Training
Module
Manage access, add entry points, and review Microsoft Search feedback - Training
Get an overview of solutions to manage access to files and sites, add search entry points, and review feedback from your users.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
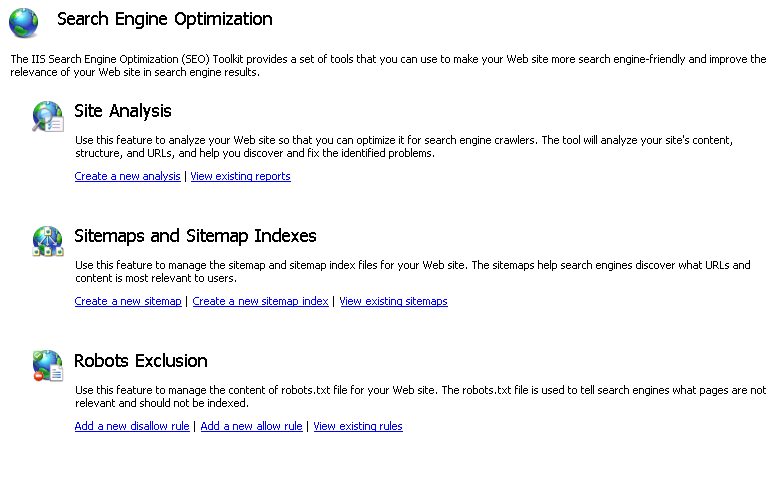
The IIS Search Engine Optimization Toolkit includes a Robots Exclusion feature that you can use to manage the content of the Robots.txt file for your Web site, and includes the Sitemaps and Sitemap Indexes feature that you can use to manage your site's sitemaps. This walkthrough explains how and why to use these features.
Search engine crawlers will spend limited time and resources on your Web site. Therefore, it's critical to do the following:
There are two protocols that are commonly used to achieve these tasks: the Robots Exclusion protocol and the Sitemaps protocol.
The Robots Exclusion protocol is used to tell search engine crawlers which URLs it should NOT request when crawling a Web site. The exclusion instructions are placed into a text file named Robots.txt, which is located at the root of the Web site. Most search engine crawlers usually look for this file and follow the instructions in it.
The Sitemaps protocol is used to inform search engine crawlers about URLs that are available for crawling on your Web site. In addition, Sitemaps are used to provide some additional metadata about the site's URLs, such as last modified time, modification frequency, relative priority, etc. Search engines might use this metadata when indexing your Web site.
In order to complete this walkthrough, you will need an IIS 7 or above hosted Web site or a Web application that you control. If you do not have one, you can install one from the Microsoft Web Application Gallery. For the purposes of this walkthrough, we will use the popular blogging application DasBlog.
Once you have a Web site or a Web application, you may want to analyze it to understand how a typical search engine will crawl its contents. To do this, follow the steps outlined in the articles "Using Site Analysis to Crawl a Web Site" and "Using Site Analysis Reports". When you do your analysis, you will probably notice that you have certain URLs that are available for the search engines to crawl, but that there is no real benefit in having them being crawled or indexed. For example, login pages or resource pages should not be even requested by search engine crawlers. URLs like these should be hidden from search engines by adding them to the Robots.txt file.
You can use the Robots Exclusion feature of the IIS SEO Toolkit to author a Robots.txt file which tells search engines which parts of the Web site should not be crawled or indexed. The following steps describe how to use this tool.

The "Add Disallow Rules" dialog will open automatically:
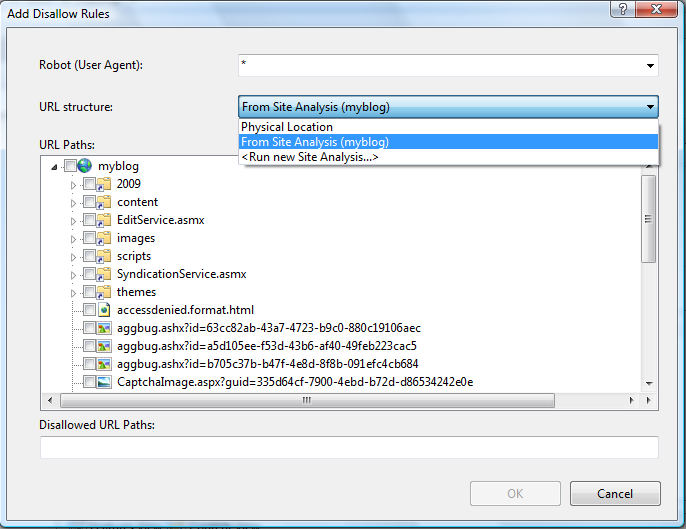
Robots Exclusion protocol uses "Allow" and "Disallow" directives to inform search engines about URL paths that can be crawled and the ones that cannot. These directives can be specified for all search engines or for specific user agents identified by a user-agent HTTP header. Within the "Add Disallow Rules" dialog you can specify which search engine crawler the directive applies to by entering the crawler's user-agent into the "Robot (User Agent)" field.
The URL Path tree view is used to select which URLs should be disallowed. You can choose from several options when selecting the URL paths by using the "URL structure" drop down list:
After have completed the steps described in the prerequisites section, you will have a site analysis available. Choose the analysis in the drop down list and then check the URLs that need to be hidden from search engines by using the checkboxes in the "URL Paths" tree view:
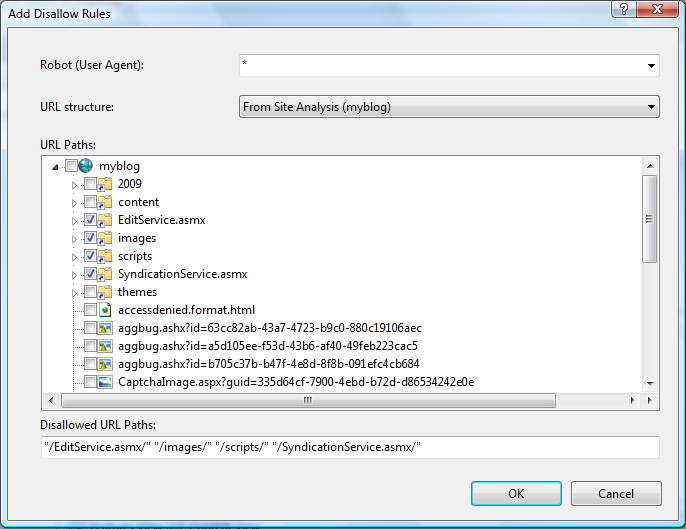
After selecting all the directories and files that need to be disallowed, click OK. You will see the new disallow entries in the main feature view:
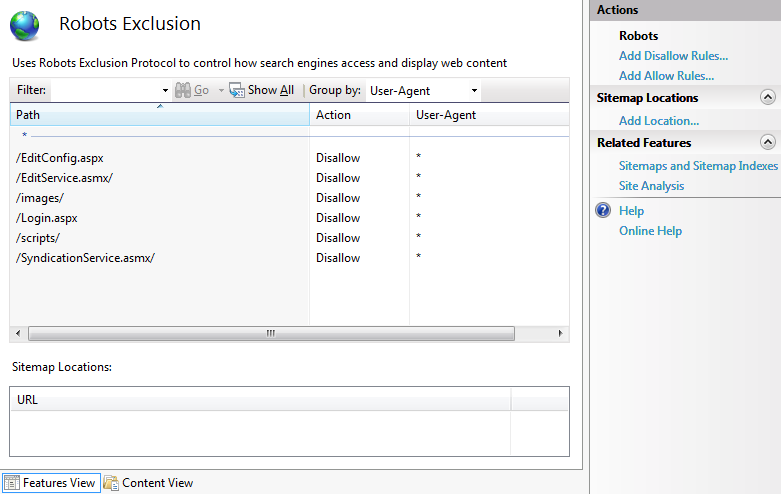
Also, the Robots.txt file for the site will be updated (or created if it did not exist). Its content will look similar to this:
User-agent: *
Disallow: /EditConfig.aspx
Disallow: /EditService.asmx/
Disallow: /images/
Disallow: /Login.aspx
Disallow: /scripts/
Disallow: /SyndicationService.asmx/
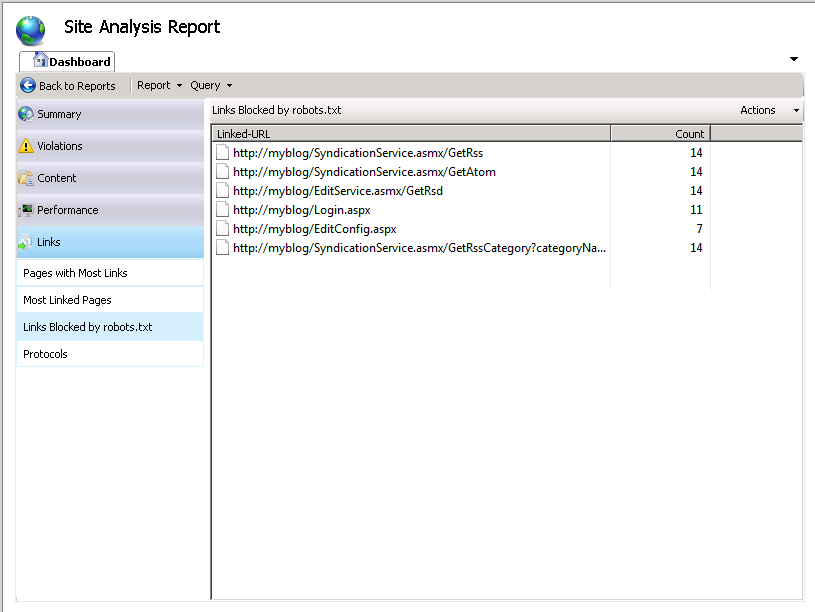
To see how Robots.txt works, go back to the Site Analysis feature and re-run the analysis for the site. On the Reports Summary page, in the Links category, choose Links Blocked by Robots.txt. This report will display all the links that have not been crawled because they have been disallowed by the Robots.txt file that you have just created.
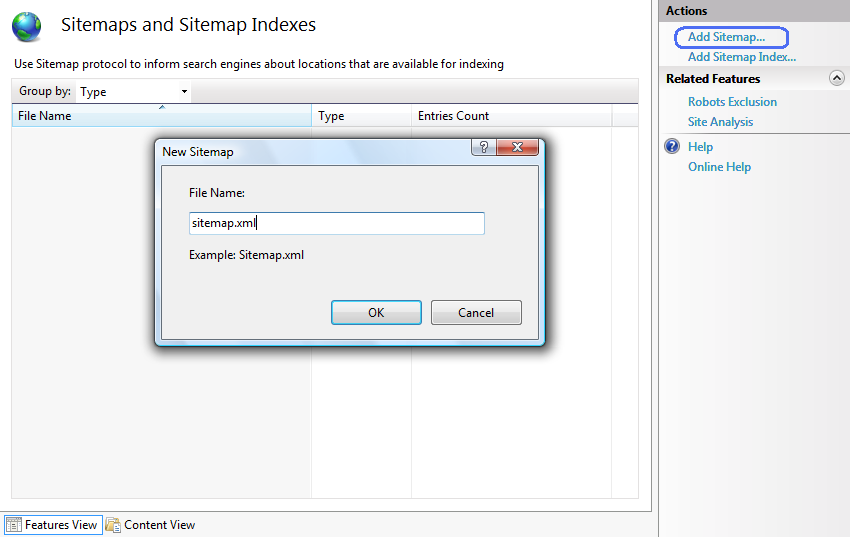
You can use the Sitemaps and Sitemap Indexes feature of the IIS SEO Toolkit to author sitemaps on your Web site to inform search engines of the pages that should be crawled and indexed. To do this, follow these steps:
The Add URLs dialog looks like this:
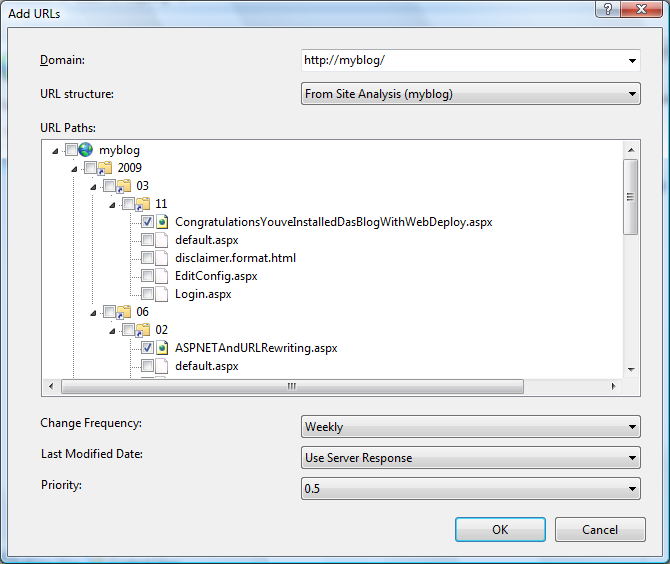
The Sitemap file is basically a simple XML file that lists URLs along with some metadata, such as change frequency, last modified date, and relative priority. You use the Add URLs dialog to add new URL entries to the Sitemap xml file. Each URL in the sitemap must be in a fully qualified URI format (i.e. it must include protocol prefix and domain name). So, the first thing you have to specify is the domain that will be used for the URLs that you are going to add to the sitemap.
The URL Path tree view is used to select which URLs should be added to the sitemap for indexing. You can choose from several options by using the "URL structure" drop down list:
After you have completed the steps in the prerequisites section, you will have a site analysis available. Choose it from the drop-down list, and then check the URLs that need to be added to the sitemap.
If necessary, modify the Change Frequency, Last Modified Date, and Priority options, and then click OK to add the URLs to the sitemap. A sitemap.xml file will be updated (or created if it did not exist), and its content will look like the following:
<urlset>
<url>
<loc>http://myblog/2009/03/11/CongratulationsYouveInstalledDasBlogWithWebDeploy.aspx</loc>
<lastmod>2009-06-03T16:05:02</lastmod>
<changefreq>weekly</changefreq>
<priority>0.5</priority>
</url>
<url>
<loc>http://myblog/2009/06/02/ASPNETAndURLRewriting.aspx</loc>
<lastmod>2009-06-03T16:05:01</lastmod>
<changefreq>weekly</changefreq>
<priority>0.5</priority>
</url>
</urlset>
Now that you have created a sitemap, you will need to let search engines know where it is located so that they can start using it. The simplest way to do this is to add the sitemap location URL to the Robots.txt file.
In the Sitemaps and Sitemap Indexes feature, choose the sitemap that you have just created, and then click Add to Robots.txt in the Actions pane:
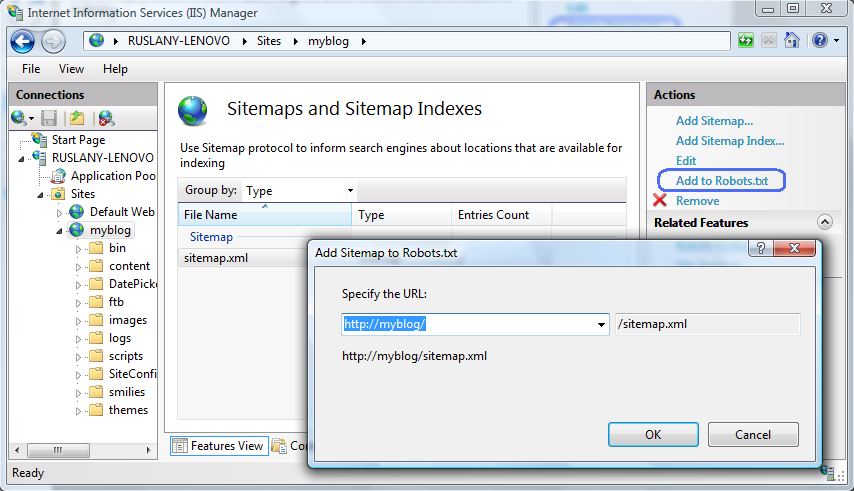
Your Robots.txt file will look similar to the following:
User-agent: *
Disallow: /EditService.asmx/
Disallow: /images/
Disallow: /scripts/
Disallow: /SyndicationService.asmx/
Disallow: /EditConfig.aspx
Disallow: /Login.aspx
Sitemap: http://myblog/sitemap.xml
In addition to adding the sitemap location to the Robots.txt file, it is recommended that you submit your sitemap location URL to the major search engines. This will allow you to obtain useful status and statistics about your Web site from the search engine's webmasters tools.
In this walkthrough, you have learned how to use the Robots Exclusion and Sitemaps and Sitemap Indexes features of the IIS Search Engine Optimization Toolkit to manage the Robots.txt and sitemap files on your Web site. The IIS Search Engine Optimization Toolkit provides an integrated set of tools that work together to help you author and validate the correctness of the Robots.txt and sitemap files before search engines start using them.
Training
Module
Manage access, add entry points, and review Microsoft Search feedback - Training
Get an overview of solutions to manage access to files and sites, add search entry points, and review feedback from your users.