Transformieren von Daten in Azure Virtual Network mithilfe einer Hive-Aktivität in Azure Data Factory mithilfe des Azure-Portals
GILT FÜR: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Tutorial verwenden Sie das Azure-Portal, um eine Data Factory-Pipeline zu erstellen, die Daten mithilfe einer Hive-Aktivität in einem HDInsight-Cluster transformiert, der sich in einem virtuellen Azure-Netzwerk (VNet) befindet. In diesem Tutorial führen Sie die folgenden Schritte aus:
- Erstellen einer Data Factory.
- Erstellen einer selbstgehosteten Integration Runtime
- Erstellen verknüpfter Azure Storage- und HDInsight-Dienste
- Erstellen einer Pipeline mit Hive-Aktivität
- Auslösen einer Pipelineausführung
- Überwachen der Pipelineausführung
- Überprüfen der Ausgabe
Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
Voraussetzungen
Hinweis
Es wird empfohlen, das Azure Az PowerShell-Modul für die Interaktion mit Azure zu verwenden. Informationen zu den ersten Schritten finden Sie unter Installieren des Azure Az PowerShell-Moduls. Informationen zum Migrieren zum Az PowerShell-Modul finden Sie unter Migrieren von Azure PowerShell von AzureRM zum Az-Modul.
Azure Storage-Konto. Erstellen Sie ein Hive-Skript, und laden Sie es in Azure Storage hoch. Die Ausgabe des Hive-Skripts wird in diesem Storage-Konto gespeichert. In diesem Beispiel verwendet der HDInsight-Cluster dieses Azure Storage-Konto als primären Speicher.
Azure Virtual Network. Wenn Sie noch nicht über ein Azure Virtual Network verfügen, erstellen Sie ein solches anhand dieser Anweisungen. In diesem Beispiel befindet sich HDInsight in einem Azure Virtual Network. Hier finden Sie die Beispielkonfiguration von Azure Virtual Network.
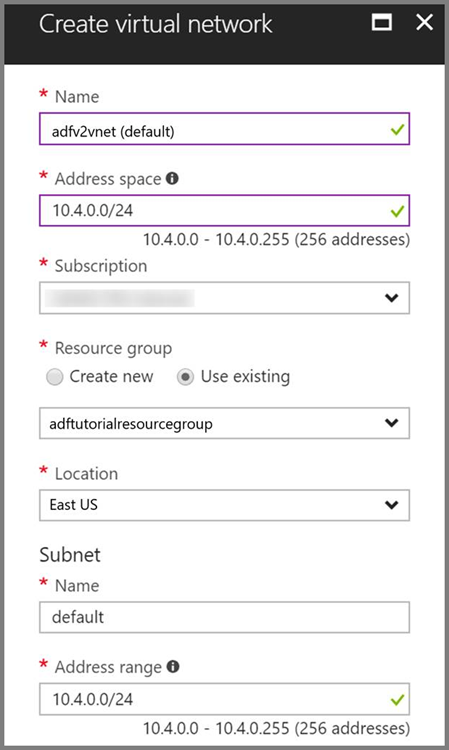
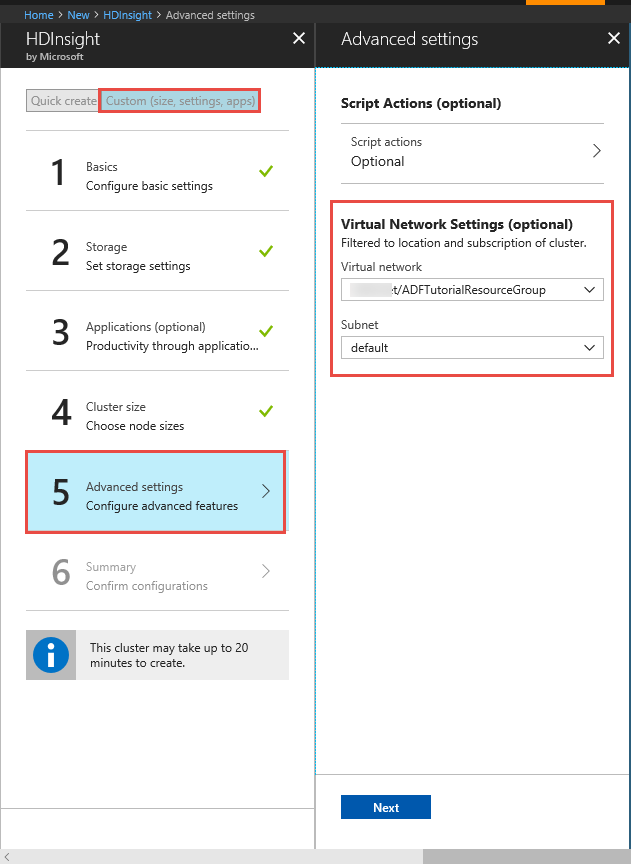
HDInsight-Cluster. Erstellen Sie einen HDInsight-Cluster, und binden Sie ihn in das virtuelle Netzwerk ein, das Sie im vorherigen Schritt erstellt haben. Befolgen Sie dazu die Anweisungen in folgendem Artikel: Erweitern von Azure HDInsight per Azure Virtual Network. Hier finden Sie die Beispielkonfiguration von HDInsight in einem virtuellen Netzwerk.
Azure PowerShell. Befolgen Sie die Anweisungen unter Get started with Azure PowerShell cmdlets (Erste Schritte mit Azure PowerShell-Cmdlets).
Ein virtueller Computer. Erstellen Sie einen virtuellen Azure-Computer, und binden Sie ihn in das virtuelle Netzwerk ein, das Ihren HDInsight-Cluster enthält. Ausführliche Informationen finden Sie unter Erstellen virtueller Computer.
Hochladen eines Hive-Skripts in Ihr Blob Storage-Konto
Erstellen Sie eine Hive SQL-Datei mit dem Namen hivescript.hql und dem folgenden Inhalt:
DROP TABLE IF EXISTS HiveSampleOut; CREATE EXTERNAL TABLE HiveSampleOut (clientid string, market string, devicemodel string, state string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '${hiveconf:Output}'; INSERT OVERWRITE TABLE HiveSampleOut Select clientid, market, devicemodel, state FROM hivesampletableErstellen Sie in Azure Blob Storage einen Container mit dem Namen adftutorial, falls dieser noch nicht vorhanden ist.
Erstellen Sie einen Ordner mit dem Namen hivescripts.
Laden Sie die Datei hivescript.hql in den Unterordner hivescripts hoch.
Erstellen einer Data Factory
Wenn Sie Ihre Data Factory noch nicht erstellt haben, befolgen Sie die Schritte im Schnellstart: Erstellen einer Data Factory mithilfe des Azure-Portals und Azure Data Factory Studio, um eine zu erstellen. Navigieren Sie nach dem Erstellen zur Data Factory im Azure-Portal.
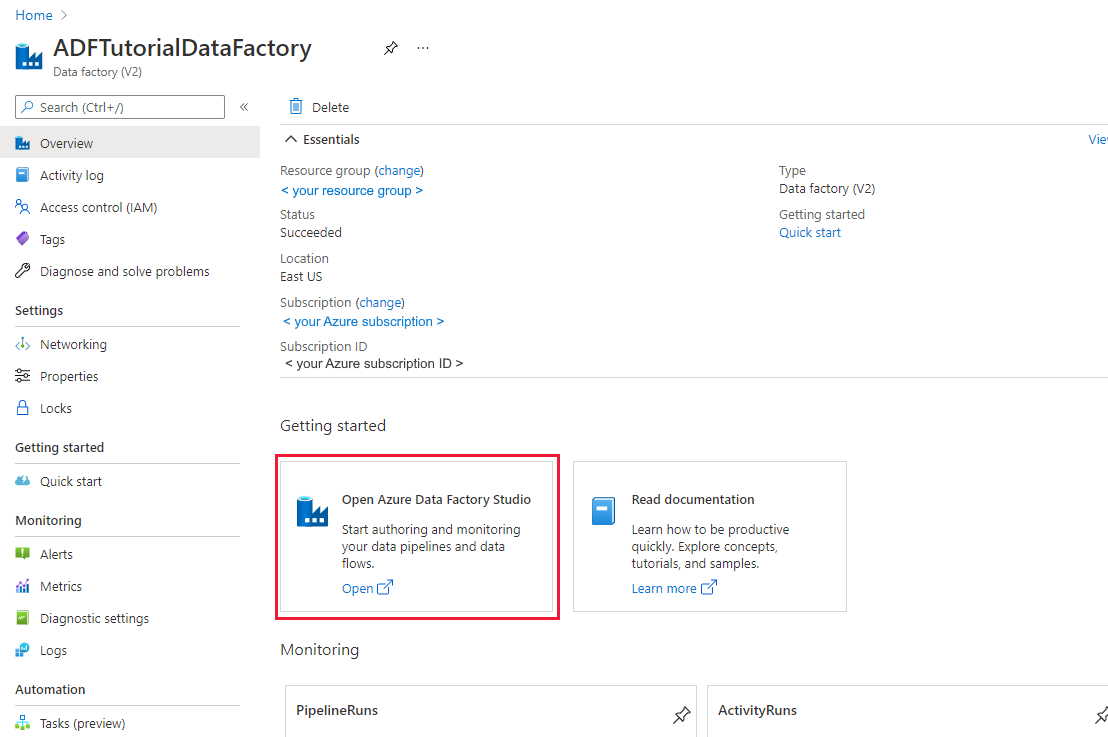
Klicken Sie auf der Kachel Open Azure Data Factory Studio auf Öffnen, um die Datenintegrationsanwendung in einer separaten Registerkarte zu starten.
Erstellen einer selbstgehosteten Integration Runtime
Da sich der Hadoop-Cluster in einem virtuellen Netzwerk befindet, müssen Sie in diesem virtuellen Netzwerk eine selbstgehostete Integration Runtime (IR) installieren. In diesem Abschnitt erstellen Sie einen neuen virtuellen Computer, binden ihn in das gleiche virtuelle Netzwerk ein und installieren eine selbstgehostete IR auf dem Computer. Mit der selbstgehosteten IR kann der Data Factory-Dienst innerhalb eines virtuellen Netzwerks Verarbeitungsanforderungen an einen Computedienst wie HDInsight verteilen. Außerdem können Sie Daten aus Datenspeichern in einem virtuellen Netzwerk nach Azure verschieben (und umgekehrt). Eine selbstgehostete IR wird verwendet, wenn sich der Datenspeicher oder die Computeressource ebenfalls in einer lokalen Umgebung befindet.
Klicken Sie auf der Azure Data Factory-Benutzeroberfläche im unteren Bereich des Fensters auf Verbindungen, wechseln Sie zur Registerkarte Integration Runtimes, und klicken Sie anschließend auf der Symbolleiste auf + Neu.
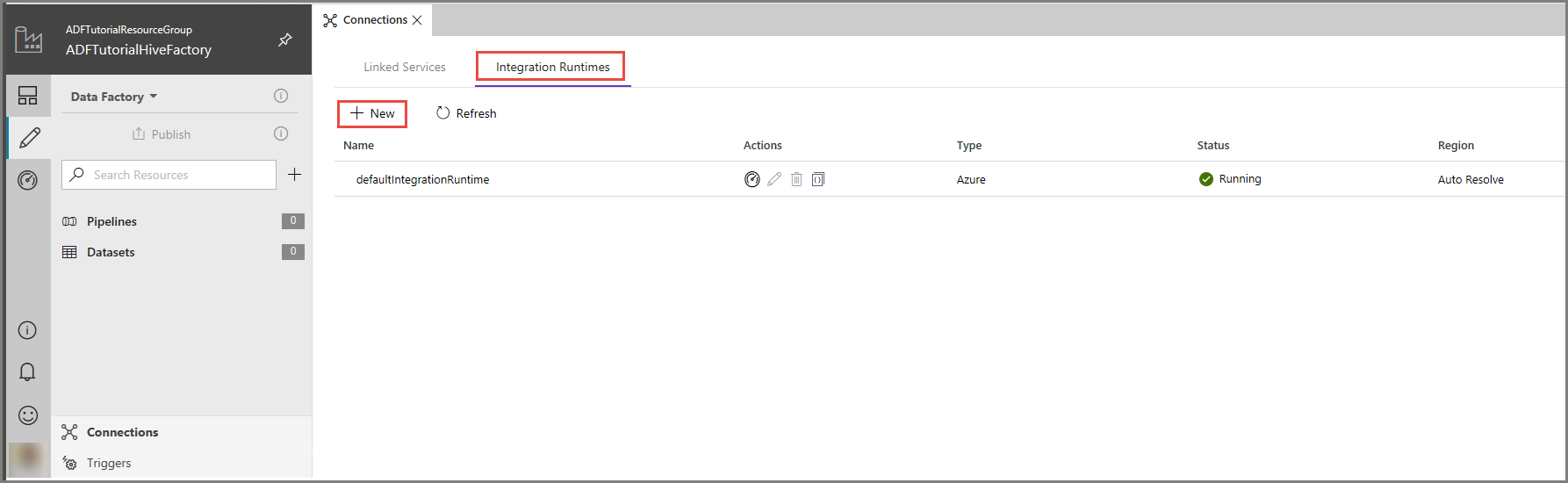
Wählen Sie im Fenster Integration Runtime Setup (Integration Runtime-Setup) die Option Perform data movement and dispatch activities to external computes (Datenverschiebung und -verteilung an externe Computeressourcen ausführen), und klicken Sie auf Weiter.
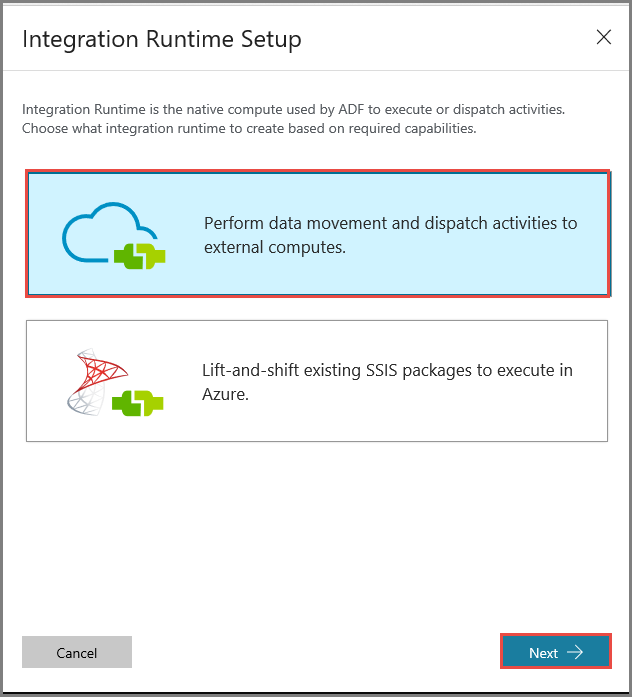
Wählen Sie Privates Netzwerk, und klicken Sie auf Weiter.
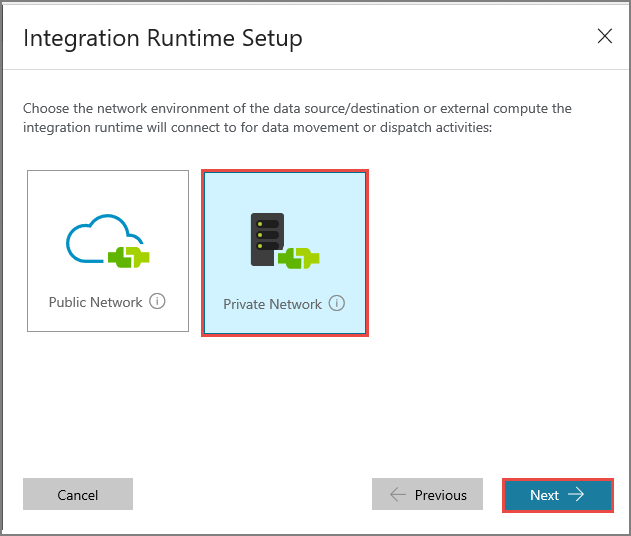
Geben Sie unter Name die Zeichenfolge MySelfHostedIR ein, und klicken Sie auf Weiter.
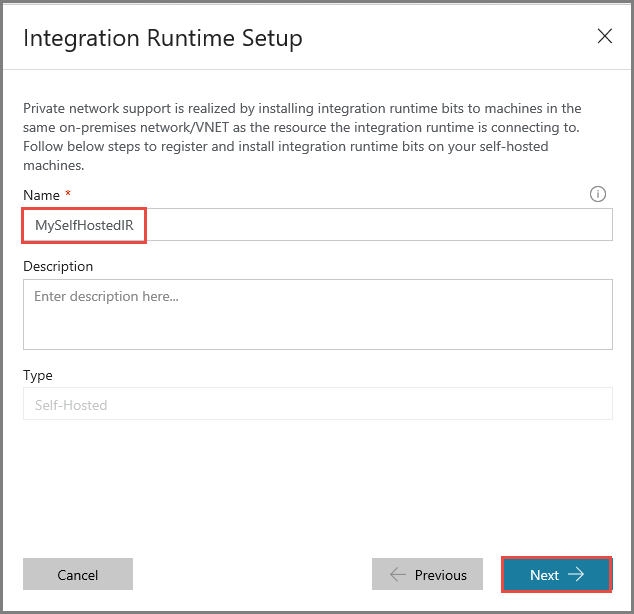
Klicken Sie auf die Kopierschaltfläche, um den Authentifizierungsschlüssel für die Integration Runtime zu kopieren, und speichern Sie ihn. Lassen Sie das Fenster geöffnet. Mit diesem Schlüssel wird die auf einem virtuellen Computer installierte IR registriert.
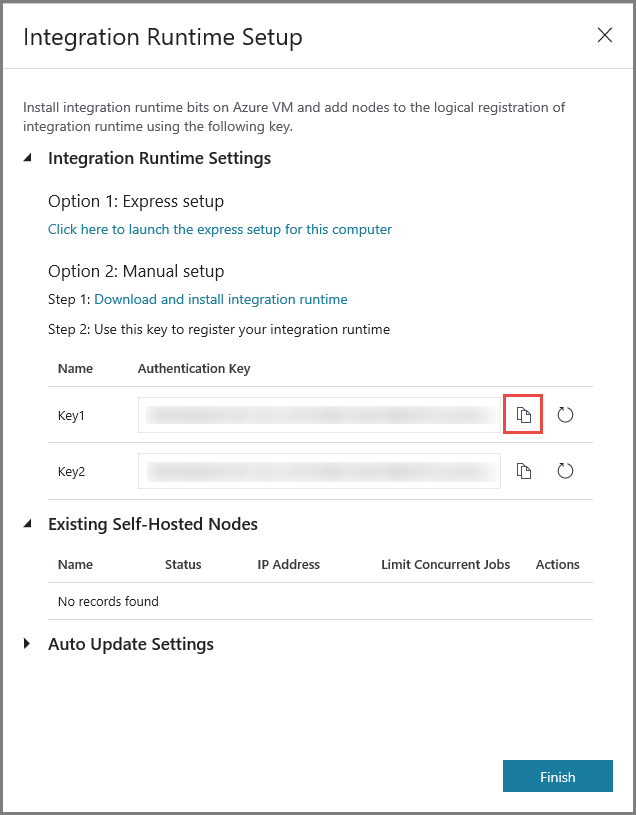
Installieren der IR auf einem virtuellen Computer
Laden Sie die selbstgehostete Integration Runtime auf den virtuellen Azure-Computer herunter. Verwenden Sie den Authentifizierungsschlüssel, den Sie im vorherigen Schritt abgerufen haben, um die selbstgehostete Integration Runtime manuell zu registrieren.
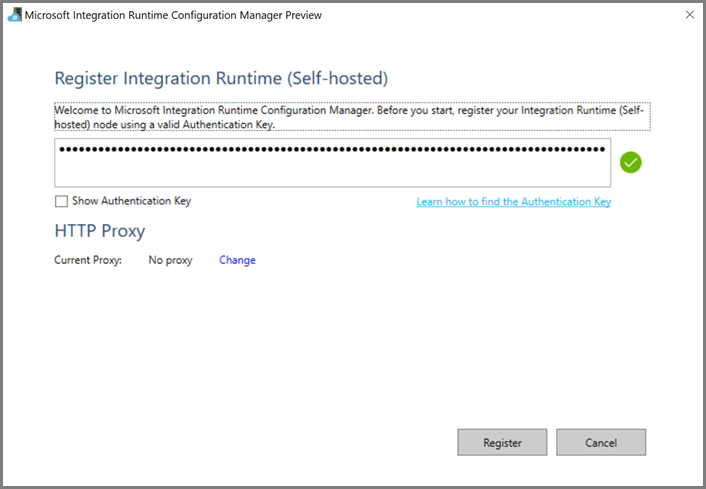
Wenn die selbstgehostete Integration Runtime erfolgreich registriert wurde, wird die folgende Meldung angezeigt:
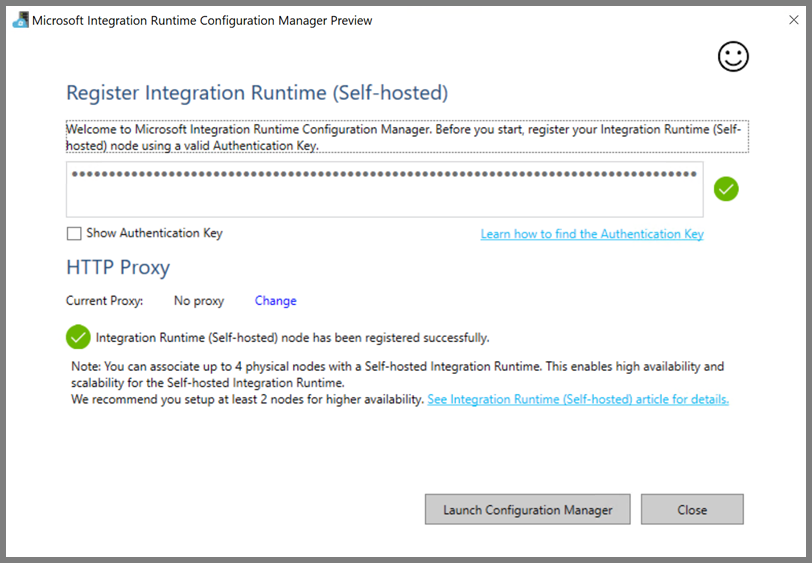
Klicken Sie auf Konfigurations-Manager starten. Folgende Seite wird angezeigt, wenn der Knoten mit dem Clouddienst verbunden ist:
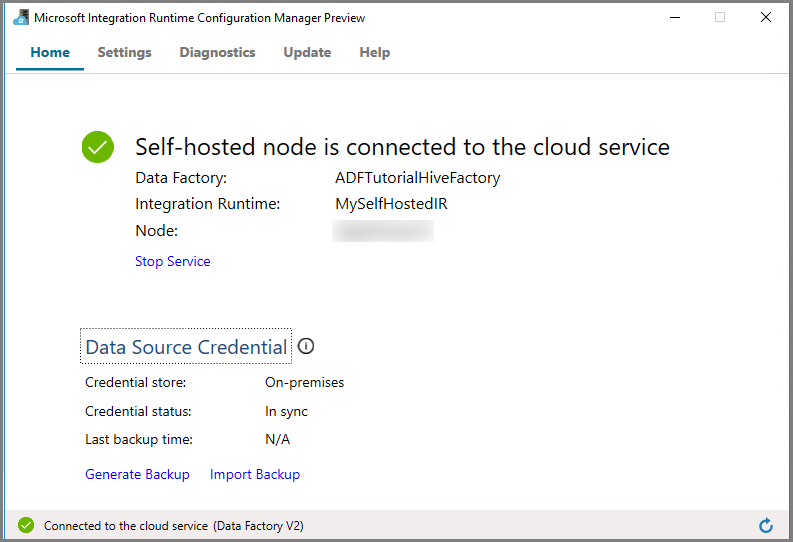
Selbstgehostete IR auf der Azure Data Factory-Benutzeroberfläche
Auf der Azure Data Factory-Benutzeroberfläche sollten der Name des selbstgehosteten virtuellen Computers sowie dessen Status angezeigt werden.
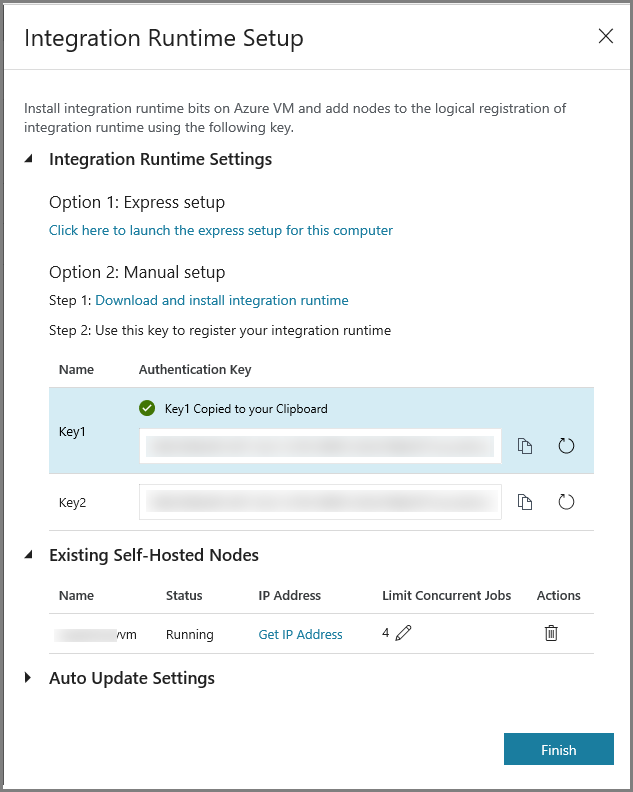
Klicken Sie auf Fertig stellen, um das Fenster Integration Runtime Setup (Integration Runtime-Setup) zu schließen. Die selbstgehostete IR wird in der Liste mit den Integration Runtimes angezeigt.

Erstellen von verknüpften Diensten
In diesem Abschnitt erstellen Sie zwei verknüpfte Dienste und stellen sie bereit:
- Einen verknüpften Azure Storage-Dienst, der ein Azure Storage-Konto mit der Data Factory verknüpft. Dies ist der primäre Speicher, der von Ihrem HDInsight-Cluster verwendet wird. In diesem Fall wird das Azure Storage-Konto zum Speichern des Hive-Skripts und der Skriptausgabe verwendet.
- Einen verknüpften HDInsight-Dienst. Azure Data Factory übermittelt das Hive-Skript zur Ausführung an diesen HDInsight-Cluster.
Erstellen des mit Azure Storage verknüpften Diensts
Wechseln Sie zur Registerkarte Verknüpfte Dienste, und klicken Sie auf Neu.
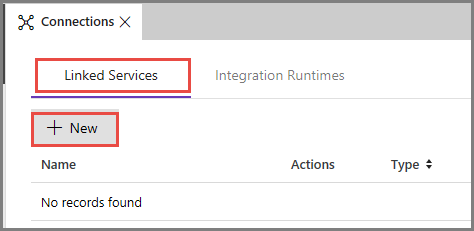
Wählen Sie im Fenster New Linked Service (Neuer verknüpfter Dienst) die Option Azure Blob Storage, und klicken Sie dann auf Weiter.
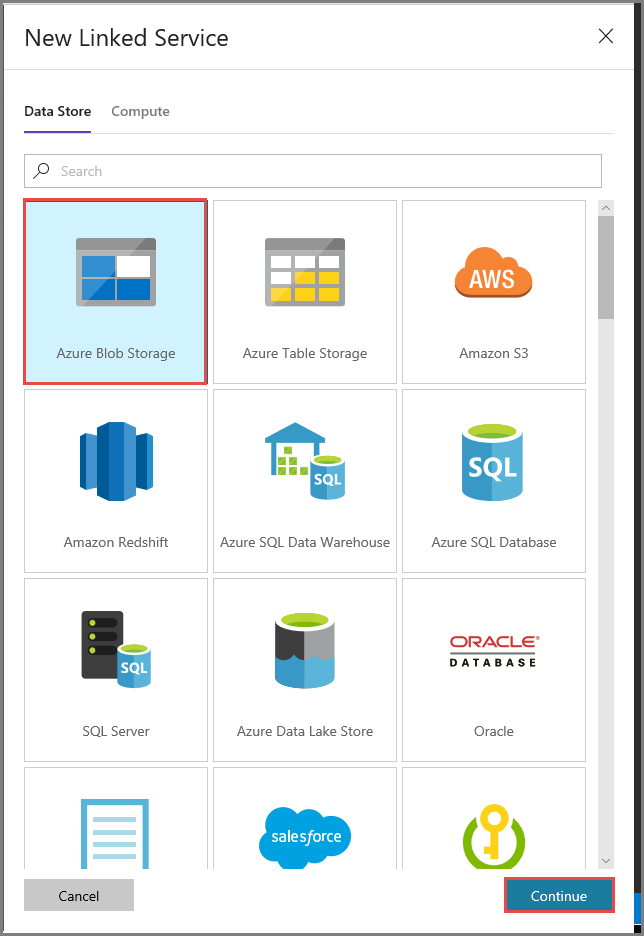
Führen Sie im Fenster New Linked Service (Neuer verknüpfter Dienst) die folgenden Schritte aus:
Geben Sie unter Name die Zeichenfolge AzureStorageLinkedService ein.
Wählen Sie unter Connect via integration runtime (Verbindung per Integration Runtime herstellen) die Option MySelfHostedIR aus.
Wählen Sie unter Speicherkontoname Ihr Azure-Speicherkonto aus.
Klicken Sie auf Verbindung testen, um die Verbindung mit dem Speicherkonto zu testen.
Klicken Sie auf Speichern.
Erstellen eines verknüpften HDInsight-Diensts
Klicken Sie erneut auf Neu, um einen weiteren verknüpften Dienst zu erstellen.
Wechseln Sie zur Registerkarte Compute, wählen Sie Azure HDInsight aus, und klicken Sie anschließend auf Weiter.
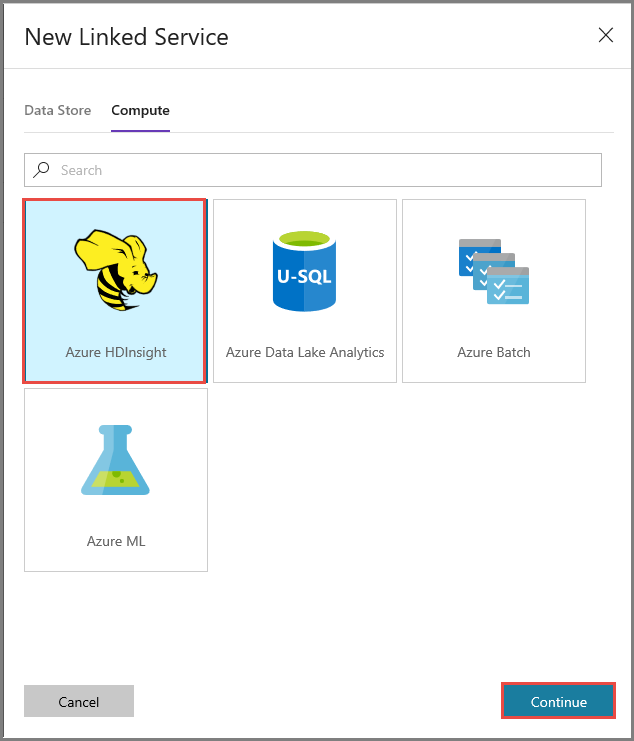
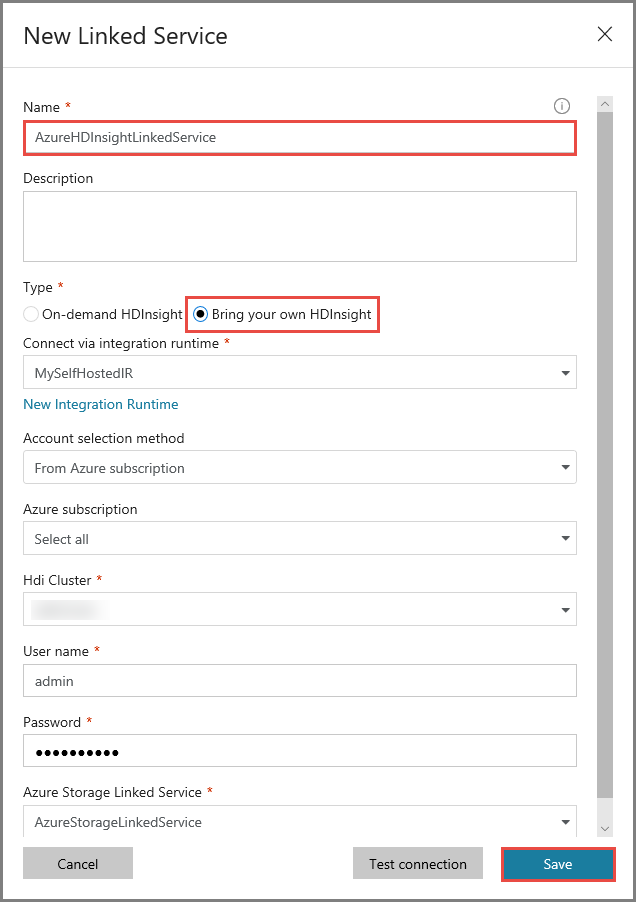
Führen Sie im Fenster New Linked Service (Neuer verknüpfter Dienst) die folgenden Schritte aus:
Geben Sie unter Name die Zeichenfolge AzureHDInsightLinkedService ein.
Wählen Sie Bring your own HDInsight (Eigenes HDInsight verwenden) aus.
Wählen Sie unter Hdi cluster (HDI-Cluster) Ihren HDInsight-Cluster aus.
Geben Sie unter Benutzername den Benutzernamen für den HDInsight-Cluster ein.
Geben Sie das Kennwort für den Benutzer ein.
In diesem Artikel wird davon ausgegangen, dass Sie über das Internet auf den Cluster zugreifen können. Sie müssen z.B. unter https://clustername.azurehdinsight.net eine Verbindung mit dem Cluster herstellen können. Diese Adresse verwendet das öffentliche Gateway, das nicht verfügbar ist, wenn Sie über Netzwerksicherheitsgruppen (Network Security Groups, NSGs) oder benutzerdefinierte Routen (User-Defined Routes, UDRs) den Zugriff aus dem Internet beschränken. Damit Data Factory Aufträge an den HDInsight-Cluster in Ihrem Azure Virtual Network übermitteln kann, müssen Sie das Netzwerk so konfigurieren, dass die URL in die private IP-Adresse des von HDInsight verwendeten Gateways aufgelöst werden kann.
Öffnen Sie im Azure-Portal das virtuelle Netzwerk, in dem sich HDInsight befindet. Öffnen Sie die Netzwerkschnittstelle, deren Name mit
nic-gateway-0beginnt. Notieren Sie die private IP-Adresse. Beispiel: 10.6.0.15.Wenn in Ihrem Azure Virtual Network DNS-Server vorhanden sind, aktualisieren Sie den DNS-Eintrag, sodass die URL des HDInsight-Clusters,
https://<clustername>.azurehdinsight.net, in10.6.0.15aufgelöst werden kann. Wenn in Ihrem virtuellen Azure-Netzwerk kein DNS-Server vorhanden ist, können Sie dieses Problem vorübergehend umgehen, indem Sie die Hostdatei (C:\Windows\System32\drivers\etc) aller virtuellen Computer bearbeiten, die als Knoten für die selbstgehostete Integration Runtime registriert sind. Fügen Sie hierzu einen Eintrag wie den folgenden hinzu:10.6.0.15 myHDIClusterName.azurehdinsight.net
Erstellen einer Pipeline
In diesem Schritt erstellen Sie eine neue Pipeline mit einer Hive-Aktivität. Die Aktivität führt ein Hive-Skript aus, um Daten aus einer Beispieltabelle zurückzugeben und in einem von Ihnen definierten Pfad zu speichern.
Beachten Sie folgende Punkte:
- scriptPath zeigt auf den Pfad zu dem Hive-Skript im Azure Storage-Konto, das Sie für „MyStorageLinkedService“ verwendet haben. Der Pfad berücksichtigt die Groß- und Kleinschreibung.
- Output ist ein im Hive-Skript verwendetes Argument. Verwenden Sie das Format
wasbs://<Container>@<StorageAccount>.blob.core.windows.net/outputfolder/, um auf einen vorhandenen Ordner in Ihrem Azure Storage zu zeigen. Der Pfad berücksichtigt die Groß- und Kleinschreibung.
Klicken Sie im linken Bereich der Data Factory-Benutzeroberfläche auf + (Pluszeichen) und dann auf Pipeline.
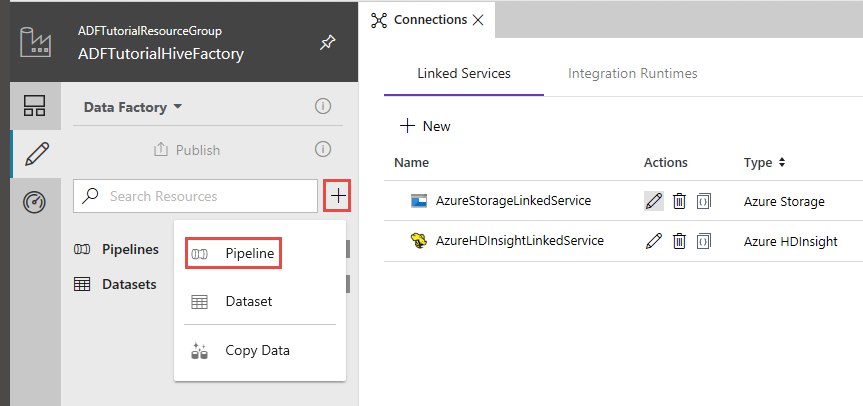
Erweitern Sie in der Toolbox Aktivitäten die Option HDInsight, und ziehen Sie die Aktivität Hive auf die Oberfläche des Pipeline-Designers.

Wechseln Sie im Eigenschaftenfenster zur Registerkarte HDI-Cluster, und wählen Sie unter HDInsight Linked Service (Verknüpfter HDInsight-Dienst) die Option AzureHDInsightLinkedService aus.

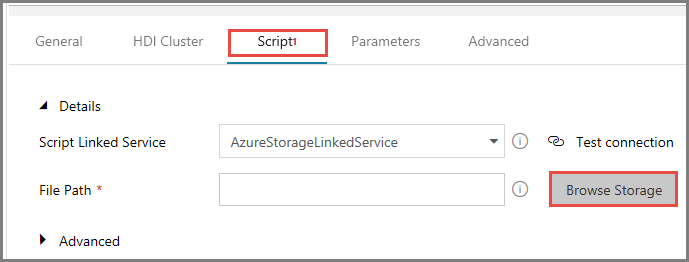
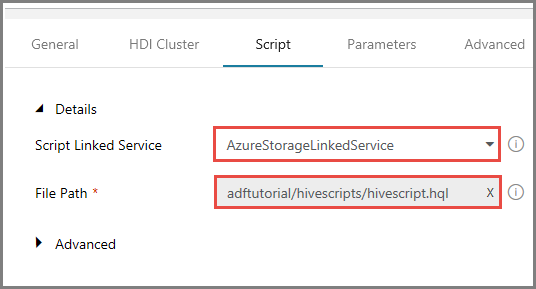
Wechseln Sie zur Registerkarte Skripts, und führen Sie die folgenden Schritte aus:
Wählen Sie unter Mit dem Skript verknüpfter Dienst die Option AzureStorageLinkedService aus.
Klicken Sie unter Dateipfad auf Speicher durchsuchen.
Navigieren Sie im Fenster Choose a file or folder (Datei oder Ordner auswählen) zum Ordner hivescripts des Containers adftutorial, wählen Sie die Datei hivescript.hql aus, und klicken Sie auf Fertig stellen.
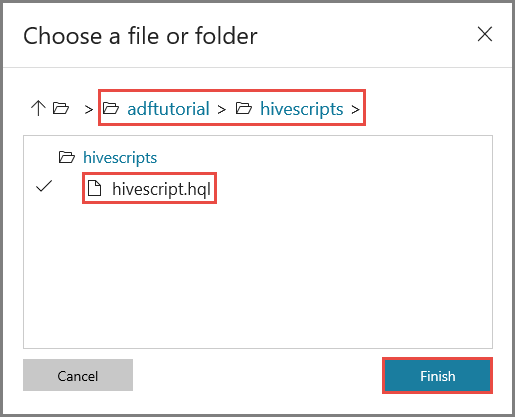
Vergewissern Sie sich, dass Dateipfad die Zeichenfolge adftutorial/hivescripts/hivescript.hql enthält.
Erweitern Sie auf der Registerkarte Skript den Abschnitt Erweitert.
Klicken Sie unter Parameter auf Auto-fill from script (Automatisch anhand des Skripts ausfüllen).
Geben Sie den Wert für den Parameter Ausgabe im folgenden Format ein:
wasbs://<Blob Container>@<StorageAccount>.blob.core.windows.net/outputfolder/. Beispiel:wasbs://adftutorial@mystorageaccount.blob.core.windows.net/outputfolder/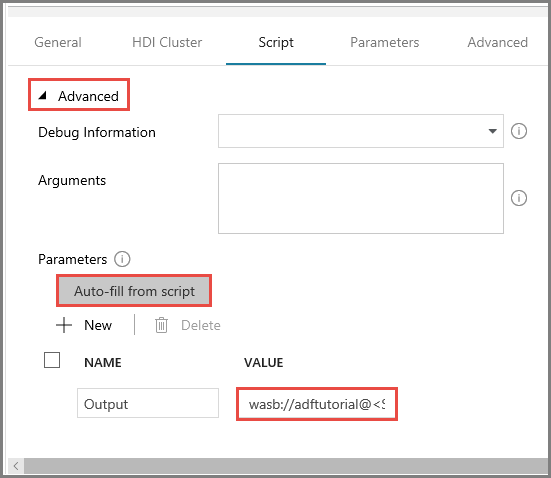
Klicken Sie auf Veröffentlichen, um Artefakte für Data Factory zu veröffentlichen.
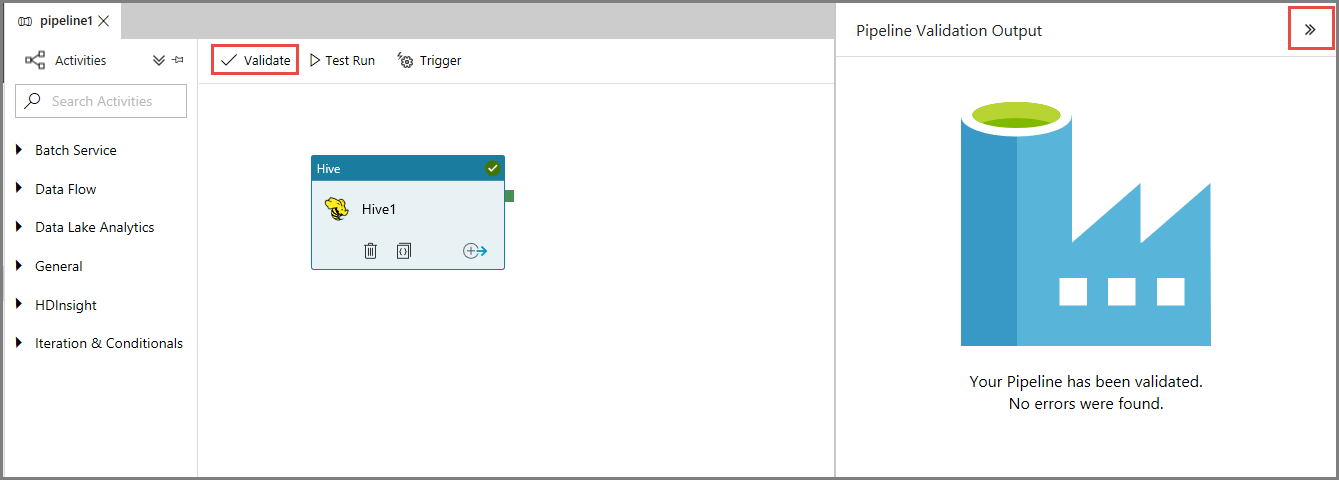
Auslösen einer Pipelineausführung
Klicken Sie zum Überprüfen der Pipeline zunächst auf der Symbolleiste auf die Schaltfläche Überprüfen. Klicken Sie auf >> (Pfeil nach rechts), um das Fenster mit der Ausgabe der Pipelineüberprüfung zu schließen.
Klicken Sie auf der Symbolleiste auf „Trigger“ und anschließend auf „Trigger Now“ (Jetzt auslösen), um eine Pipelineausführung auszulösen.

Überwachen der Pipelineausführung
Wechseln Sie im linken Bereich zur Registerkarte Überwachen. In der Liste mit den Pipelineausführungen wird eine Pipelineausführung angezeigt.
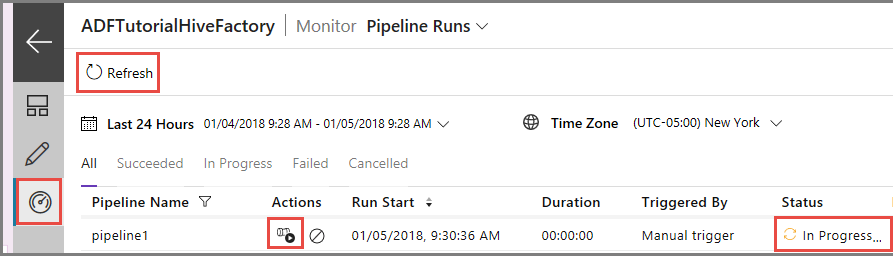
Klicken Sie zum Aktualisieren der Liste auf Aktualisieren.
Wenn Sie mit der Pipelineausführung verknüpfte Aktivitätsausführungen anzeigen möchten, klicken Sie in der Spalte Aktionen auf View activity runs (Aktivitätsausführungen anzeigen). Andere Aktionslinks dienen zum Beenden/erneuten Ausführen der Pipeline.
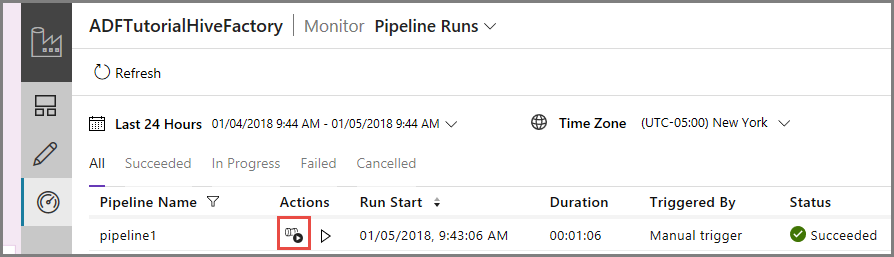
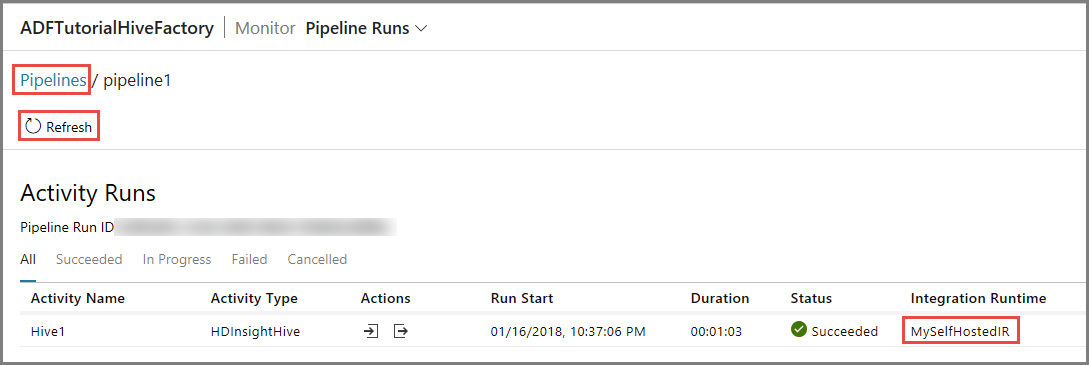
Da die Pipeline nur eine einzelne Aktivität vom Typ HDInsightHive enthält, wird nur eine einzelne Aktivitätsausführung angezeigt. Klicken Sie im oberen Bereich auf den Link Pipelines, um zur vorherigen Ansicht zurückzukehren.
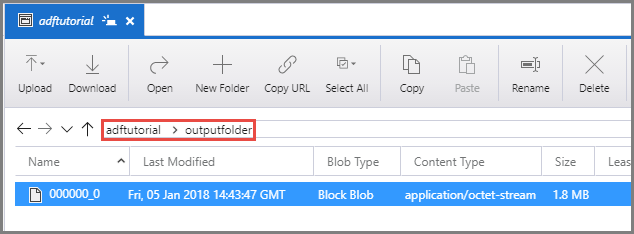
Vergewissern Sie sich, dass im Ausgabeordner (outputfolder) des Containers adftutorial eine Ausgabedatei angezeigt wird.
Zugehöriger Inhalt
In diesem Tutorial haben Sie die folgenden Schritte ausgeführt:
- Erstellen einer Data Factory.
- Erstellen einer selbstgehosteten Integration Runtime
- Erstellen verknüpfter Azure Storage- und HDInsight-Dienste
- Erstellen einer Pipeline mit Hive-Aktivität
- Auslösen einer Pipelineausführung
- Überwachen der Pipelineausführung
- Überprüfen der Ausgabe
Fahren Sie mit dem nächsten Tutorial fort, um zu erfahren, wie Sie mithilfe eines Spark-Clusters in Azure Daten transformieren: