Come creare un progetto di classificazione del testo personalizzato
Articolo
Usare questo articolo per informazioni su come configurare i requisiti per iniziare con la classificazione del testo personalizzata e creare un progetto.
Prerequisiti
Prima di iniziare a usare la classificazione del testo personalizzata, è necessario:
Prima di iniziare a usare la classificazione del testo personalizzata, è necessaria una risorsa del linguaggio di intelligenza artificiale di Azure. È consigliabile creare la risorsa lingua e connetterla a un account di archiviazione nel portale di Azure. La creazione di una risorsa nella portale di Azure consente di creare contemporaneamente un account di archiviazione di Azure, con tutte le autorizzazioni necessarie preconfigurato. È anche possibile leggere ulteriormente l'articolo per informazioni su come usare una risorsa preesistente e configurarla per l'uso della classificazione del testo personalizzata.
Sarà anche necessario un account di archiviazione di Azure in cui verranno caricati i .txt documenti che verranno usati per eseguire il training di un modello per classificare il testo.
Nota
Per creare una risorsa lingua, è necessario avere un ruolo di proprietario assegnato nel gruppo di risorse.
Se si connetterà un account di archiviazione preesistente, è necessario assegnare un ruolo di proprietario .
Creare una risorsa lingua e connettere l'account di archiviazione
Nota
Non è consigliabile spostare l'account di archiviazione in un gruppo di risorse o una sottoscrizione diverso dopo che è collegato alla risorsa Lingua.
Passare alla portale di Azure per creare una nuova risorsa del linguaggio di intelligenza artificiale di Azure.
Nella finestra visualizzata selezionare Classificazione testo personalizzata e riconoscimento di entità denominate personalizzate dalle funzionalità personalizzate. Selezionare Continua per creare la risorsa nella parte inferiore della schermata .
Creare una risorsa lingua con i dettagli seguenti.
Nome
Valore obbligatorio
Abbonamento
La sottoscrizione di Azure.
Gruppo di risorse
Gruppo di risorse che conterrà la risorsa. È possibile usare uno esistente o crearne uno nuovo.
Area
Una delle aree supportate. Ad esempio, "Stati Uniti occidentali 2".
Nome
Nome della risorsa.
Piano tariffario
Uno dei piani tariffari supportati. È possibile usare il livello Gratuito (F0) per provare il servizio.
Se viene visualizzato un messaggio che indica che l'account di accesso non è un proprietario del gruppo di risorse dell'account di archiviazione selezionato, l'account deve avere un ruolo di proprietario assegnato nel gruppo di risorse prima di poter creare una risorsa lingua. Per assistenza, contattare il proprietario della sottoscrizione di Azure.
È possibile determinare il proprietario della sottoscrizione di Azure eseguendo una ricerca nel gruppo di risorse e seguendo il collegamento alla sottoscrizione associata. Quindi:
Selezionare la scheda Controllo di accesso (IAM)
Selezionare Assegnazioni di ruolo
Filtrare in base a Role:Owner.
Nella sezione Classificazione testo personalizzata e riconoscimento di entità denominate personalizzate selezionare un account di archiviazione esistente o selezionare Nuovo account di archiviazione. Si noti che questi valori consentono di iniziare e non necessariamente i valori dell'account di archiviazione da usare negli ambienti di produzione. Per evitare la latenza durante la compilazione del progetto, connettersi agli account di archiviazione nella stessa area della risorsa lingua.
Archiviazione valore dell'account
Valore consigliato
Nome account di archiviazione
Qualsiasi nome
Storage account type
LRS Standard
Assicurarsi che sia selezionata l'informativa sull'intelligenza artificiale responsabile. Selezionare Rivedi e crea nella parte inferiore della pagina.
Creare una nuova risorsa lingua da Language Studio
Se è la prima volta che si accede, verrà visualizzata una finestra in Language Studio che consentirà di scegliere una risorsa lingua esistente o crearne una nuova. È anche possibile creare una risorsa facendo clic sull'icona delle impostazioni nell'angolo in alto a destra, selezionando Risorse e quindi facendo clic su Crea una nuova risorsa.
Creare una risorsa lingua con i dettagli seguenti.
Assicurarsi di abilitare l'identità gestita quando si crea una risorsa lingua.
Leggere e confermare l'avviso di IA responsabile
Per usare la classificazione del testo personalizzata, è necessario connettere la risorsa a un account di archiviazione. Se non ne è disponibile uno, è possibile creare un account di archiviazione di Azure. Usare la procedura seguente per creare il primo progetto e connettere l'account di archiviazione.
Accedere a Language Studio. Verrà visualizzata una finestra che consente di selezionare la sottoscrizione e la risorsa lingua. Selezionare la risorsa Lingua.
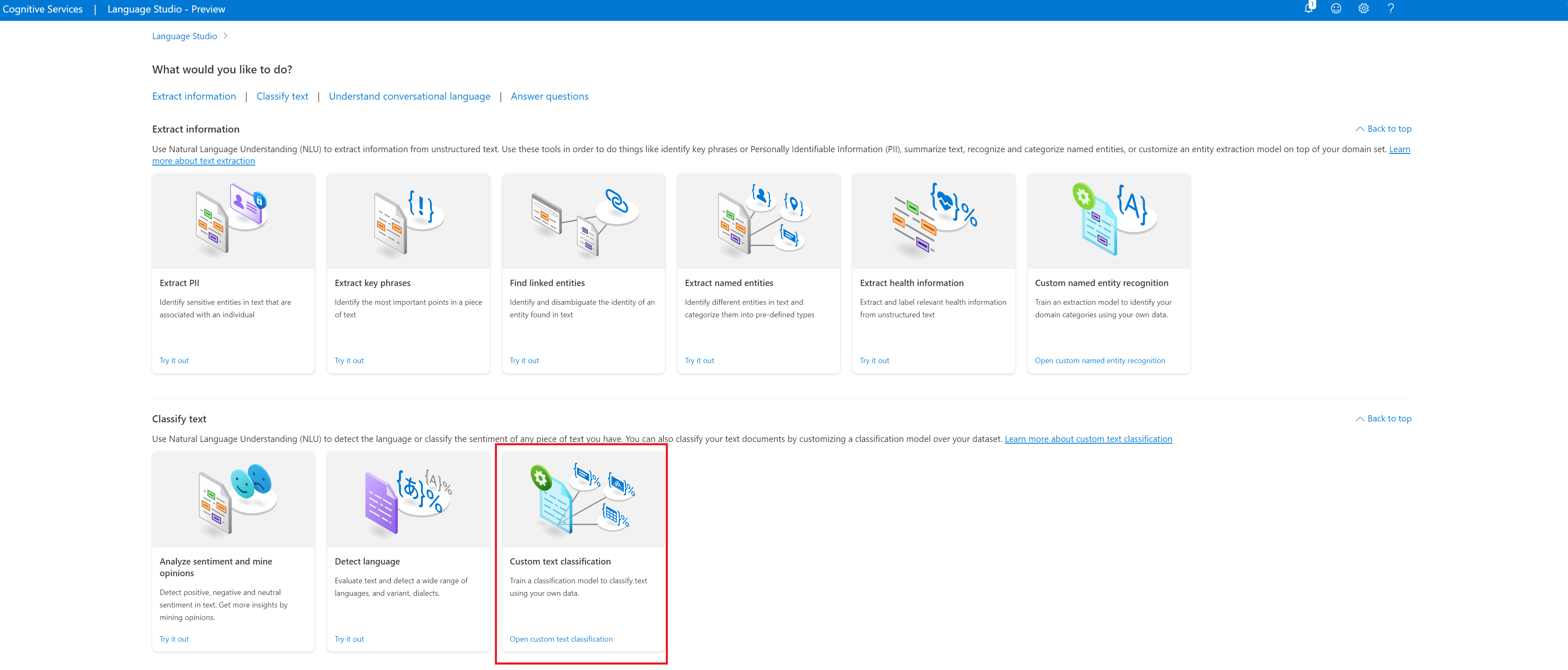
Nella sezione Classifica testo di Language Studio selezionare Classificazione testo personalizzata.
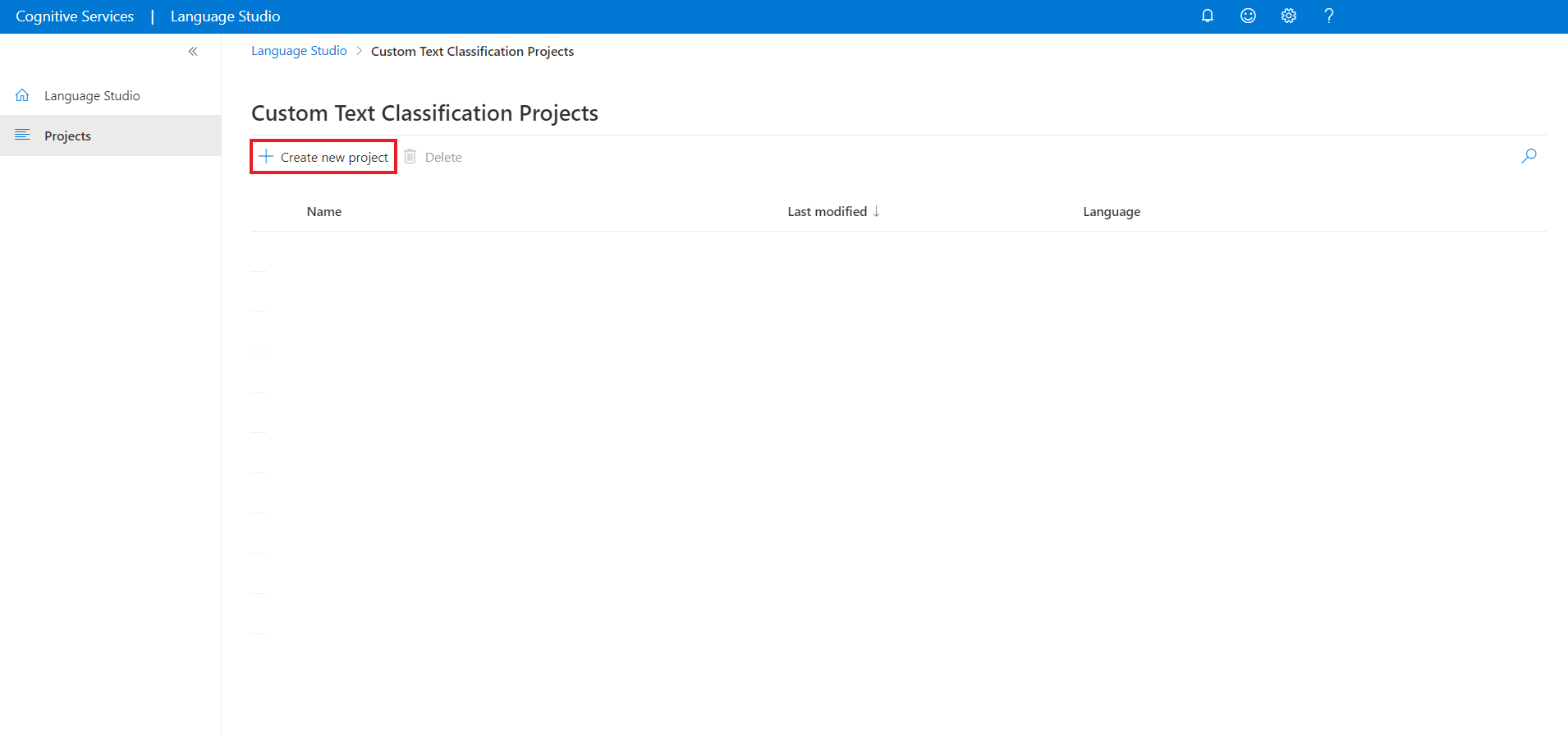
Selezionare Crea nuovo progetto dal menu in alto nella pagina dei progetti. La creazione di un progetto consentirà di etichettare i dati, eseguire il training, valutare, migliorare e distribuire i modelli.
Dopo aver fatto clic su Crea nuovo progetto, verrà visualizzata una finestra per consentire la connessione dell'account di archiviazione. Se è già stato connesso un account di archiviazione, verrà visualizzato l'account di archiviazione connesso. In caso contrario, scegliere l'account di archiviazione dall'elenco a discesa visualizzato e selezionare Connessione account di archiviazione. Verranno impostati i ruoli necessari per l'account di archiviazione. Questo passaggio restituirà un errore se non si è assegnati come proprietario nell'account di archiviazione.
Nota
È necessario eseguire questo passaggio una sola volta per ogni nuova risorsa di lingua usata.
Questo processo è irreversibile, se si connette un account di archiviazione alla risorsa lingua, non è possibile disconnetterlo in un secondo momento.
È possibile connettere la risorsa lingua solo a un account di archiviazione.
Selezionare il tipo di progetto. È possibile creare un progetto di classificazione con più etichette in cui ogni documento può appartenere a una o più classi o a un progetto di classificazione con etichetta singola in cui ogni documento può appartenere a una sola classe. Il tipo selezionato non può essere modificato in un secondo momento. Altre informazioni sui tipi di progetto
Immettere le informazioni sul progetto, inclusi un nome, una descrizione e la lingua dei documenti nel progetto. Se si usa il set di dati di esempio, selezionare Inglese. Non sarà possibile modificare il nome del progetto in un secondo momento. Seleziona Avanti.
Suggerimento
Il set di dati non deve essere interamente nello stesso linguaggio. È possibile avere più documenti, ognuno con lingue supportate diverse. Se il set di dati contiene documenti di lingue diverse o se si prevede testo da lingue diverse durante il runtime, selezionare l'opzione Abilita set di dati multilingue quando si immettono le informazioni di base per il progetto. Questa opzione può essere abilitata in un secondo momento dalla pagina Impostazioni progetto.
Selezionare il contenitore in cui è stato caricato il set di dati.
Nota
Se i dati sono già stati etichettati, assicurarsi che seguano il formato supportato e selezionare Sì, i documenti sono già etichettati e ho formattato il file di etichette JSON e selezionare il file delle etichette dal menu a discesa seguente.
Se si usa uno dei set di dati di esempio, usare il file incluso webOfScience_labelsFile o movieLabels json. Quindi seleziona Avanti.
Esaminare i dati immessi e selezionare Crea progetto.
È possibile creare una nuova risorsa e un account di archiviazione usando il modello e i file di parametri dell'interfaccia della riga di comando seguenti, ospitati in GitHub.
Modificare i valori seguenti nel file dei parametri:
Nome parametro
Descrizione valore
name
Nome della risorsa lingua
location
Area in cui è ospitata la risorsa. Per altre informazioni, vedere Supporto dell'area.
sku
Piano tariffario della risorsa. Per altre informazioni, vedere Limiti del servizio.
storageResourceName
Nome dell'account di archiviazione
storageLocation
Area in cui è ospitato l'account di archiviazione.
storageSkuType
SKU dell'account di archiviazione.
storageResourceGroupName
Gruppo di risorse dell'account di archiviazione
Usare il comando di PowerShell seguente per distribuire il modello di Azure Resource Manager (ARM) con i file modificati.
Per informazioni sulla distribuzione di modelli e file di parametri, vedere la documentazione del modello di Resource Manager.
Nota
Il processo di connessione di un account di archiviazione alla risorsa lingua è irreversibile e non può essere disconnesso in un secondo momento.
È possibile connettere la risorsa di lingua solo a un account di archiviazione.
Uso di una risorsa language preesistente
Requisito
Descrizione
Aree
Assicurarsi che il provisioning della risorsa esistente venga eseguito in una delle aree supportate. Se non si dispone di una risorsa, sarà necessario crearne uno nuovo in un'area supportata.
La risorsa lingua deve avere la gestione delle identità per abilitarla usando portale di Azure:
Passare alla risorsa lingua
Nel menu a sinistra, nella sezione Gestione risorse selezionare Identità
Dalla scheda Assegnata dal sistema assicurarsi di impostare Stato su Sì
La risorsa lingua deve avere la gestione delle identità per abilitarla tramite Language Studio:
Selezionare l'icona delle impostazioni nell'angolo superiore destro della schermata
Selezionare risorse
Selezionare la casella di controllo Identità gestita per la risorsa del linguaggio di intelligenza artificiale di Azure.
Abilitare la funzionalità di classificazione del testo personalizzata
Assicurarsi di abilitare la funzionalità Di classificazione testo personalizzata/Riconoscimento di entità denominate personalizzata da portale di Azure.
Nel menu a sinistra, nella sezione Gestione risorse selezionare Funzionalità
Abilitare la funzionalità di classificazione del testo personalizzata/Riconoscimento di entità denominate personalizzate
Connessione l'account di archiviazione
Selezionare Applica.
Importante
Assicurarsi che alla risorsa di linguaggio sia assegnato il ruolo collaboratore ai dati dei BLOB di archiviazione nell'account di archiviazione che si connette.
Impostare i ruoli per la risorsa del linguaggio di intelligenza artificiale di Azure e l'account di archiviazione
Usare la procedura seguente per impostare i ruoli necessari per la risorsa lingua e l'account di archiviazione.
Ruoli per la risorsa del linguaggio di intelligenza artificiale di Azure
Passare alla risorsa dell'account di archiviazione o della lingua nel portale di Azure.
Selezionare Controllo di accesso (IAM) nel menu di spostamento a sinistra.
Selezionare Aggiungi per aggiungere assegnazioni di ruolo e scegliere il ruolo appropriato per l'account.
È necessario avere il ruolo di proprietario o collaboratore assegnato nella risorsa Lingua.
In Assegna accesso a selezionare Utente, gruppo o entità servizio
Selezionare Seleziona membri
Selezionare il nome utente. È possibile cercare i nomi utente nel campo Seleziona . Ripetere questa operazione per tutti i ruoli.
Ripetere questi passaggi per tutti gli account utente che devono accedere a questa risorsa.
Ruoli per l'account di archiviazione
Passare alla pagina dell'account di archiviazione nel portale di Azure.
Selezionare Controllo di accesso (IAM) nel menu di spostamento a sinistra.
Selezionare Aggiungi per aggiungere assegnazioni di ruolo e scegliere il ruolo collaboratore ai dati BLOB Archiviazione nell'account di archiviazione.
In Assegna accesso a selezionare Identità gestita.
Selezionare Seleziona membri
Selezionare la sottoscrizione e Lingua come identità gestita. È possibile cercare i nomi utente nel campo Seleziona .
Importante
Se si dispone di una rete virtuale o di un endpoint privato, assicurarsi di selezionare Consenti ai servizi di Azure nell'elenco dei servizi attendibili di accedere a questo account di archiviazione nel portale di Azure.
Abilitare CORS per l'account di archiviazione
Assicurarsi di consentire i metodi (GET, PUT, DELETE) quando si abilita la condivisione di risorse tra le origini (CORS).
Impostare il campo origini consentite su https://language.cognitive.azure.com. Consenti tutte le intestazioni aggiungendo * ai valori di intestazione consentiti e impostando la validità massima su 500.
Creare un progetto di classificazione personalizzata del testo
Dopo aver configurato la risorsa e il contenitore di archiviazione, creare un nuovo progetto di classificazione del testo personalizzato. Un progetto è un'area di lavoro per la creazione di modelli di intelligenza artificiale personalizzati basati sui dati. È possibile accedere al progetto solo dall'utente e da altri utenti che hanno accesso alla risorsa di Azure usata. Se sono stati etichettati dati, è possibile importarli per iniziare.
Accedere a Language Studio. Verrà visualizzata una finestra che consente di selezionare la sottoscrizione e la risorsa lingua. Selezionare la risorsa Lingua.
Nella sezione Classifica testo di Language Studio selezionare Classificazione testo personalizzata.
Selezionare Crea nuovo progetto dal menu in alto nella pagina dei progetti. La creazione di un progetto consentirà di etichettare i dati, eseguire il training, valutare, migliorare e distribuire i modelli.
Dopo aver fatto clic su Crea nuovo progetto, verrà visualizzata una finestra per consentire la connessione dell'account di archiviazione. Se è già stato connesso un account di archiviazione, verrà visualizzato l'account di archiviazione connesso. In caso contrario, scegliere l'account di archiviazione dall'elenco a discesa visualizzato e selezionare Connessione account di archiviazione. Verranno impostati i ruoli necessari per l'account di archiviazione. Questo passaggio restituirà un errore se non si è assegnati come proprietario nell'account di archiviazione.
Nota
È necessario eseguire questo passaggio una sola volta per ogni nuova risorsa di lingua usata.
Questo processo è irreversibile, se si connette un account di archiviazione alla risorsa lingua, non è possibile disconnetterlo in un secondo momento.
È possibile connettere la risorsa lingua solo a un account di archiviazione.
Selezionare il tipo di progetto. È possibile creare un progetto di classificazione con più etichette in cui ogni documento può appartenere a una o più classi o a un progetto di classificazione con etichetta singola in cui ogni documento può appartenere a una sola classe. Il tipo selezionato non può essere modificato in un secondo momento. Altre informazioni sui tipi di progetto
Immettere le informazioni sul progetto, inclusi un nome, una descrizione e la lingua dei documenti nel progetto. Se si usa il set di dati di esempio, selezionare Inglese. Non sarà possibile modificare il nome del progetto in un secondo momento. Seleziona Avanti.
Suggerimento
Il set di dati non deve essere interamente nello stesso linguaggio. È possibile avere più documenti, ognuno con lingue supportate diverse. Se il set di dati contiene documenti di lingue diverse o se si prevede testo da lingue diverse durante il runtime, selezionare l'opzione Abilita set di dati multilingue quando si immettono le informazioni di base per il progetto. Questa opzione può essere abilitata in un secondo momento dalla pagina Impostazioni progetto.
Selezionare il contenitore in cui è stato caricato il set di dati.
Nota
Se i dati sono già stati etichettati, assicurarsi che seguano il formato supportato e selezionare Sì, i documenti sono già etichettati e ho formattato il file di etichette JSON e selezionare il file delle etichette dal menu a discesa seguente.
Se si usa uno dei set di dati di esempio, usare il file incluso webOfScience_labelsFile o movieLabels json. Quindi seleziona Avanti.
Esaminare i dati immessi e selezionare Crea progetto.
Per iniziare a creare un modello di classificazione del testo personalizzato, è necessario creare un progetto. La creazione di un progetto consentirà di etichettare i dati, eseguire il training, valutare, migliorare e distribuire i modelli.
Nota
Il nome del progetto fa distinzione tra maiuscole e minuscole per tutte le operazioni.
Creare una richiesta PATCH usando l'URL, le intestazioni e il corpo JSON seguenti per creare il progetto.
Richiesta URL
Usare l'URL seguente per creare un progetto. Sostituire i valori segnaposto seguenti con i propri valori.
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole.
myProject
{API-VERSION}
Versione dell'API che si sta chiamando. Il valore a cui viene fatto riferimento è relativo alla versione più recente rilasciata. Per altre informazioni sulle altre versioni dell'API disponibili, vedere Ciclo di vita del modello.
2022-05-01
Intestazioni
Usare l'intestazione seguente per autenticare la richiesta.
Chiave
valore
Ocp-Apim-Subscription-Key
Chiave della risorsa. Usato per l'autenticazione delle richieste API.
Corpo
Usare il codice JSON seguente nella richiesta. Sostituire i valori segnaposto seguenti con i propri valori.
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole.
myProject
lingua
{LANGUAGE-CODE}
Stringa che specifica il codice della lingua per i documenti usati nel progetto. Se il progetto è un progetto multilingue, scegliere il codice linguistico della maggior parte dei documenti. Per altre informazioni sui codici linguistici supportati, vedere Supporto linguistico.
en-us
projectKind
customMultiLabelClassification
Tipo di progetto.
customMultiLabelClassification
Multilingue
true
Valore booleano che consente di avere documenti in più lingue nel set di dati e quando il modello viene distribuito, è possibile eseguire query sul modello in qualsiasi linguaggio supportato (non necessariamente incluso nei documenti di training. Per altre informazioni sul supporto multilingue, vedere Supporto linguistico.
true
storageInputContainerName
{CONTAINER-NAME}
Nome del contenitore di archiviazione di Azure in cui sono stati caricati i documenti.
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole.
myProject
lingua
{LANGUAGE-CODE}
Stringa che specifica il codice della lingua per i documenti usati nel progetto. Se il progetto è un progetto multilingue, scegliere il codice linguistico della maggior parte dei documenti. Per altre informazioni sui codici linguistici supportati, vedere Supporto linguistico.
en-us
projectKind
customSingleLabelClassification
Tipo di progetto.
customSingleLabelClassification
Multilingue
true
Valore booleano che consente di avere documenti in più lingue nel set di dati e quando il modello viene distribuito, è possibile eseguire query sul modello in qualsiasi linguaggio supportato (non necessariamente incluso nei documenti di training. Per altre informazioni sul supporto multilingue, vedere Supporto linguistico.
true
storageInputContainerName
{CONTAINER-NAME}
Nome del contenitore di archiviazione di Azure in cui sono stati caricati i documenti.
myContainer
Questa richiesta restituirà una risposta 201, il che significa che il progetto viene creato.
Questa richiesta restituirà un errore se:
La risorsa selezionata non dispone dell'autorizzazione appropriata per l'account di archiviazione.
Importare un progetto di classificazione del testo personalizzato
Se i dati sono già etichettati, è possibile usarli per iniziare a usare il servizio. Assicurarsi che i dati etichettati seguano i formati di dati accettati.
Accedere a Language Studio. Verrà visualizzata una finestra che consente di selezionare la sottoscrizione e la risorsa lingua. Selezionare la risorsa Lingua.
Nella sezione Classifica testo di Language Studio selezionare Classificazione testo personalizzata.
Selezionare Crea nuovo progetto dal menu in alto nella pagina dei progetti. La creazione di un progetto consentirà di etichettare i dati, eseguire il training, valutare, migliorare e distribuire i modelli.
Dopo aver selezionato Crea nuovo progetto, verrà visualizzata una schermata che consente di connettere l'account di archiviazione. Se non è possibile trovare l'account di archiviazione, assicurarsi di aver creato una risorsa usando la procedura consigliata. Se è già stato connesso un account di archiviazione alla risorsa lingua, verrà visualizzato l'account di archiviazione connesso.
Nota
È necessario eseguire questo passaggio una sola volta per ogni nuova risorsa di lingua usata.
Questo processo è irreversibile, se si connette un account di archiviazione alla risorsa lingua, non è possibile disconnetterlo in un secondo momento.
È possibile connettere la risorsa lingua solo a un account di archiviazione.
Selezionare il tipo di progetto. È possibile creare un progetto di classificazione con più etichette in cui ogni documento può appartenere a una o più classi o a un progetto di classificazione con etichetta singola in cui ogni documento può appartenere a una sola classe. Il tipo selezionato non può essere modificato in un secondo momento.
Immettere le informazioni sul progetto, inclusi un nome, una descrizione e la lingua dei documenti nel progetto. Non sarà possibile modificare il nome del progetto in un secondo momento. Seleziona Avanti.
Suggerimento
Il set di dati non deve essere interamente nello stesso linguaggio. È possibile avere più documenti, ognuno con lingue supportate diverse. Se il set di dati contiene documenti di lingue diverse o se si prevede testo da lingue diverse durante il runtime, selezionare l'opzione Abilita set di dati multilingue quando si immettono le informazioni di base per il progetto. Questa opzione può essere abilitata in un secondo momento dalla pagina Impostazioni progetto.
Selezionare il contenitore in cui è stato caricato il set di dati.
Selezionare Sì, i documenti sono già etichettati e ho formattato il file delle etichette JSON e selezionare il file delle etichette dal menu a discesa seguente per importare il file delle etichette JSON. Assicurarsi che segua il formato supportato.
Seleziona Avanti.
Esaminare i dati immessi e selezionare Crea progetto.
Inviare una richiesta POST usando l'URL, le intestazioni e il corpo JSON seguenti per importare il file di etichette. Assicurarsi che il file delle etichette segua il formato accettato.
Se esiste già un progetto con lo stesso nome, i dati del progetto vengono sostituiti.
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole.
myProject
{API-VERSION}
Versione dell'API che si sta chiamando. Il valore a cui viene fatto riferimento è relativo alla versione più recente rilasciata. Altre informazioni sulle altre versioni dell'API disponibili
2022-05-01
Intestazioni
Usare l'intestazione seguente per autenticare la richiesta.
Chiave
valore
Ocp-Apim-Subscription-Key
Chiave della risorsa. Usato per l'autenticazione delle richieste API.
Corpo
Usare il codice JSON seguente nella richiesta. Sostituire i valori segnaposto seguenti con i propri valori.
Versione dell'API che si sta chiamando. La versione usata qui deve essere la stessa versione dell'API nell'URL. Altre informazioni sulle altre versioni dell'API disponibili
2022-05-01
projectName
{PROJECT-NAME}
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole.
myProject
projectKind
customMultiLabelClassification
Tipo di progetto.
customMultiLabelClassification
lingua
{LANGUAGE-CODE}
Stringa che specifica il codice della lingua per i documenti usati nel progetto. Se il progetto è un progetto multilingue, scegliere il codice linguistico della maggior parte dei documenti. Per altre informazioni sul supporto multilingue, vedere Supporto linguistico.
en-us
Multilingue
true
Valore booleano che consente di avere documenti in più lingue nel set di dati e quando il modello viene distribuito, è possibile eseguire query sul modello in qualsiasi linguaggio supportato (non necessariamente incluso nei documenti di training. Per altre informazioni sul supporto multilingue, vedere Supporto linguistico.
true
storageInputContainerName
{CONTAINER-NAME}
Nome del contenitore di archiviazione di Azure in cui sono stati caricati i documenti.
myContainer
classi
[]
Matrice contenente tutte le classi presenti nel progetto. Queste sono le classi in cui classificare i documenti.
[]
documenti
[]
Matrice contenente tutti i documenti del progetto e le classi etichettate per questo documento.
[]
posizione
{DOCUMENT-NAME}
Posizione dei documenti nel contenitore di archiviazione. Poiché tutti i documenti si trovano nella radice del contenitore, questo deve essere il nome del documento.
doc1.txt
set di dati
{DATASET}
Set di test a cui verrà eseguito il documento quando si divide prima del training. Per altre informazioni sulla suddivisione dei dati, vedere Come eseguire il training di un modello . I valori possibili per questo campo sono Train e Test.
Versione dell'API che si sta chiamando. La versione usata qui deve essere la stessa versione dell'API nell'URL.
2022-05-01
projectName
{PROJECT-NAME}
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole.
myProject
projectKind
customSingleLabelClassification
Tipo di progetto.
customSingleLabelClassification
lingua
{LANGUAGE-CODE}
Stringa che specifica il codice della lingua per i documenti usati nel progetto. Se il progetto è un progetto multilingue, scegliere il codice linguistico della maggior parte dei documenti. Per altre informazioni sui codici linguistici supportati, vedere Supporto linguistico.
en-us
Multilingue
true
Valore booleano che consente di avere documenti in più lingue nel set di dati e quando il modello viene distribuito, è possibile eseguire query sul modello in qualsiasi linguaggio supportato (non necessariamente incluso nei documenti di training. Per altre informazioni sul supporto multilingue, vedere Supporto linguistico.
true
storageInputContainerName
{CONTAINER-NAME}
Nome del contenitore di archiviazione di Azure in cui sono stati caricati i documenti.
myContainer
classi
[]
Matrice contenente tutte le classi presenti nel progetto. Queste sono le classi in cui classificare i documenti.
[]
documenti
[]
Matrice contenente tutti i documenti del progetto e la classe a cui appartiene il documento.
[]
posizione
{DOCUMENT-NAME}
Posizione dei documenti nel contenitore di archiviazione. Poiché tutti i documenti si trovano nella radice del contenitore, questo deve essere il nome del documento.
doc1.txt
set di dati
{DATASET}
Set di test a cui verrà eseguito il documento quando si divide prima del training. Per altre informazioni sulla suddivisione dei dati, vedere Come eseguire il training di un modello . I valori possibili per questo campo sono Train e Test.
Train
Dopo aver inviato la richiesta API, si riceverà una 202 risposta che indica che il processo è stato inviato correttamente. Nelle intestazioni della risposta estrarre il operation-location valore. Il formato sarà simile al seguente:
{JOB-ID} viene usato per identificare la richiesta, poiché questa operazione è asincrona. Questo URL verrà usato per ottenere lo stato del processo di importazione.
Possibili scenari di errore per questa richiesta:
La risorsa selezionata non dispone delle autorizzazioni appropriate per l'account di archiviazione.
L'oggetto storageInputContainerName specificato non esiste.
Viene usato codice linguistico non valido o se il tipo di codice della lingua non è stringa.
multilingual value è una stringa e non un valore booleano.
Passare alla pagina delle impostazioni del progetto in Language Studio.
È possibile visualizzare i dettagli del progetto.
In questa pagina è possibile aggiornare la descrizione del progetto e abilitare/disabilitare il set di dati multilingue nelle impostazioni del progetto.
È anche possibile visualizzare l'account di archiviazione connesso e il contenitore alla risorsa Lingua.
È anche possibile recuperare la chiave primaria della risorsa da questa pagina.
Per ottenere i dettagli del progetto di classificazione del testo personalizzato, inviare una richiesta GET usando l'URL e le intestazioni seguenti. Sostituire i valori segnaposto con i propri valori.
Questo valore può essere customSingleLabelClassification o customMultiLabelClassification.
storageInputContainerName
{CONTAINER-NAME}
Nome del contenitore di archiviazione di Azure in cui sono stati caricati i documenti.
myContainer
projectName
{PROJECT-NAME}
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole.
myProject
multilingual
Valore booleano che consente di avere documenti in più lingue nel set di dati. Quando il modello viene distribuito, è possibile eseguire query sul modello in qualsiasi linguaggio supportato (non necessariamente incluso nei documenti di training. Per altre informazioni sul supporto multilingue, vedere Supporto linguistico.
true
language
{LANGUAGE-CODE}
Stringa che specifica il codice della lingua per i documenti usati nel progetto. Se il progetto è un progetto multilingue, scegliere il codice linguistico della maggior parte dei documenti. Per altre informazioni sui codici linguistici supportati, vedere Supporto linguistico.
en-us
Dopo aver inviato la richiesta API, si riceverà una 200 risposta che indica l'esito positivo e il corpo della risposta JSON con i dettagli del progetto.
Quando il progetto non è più necessario, è possibile eliminare il progetto usando Language Studio. Selezionare Classificazione testo personalizzata nella parte superiore e quindi selezionare il progetto da eliminare. Selezionare Elimina dal menu in alto per eliminare il progetto.
Quando il progetto non è più necessario, è possibile eliminarlo con la richiesta DELETE seguente. Sostituire i valori segnaposto con i propri valori.
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole.
myProject
{API-VERSION}
Versione dell'API che si sta chiamando. Il valore a cui viene fatto riferimento è relativo alla versione più recente rilasciata. Altre informazioni sulle altre versioni dell'API disponibili
2022-05-01
Intestazioni
Usare l'intestazione seguente per autenticare la richiesta.
Chiave
valore
Ocp-Apim-Subscription-Key
Chiave della risorsa. Usato per l'autenticazione delle richieste API.
Dopo aver inviato la richiesta API, si riceverà una 202 risposta che indica l'esito positivo, il che significa che il progetto è stato eliminato. Risultati di una chiamata con esito positivo con un'intestazione Operation-Location usata per controllare lo stato del processo.
Passaggi successivi
È necessario avere un'idea dello schema del progetto che verrà usato per etichettare i dati.
Dopo aver creato il progetto, è possibile iniziare a etichettare i dati, che indicherà al modello di classificazione del testo come interpretare il testo e viene usato per il training e la valutazione.