Funzionalità e terminologia di Hub eventi di Azure
Hub eventi di Azure è un servizio scalabile di elaborazione degli eventi che inserisce ed elabora grandi volumi di eventi e dati, con latenza bassa e affidabilità elevata. Per una panoramica generale del servizio, vedere Che cos'è Hub eventi?.
Questo articolo si basa sulle informazioni presenti nella panoramica e contiene dettagli tecnici e informazioni sull'implementazione relativi ai componenti e alle funzionalità di Hub eventi.
Spazio dei nomi
Uno spazio dei nomi di Hub eventi è un contenitore di gestione per hub eventi (o argomenti, in linguaggio Kafka). Offre endpoint di rete integrati dns e una gamma di funzionalità di controllo di accesso e gestione dell'integrazione di rete, ad esempio filtri IP, endpoint servizio di rete virtuale e collegamento privato.

Partizioni
Hub eventi organizza sequenze di eventi inviati a un hub eventi in una o più partizioni. Man mano che arrivano, i nuovi eventi vengono aggiunti alla fine di questa sequenza.

Una partizione può essere considerata come un log di commit. Le partizioni contengono i dati dell'evento che contengono le informazioni seguenti:
- Corpo dell'evento
- Contenitore di proprietà definito dall'utente che descrive l'evento
- Metadati, ad esempio l'offset nella partizione, il relativo numero nella sequenza di flusso
- Timestamp sul lato servizio in corrispondenza del quale è stato accettato

Vantaggi dell'uso delle partizioni
Hub eventi è progettato per semplificare l'elaborazione di volumi elevati di eventi e il partizionamento contribuisce a questo scopo in due modi:
- Anche se Hub eventi è un servizio PaaS, esiste una realtà fisica sottostante. La gestione di un log che mantiene l'ordine degli eventi richiede che questi eventi vengano mantenuti insieme nella risorsa di archiviazione sottostante e nelle relative repliche e che comportano un limite di velocità effettiva per tale log. Il partizionamento consente l'uso di più log paralleli per lo stesso hub eventi e quindi la moltiplicazione della capacità di output di input non elaborato (I/O) disponibile.
- Le applicazioni personalizzate devono essere in grado di mantenere il passo con l'elaborazione del volume di eventi inviati a un hub eventi. Potrebbe essere complesso e richiede una capacità di elaborazione parallela sostanziale, con scalabilità orizzontale. La capacità di un singolo processo per gestire gli eventi è limitata, quindi sono necessari diversi processi. Le partizioni sono il modo in cui la soluzione inserisce tali processi e garantisce tuttavia che ogni evento abbia un proprietario di elaborazione chiaro.
Numero di partizioni
Il numero di partizioni viene specificato al momento della creazione di un hub eventi. Deve essere compreso tra uno e il numero massimo di partizioni consentito per ogni piano tariffario. Per il limite di conteggio delle partizioni per ogni livello, vedere questo articolo.
È consigliabile scegliere almeno il numero di partizioni previste durante il carico massimo dell'applicazione per tale hub eventi specifico. Per i livelli diversi dai livelli Premium e dedicati, non è possibile modificare il numero di partizioni per un hub eventi dopo la creazione. Per un hub eventi in un livello Premium o dedicato, è possibile aumentare il numero di partizioni dopo la creazione, ma non è possibile ridurle. La distribuzione dei flussi tra le partizioni cambierà quando viene eseguito come mapping delle chiavi di partizione alle modifiche alle partizioni, pertanto è consigliabile provare a evitare tali modifiche se l'ordine relativo degli eventi è importante nell'applicazione.
Si potrebbe essere tentati di impostare il numero di partizioni sul valore massimo consentito, ma tenere sempre presente che i flussi di eventi devono essere strutturati in modo da consentire di usufruire di più partizioni. Se è necessaria la conservazione assoluta degli ordini in tutti gli eventi o solo una manciata di sottostream, potrebbe non essere possibile sfruttare molte partizioni. Inoltre, molte partizioni rendono l'elaborazione più complessa.
Non importa quante partizioni si trovano in un hub eventi quando si tratta di prezzi. Dipende dal numero di unità tariffarie (unità elaborate (UR) per il livello standard, le unità di elaborazione (UR) per il livello Premium e le unità di capacità (CU) per il livello dedicato) per lo spazio dei nomi o il cluster dedicato. Ad esempio, un hub eventi del livello standard con 32 partizioni o con una partizione comporta lo stesso costo esatto quando lo spazio dei nomi è impostato su una capacità TU. È anche possibile ridimensionare le UNITÀ richiesta o lo spazio dei nomi o le UNITÀ di configurazione del cluster dedicato indipendentemente dal numero di partizioni.
Poiché la partizione è un meccanismo di organizzazione dei dati che consente di pubblicare e utilizzare i dati in modo parallelo. È consigliabile bilanciare le unità di ridimensionamento (unità elaborate per il livello standard, le unità di elaborazione per il livello Premium o le unità di capacità per il livello dedicato) e le partizioni per ottenere una scalabilità ottimale. In generale, è consigliabile una velocità effettiva massima di 1 MB/s per partizione. Pertanto, una regola generale per calcolare il numero di partizioni consiste nel dividere la velocità effettiva massima prevista per 1 MB/s. Ad esempio, se il caso d'uso richiede 20 MB/s, è consigliabile scegliere almeno 20 partizioni per ottenere la velocità effettiva ottimale.
Tuttavia, se si dispone di un modello in cui l'applicazione ha un'affinità con una determinata partizione, l'aumento del numero di partizioni non è vantaggioso. Per altre informazioni, vedere Disponibilità e coerenza.
Mapping di eventi a partizioni
È possibile usare una chiave di partizione per mappare i dati dell'evento in ingresso in partizioni specifiche ai fini dell'organizzazione dei dati. La chiave di partizione è un valore fornito dal mittente che viene passato a un hub eventi. Viene elaborato tramite una funzione hash statica, che crea l'assegnazione di partizione. Se non si specifica una chiave di partizione quando si pubblica un evento, viene usata un'assegnazione round robin.
L'autore di eventi è a conoscenza solo della chiave di partizione, non la partizione in cui gli eventi vengono pubblicati. Questa separazione tra chiave e partizione evita che il mittente debba conoscere troppe informazioni sull'elaborazione downstream. Un’identità univoca per dispositivo o utente crea una chiave di partizione efficace, ma è possibile utilizzare anche altri attributi, ad esempio l’area geografica, per raggruppare gli eventi correlati in un'unica partizione.
La specifica di una chiave di partizione consente di mantenere insieme gli eventi correlati nella stessa partizione e nell'ordine esatto in cui sono arrivati. La chiave di partizione è una stringa derivata dal contesto dell'applicazione che identifica l'interrelazione degli eventi. Una sequenza di eventi identificata da una chiave di partizione è un flusso. Una partizione è un archivio di log multiplex per molti flussi di questo tipo.
Nota
Anche se è possibile inviare eventi direttamente alle partizioni, non è consigliabile, soprattutto quando la disponibilità elevata è importante. Effettua il downgrade della disponibilità di un hub eventi a livello di partizione. Per altre informazioni, vedere Disponibilità e coerenza.
Publisher di eventi
Qualsiasi entità che invia dati a un hub eventi è un server di pubblicazione eventi (sinonimo di producer di eventi). Gli editori di eventi possono pubblicare eventi usando HTTPS o AMQP 1.0 o il protocollo Kafka. Gli editori di eventi usano l'autorizzazione basata su ID Entra di Microsoft con token JWT rilasciati da OAuth2 o un token sas (Shared Access Signature) specifico dell'hub eventi per ottenere l'accesso alla pubblicazione.
È possibile pubblicare un evento tramite AMQP 1.0, il protocollo Kafka o HTTPS. Il servizio Hub eventi fornisce api REST e librerie client .NET, Java, Python, JavaScript e Go per la pubblicazione di eventi in un hub eventi. Per altre piattaforme e runtime, è possibile utilizzare qualsiasi client AMQP 1.0, ad esempio Apache Qpid.
La scelta tra AMQP e HTTPS dipende dallo scenario di utilizzo. AMQP richiede di stabilire un socket bidirezionale persistente oltre alla sicurezza a livello di trasporto (TLS) o SSL/TLS. AMQP ha costi di rete più elevati durante l'inizializzazione della sessione, tuttavia HTTPS richiede un sovraccarico TLS aggiuntivo per ogni richiesta. AMQP offre prestazioni più elevate per i server di pubblicazione frequenti e può ottenere latenze molto inferiori se usate con codice di pubblicazione asincrono.
È possibile pubblicare gli eventi singolarmente o in batch. Una singola pubblicazione ha un limite di 1 MB, indipendentemente dal fatto che si tratti di un singolo evento o di un batch. Gli eventi di pubblicazione superiori a questa soglia vengono rifiutati.
La velocità effettiva di Hub eventi viene ridimensionata usando partizioni e allocazioni di unità elaborate. È consigliabile che gli editori rimangano a conoscenza del modello di partizionamento specifico scelto per un hub eventi e di specificare solo una chiave di partizione usata per assegnare in modo coerente gli eventi correlati alla stessa partizione.
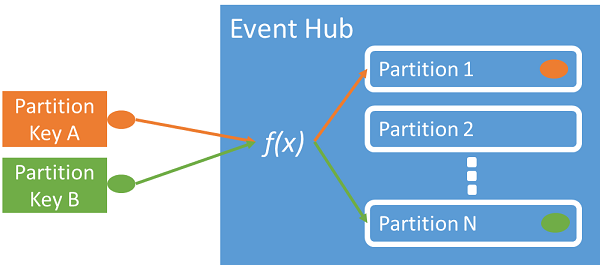
Hub eventi garantisce che tutti gli eventi che condividono un valore di chiave di partizione vengano archiviati insieme e recapitati in ordine di arrivo. Se si usano chiavi di partizione con i criteri di autore, l'identità dell’autore e il valore della chiave di partizione devono corrispondere. In caso contrario si verifica un errore.
Conservazione degli eventi
Gli eventi pubblicati vengono rimossi da un hub eventi in base a un criterio di conservazione basato su timed configurabile. Ecco alcuni punti importanti:
- Il valore predefinito e il periodo di conservazione più breve possibile è 1 ora. Attualmente, è possibile impostare il periodo di conservazione in ore solo nel portale di Azure. Il modello di Resource Manager, PowerShell e l'interfaccia della riga di comando consentono di impostare questa proprietà solo in giorni.
- Per Hub eventi Standard, il periodo di conservazione massimo è di 7 giorni.
- Per Hub eventi Premium e Dedicato, il periodo di conservazione massimo è 90 giorni.
- Se si modifica il periodo di conservazione, si applica a tutti gli eventi inclusi gli eventi già presenti nell'hub eventi.
Hub eventi mantiene gli eventi per un periodo di conservazione configurato che viene applicato a tutte le partizioni. Gli eventi vengono rimossi automaticamente al raggiungimento del periodo di conservazione. Se è stato specificato un periodo di conservazione di un giorno (24 ore), l'evento diventa non disponibile esattamente 24 ore dopo che è stato accettato. Non è possibile eliminare in modo esplicito gli eventi.
Se è necessario archiviare gli eventi oltre il periodo di conservazione consentito, è possibile archiviarli automaticamente in Archiviazione di Azure o Azure Data Lake attivando la funzionalità acquisizione di Hub eventi. Se è necessario cercare o analizzare tali archivi profondi, è possibile importarli facilmente in Azure Synapse o in altri archivi e piattaforme di analisi simili.
Il motivo del limite temporale di Hub eventi per la conservazione dei dati è di impedire che volumi elevati di dati cronologici dei clienti vengano intrappolati in un archivio profondo che viene indicizzato solo in base a timestamp e consente solo l'accesso sequenziale. La filosofia dell'architettura è che i dati cronologici hanno bisogno di un'indicizzazione più completa e un accesso più diretto rispetto all'interfaccia di eventi in tempo reale che hub eventi o Kafka forniscono. I motori di flusso di eventi non sono adatti per svolgere il ruolo di data lake o archivi a lungo termine per l'origine degli eventi.
Nota
Hub eventi è un motore di flusso di eventi in tempo reale e non è progettato per essere usato invece di un database e/o come archivio permanente per flussi di eventi mantenuti infinitamente.
Più approfondita è la cronologia di un flusso di eventi, più saranno necessari indici ausiliari per trovare una particolare sezione cronologica di un determinato flusso. L'ispezione dei payload e dell'indicizzazione degli eventi non rientra nell'ambito della funzionalità di Hub eventi (o Apache Kafka). I database e i motori di analisi specializzati, ad esempio Azure Data Lake Store, Azure Data Lake Analytics e Azure Synapse, sono quindi molto più adatti per l'archiviazione di eventi cronologici.
Acquisizione di Hub eventi si integra direttamente con Archiviazione BLOB di Azure e Azure Data Lake Archiviazione e, tramite tale integrazione, consente anche il flusso di eventi direttamente in Azure Synapse.
Criteri di autore
Hub eventi consente un controllo granulare degli autori di eventi tramite criteri di autore. I criteri di autore sono funzionalità di runtime progettate per consentire un numero elevato di autori di eventi indipendenti. Con i criteri di autore, ogni autore usa il proprio identificatore univoco durante la pubblicazione di eventi in un hub eventi, con il meccanismo seguente:
//<my namespace>.servicebus.windows.net/<event hub name>/publishers/<my publisher name>
Non è necessario creare nomi di autore prima di procedere, ma devono corrispondere al token SAS utilizzato quando si pubblica un evento, al fine di garantire le identità di autore indipendenti. Quando si usano i criteri di pubblicazione, il valore PartitionKey deve essere impostato sul nome dell'editore. Per il corretto funzionamento, questi valori devono corrispondere.
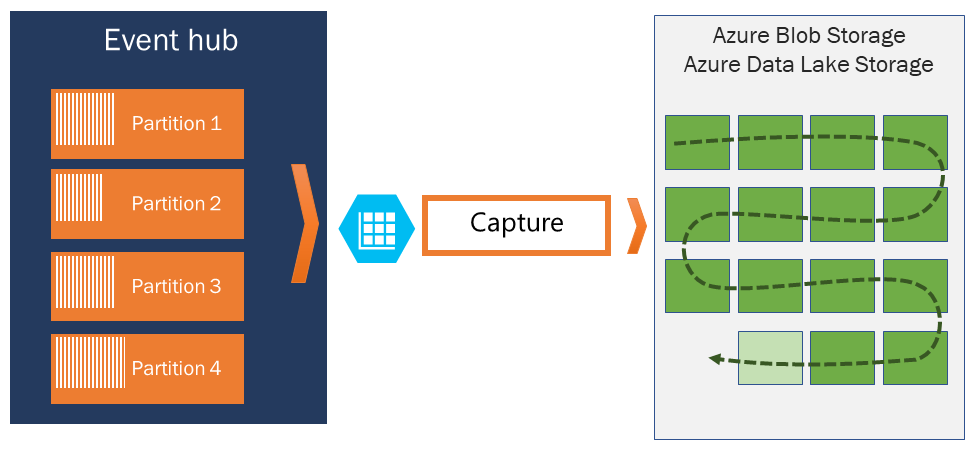
Capture
Acquisizione di Hub eventi consente di acquisire automaticamente i dati di streaming in Hub eventi e salvarli nella scelta di un account di archiviazione BLOB o di un account di azure Data Lake Archiviazione. È possibile abilitare l'acquisizione dal portale di Azure e specificare una dimensione minima e un intervallo di tempo per eseguire l'acquisizione. Usando Acquisizione di Hub eventi, è possibile specificare un account e un contenitore di Archiviazione BLOB di Azure personalizzati oppure un account azure Data Lake Archiviazione, uno dei quali viene usato per archiviare i dati acquisiti. I dati acquisiti vengono scritti nel formato di Apache Avro.
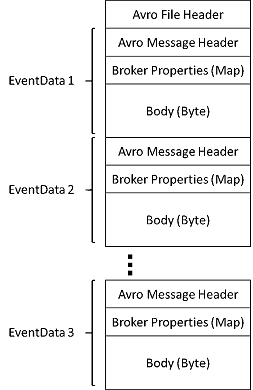
I file generati da Acquisizione di Hub eventi hanno lo schema Avro seguente:
Nota
Quando non si usa alcun editor di codice nella portale di Azure, è possibile acquisire dati di streaming in Hub eventi in un account Azure Data Lake Archiviazione Gen2 in formato Parquet. Per altre informazioni, vedere Procedura: Acquisire dati da Hub eventi in formato Parquet ed Esercitazione: Acquisire i dati di Hub eventi in formato Parquet e analizzare con Azure Synapse Analytics.
Token di firma di accesso condiviso
Hub eventi usa firme di accesso condiviso, disponibili a livello di spazio dei nomi e di hub eventi. Un token SAS viene generato da una chiave SAS ed è un hash SHA di un URL, codificato in un formato specifico. Hub eventi può rigenerare l'hash usando il nome della chiave (criterio) e il token e quindi autenticare il mittente. In genere, i token di firma di accesso condiviso per gli autori di eventi vengono creati con privilegi solo di invio per un hub eventi specifico. Questo meccanismo di URL token SAS costituisce la base per l'identificazione dell’autore introdotta nei criteri di autore. Per altre informazioni sull'uso di SAS, vedere Autenticazione della firma di accesso condiviso con il bus di servizio.
Consumer di eventi
Qualsiasi entità che legge i dati dell'evento da un hub eventi è un consumer eventi. Tutti i consumer di Hub eventi si connettono tramite la sessione AMQP 1.0 e gli eventi vengono recapitati tramite la sessione appena disponibili. Il client non deve eseguire il polling della disponibilità dei dati.
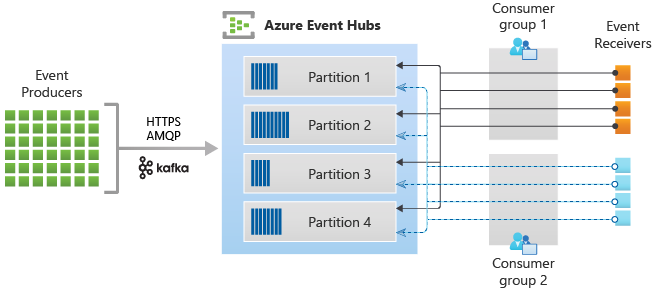
Gruppi di consumer
Il meccanismo di pubblicazione/sottoscrizione degli Hub eventi è abilitato tramite i gruppi di consumer. Un gruppo di consumer è un raggruppamento logico di consumer che leggono i dati da un hub eventi o da un argomento Kafka. Consente a più applicazioni che utilizzano di leggere gli stessi dati di streaming in un hub eventi in modo indipendente con i propri offset. Consente di parallelizzare l'utilizzo dei messaggi e di distribuire il carico di lavoro tra più consumer mantenendo l'ordine dei messaggi all'interno di ogni partizione.
È consigliabile che sia presente un solo ricevitore attivo in una partizione all'interno di un gruppo di consumer. In alcuni scenari, tuttavia, è possibile usare fino a cinque consumer o ricevitori per partizione in cui tutti i ricevitori ottengono tutti gli eventi della partizione. Se si dispone di più lettori nella stessa partizione, si elaborano eventi duplicati. È necessario gestirlo nel codice, che non è semplice. È tuttavia un approccio valido in alcuni scenari.
In un'architettura di elaborazione del flusso, ogni applicazione downstream equivale a un gruppo di consumer. Se si vogliono scrivere i dati degli eventi nell'archiviazione a lungo termine, tale applicazione del writer di archiviazione è un gruppo di consumer. L'elaborazione di eventi complessi può quindi essere eseguita da un altro gruppo di consumer separato. È possibile accedere alle partizioni solo tramite un gruppo di consumer. Esiste sempre un gruppo di consumer predefinito in un hub eventi ed è possibile creare fino al numero massimo di gruppi di consumer per il piano tariffario corrispondente.
Alcuni client offerti dagli SDK di Azure sono agenti consumer intelligenti che gestiscono automaticamente i dettagli per garantire che ogni partizione abbia un singolo lettore e che tutte le partizioni per un hub eventi vengano lette da. Consente al codice di concentrarsi sull'elaborazione degli eventi letti dall'hub eventi in modo che possa ignorare molti dei dettagli delle partizioni. Per altre informazioni, vedere Connessione a una partizione.
Gli esempi seguenti illustrano la convenzione URI del gruppo di consumer:
//<my namespace>.servicebus.windows.net/<event hub name>/<Consumer Group #1>
//<my namespace>.servicebus.windows.net/<event hub name>/<Consumer Group #2>
La figura seguente illustra l'architettura di elaborazione del flusso di Hub eventi:
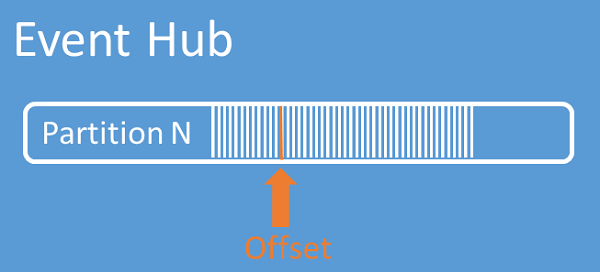
Offset di flusso
Un offset è la posizione di un evento all'interno di una partizione. Un offset può essere considerato come un cursore sul lato client. L'offset è la numerazione di byte dell'evento. Questo offset consente a un consumer di eventi (lettore) di specificare un punto nel flusso di eventi da cui iniziare la lettura degli eventi. È possibile specificare l'offset come un timestamp o un valore di offset. I consumer sono responsabili di archiviare i propri valori di offset all'esterno del servizio Hub eventi. All'interno di una partizione, ogni evento include un offset.
Checkpoint
Checkpoint è un processo mediante il quale i lettori contrassegnano o eseguono il commit della propria posizione all'interno di una sequenza di eventi di partizione. Il checkpoint è responsabilità del consumer e si verifica per partizione all'interno di un gruppo di consumer. Questa responsabilità significa che per ogni gruppo di consumer, ogni lettore di partizione deve tenere traccia della posizione corrente nel flusso di eventi e può informare il servizio quando considera completo il flusso di dati.
Se un lettore si disconnette da una partizione, quando riconnette inizia a leggere in corrispondenza del checkpoint inviato in precedenza dall’ulitimo lettore di tale partizione in tale gruppo di consumer. Quando il lettore si connette, passa l'offset all'hub eventi per specificare la posizione da cui iniziare la lettura. In questo modo è possibile usare la funzionalità di checkpoint sia per contrassegnare gli eventi come "completi" dalle applicazioni a valle sia per fornire la resilienza in caso di failover tra i lettori in esecuzione in computer diversi. È possibile tornare a dati precedenti specificando un offset inferiore da questo processo di checkpoint. Tramite questo meccanismo il checkpoint consente sia la resilienza del failover che la riproduzione del flusso di eventi.
Importante
Gli offset vengono forniti dal servizio Hub eventi. È responsabilità dell'utente eseguire il checkpoint quando vengono elaborati gli eventi.
Seguire questi consigli quando si usa Archiviazione BLOB di Azure come archivio checkpoint:
- Usare un contenitore separato per ogni gruppo di consumer. È possibile usare lo stesso account di archiviazione, ma usare un contenitore per ogni gruppo.
- Non usare il contenitore per altri elementi e non usare l'account di archiviazione per altri elementi.
- Archiviazione account deve trovarsi nella stessa area in cui si trova l'applicazione distribuita. Se l'applicazione è locale, provare a scegliere l'area più vicina possibile.
Nella pagina Archiviazione account della portale di Azure, nella sezione Servizio BLOB verificare che le impostazioni seguenti siano disabilitate.
- Spazio dei nomi gerarchico
- Eliminazione temporanea dei BLOB
- Controllo delle versioni
Compattazione dei log
Hub eventi di Azure supporta la compattazione del registro eventi per mantenere gli eventi più recenti di una determinata chiave evento. Con l'argomento Hub eventi compressi/Kafka, è possibile usare la conservazione basata su chiave anziché usare la conservazione basata sul tempo più grossolana.
Per altre informazioni sulla compattazione dei log, vedere Compattazione dei log.
Attività comuni del consumer
Tutti i consumer di Hub eventi si connettono tramite una sessione AMQP 1.0 e un canale di comunicazione bidirezionale in grado di riconoscere lo stato. Ogni partizione ha una sessione AMQP 1.0 che facilita il trasporto di eventi separati dalla partizione.
Connettersi a una partizione
Quando ci si connette alle partizioni, è pratica comune usare un meccanismo di leasing per coordinare le connessioni del lettore a partizioni specifiche. In questo modo, è possibile che ogni partizione in un gruppo di consumer abbia un solo lettore attivo. I checkpoint, il leasing e la gestione dei lettori sono semplificati usando i client all'interno degli SDK di Hub eventi, che fungono da agenti consumer intelligenti. Sono:
- EventProcessorClient per .NET
- EventProcessorClient per Java
- EventHubConsumerClient per Python
- EventHubConsumerClient per JavaScript/TypeScript
Leggere gli eventi
Dopo l'apertura di una sessione AMQP 1.0 e del collegamento per una partizione specifica, gli eventi vengono recapitati al client AMQP 1.0 dal servizio Hub eventi. Questo meccanismo di recapito permette una velocità effettiva più elevata e una latenza più bassa rispetto ai meccanismi basati su pull, ad esempio HTTP GET. Quando gli eventi vengono inviati al client, ogni istanza dei dati dell'evento contiene metadati importanti, ad esempio l’offset e il numero di sequenza utilizzati per facilitare il checkpoint sulla in sequenza di eventi.
Dati evento:
- Contropartita
- Sequenza numerica
- Corpo
- Proprietà utente
- Proprietà di sistema
È responsabilità dell'utente gestire l'offset.
Gruppi di applicazioni
Un gruppo di applicazioni è una raccolta di applicazioni client che si connettono a uno spazio dei nomi di Hub eventi che condividono una condizione di identificazione univoca, ad esempio il contesto di sicurezza, i criteri di accesso condiviso o l'ID applicazione Microsoft Entra.
Hub eventi di Azure consente di definire criteri di accesso alle risorse, ad esempio i criteri di limitazione per un determinato gruppo di applicazioni e controlla lo streaming di eventi (pubblicazione o utilizzo) tra applicazioni client e Hub eventi.
Per altre informazioni, vedere Governance delle risorse per le applicazioni client con gruppi di applicazioni.
Supporto di Apache Kafka
Il supporto del protocollo per i client Apache Kafka (versioni >=1.0) fornisce endpoint che consentono alle applicazioni Kafka esistenti di usare Hub eventi. La maggior parte delle applicazioni Kafka esistenti può semplicemente essere riconfigurata in modo che punti a uno spazio dei nomi s anziché a un server bootstrap del cluster Kafka.
Dal punto di vista dei costi, delle attività operative e dell'affidabilità, Hub eventi di Azure è un'ottima alternativa alla distribuzione e alla gestione di cluster Kafka e Zookeeper e alle offerte Kafka-as-a-Service non native in Azure.
Oltre a ottenere la stessa funzionalità di base del broker Apache Kafka, è anche possibile accedere alle funzionalità di Hub eventi di Azure come l'invio in batch e l'archiviazione automatica tramite Acquisizione di Hub eventi, scalabilità e bilanciamento automatico, ripristino di emergenza, supporto della zona di disponibilità indipendente dai costi, integrazione della rete flessibile e sicura e supporto multi-protocollo, incluso il protocollo AMQP-over-WebSocket.
Passaggi successivi
Per altre informazioni su Hub eventi, vedere i collegamenti seguenti:
- Introduzione a Hub eventi