Source transformation in mapping data flows
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
Data flows are available both in Azure Data Factory and Azure Synapse Pipelines. This article applies to mapping data flows. If you are new to transformations, please refer to the introductory article Transform data using a mapping data flow.
A source transformation configures your data source for the data flow. When you design data flows, your first step is always configuring a source transformation. To add a source, select the Add Source box in the data flow canvas.
Every data flow requires at least one source transformation, but you can add as many sources as necessary to complete your data transformations. You can join those sources together with a join, lookup, or a union transformation.
Each source transformation is associated with exactly one dataset or linked service. The dataset defines the shape and location of the data you want to write to or read from. If you use a file-based dataset, you can use wildcards and file lists in your source to work with more than one file at a time.
Inline datasets
The first decision you make when you create a source transformation is whether your source information is defined inside a dataset object or within the source transformation. Most formats are available in only one or the other. To learn how to use a specific connector, see the appropriate connector document.
When a format is supported for both inline and in a dataset object, there are benefits to both. Dataset objects are reusable entities that can be used in other data flows and activities such as Copy. These reusable entities are especially useful when you use a hardened schema. Datasets aren't based in Spark. Occasionally, you might need to override certain settings or schema projection in the source transformation.
Inline datasets are recommended when you use flexible schemas, one-off source instances, or parameterized sources. If your source is heavily parameterized, inline datasets allow you to not create a "dummy" object. Inline datasets are based in Spark, and their properties are native to data flow.
To use an inline dataset, select the format you want in the Source type selector. Instead of selecting a source dataset, you select the linked service you want to connect to.
Schema options
Because an inline dataset is defined inside the data flow, there isn't a defined schema associated with the inline dataset. On the Projection tab, you can import the source data schema and store that schema as your source projection. On this tab, you find a "Schema options" button that allows you to define the behavior of ADF's schema discovery service.
- Use projected schema: This option is useful when you have a large number of source files that ADF scans as your source. ADF's default behavior is to discover the schema of every source file. But if you have a pre-defined projection already stored in your source transformation, you can set this to true and ADF skips auto-discovery of every schema. With this option turned on, the source transformation can read all files in a much faster manner, applying the pre-defined schema to every file.
- Allow schema drift: Turn on schema drift so that your data flow allows new columns that aren't already defined in the source schema.
- Validate schema: Setting this option causes the data flow to fail if any column and type defined in the projection doesn't match the discovered schema of the source data.
- Infer drifted column types: When new drifted columns are identified by ADF, those new columns are cast to the appropriate data type using ADF's automatic type inference.

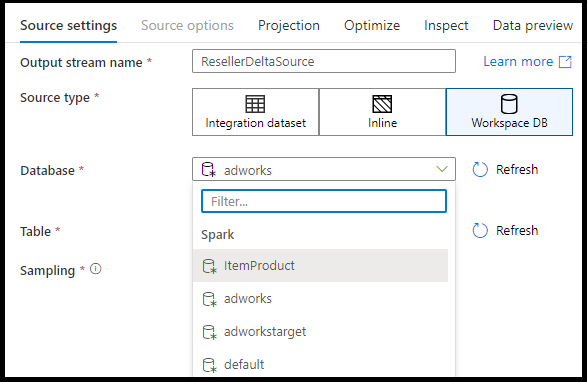
Workspace DB (Synapse workspaces only)
In Azure Synapse workspaces, an additional option is present in data flow source transformations called Workspace DB. This allows you to directly pick a workspace database of any available type as your source data without requiring additional linked services or datasets. The databases created through the Azure Synapse database templates are also accessible when you select Workspace DB.
Supported source types
Mapping data flow follows an extract, load, and transform (ELT) approach and works with staging datasets that are all in Azure. Currently, the following datasets can be used in a source transformation.
| Connector | Format | Dataset/inline |
|---|---|---|
| Amazon S3 | Avro Delimited text Delta Excel JSON ORC Parquet XML |
✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ |
| Appfigures (Preview) | -/✓ | |
| Asana (Preview) | -/✓ | |
| Azure Blob Storage | Avro Delimited text Delta Excel JSON ORC Parquet XML |
✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ |
| Azure Cosmos DB for NoSQL | ✓/- | |
| Azure Data Lake Storage Gen1 | Avro Delimited text Excel JSON ORC Parquet XML |
✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ |
| Azure Data Lake Storage Gen2 | Avro Common Data Model Delimited text Delta Excel JSON ORC Parquet XML |
✓/✓ -/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ |
| Azure Database for MySQL | ✓/✓ | |
| Azure Database for PostgreSQL | ✓/✓ | |
| Azure Data Explorer | ✓/✓ | |
| Azure SQL Database | ✓/✓ | |
| Azure SQL Managed Instance | ✓/✓ | |
| Azure Synapse Analytics | ✓/✓ | |
| data.world (Preview) | -/✓ | |
| Dataverse | ✓/✓ | |
| Dynamics 365 | ✓/✓ | |
| Dynamics CRM | ✓/✓ | |
| Google Sheets (Preview) | -/✓ | |
| Hive | -/✓ | |
| Quickbase (Preview) | -/✓ | |
| SFTP | Avro Delimited text Excel JSON ORC Parquet XML |
✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ |
| Smartsheet (Preview) | -/✓ | |
| Snowflake | ✓/✓ | |
| SQL Server | ✓/✓ | |
| REST | ✓/✓ | |
| TeamDesk (Preview) | -/✓ | |
| Twilio (Preview) | -/✓ | |
| Zendesk (Preview) | -/✓ |
Settings specific to these connectors are located on the Source options tab. Information and data flow script examples on these settings are located in the connector documentation.
Azure Data Factory and Synapse pipelines have access to more than 90 native connectors. To include data from those other sources in your data flow, use the Copy Activity to load that data into one of the supported staging areas.
Source settings
After you've added a source, configure via the Source settings tab. Here you can pick or create the dataset your source points at. You can also select schema and sampling options for your data.
Development values for dataset parameters can be configured in debug settings. (Debug mode must be turned on.)

Output stream name: The name of the source transformation.
Source type: Choose whether you want to use an inline dataset or an existing dataset object.
Test connection: Test whether or not the data flow's Spark service can successfully connect to the linked service used in your source dataset. Debug mode must be on for this feature to be enabled.
Schema drift: Schema drift is the ability of the service to natively handle flexible schemas in your data flows without needing to explicitly define column changes.
Select the Allow schema drift check box if the source columns change often. This setting allows all incoming source fields to flow through the transformations to the sink.
Selecting Infer drifted column types instructs the service to detect and define data types for each new column discovered. With this feature turned off, all drifted columns are of type string.
Validate schema: If Validate schema is selected, the data flow fails to run if the incoming source data doesn't match the defined schema of the dataset.
Skip line count: The Skip line count field specifies how many lines to ignore at the beginning of the dataset.
Sampling: Enable Sampling to limit the number of rows from your source. Use this setting when you test or sample data from your source for debugging purposes. This is very useful when executing data flows in debug mode from a pipeline.
To validate your source is configured correctly, turn on debug mode and fetch a data preview. For more information, see Debug mode.
Note
When debug mode is turned on, the row limit configuration in debug settings overwrite the sampling setting in the source during data preview.
Source options
The Source options tab contains settings specific to the connector and format chosen. For more information and examples, see the relevant connector documentation. This includes details like isolation level for those data sources that support it (like on-premises SQL Servers, Azure SQL Databases, and Azure SQL Managed instances), and other data source specific settings as well.
Projection
Like schemas in datasets, the projection in a source defines the data columns, types, and formats from the source data. For most dataset types, such as SQL and Parquet, the projection in a source is fixed to reflect the schema defined in a dataset. When your source files aren't strongly typed (for example, flat .csv files rather than Parquet files), you can define the data types for each field in the source transformation.
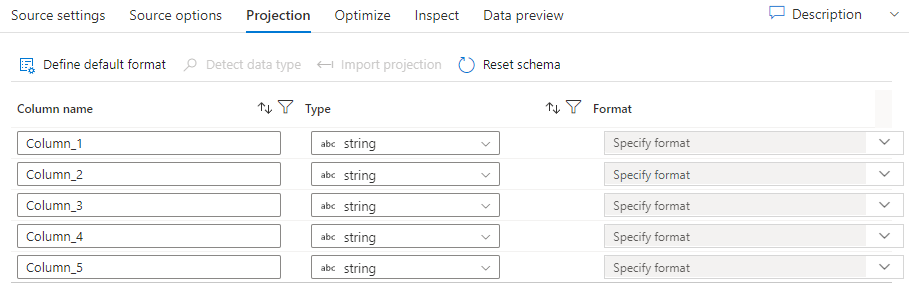
If your text file has no defined schema, select Detect data type so that the service samples and infers the data types. Select Define default format to autodetect the default data formats.
Reset schema resets the projection to what is defined in the referenced dataset.
Overwrite schema allows you to modify the projected data types here the source, overwriting the schema-defined data types. You can alternatively modify the column data types in a downstream derived-column transformation. Use a select transformation to modify the column names.
Import schema
Select the Import schema button on the Projection tab to use an active debug cluster to create a schema projection. It's available in every source type. Importing the schema here overrides the projection defined in the dataset. The dataset object won't be changed.
Importing schema is useful in datasets like Avro and Azure Cosmos DB that support complex data structures that don't require schema definitions to exist in the dataset. For inline datasets, importing schema is the only way to reference column metadata without schema drift.
Optimize the source transformation
The Optimize tab allows for editing of partition information at each transformation step. In most cases, Use current partitioning optimizes for the ideal partitioning structure for a source.
If you're reading from an Azure SQL Database source, custom Source partitioning likely reads data the fastest. The service reads large queries by making connections to your database in parallel. This source partitioning can be done on a column or by using a query.
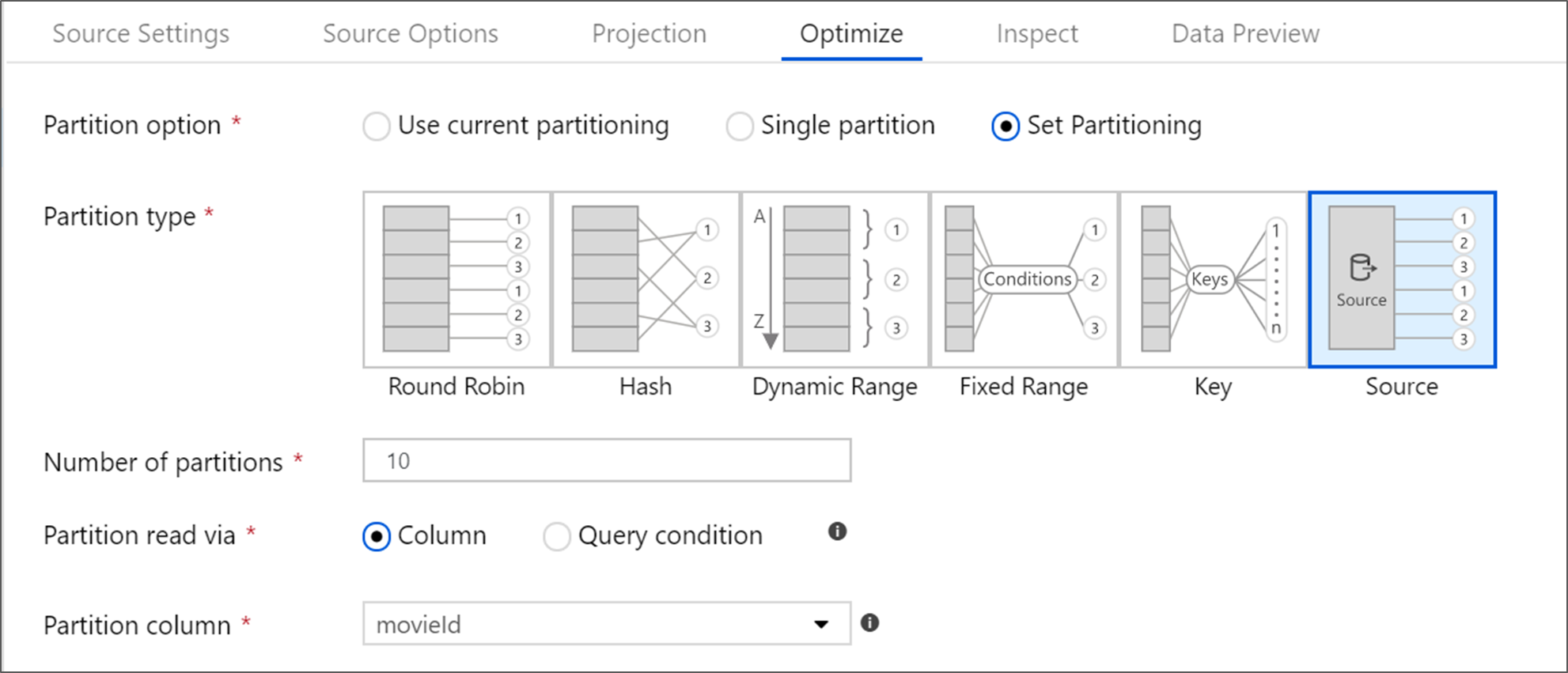
For more information on optimization within mapping data flow, see the Optimize tab.
Related content
Begin building your data flow with a derived-column transformation and a select transformation.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for