VMware to Azure disaster recovery architecture - Classic
This article describes the architecture and processes used when you deploy disaster recovery replication, failover, and recovery of VMware virtual machines (VMs) between an on-premises VMware site and Azure using the Azure Site Recovery service - Classic.
For details about modernized architecture, see this article
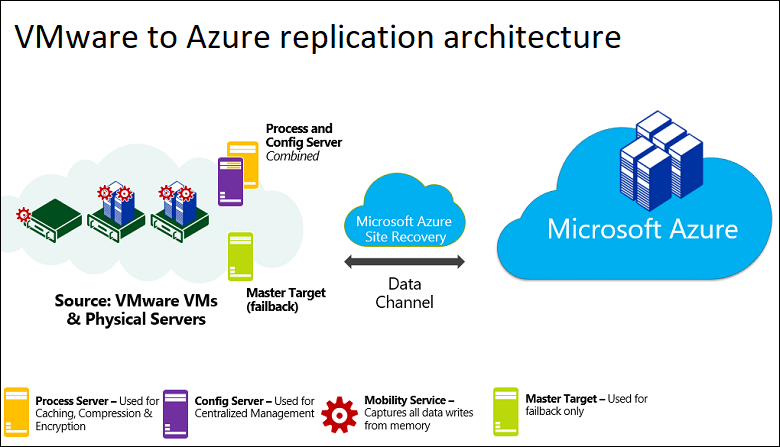
The following table and graphic provide a high-level view of the components used for VMware VMs/Physical machines disaster recovery to Azure.
| Component | Requirement | Details |
|---|---|---|
| Azure | An Azure subscription, Azure Storage account for cache, Managed Disk, and Azure network. | Replicated data from on-premises VMs is stored in Azure storage. Azure VMs are created with the replicated data when you run a failover from on-premises to Azure. The Azure VMs connect to the Azure virtual network when they're created. |
| Configuration server machine | A single on-premises machine. We recommend that you run it as a VMware VM that can be deployed from a downloaded OVF template. The machine runs all on-premises Site Recovery components, which include the configuration server, process server, and master target server. |
Configuration server: Coordinates communications between on-premises and Azure, and manages data replication. Process server: Installed by default on the configuration server. It receives replication data; optimizes it with caching, compression, and encryption; and sends it to Azure Storage. The process server also installs Azure Site Recovery Mobility Service on VMs you want to replicate, and performs automatic discovery of on-premises machines. As your deployment grows, you can add additional, separate process servers to handle larger volumes of replication traffic. Master target server: Installed by default on the configuration server. It handles replication data during failback from Azure. For large deployments, you can add an additional, separate master target server for failback. |
| VMware servers | VMware VMs are hosted on on-premises vSphere ESXi servers. We recommend a vCenter server to manage the hosts. | During Site Recovery deployment, you add VMware servers to the Recovery Services vault. |
| Replicated machines | Mobility Service is installed on each VMware VM that you replicate. | We recommend that you allow automatic installation from the process server. Alternatively, you can install the service manually or use an automated deployment method, such as Configuration Manager. |
For Site Recovery to work as expected, you need to modify outbound network connectivity to allow your environment to replicate.
Note
Site Recovery of VMware/Physical machines using Classic architecture doesn't support using an authentication proxy to control network connectivity. The same is supported when using the modernized architecture.
If you're using a URL-based firewall proxy to control outbound connectivity, allow access to these URLs:
| Name | Commercial | Government | Description |
|---|---|---|---|
| Storage | *.blob.core.windows.net |
*.blob.core.usgovcloudapi.net |
Allows data to be written from the VM to the cache storage account in the source region. |
| Microsoft Entra ID | login.microsoftonline.com |
login.microsoftonline.us |
Provides authorization and authentication to Site Recovery service URLs. |
| Replication | *.hypervrecoverymanager.windowsazure.com |
*.hypervrecoverymanager.windowsazure.us |
Allows the VM to communicate with the Site Recovery service. |
| Service Bus | *.servicebus.windows.net |
*.servicebus.usgovcloudapi.net |
Allows the VM to write Site Recovery monitoring and diagnostics data. |
For exhaustive list of URLs to be filtered for communication between on-premises Azure Site Recovery infrastructure and Azure services, refer to network requirements section in the prerequisites article.
When you enable replication for a VM, initial replication to Azure storage begins, using the specified replication policy. Note the following:
- For VMware VMs, replication is block-level, near-continuous, using the Mobility service agent running on the VM.
- Any replication policy settings are applied:
- RPO threshold. This setting does not affect replication. It helps with monitoring. An event is raised, and optionally an email sent, if the current RPO exceeds the threshold limit that you specify.
- Recovery point retention. This setting specifies how far back in time you want to go when a disruption occurs. Maximum retention is 15 days on Managed disk.
- App-consistent snapshots. App-consistent snapshot can be taken every 1 to 12 hours, depending on your app needs. Snapshots are standard Azure blob snapshots. The Mobility agent running on a VM requests a VSS snapshot in accordance with this setting, and bookmarks that point-in-time as an application consistent point in the replication stream.
Note
High recovery point retention period may have an implication on the storage cost since more recovery points may need to be saved.
Traffic replicates to Azure storage public endpoints over the internet. Alternately, you can use Azure ExpressRoute with Microsoft peering. Replicating traffic over a site-to-site virtual private network (VPN) from an on-premises site to Azure isn't supported.
Initial replication operation ensures that entire data on the machine at the time of enable replication is sent to Azure. After initial replication finishes, replication of delta changes to Azure begins. Tracked changes for a machine are sent to the process server.
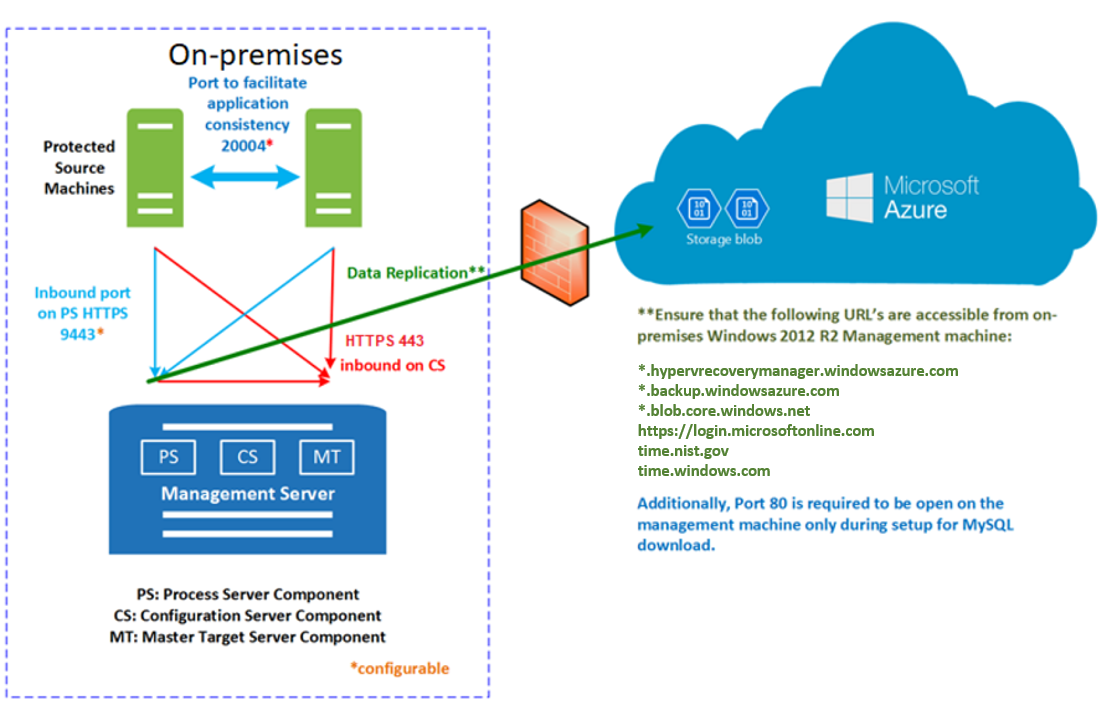
Communication happens as follows:
- VMs communicate with the on-premises configuration server on port HTTPS 443 inbound, for replication management.
- The configuration server orchestrates replication with Azure over port HTTPS 443 outbound.
- VMs send replication data to the process server (running on the configuration server machine) on port HTTPS 9443 inbound. This port can be modified.
- The process server receives replication data, optimizes, and encrypts it, and sends it to Azure storage over port 443 outbound.
The replication data logs first land in a cache storage account in Azure. These logs are processed and the data is stored in an Azure Managed Disk (called as Azure Site Recovery seed disk). The recovery points are created on this disk.
- At times, during initial replication or while transferring delta changes, there can be network connectivity issues between source machine to process server or between process server to Azure. Either of these can lead to failures in data transfer to Azure momentarily.
- To avoid data integrity issues, and minimize data transfer costs, Site Recovery marks a machine for resynchronization.
- A machine can also be marked for resynchronization in situations like following to maintain consistency of between source machine and data stored in Azure
- If a machine undergoes force shut-down
- If a machine undergoes configurational changes like disk resizing (modifying the size of disk from 2 TB to 4 TB)
- Resynchronization sends only delta data to Azure. Data transfer between on-premises and Azure by minimized by computing checksums of data between source machine and data stored in Azure.
- By default resynchronization is scheduled to run automatically outside office hours. If you don't want to wait for default resynchronization outside hours, you can resynchronize a VM manually. To do this, go to Azure portal, select the VM > Resynchronize.
- If default resynchronization fails outside office hours and a manual intervention is required, then an error is generated on the specific machine in Azure portal. You can resolve the error and trigger the resynchronization manually.
- After completion of resynchronization, replication of delta changes will resume.
- You can customize the settings of replication policies as you enable replication.
- You can create a replication policy at any time, and then apply it when you enable replication.
If you want VMs to replicate together, and have shared crash-consistent and app-consistent recovery points at failover, you can gather them together into a replication group. Multi-VM consistency impacts workload performance, and should only be used for VMs running workloads that need consistency across all machines.
Recovery points are created from snapshots of VM disks taken at a specific point in time. When you fail over a VM, you use a recovery point to restore the VM in the target location.
When failing over, we generally want to ensure that the VM starts with no corruption or data loss, and that the VM data is consistent for the operating system, and for apps that run on the VM. This depends on the type of snapshots taken.
Site Recovery takes snapshots as follows:
- Site Recovery takes crash-consistent snapshots of data by default, and app-consistent snapshots if you specify a frequency for them.
- Recovery points are created from the snapshots, and stored in accordance with retention settings in the replication policy.
The following table explains different types of consistency.
| Description | Details | Recommendation |
|---|---|---|
| A crash consistent snapshot captures data that was on the disk when the snapshot was taken. It doesn't include anything in memory. It contains the equivalent of the on-disk data that would be present if the VM crashed or the power cord was pulled from the server at the instant that the snapshot was taken. A crash-consistent doesn't guarantee data consistency for the operating system, or for apps on the VM. |
Site Recovery creates crash-consistent recovery points every five minutes by default. This setting can't be modified. |
Today, most apps can recover well from crash-consistent points. Crash-consistent recovery points are usually sufficient for the replication of operating systems, and apps such as DHCP servers and print servers. |
| Description | Details | Recommendation |
|---|---|---|
| App-consistent recovery points are created from app-consistent snapshots. An app-consistent snapshot contains all the information in a crash-consistent snapshot, plus all the data in memory and transactions in progress. |
App-consistent snapshots use the Volume Shadow Copy Service (VSS): 1) Azure Site Recovery uses Copy Only backup (VSS_BT_COPY) method which does not change Microsoft SQL's transaction log backup time and sequence number 2) When a snapshot is initiated, VSS perform a copy-on-write (COW) operation on the volume. 3) Before it performs the COW, VSS informs every app on the machine that it needs to flush its memory-resident data to disk. 4) VSS then allows the backup/disaster recovery app (in this case Site Recovery) to read the snapshot data and proceed. |
App-consistent snapshots are taken in accordance with the frequency you specify. This frequency should always be less than you set for retaining recovery points. For example, if you retain recovery points using the default setting of 24 hours, you should set the frequency at less than 24 hours. They're more complex and take longer to complete than crash-consistent snapshots. They affect the performance of apps running on a VM enabled for replication. |
After replication is set up and you run a disaster recovery drill (test failover) to check that everything's working as expected, you can run failover and failback as you need to.
You run fail for a single machine, or create a recovery plans to fail over multiple VMs at the same time. The advantage of a recovery plan rather than single machine failover include:
- You can model app-dependencies by including all the VMs across the app in a single recovery plan.
- You can add scripts, Azure runbooks, and pause for manual actions.
After triggering the initial failover, you commit it to start accessing the workload from the Azure VM.
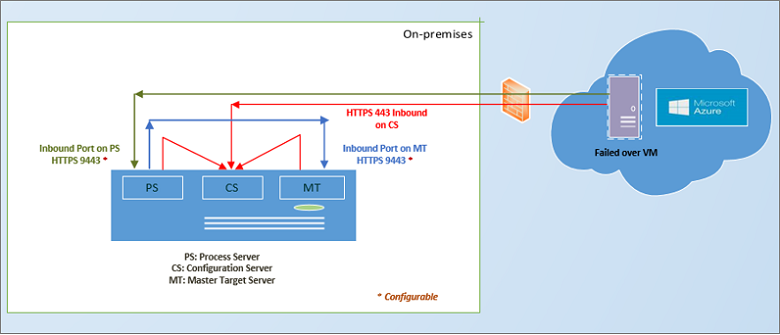
When your primary on-premises site is available again, you can prepare for fail back. In order to fail back, you need to set up a failback infrastructure, including:
- Temporary process server in Azure: To fail back from Azure, you set up an Azure VM to act as a process server to handle replication from Azure. You can delete this VM after failback finishes.
- VPN connection: To fail back, you need a VPN connection (or ExpressRoute) from the Azure network to the on-premises site.
- Separate master target server: By default, the master target server that was installed with the configuration server on the on-premises VMware VM handles failback. If you need to fail back large volumes of traffic, set up a separate on-premises master target server for this purpose.
- Failback policy: To replicate back to your on-premises site, you need a failback policy. This policy is automatically created when you create a replication policy from on-premises to Azure.
After the components are in place, failback occurs in three actions:
- Stage 1: Reprotect the Azure VMs so that they replicate from Azure back to the on-premises VMware VMs.
- Stage 2: Run a failover to the on-premises site.
- Stage 3: After workloads have failed back, you reenable replication for the on-premises VMs.
Follow this tutorial to enable VMware to Azure replication.