Inkrementelles Laden von Daten aus mehreren Tabellen in SQL Server in Azure SQL-Datenbank mithilfe von PowerShell
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Tutorial erstellen Sie eine Azure Data Factory-Instanz mit einer Pipeline, bei der Deltadaten aus mehreren Tabellen in einer SQL Server-Datenbank in Azure SQL-Datenbank geladen werden.
In diesem Tutorial führen Sie die folgenden Schritte aus:
- Vorbereiten von Quell- und Zieldatenspeichern
- Erstellen einer Data Factory.
- Erstellen Sie eine selbstgehostete Integration Runtime.
- Installieren der Integration Runtime
- Erstellen Sie verknüpfte Dienste.
- Erstellen des Quell-, Senken-, Grenzwertdatasets
- Erstellen, Ausführen und Überwachen einer Pipeline
- Überprüfen Sie die Ergebnisse.
- Hinzufügen oder Aktualisieren von Daten in Quelltabellen
- Erneutes Ausführen und Überwachen der Pipeline
- Überprüfen der Endergebnisse
Übersicht
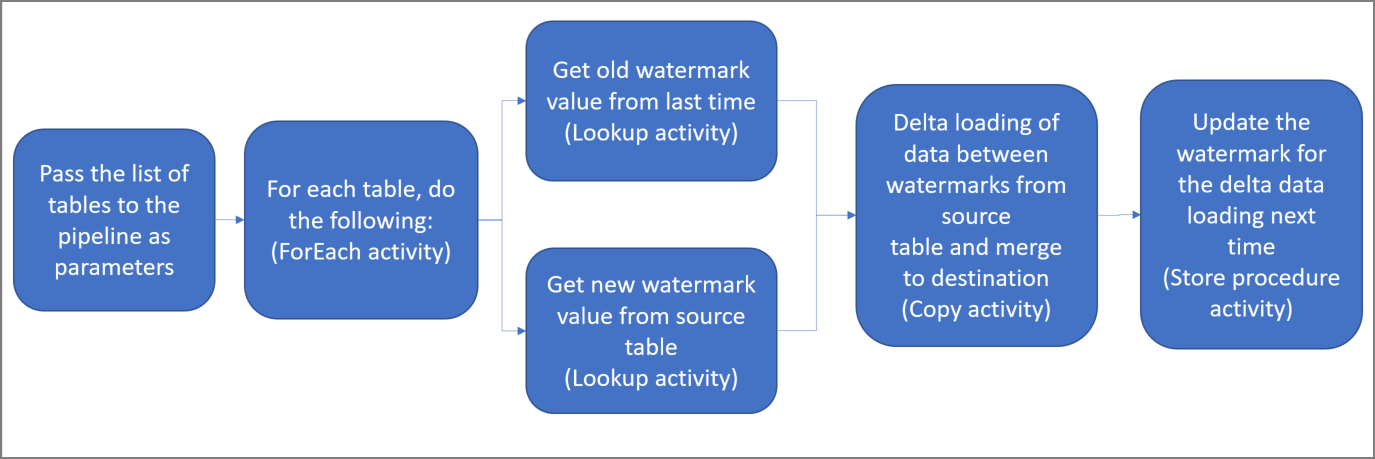
Hier sind die wesentlichen Schritte beim Erstellen dieser Lösung aufgeführt:
Select the watermark column (Wählen Sie die Grenzwert-Spalte aus) .
Wählen Sie für jede Tabelle im Quelldatenspeicher eine Spalte aus, mit der Sie die neuen oder aktualisierten Datensätze für jede Ausführung identifizieren können. Normalerweise steigen die Daten in dieser ausgewählten Spalte (z.B. Last_modify_time oder ID), wenn Zeilen erstellt oder aktualisiert werden. Der maximale Wert in dieser Spalte wird als Grenzwert verwendet.
Prepare a data store to store the watermark value (Vorbereiten eines Datenspeichers zum Speichern des Grenzwerts) .
In diesem Tutorial speichern Sie den Grenzwert in einer SQL-Datenbank.
Erstellen Sie eine Pipeline mit den folgenden Aktivitäten:
Erstellen Sie eine ForEach-Aktivität zum Durchlaufen einer Liste mit Namen von Quelltabellen, die als Parameter an die Pipeline übergeben wird. Für jede Quelltabelle werden die folgenden Aktivitäten aufgerufen, um den Deltaladevorgang für diese Tabelle durchzuführen:
Erstellen Sie zwei Lookup-Aktivitäten. Verwenden Sie die erste Lookup-Aktivität, um den letzten Grenzwert abzurufen. Verwenden Sie die zweite Lookup-Aktivität, um den neuen Grenzwert abzurufen. Diese Grenzwerte werden an die Copy-Aktivität übergeben.
Erstellen Sie eine Copy-Aktivität, die Zeilen aus dem Quelldatenspeicher kopiert, wobei der Wert der Grenzwertspalte größer als der alte Grenzwert und kleiner als der neue Grenzwert ist oder mit diesem identisch ist. Anschließend werden die Deltadaten aus dem Quelldatenspeicher als neue Datei in Azure Blob Storage kopiert.
Erstellen Sie eine StoredProcedure-Aktivität, die den Grenzwert für die Pipeline aktualisiert, die nächstes Mal ausgeführt wird.
Allgemeines Lösungsdiagramm:
Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
Voraussetzungen
- SQL Server. In diesem Tutorial verwenden Sie eine SQL Server-Datenbank als Quelldatenspeicher.
- Azure SQL-Datenbank. Sie verwenden eine Datenbank in Azure SQL-Datenbank als Senkendatenspeicher. Wenn Sie noch keine SQL-Datenbank haben, lesen Sie Erstellen einer Datenbank in Azure SQL-Datenbank. Dort finden Sie die erforderlichen Schritte zum Erstellen einer solchen Datenbank.
Erstellen von Quelltabellen in Ihrer SQL Server-Datenbank
Öffnen Sie SQL Server Management Studio (SSMS) oder Azure Data Studio, und stellen Sie eine Verbindung mit Ihrer SQL Server-Datenbank her.
Klicken Sie im Server-Explorer (SSMS) oder im Bereich „Verbindungen“ (Azure Data Studio) mit der rechten Maustaste auf die Datenbank, und wählen Sie Neue Abfrage aus.
Führen Sie den folgenden SQL-Befehl für Ihre Datenbank aus, um Tabellen mit den Namen
customer_tableundproject_tablezu erstellen:create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime ); INSERT INTO customer_table (PersonID, Name, LastModifytime) VALUES (1, 'John','9/1/2017 12:56:00 AM'), (2, 'Mike','9/2/2017 5:23:00 AM'), (3, 'Alice','9/3/2017 2:36:00 AM'), (4, 'Andy','9/4/2017 3:21:00 AM'), (5, 'Anny','9/5/2017 8:06:00 AM'); INSERT INTO project_table (Project, Creationtime) VALUES ('project1','1/1/2015 0:00:00 AM'), ('project2','2/2/2016 1:23:00 AM'), ('project3','3/4/2017 5:16:00 AM');
Erstellen von Zieltabellen in Ihrer Azure SQL-Datenbank-Instanz
Öffnen Sie SQL Server Management Studio (SSMS) oder Azure Data Studio, und stellen Sie eine Verbindung mit Ihrer SQL Server-Datenbank her.
Klicken Sie im Server-Explorer (SSMS) oder im Bereich „Verbindungen“ (Azure Data Studio) mit der rechten Maustaste auf die Datenbank, und wählen Sie Neue Abfrage aus.
Führen Sie den folgenden SQL-Befehl für Ihre Datenbank aus, um Tabellen mit den Namen
customer_tableundproject_tablezu erstellen:create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime );
Erstellen einer weiteren Tabelle in Azure SQL-Datenbank zum Speichern des hohen Grenzwerts
Führen Sie den folgenden SQL-Befehl für Ihre Datenbank aus, um eine Tabelle mit dem Namen
watermarktablezum Speichern des Grenzwerts zu erstellen:create table watermarktable ( TableName varchar(255), WatermarkValue datetime, );Fügen Sie die anfänglichen Grenzwerte für beide Quelltabellen in die Tabelle mit den Grenzwerten ein.
INSERT INTO watermarktable VALUES ('customer_table','1/1/2010 12:00:00 AM'), ('project_table','1/1/2010 12:00:00 AM');
Erstellen einer gespeicherten Prozedur in der Azure SQL-Datenbank-Instanz
Führen Sie den folgenden Befehl zum Erstellen einer gespeicherten Prozedur in Ihrer Datenbank aus. Mit dieser gespeicherten Prozedur wird der Grenzwert nach jeder Pipelineausführung aktualisiert.
CREATE PROCEDURE usp_write_watermark @LastModifiedtime datetime, @TableName varchar(50)
AS
BEGIN
UPDATE watermarktable
SET [WatermarkValue] = @LastModifiedtime
WHERE [TableName] = @TableName
END
Erstellen von Datentypen und zusätzlichen gespeicherten Prozeduren in Azure SQL-Datenbank
Führen Sie die folgende Abfrage aus, um zwei gespeicherte Prozeduren und zwei Datentypen in Ihrer Datenbank zu erstellen. Sie werden zum Zusammenführen der Daten aus Quelltabellen in Zieltabellen verwendet.
Um den Einstieg zu erleichtern, verwenden wir diese gespeicherten Prozeduren direkt. Dabei übergeben wir die Deltadaten mithilfe einer Tabellenvariablen und führen sie anschließend im Zielspeicher zusammen. In der Tabellenvariablen sollten maximal 100 Deltazeilen gespeichert werden.
Falls Sie im Zielspeicher eine große Anzahl von Deltazeilen zusammenführen möchten, empfiehlt es sich, die Deltadaten zunächst mithilfe der Kopieraktivität in eine temporäre Stagingtabelle im Zielspeicher zu kopieren und anschließen eine eigene gespeicherte Prozedur ohne Tabellenvariable zu erstellen, um die Daten aus der Stagingtabelle in der finalen Tabelle zusammenzuführen.
CREATE TYPE DataTypeforCustomerTable AS TABLE(
PersonID int,
Name varchar(255),
LastModifytime datetime
);
GO
CREATE PROCEDURE usp_upsert_customer_table @customer_table DataTypeforCustomerTable READONLY
AS
BEGIN
MERGE customer_table AS target
USING @customer_table AS source
ON (target.PersonID = source.PersonID)
WHEN MATCHED THEN
UPDATE SET Name = source.Name,LastModifytime = source.LastModifytime
WHEN NOT MATCHED THEN
INSERT (PersonID, Name, LastModifytime)
VALUES (source.PersonID, source.Name, source.LastModifytime);
END
GO
CREATE TYPE DataTypeforProjectTable AS TABLE(
Project varchar(255),
Creationtime datetime
);
GO
CREATE PROCEDURE usp_upsert_project_table @project_table DataTypeforProjectTable READONLY
AS
BEGIN
MERGE project_table AS target
USING @project_table AS source
ON (target.Project = source.Project)
WHEN MATCHED THEN
UPDATE SET Creationtime = source.Creationtime
WHEN NOT MATCHED THEN
INSERT (Project, Creationtime)
VALUES (source.Project, source.Creationtime);
END
Azure PowerShell
Installieren Sie die aktuellen Azure PowerShell-Module, indem Sie die Anweisungen unter Installieren und Konfigurieren von Azure PowerShell befolgen.
Erstellen einer Data Factory
Definieren Sie eine Variable für den Ressourcengruppennamen zur späteren Verwendung in PowerShell-Befehlen. Kopieren Sie den folgenden Befehlstext nach PowerShell, geben Sie einen Namen für die Azure-Ressourcengruppe in doppelten Anführungszeichen an, und führen Sie dann den Befehl aus. z. B.
"adfrg".$resourceGroupName = "ADFTutorialResourceGroup";Beachten Sie, dass die Ressourcengruppe ggf. nicht überschrieben werden soll, falls sie bereits vorhanden ist. Weisen Sie der Variablen
$resourceGroupNameeinen anderen Wert zu, und führen Sie den Befehl erneut aus.Definieren Sie eine Variable für den Speicherort der Data Factory.
$location = "East US"Führen Sie den folgenden Befehl aus, um die Azure-Ressourcengruppe zu erstellen:
New-AzResourceGroup $resourceGroupName $locationBeachten Sie, dass die Ressourcengruppe ggf. nicht überschrieben werden soll, falls sie bereits vorhanden ist. Weisen Sie der Variablen
$resourceGroupNameeinen anderen Wert zu, und führen Sie den Befehl erneut aus.Definieren Sie eine Variable für den Namen der Data Factory.
Wichtig
Aktualisieren Sie den Data Factory-Namen, damit er global eindeutig ist. Beispiel: ADFIncMultiCopyTutorialFactorySP1127.
$dataFactoryName = "ADFIncMultiCopyTutorialFactory";Führen Sie zum Erstellen der Data Factory das Cmdlet Set-AzDataFactoryV2 wie folgt aus:
Set-AzDataFactoryV2 -ResourceGroupName $resourceGroupName -Location $location -Name $dataFactoryName
Beachten Sie folgende Punkte:
Der Name der Data Factory muss global eindeutig sein. Wenn die folgende Fehlermeldung angezeigt wird, ändern Sie den Namen, und wiederholen Sie den Vorgang:
Set-AzDataFactoryV2 : HTTP Status Code: Conflict Error Code: DataFactoryNameInUse Error Message: The specified resource name 'ADFIncMultiCopyTutorialFactory' is already in use. Resource names must be globally unique.Damit Sie Data Factory-Instanzen erstellen können, muss das Benutzerkonto, mit dem Sie sich bei Azure anmelden, ein Mitglied der Rolle „Mitwirkender“ oder „Besitzer“ oder ein Administrator des Azure-Abonnements sein.
Eine Liste der Azure-Regionen, in denen Data Factory derzeit verfügbar ist, finden Sie, indem Sie die für Sie interessanten Regionen auf der folgenden Seite auswählen und dann Analysen erweitern, um Data Factory zu finden: Verfügbare Produkte nach Region. Die Datenspeicher (Azure Storage, SQL-Datenbank, SQL Managed Instance usw.) und Computeeinheiten (Azure HDInsight usw.), die von der Data Factory genutzt werden, können sich in anderen Regionen befinden.
Erstellen einer selbstgehosteten Integration Runtime
In diesem Abschnitt erstellen Sie eine selbstgehostete Integration Runtime und ordnen sie einem lokalen Computer mit der SQL Server-Datenbank zu. Die selbstgehostete Integration Runtime ist die Komponente, die Daten aus SQL Server auf Ihrem Computer in Azure SQL-Datenbank kopiert.
Erstellen Sie eine Variable für den Namen der Integration Runtime. Verwenden Sie einen eindeutigen Namen, und notieren Sie ihn. Sie benötigen ihn später in diesem Tutorial.
$integrationRuntimeName = "ADFTutorialIR"Erstellen Sie eine selbstgehostete Integration Runtime.
Set-AzDataFactoryV2IntegrationRuntime -Name $integrationRuntimeName -Type SelfHosted -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupNameHier ist die Beispielausgabe:
Name : <Integration Runtime name> Type : SelfHosted ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Description : Id : /subscriptions/<subscription ID>/resourceGroups/<ResourceGroupName>/providers/Microsoft.DataFactory/factories/<DataFactoryName>/integrationruntimes/ADFTutorialIRFühren Sie den folgenden Befehl aus, um den Status der erstellten Integration Runtime abzurufen. Vergewissern Sie sich, dass der Wert der Eigenschaft State auf NeedRegistration festgelegt ist.
Get-AzDataFactoryV2IntegrationRuntime -name $integrationRuntimeName -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -StatusHier ist die Beispielausgabe:
State : NeedRegistration Version : CreateTime : 9/24/2019 6:00:00 AM AutoUpdate : On ScheduledUpdateDate : UpdateDelayOffset : LocalTimeZoneOffset : InternalChannelEncryption : Capabilities : {} ServiceUrls : {eu.frontend.clouddatahub.net} Nodes : {} Links : {} Name : ADFTutorialIR Type : SelfHosted ResourceGroupName : <ResourceGroup name> DataFactoryName : <DataFactory name> Description : Id : /subscriptions/<subscription ID>/resourceGroups/<ResourceGroup name>/providers/Microsoft.DataFactory/factories/<DataFactory name>/integrationruntimes/<Integration Runtime name>Führen Sie den folgenden Befehl aus, um die Authentifizierungsschlüssel abzurufen, mit denen Sie die selbstgehostete Integration Runtime beim Azure Data Factory-Dienst in der Cloud registrieren:
Get-AzDataFactoryV2IntegrationRuntimeKey -Name $integrationRuntimeName -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName | ConvertTo-JsonHier ist die Beispielausgabe:
{ "AuthKey1": "IR@0000000000-0000-0000-0000-000000000000@xy0@xy@xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx=", "AuthKey2": "IR@0000000000-0000-0000-0000-000000000000@xy0@xy@yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy=" }Kopieren Sie einen der Schlüssel (ohne Anführungszeichen) zum Registrieren der selbstgehosteten Integration Runtime, die Sie in den nächsten Schritten auf Ihrem Computer installieren.
Installieren des Integration Runtime-Tools
Falls die Integration Runtime bereits auf Ihrem Computer installiert ist, deinstallieren Sie sie über Programme hinzufügen oder entfernen.
Führen Sie den Download der selbstgehosteten Integration Runtime auf einen lokalen Windows-Computer durch. Führen Sie die Installation aus.
Klicken Sie auf der Seite Welcome to Microsoft Integration Runtime Setup (Willkommen beim Microsoft Integration Runtime-Setup) auf Weiter.
Stimmen Sie auf der Seite mit den Microsoft-Software-Lizenzbedingungen den Bedingungen bzw. der Lizenzvereinbarung zu, und klicken Sie auf Weiter.
Klicken Sie auf der Seite Zielordner auf Weiter.
Wählen Sie auf der Seite Ready to install Microsoft Integration Runtime (Bereit für Installation der Microsoft Integration Runtime) die Option Installieren.
Klicken Sie auf der Seite Completed the Microsoft Integration Runtime Setup (Setup für Microsoft Integration Runtime abgeschlossen) auf Fertig stellen.
Fügen Sie auf der Seite Integrationslaufzeit (selbstgehostet) registrieren den Schlüssel ein, den Sie im vorherigen Abschnitt gespeichert haben, und klicken Sie auf Registrieren.
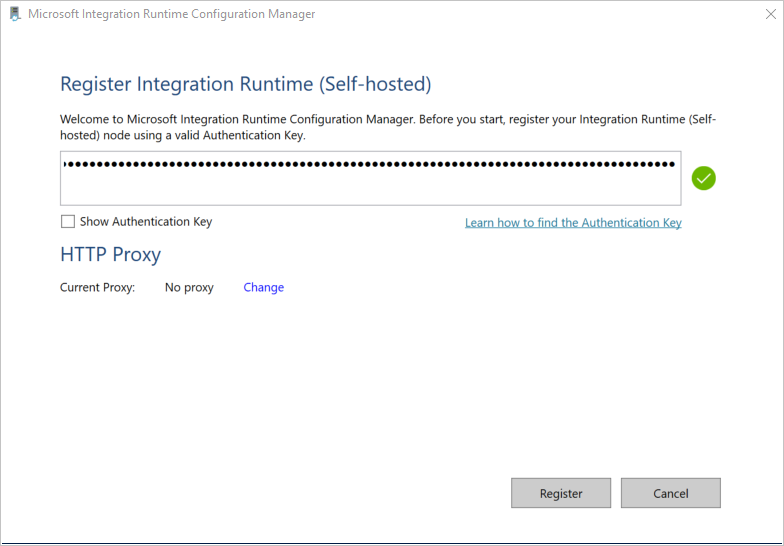
Klicken Sie auf der Seite Neuer Knoten der Integrationslaufzeit (selbstgehostet) auf Fertig stellen.
Wenn die selbstgehostete Integration Runtime erfolgreich registriert wurde, wird folgende Meldung angezeigt:
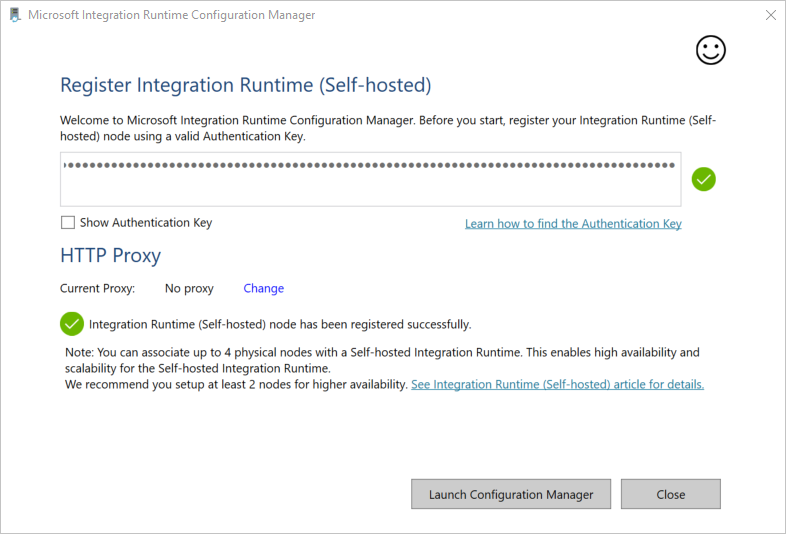
Klicken Sie auf der Seite Integrationslaufzeit (selbstgehostet) registrieren auf Konfigurations-Manager starten.
Wenn der Knoten mit dem Clouddienst verbunden ist, wird die folgende Seite angezeigt:
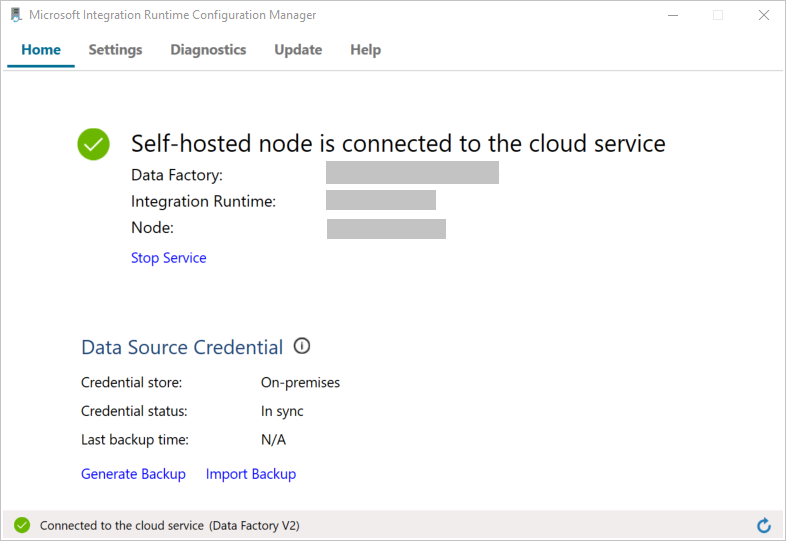
Testen Sie nun die Verbindung mit Ihrer SQL Server-Datenbank.
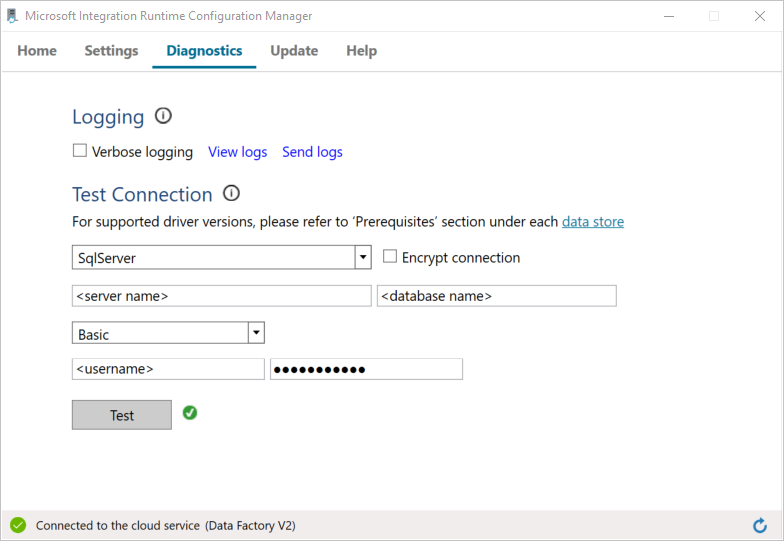
a. Wechseln Sie auf der Seite Konfigurations-Manager zur Registerkarte Diagnose.
b. Wählen Sie als Datenquellentyp die Option SqlServer.
c. Geben Sie den Servernamen ein.
d. Geben Sie den Datenbanknamen ein.
e. Wählen Sie den Authentifizierungsmodus aus.
f. Geben Sie den Benutzernamen ein.
g. Geben Sie das Kennwort ein, das dem Benutzernamen zugeordnet ist.
h. Wählen Sie die Option Test, um zu überprüfen, ob die Integration Runtime eine Verbindung mit SQL Server herstellen kann. Wenn die Verbindung erfolgreich hergestellt wurde, wird ein grünes Häkchen angezeigt. Wenn keine Verbindung hergestellt wurde, wird eine Fehlermeldung angezeigt. Beheben Sie alle Probleme, und stellen Sie sicher, dass die Integration Runtime eine Verbindung mit SQL Server herstellen kann.
Hinweis
Notieren Sie die Werte für Authentifizierungstyp, Server, Datenbank, Benutzer und Kennwort. Sie benötigen sie später in diesem Tutorial.
Erstellen von verknüpften Diensten
Um Ihre Datenspeicher und Compute Services mit der Data Factory zu verknüpfen, können Sie verknüpfte Dienste in einer Data Factory erstellen. In diesem Abschnitt erstellen Sie verknüpfte Dienste für Ihre SQL Server-Datenbank und Ihre Datenbank in Azure SQL-Datenbank.
Erstellen des mit SQL Server verknüpften Diensts
In diesem Schritt verknüpfen Sie Ihre SQL Server-Datenbank mit der Data Factory.
Erstellen Sie im Ordner „C:\ADFTutorials\IncCopyMultiTableTutorial“ (erstellen Sie die lokalen Ordner, sofern noch nicht vorhanden) eine JSON-Datei mit dem Namen SqlServerLinkedService.json mit folgendem Inhalt. Wählen Sie basierend auf der Authentifizierung, die Sie zum Herstellen einer Verbindung mit SQL Server verwenden, den richtigen Abschnitt aus.
Wichtig
Wählen Sie basierend auf der Authentifizierung, die Sie zum Herstellen einer Verbindung mit SQL Server verwenden, den richtigen Abschnitt aus.
Kopieren Sie bei Verwendung der SQL-Authentifizierung die folgende JSON-Definition:
{ "name":"SqlServerLinkedService", "properties":{ "annotations":[ ], "type":"SqlServer", "typeProperties":{ "connectionString":"integrated security=False;data source=<servername>;initial catalog=<database name>;user id=<username>;Password=<password>" }, "connectVia":{ "referenceName":"<integration runtime name>", "type":"IntegrationRuntimeReference" } } }Kopieren Sie bei Verwendung der Windows-Authentifizierung die folgende JSON-Definition:
{ "name":"SqlServerLinkedService", "properties":{ "annotations":[ ], "type":"SqlServer", "typeProperties":{ "connectionString":"integrated security=True;data source=<servername>;initial catalog=<database name>", "userName":"<username> or <domain>\\<username>", "password":{ "type":"SecureString", "value":"<password>" } }, "connectVia":{ "referenceName":"<integration runtime name>", "type":"IntegrationRuntimeReference" } } }Wichtig
- Wählen Sie basierend auf der Authentifizierung, die Sie zum Herstellen einer Verbindung mit SQL Server verwenden, den richtigen Abschnitt aus.
- Ersetzen Sie <Name der Integration Runtime> durch den Namen Ihrer Integration Runtime.
- Ersetzen Sie vor dem Speichern der Datei <servername>, <databasename>, <username> und <password> durch die Werte Ihrer SQL Server-Datenbank.
- Wenn Sie im Benutzerkonto- oder Servernamen einen Schrägstrich (
\) verwenden müssen, verwenden Sie das Escapezeichen (\). z. B.mydomain\\myuser.
Führen Sie in PowerShell das folgende Cmdlet aus, um zum Ordner „C:\ADFTutorials\IncCopyMultiTableTutorial“ zu wechseln.
Set-Location 'C:\ADFTutorials\IncCopyMultiTableTutorial'Führen Sie das Cmdlet Set-AzDataFactoryV2LinkedService aus, um den verknüpften Dienst „AzureStorageLinkedService“ zu erstellen. Im folgenden Beispiel übergeben Sie Werte für die ResourceGroupName- und DataFactoryName-Parameter:
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SqlServerLinkedService" -File ".\SqlServerLinkedService.json"Hier ist die Beispielausgabe:
LinkedServiceName : SqlServerLinkedService ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Properties : Microsoft.Azure.Management.DataFactory.Models.SqlServerLinkedService
Erstellen des mit der SQL-Datenbank verknüpften Diensts
Erstellen Sie im Ordner „C:\ADFTutorials\IncCopyMultiTableTutorial“ eine JSON-Datei mit dem Namen AzureSQLDatabaseLinkedService.json mit folgendem Inhalt. (Erstellen Sie den Ordner „ADF“, wenn er noch nicht vorhanden ist.) Ersetzen Sie „<servername>“, „<database name>“, „<user name>“ und „<password>“ durch den Namen Ihrer SQL Server-Datenbank, den Namen Ihrer Datenbank, den Benutzernamen und das Kennwort, bevor Sie die Datei speichern.
{ "name":"AzureSQLDatabaseLinkedService", "properties":{ "annotations":[ ], "type":"AzureSqlDatabase", "typeProperties":{ "connectionString":"integrated security=False;encrypt=True;connection timeout=30;data source=<servername>.database.windows.net;initial catalog=<database name>;user id=<user name>;Password=<password>;" } } }Führen Sie in PowerShell das Cmdlet Set-AzDataFactoryV2LinkedService aus, um den verknüpften Dienst „AzureSQLDatabaseLinkedService“ zu erstellen.
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "AzureSQLDatabaseLinkedService" -File ".\AzureSQLDatabaseLinkedService.json"Hier ist die Beispielausgabe:
LinkedServiceName : AzureSQLDatabaseLinkedService ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlDatabaseLinkedService
Erstellen von Datasets
In diesem Schritt erstellen Sie Datasets zur Darstellung der Datenquelle, des Datenziels und des Speicherorts des Grenzwerts.
Erstellen eines Quelldatasets
Erstellen Sie in demselben Ordner eine JSON-Datei mit dem Namen SourceDataset.json und folgendem Inhalt:
{ "name":"SourceDataset", "properties":{ "linkedServiceName":{ "referenceName":"SqlServerLinkedService", "type":"LinkedServiceReference" }, "annotations":[ ], "type":"SqlServerTable", "schema":[ ] } }Für die Copy-Aktivität in der Pipeline wird eine SQL-Abfrage zum Laden der Daten anstelle der gesamten Tabelle verwendet.
Führen Sie das Cmdlet Set-AzDataFactoryV2Dataset aus, um das Dataset „SourceDataset“ zu erstellen.
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SourceDataset" -File ".\SourceDataset.json"Hier ist die Beispielausgabe des Cmdlets:
DatasetName : SourceDataset ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.SqlServerTableDataset
Erstellen Sie ein Senkendataset
Erstellen Sie eine JSON-Datei mit dem Namen SinkDataset.json im selben Ordner und mit folgendem Inhalt. Das tableName-Element wird zur Laufzeit dynamisch von der Pipeline festgelegt. Die ForEach-Aktivität in der Pipeline durchläuft eine Liste mit Tabellennamen und übergibt den Tabellennamen bei jedem Durchlauf an dieses Dataset.
{ "name":"SinkDataset", "properties":{ "linkedServiceName":{ "referenceName":"AzureSQLDatabaseLinkedService", "type":"LinkedServiceReference" }, "parameters":{ "SinkTableName":{ "type":"String" } }, "annotations":[ ], "type":"AzureSqlTable", "typeProperties":{ "tableName":{ "value":"@dataset().SinkTableName", "type":"Expression" } } } }Führen Sie das Cmdlet Set-AzDataFactoryV2Dataset aus, um das Dataset „SinkDataset“ zu erstellen.
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SinkDataset" -File ".\SinkDataset.json"Hier ist die Beispielausgabe des Cmdlets:
DatasetName : SinkDataset ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
Erstellen eines Datasets für einen Grenzwert
In diesem Schritt erstellen Sie ein Dataset zum Speichern eines hohen Grenzwerts.
Erstellen Sie eine JSON-Datei mit dem Namen WatermarkDataset.json im selben Ordner und dem folgenden Inhalt:
{ "name": " WatermarkDataset ", "properties": { "type": "AzureSqlTable", "typeProperties": { "tableName": "watermarktable" }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" } } }Führen Sie das Cmdlet Set-AzDataFactoryV2Dataset aus, um das Dataset „WatermarkDataset“ zu erstellen.
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "WatermarkDataset" -File ".\WatermarkDataset.json"Hier ist die Beispielausgabe des Cmdlets:
DatasetName : WatermarkDataset ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
Erstellen einer Pipeline
Die Pipeline verwendet die Liste mit den Tabellennamen als Parameter. Die ForEach-Aktivität durchläuft die Liste mit den Tabellennamen und führt die folgenden Vorgänge aus:
Verwenden Sie die Lookup-Aktivität, um den alten Grenzwert abzurufen (anfänglicher Wert oder der im letzten Durchlauf verwendete Wert).
Verwenden Sie die Lookup-Aktivität, um den neuen Grenzwert abzurufen (Höchstwert der Grenzwertspalte in der Quelltabelle).
Verwenden Sie die Copy-Aktivität, um Daten zwischen diesen beiden Grenzwerten aus der Quelldatenbank in die Zieldatenbank zu kopieren.
Verwenden Sie die StoredProcedure-Aktivität, um den alten Grenzwert zu aktualisieren, damit er im ersten Schritt des nächsten Durchlaufs verwendet werden kann.
Erstellen der Pipeline
Erstellen Sie in demselben Ordner die JSON-Datei IncrementalCopyPipeline.json mit folgendem Inhalt:
{ "name":"IncrementalCopyPipeline", "properties":{ "activities":[ { "name":"IterateSQLTables", "type":"ForEach", "dependsOn":[ ], "userProperties":[ ], "typeProperties":{ "items":{ "value":"@pipeline().parameters.tableList", "type":"Expression" }, "isSequential":false, "activities":[ { "name":"LookupOldWaterMarkActivity", "type":"Lookup", "dependsOn":[ ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"AzureSqlSource", "sqlReaderQuery":{ "value":"select * from watermarktable where TableName = '@{item().TABLE_NAME}'", "type":"Expression" } }, "dataset":{ "referenceName":"WatermarkDataset", "type":"DatasetReference" } } }, { "name":"LookupNewWaterMarkActivity", "type":"Lookup", "dependsOn":[ ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"SqlServerSource", "sqlReaderQuery":{ "value":"select MAX(@{item().WaterMark_Column}) as NewWatermarkvalue from @{item().TABLE_NAME}", "type":"Expression" } }, "dataset":{ "referenceName":"SourceDataset", "type":"DatasetReference" }, "firstRowOnly":true } }, { "name":"IncrementalCopyActivity", "type":"Copy", "dependsOn":[ { "activity":"LookupOldWaterMarkActivity", "dependencyConditions":[ "Succeeded" ] }, { "activity":"LookupNewWaterMarkActivity", "dependencyConditions":[ "Succeeded" ] } ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"SqlServerSource", "sqlReaderQuery":{ "value":"select * from @{item().TABLE_NAME} where @{item().WaterMark_Column} > '@{activity('LookupOldWaterMarkActivity').output.firstRow.WatermarkValue}' and @{item().WaterMark_Column} <= '@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}'", "type":"Expression" } }, "sink":{ "type":"AzureSqlSink", "sqlWriterStoredProcedureName":{ "value":"@{item().StoredProcedureNameForMergeOperation}", "type":"Expression" }, "sqlWriterTableType":{ "value":"@{item().TableType}", "type":"Expression" }, "storedProcedureTableTypeParameterName":{ "value":"@{item().TABLE_NAME}", "type":"Expression" }, "disableMetricsCollection":false }, "enableStaging":false }, "inputs":[ { "referenceName":"SourceDataset", "type":"DatasetReference" } ], "outputs":[ { "referenceName":"SinkDataset", "type":"DatasetReference", "parameters":{ "SinkTableName":{ "value":"@{item().TABLE_NAME}", "type":"Expression" } } } ] }, { "name":"StoredProceduretoWriteWatermarkActivity", "type":"SqlServerStoredProcedure", "dependsOn":[ { "activity":"IncrementalCopyActivity", "dependencyConditions":[ "Succeeded" ] } ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "storedProcedureName":"[dbo].[usp_write_watermark]", "storedProcedureParameters":{ "LastModifiedtime":{ "value":{ "value":"@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}", "type":"Expression" }, "type":"DateTime" }, "TableName":{ "value":{ "value":"@{activity('LookupOldWaterMarkActivity').output.firstRow.TableName}", "type":"Expression" }, "type":"String" } } }, "linkedServiceName":{ "referenceName":"AzureSQLDatabaseLinkedService", "type":"LinkedServiceReference" } } ] } } ], "parameters":{ "tableList":{ "type":"array" } }, "annotations":[ ] } }Führen Sie das Cmdlet Set-AzDataFactoryV2Pipeline aus, um die Pipeline „IncrementalCopyPipeline“ zu erstellen.
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "IncrementalCopyPipeline" -File ".\IncrementalCopyPipeline.json"Hier ist die Beispielausgabe:
PipelineName : IncrementalCopyPipeline ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Activities : {IterateSQLTables} Parameters : {[tableList, Microsoft.Azure.Management.DataFactory.Models.ParameterSpecification]}
Führen Sie die Pipeline aus.
Erstellen Sie in demselben Ordner eine Parameterdatei namens Parameters.json mit folgendem Inhalt:
{ "tableList": [ { "TABLE_NAME": "customer_table", "WaterMark_Column": "LastModifytime", "TableType": "DataTypeforCustomerTable", "StoredProcedureNameForMergeOperation": "usp_upsert_customer_table" }, { "TABLE_NAME": "project_table", "WaterMark_Column": "Creationtime", "TableType": "DataTypeforProjectTable", "StoredProcedureNameForMergeOperation": "usp_upsert_project_table" } ] }Führen Sie mithilfe des Cmdlets Invoke-AzDataFactoryV2Pipeline die Pipeline „IncrementalCopyPipeline“ aus. Ersetzen Sie Platzhalter mit Ihrem eigenen Ressourcengruppen- und Data Factory-Namen.
$RunId = Invoke-AzDataFactoryV2Pipeline -PipelineName "IncrementalCopyPipeline" -ResourceGroup $resourceGroupName -dataFactoryName $dataFactoryName -ParameterFile ".\Parameters.json"
Überwachen der Pipeline
Melden Sie sich beim Azure-Portal an.
Klicken Sie auf Alle Dienste, führen Sie eine Suche mit dem Schlüsselwort Data Factorys durch, und wählen Sie Data Factorys aus.
Suchen Sie in der Liste mit den Data Factorys nach Ihrer Data Factory, und wählen Sie sie aus, um die Seite Data Factory zu öffnen.
Klicken Sie auf der Seite Data Factory auf der Kachel Open Azure Data Factory Studio (Azure Data Factory Studio öffnen) auf Öffnen, um Azure Data Factory in einer separaten Registerkarte zu starten.
Wählen Sie auf der Startseite von Azure Data Factory links Überwachung aus.
Alle Pipelineausführungen mit dem dazugehörigen Status werden angezeigt. Beachten Sie, dass der Status der Pipelineausführung im folgenden Beispiel Erfolgreich lautet. Überprüfen Sie die an die Pipeline übergebenen Parameter, indem Sie in der Spalte Parameter auf den Link klicken. Wenn ein Fehler auftritt, wird in der Spalte Fehler ein Link angezeigt.

Wenn Sie in der Spalte Aktionen den Link auswählen, werden alle Aktivitätsausführungen der Pipeline angezeigt.
Wählen Sie Alle Pipelineausführungen aus, um zurück zur Ansicht Pipelineausführungen zu wechseln.
Überprüfen der Ergebnisse
Führen Sie in SQL Server Management Studio die folgenden Abfragen für die SQL-Zieldatenbank aus, um sicherzustellen, dass die Daten aus den Quelltabellen in die Zieltabellen kopiert wurden:
Abfrage
select * from customer_table
Ausgabe
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 Alice 2017-09-03 02:36:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
Abfrage
select * from project_table
Ausgabe
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
Abfrage
select * from watermarktable
Ausgabe
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-05 08:06:00.000
project_table 2017-03-04 05:16:00.000
Beachten Sie, dass die Grenzwerte für beide Tabellen aktualisiert wurden.
Hinzufügen von weiteren Daten zu den Quelltabellen
Führen Sie die folgende Abfrage für die SQL Server-Quelldatenbank aus, um in der Kundentabelle (customer_table) eine vorhandene Zeile zu aktualisieren. Fügen Sie eine neue Zeile in die Projekttabelle (project_table) ein.
UPDATE customer_table
SET [LastModifytime] = '2017-09-08T00:00:00Z', [name]='NewName' where [PersonID] = 3
INSERT INTO project_table
(Project, Creationtime)
VALUES
('NewProject','10/1/2017 0:00:00 AM');
Erneutes Ausführen der Pipeline
Führen Sie die Pipeline jetzt erneut aus, indem Sie den folgenden PowerShell-Befehl verwenden:
$RunId = Invoke-AzDataFactoryV2Pipeline -PipelineName "IncrementalCopyPipeline" -ResourceGroup $resourceGroupname -dataFactoryName $dataFactoryName -ParameterFile ".\Parameters.json"Überwachen Sie die Pipelineausführungen, indem Sie die Anleitung im Abschnitt Überwachen der Pipeline befolgen. Wenn der Pipelinestatus In Bearbeitung lautet, wird unter Aktionen ein weiterer Aktionslink zum Abbrechen der Pipelineausführung angezeigt.
Klicken Sie auf Aktualisieren, um die Liste zu aktualisieren, bis die Pipelineausführung erfolgreich ist.
Klicken Sie optional unter Aktionen auf den Link View Activity Runs (Aktivitätsausführungen anzeigen), um alle Aktivitätsausführungen anzuzeigen, die dieser Pipelineausführung zugeordnet sind.
Überprüfen der Endergebnisse
Führen Sie in SQL Server Management Studio die folgenden Abfragen für die Zieldatenbank aus, um sicherzustellen, dass die aktualisierten bzw. neuen Daten aus den Quelltabellen in die Zieltabellen kopiert wurden.
Abfrage
select * from customer_table
Ausgabe
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 NewName 2017-09-08 00:00:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
Beachten Sie die neuen Werte in Name und LastModifytime für PersonID für Nummer 3.
Abfrage
select * from project_table
Ausgabe
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
NewProject 2017-10-01 00:00:00.000
Beachten Sie, dass der Projekttabelle (project_table) der Eintrag NewProject hinzugefügt wurde.
Abfrage
select * from watermarktable
Ausgabe
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-08 00:00:00.000
project_table 2017-10-01 00:00:00.000
Beachten Sie, dass die Grenzwerte für beide Tabellen aktualisiert wurden.
Zugehöriger Inhalt
In diesem Tutorial haben Sie die folgenden Schritte ausgeführt:
- Vorbereiten von Quell- und Zieldatenspeichern
- Erstellen einer Data Factory.
- Erstellen einer selbstgehosteten Integration Runtime (IR)
- Installieren der Integration Runtime
- Erstellen Sie verknüpfte Dienste.
- Erstellen des Quell-, Senken-, Grenzwertdatasets
- Erstellen, Ausführen und Überwachen einer Pipeline
- Überprüfen Sie die Ergebnisse.
- Hinzufügen oder Aktualisieren von Daten in Quelltabellen
- Erneutes Ausführen und Überwachen der Pipeline
- Überprüfen der Endergebnisse
Fahren Sie mit dem nächsten Tutorial fort, um zu erfahren, wie Sie mithilfe eines Spark-Clusters in Azure Daten transformieren: