Cet article décrit une approche particulière des projets d’entrepôt de données appelée Analyse exploratoire des données (EDA, Exploratory Data Analysis). Cette approche peut réduire les défis liés aux opérations d’extraction, de transformation et de chargement (ETL). Elle se concentre sur la génération d’insights métier, puis sur la résolution des tâches de modélisation et ETL.
Architecture

Téléchargez un fichier Visio de cette architecture.
Pour l’EDA, vous vous intéressez uniquement au côté droit du diagramme. Azure Synapse SQL serverless est utilisé en tant que moteur de calcul sur les fichiers du lac de données.
Pour effectuer une EDA :
- Les requêtes T-SQL s’exécutent directement dans Azure Synapse SQL serverless ou dans Azure Synapse Spark.
- Les requêtes s’exécutent à partir d’un outil de requête graphique tel que Power BI ou Azure Data Studio.
Nous vous recommandons de conserver toutes les données du lakehouse au moyen de Parquet ou de Delta.
Vous pouvez implémenter le côté gauche du diagramme (ingestion de données) avec n’importe quel outil d’extraction, de chargement et de transformation (ELT). Cela n’a aucun effet sur l’EDA.
Composants
Azure Synapse Analytics combine l’intégration de données, l’entreposage des données d’entreprise et l’analytique du Big Data sur les données du lakehouse. Contenu de cette solution :
- Un espace de travail Azure Synapse favorise la collaboration parmi les ingénieurs Données, les scientifiques des données, les analystes de données et les professionnels du décisionnel pour les tâches EDA.
- Les pools SQL serverless Azure Synapse analysent les données non structurées et semi-structurées dans Azure Data Lake Storage en utilisant le langage T-SQL standard.
- Les pools Apache Spark serverless Azure Synapse effectuent des explorations code-first dans Data Lake Storage en utilisant des langages Spark tels que Spark SQL, PySpark et Scala.
Azure Data Lake Storage fournit un espace de stockage pour les données qui sont ensuite analysées par les pools SQL serverless Azure Synapse.
Azure Machine Learning fournit des données à Azure Synapse Spark.
Power BI est utilisé dans cette solution pour interroger des données en vue d’effectuer l’EDA.
Autres solutions
Vous pouvez remplacer les pools SQL serverless Synapse SQL par Azure Databricks ou les compléter avec ce dernier.
Au lieu d’utiliser un modèle de lakehouse avec des pools SQL serverless Synapse SQL, vous pouvez utiliser des pools SQL dédiés Azure Synapse pour stocker les données d’entreprise. Passez en revue les cas d’usage et les éléments à prendre en considération présentés dans cet article et les ressources associées pour choisir la technologie à utiliser.
Détails du scénario
Cette solution montre une implémentation de l’approche EDA pour des projets d’entrepôt de données. Cette approche peut atténuer les défis liés aux opérations ETL. Elle se concentre d’abord sur la génération d’insights métier, puis sur la résolution des tâches de modélisation et ETL.
Cas d’usage potentiels
Autres scénarios qui peuvent tirer parti de ce modèle d’analytique :
Analytique normative. Posez des questions sur vos données, par exemple Quelle est la meilleure prochaine action ? ou Que faire ensuite ? Utilisez les données afin de vous baser davantage sur les données que sur votre intuition. Les données peuvent être non structurées et provenir de nombreuses sources externes de qualité variable. Vous pouvez utiliser les données aussi rapidement que possible pour évaluer votre stratégie métier sans réellement charger les données dans un entrepôt de données. Vous pouvez supprimer les données une fois que vous avez répondu à vos questions.
ETL Libre-service. Procédez à des opérations ETL/ELT quand vous effectuez vos activités de sandboxing de données (EDA). Transformez les données et rendez-les précieuses. Cela permet d’améliorer l’échelle de vos développeurs ETL.
À propos de l’analyse exploratoire des données
Avant de voir plus en détail le fonctionnement de l’EDA, il est intéressant de résumer l’approche traditionnelle des projets d’entrepôt de données. L’approche traditionnelle ressemble à ceci :
Collecte des exigences. Documenter les opérations à effectuer avec les données.
Modélisation de données. Déterminer comment modéliser les données numériques et d’attributs dans des tables de faits et de dimension. En règle générale, vous effectuez cette étape avant d’acquérir les nouvelles données.
ETL. Acquérir les données et les préparer en vue de les intégrer au modèle de données de l’entrepôt de données.
Ces étapes peuvent durer des semaines, voire des mois. Ensuite seulement, vous pouvez commencer à interroger les données et à résoudre le problème métier. L’utilisateur ne voit de la valeur qu’une fois les rapports créés. L’architecture de la solution est généralement similaire à celle-ci :
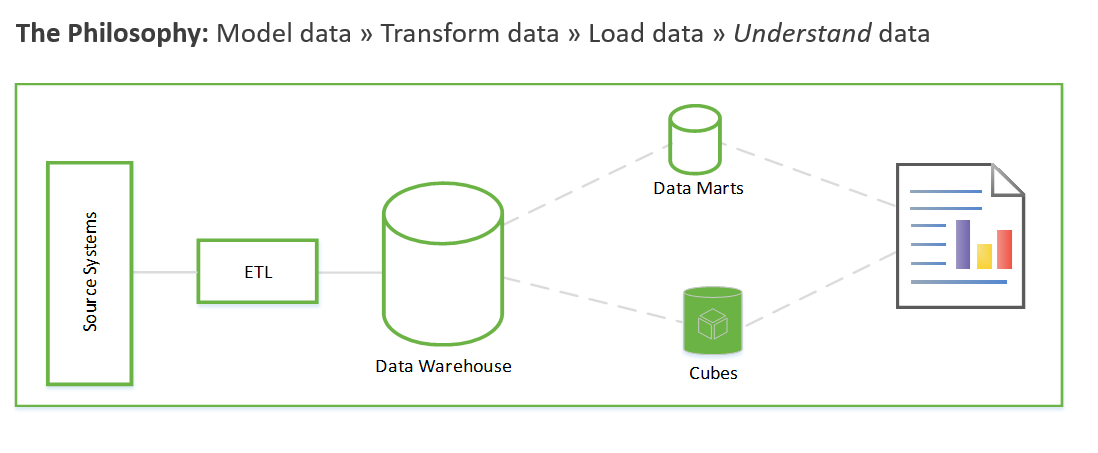
Vous pouvez adopter une autre approche qui se concentre sur la génération d’insights métier, puis sur la résolution des tâches de modélisation et ETL. Le processus est similaire aux processus de science des données. Voici ce à quoi elle ressemble :
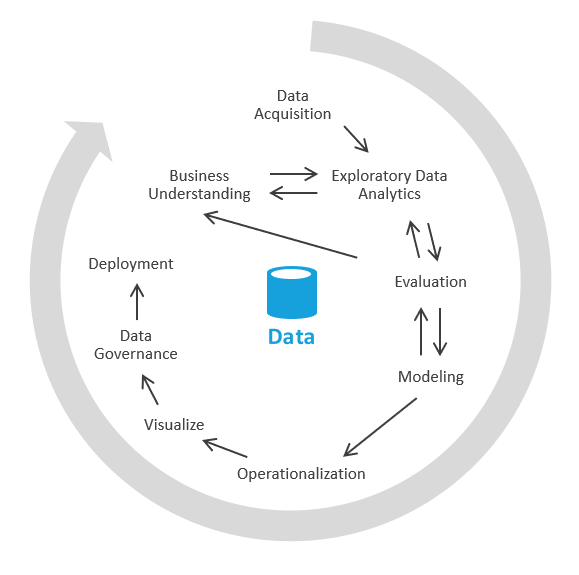
Dans le secteur, ce processus est appelé EDA ou Analyse exploratoire des données.
Voici les étapes à suivre :
Acquisition de données. Tout d’abord, vous devez déterminer les sources de données que vous devez ingérer dans votre lac de données/bac à sable. Vous devez ensuite placer ces données dans la zone de destination de votre lac. Azure fournit des outils tels qu’Azure Data Factory et Azure Logic Apps qui peuvent ingérer les données rapidement.
Sandboxing de données. Au départ, un analyste métier et un ingénieur expérimenté en analyse exploratoire des données avec Azure Synapse Analytics serverless ou des procédures SQL de base collaborent. Au cours de cette phase, ils tentent de mettre au jour l’insight métier en utilisant les nouvelles données. L’EDA un processus itératif. Vous devrez peut-être ingérer plus de données, communiquer avec des SME, poser des questions ou générer des visualisations.
Évaluation. Une fois que vous avez trouvé l’insight métier, vous devez évaluer les opérations à effectuer avec les données. Vous pouvez conserver les données dans l’entrepôt de données (ce qui vous permet de passer à la phase de modélisation). Dans d’autres cas, vous pouvez décider de conserver les données dans le lac de données/lakehouse et de les utiliser pour l’analyse prédictive (algorithmes de Machine Learning). Dans d’autres cas encore, vous pouvez décider de rétro-alimenter vos systèmes d’enregistrement avec les nouveaux insights. En fonction de ces décisions, vous pouvez mieux comprendre ce que vous devez faire ensuite. Vous n’avez peut-être pas besoin d’exécuter une opération ETL.
Ces méthodes sont le cœur de la véritable analytique libre-service. En utilisant le lac de données et un outil de requête comme Azure Synapse serverless qui comprend les modèles de requête de lac de données, vous pouvez mettre vos ressources de données entre les mains de professionnels ayant un minimum de connaissances en SQL. Vous pouvez raccourcir radicalement le temps de valorisation en utilisant cette méthode et supprimer certains risques associés aux initiatives de données d’entreprise.
Considérations
Ces considérations implémentent les piliers d’Azure Well-Architected Framework qui est un ensemble de principes directeurs qui permettent d’améliorer la qualité d’une charge de travail. Pour plus d’informations, consultez Microsoft Azure Well-Architected Framework.
Disponibilité
Les pools SQL serverless Azure Synapse constituent une fonctionnalité PaaS (platform as a service) qui peut répondre à vos exigences en matière de haute disponibilité (HA) et de reprise d’activité (DR).
Les pools serverless sont disponibles à la demande. Ils ne nécessitent strictement aucune opération de scale-up, scale-down, scale-in, scale-out ou d’administration. Ils utilisent un modèle de paiement par requête, de sorte qu’il n’y a jamais de capacité inutilisée. Les pools serverless sont idéaux pour les scénarios suivants :
- Explorations de science des données ad hoc en T-SQL.
- Prototypage précoce pour les entités d’entrepôt de données.
- Définition de vues que les consommateurs peuvent utiliser, par exemple dans Power BI, pour les scénarios qui peuvent tolérer un décalage des performances.
- Analyse exploratoire des données.
Operations
Synapse SQL serverless utilise T-SQL standard pour l’interrogation et les opérations. Vous pouvez utiliser l’interface utilisateur de l’espace de travail Synapse, Azure Data Studio ou SQL Server Management Studio comme outil T-SQL.
Optimisation des coûts
L’optimisation des coûts consiste à examiner les moyens de réduire les dépenses inutiles et d’améliorer l’efficacité opérationnelle. Pour plus d’informations, consultez Vue d’ensemble du pilier d’optimisation des coûts.
La tarification Data Lake Storage dépend de la quantité de données que vous stockez et de la fréquence à laquelle vous utilisez ces données. L’exemple de tarif inclut 1 To de données stockées, avec d’autres hypothèses transactionnelles. 1 To fait référence à la taille du lac de données, et non à la taille de la base de données héritée initiale.
Le pool Azure Synapse Spark est facturé en fonction de la taille des nœuds, du nombre d’instances et de la durée de fonctionnement. L’exemple suppose un petit nœud de calcul avec une utilisation comprise entre cinq heures par semaine et 40 heures par mois.
La tarification des pools SQL serverless Azure Synapse est basée sur les To de données traitées. L’exemple se base sur 50 To traités par mois. Ce chiffre fait référence à la taille du lac de données, et non à la taille de la base de données héritée initiale.
Contributeurs
Cet article est mis à jour et géré par Microsoft. Il a été écrit à l’origine par les contributeurs suivants.
Auteurs principaux :
- Dave Wentzel | Architecte technique MTC principal
Étapes suivantes
- Parcours d’apprentissage pour les ingénieurs Données
- Tutoriel : Bien démarrer avec Azure Synapse Analytics
- Créer une base de données unique - Azure SQL Database
- Architecture Azure Synapse SQL
- Créer un compte de stockage pour Azure Data Lake Storage
- Démarrage rapide Azure Event Hubs - Créer un Event Hub en utilisant le portail Azure
- Démarrage rapide – Créer un travail Stream Analytics avec le portail Azure
- Démarrage rapide : Bien démarrer avec Azure Machine Learning