Kopieren von Daten aus einer SQL Server-Datenbank nach Azure Blob Storage
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Tutorial verwenden Sie die Benutzeroberfläche (User Interface, UI) von Azure Data Factory zum Erstellen einer Data Factory-Pipeline, mit der Daten aus einer SQL Server-Datenbank in Azure Blob Storage kopiert werden. Sie erstellen und verwenden eine selbstgehostete Integration Runtime, die Daten zwischen lokalen Speichern und Clouddatenspeichern verschiebt.
Hinweis
Dieser Artikel enthält keine ausführliche Einführung in Data Factory. Weitere Informationen finden Sie unter Einführung in Azure Data Factory.
In diesem Tutorial führen Sie die folgenden Schritte aus:
- Erstellen einer Data Factory.
- Erstellen Sie eine selbstgehostete Integration Runtime.
- Erstellen von verknüpften SQL Server- und Azure Storage-Diensten
- Erstellen von SQL Server- und Azure Blob-Datasets
- Erstellen einer Pipeline mit Kopieraktivität zum Verschieben der Daten
- Starten einer Pipelineausführung
- Überwachen der Pipelineausführung.
Voraussetzungen
Azure-Abonnement
Wenn Sie nicht bereits ein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
Azure-Rollen
Damit Sie Data Factory-Instanzen erstellen können, muss dem Benutzerkonto, mit dem Sie sich bei Azure anmelden, die Rolle Mitwirkender oder Besitzer zugewiesen sein, oder es muss ein Administrator des Azure-Abonnements sein.
Die Berechtigungen, über die Sie im Abonnement verfügen, können Sie im Azure-Portal einsehen. Wählen Sie oben rechts Ihren Benutzernamen und dann in der Liste Berechtigungen aus. Wenn Sie Zugriff auf mehrere Abonnements besitzen, wählen Sie das entsprechende Abonnement aus. Beispielanleitungen zum Hinzufügen eines Benutzers zu einer Rolle finden Sie im Artikel Hinzufügen von Azure-Rollenzuweisungen über das Azure-Portal.
SQL Server 2014, 2016 und 2017
In diesem Tutorial verwenden Sie eine SQL Server-Datenbank als Quelldatenspeicher. Die Pipeline in der in diesem Tutorial erstellten Data Factory kopiert Daten aus dieser SQL Server-Datenbank (Quelle) in Blob Storage (Senke). Anschließend erstellen Sie eine Tabelle mit dem Namen emp in Ihrer SQL Server-Datenbank und fügen einige Beispieleinträge in die Tabelle ein.
Starten Sie SQL Server Management Studio. Falls die Suite auf Ihrem Computer noch nicht installiert wurde, rufen Sie Herunterladen von SQL Server Management Studio (SSMS) auf.
Stellen Sie eine Verbindung mit Ihrer SQL Server-Instanz her, indem Sie Ihre Anmeldeinformationen verwenden.
Erstellen Sie eine Beispieldatenbank. Klicken Sie in der Strukturansicht mit der rechten Maustaste auf Datenbanken, und wählen Sie anschließend Neue Datenbank.
Geben Sie im Fenster Neue Datenbank einen Namen für die Datenbank ein, und wählen Sie dann OK.
Führen Sie das folgende Abfrageskript für die Datenbank aus, um die Tabelle emp zu erstellen und einige Beispieldaten einzufügen. Klicken Sie in der Strukturansicht mit der rechten Maustaste auf die von Ihnen erstellte Datenbank, und wählen Sie anschließend Neue Abfrage.
CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO INSERT INTO emp (FirstName, LastName) VALUES ('John', 'Doe') INSERT INTO emp (FirstName, LastName) VALUES ('Jane', 'Doe') GO
Azure-Speicherkonto
Sie verwenden in diesem Tutorial ein Azure Storage-Allzweckkonto (Blob Storage) als Ziel-/Senkendatenspeicher. Falls Sie noch nicht über ein allgemeines Azure-Speicherkonto verfügen, helfen Ihnen die Informationen unter Erstellen Sie ein Speicherkonto weiter. Die Pipeline in der in diesem Tutorial erstellten Data Factory kopiert Daten aus der SQL Server-Datenbank (Quelle) in Blob Storage (Senke).
Abrufen des Speicherkontonamens und des Kontoschlüssels
In diesem Tutorial verwenden Sie Name und Schlüssel Ihres Speicherkontos. Den Namen und den Schlüssel Ihres Speicherkontos ermitteln Sie anhand der folgenden Schritte:
Melden Sie sich mit Ihrem Azure-Benutzernamen und dem dazugehörigen Kennwort beim Azure-Portal an.
Wählen Sie im linken Bereich Alle Dienste aus. Filtern Sie nach dem Schlüsselwort Speicher, und wählen Sie dann Speicherkonten aus.
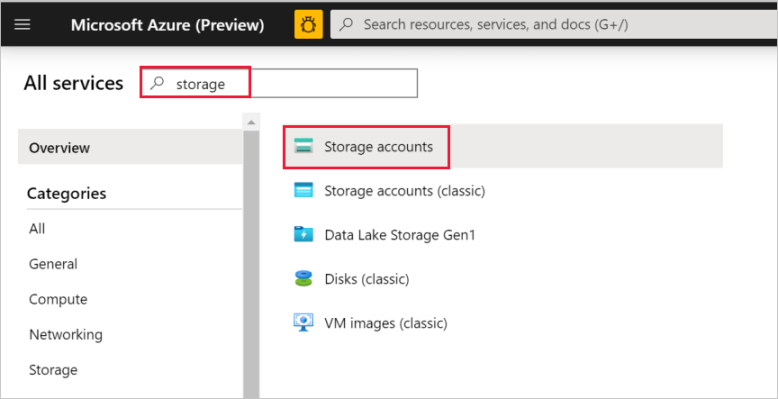
Filtern Sie in der Liste mit den Speicherkonten ggf. nach Ihrem Speicherkonto. Wählen Sie dann Ihr Speicherkonto aus.
Wählen Sie im Fenster Speicherkonto die Option Zugriffsschlüssel.
Kopieren Sie in den Feldern Speicherkontoname und key1 die Werte, und fügen Sie sie zur späteren Verwendung im Tutorial in einen Editor ein.
Erstellen des Containers „adftutorial“
In diesem Abschnitt erstellen Sie einen Blobcontainer mit dem Namen adftutorial in Ihrer Blob Storage-Instanz.
Wechseln Sie im Fenster Speicherkonto zu Übersicht, und wählen Sie die Option Container aus.
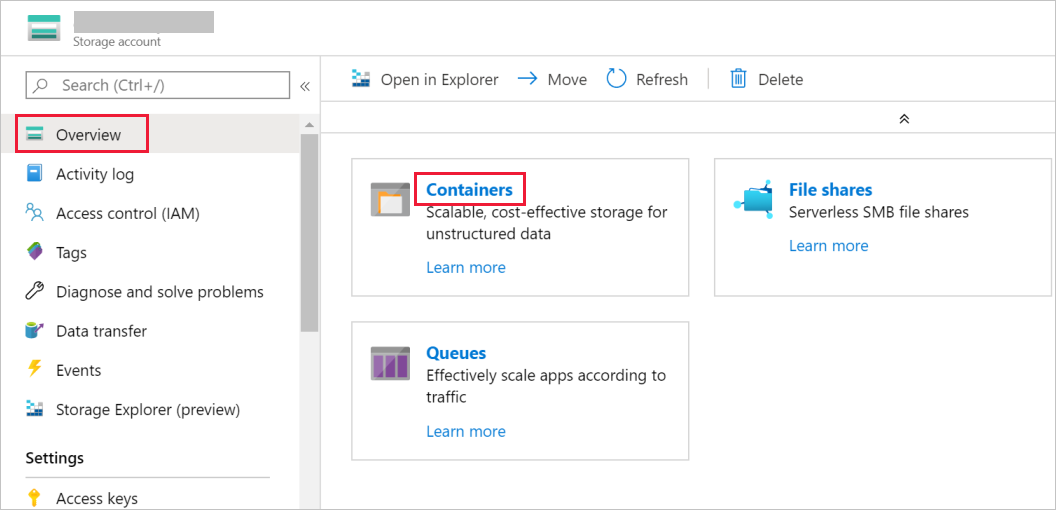
Wählen Sie im Fenster Container die Option + Container aus, um einen neuen Container zu erstellen.
Geben Sie im Fenster Neuer Container unter Name den Namen adftutorial ein. Klicken Sie anschließend auf Erstellen.
Wählen Sie in der Liste mit den Containern den eben erstellten Container adftutorial aus.
Lassen Sie das Fenster Container für adftutorial geöffnet. Sie überprüfen darin am Ende des Tutorials die Ausgabe. Data Factory erstellt den Ausgabeordner automatisch in diesem Container, damit Sie ihn nicht selbst erstellen müssen.
Erstellen einer Data Factory
In diesem Schritt erstellen Sie eine Data Factory und starten die Data Factory-Benutzeroberfläche, um eine Pipeline in der Data Factory zu erstellen.
Öffnen Sie Microsoft Edge oder Google Chrome. Die Data Factory-Benutzeroberfläche wird zurzeit nur in den Webbrowsern Microsoft Edge und Google Chrome unterstützt.
Wählen Sie im Menü auf der linken Seite Ressource erstellen>Integration>Data Factory aus:
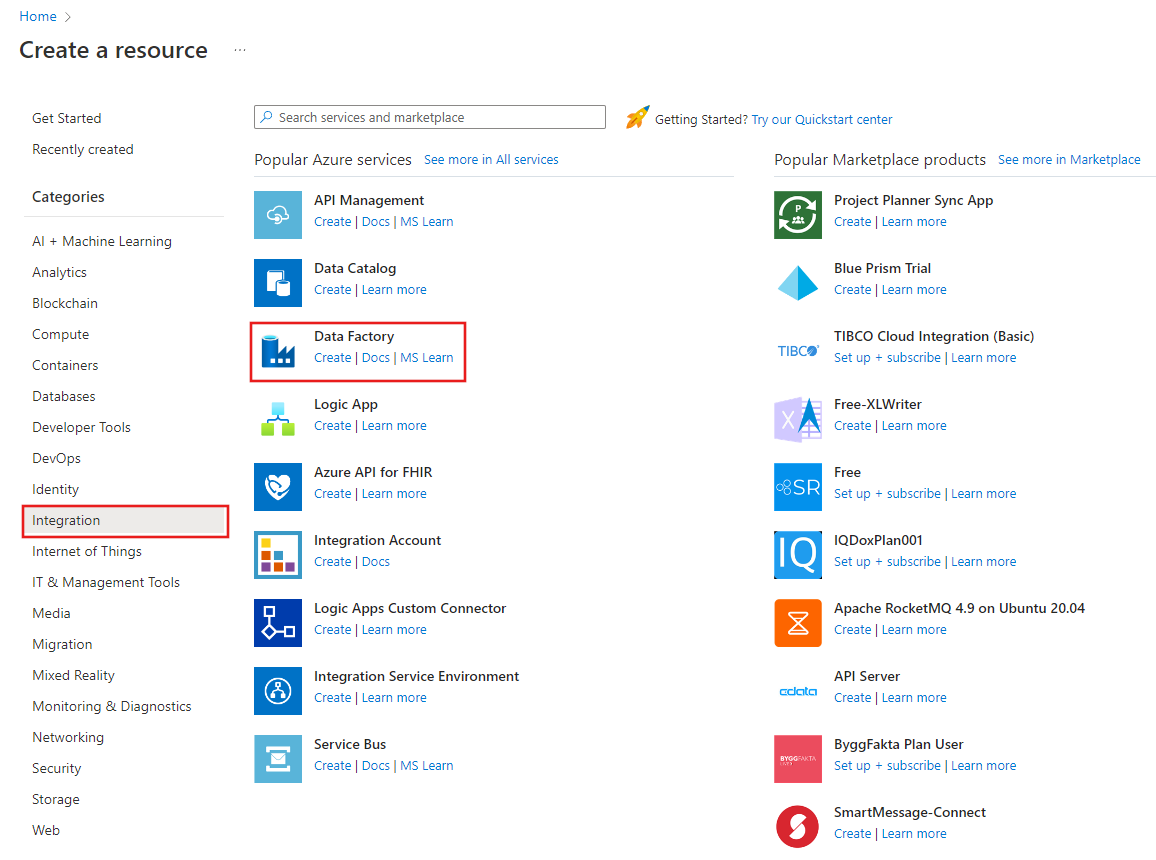
Geben Sie auf der Seite Neue Data Factory unter Name den Namen ADFTutorialDataFactory ein.
Der Name der Data Factory muss global eindeutig sein. Sollte für das Feld „Name“ die folgende Fehlermeldung angezeigt werden, ändern Sie den Namen der Data Factory (beispielsweise in „
ADFTutorialDataFactory“). Benennungsregeln für Data Factory-Artefakte finden Sie im Thema Azure Data Factory – Benennungsregeln. 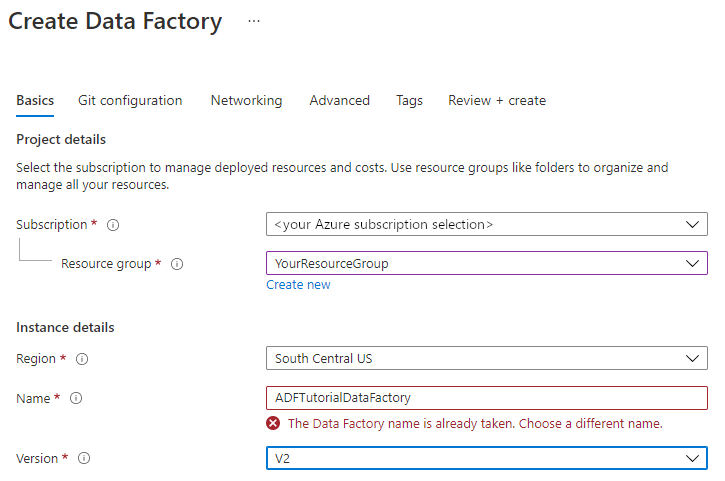
Wählen Sie das Azure-Abonnement aus, in dem die Data Factory erstellt werden soll.
Führen Sie unter Ressourcengruppe einen der folgenden Schritte aus:
Wählen Sie die Option Use existing(Vorhandene verwenden) und dann in der Dropdownliste eine vorhandene Ressourcengruppe.
Wählen Sie Neu erstellen, und geben Sie den Namen einer Ressourcengruppe ein.
Weitere Informationen zu Ressourcengruppen finden Sie unter Verwenden von Ressourcengruppen zum Verwalten von Azure-Ressourcen.
Wählen Sie unter Version die Option V2.
Wählen Sie unter Standort den Standort für die Data Factory aus. In der Dropdownliste werden nur unterstützte Standorte angezeigt. Die Datenspeicher (etwa Storage und SQL-Datenbank) und Computeeinheiten (etwa Azure HDInsight), die von Data Factory genutzt werden, können sich in anderen Regionen befinden.
Klicken Sie auf Erstellen.
Nach Abschluss der Erstellung wird die Seite Data Factory wie in der Abbildung angezeigt:
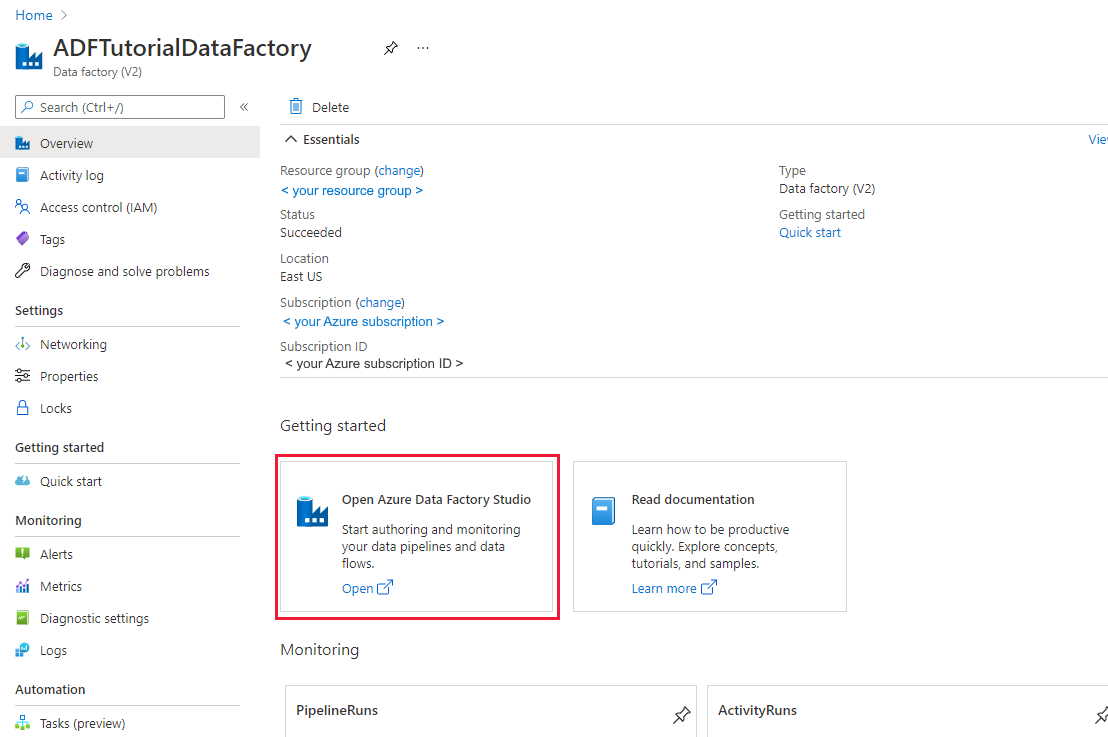
Klicken Sie auf der Kachel Open Azure Data Factory Studio auf Öffnen, um die Data Factory-Benutzeroberfläche in einer separaten Registerkarte zu starten.
Erstellen einer Pipeline
Klicken Sie auf der Startseite von Azure Data Factory auf Orchestrieren. Eine Pipeline wird automatisch für Sie erstellt. Die Pipeline wird in der Strukturansicht angezeigt, und der dazugehörige Editor wird geöffnet.

Geben Sie im Bereich „Allgemein“ unter Eigenschaften die Eigenschaft SQLServerToBlobPipeline für Name an. Reduzieren Sie dann den Bereich, indem Sie in der oberen rechten Ecke auf das Symbol „Eigenschaften“ klicken.
Erweitern Sie in der Toolbox Aktivitäten die Option Move & Transform (Verschieben und transformieren). Ziehen Sie die Aktivität Kopieren auf die Oberfläche zum Entwerfen von Pipelines. Legen Sie den Namen der Aktivität auf CopySqlServerToAzureBlobActivity fest.
Wechseln Sie im Fenster Eigenschaften zur Registerkarte Quelle, und klicken Sie auf + Neu.
Suchen Sie im Dialogfeld Neues Dataset nach SQL Server. Wählen Sie SQL Server und dann Weiter aus.
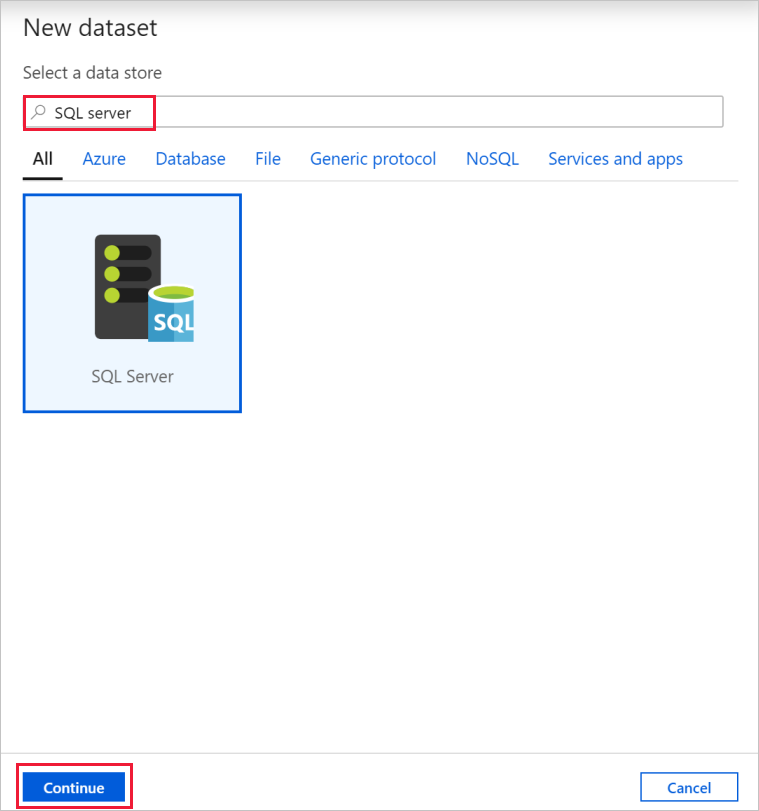
Geben Sie im Dialogfeld Eigenschaften festlegen unter Name den Namen SqlServerDataset ein. Wählen Sie unter Verknüpfter Dienst die Option + Neu aus. In diesem Schritt erstellen Sie eine Verbindung mit dem Quelldatenspeicher (SQL Server-Datenbank).
Fügen Sie im Dialogfeld New Linked Service (Neuer verknüpfter Dienst) als Name den Namen SqlServerLinkedService hinzu. Wählen Sie unter Connect via integration runtime (Verbindung per Integration Runtime herstellen) die Option +Neu aus. In diesem Abschnitt erstellen Sie eine selbstgehostete Integration Runtime und ordnen sie einem lokalen Computer mit der SQL Server-Datenbank zu. Die selbstgehostete Integration Runtime ist die Komponente, die Daten aus der SQL Server-Datenbank auf Ihrem Computer in Blob Storage kopiert.
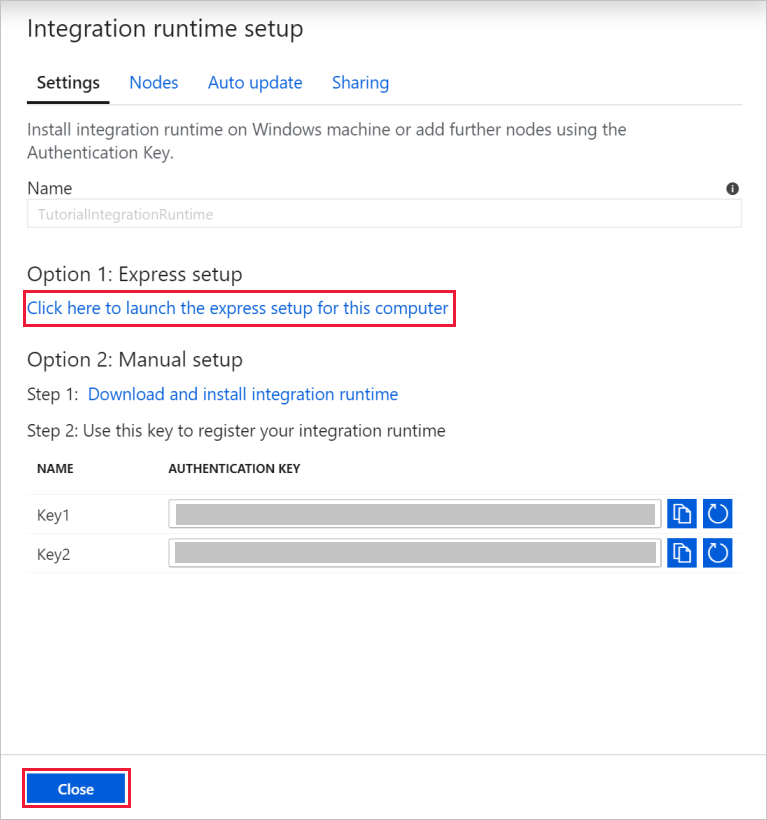
Wählen Sie im Dialogfeld Integration Runtime Setup (Integration Runtime-Setup) die Option Self-Hosted (Selbstgehostet) und anschließend Weiter aus.
Geben Sie unter „Name“ den Namen TutorialIntegrationRuntime ein. Klicken Sie anschließend auf Erstellen.
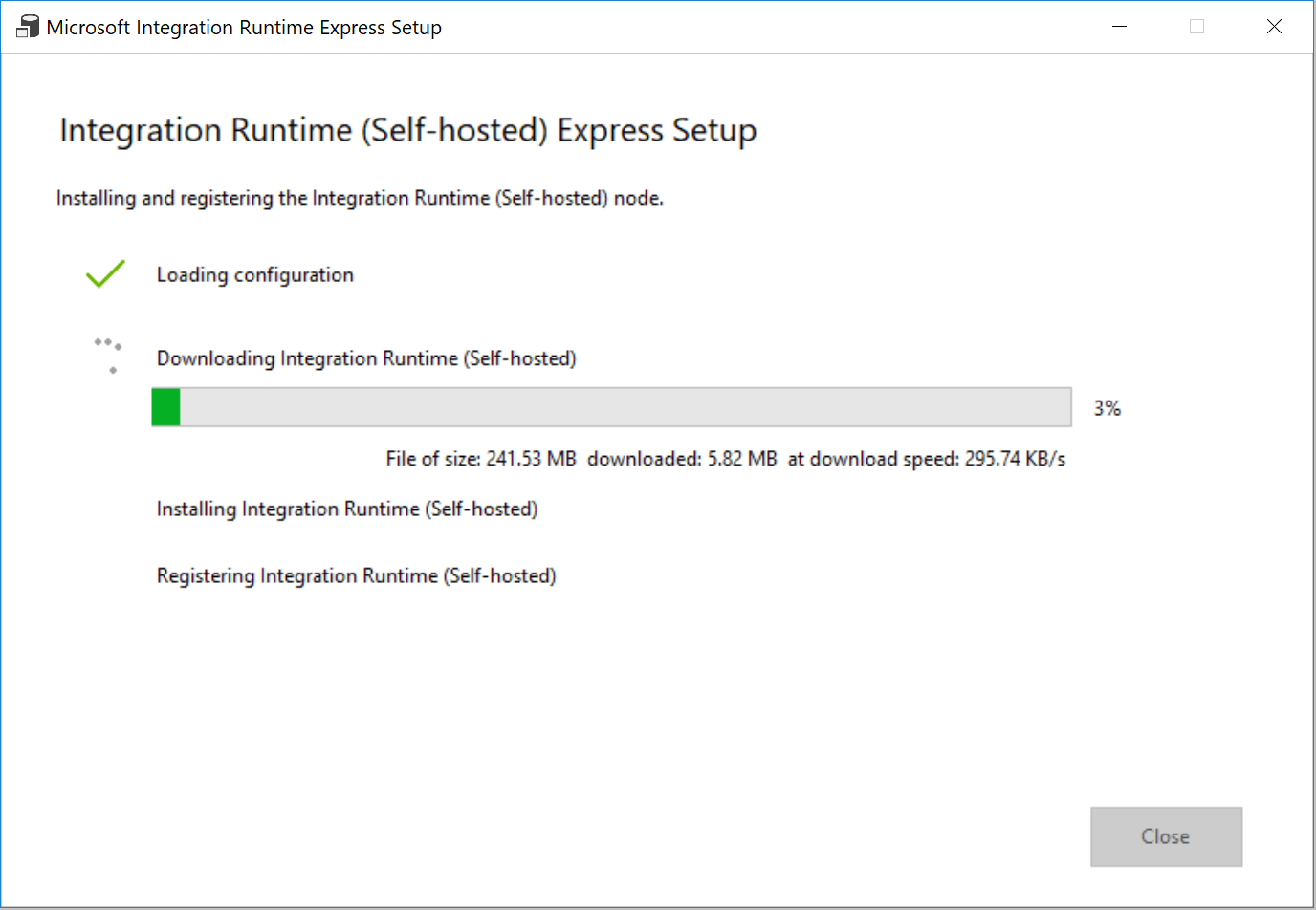
Wählen Sie in den Einstellungen die Option Click here to launch the express setup for this computer (Klicken Sie hier, um das Express-Setup für diesen Computer zu starten) aus. Dadurch wird die Integration Runtime auf Ihrem Computer installiert und bei Data Factory registriert. Alternativ können Sie die Installationsdatei über die manuelle Setupoption herunterladen, die Datei ausführen und die Integration Runtime mithilfe des Schlüssels registrieren.
Wählen Sie im Fenster Express-Setup von Integration Runtime (selbstgehostet) nach Abschluss des Vorgangs Schließen aus.
Stellen Sie im Dialogfeld New linked service (SQL Server) (Neuer verknüpfter Dienst (SQL Server)) sicher, dass TutorialIntegrationRuntime unter Connect via integration runtime (Verbindung per Integration Runtime herstellen) ausgewählt ist. Führen Sie dann die folgenden Schritte aus:
a. Geben Sie unter Name die Zeichenfolge SqlServerLinkedService ein.
b. Geben Sie unter Servername den Namen Ihrer SQL Server-Instanz ein.
c. Geben Sie unter Datenbankname den Namen der Datenbank mit der Tabelle emp an.
d. Wählen Sie unter Authentifizierungstyp einen geeigneten Authentifizierungstyp aus, den Data Factory beim Herstellen der Verbindung mit Ihrer SQL Server-Datenbank verwenden soll.
e. Geben Sie unter Benutzername und Kennwort den Namen und das Kennwort ein. Verwenden Sie bei Bedarf mydomain\myuser als Benutzernamen.
f. Klicken Sie auf Verbindung testen. Mit diesem Schritt vergewissern Sie sich, dass Data Factory über die selbstgehostete Integration Runtime, die Sie erstellt haben, eine Verbindung mit Ihrer SQL Server-Datenbank herstellen kann.
g. Wählen Sie Erstellen aus, um den verknüpften Dienst zu speichern.
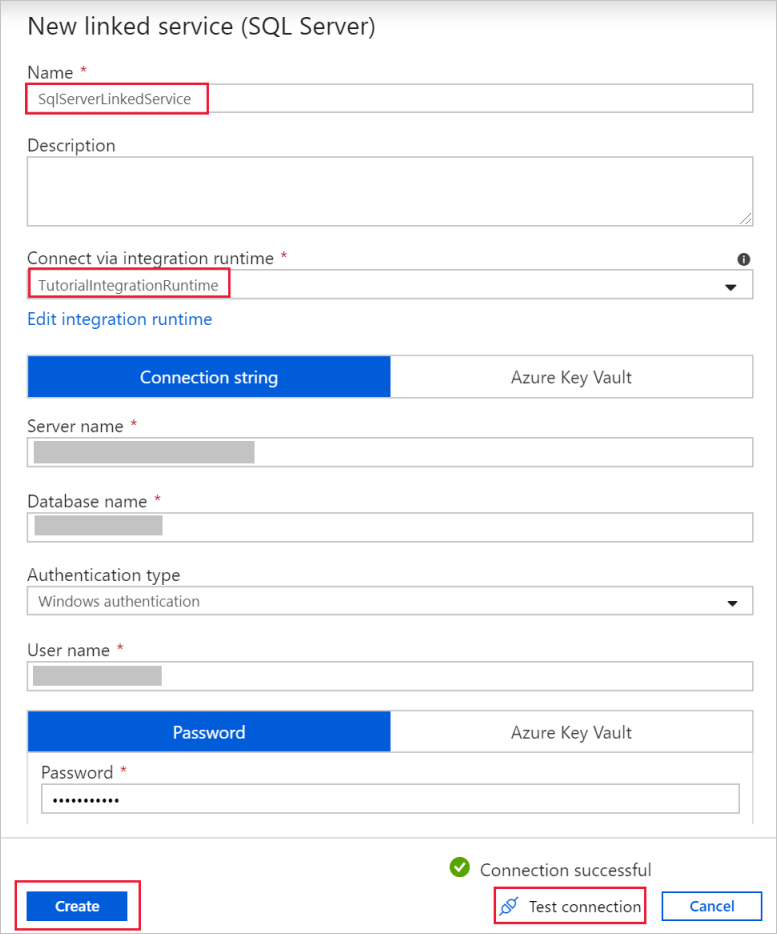
Nach der Erstellung des verknüpften Diensts wird wieder die Seite Eigenschaften festlegen für „SqlServerDataset“ angezeigt. Führen Sie die folgenden Schritte aus:
a. Vergewissern Sie sich, dass unter Verknüpfter Dienst die Zeichenfolge SqlServerLinkedService angezeigt wird.
b. Wählen Sie unter Tabellenname die Option [dbo].[emp] aus.
c. Klicken Sie auf OK.
Wechseln Sie zur Registerkarte mit der Pipeline SQLServerToBlobPipeline, oder klicken Sie in der Strukturansicht auf SQLServerToBlobPipeline.
Wechseln Sie unten im Fenster Eigenschaften zur Registerkarte Senke, und klicken Sie auf + Neu.
Wählen Sie im Dialogfeld Neues Dataset die Option Azure Blob Storage aus. Klicken Sie anschließend auf Weiter.
Wählen Sie im Dialogfeld Format auswählen den Formattyp Ihrer Daten aus. Klicken Sie anschließend auf Weiter.

Geben Sie im Dialogfeld Eigenschaften festlegen als Name AzureBlobDataset ein. Klicken Sie neben dem Textfeld Verknüpfter Dienst auf + Neu.
Geben Sie im Dialogfeld New Linked Service (Azure Blob Storage) (Neuer verknüpfter Dienst (Azure Blob Storage)) als Name AzureStorageLinkedService ein, und wählen Sie in der Liste Speicherkontoname Ihr Speicherkonto aus. Testen Sie die Verbindung, und wählen Sie dann Erstellen aus, um den verknüpften Dienst bereitzustellen.
Nach der Erstellung des verknüpften Diensts wird wieder die Seite Eigenschaften festlegen angezeigt. Klicken Sie auf OK.
Öffnen Sie das Senkendataset. Führen Sie auf der Registerkarte Verbindung folgende Schritte aus:
a. Vergewissern Sie sich, dass unter Verknüpfter Dienst die Option AzureStorageLinkedService ausgewählt ist.
b. Geben Sie unter Dateipfad für den Teil Container/Verzeichnis die Zeichenfolge adftutorial/fromonprem ein. Sollte der Ausgabeordner im Container „adftutorial“ nicht vorhanden sein, wird der Ausgabeordner von Data Factory automatisch erstellt.
c. Wählen Sie für den Teil Datei die Option Dynamischen Inhalt hinzufügen aus.
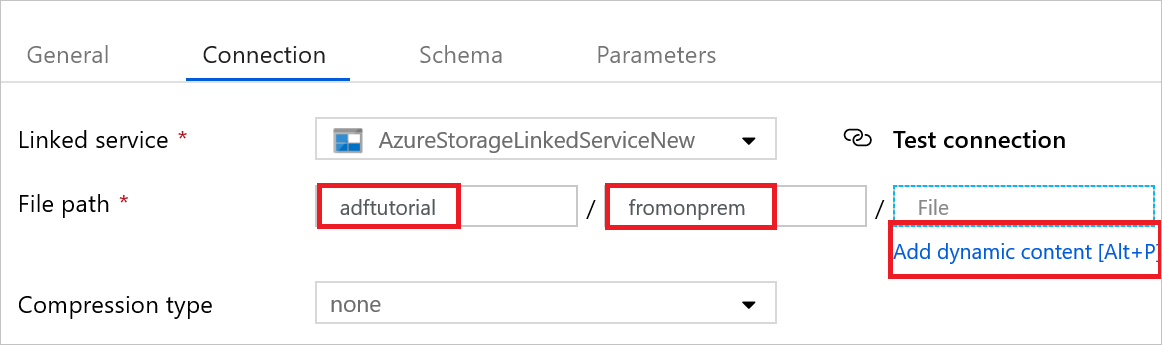
d. Fügen Sie
@CONCAT(pipeline().RunId, '.txt')hinzu, und wählen Sie dann Fertig stellen aus. Dadurch wird die Datei in „PipelineRunID.txt“ umbenannt.Wechseln Sie zur Registerkarte mit der geöffneten Pipeline, oder klicken Sie in der Strukturansicht auf die Pipeline. Vergewissern Sie sich, dass unter Sink Dataset (Senkendataset) die Option AzureBlobDataset ausgewählt ist.
Klicken Sie zum Überprüfen der Pipelineeinstellungen auf der Symbolleiste für die Pipeline auf Überprüfen. Wählen Sie zum Schließen der Ausgabe der Pipelineüberprüfung das Symbol >> aus.
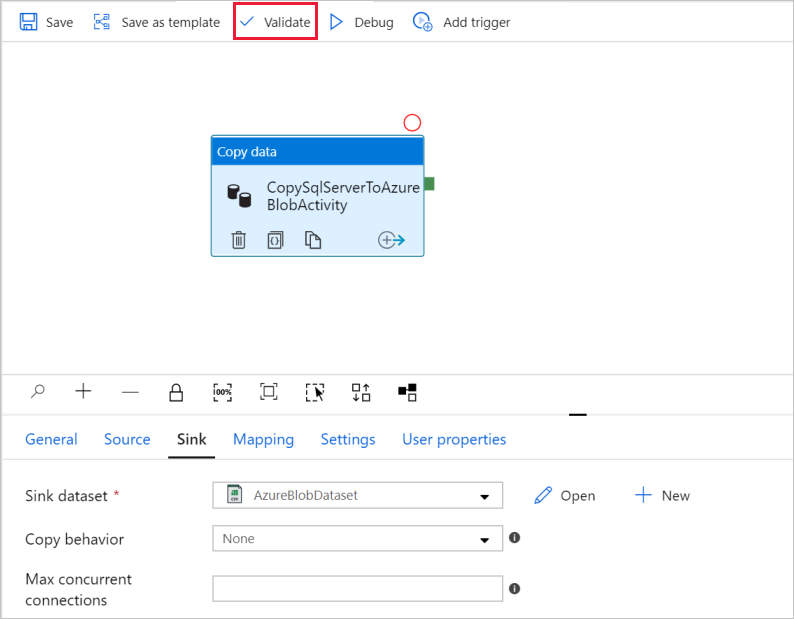
Wählen Sie zum Veröffentlichen der erstellten Entitäten in Data Factory Alle veröffentlichen aus.
Warten Sie, bis die Popupmeldung Publishing completed (Veröffentlichung abgeschlossen) angezeigt wird. Wenn Sie den Veröffentlichungsstatus überprüfen möchten, wählen Sie oben im Fenster den Link Benachrichtigungen anzeigen aus. Klicken Sie zum Schließen des Fensters mit den Benachrichtigungen auf Schließen.
Auslösen einer Pipelineausführung
Wählen Sie auf der Symbolleiste für die Pipeline die Option Trigger hinzufügen und dann Trigger Now (Jetzt auslösen) aus.
Überwachen der Pipelineausführung
Wechseln Sie zur Registerkarte Überwachen. Dort sehen Sie die Pipeline, die Sie im vorherigen Schritt manuell ausgelöst haben.
Wenn Sie die der Pipelineausführung zugeordneten Aktivitätsausführungen anzeigen möchten, wählen Sie unter PIPELINENAME den Link SQLServerToBlobPipeline aus.

Wenn Sie Details zum Kopiervorgang anzeigen möchten, wählen Sie auf der Seite Aktivitätsausführungen den Link „Details“ (Brillensymbol) aus. Wählen Sie oben Alle Pipelineausführungen aus, um zurück zur Ansicht mit den Pipelineausführungen zu wechseln.
Überprüfen der Ausgabe
Die Pipeline erstellt den Ausgabeordner fromonprem automatisch im Blobcontainer adftutorial. Vergewissern Sie sich, dass die Datei [pipeline().RunId].txt im Ausgabeordner enthalten ist.
Zugehöriger Inhalt
Die Pipeline in diesem Beispiel kopiert Daten in Blob Storage von einem Speicherort an einen anderen. Sie haben Folgendes gelernt:
- Erstellen einer Data Factory.
- Erstellen Sie eine selbstgehostete Integration Runtime.
- Erstellen von verknüpften SQL Server- und Storage-Diensten
- Erstellen von SQL Server- und Blob Storage-Datasets
- Erstellen einer Pipeline mit Kopieraktivität zum Verschieben der Daten
- Starten einer Pipelineausführung
- Überwachen der Pipelineausführung.
Eine Liste mit den von Data Factory unterstützten Datenspeichern finden Sie unter Unterstützte Datenspeicher und Formate.
Fahren Sie mit dem folgenden Tutorial fort, um mehr über das Kopieren von Daten per Massenvorgang aus einer Quelle in ein Ziel zu erfahren: