Aspekty datové platformy pro klíčové úlohy v Azure
Výběr efektivní aplikační datové platformy je další zásadní oblastí rozhodování, která má dalekosáhlé důsledky v jiných oblastech návrhu. Azure nakonec nabízí celou řadu relačních, nerelačních a analytických datových platforem, které se výrazně liší schopnostmi. Proto je nezbytné, aby klíčové požadavky, které nejsou funkční, byly plně zvažované společně s dalšími rozhodovacími faktory, jako je konzistence, funkčnost, náklady a složitost. Například schopnost pracovat v konfiguraci zápisu do více oblastí bude mít zásadní vliv na vhodnost pro globálně dostupnou platformu.
Tato oblast návrhu rozšiřuje návrh aplikací a poskytuje klíčové aspekty a doporučení pro výběr optimální datové platformy.
Důležité
Tento článek je součástí série důležitých úloh Azure Well-Architected . Pokud tuto řadu neznáte, doporučujeme začít s tím , co je kriticky důležitá úloha?
Čtyři vs. velké objemy dat
Čtyři s velkými objemy dat poskytují rámec pro lepší pochopení požadovaných charakteristik pro vysoce dostupnou datovou platformu a způsobu, jakým je možné data použít k maximalizaci obchodní hodnoty. V této části se proto podíváme na to, jak lze na koncepční úrovni použít charakteristiky objemu, rychlosti, rozmanitosti a přesnosti, aby se pomohlo navrhnout datovou platformu s využitím vhodných datových technologií.
- Volume: kolik dat přichází, abychom informovali o požadavcích na kapacitu úložiště a vrstvení – to je velikost datové sady.
- Velocity: rychlost, s jakou se data zpracovávají, buď jako dávky, nebo jako průběžné proudy – to je rychlost toku.
- Variety: uspořádání a formát dat, zachytávání strukturovaných, částečně strukturovaných a nestrukturovaných formátů – to jsou data napříč několika úložišti nebo typy.
- Veracity: zahrnuje původ a kurátorování zvažovaných datových sad pro zásady správného řízení a kontrolu kvality dat – to znamená přesnost dat.
Aspekty návrhu
Svazek
Stávající (pokud nějaké) a očekávané budoucí objemy dat založené na předpokládané míře růstu dat odpovídají obchodním cílům a plánům.
- Objem dat by měl zahrnovat samotná data a indexy, protokoly, telemetrii a další použitelné datové sady.
- Velké podnikové a klíčové aplikace obvykle každý den generují a ukládají velké objemy (GB a TB).
- Rozšíření dat může mít významný dopad na náklady.
Objem dat může kolísat kvůli měnícím se obchodním okolnostem nebo postupům úklidu.
Objem dat může mít výrazný dopad na výkon dotazů na datovou platformu.
Dosažení limitů objemu datových platforem může mít zásadní dopad.
- Bude to mít za následek výpadek? a pokud ano, na jak dlouho?
- Jaké jsou postupy pro zmírnění rizik? a bude omezení rizik vyžadovat změny aplikace?
- Bude hrozit ztráta dat?
Funkce, jako je hodnota TTL (Time to Live), se dají použít ke správě růstu dat tím, že po uplynutí doby automaticky odstraní záznamy, a to buď vytvořením, nebo úpravou záznamů.
- Například Azure Cosmos DB poskytuje integrovanou funkci TTL .
Rychlost
Rychlost, s jakou se data generují z různých komponent aplikace, a požadavky na propustnost pro rychlost potvrzení a načítání dat jsou zásadní pro určení optimální datové technologie pro klíčové scénáře úloh.
- Povaha požadavků na propustnost se bude lišit podle scénářů úloh, například těch, které jsou náročné na čtení nebo zápis.
- Analytické úlohy například obvykle potřebují zajistit velkou propustnost čtení.
- Jaká je požadovaná propustnost? A jak se očekává růst propustnosti?
- Jaké jsou požadavky na latenci dat u P50/P99 při referenčních úrovních zatížení?
- Povaha požadavků na propustnost se bude lišit podle scénářů úloh, například těch, které jsou náročné na čtení nebo zápis.
Možnosti, jako je podpora návrhu bez uzamčení, ladění indexů a zásad konzistence, jsou pro dosažení vysoké propustnosti klíčové.
- Optimalizace konfigurace pro vysokou propustnost má za následek kompromisy, které by měly být plně pochopitelné.
- K další optimalizaci propustnosti je možné využít vzorce trvalosti vyrovnávání zatížení a zasílání zpráv, jako jsou CQRS a Event Sourcing.
Úrovně zatížení budou v mnoha aplikačních scénářích přirozeně kolísat, přičemž přirozené špičky vyžadují dostatečný stupeň pružnosti, aby zvládly proměnlivou poptávku při zachování propustnosti a latence.
- Agilní škálovatelnost je klíčem k efektivní podpoře proměnlivé propustnosti a úrovně zatížení bez nadměrného zřizování úrovní kapacity.
- Propustnost čtení i zápisu se musí škálovat podle požadavků aplikace a zatížení.
- Při reakci na měnící se úrovně zatížení je možné použít vertikální i horizontální operace škálování.
- Agilní škálovatelnost je klíčem k efektivní podpoře proměnlivé propustnosti a úrovně zatížení bez nadměrného zřizování úrovní kapacity.
Dopad propadů propustnosti se může lišit v závislosti na scénáři úlohy.
- Dojde k přerušení připojení?
- Vrátí jednotlivé operace kódy selhání, zatímco řídicí rovina bude dál fungovat?
- Aktivuje datová platforma omezování, a pokud ano, jak dlouho?
Základní doporučení návrhu aplikací pro použití geografické distribuce typu aktivní-aktivní přináší problémy související s konzistencí dat.
- Existuje kompromis mezi konzistencí a výkonem s ohledem na úplnou transakční sémantiku ACID a tradiční chování uzamykání.
- Minimalizace latence zápisu bude za cenu konzistence dat.
- Existuje kompromis mezi konzistencí a výkonem s ohledem na úplnou transakční sémantiku ACID a tradiční chování uzamykání.
V konfiguraci zápisu do více oblastí bude potřeba synchronizovat a sloučit změny mezi všemi replikami s řešením konfliktů tam, kde je to potřeba, což může mít vliv na úrovně výkonu a škálovatelnost.
Repliky jen pro čtení (v rámci oblasti a mezi oblastmi) je možné použít k minimalizaci latence odezvy a distribuci provozu za účelem zvýšení výkonu, propustnosti, dostupnosti a škálovatelnosti.
Vrstvu ukládání do mezipaměti je možné použít ke zvýšení propustnosti čtení, aby se zlepšilo uživatelské prostředí a doba odezvy klienta.
- Aby se optimalizovala nedávnost dat, je potřeba vzít v úvahu časy vypršení platnosti mezipaměti a zásady.
Různých
Datový model, datové typy, datové relace a zamýšlený dotazovací model budou mít zásadní vliv na rozhodování datové platformy.
- Vyžaduje aplikace relační datový model, nebo může podporovat schéma proměnných nebo nerelační datový model?
- Jak se bude aplikace dotazovat na data? A budou dotazy záviset na konceptech databázové vrstvy, jako jsou relační spojení? Nebo aplikace takovou sémantiku poskytuje?
Povaha datových sad, které aplikace zvažuje, se může lišit, od nestrukturovaného obsahu, jako jsou obrázky a videa, až po více strukturovaných souborů, jako jsou CSV a Parquet.
- Složené úlohy aplikací mají obvykle odlišné datové sady a související požadavky.
Kromě relačních nebo nerelačních datových platforem mohou být pro určité úlohy dat vhodné také platformy pro grafy nebo datové platformy klíč-hodnota.
- Některé technologie se zaměřují na datové modely s proměnlivým schématem, kde jsou datové položky sémanticky podobné a/nebo se společně ukládají a dotazují, ale strukturálně se liší.
V architektuře mikroslužeb je možné jednotlivé aplikační služby sestavit s odlišnými úložišti dat optimalizovanými pro scénáře, a ne záviset na jediném monolitickém úložišti dat.
- Vzory návrhu, jako je SAGA , je možné použít ke správě konzistence a závislostí mezi různými úložišti dat.
- Přímé dotazy mezi databázemi můžou mít omezení ve společném umístění.
- Použití více datových technologií zvýší určitou režii při správě, aby se zachovaly související technologie.
- Vzory návrhu, jako je SAGA , je možné použít ke správě konzistence a závislostí mezi různými úložišti dat.
Sady funkcí pro každou službu Azure se v různých jazycích, sadách SDK a rozhraních API liší, což může výrazně ovlivnit úroveň ladění konfigurace, kterou je možné použít.
Možnosti optimalizovaného sladění s datovým modelem a zahrnujícími datovými typy budou mít zásadní vliv na rozhodování datových platforem.
- Vrstvy dotazů, jako jsou uložené procedury a objektově-relační mapovače.
- Jazykově neutrální dotazování, jako je zabezpečená vrstva rozhraní REST API.
- Možnosti provozní kontinuity, jako je zálohování a obnovení.
Analytická úložiště dat obvykle podporují polyglotní úložiště pro různé typy datových struktur.
- Prostředí analytického modulu runtime, jako je Apache Spark, můžou mít omezení integrace pro analýzu polyglotových datových struktur.
V podnikovém kontextu může mít využití stávajících procesů a nástrojů a kontinuita dovedností významný vliv na návrh datové platformy a výběr datových technologií.
Pravdivost
K ověření přesnosti dat v rámci aplikace je potřeba vzít v úvahu několik faktorů a správa těchto faktorů může mít významný vliv na návrh datové platformy.
- Konzistence dat.
- Funkce zabezpečení platformy.
- Zásady správného řízení dat.
- Správa změn a vývoj schémat.
- Závislosti mezi datovými sadami.
V každé distribuované aplikaci s více replikami dat existuje kompromis mezi konzistencí a latencí, jak je vyjádřeno v teorémech CAP a PACELC .
- Pokud jsou čtenáři a zapisovače distribuované zřetelně, musí se aplikace rozhodnout vrátit buď nejrychlejší dostupnou verzi datové položky, i když je zastaralá v porovnání s právě dokončeným zápisem (aktualizací) této datové položky v jiné replice, nebo nejaktuálnější verzi datové položky, což může způsobovat další latenci při určování a získání nejnovějšího stavu.
- Konzistenci a dostupnost je možné nakonfigurovat na úrovni platformy nebo na úrovni jednotlivých požadavků na data.
- Jaké je uživatelské prostředí, pokud se data měla obsluhovat z repliky, která je uživateli nejblíže, což neodráží nejnovější stav jiné repliky? tj. může aplikace podporovat poskytování zastaralých dat?
Pokud se v kontextu zápisu do více oblastí změní stejná datová položka ve dvou samostatných replikách pro zápis před replikací některé z těchto změn, vytvoří se konflikt, který se musí vyřešit.
- Je možné použít standardizované zásady řešení konfliktů, jako je například poslední zápis, nebo vlastní strategie s vlastní logikou.
Implementace požadavků na zabezpečení může nepříznivě ovlivnit propustnost nebo výkon.
Šifrování neaktivních uložených dat je možné implementovat v aplikační vrstvě pomocí šifrování na straně klienta nebo datové vrstvy pomocí šifrování na straně serveru.
Azure podporuje různé modely šifrování, včetně šifrování na straně serveru, které používá klíče spravované službou, klíče spravované zákazníkem v Key Vault nebo klíče spravované zákazníkem na hardwaru řízeném zákazníkem.
- Při šifrování na straně klienta je možné klíče spravovat v Key Vault nebo jiném zabezpečeném umístění.
Šifrování datového propojení MACsec (IEEE 802.1AE MAC) se používá k zabezpečení veškerého provozu mezi datovými centry Azure v páteřní síti Microsoftu.
- Pakety se na zařízeních před odesláním zašifrují a dešifrují, aby se zabránilo fyzickým útokům man-in-the-middle nebo slídání/odposlechu.
Ověřování a autorizace roviny dat a řídicí roviny.
- Jak bude datová platforma ověřovat a autorizovat přístup k aplikacím a provozní přístup?
Pozorovatelnost prostřednictvím monitorování stavu platformy a přístupu k datům.
- Jak se budou upozorňování uplatňovat u podmínek mimo přijatelné provozní hranice?
Doporučení k návrhu
Svazek
Zajistěte, aby budoucí objemy dat spojené s organickým růstem nepřekračovaly možnosti datové platformy.
- Odhad míry růstu dat v souladu s obchodními plány a využití stanovených sazeb k informování o průběžných požadavcích na kapacitu
- Porovnejte agregované svazky záznamů a svazky záznamů pro jednotlivá data s omezeními datové platformy.
- Pokud existuje riziko dosažení limitů za výjimečných okolností, zajistěte, aby se zabránilo výpadkům a ztrátě dat.
Monitorujte objem dat a ověřte ho podle modelu kapacity s ohledem na limity škálování a očekávanou míru růstu dat.
- Zajistěte, aby operace škálování odpovídaly požadavkům na úložiště, výkon a konzistenci.
- Při zavedení nové jednotky škálování může být potřeba replikovat podkladová data, což bude nějakou dobu trvat a při replikaci pravděpodobně dojde k penalizaci výkonu. Pokud je to možné, ujistěte se, že se tyto operace provádějí mimo kritickou pracovní dobu.
Definujte datové vrstvy aplikace pro klasifikaci datových sad na základě využití a důležitosti, abyste usnadnili odebrání nebo snižování zátěže starších dat.
- Zvažte klasifikaci datových sad na horkou, teplou a studenou (archiv).
- Základní referenční implementace například používají Azure Cosmos DB k ukládání "horkých" dat, která aplikace aktivně používá, zatímco Azure Storage se používá pro "studená" provozní data pro analytické účely.
- Zvažte klasifikaci datových sad na horkou, teplou a studenou (archiv).
Konfigurujte postupy správy pro optimalizaci růstu dat a zvýšení efektivity dat, jako je výkon dotazů a správa rozšiřování dat.
- Nakonfigurujte vypršení platnosti hodnoty TTL (Time-to-Live) pro data, která už nejsou vyžadována a nemají žádnou dlouhodobou analytickou hodnotu.
- Ověřte, že je možné stará data bezpečně vrstvit do sekundárního úložiště nebo přímo odstranit, aniž by to mělo nepříznivý dopad na aplikaci.
- Přesměrování nekritičtějších dat do sekundárního studeného úložiště, ale zachování jejich analytické hodnoty a splnění požadavků auditu
- Shromážděte telemetrii a statistiky využití datové platformy, aby týmy DevOps mohly neustále vyhodnocovat požadavky na údržbu a úložiště dat správné velikosti.
- Nakonfigurujte vypršení platnosti hodnoty TTL (Time-to-Live) pro data, která už nejsou vyžadována a nemají žádnou dlouhodobou analytickou hodnotu.
V souladu s návrhem aplikace mikroslužeb zvažte paralelní použití několika různých datových technologií s optimalizovanými datovými řešeními pro konkrétní scénáře úloh a požadavky na objemy.
- Vyhněte se vytváření jednoho monolitického úložiště dat, ve kterém může být obtížné spravovat objem dat z rozšíření.
Rychlost
Datová platforma musí být ze své podstaty navržená a nakonfigurovaná tak, aby podporovala vysokou propustnost, přičemž úlohy jsou rozdělené do různých kontextů, aby se maximalizoval výkon s využitím datových řešení optimalizovaných pro scénáře.
- Ujistěte se, že propustnost čtení a zápisu pro každý datový scénář může být škálovat podle očekávaných vzorů zatížení s dostatečnou odolností pro neočekávanou odchylku.
- Rozdělte různé datové úlohy, jako jsou transakční a analytické operace, do různých kontextů výkonu.
Úroveň zatížení pomocí asynchronního neblokujícího zasílání zpráv, například pomocí vzorů CQRS nebo Event Sourcing .
- Mezi žádostmi o zápis a zpřístupněním nových dat ke čtení může docházet k latenci, což může mít vliv na uživatelské prostředí.
- Tento dopad musí být srozumitelný a přijatelný v kontextu klíčových obchodních požadavků.
- Mezi žádostmi o zápis a zpřístupněním nových dat ke čtení může docházet k latenci, což může mít vliv na uživatelské prostředí.
Zajistěte agilní škálovatelnost pro podporu proměnlivé propustnosti a úrovně zatížení.
- Pokud jsou úrovně zatížení vysoce nestálé, zvažte nadměrné zřízení úrovní kapacity, abyste zajistili zachování propustnosti a výkonu.
- Otestujte a ověřte dopad na úlohy složené aplikace, když nejde zachovat propustnost.
Upřednostněte nativní datové služby Azure pomocí automatizovaných operací škálování, abyste usnadnili rychlou reakci na nestálost na úrovni zatížení.
- Nakonfigurujte automatické škálování na základě interních prahových hodnot služby a nastavených aplikací.
- Škálování by mělo být inicializovat a dokončeno v časových rámcích, které jsou konzistentní s obchodními požadavky.
- Ve scénářích, ve kterých je nutná ruční interakce, vytvořte automatizované provozní playbooky, které je možné aktivovat místo provádění ručních provozních akcí.
- Zvažte, jestli je možné automatizované aktivační události použít v rámci následných investic do technického inženýrství.
Monitorujte propustnost čtení a zápisu dat aplikace podle požadavků na latenci P50/P99 a zarovnejte se s modelem kapacity aplikace.
Nadměrná propustnost by měla být řádně zpracována datovou platformou nebo aplikační vrstvou a zachycena modelem stavu pro provozní reprezentaci.
Implementujte ukládání do mezipaměti pro scénáře "horkých" dat, abyste minimalizovali dobu odezvy.
- Použijte vhodné zásady pro vypršení platnosti mezipaměti a správu domu, abyste se vyhnuli nárůstu nehotových dat.
- Vypršení platnosti položek mezipaměti při změně záložních dat
- Pokud je vypršení platnosti mezipaměti výhradně založené na hodnotě TTL (Time-To-Live), je potřeba porozumět dopadu a zkušenostem zákazníků při poskytování zastaralých dat.
- Použijte vhodné zásady pro vypršení platnosti mezipaměti a správu domu, abyste se vyhnuli nárůstu nehotových dat.
Různých
V souladu s principem návrhu nativního pro cloud a Azure se důrazně doporučuje stanovit prioritu spravovaných služeb Azure, abyste snížili složitost provozu a správy a využili budoucí investice Microsoftu do platformy.
V souladu s principem návrhu aplikací volně propojených architektur mikroslužeb umožňují jednotlivým službám používat odlišná úložiště dat a technologie dat optimalizované pro scénáře.
- Identifikujte typy datové struktury, které bude aplikace zpracovávat pro konkrétní scénáře úloh.
- Vyhněte se vytváření závislosti na jednom monolitickém úložišti dat.
- Představte si vzor návrhu SAGA , kde existují závislosti mezi úložišti dat.
Ověřte, že jsou pro vybrané datové technologie k dispozici požadované funkce.
- Zajistěte podporu požadovaných jazyků a funkcí sady SDK. Ne všechny funkce jsou dostupné pro každý jazyk nebo sadu SDK stejným způsobem.
Pravdivost
Osvojte návrh datové platformy ve více oblastech a distribuujte repliky napříč oblastmi pro zajištění maximální spolehlivosti, dostupnosti a výkonu tím, že přesunete data blíže ke koncovým bodům aplikace.
- Distribuujte repliky dat mezi Zóny dostupnosti (AZ) v rámci oblasti (nebo použijte zónově redundantní úrovně služby) k maximalizaci dostupnosti v rámci oblasti.
Tam, kde to požadavky na konzistenci umožňují, použijte návrh datové platformy pro zápis do více oblastí, abyste maximalizovali celkovou globální dostupnost a spolehlivost.
- Zvažte obchodní požadavky pro řešení konfliktů, pokud se stejná položka dat změní ve dvou samostatných replikách zápisu předtím, než je možné replikovat některou z těchto změn, a tím vytvořit konflikt.
- Pokud je to možné, použijte standardizované zásady řešení konfliktů, jako je "Poslední vyhrává".
- Pokud se vyžaduje vlastní strategie s vlastní logikou, ujistěte se, že se při správě vlastní logiky používají postupy CI/CD DevOps.
- Pokud je to možné, použijte standardizované zásady řešení konfliktů, jako je "Poslední vyhrává".
- Zvažte obchodní požadavky pro řešení konfliktů, pokud se stejná položka dat změní ve dvou samostatných replikách zápisu předtím, než je možné replikovat některou z těchto změn, a tím vytvořit konflikt.
Otestujte a ověřte možnosti zálohování a obnovení a operace převzetí služeb při selhání prostřednictvím testování chaosu v rámci procesů průběžného doručování.
Spusťte srovnávací testy výkonu, abyste zajistili, že požadavky na propustnost a výkon nebudou ovlivněné zahrnutím požadovaných funkcí zabezpečení, jako je šifrování.
- Ujistěte se, že procesy průběžného doručování zvažují zátěžové testování proti známým srovnávacím testům výkonu.
Při použití šifrování se důrazně doporučuje používat šifrovací klíče spravované službou jako způsob, jak snížit složitost správy.
- Pokud existují specifické požadavky na zabezpečení klíčů spravovaných zákazníkem, ujistěte se, že jsou použity odpovídající postupy správy klíčů, které zajistí dostupnost, zálohování a obměně všech uvažovaných klíčů.
Poznámka
Při integraci s širší implementací organizace je důležité, aby se při zřizování a provozu komponent datové platformy v návrhu aplikace použil přístup zaměřený na aplikace.
Přesněji řečeno, pro maximalizaci spolehlivosti je důležité, aby jednotlivé komponenty datové platformy odpovídajícím způsobem reagovaly na stav aplikace prostřednictvím provozních akcí, které můžou zahrnovat další komponenty aplikace. Například ve scénáři, kdy jsou potřeba další prostředky datové platformy, bude pravděpodobně nutné škálovat datovou platformu spolu s dalšími komponentami aplikace podle modelu kapacity, případně prostřednictvím zřízení dalších jednotek škálování. Tento přístup bude nakonec omezen, pokud existuje pevná závislost centralizovaného provozního týmu, který bude řešit problémy související s datovou platformou izolovaně.
V konečném důsledku používání centralizovaných datových služeb (tj. centrálního IT DBaaS) dochází k provozním kritickým bodům, které výrazně brání flexibilitě prostřednictvím do značné míry nekontextualizovaného prostředí správy, a je třeba se jim vyhnout v klíčovém nebo důležitém obchodním kontextu.
Další odkazy
Další doprovodné materiály k datové platformě najdete v průvodci architekturou Aplikace Azure.
- Rozhodovací strom úložiště dat Azure
- Kritéria pro výběr úložiště dat
- Nerelační úložiště dat
- Relační úložiště dat OLTP
Globálně distribuované úložiště dat zápisu do více oblastí
Aby bylo možné plně vyhovět globálně distribuovaným aspiracím typu aktivní-aktivní návrh aplikace, důrazně doporučujeme zvážit distribuovanou datovou platformu pro zápis do více oblastí, kde se změny oddělených zapisovatelných replik synchronizují a slučují mezi všemi replikami s řešením konfliktů tam, kde je to potřeba.
Důležité
Mikroslužby nemusí všechny vyžadovat distribuované úložiště dat pro zápis do více oblastí, proto byste měli zvážit kontext architektury a obchodní požadavky jednotlivých scénářů úloh.
Azure Cosmos DB poskytuje globálně distribuované a vysoce dostupné úložiště dat NoSQL, které nabízí zápisy do více oblastí a přizpůsobitelnou konzistenci. Aspekty návrhu a doporučení v této části se proto zaměří na optimální využití služby Azure Cosmos DB.
Na co dát pozor při navrhování
Azure Cosmos DB
Azure Cosmos DB ukládá data v kontejnerech, což jsou indexovaná řádková transakční úložiště, která umožňují rychlé transakční čtení a zápisy s dobou odezvy v řádu milisekund.
Azure Cosmos DB podporuje několik různých rozhraní API s různými sadami funkcí, jako jsou SQL, Cassandra a MongoDB.
- Azure Cosmos DB for NoSQL první strany poskytuje nejbohatší sadu funkcí a obvykle se jedná o rozhraní API, kde budou nové funkce k dispozici jako první.
Azure Cosmos DB podporuje režimy brány a přímého připojení, kde direct usnadňuje připojení přes TCP k back-endovým uzlům repliky služby Azure Cosmos DB pro zajištění lepšího výkonu s menším počtem síťových směrování, zatímco brána poskytuje připojení HTTPS k uzlům front-endové brány.
- Přímý režim je k dispozici pouze při použití služby Azure Cosmos DB for NoSQL a v současné době je podporovaný pouze na platformách .NET a Java SDK.
V rámci oblastí s povolenou zónou dostupnosti nabízí Azure Cosmos DB podporu redundance zóny dostupnosti pro zajištění vysoké dostupnosti a odolnosti proti selhání zón v rámci oblasti.
Azure Cosmos DB udržuje čtyři repliky dat v rámci jedné oblasti, a pokud je povolená redundance zóny dostupnosti (AZ), Azure Cosmos DB zajišťuje umístění replik dat mezi více zón, aby bylo možné je chránit před selháním zón.
- K dosažení kvora napříč replikami v rámci oblasti se používá protokol konsensu Paxos.
Účet služby Azure Cosmos DB je možné snadno nakonfigurovat tak, aby replikoval data do několika oblastí, aby se zmírnit riziko nedostupnosti jedné oblasti.
- Replikaci je možné nakonfigurovat pomocí zápisů do jedné oblasti nebo zápisů do více oblastí.
- Při zápisech do jedné oblasti se ke všem zápisům používá primární "centrální" oblast, a pokud se tato oblast centra stane nedostupnou, musí proběhnout operace převzetí služeb při selhání, která zvýší úroveň jiné oblasti jako zapisovatelné.
- Při zápisu do více oblastí můžou aplikace zapisovat do libovolné nakonfigurované oblasti nasazení, která bude replikovat změny mezi všemi ostatními oblastmi. Pokud je oblast nedostupná, zbývající oblasti se použijí k poskytování provozu zápisu.
- Replikaci je možné nakonfigurovat pomocí zápisů do jedné oblasti nebo zápisů do více oblastí.
V konfiguraci zápisu do více oblastí může dojít ke konfliktům aktualizací (vložení, nahrazení, odstranění), kdy zapisovač současně aktualizuje stejnou položku ve více oblastech.
Azure Cosmos DB poskytuje dvě zásady řešení konfliktů, které se dají použít k automatickému řešení konfliktů.
- Služba Wins posledního zápisu (LWW) používá protokol hodin synchronizace času pomocí vlastnosti časového razítka
_tsdefinované systémem jako cestu řešení konfliktů. V případě konfliktu se vítězem stane položka s nejvyšší hodnotou cesty řešení konfliktů a pokud má více položek stejnou číselnou hodnotu, systém vybere vítěze, aby se všechny oblasti mohly sloučit ke stejné verzi potvrzené položky.- Při odstranění konfliktů odstraněná verze vždy vyhrává nad konflikty vložení nebo nahrazení bez ohledu na hodnotu cesty řešení konfliktů.
- Výchozí zásadou řešení konfliktů je poslední zápis wins.
- Při použití služby Azure Cosmos DB for NoSQL je možné k řešení konfliktů použít vlastní číselnou vlastnost, například vlastní definici časového razítka.
- Vlastní zásady řešení umožňují sémantiku definovanou aplikací sladit konflikty pomocí registrované uložené procedury sloučení, která je automaticky vyvolána při zjištění konfliktů.
- Systém poskytuje přesně jednou záruku pro provedení procedury sloučení v rámci protokolu závazku.
- Vlastní zásady řešení konfliktů jsou k dispozici pouze ve službě Azure Cosmos DB for NoSQL a je možné je nastavit pouze při vytváření kontejneru.
- Služba Wins posledního zápisu (LWW) používá protokol hodin synchronizace času pomocí vlastnosti časového razítka
V konfiguraci zápisu do více oblastí existuje závislost na jedné "centrální" oblasti Služby Azure Cosmos DB, která provádí řešení všech konfliktů, přičemž k dosažení kvora napříč replikami v rámci oblasti centra se používá protokol paxos pro konsensus.
- Platforma poskytuje vyrovnávací paměť zpráv pro konflikty zápisu v rámci oblasti centra, aby se zajistila úroveň zatížení a redundance pro přechodné chyby.
- Vyrovnávací paměť je schopná ukládat aktualizace zápisu v hodnotě několika minut, které vyžadují konsensus.
- Platforma poskytuje vyrovnávací paměť zpráv pro konflikty zápisu v rámci oblasti centra, aby se zajistila úroveň zatížení a redundance pro přechodné chyby.
Strategickým směrem platformy Azure Cosmos DB je odebrání této závislosti na jedné oblasti pro řešení konfliktů v konfiguraci zápisu do více oblastí s využitím dvoufázového přístupu Paxos k dosažení kvora na globální úrovni a v rámci oblasti.
Primární oblast centra je určená první oblastí, ve které je služba Azure Cosmos DB nakonfigurovaná.
- Pořadí priorit se konfiguruje pro další oblasti satelitního nasazení pro účely převzetí služeb při selhání.
Datový model a dělení napříč logickými a fyzickými oddíly hraje důležitou roli při dosažení optimálního výkonu a dostupnosti.
Při nasazení s jednou oblastí zápisu je možné nakonfigurovat službu Azure Cosmos DB pro automatické převzetí služeb při selhání na základě definované priority převzetí služeb při selhání s ohledem na všechny repliky oblastí čtení.
Plánovaná doba obnovení poskytovaná platformou Azure Cosmos DB je přibližně 10 až 15 minut a zachycuje uplynulý čas k provedení regionálního převzetí služeb při selhání služby Azure Cosmos DB v případě, že oblast centra ovlivní katastrofická havárie.
- Tato plánovaná doba obnovení (RTO) je také relevantní v kontextu zápisu do více oblastí vzhledem k závislosti na jedné oblasti centra pro řešení konfliktů.
- Pokud se oblast centra stane nedostupnou, zápisy provedené do jiných oblastí po zaplnění vyrovnávací paměti zpráv selžou, protože k vyřešení konfliktů nebude možné dojít, dokud služba nepřebere služby při selhání a nenaváže se nová oblast centra.
- Tato plánovaná doba obnovení (RTO) je také relevantní v kontextu zápisu do více oblastí vzhledem k závislosti na jedné oblasti centra pro řešení konfliktů.
Strategickým směrem platformy Azure Cosmos DB je snížit plánovanou dobu obnovení (RTO) na přibližně 5 minut tím, že povolíte převzetí služeb při selhání na úrovni oddílů.
Cíle bodu obnovení (RPO) a plánovaná doba obnovení (RTO) se dají konfigurovat prostřednictvím úrovní konzistence s kompromisem mezi stálostí dat a propustností.
- Azure Cosmos DB poskytuje minimální plánovanou dobu obnovení (RTO) 0 pro uvolněnou úroveň konzistence s zápisy do více oblastí nebo cíl bodu obnovení (RPO) 0 pro zajištění silné konzistence s oblastí s jedním zápisem.
Azure Cosmos DB nabízí smlouvu SLA 99,999 % pro dostupnost čtení i zápisu pro databázové účty nakonfigurované s více oblastmi Azure jako zapisovatelnými.
- Smlouvu SLA představuje procento měsíční doby provozu, které se vypočítá jako 100 % – průměrná míra chyb.
- Průměrná míra chyb je definována jako součet chybovosti za každou hodinu ve fakturačním měsíci vydělený celkovým počtem hodin ve fakturačním měsíci, kde míra chyb je celkový počet neúspěšných žádostí dělený celkovým počtem žádostí v daném hodinovém intervalu.
Azure Cosmos DB nabízí 99,99% smlouvu SLA na propustnost, konzistenci, dostupnost a latenci pro databázové účty s oborem na jednu oblast Azure, pokud jsou nakonfigurované s některou z pěti úrovní konzistence.
- Smlouva SLA 99,99 % se vztahuje také na databázové účty v několika oblastech Azure s nakonfigurovanou některou ze čtyř uvolněných úrovní konzistence.
Ve službě Azure Cosmos DB je možné zřídit dva typy propustnosti– standardní a automatické škálování, které se měří pomocí jednotek žádostí za sekundu (RU/s).
- Standardní propustnost přiděluje prostředky potřebné k zaručení zadané hodnoty RU/s.
- Zřízená propustnost úrovně Standard se účtuje po hodinách.
- Automatické škálování definuje hodnotu maximální propustnosti a služba Azure Cosmos DB automaticky vertikálně navyšuje nebo snižuje kapacitu v závislosti na zatížení aplikace, a to mezi hodnotou maximální propustnosti a minimálně 10 % hodnoty maximální propustnosti.
- Automatické škálování se účtuje po hodinách za maximální spotřebovanou propustnost.
- Standardní propustnost přiděluje prostředky potřebné k zaručení zadané hodnoty RU/s.
Statická zřízená propustnost s proměnlivou úlohou může vést k chybám omezování, což ovlivní vnímanou dostupnost aplikace.
- Automatické škálování chrání před chybami omezování tím, že umožňuje vertikálně navýšit kapacitu služby Azure Cosmos DB podle potřeby a současně zachovat ochranu nákladů vertikálním snížením kapacity při snížení zatížení.
Při replikaci služby Azure Cosmos DB do více oblastí se zřízené jednotky žádostí (RU) účtují podle oblasti.
Mezi konfigurací zápisu do více oblastí a konfigurace zápisu do jedné oblasti existuje významný rozdíl nákladů, což v mnoha případech může znemožnit náklady na datovou platformu Azure Cosmos DB s více hlavními instancemi.
| Čtení/zápis v jedné oblasti | Zápis do jedné oblasti – čtení z duální oblasti | Čtení a zápis duální oblasti |
|---|---|---|
| 1 RU | 2 RU | 4 RU |
Rozdíl mezi zápisem do jedné oblasti a zápisem do více oblastí je ve skutečnosti menší než poměr 1:2 uvedený ve výše uvedené tabulce. Přesněji řečeno, s aktualizacemi zápisu v konfiguraci s jedním zápisem se účtují poplatky za přenos dat mezi oblastmi, které se nezachycují v rámci nákladů na RU jako u konfigurace zápisu do více oblastí.
Spotřebované úložiště se účtuje paušální sazbou za celkovou velikost úložiště (GB) spotřebovanou k hostování dat a indexů za danou hodinu.
Sessionje výchozí a nejpoužívanější úroveň konzistence , protože data se přijímají ve stejném pořadí jako zápisy.Azure Cosmos DB podporuje ověřování prostřednictvím identity Microsoft Entra nebo klíčů a tokenů prostředků služby Azure Cosmos DB, které poskytují překrývající se možnosti.
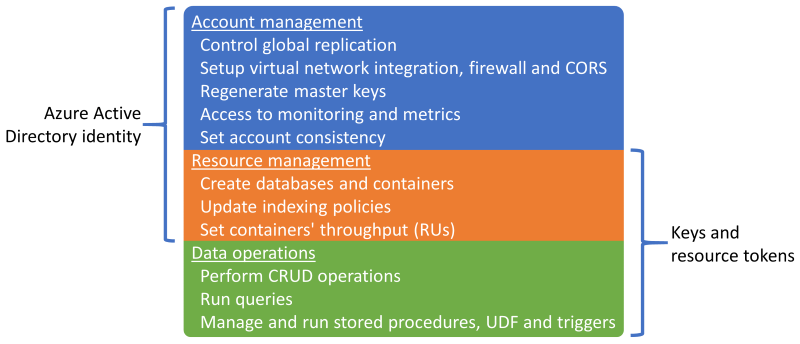
Operace správy prostředků je možné zakázat pomocí klíčů nebo tokenů prostředků a omezit tak klíče a tokeny prostředků pouze na operace s daty, což umožňuje podrobné řízení přístupu k prostředkům pomocí Microsoft Entra řízení přístupu na základě role (RBAC).
- Omezení přístupu k řídicí rovině prostřednictvím klíčů nebo tokenů prostředků zakáže operace řídicí roviny pro klienty, kteří používají sady SDK služby Azure Cosmos DB, a proto by se měly důkladně vyhodnotit a otestovat.
- Nastavení
disableKeyBasedMetadataWriteAccessje možné nakonfigurovat prostřednictvím definic šablon ARM IaC nebo integrovaného Azure Policy.
Microsoft Entra podpora RBAC ve službě Azure Cosmos DB se vztahuje na operace správy roviny řízení účtů a prostředků.
- Správci aplikací můžou uživatelům, skupinám, instančním objektům nebo spravovaným identitám přiřazovat role a udělovat nebo odepřít přístup k prostředkům a operacím s prostředky služby Azure Cosmos DB.
- Pro přiřazení rolí je k dispozici několik předdefinovaných rolí RBAC a vlastní role RBAC je možné použít také k vytvoření konkrétních kombinací oprávnění.
- Čtečka účtů služby Cosmos DB umožňuje přístup k prostředku služby Azure Cosmos DB jen pro čtení.
- Přispěvatel účtu DocumentDB umožňuje správu účtů služby Azure Cosmos DB, včetně klíčů a přiřazení rolí, ale neumožňuje přístup k rovině dat.
- Operátor služby Cosmos DB, který je podobný přispěvateli účtu DocumentDB, ale neposkytuje možnost spravovat klíče nebo přiřazení rolí.
Prostředky Azure Cosmos DB (účty, databáze a kontejnery) je možné chránit před nesprávnými úpravami nebo odstraněním pomocí zámků prostředků.
- Zámky prostředků je možné nastavit na úrovni účtu, databáze nebo kontejneru.
- Zámek prostředku nastavený na hodnotu u prostředku se zdědí všemi podřízenými prostředky. Například zámek prostředků nastavený pro účet služby Azure Cosmos DB zdědí všechny databáze a kontejnery v rámci účtu.
- Zámky prostředků se vztahují pouze na operace řídicí roviny a nebrání operacím roviny dat, jako je vytváření, změna nebo odstraňování dat.
- Pokud přístup k řídicí rovině není omezen pomocí
disableKeyBasedMetadataWriteAccessnástroje , klienti budou moct provádět operace řídicí roviny pomocí klíčů účtu.
Kanál změn azure Cosmos DB poskytuje kanál časově uspořádaných změn dat v kontejneru Azure Cosmos DB.
- Kanál změn zahrnuje pouze operace vložení a aktualizace zdrojového kontejneru Azure Cosmos DB. nezahrnuje odstranění.
Kanál změn se dá použít k udržování samostatného úložiště dat od primárního kontejneru používaného aplikací s průběžnými aktualizacemi cílového úložiště dat, které kanál změn předá ze zdrojového kontejneru.
- Kanál změn je možné použít k naplnění sekundárního úložiště pro další redundanci datové platformy nebo pro následné analytické scénáře.
Pokud operace odstranění pravidelně ovlivňují data ve zdrojovém kontejneru, pak bude úložiště předávané kanálem změn nepřesné a bude nereflektivum odstraněných dat.
- Model obnovitelného odstranění je možné implementovat tak, aby se datové záznamy zahrnuly do kanálu změn.
- Místo explicitního odstranění datových záznamů se datové záznamy aktualizují nastavením příznaku (např.
IsDeleted), který označuje, že se položka považuje za odstraněnou. - Všechna cílová úložiště dat, která jsou zásobována kanálem změn, bude muset detekovat a zpracovávat položky s příznakem odstranění nastaveným na Hodnotu True. místo ukládání obnovitelně odstraněných datových záznamů bude potřeba odstranit stávající verzi datového záznamu v cílovém úložišti.
- Místo explicitního odstranění datových záznamů se datové záznamy aktualizují nastavením příznaku (např.
- Krátká hodnota TTL (Time to Live) se obvykle používá se vzorem obnovitelného odstranění, aby služba Azure Cosmos DB automaticky odstranila data s vypršenou platností, ale až poté, co se projeví v kanálu změn s příznakem odstraněných dat nastaveným na Hodnotu True.
- Provede původní záměr odstranění a zároveň rozšíří odstranění prostřednictvím kanálu změn.
- Model obnovitelného odstranění je možné implementovat tak, aby se datové záznamy zahrnuly do kanálu změn.
Službu Azure Cosmos DB je možné nakonfigurovat jako analytické úložiště, které používá formát sloupce pro optimalizované analytické dotazy k řešení problémů se složitostí a latencí, ke kterým dochází u tradičních kanálů ETL.
Azure Cosmos DB automaticky zálohuje data v pravidelných intervalech, aniž by to mělo vliv na výkon nebo dostupnost a spotřebovávají RU/s.
Službu Azure Cosmos DB je možné nakonfigurovat podle dvou různých režimů zálohování.
- Pravidelné je výchozí režim zálohování pro všechny účty, kdy se zálohy vytvářejí v pravidelných intervalech a data se obnovují vytvořením žádosti s týmem podpory.
- Výchozí doba uchovávání pravidelných záloh je osm hodin a výchozí interval zálohování je čtyři hodiny, což znamená, že ve výchozím nastavení se ukládají jenom poslední dvě zálohy.
- Interval zálohování a doba uchovávání se v rámci účtu dají konfigurovat.
- Maximální doba uchovávání se prodlužuje na měsíc s minimálním intervalem zálohování jednu hodinu.
- Ke konfiguraci redundance úložiště zálohování se vyžaduje přiřazení role k roli Čtenář účtů služby Azure Cosmos DB.
- Dvě záložní kopie jsou zahrnuty bez dalších poplatků, ale za další zálohy se účtují další náklady.
- Ve výchozím nastavení se pravidelné zálohy ukládají do samostatného úložiště Geo-Redundant Storage (GRS), které není přímo přístupné.
- Úložiště zálohování existuje v primární oblasti centra a prostřednictvím replikace základního úložiště se replikuje do spárované oblasti.
- Konfigurace redundance základního účtu úložiště zálohování je konfigurovatelná na zónově redundantní úložiště nebo Locally-Redundant Storage.
- Provedení operace obnovení vyžaduje žádost o podporu , protože zákazníci nemůžou provést obnovení přímo.
- Před otevřením lístku podpory by se doba uchovávání záloh měla prodloužit alespoň na sedm dnů do osmi hodin od události ztráty dat.
- Operace obnovení vytvoří nový účet služby Azure Cosmos DB, ve kterém se obnoví data.
- K obnovení není možné použít existující účet služby Azure Cosmos DB.
- Ve výchozím nastavení se použije nový účet služby Azure Cosmos DB s názvem
<Azure_Cosmos_account_original_name>-restored<n>.- Tento název lze upravit, například opětovným použitím existujícího názvu, pokud byl původní účet odstraněn.
- Pokud se propustnost zřídí na úrovni databáze, zálohování a obnovení proběhne na úrovni databáze.
- Není možné vybrat podmnožinu kontejnerů k obnovení.
- Režim průběžného zálohování umožňuje obnovení k jakémukoli bodu v čase během posledních 30 dnů.
- Operace obnovení je možné provést tak, aby se vrátily k určitému bodu v čase (PITR) s intervalem jedné sekundy.
- Dostupné časové období pro operace obnovení je až 30 dnů.
- Je také možné provést obnovení do stavu vytvoření instance prostředku.
- Průběžné zálohování se provádí v rámci všech oblastí Azure, ve kterých existuje účet služby Azure Cosmos DB.
- Průběžné zálohování se ukládá ve stejné oblasti Azure jako každá replika služby Azure Cosmos DB pomocí služby Locally-Redundant Storage (LRS) nebo zónově redundantního úložiště (ZRS) v oblastech, které podporují Zóny dostupnosti.
- Samoobslužné obnovení je možné provést pomocí artefaktů Azure Portal nebo IaC, jako jsou šablony ARM.
- Průběžné zálohování má několik omezení .
- Režim průběžného zálohování není v současné době k dispozici v konfiguraci zápisu do více oblastí.
- Průběžné zálohování je v současnosti možné nakonfigurovat pouze ve službách Azure Cosmos DB for NoSQL a Azure Cosmos DB pro MongoDB.
- Pokud má kontejner nakonfigurovanou hodnotu TTL, obnovená data, která překročila hodnotu TTL, se můžou okamžitě odstranit.
- Operace obnovení vytvoří nový účet služby Azure Cosmos DB pro obnovení k určitému bodu v čase.
- Za průběžné zálohování a operace obnovení se nástaví další náklady na úložiště .
- Pravidelné je výchozí režim zálohování pro všechny účty, kdy se zálohy vytvářejí v pravidelných intervalech a data se obnovují vytvořením žádosti s týmem podpory.
Stávající účty Azure Cosmos DB je možné migrovat z periodického na průběžné, ale ne z průběžného na periodické. migrace je jednosměrná a nevratná.
Každá záloha Azure Cosmos DB se skládá ze samotných dat a podrobností konfigurace pro zřízenou propustnost, zásady indexování, oblasti nasazení a nastavení hodnoty TTL kontejneru.
- Zálohy neobsahují nastavení brány firewall, seznamy řízení přístupu k virtuální síti, nastavení privátních koncových bodů, nastavení konzistence (účet se obnovuje s konzistencí relací), uložené procedury, triggery, funkce definované uživatelem nebo nastavení ve více oblastech.
- Zákazníci zodpovídají za opětovné nasazení funkcí a nastavení konfigurace. Ty se neobnoví prostřednictvím zálohování služby Azure Cosmos DB.
- Azure Synapse Data analytického úložiště Link také nejsou zahrnutá do záloh Služby Azure Cosmos DB.
- Zálohy neobsahují nastavení brány firewall, seznamy řízení přístupu k virtuální síti, nastavení privátních koncových bodů, nastavení konzistence (účet se obnovuje s konzistencí relací), uložené procedury, triggery, funkce definované uživatelem nebo nastavení ve více oblastech.
Vlastní funkce zálohování a obnovení je možné implementovat ve scénářích, kdy pravidelné a průběžné přístupy nevyhovují.
- Vlastní přístup přináší značné náklady a další režii na správu, což je potřeba pochopit a pečlivě posoudit.
- Měly by se modelovat běžné scénáře obnovení, jako je poškození nebo odstranění účtu, databáze nebo kontejneru u položky dat.
- Aby se zabránilo nárůstu záloh, měly by se implementovat postupy úklidu.
- Je možné použít Azure Storage nebo alternativní datovou technologii, jako je alternativní kontejner Azure Cosmos DB.
- Azure Storage a Azure Cosmos DB poskytují nativní integrace se službami Azure, jako jsou Azure Functions a Azure Data Factory.
- Vlastní přístup přináší značné náklady a další režii na správu, což je potřeba pochopit a pečlivě posoudit.
Dokumentace ke službě Azure Cosmos DB označuje dvě potenciální možnosti implementace vlastních záloh.
- Kanál změn služby Azure Cosmos DB pro zápis dat do samostatného úložiště
- Funkce Azure nebo ekvivalentní aplikační proces používá procesor kanálu změn k vytvoření vazby na kanál změn a zpracování položek do úložiště.
- Pomocí kanálu změn je možné implementovat průběžné i pravidelné (dávkové) vlastní zálohy.
- Kanál změn azure Cosmos DB zatím neodráží odstranění, takže je potřeba použít vzor obnovitelného odstranění s použitím logické vlastnosti a hodnoty TTL.
- Tento model se nebude vyžadovat, pokud kanál změn poskytuje plně věrné aktualizace.
- Azure Data Factory konektor pro Azure Cosmos DB (konektory rozhraní Api Azure Cosmos DB pro NoSQL nebo MongoDB) pro kopírování dat.
- Azure Data Factory (ADF) podporuje ruční spouštění a aktivační události založené na plánu, přeskakující okno a triggery založené na událostech.
- Poskytuje podporu pro Storage i Event Grid.
- ADF je kvůli dávkové orchestraci primárně vhodná pro pravidelné implementace vlastních záloh.
- Kvůli režii provádění orchestrace je méně vhodná pro implementace průběžného zálohování s častými událostmi.
- ADF podporuje Azure Private Link ve scénářích s vysokým zabezpečením sítě.
- Azure Data Factory (ADF) podporuje ruční spouštění a aktivační události založené na plánu, přeskakující okno a triggery založené na událostech.
- Kanál změn služby Azure Cosmos DB pro zápis dat do samostatného úložiště
Azure Cosmos DB se používá v rámci návrhu mnoha služeb Azure, takže významný regionální výpadek služby Azure Cosmos DB bude mít kaskádový efekt napříč různými službami Azure v této oblasti. Přesný dopad na konkrétní službu bude do značné míry záviset na tom, jak návrh základní služby využívá Službu Azure Cosmos DB.
Doporučení k návrhu
Azure Cosmos DB
Azure Cosmos DB použijte jako primární datovou platformu tam, kde to požadavky umožňují.
Pro klíčové scénáře úloh nakonfigurujte službu Azure Cosmos DB s replikou pro zápis v každé oblasti nasazení, abyste snížili latenci a zajistili maximální redundanci.
- Nakonfigurujte aplikaci tak, aby upřednostňovala použití místní repliky služby Azure Cosmos DB pro zápisy a čtení za účelem optimalizace zatížení aplikace, výkonu a regionální spotřeby RU/s.
- Konfigurace zápisu do více oblastí má značné náklady a měla by mít prioritu pouze pro scénáře úloh vyžadujících maximální spolehlivost.
U méně důležitých scénářů úloh upřednostňujte použití konfigurace zápisu do jedné oblasti (při použití Zóny dostupnosti) s globálně distribuovanými replikami pro čtení, protože nabízí vysokou úroveň spolehlivosti datové platformy (99,999 % SLA pro čtení, 99,995 % SLA pro operace zápisu) za přesvědčivější cenu.
- Nakonfigurujte aplikaci tak, aby k optimalizaci výkonu čtení používala místní repliku pro čtení služby Azure Cosmos DB.
Vyberte optimální oblast nasazení centra, kde v konfiguraci zápisu do více oblastí dojde k řešení konfliktů, a všechny zápisy se budou provádět v konfiguraci zápisu do jedné oblasti.
- Zvažte vzdálenost vzhledem k ostatním oblastem nasazení a související latenci při výběru primární oblasti a požadované možnosti, jako je Zóny dostupnosti podpora.
Nakonfigurujte službu Azure Cosmos DB s redundancí zóny dostupnosti (AZ) ve všech oblastech nasazení s podporou zóny dostupnosti, abyste zajistili odolnost proti selhání zón v rámci oblasti.
Azure Cosmos DB for NoSQL můžete používat, protože nabízí nejkomplexnější sadu funkcí, zejména pokud jde o ladění výkonu.
- Alternativní rozhraní API by se měla zvažovat především pro scénáře migrace nebo kompatibility.
- Pokud používáte alternativní rozhraní API, ověřte, že jsou s vybraným jazykem a sadou SDK dostupné požadované funkce, abyste zajistili optimální konfiguraci a výkon.
- Alternativní rozhraní API by se měla zvažovat především pro scénáře migrace nebo kompatibility.
Režim přímého připojení použijte k optimalizaci výkonu sítě prostřednictvím přímého připojení TCP k back-endovým uzlům Azure Cosmos DB se sníženým počtem segmentů směrování v síti.
Smlouva SLA služby Azure Cosmos DB se počítá z průměru neúspěšných požadavků, který nemusí přímo odpovídat rozpočtu chyb na úrovni spolehlivosti 99,999 %. Při návrhu s 99,999% SLO je proto důležité naplánovat nedostupnost zápisu do služby Azure Cosmos DB v jednotlivých oblastech a ve více oblastech, a zajistit tak umístění technologie záložního úložiště v případě selhání, jako je trvalá fronta zpráv, pro následné přehrání.
Definujte strategii dělení napříč logickými i fyzickými oddíly pro optimalizaci distribuce dat podle datového modelu.
- Minimalizujte dotazy napříč oddíly.
- Iterativně otestujte a ověřte strategii dělení, abyste zajistili optimální výkon.
Vyberte optimální klíč oddílu.
- Klíč oddílu nelze po jeho vytvoření v kolekci změnit.
- Klíč oddílu by měl být hodnota vlastnosti, která se nemění.
- Vyberte klíč oddílu s vysokou kardinalitou a širokou škálou možných hodnot.
- Klíč oddílu by měl rovnoměrně rozdělit spotřebu RU a úložiště dat napříč všemi logickými oddíly, aby se zajistilo rovnoměrné využití RU a distribuce úložiště napříč fyzickými oddíly.
- Spusťte dotazy na čtení na dělený sloupec, abyste snížili spotřebu RU a latenci.
Indexování je také zásadní pro výkon, proto se ujistěte, že se vyloučení indexů používají ke snížení počtu RU/s a požadavků na úložiště.
- Indexovat pouze pole, která jsou potřebná pro filtrování v rámci dotazů; návrh indexů pro nejpoužívanější predikáty.
Využijte integrované zpracování chyb, opakování a širší možnosti spolehlivosti sady SDK služby Azure Cosmos DB.
- Implementujte logiku opakování v sadě SDK na klientech.
Použití šifrovacích klíčů spravovaných službou ke snížení složitosti správy
- Pokud pro klíče spravované zákazníkem existuje konkrétní požadavek na zabezpečení, ujistěte se, že se používají odpovídající postupy správy klíčů, jako je zálohování a obměně.
Zakažte přístup k zápisu metadat založený na klíčích služby Azure Cosmos DB použitím integrovaného Azure Policy.
Povolte Azure Monitoru shromažďovat klíčové metriky a diagnostické protokoly, jako je zřízená propustnost (RU/s).
- Směrujte provozní data služby Azure Monitor do pracovního prostoru služby Log Analytics vyhrazeného pro službu Azure Cosmos DB a dalších globálních prostředků v rámci návrhu aplikace.
- K určení, jestli jsou vzory provozu aplikací vhodné pro automatické škálování, použijte metriky Azure Monitoru.
Vyhodnoťte vzory provozu aplikací a vyberte optimální možnost pro typy zřízené propustnosti.
- Zvažte automatické škálování zřízené propustnosti za účelem automatického vyrovnání požadavků na úlohy.
Vyhodnoťte tipy microsoftu pro zvýšení výkonu pro službu Azure Cosmos DB , abyste optimalizovali konfiguraci na straně klienta a serveru za účelem zvýšení latence a propustnosti.
Pokud jako výpočetní platformu používáte AKS: U úloh náročných na dotazy vyberte skladovou položku uzlu AKS s povolenými akcelerovanými síťovými službami, aby se snížila latence a kolísání procesoru.
V případě nasazení s jednou oblastí zápisu důrazně doporučujeme nakonfigurovat službu Azure Cosmos DB pro automatické převzetí služeb při selhání.
Úroveň zatížení prostřednictvím použití asynchronního neblokujícího zasílání zpráv v rámci systémových toků, které zapisují aktualizace do služby Azure Cosmos DB.
- Zvažte vzory, jako je oddělení zodpovědnosti za příkazy a dotazy a model Event Sourcing.
Nakonfigurujte účet služby Azure Cosmos DB pro průběžné zálohování, abyste získali podrobné body obnovení za posledních 30 dnů.
- Zvažte použití záloh Služby Azure Cosmos DB ve scénářích, kdy jsou data obsažená nebo účet služby Azure Cosmos DB odstraněna nebo poškozena.
- Pokud to není nezbytně nutné, vyhněte se použití vlastního zálohování.
Důrazně doporučujeme vyzkoušet postupy obnovení u neprodukčních prostředků a dat v rámci standardní přípravy provozní kontinuity.
Definujte artefakty IaC pro opětovné vytvoření nastavení konfigurace a možností obnovení zálohy služby Azure Cosmos DB.
Vyhodnoťte a použijte pokyny k řízení standardních hodnot zabezpečení Azure pro zálohování a obnovení služby Azure Cosmos DB.
V případě analytických úloh vyžadujících dostupnost ve více oblastech použijte analytické úložiště Azure Cosmos DB, které používá formát sloupce pro optimalizované analytické dotazy.
Technologie relačních dat
Ve scénářích s vysoce relačním datovým modelem nebo závislostmi na existujících relačních technologiích nemusí být použití služby Azure Cosmos DB v konfiguraci zápisu do více oblastí přímo použitelné. V takových případech je nezbytné, aby použité relační technologie byly navrženy a nakonfigurovány tak, aby podporovaly aktivní-aktivní snahy o návrh aplikace ve více oblastech.
Azure poskytuje mnoho spravovaných relačních datových platforem, včetně Azure SQL Database a Azure Database pro běžná relační řešení OSS, včetně MySQL, PostgreSQL a MariaDB. Aspekty návrhu a doporučení v této části se proto zaměří na optimální využití variant operačních systémů Azure SQL Database a Azure Database, aby se maximalizovala spolehlivost a globální dostupnost.
Na co dát pozor při navrhování
Zatímco technologie relačních dat je možné nakonfigurovat tak, aby operace čtení snadno škálovaly, zápisy jsou obvykle omezené tak, aby procházely jednou primární instancí, což výrazně omezuje škálovatelnost a výkon.
Horizontální dělení je možné použít k distribuci dat a zpracování mezi více identických strukturovaných databází a horizontálnímu dělení databází za účelem navigace v omezeních platformy.
- Například horizontální dělení se často používá na platformách SaaS s více tenanty, aby se skupiny tenantů oddělily do odlišných konstruktorů datové platformy.
Azure SQL Database
Azure SQL Database poskytuje plně spravovaný databázový stroj, který vždy běží na nejnovější stabilní verzi SQL Server databázového stroje a základního operačního systému.
- Poskytuje inteligentní funkce, jako je ladění výkonu, monitorování hrozeb a posouzení ohrožení zabezpečení.
Azure SQL Database poskytuje integrovanou regionální vysokou dostupnost a geografickou replikaci na klíč pro distribuci replik pro čtení napříč oblastmi Azure.
- V případě geografické replikace zůstávají repliky sekundární databáze jen pro čtení, dokud se neiniciuje převzetí služeb při selhání.
- Ve stejných nebo různých oblastech se podporují až čtyři sekundární počítače.
- Sekundární repliky lze také použít pro přístup k dotazům jen pro čtení, aby se optimalizoval výkon čtení.
- Převzetí služeb při selhání se musí zahájit ručně, ale je možné ho zabalit do automatizovaných provozních postupů.
Azure SQL Database poskytuje skupiny automatického převzetí služeb při selhání, které replikují databáze na sekundární server a umožňují transparentní převzetí služeb při selhání v případě selhání.
- Skupiny automatického převzetí služeb při selhání podporují geografickou replikaci všech databází ve skupině pouze na jeden sekundární server nebo instanci v jiné oblasti.
- Skupiny automatického převzetí služeb při selhání se v současné době nepodporují na úrovni služby Hyperscale.
- Sekundární databáze je možné použít k přesměrování zatížení provozu čtení.
Repliky databáze úrovně služby Premium nebo Pro důležité obchodní informace je možné distribuovat mezi Zóny dostupnosti bez dalších poplatků.
- Řídicí okruh je také duplikován napříč několika zónami jako tři okruhy bran (GW).
- Směrování do konkrétního okruhu brány řídí Azure Traffic Manager.
- Při použití úrovně Pro důležité obchodní informace je zónově redundantní konfigurace dostupná jenom v případě, že je vybraný výpočetní hardware Gen5.
- Řídicí okruh je také duplikován napříč několika zónami jako tři okruhy bran (GW).
Azure SQL Database nabízí základní smlouvu SLA s 99,99% dostupností napříč všemi úrovněmi služby, ale poskytuje vyšší 99,995% smlouvu SLA pro úrovně Pro důležité obchodní informace nebo Premium v oblastech, které podporují zóny dostupnosti.
- úrovně Azure SQL Database Pro důležité obchodní informace nebo Premium, které nejsou nakonfigurované pro zónově redundantní nasazení, mají smlouvu SLA o dostupnosti 99,99 %.
Při konfiguraci s geografickou replikací poskytuje úroveň Pro důležité obchodní informace databáze Azure SQL plánovanou dobu obnovení (RTO) 30 sekund po dobu 100 % nasazených hodin.
Při konfiguraci s geografickou replikací má úroveň Pro důležité obchodní informace databáze Azure SQL cíl bodu obnovení (RPO) 5 sekund po dobu 100 % nasazených hodin.
Azure SQL úroveň Hyperškálování databáze, pokud je nakonfigurovaná s alespoň dvěma replikami, má smlouvu SLA dostupnosti 99,99 %.
Náklady na výpočetní prostředky spojené se službou Azure SQL Database je možné snížit pomocí slevy za rezervaci.
- Rezervovanou kapacitu není možné použít pro databáze založené na DTU.
Obnovení k určitému bodu v čase lze použít k vrácení databáze a obsažených dat do dřívějšího bodu v čase.
Geografické obnovení je možné použít k obnovení databáze z geograficky redundantní zálohy.
Azure Database For PostgreSQL
Azure Database for PostgreSQL se nabízí ve třech různých možnostech nasazení:
- Jeden server, SLA 99,99 %
- Flexibilní server, který nabízí redundanci zóny dostupnosti, SLA 99,99 %
- Hyperscale (Citus), SMLOUVA SLA 99,95 %, pokud je povolený režim vysoké dostupnosti.
Hyperscale (Citus) poskytuje dynamickou škálovatelnost prostřednictvím horizontálního dělení bez změn aplikací.
- Distribuce řádků tabulky na několik serverů PostgreSQL je klíčem k zajištění škálovatelných dotazů v Hyperscale (Citus).
- Více uzlů může společně uchovávat více dat než tradiční databáze a v mnoha případech může k optimalizaci nákladů použít pracovní procesory paralelně.
Automatické škálování je možné nakonfigurovat prostřednictvím automatizace runbooků, aby se zajistila elasticita v reakci na měnící se vzorce provozu.
Flexibilní server poskytuje nákladovou efektivitu pro neprodukční úlohy prostřednictvím možnosti zastavit/spustit server a nárazové výpočetní úrovně, která je vhodná pro úlohy, které nevyžadují nepřetržitou výpočetní kapacitu.
Za úložiště zálohování pro až 100 % celkového zřízeného úložiště serveru se neúčtují žádné další poplatky.
- Další spotřeba úložiště zálohování se účtuje podle spotřebovaných GB za měsíc.
Náklady na výpočetní prostředky spojené s Azure Database for PostgreSQL je možné snížit pomocí slevy za rezervaci jednoho serveru nebo slevy za rezervaci Hyperscale (Citus).
Doporučení k návrhu
Zvažte horizontální dělení relačních databází na základě různých kontextů aplikací a dat, které pomáhá procházet omezení platformy, maximalizovat škálovatelnost a dostupnost a izolaci chyb.
- Toto doporučení platí zejména v případě, že návrh aplikace zohledňuje tři nebo více oblastí Azure, protože omezení relačních technologií můžou výrazně bránit globálně distribuovaným datovým platformám.
- Horizontální dělení není vhodné pro všechny scénáře aplikací, proto se vyžaduje kontextové vyhodnocení.
Určete prioritu použití služby Azure SQL Database, ve které existují relační požadavky, a to z důvodu její vyspělosti na platformě Azure a široké škály možností spolehlivosti.
Azure SQL Database
Úroveň služby Business-Critical můžete použít k maximalizaci spolehlivosti a dostupnosti, včetně přístupu k důležitým funkcím odolnosti.
Model spotřeby založený na virtuálních jádrech vám usnadní nezávislý výběr výpočetních prostředků a prostředků úložiště přizpůsobených požadavkům na objem a propustnost úloh.
- Ujistěte se, že se používá definovaný model kapacity, který informuje o požadavcích na výpočetní prostředky a prostředky úložiště.
- Zvažte rezervovanou kapacitu , abyste mohli zajistit potenciální optimalizaci nákladů.
- Ujistěte se, že se používá definovaný model kapacity, který informuje o požadavcích na výpočetní prostředky a prostředky úložiště.
Nakonfigurujte model nasazení Zone-Redundant tak, aby se repliky databáze Pro důležité obchodní informace rozprostřely v rámci stejné oblasti napříč Zóny dostupnosti.
Pomocí aktivní geografické replikace nasaďte repliky pro čtení ve všech oblastech nasazení (až čtyři).
Skupiny automatického převzetí služeb při selhání slouží k zajištění transparentního převzetí služeb při selhání sekundární oblastí s geografickou replikací, která zajišťuje replikaci do dalších oblastí nasazení za účelem optimalizace čtení a redundance databáze.
- V případě scénářů aplikací omezených pouze na dvě oblasti nasazení by měla být upřednostněna použití skupin automatického převzetí služeb při selhání.
Zvažte automatizované provozní triggery založené na upozorňování, které odpovídají modelu stavu aplikace, a proveďte převzetí služeb při selhání geograficky replikovanými instancemi v případě, že selhání ovlivňuje primární a sekundární službu v rámci skupiny automatického převzetí služeb při selhání.
Důležité
U aplikací, které zvažují více než čtyři oblasti nasazení, je potřeba vážně zvážit horizontální dělení v rámci aplikace nebo refaktoring aplikace tak, aby podporovaly technologie zápisu do více oblastí, jako je azure Cosmos DB. Pokud to ale není možné ve scénáři úloh aplikace, doporučujeme zvýšit úroveň oblasti v rámci jedné geografické oblasti na primární stav zahrnující geograficky replikovanou instanci na rovnoměrnější přístup pro čtení.
Nakonfigurujte aplikaci tak, aby se za účelem optimalizace výkonu čtení dotazovali na instance replik pro dotazy na čtení.
Využijte Azure Monitor a Azure SQL Analytics k získání provozních přehledů téměř v reálném čase ve službě Azure SQL DB pro detekci incidentů spolehlivosti.
Pomocí Azure Monitoru vyhodnoťte využití všech databází, abyste zjistili, jestli mají správnou velikost.
- Ujistěte se, že kanály CD zvažují zátěžové testování pod reprezentativními úrovněmi zatížení, aby se ověřilo správné chování datové platformy.
Vypočítejte metriku stavu databázových komponent, abyste mohli sledovat stav vzhledem k obchodním požadavkům a využití prostředků. Tam, kde je to vhodné, využijte monitorování a výstrahy k řízení automatizovaných provozních akcí.
- Ujistěte se, že jsou zahrnuté klíčové metriky výkonu dotazů, aby bylo možné provést rychlou akci, když dojde ke snížení výkonu služby.
Optimalizujte dotazy, tabulky a databáze pomocí nástroje Query Performance Insights a běžných doporučení k výkonu od Microsoftu.
Implementujte logiku opakování pomocí sady SDK, abyste zmírnili přechodné chyby, které mají vliv na připojení Azure SQL databáze.
Při použití transparentního šifrování dat (TDE) na straně serveru pro šifrování neaktivních uložených dat určete prioritu použití klíčů spravovaných službou.
- Pokud se vyžaduje šifrování klíčů spravovaných zákazníkem nebo šifrování na straně klienta (AlwaysEncrypted), ujistěte se, že klíče jsou správně odolné díky zálohám a možnostem automatizované rotace.
Zvažte použití obnovení k určitému bodu v čase jako provozního playbooku k zotavení po závažných chybách konfigurace.
Azure Database For PostgreSQL
Flexibilní server se doporučuje používat pro důležité obchodní úlohy kvůli podpoře zóny dostupnosti.
Pokud používáte Hyperscale (Citus) pro důležité obchodní úlohy, povolte režim vysoké dostupnosti, aby získal 99,95% záruku SLA.
Pomocí konfigurace serveru Hyperscale (Citus) maximalizujte dostupnost napříč několika uzly.
Definujte pro aplikaci model kapacity, který bude informovat o požadavcích na výpočetní prostředky a prostředky úložiště v rámci datové platformy.
- Zvažte slevu za rezervaci Hyperscale (Citus), která vám poskytne potenciální optimalizaci nákladů.
Ukládání dat horké vrstvy do mezipaměti
Vrstvu ukládání do mezipaměti v paměti je možné použít k vylepšení datové platformy výrazným zvýšením propustnosti čtení a zlepšením doby odezvy klienta u scénářů s daty horké vrstvy.
Azure poskytuje několik služeb s použitelnými funkcemi pro ukládání klíčových datových struktur do mezipaměti s Azure Cache for Redis pro abstrakci a optimalizaci přístupu ke čtení z datové platformy. Tato část se proto zaměří na optimální využití Azure Cache for Redis ve scénářích, kde se vyžaduje další výkon při čtení a stálost přístupu k datům.
Aspekty návrhu
Vrstva ukládání do mezipaměti poskytuje další odolnost přístupu k datům, protože i v případě výpadku, který ovlivňuje technologie podkladových dat, je stále možné přistupovat ke snímku dat aplikace prostřednictvím vrstvy ukládání do mezipaměti.
V určitých scénářích úloh je možné ukládání do mezipaměti v paměti implementovat v rámci samotné aplikační platformy.
Azure Cache for Redis
Redis Cache je open source systém úložiště NoSQL klíč-hodnota v paměti.
Úrovně Enterprise a Enterprise Flash je možné nasadit v konfiguraci aktivní-aktivní napříč Zóny dostupnosti v rámci oblasti a různých oblastí Azure prostřednictvím geografické replikace.
- Při nasazení do nejméně tří oblastí Azure a tří nebo více Zóny dostupnosti v každé oblasti s povolenou aktivní geografickou replikací pro všechny instance mezipaměti Azure Cache for Redis poskytuje smlouvu SLA na 99,999 % pro připojení k jednomu regionálnímu koncovému bodu mezipaměti.
- Při nasazení ve třech Zóny dostupnosti v rámci jedné oblasti Azure je poskytována smlouva SLA o připojení 99,99 %.
Podniková úroveň Flash běží na kombinaci paměti RAM a úložiště paměti flash, které nejsou nestálé, a přestože to přináší malé snížení výkonu, umožňuje také velmi velké mezipaměti, až do 13 TB s clusteringem.
U geografické replikace se kromě přímých nákladů spojených s instancemi mezipaměti budou účtovat také poplatky za přenos dat mezi oblastmi.
Funkce Plánované Aktualizace nezahrnuje aktualizace Azure nebo aktualizace použité na základní operační systém virtuálního počítače.
Během operace škálování na více instancí dojde ke zvýšení využití procesoru, zatímco se data migrují do nových instancí.
Doporučení k návrhu
Zvažte optimalizovanou vrstvu ukládání do mezipaměti pro scénáře "horkých" dat, abyste zvýšili propustnost čtení a vylepšili dobu odezvy.
Použijte vhodné zásady pro vypršení platnosti mezipaměti a správu domácnosti, abyste zabránili nechtěným nárůstům dat.
- Při změně záložních dat zvažte vypršení platnosti položek mezipaměti.
Azure Cache for Redis
Využijte skladovou položku Premium nebo Enterprise k maximalizaci spolehlivosti a výkonu.
- Ve scénářích s extrémně velkými objemy dat byste měli zvážit úroveň Enterprise Flash.
- Ve scénářích, ve kterých se vyžaduje pouze pasivní geografická replikace, je možné zvážit také úroveň Premium.
Nasaďte instance replik pomocí geografické replikace v aktivní konfiguraci napříč všemi zvaženými oblastmi nasazení.
Ujistěte se, že jsou instance replik nasazené napříč Zóny dostupnosti v každé považované oblasti Azure.
K vyhodnocení Azure Cache for Redis použijte Azure Monitor.
- Vypočítejte skóre stavu komponent místní mezipaměti, abyste mohli sledovat stav vzhledem k obchodním požadavkům a využití prostředků.
- Sledujte klíčové metriky, jako jsou vysoké využití procesoru, vysoké využití paměti, vysoké zatížení serveru a vyřazené klíče, a upozorňování na tyto metriky, abyste mohli získat přehled o škálování mezipaměti.
Optimalizujte odolnost připojení implementací logiky opakování, vypršení časových limitů a použitím jednoznačné implementace multiplexeru připojení Redis.
Nakonfigurujte plánované aktualizace tak, aby předepisují dny a časy, kdy se aktualizace Redis Serveru použijí v mezipaměti.
Analytické scénáře
U důležitých aplikací je stále častější uvažovat o analytických scénářích jako o prostředku, jak ze zahrnutí toků dat získat další hodnotu. Aplikační a provozní analytické scénáře (AIOps) proto tvoří zásadní aspekt vysoce spolehlivé datové platformy.
Analytické a transakční úlohy vyžadují různé možnosti a optimalizace datové platformy pro přijatelný výkon v příslušných kontextech.
| Description | Analytické | Transakční |
|---|---|---|
| Případ použití | Analýza velmi velkých objemů dat ("velké objemy dat") | Zpracování velmi velkých objemů jednotlivých transakcí |
| Optimalizováno pro | Čtení dotazů a agregací u mnoha záznamů | Dotazy CRUD (Create/Read/Update/Delete) téměř v reálném čase nad několika záznamy |
| Klíčové charakteristiky | – Konsolidace ze zdrojů dat záznamů - Sloupcové úložiště - Distribuované úložiště - Paralelní zpracování - Denormalizované - Nízká souběžnost čtení a zápisy - Optimalizace pro svazek úložiště s kompresí |
– Zdroj dat záznamu pro aplikaci – Řádkové úložiště - Souvislé úložiště - Symetrické zpracování -Normalizované - Vysoká souběžnost čtení a zápisů, aktualizace indexů - Optimalizace pro rychlý přístup k datům s využitím úložiště v paměti |
Azure Synapse poskytuje podnikovou analytickou platformu, která spojuje relační a nerelační data s technologiemi Sparku a využívá integrovanou integraci se službami Azure, jako je Azure Cosmos DB, a usnadňuje tak analýzu velkých objemů dat. Aspekty návrhu a doporučení v této části se proto zaměří na optimální Azure Synapse a využití služby Azure Cosmos DB pro analytické scénáře.
Aspekty návrhu
- Tradičně se rozsáhlé analytické scénáře usnadňují extrahováním dat do samostatné datové platformy optimalizované pro následné analytické dotazy.
- K extrakci dat se používají kanály extrakce, transformace a načítání (ETL), které spotřebovávají propustnost a ovlivňují výkon transakčních úloh.
- Občasné spouštění kanálů ETL za účelem snížení propustnosti a dopadu na výkon způsobí, že analytická data budou méně aktuální.
- Se složitějšími transformacemi dat se zvyšuje režie na vývoj a údržbu kanálů ETL.
- Pokud se například často mění nebo odstraňují zdrojová data, kanály ETL musí tyto změny v cílových datech pro analytické dotazy zohlednit prostřednictvím doplňkového přístupu nebo přístupu s verzí, výpisu a opětovného načtení nebo místních změn v analytických datech. Každý z těchto přístupů bude mít vliv na deriváty, například opětovné vytvoření nebo aktualizace indexu.
Azure Cosmos DB
Analytické dotazy spouštěné na transakčních datech služby Azure Cosmos DB se obvykle agregují napříč oddíly ve velkých objemech dat a spotřebovávají významnou propustnost jednotky žádostí (RU), což může mít vliv na výkon okolních transakčních úloh.
Analytické úložiště azure Cosmos DB poskytuje schematizované, plně izolované sloupcově orientované úložiště dat, které umožňuje rozsáhlé analýzy dat služby Azure Cosmos DB z Azure Synapse bez dopadu na transakční úlohy služby Azure Cosmos DB.
- Pokud je kontejner Azure Cosmos DB povolený jako analytické úložiště, vytvoří se interně nové úložiště sloupců z provozních dat v kontejneru. Toto úložiště sloupců se uchovává odděleně od úložiště transakcí orientovaných na řádky pro kontejner.
- Operace vytvoření, aktualizace a odstranění provozních dat se automaticky synchronizují s analytickým úložištěm, takže se nevyžaduje žádný kanál změn ani zpracování ETL.
- Synchronizace dat z provozního úložiště do analytického úložiště nevyužívají jednotky žádostí o propustnost (RU) zřízené v kontejneru nebo databázi. Transakční úlohy nemají žádný vliv na výkon. Analytické úložiště nevyžaduje přidělení dalších RU ve službě Azure Cosmos DB Database nebo kontejneru.
- Automatická synchronizace je proces, při kterém se změny provozních dat automaticky synchronizují do analytického úložiště. Latence automatické synchronizace je obvykle kratší než dvě (2) minuty.
- Latence automatické synchronizace může u databáze se sdílenou propustností a velkým počtem kontejnerů být až pět (5) minut.
- Jakmile se automatická synchronizace dokončí, můžete se na nejnovější data dotazovat z Azure Synapse.
- Úložiště analytického úložiště používá cenový model založený na spotřebě, který účtuje objem dat a počet operací čtení a zápisu. Ceny analytického úložiště jsou oddělené od cen transakčního úložiště.
Pomocí Azure Synapse Link je možné dotazovat analytické úložiště Azure Cosmos DB přímo z Azure Synapse. To umožňuje hybridní Transactional-Analytical zpracování bez ETL (HTAP) ze Synapse, aby se data Azure Cosmos DB mohla dotazovat spolu s dalšími analytickými úlohami ze Synapse téměř v reálném čase.
Analytické úložiště služby Azure Cosmos DB není ve výchozím nastavení rozdělené na oddíly.
- V některých scénářích dotazů se výkon zlepší dělením dat analytického úložiště pomocí klíčů, které se často používají v predikátech dotazů.
- Dělení aktivuje úloha v Azure Synapse, která spouští poznámkový blok Sparku pomocí Synapse Link, který načte data z analytického úložiště Azure Cosmos DB a zapíše je do úložiště synapse rozděleného do primárního účtu úložiště pracovního prostoru Synapse.
Azure Synapse Bezserverové fondy SQL Analytics můžou dotazovat analytické úložiště prostřednictvím automaticky aktualizovaných zobrazení nebo příkazů
SELECT / OPENROWSET.fondy Sparku Azure Synapse Analytics se můžou dotazovat na analytické úložiště prostřednictvím automaticky aktualizovaných tabulek Sparku
spark.readnebo příkazu.Data je také možné zkopírovat z analytického úložiště Azure Cosmos DB do vyhrazeného fondu Synapse SQL pomocí Sparku, aby bylo možné použít zřízené prostředky Azure Synapse fondu SQL.
Data analytického úložiště služby Azure Cosmos DB je možné dotazovat pomocí Azure Synapse Sparku.
- Poznámkové bloky Spark umožňují kombinací datových rámců Sparku agregovat a transformovat analytická data služby Azure Cosmos DB s jinými sadami dat a používat další pokročilé funkce Synapse Sparku, včetně zápisu transformovaných dat do jiných úložišť nebo trénování modelů AIOps Machine Learning.
 s
s
- Kanál změn azure Cosmos DB je také možné použít k údržbě samostatného sekundárního úložiště dat pro analytické scénáře.
Azure Synapse
Azure Synapse spojuje analytické funkce, včetně sql datových skladů, Sparku pro velké objemy dat a Data Explorer pro analýzu protokolů a časových řad.
- Azure Synapse používá propojené služby k definování připojení k dalším službám, jako je Azure Storage.
- Data je možné ingestovat do Synapse Analytics prostřednictvím aktivita Copy z podporovaných zdrojů. To umožňuje analýzu dat v Synapse, aniž by to mělo vliv na zdrojové úložiště dat, ale kvůli přenosu dat se zvyšuje režie času, nákladů a latence.
- Data se také dají dotazovat místně v podporovaných externích úložištích, aby se zabránilo režii příjmu a přesunu dat. Azure Storage s Data Lake Gen2 je podporované úložiště pro Synapse a exportovaná data Log Analytics se dají dotazovat přes Synapse Spark.
Azure Synapse Studio spojuje úlohy příjmu dat a dotazování.
- Zdrojová data, včetně dat analytického úložiště služby Azure Cosmos DB a exportních dat Log Analytics, se dotazují a zpracovávají za účelem podpory business intelligence a dalších agregovaných analytických případů použití.

Doporučení k návrhu
- Ujistěte se, že analytické úlohy nemají vliv na úlohy transakčních aplikací, aby se zachoval transakční výkon.
Analýza aplikací
Pomocí nástroje Azure Synapse Link s analytickým úložištěm Azure Cosmos DB můžete provádět analýzy provozních dat služby Azure Cosmos DB vytvořením optimalizovaného úložiště dat, které neovlivní výkon transakcí.
- Povolte Azure Synapse Link v účtech Služby Azure Cosmos DB.
- Vytvořte kontejner s povoleným analytickým úložištěm nebo povolte existující kontejner pro analytické úložiště.
- Připojte pracovní prostor Azure Synapse k analytickému úložišti služby Azure Cosmos DB, abyste umožnili analytickým úlohám v Azure Synapse dotazovat data služby Azure Cosmos DB. Použijte připojovací řetězec s klíčem Azure Cosmos DB jen pro čtení.
Upřednostnění analytického úložiště služby Azure Cosmos DB s využitím Azure Synapse Linku místo použití kanálu změn služby Azure Cosmos DB k údržbě analytického úložiště dat
- Kanál změn služby Azure Cosmos DB může být vhodný pro velmi jednoduché analytické scénáře.
AIOps a provozní analýzy
Vytvořte jeden pracovní prostor Azure Synapse s propojenými službami a datovými sadami pro každý zdrojový účet Azure Storage, do kterého se odesílají provozní data z prostředků.
Vytvořte vyhrazený účet Azure Storage a použijte ho jako primární účet úložiště pracovního prostoru k ukládání dat a metadat katalogu pracovních prostorů Synapse. Nakonfigurujte ho s hierarchickým oborem názvů, abyste povolili Azure Data Lake Gen2.
- Udržujte oddělení mezi zdrojovými analytickými daty a metadaty a daty pracovního prostoru Synapse.
- Nepoužívejte jeden z regionálních nebo globálních účtů Azure Storage, do kterých se odesílají provozní data.
- Udržujte oddělení mezi zdrojovými analytickými daty a metadaty a daty pracovního prostoru Synapse.
Další krok
Projděte si důležité informace o sítích.
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro