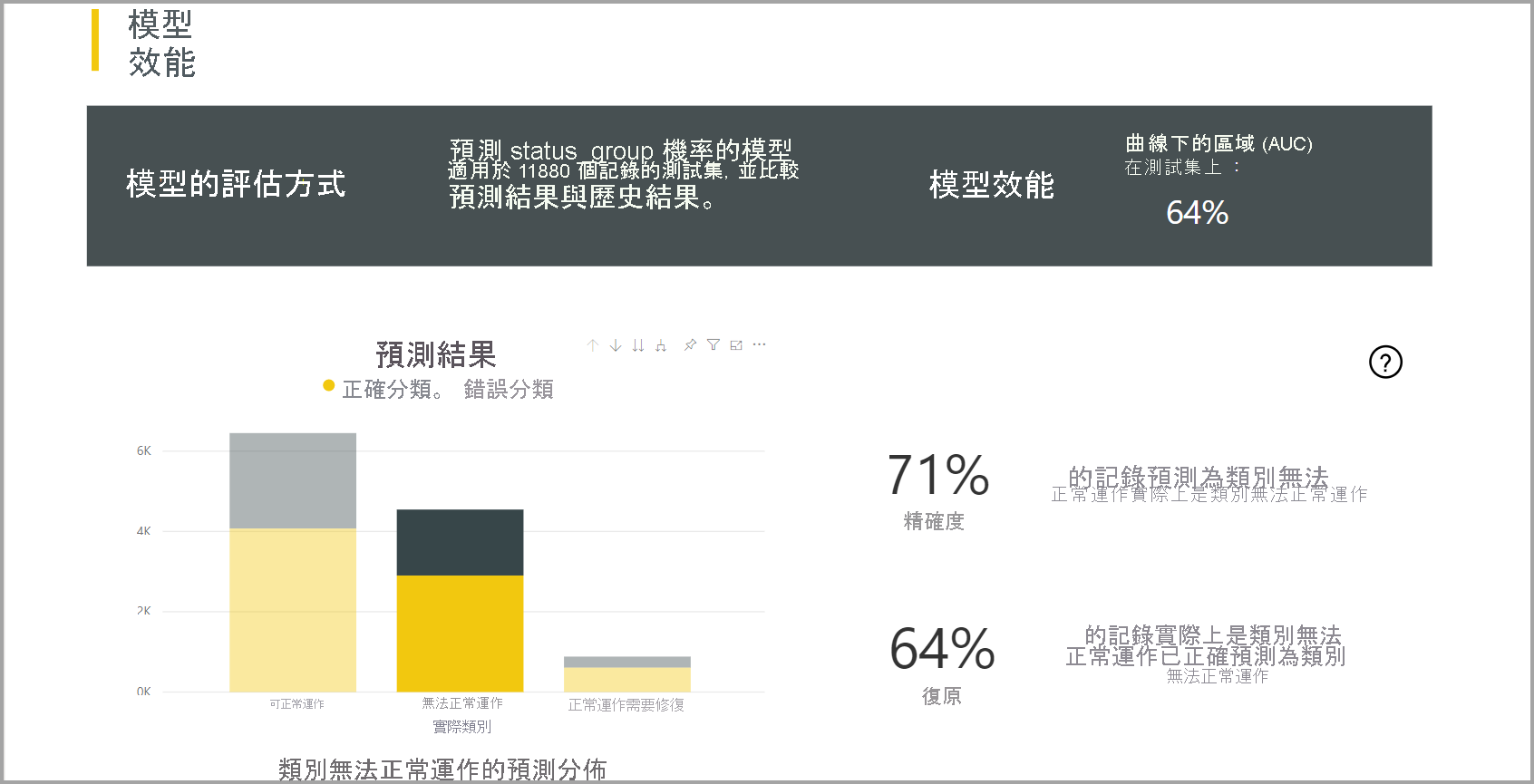
進一步的類別特定向下切入動作可讓您分析已知類別的預測分佈方式。 此分析顯示其他類別,其中已知類別的數據列可能分類錯誤。
報表中的模型說明也包含每個類別的最高預測值。
分類模型報表也包含類似其他模型類型頁面的訓練詳細數據頁面, 如先前在 AutoML 模型報告中所述。
套用分類模型
若要套用分類 ML 模型,您必須使用輸入資料和輸出數據行名稱前置詞來指定數據表。
套用分類模型時,會將五個輸出數據行新增至擴充的輸出數據表:ClassificationScore、ClassificationResult、ClassificationExplanation、ClassProbabilities 和 ExplanationIndex。 在套用模型時,數據表中的數據行名稱具有指定的前置詞。
ClassProbabilities 數據行包含每個可能類別之數據列的機率分數清單。
ClassificationScore 是百分比機率,可識別數據列將達到指定類別準則的可能性。
ClassificationResult 數據行包含數據列最有可能預測的類別。
ClassificationExplanation 數據行包含說明,其中包含輸入特徵在 ClassificationScore 上具有的特定影響。
回歸模型
回歸模型可用來預測數值,並可用於判斷下列案例:
- 從銷售交易中可能實現的收入。
- 帳戶的存留期值。
- 可能支付的應收發票金額
- 發票的付款日期等等。
回歸模型的輸出是預測值。
定型回歸模型
包含回歸模型定型數據的輸入數據表必須具有數值數據行做為結果數據行,以識別已知的結果值。
必要條件:
- 回歸模型至少需要100個數據列的歷史數據。
回歸模型的建立程式會遵循與其他 AutoML 模型相同的步驟,如上一節 <設定 ML 模型輸入>中所述。
回歸模型報告
與其他 AutoML 模型報告一樣,回歸報告是以將模型套用至鑒效組測試數據的結果為基礎。
模型報表包含圖表,可比較預測值與實際值。 在此圖表中,對角線的距離表示預測中的錯誤。
殘差誤差圖會顯示保留測試語意模型中不同值的平均誤差百分比分布。 水平軸代表群組實際值的平均值。 泡泡的大小會顯示該範圍內值的頻率或計數。 垂直軸是平均剩餘誤差。
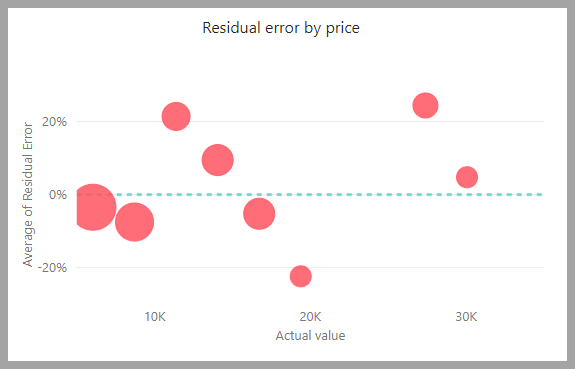
回歸模型報表也包含訓練詳細數據頁面,例如其他模型類型的報表,如上一節 AutoML 模型報表中所述。
套用回歸模型
若要套用回歸 ML 模型,您必須使用輸入資料和輸出數據行名稱前置詞來指定數據表。
![[套用價格預測] 對話框的螢幕快照。](media/service-machine-learning-automated/automated-machine-learning-power-bi-19.png)
套用回歸模型時,它會將三個輸出數據行新增至擴充的輸出數據表: RegressionResult、 RegressionExplanation 和 ExplanationIndex。 在套用模型時,數據表中的數據行名稱具有指定的前置詞。
RegressionResult 數據行包含根據輸入數據行的數據列預測值。 RegressionExplanation 數據行包含說明,其中包含輸入特徵在 RegressionResult 上具有的特定影響。
Power BI 中的 Azure 機器學習 整合
許多組織會使用機器學習模型,以取得其業務的相關深入解析和預測。 您可以使用機器學習搭配報表、儀錶板和其他分析來取得這些見解。 從這些模型可視化及叫用深入解析的能力,可協助將這些深入解析傳播給最需要它的商務使用者。 Power BI 現在可讓您使用簡單的點選手勢,將 Azure 機器學習 上裝載的模型深入解析納入其中。
若要使用這項功能,數據科學家可以使用 Azure 入口網站,將 Azure 機器學習 模型的存取權授與 BI 分析師。 然後,在每個會話開始時,Power Query 會探索用戶可存取的所有 Azure 機器學習 模型,並將其公開為動態 Power Query 函式。 然後,使用者可以從功能區存取 Power Query 編輯器 中的函式,或直接叫用 M 函式來叫用這些函式。 Power BI 也會在叫用一組數據列的 Azure 機器學習 模型時自動批處理存取要求,以達到更佳的效能。
此功能目前僅支援 Power BI 數據流,以及 Power BI 服務 中的 Power Query 在線。
若要深入了解數據流,請參閱 數據流和自助數據準備簡介。
若要深入瞭解 Azure 機器學習,請參閱:
- 概觀:什麼是 Azure 機器學習?
- Azure 機器學習 快速入門和教學課程:Azure 機器學習 檔
將 Azure 機器學習 模型的存取權授與 Power BI 使用者
若要從 Power BI 存取 Azure 機器學習 模型,用戶必須具有 Azure 訂用帳戶和 機器學習 工作區的讀取許可權。
本文中的步驟說明如何將裝載在 Azure 機器學習 服務上的模型存取權授與 Power BI 使用者,以 Power Query 函式的形式存取此模型。 如需詳細資訊,請參閱使用 Azure 入口網站指派 Azure 角色。
登入 Azure 入口網站。
移至 [訂用 帳戶] 頁面。 您可以在 Azure 入口網站 的瀏覽窗格選單中,透過 [所有服務] 清單找到 [訂用帳戶] 頁面。
選取您的訂用帳戶。
選取 [存取控制 [IAM],然後選擇 [新增] 按鈕。
選取 [讀取器 ] 作為 [角色]。 然後選擇您想要授與 Azure 機器學習 模型存取權的 Power BI 使用者。
![在 [新增許可權] 窗格上,將角色變更為讀者的螢幕快照。](media/service-machine-learning-integration/machine-learning-integration-04.png)
選取 [儲存]。
重複步驟 3 到 6,為裝載模型的特定機器學習工作區授 與讀者 存取權。



![在 [新增許可權] 窗格上,將角色變更為讀者的螢幕快照。](media/service-machine-learning-integration/machine-learning-integration-04.png#lightbox)
機器學習模型的架構探索
數據科學家主要使用 Python 來開發甚至部署其機器學習模型的機器學習模型。 數據科學家必須使用 Python 明確產生架構檔案。
此架構檔案必須包含在已部署的 Web 服務中,才能用於機器學習模型。 若要自動產生 Web 服務的架構,您必須在已部署模型的輸入/輸出專案文本中提供輸入/輸出的範例。 如需詳細資訊,請參閱 使用在線端點部署和評分機器學習模型。 連結包含範例專案腳本,以及架構產生語句。
具體而言,專案腳本中的@input_schema和@output_schema函式會參考input_sample和output_sample變數中的輸入和輸出範例格式。 函式會使用這些範例,在部署期間產生 Web 服務的 OpenAPI (Swagger) 規格。
更新專案腳本來產生架構的這些指示也必須套用至使用 Azure 機器學習 SDK 自動化機器學習實驗所建立的模型。
注意
使用 Azure 機器學習 可視化介面所建立的模型目前不支援產生架構,但在後續版本中會支援。
在 Power BI 中叫用 Azure 機器學習 模型
您可以直接從數據流中的 Power Query 編輯器,叫用您已獲授與存取權的任何 Azure 機器學習 模型。 若要存取 Azure 機器學習 模型,請選取您要從 Azure 機器學習 模型擴充見解之數據表的 [編輯數據表] 按鈕,如下圖所示。
![針對數據流實體反白顯示的 [編輯數據表] 圖示螢幕快照。](media/service-machine-learning-integration/machine-learning-integration-05.png#lightbox)
選取 [編輯數據表] 按鈕會開啟資料流中數據表的 Power Query 編輯器。
![Power Query 的螢幕快照,其中醒目提示 [AI 深入解析] 按鈕。](media/service-machine-learning-integration/machine-learning-integration-06.png#lightbox)
選取功能區中的 [AI 見解] 按鈕,然後從導覽窗格功能表中選取 [Azure 機器學習 Models] 資料夾。 您有權存取的所有 Azure 機器學習 模型都會列在這裡作為 Power Query 函式。 此外,Azure 機器學習 模型的輸入參數會自動對應為對應 Power Query 函式的參數。
若要叫用 Azure 機器學習 模型,您可以將任何選取資料表的數據行指定為下拉式清單的輸入。 您也可以將資料行圖示切換至輸入對話框左邊,以指定要當做輸入的常數值。
![[叫用函式] 對話框上數據行選取選項的螢幕快照。](media/service-machine-learning-integration/machine-learning-integration-07.png#lightbox)
選取 [叫用] 以檢視 Azure 機器學習 模型輸出的預覽,作為數據表中的新數據行。 模型調用會顯示為查詢的套用步驟。

如果模型傳回多個輸出參數,它們會分組為輸出數據行中的數據列。 您可以展開數據行,以在不同的數據行中產生個別的輸出參數。

儲存數據流之後,數據表中任何新的或更新的數據列都會在重新整理數據流時自動叫用模型。
考量與限制
- 數據流 Gen2 目前未與自動化機器學習整合。
- 具有 Proxy 驗證設定的機器不支援 AI 深入解析(認知服務和 Azure 機器學習 模型)。
- 來賓使用者不支援 Azure 機器學習 模型。
- 搭配 AutoML 和認知服務使用閘道有一些已知問題。 如果您需要使用閘道,建議您先建立資料流,以透過閘道匯入必要的數據。 然後建立另一個數據流,參考第一個數據流來建立或套用這些模型和 AI 函式。
- 如果您的 AI 使用資料流失敗,您可能需要在搭配資料流使用 AI 時啟用快速合併。 匯入數據表之後,開始新增 AI 功能之前,請從 [常用] 功能區選取 [選項],然後在出現的視窗中選取 [允許合併多個來源的數據] 旁的複選框來啟用此功能,然後選取 [確定] 以儲存您的選取專案。 然後,您可以將 AI 功能新增至數據流。
相關內容
本文提供 Power BI 服務 中數據流的自動化 機器學習 概觀。 下列文章可能也很實用。
下列文章提供數據流和 Power BI 的詳細資訊:
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應