Apache Ambari Hive-nézet használata Apache Hadooppal a HDInsightban
Megtudhatja, hogyan futtathat Hive-lekérdezéseket az Apache Ambari Hive View használatával. A Hive nézet lehetővé teszi Hive-lekérdezések készítését, optimalizálását és futtatását a webböngészőből.
Előfeltételek
Hadoop-fürt a HDInsighton. Tekintse meg a HDInsight linuxos használatának első lépéseit.
Hive-lekérdezések futtatása
Az Azure Portalon válassza ki a fürtöt. Útmutatásért tekintse meg a fürtök listáját és megjelenítését. A fürt új portálnézetben nyílik meg.
A fürt irányítópultjai közül válassza az Ambari-nézeteket. Amikor a rendszer kéri a hitelesítést, használja a fürt létrehozásakor megadott (alapértelmezett
admin) fióknevet és jelszót. A böngészőben arra is navigálhathttps://CLUSTERNAME.azurehdinsight.net/#/main/views, hogy holCLUSTERNAMEtalálható a fürt neve.A nézetek listájában válassza a Hive Nézet lehetőséget.
A Hive nézet lapja a következő képhez hasonló:
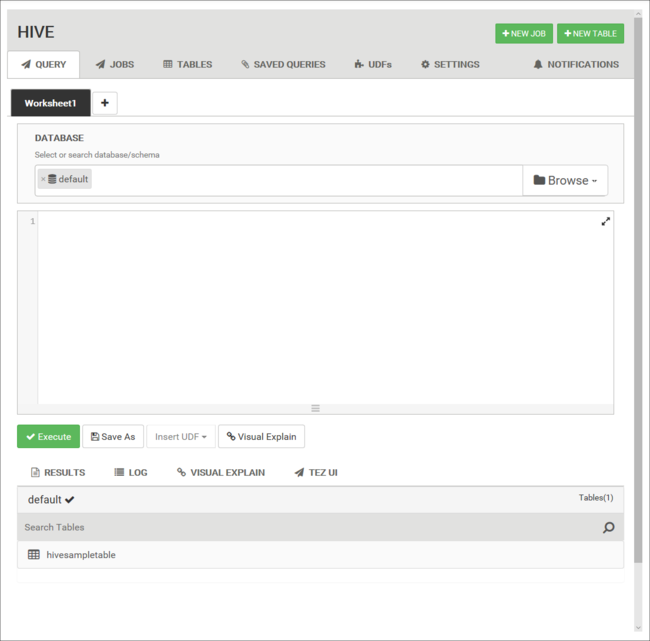
A Lekérdezés lapon illessze be a következő HiveQL-utasításokat a munkalapra:
DROP TABLE log4jLogs; CREATE EXTERNAL TABLE log4jLogs( t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/example/data/'; SELECT t4 AS loglevel, COUNT(*) AS count FROM log4jLogs WHERE t4 = '[ERROR]' GROUP BY t4;Ezek az utasítások a következő műveleteket hajtják végre:
Utasítás Leírás DROP TABLE Törli a táblát és az adatfájlt, ha a tábla már létezik. KÜLSŐ TÁBLA LÉTREHOZÁSA Létrehoz egy új "külső" táblát a Hive-ben. A külső táblák csak a Hive-ben tárolják a tábladefiníciót. Az adatok az eredeti helyen maradnak. SORFORMÁTUM Az adatok formázásának módját mutatja be. Ebben az esetben az egyes naplók mezőit szóköz választja el egymástól. SZÖVEGFÁJL HELYEKÉNT TÁROLVA Megjeleníti az adatok tárolásának helyét, valamint azt, hogy az adatok szövegként vannak tárolva. SELECT Kiválasztja az összes olyan sor számát, ahol a t4 oszlop tartalmazza a [HIBA] értéket. Fontos
Hagyja az adatbázis-kijelölést az alapértelmezett értéken. A dokumentumban szereplő példák a HDInsight alapértelmezett adatbázisát használják.
A lekérdezés elindításához válassza a Munkalap alatti Végrehajtás lehetőséget . A gomb narancssárgára változik, a szöveg pedig leállításra változik.
A lekérdezés befejezése után az Eredmények lap megjeleníti a művelet eredményeit. A lekérdezés eredménye a következő szöveg:
loglevel count [ERROR] 3A LOG lapon megtekintheti a feladat által létrehozott naplózási adatokat.
Tipp.
Töltse le vagy mentse az eredményeket az Eredmények lap Műveletek legördülő listájából.
Vizualizációs magyarázat
A lekérdezésterv vizualizációjának megjelenítéséhez válassza a Munkalap alatti Vizualizáció magyarázata lapot.
A lekérdezés vizualizációs magyarázó nézete hasznos lehet az összetett lekérdezések folyamatának megértésében.
Tez felhasználói felület
A lekérdezés Tez felhasználói felületének megjelenítéséhez válassza a munkalap alatti Tez felhasználói felület lapot.
Fontos
A Tez nem használható az összes lekérdezés feloldására. A Tez használata nélkül számos lekérdezést meg lehet oldani.
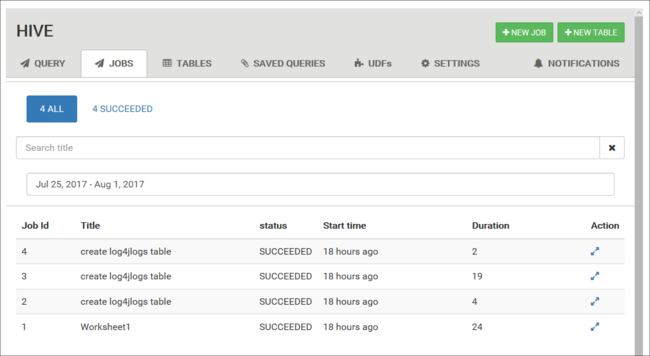
Feladatelőzmények megtekintése
A Feladatok lapon a Hive-lekérdezések előzményei láthatók.
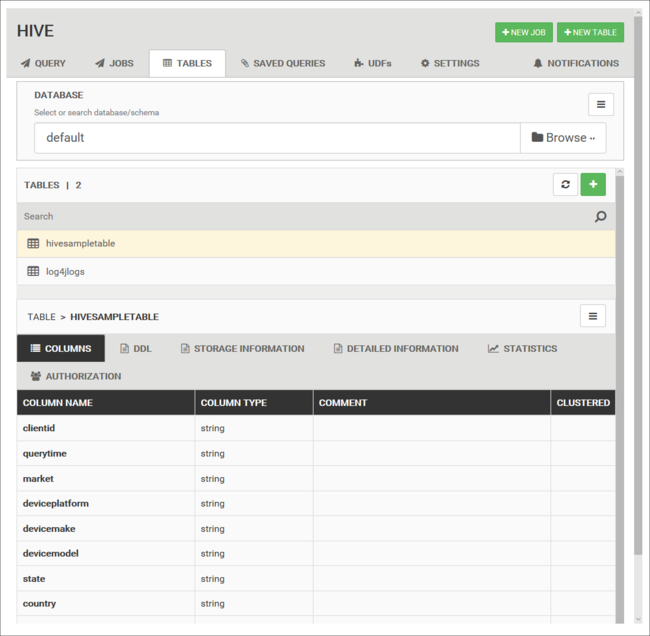
Adatbázistáblák
A Táblák lapon a Hive-adatbázisban lévő táblákkal dolgozhat.
Mentett lekérdezések
A Lekérdezés lapon igény szerint mentheti a lekérdezéseket. Miután mentett egy lekérdezést, újra felhasználhatja a Mentett lekérdezések lapon.
Tipp.
A mentett lekérdezések az alapértelmezett fürttárolóban vannak tárolva. A mentett lekérdezéseket az elérési út /user/<username>/hive/scriptsalatt találja. Ezek egyszerű szöveges .hql fájlokként vannak tárolva.
Ha törli a fürtöt, de megtartja a tárterületet, használhat egy olyan segédprogramot, mint az Azure Storage Explorer vagy a Data Lake Storage Explorer (az Azure Portalról) a lekérdezések lekéréséhez.
Felhasználó által definiált függvények
A Hive-t felhasználó által definiált függvényekkel (UDF) bővítheti. UDF használatával olyan funkciókat vagy logikát valósíthat meg, amelyek nem könnyen modelleződnek a HiveQL-ben.
Deklarálhat és menthet egy UDF-készletet a Hive nézet tetején található UDF lap használatával. Ezek az UDF-ek a Lekérdezésszerkesztő használhatók.
Megjelenik az udfs beszúrása gomb a Lekérdezésszerkesztő alján. Ez a bejegyzés megjeleníti a Hive nézetben definiált UDF-ek legördülő listáját. Ha kiválaszt egy UDF-et, hiveQL-utasításokat ad hozzá a lekérdezéshez az UDF engedélyezéséhez.
Ha például definiált egy UDF-et a következő tulajdonságokkal:
Erőforrás neve: myudfs
Erőforrás elérési útja: /myudfs.jar
UDF neve: myawesomeudf
UDF-osztály neve: com.myudfs.Awesome
Az udfs beszúrása gombbal megjelenik egy myudfs nevű bejegyzés, amely egy másik legördülő listával rendelkezik az adott erőforráshoz definiált egyes UDF-ekhez. Ebben az esetben ez myawesomeudf. Ha ezt a bejegyzést választja, a következőt adja hozzá a lekérdezés elejéhez:
add jar /myudfs.jar;
create temporary function myawesomeudf as 'com.myudfs.Awesome';
Ezután használhatja az UDF-et a lekérdezésben. Például: SELECT myawesomeudf(name) FROM people;.
Az UDF-ek HDInsighton futó Hive-lel való használatáról az alábbi cikkekben talál további információt:
- Python használata Az Apache Hive és az Apache Pig használatával a HDInsightban
- Java UDF használata az Apache Hive-lel a HDInsightban
Hive-beállítások
Módosíthatja a Hive különböző beállításait, például a Hive végrehajtási motorját tezről (alapértelmezett) MapReduce-re.
Következő lépések
A HDInsighton futó Hive-re vonatkozó általános információk: