Notes
Cet article s’appuie sur une bibliothèque open source hébergée sur GitHub sur : https://github.com/mspnp/spark-monitoring.
La bibliothèque d’origine prend en charge Azure Databricks Runtime 10.x (Spark 3.2.x) et versions antérieures.
Databricks a fourni une version mise à jour pour prendre en charge Azure Databricks Runtime 11.0 (Spark 3.3.x) et versions ultérieures sur la branche l4jv2 à l’adresse : https://github.com/mspnp/spark-monitoring/tree/l4jv2.
Notez que la version 11.0 n’est pas rétrocompatible, en raison des différents systèmes de journalisation utilisés dans les runtimes Databricks. Veillez à utiliser la build appropriée pour votre runtime Databricks. La bibliothèque et le dépôt GitHub sont en mode maintenance. Il n’est pas prévu d’autres versions, et la prise en charge des problèmes sera uniquement fournie sur la base du meilleur effort. Pour toute question supplémentaire sur la bibliothèque ou sur la feuille de route pour le monitoring et la journalisation de vos environnements Azure Databricks, contactez azure-spark-monitoring-help@databricks.com.
Cette solution démontre comment les métriques et les modèles d’observabilité peuvent améliorer les performances de traitement d’un système Big Data à l’aide d’Azure Databricks.
Architecture

Téléchargez un fichier Visio de cette architecture.
Workflow
La solution implique les étapes suivantes :
Le serveur envoie un fichier GZIP volumineux compilé par client au dossier source d’Azure Data Lake Storage (ADLS).
ADLS envoie ensuite un fichier client extrait avec succès à Azure Event Grid, qui transforme à son tour les données du fichier client en plusieurs messages.
Azure Event Grid envoie les messages au service Stockage File d'attente Azure, qui les stocke dans une file d’attente.
Le service Stockage File d'attente Azure envoie la file d’attente à la plateforme d’analytique des données Azure Databricks pour traitement.
Azure Databricks décompresse et traite les données de la file d’attente dans un fichier traité qu’il renvoie à ADLS :
Si le fichier traité est valide, il est placé dans le dossier Landing.
Dans le cas contraire, le fichier est placé dans l’arborescence de dossiers Bad. Initialement, le fichier est placé dans le sous-dossier Retry et ADLS tente à nouveau de traiter le fichier client (étape 2). Si une paire de nouvelles tentatives aboutit toujours à Azure Databricks retournant des fichiers traités qui ne sont pas valides, le fichier traité est placé dans le sous-dossier Failure.
En plus de décompresser et de traiter les données à l’étape précédente, Azure Databricks envoie également des journaux et des métriques d’application à Azure Monitor à des fins de stockage.
Un espace de travail Azure Log Analytics applique des requêtes Kusto sur les journaux et les métriques d’application d’Azure Monitor à des fins de résolution des problèmes et de diagnostic détaillé.
Composants
- Azure Data Lake Storage est un ensemble de fonctionnalités dédiées à l’analytique du Big Data.
- Azure Event Grid permet au développeur de créer facilement des applications avec des architectures basées sur des événements.
- Le service Stockage File d’attente Azure est un service permettant de stocker un grand nombre de messages. Il permet d’accéder aux messages depuis n’importe où dans le monde par le biais d’appels authentifiés à l’aide du protocole HTTP ou HTTPS. Vous pouvez utiliser les files d’attente pour créer un backlog de travail à traiter de façon asynchrone.
- Azure Databricks est une plateforme d’analytique données optimisée pour la plateforme cloud Azure. L’un des deux environnements que Azure Databricks offre pour le développement d’applications gourmandes en données est Azure Databricks Workspace, un moteur d’analyse unifié basé sur Apache Spark et dédié au traitement des données à grande échelle.
- La plateforme Azure Monitor collecte et analyse la télémétrie des applications, comme les métriques de performances et les journaux d’activité.
- Azure Log Analytics est un outil permettant de modifier et d’exécuter des requêtes de journal à l’aide de données.
Détails du scénario
Votre équipe de développement peut utiliser des modèles d’observabilité et des métriques pour rechercher les goulots d’étranglement et améliorer les performances d’un système Big Data. Votre équipe doit effectuer un test de charge d’un flux de métriques volumineux sur une application à grande échelle.
Ce scénario propose des conseils pour optimiser les performances. Étant donné que le scénario présente un défi en matière de performances pour la journalisation par client, il utilise Azure Databricks, qui peut surveiller ces aspects de façon fiable :
- Métriques d’application personnalisées
- Événements de requête de diffusion en continu
- Messages du journal des applications
Azure Databricks peut envoyer ces données de supervision à différents services de journalisation, tels que Azure Log Analytics.
Ce scénario décrit l’ingestion d’un vaste ensemble de données qui ont été regroupées par client et stockées dans un fichier d’archive GZIP. Les journaux détaillés n’étant pas disponibles à partir d’Azure Databricks en dehors de l’interface utilisateur Apache Spark™ en temps réel, votre équipe a besoin d’un moyen de stocker toutes les données pour chaque client, puis de les tester et de les comparer. Dans le cas d’un scénario de données de grande ampleur, il est important de trouver une combinaison optimale entre un pool d’exécuteurs et une taille de machine virtuelle pour le temps de traitement le plus rapide. Pour ce scénario d’entreprise, l’application globale s’appuie sur la vitesse des exigences d’ingestion et d’interrogation, de sorte que le débit du système ne se dégrade pas de façon inattendue avec l’accroissement du volume de travail. Le scénario doit garantir que le système répond aux contrats de niveau de service (SLA) établis avec vos clients.
Cas d’usage potentiels
Les scénarios susceptibles de bénéficier de cette solution comprennent les suivants :
- Surveillance de l’intégrité du système.
- Maintenance des performances.
- Surveillance de l’utilisation quotidienne du système.
- Détection des tendances susceptibles de provoquer des problèmes futurs si elles ne sont pas traitées.
Considérations
Ces considérations implémentent les piliers d’Azure Well-Architected Framework qui est un ensemble de principes directeurs qui permettent d’améliorer la qualité d’une charge de travail. Pour plus d’informations, consultez Microsoft Azure Well-Architected Framework.
Gardez ces points à l’esprit lorsque vous envisagez cette architecture :
Azure Databricks peut allouer automatiquement les ressources de calcul nécessaires pour un travail volumineux, ce qui évite les problèmes que d’autres solutions introduisent. Par exemple, avec la mise à l’échelle automatique optimisée par Databricks sur Apache Spark, l’approvisionnement excessif peut entraîner une utilisation non optimale des ressources. Ou vous risquez de ne pas connaître le nombre d’exécuteurs requis pour un travail.
La taille maximale d’un message de file d’attente dans le Stockage File d'attente Azure est de 64 Ko. Une file d’attente peut contenir des millions de messages, dans la limite de la capacité totale d’un compte de stockage.
Optimisation des coûts
L’optimisation des coûts consiste à examiner les moyens de réduire les dépenses inutiles et d’améliorer l’efficacité opérationnelle. Pour plus d’informations, consultez Vue d’ensemble du pilier d’optimisation des coûts.
Utilisez la Calculatrice de prix Azure pour estimer le coût de l’implémentation de cette solution.
Déployer ce scénario
Notes
Les étapes de déploiement décrites ici s’appliquent uniquement à Azure Databricks, Azure Monitor et Azure Log Analytics. Le déploiement des autres composants n’est pas abordé dans cet article.
Pour récupérer tous les journaux et informations du processus, configurez Azure Log Analytics et la bibliothèque de surveillance Azure Databricks. La bibliothèque d’analyse transmet en continu les événements du niveau Apache Spark et les métriques Spark Structured Streaming de vos tâches dans Azure Monitor. Vous n’êtes pas tenu de modifier votre code d’application pour ces événements et métriques.
Les étapes pour configurer l’optimisation des performances d’un système Big Data sont les suivantes :
Dans le portail Azure, créez un espace de travail Azure Databricks. Copiez et enregistrez l’ID d’abonnement Azure (GUID), le nom du groupe de ressources, le nom de l’espace de travail Databricks et l’URL du portail d’espace de travail pour une utilisation ultérieure.
Dans un navigateur Web, accédez à l’URL de l’espace de travail Databricks et générez un jeton d’accès personnel Databricks. Copiez et enregistrez la chaîne de jeton qui s’affiche (qui commence par
dapiet une valeur hexadécimale à 32 caractères) pour une utilisation ultérieure.Clonez le référentiel GitHub mspnp/spark-monitoring sur votre ordinateur local. Ce référentiel dispose du code source pour les composants suivants :
- Modèle Azure Resource Manager (ARM) pour la création d’un espace de travail Azure Log Analytics, qui installe également des requêtes prédéfinies pour la collecte des métriques Spark
- Bibliothèques de surveillance Azure Databricks
- L’exemple d’application pour l’envoi de métriques et de journaux d’applications d’Azure Databricks à Azure Monitor
À l’aide de la commande Azure CLI pour le déploiement d’un modèle ARM, créez un espace de travail Azure Log Analytics avec des requêtes de métriques Spark prégénérées. À partir de la sortie de commande, copiez et enregistrez le nom généré pour le nouvel espace de travail Log Analytics (au format spark-monitoring-<randomized-string>).
Dans le portail Azure, copiez et enregistrez votre ID et votre clé d’espace de travail log Analytics pour une utilisation ultérieure.
Installez l’édition Community de IntelliJ IDEA, un environnement de développement intégré (IDE) qui offre une prise en charge intégrée du Kit de développement Java (JDK) et Apache Maven. Ajoutez le plug-in Scala.
À l’aide de IntelliJ IDEA, créez les bibliothèques de surveillance Azure Databricks. Pour procéder à la génération effective, sélectionnez Afficher>Fenêtres Outil>Maven afin d’afficher la fenêtre d’outils Maven, puis sélectionnez Exécuter Maven Goal>package mvn.
À l’aide d’un outil d’installation de package Python, installez la CLI Azure Databricks et configurez l’authentification avec le jeton d’accès personnel Databricks que vous avez copié précédemment.
Configurez l’espace de travail Azure Databricks en modifiant le script d’initialisation Databricks avec les valeurs Databricks et Log Analytics que vous avez copiées précédemment, puis en utilisant la CLI Azure Databricks pour copier le script d’initialisation et les bibliothèques de surveillance Azure Databricks vers votre espace de travail Databricks.
Dans votre portail d’espace de travail Databricks, créez et configurez un cluster Azure Databricks.
Dans IntelliJ IDEA, générez l’exemple d’application à l’aide de Maven. Ensuite, dans votre portail d’espace de travail Databricks, exécutez l’exemple d’application afin de générer des exemples de journaux et de métriques pour Azure Monitor.
Lorsque l’exemple de travail s’exécute dans Azure Databricks, accédez au portail Azure pour afficher et interroger les types d’événements (journaux et métriques d’applications) dans l'interface de Log Analytics :
- Sélectionnez Tables>Journaux personnalisés afin d’afficher le schéma de table pour les événements de l’écouteur Spark (SparkListenerEvent_CL), les événements de journalisation Spark (SparkLoggingEvent_CL) et les métriques Spark (SparkMetric_CL).
- Sélectionnez Explorateur de requêtes>Requêtes enregistrées>Métriques Spark pour afficher et exécuter les requêtes qui ont été ajoutées lorsque vous avez créé l’espace de travail Log Analytics.
Pour plus d’informations sur l’affichage et l’exécution de requêtes prédéfinies et personnalisées, consultez la section suivante.
Interroger les journaux et les métriques dans Azure Log Analytics
Accéder aux requêtes prédéfinies
Les noms de requête prédéfinie pour la récupération des métriques Spark sont répertoriés ci-dessous.
- % temps processeur par exécuteur
- % temps de désérialisation par exécuteur
- % temps JVM par exécuteur
- % temps de sérialisation par exécuteur
- Octets disque vidés
- Traces d’erreurs (enregistrement incorrect ou fichiers incorrects)
- Lecture d’octets du système de fichiers par exécuteur
- Écriture d’octets du système de fichiers par exécuteur
- Erreurs de travail par travail
- Latence de travail par travail (durée de lot)
- Débit de travail
- Exécuteurs en cours d’exécution
- Lecture aléatoire d’octets
- Lecture aléatoire d’octets par exécuteur
- Lecture aléatoire d’octets sur disque par exécuteur
- Lecture aléatoire de la mémoire client directe
- Lecture aléatoire de la mémoire client par exécuteur
- Lecture aléatoire d’octets disque vidés par exécuteur
- Lecture aléatoire de la mémoire de segment par exécuteur
- Lecture aléatoire d’octets de mémoire vidés par exécuteur
- Latence de phase par phase (durée de phase)
- Débit de phase par phase
- Erreurs de diffusion par flux
- Latence de diffusion par flux
- Débit de diffusion lignes/sec en entrée
- Débit de diffusion lignes/sec traitées
- Somme d’exécution des tâches par hôte
- Temps de désérialisation des tâches
- Erreurs de tâche par phase
- Temps de calcul de l’exécuteur de tâche (temps d’asymétrie des données)
- Octets d’entrée de tâche lus
- Latence de tâche par phase (durée des tâches)
- Temps de sérialisation des résultats de la tâche
- Latence de retard du planificateur de tâches
- Lecture aléatoire d’octets de tâche
- Écriture aléatoire d’octets de tâche
- Temps de lecture aléatoire des tâches
- Temps d’écriture aléatoire des tâches
- Débit des tâches (somme des tâches par phase)
- Tâches par exécuteur (somme de tâches par exécuteur)
- Tâches par phase
Écrire des requêtes personnalisées
Vous pouvez également écrire vos propres requêtes dans le langage de requête Kusto (KQL). Sélectionnez simplement le volet central supérieur, modifiable, puis personnalisez la requête en fonction de vos besoins.
Les deux requêtes suivantes extraient les données des événements de journalisation Spark :
SparkLoggingEvent_CL | where logger_name_s contains "com.microsoft.pnp"
SparkLoggingEvent_CL
| where TimeGenerated > ago(7d)
| project TimeGenerated, clusterName_s, logger_name_s
| summarize Count=count() by clusterName_s, logger_name_s, bin(TimeGenerated, 1h)
Et ces deux exemples sont des requêtes sur le journal de métriques Spark :
SparkMetric_CL
| where name_s contains "executor.cpuTime"
| extend sname = split(name_s, ".")
| extend executor=strcat(sname[0], ".", sname[1])
| project TimeGenerated, cpuTime=count_d / 100000
SparkMetric_CL
| where name_s contains "driver.jvm.total."
| where executorId_s == "driver"
| extend memUsed_GB = value_d / 1000000000
| project TimeGenerated, name_s, memUsed_GB
| summarize max(memUsed_GB) by tostring(name_s), bin(TimeGenerated, 1m)
Terminologie des requêtes
Le tableau suivant décrit certains des termes utilisés lorsque vous créez une requête de journaux et de métriques d’application.
| Terme | id | Notes |
|---|---|---|
| Cluster_init | ID de l'application | |
| File d'attente | ID d’exécution | Un ID d’exécution est égal à plusieurs lots. |
| Batch | ID de lot | Un lot est égal à deux travaux. |
| Travail | ID de travail | Un travail est égal à deux phases. |
| Étape | ID de phase | Une phase comporte 100-200 ID de tâche en fonction de la tâche (lecture, lecture aléatoire ou écriture). |
| Tâches | ID de la tâche | Une tâche est assignée à un exécuteur. Une tâche est destinée à effectuer un partitionBy pour une partition. Pour environ 200 clients, il doit y avoir 200 tâches. |
Les sections suivantes contiennent les métriques typiques utilisées dans ce scénario pour surveiller le débit du système, l’état d’exécution de la tâche Spark et l’utilisation des ressources système.
Débit du système
| Nom | Mesure | Unités |
|---|---|---|
| Débit de flux | Taux moyen d’entrée sur le taux de traitement moyen par minute | Lignes par minute |
| Durée du travail | Durée moyenne d’un travail Spark terminé par minute | Durée(s) par minute |
| Nombre de travaux | Nombre moyen de travaux Spark terminés par minute | Nombre de travaux par minute |
| Durée de la phase | Durée moyenne des phases terminées par minute | Durée(s) par minute |
| Nombre de phases | Nombre moyen de phases terminées par minute | Nombre de phases par minute |
| Durée de la tâche | Durée moyenne des tâches terminées par minute | Durée(s) par minute |
| Nombre de tâches | Nombre moyen de tâches terminées par minute | Nombre de tâches par minute |
État d’exécution de la tâche Spark
| Nom | Mesure | Unités |
|---|---|---|
| Nombre de pools de planificateurs | Nombre distinct de pools de planificateurs par minute (nombre de files d’attente en fonctionnement) | Nombre de pools de planificateurs |
| Nombre d’exécuteurs en cours d’exécution | Nombre d’exécuteurs en cours d’exécution par minute | Nombre d’exécuteurs en cours d’exécution |
| Suivi d'erreur | Tous les journaux d’erreurs présentant le niveau Error et les tâches/ID de phase correspondants (affichés dans thread_name_s) |
Utilisation des ressources système
| Nom | Mesure | Unités |
|---|---|---|
| Utilisation moyenne du processeur par exécuteur/globale | Pourcentage du processeur utilisé par exécuteur par minute | % par minute |
| Mémoire directe moyenne utilisée (Mo) par hôte | Mémoire directe moyenne utilisée par les exécuteurs par minute | Mo par minute |
| Mémoire propagée par hôte | Mémoire propagée moyenne par exécuteur | Mo par minute |
| Surveiller l’impact de l’asymétrie des données sur la durée | Plage de mesures et différence du 70e-90e centile et du 90e-100e centile dans la durée des tâches | Différence nette entre 100 %, 90 % et 70 % ; différence en pourcentage entre 100 %, 90 % et 70 % |
Décidez comment associer l’entrée client, qui a été associée à un fichier d’archive GZIP, à un fichier de sortie Azure Databricks particulier, puisque Azure Databricks gère l’ensemble de l’opération par lots en tant qu’unité. Ici, vous appliquez la granularité au traçage. Vous utilisez également des métriques personnalisées pour tracer un fichier de sortie dans le fichier d’entrée d’origine.
Pour obtenir des définitions plus détaillées de chaque mesure, consultez Visualisations dans les tableaux de bord sur ce site Web ou consultez la section Métriques de la documentation Apache Spark.
Évaluer les options d’optimisation des performances
Définition de la ligne de base
Votre équipe de développement et vous-même devez établir une ligne de base afin que vous puissiez comparer les états futurs de l’application.
Mesurez les performances de votre application de façon quantitative. Dans ce scénario, la mesure clé est la latence du travail, qui est typique de l’essentiel du prétraitement et de l’ingestion des données. Essayez d’accélérer le temps de traitement des données et de vous concentrer sur la mesure de la latence, comme dans le graphique ci-dessous :
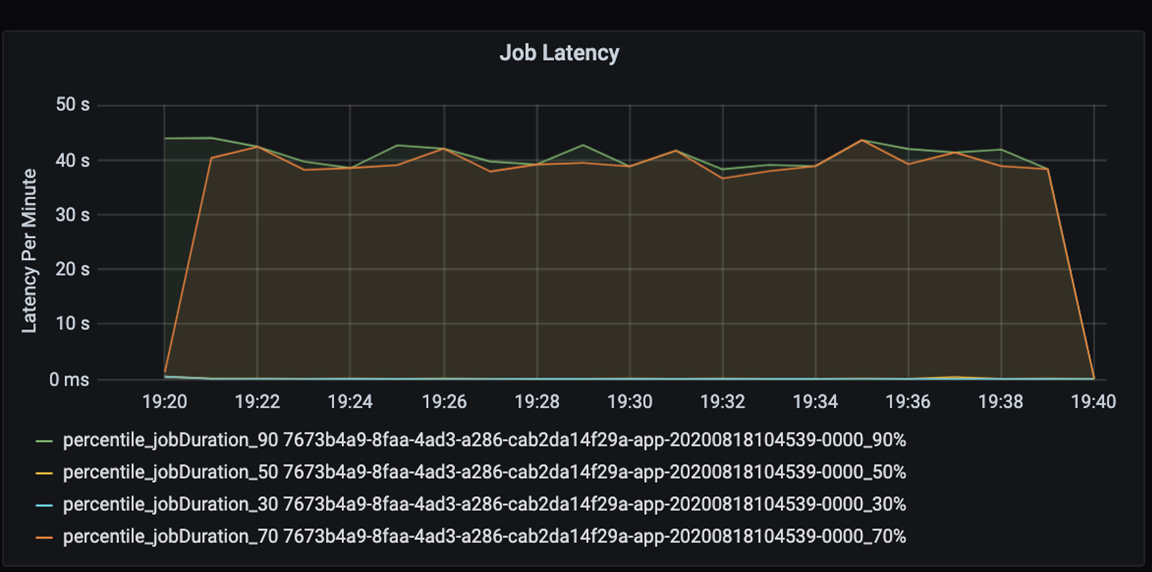
Mesurez la latence d’exécution d’un travail : une vue élémentaire sur les performances globales du travail et la durée d’exécution du travail du début à la fin (temps microbatch). Dans le graphique ci-dessus, à la marque 19:30, il faut environ 40 secondes pour traiter le travail.
Si vous examinez plus en détail ces 40 secondes, vous voyez les données ci-dessous pour les phases :
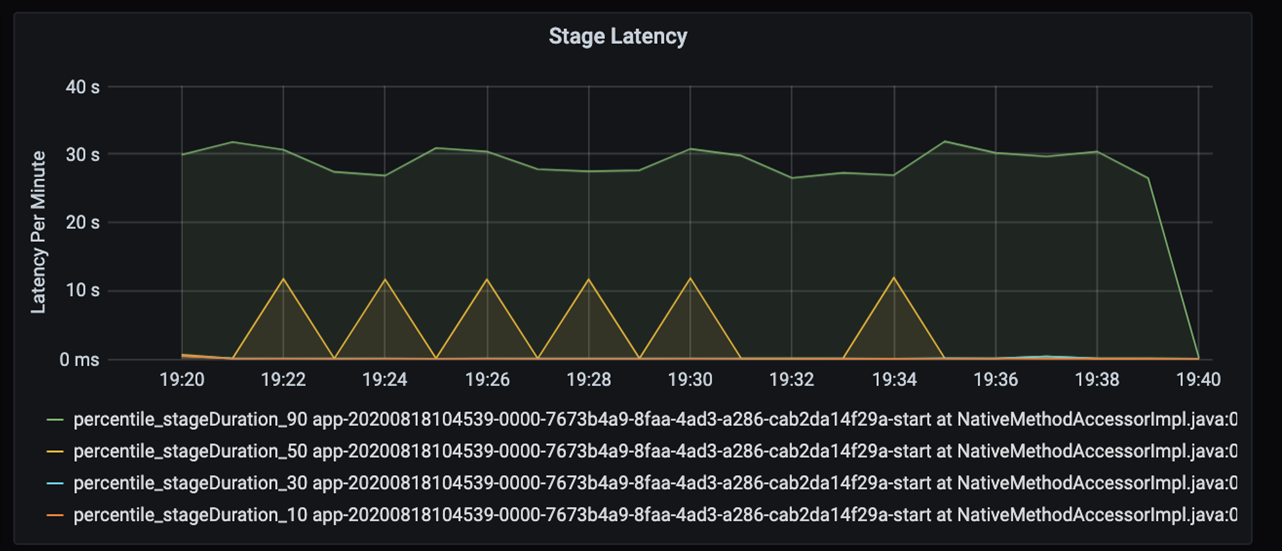
On observe deux phases à la marque 19:30 : une phase orange à 10 secondes et une phase verte à 30 secondes. Surveiller si une phase culmine, car un pic indique un retard dans une phase.
Examinez à quel moment une phase donnée s’exécute lentement. Dans le scénario de partitionnement, il y a généralement au moins deux phases : une phase pour lire un fichier, et l’autre phase pour la lecture aléatoire, la partition et l’écriture du fichier. Si vous avez une latence de phase élevée surtout à la phase d’écriture, vous risquez de rencontrer un problème de goulot d’étranglement lors du partitionnement.
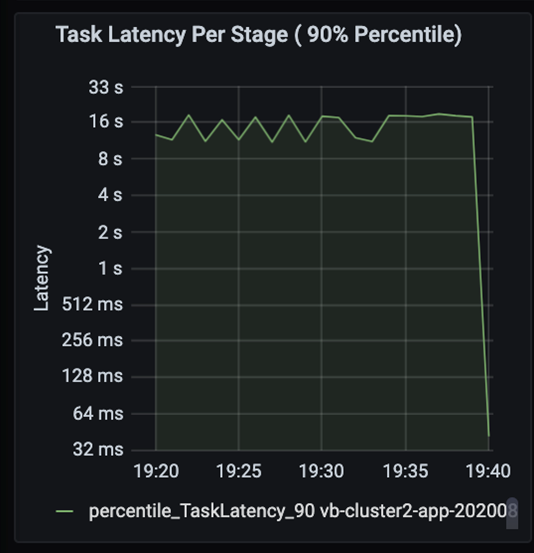
Observez les tâches alors que les phases d’un travail s’exécutent de manière séquentielle, les premières phases bloquant les suivantes. Au cours d’une phase, si une tâche exécute une partition aléatoire plus lentement que les autres tâches, toutes les tâches du cluster doivent attendre que la tâche lente se termine afin que la phase s’achève. Les tâches sont alors un moyen de surveiller l’asymétrie des données et les goulots d’étranglement possibles. Dans le graphique ci-dessus, vous pouvez voir que toutes les tâches sont réparties uniformément.
Maintenant, surveillez le temps de traitement. Étant donné que vous avez un scénario de diffusion en continu, examinez le débit de diffusion en continu.
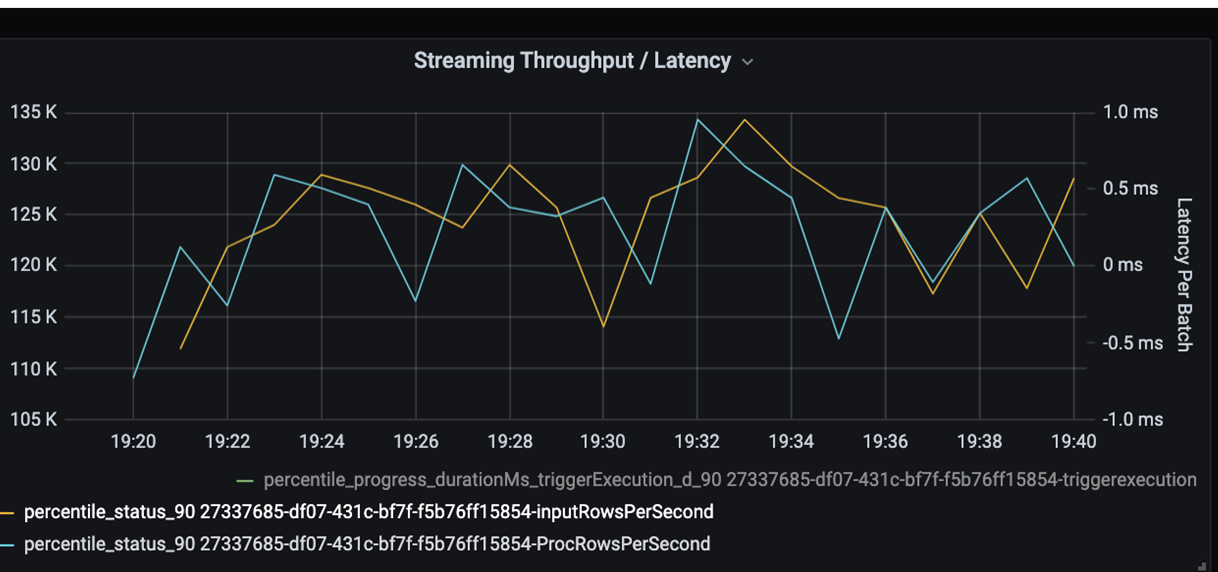
Dans le graphique de débit de diffusion en continu/latence de lot ci-dessus, la ligne orange représente le taux d’entrée (lignes d’entrée par seconde). La ligne bleue représente le taux de traitement (lignes traitées par seconde). À certains points, le taux de traitement ne rejoint pas le taux d’entrée. Le problème potentiel est que les fichiers d’entrée s’accumulent dans la file d’attente.
Étant donné que le taux de traitement ne correspond pas au taux d’entrée dans le graphique, cherchez à améliorer le taux de traitement pour couvrir complètement le taux d’entrée. Une raison possible est le déséquilibre des données client dans chaque clé de partition qui provoque un goulot d’étranglement. Pour une étape suivante et une solution potentielle, tirez parti de l’évolutivité d’Azure Databricks.
Examen du partitionnement
Tout d’abord, identifiez plus en détail le nombre correct d’exécuteurs de mise à l’échelle dont vous avez besoin avec Azure Databricks. Appliquez la règle de base de l’affectation de chaque partition à un processeur dédié dans les exécuteurs en cours d’exécution. Par exemple, si vous avez 200 clés de partition, le nombre de processeurs multiplié par le nombre d’exécuteurs doit être égal à 200. (Par exemple, huit processeurs combinés à 25 exécuteurs devraient constituer une bonne association.) Avec 200 clés de partition, chaque exécuteur ne peut travailler que sur une tâche, ce qui limite les risques de goulot d’étranglement.
Comme certaines partitions lentes se trouvent dans ce scénario, examinez la variation élevée dans la durée des tâches. Vérifiez les pics de la durée de la tâche. Une tâche gère une partition. Si une tâche nécessite plus de temps, il se peut que la partition soit trop volumineuse et provoque un goulot d’étranglement.
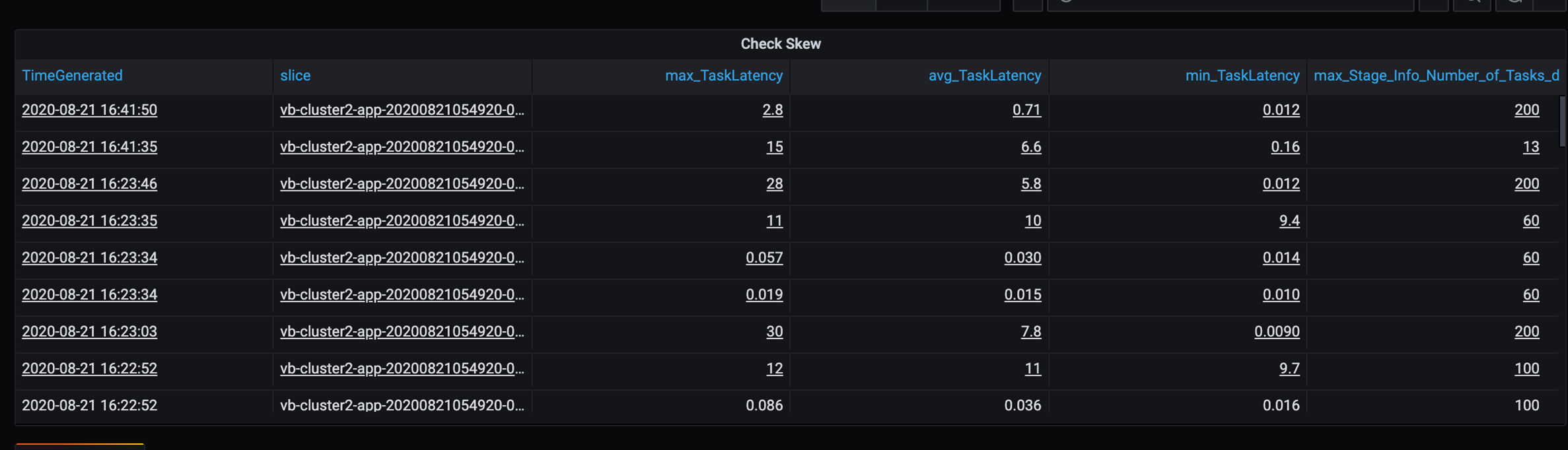
Suivi des erreurs
Ajoutez un tableau de bord pour le suivi des erreurs afin de pouvoir identifier les défaillances de données spécifiques au client. Dans le prétraitement des données, il peut arriver que des fichiers soient endommagés et que les enregistrements d’un fichier ne correspondent pas au schéma de données. Le tableau de bord suivant intercepte une grande quantité de fichiers et d’enregistrements incorrects.
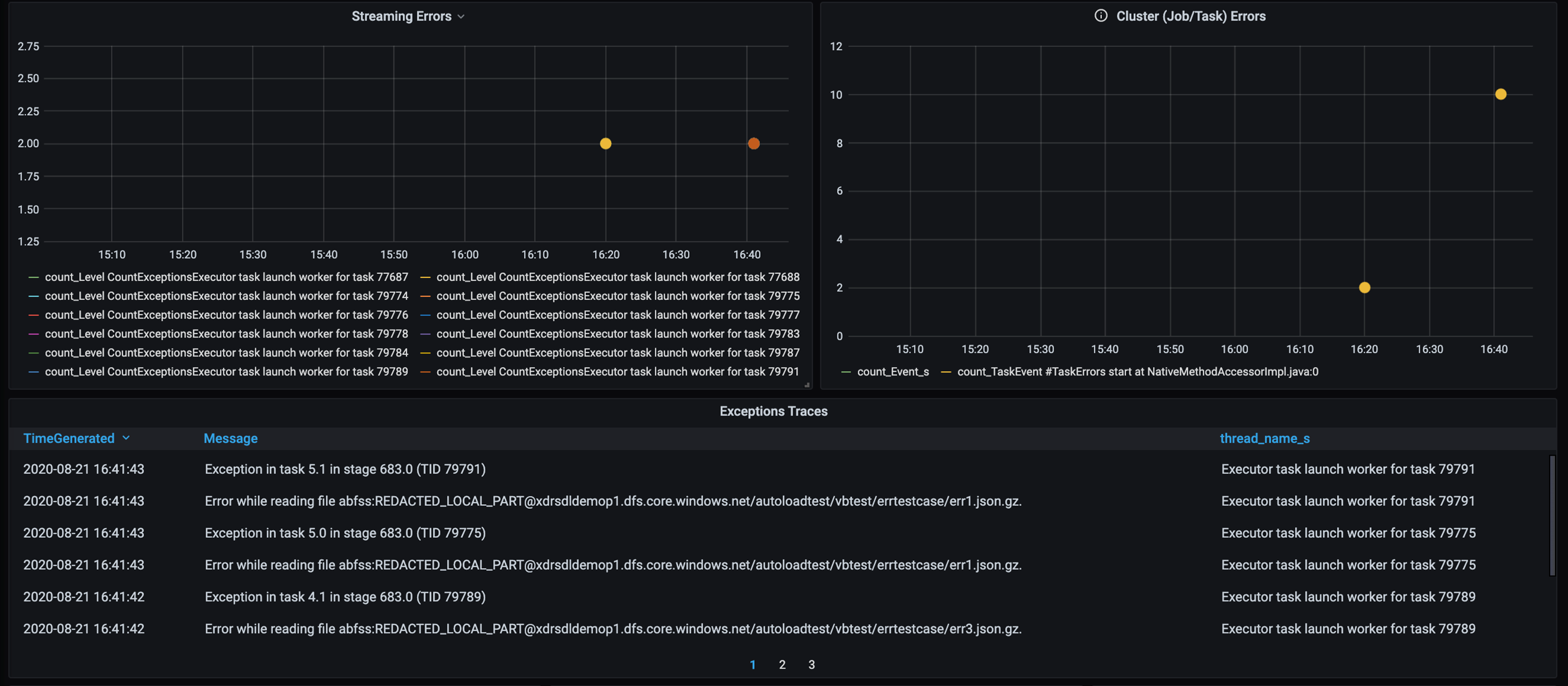
Ce tableau de bord affiche le nombre d’erreurs, le message d’erreur et l’ID de tâche à des fins de débogage. Dans le message, vous pouvez facilement remonter à l’erreur dans le fichier d’erreur. Plusieurs fichiers présentent des erreurs lors de la lecture. Vous examinez la chronologie supérieure et examinez les points spécifiques de notre graphique (16:20 et 16:40).
Autres goulots d’étranglement
Pour obtenir plus d’exemples et des conseils, consultez Résoudre les problèmes de goulot d’étranglement de performances dans Azure Databricks.
Résumé de l’évaluation de l’optimisation des performances
Pour ce scénario, ces mesures ont identifié les observations suivantes :
- Dans le graphique de latence des phases, les phases d’écriture prennent la majeure partie du temps de traitement.
- Dans le graphique de latence des tâches, la latence des tâches est stable.
- Dans le graphique de débit de diffusion en continu, le taux de sortie est inférieur au taux d’entrée à certains points.
- La table de durée des tâches présente une variation dans les tâches en raison du déséquilibre des données client.
- Pour optimiser les performances au cours de la phase de partitionnement, le nombre d’exécuteurs de mise à l’échelle doit correspondre au nombre de partitions.
- Il existe des erreurs de suivi, telles que des fichiers et des enregistrements incorrects.
Pour diagnostiquer ces problèmes, vous avez utilisé les mesures suivantes :
- Latence des travaux
- Latence des étapes
- Latence des travaux
- Débit de diffusion en continu
- Durée de la tâche (max, moyenne, min) par phase
- Suivi des erreurs (nombre, message, ID de tâche)
Contributeurs
Cet article est géré par Microsoft. Il a été écrit à l’origine par les contributeurs suivants.
Auteur principal :
- David McGhee | Responsable du programme principal
Pour afficher les profils LinkedIn non publics, connectez-vous à LinkedIn.
Étapes suivantes
- Lisez le Tutoriel Log Analytics.
- Surveillance d’Azure Databricks dans un espace de travail Azure Log Analytics
- Déploiement d’Azure Log Analytics avec les mesures Spark
- Modèles d’observabilité