Important
This article provides information on using the Azure Machine Learning SDK v1. The SDK v1 is deprecated as of March 31, 2025 and support for it will end on June 30, 2026. You're able to install and use the SDK v1 until that date.
We recommend that you transition to the SDK v2 before June 30, 2026. For more information on the SDK v2, see What is the Azure Machine Learning Python SDK v2 and the SDK v2 reference.
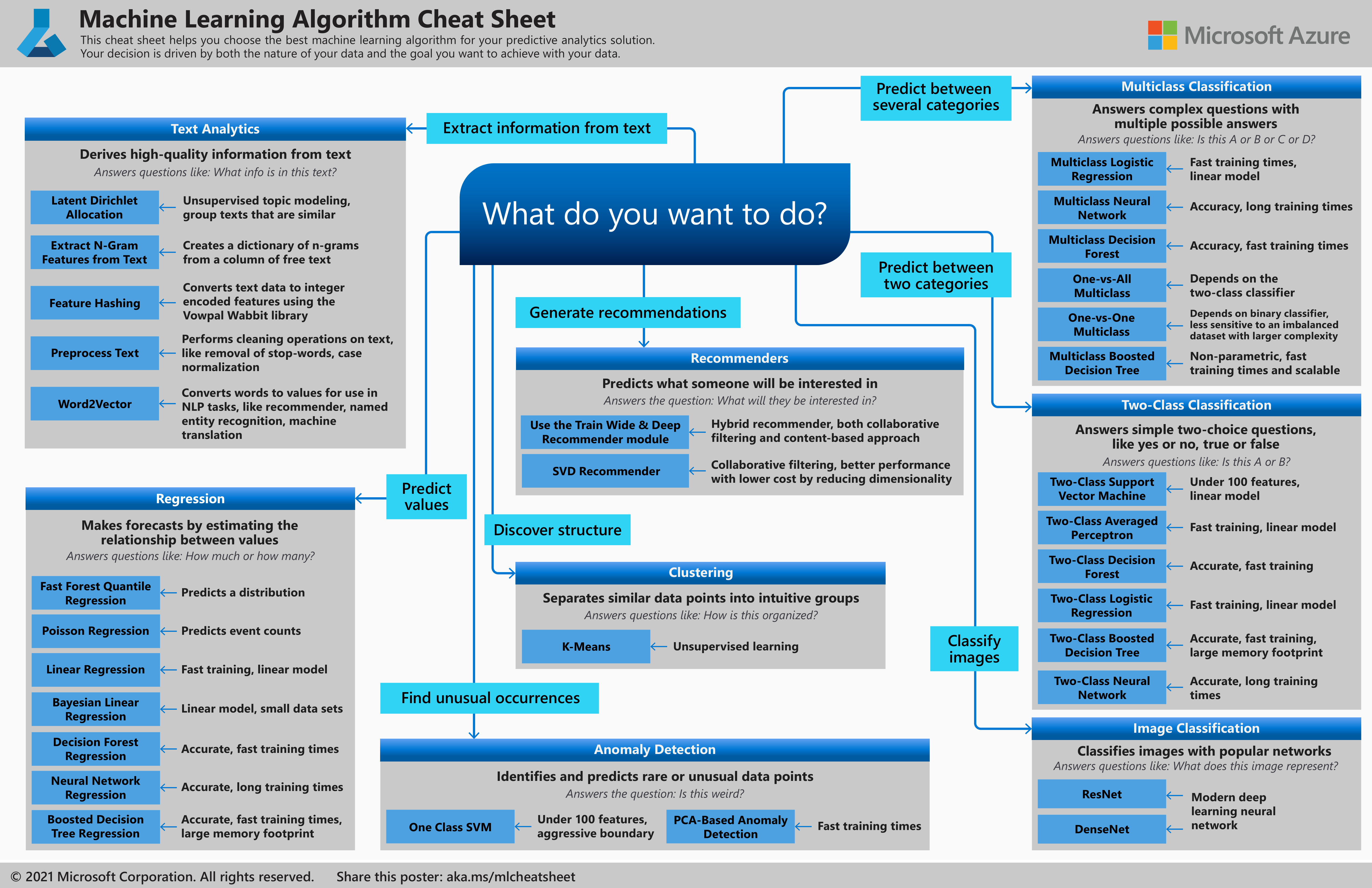
The Azure Machine Learning Algorithm Cheat Sheet helps you choose the right algorithm from the designer for a predictive analytics model.
Note
Designer supports two types of components, classic prebuilt components (v1) and custom components (v2). These two types of components are NOT compatible.
Classic prebuilt components provide prebuilt components majorly for data processing and traditional machine learning tasks like regression and classification. This type of component continues to be supported but will not have any new components added.
Custom components allow you to wrap your own code as a component. It supports sharing components across workspaces and seamless authoring across Studio, CLI v2, and SDK v2 interfaces.
For new projects, we highly suggest you use custom component, which is compatible with AzureML V2 and will keep receiving new updates.
This article applies to classic prebuilt components and not compatible with CLI v2 and SDK v2.
Azure Machine Learning has a large library of algorithms from the classification, recommender systems, clustering, anomaly detection, regression, and text analytics families. Each is designed to address a different type of machine learning problem.
For more information, see How to select algorithms.
Download: Machine Learning Algorithm Cheat Sheet
Download the cheat sheet here: Machine Learning Algorithm Cheat Sheet (11x17 in.)
Download and print the Machine Learning Algorithm Cheat Sheet in tabloid size to keep it handy and get help choosing an algorithm.
How to use the Machine Learning Algorithm Cheat Sheet
The suggestions offered in this algorithm cheat sheet are approximate rules-of-thumb. Some can be bent, and some can be flagrantly violated. This cheat sheet is intended to suggest a starting point. Don’t be afraid to run a head-to-head competition between several algorithms on your data. There is simply no substitute for understanding the principles of each algorithm and the system that generated your data.
Every machine learning algorithm has its own style or inductive bias. For a specific problem, several algorithms may be appropriate, and one algorithm may be a better fit than others. But it's not always possible to know beforehand, which is the best fit. In cases like these, several algorithms are listed together in the cheat sheet. An appropriate strategy would be to try one algorithm, and if the results are not yet satisfactory, try the others.
To learn more about the algorithms in Azure Machine Learning designer, go to the Algorithm and component reference.
Kinds of machine learning
There are three main categories of machine learning: supervised learning, unsupervised learning, and reinforcement learning.
In supervised learning, each data point is labeled or associated with a category or value of interest. An example of a categorical label is assigning an image as either a ‘cat’ or a ‘dog’. An example of a value label is the sale price associated with a used car. The goal of supervised learning is to study many labeled examples like these, and then to be able to make predictions about future data points. For example, identifying new photos with the correct animal or assigning accurate sale prices to other used cars. This is a popular and useful type of machine learning.
In unsupervised learning, data points have no labels associated with them. Instead, the goal of an unsupervised learning algorithm is to organize the data in some way or to describe its structure. Unsupervised learning groups data into clusters, as K-means does, or finds different ways of looking at complex data so that it appears simpler.
In reinforcement learning, the algorithm gets to choose an action in response to each data point. It is a common approach in robotics, where the set of sensor readings at one point in time is a data point, and the algorithm must choose the robot’s next action. It's also a natural fit for Internet of Things applications. The learning algorithm also receives a reward signal a short time later, indicating how good the decision was. Based on this signal, the algorithm modifies its strategy in order to achieve the highest reward.
