Ripristino di emergenza in Azure Service Fabric
Una parte fondamentale della distribuzione a disponibilità elevata consiste nel garantire la resistenza dei servizi a tutti i tipi di errori. Ciò è particolarmente importante per gli errori imprevisti e incontrollabili.
Questo articolo descrive alcune modalità di errore comuni che possono generare situazioni di emergenza se non organizzate e gestite correttamente. Illustra anche le mitigazioni e le azioni da intraprendere in presenza di un'emergenza. L'obiettivo consiste nel limitare o eliminare il rischio di tempi di inattività o di perdita di dati quando si verificano errori, pianificati o imprevisti.
Evitare situazioni di emergenza
L'obiettivo principale di Service Fabric è di aiutare a organizzare sia l'ambiente che i servizi in modo che gli errori comuni non generino situazioni di emergenza.
Esistono, in generale, due tipi di scenari di emergenza/errore:
- Errori hardware e software
- Errori operativi
Errori hardware e software
Gli errori hardware e software sono imprevedibili. Il modo più semplice per resistere a questi errori è eseguire più copie del servizio oltre i limiti dell'errore hardware o software.
Se ad esempio il servizio è in esecuzione solo in un solo computer, l'errore di quel computer determina una situazione di emergenza per il servizio. Questo tipo di emergenza può essere evitato semplicemente eseguendo il servizio in più computer. Anche i test sono necessari per garantire che l'errore in un unico computer non interrompa l'esecuzione del servizio. La pianificazione della capacità offre la possibilità di creare un'istanza sostitutiva in un'altra posizione ed evita che la riduzione della capacità sovraccarichi i servizi restanti.
Lo stesso criterio funziona indipendentemente dall'errore che si sta tentando di evitare. Ad esempio, se si teme il guasto di una rete SAN, si può eseguire i servizi in più reti SAN. Se si teme la perdita di un rack di server, si può eseguire il servizio su più rack. Se si teme la perdita di dati nei data center, è consigliabile eseguire il servizio in più aree di Azure, più zone di disponibilità di Azure o più data center.
Quando un servizio è distribuito su più istanze fisiche (macchine, rack, data center, aree), si è comunque soggetti ad alcuni tipi di errori simultanei. Tuttavia, errori singoli o multipli di un determinato tipo (ad esempio, una singola macchina virtuale o un collegamento di rete che determina un errore) vengono gestiti automaticamente e non costituiscono più un'"emergenza".
Service Fabric prevede meccanismi per espandere il cluster e far tornare disponibili i nodi e i servizi. Service Fabric consente anche di eseguire molte istanze dei servizi per evitare che errori imprevisti si trasformino in vere e proprie emergenze.
Esistono alcuni motivi per cui l'esecuzione di una distribuzione sufficientemente grande da coprire gli errori potrebbe non essere fattibile. Potrebbe, ad esempio, richiedere l'implementazione di risorse hardware aggiuntive il cui costo sarebbe sproporzionato rispetto alla possibilità che si verifichi un errore. Quando si lavora con le applicazioni distribuite, gli hop di comunicazione o i costi di replica di stato aggiuntivi su distanze geografiche possono causare una latenza inaccettabile. La posizione di questa linea di confine varia per ogni applicazione.
Per gli errori software, in particolare, l'errore potrebbe risiedere nel servizio che si sta tentando di scalare. La creazione di più copie, in questo caso, non previene la situazione di emergenza perché la condizione di errore è correlata a tutte le istanze.
Errori operativi
Anche se il servizio è esteso in tutto il mondo con molte ridondanze, può comunque essere soggetto a eventi di emergenza, Ad esempio se qualcuno riconfigura accidentalmente il nome DNS per il servizio o lo elimina definitivamente.
Si supponga, ad esempio, di disporre di un servizio di Service Fabric con stato e che un utente lo abbia eliminato inavvertitamente. A meno che non esistano altre mitigazioni, il servizio e il relativo stato sono ormai eliminati. Questi tipi di emergenze operative ("errori") richiedono mitigazioni e procedure per il ripristino diverse rispetto ai normali errori imprevisti.
I modi migliori per evitare questi tipi di errori operativi consistono nel:
- Limitare l'accesso operativo all'ambiente.
- Controllare rigorosamente le operazioni pericolose.
- Favorire l'automazione, impedire le modifiche manuali o fuori banda e convalidare le modifiche specifiche nell'ambiente prima di applicarle.
- Assicurarsi che le operazioni distruttive siano "soft". Le operazioni soft non hanno effetto immediato o possono essere annullate entro un intervallo di tempo.
Per evitare gli errori operativi, Service Fabric offre meccanismi come il controllo degli accessi in base al ruolo per le operazioni nel cluster. La maggior parte di questi errori operativi richiede tuttavia attività organizzative e altri sistemi. Service Fabric offre meccanismi per resistere agli errori operativi, i più noti dei quali sono il backup e il ripristino per i servizi con stato.
Gestione degli errori
Lo scopo di Service Fabric è la gestione automatica degli errori. Tuttavia per gestire alcuni tipi di errori, i servizi devono essere dotati di codice aggiuntivo. Altri tipi di errori non devono essere risolti automaticamente per motivi di continuità e sicurezza aziendali.
Gestione di errori singoli
I computer singoli possono essere soggetti a errori per ogni genere di motivo. A volte sono causati dall'hardware, ad esempio i guasti agli alimentatori e all'hardware di rete. Altri errori sono nel software. Questi errori includono quelli del sistema operativo e del servizio stesso. Service Fabric rileva automaticamente questi tipi di errori, inclusi i casi in cui il computer viene isolato dagli altri computer a causa di problemi di rete.
Indipendentemente dal tipo di servizio, l'esecuzione di una sola istanza provoca tempi di inattività del servizio se per qualche motivo l'unica copia del codice genera un errore.
Per gestire qualsiasi errore singolo, la soluzione più semplice è assicurarsi di eseguire i servizi in più nodi come impostazione predefinita. Per servizi senza stato, assicurarsi che InstanceCount sia maggiore di 1. Per i servizi con stato il requisito minimo è che TargetReplicaSetSize e MinReplicaSetSize siano entrambi impostati a 3. L'esecuzione di più copie del codice del servizio assicura al servizio la capacità di gestire qualsiasi errore automaticamente.
Gestione di errori coordinati
Gli errori coordinati in un cluster possono essere dovuti a modifiche ed errori nell'infrastruttura pianificati o imprevisti di o modifiche software pianificate. Service Fabric crea le zone di infrastruttura che sperimentano errori coordinati come domini di errore. Le aree che sperimentano le modifiche software coordinate vengono modellate come domini di aggiornamento. Per altre informazioni sui domini di errore, sui domini di aggiornamento e sulla topologia del cluster, vedere Descrivere un cluster Service Fabric utilizzando Gestione risorse cluster.
Per impostazione predefinita, Service Fabric considera i domini di errore e di aggiornamento quando si pianificano le posizioni di esecuzione dei servizi. Per impostazione predefinita, Service Fabric tenta di assicurarsi che i servizi vengano eseguiti in diversi domini di errore e di aggiornamento in modo che, se si verificano modifiche pianificate o impreviste, i servizi rimangano disponibili.
Si supponga, ad esempio, che un guasto all'alimentazione determini un errore in un intero rack di computer. Se sono in esecuzione più copie del servizio, la perdita di molti computer per l'errore del dominio di errore si trasforma in un altro semplice esempio di errore singolo per un servizio. Questo perché la gestione dei domini di errore e di aggiornamento è essenziale per garantire la disponibilità elevata dei servizi.
Quando si esegue Azure Service Fabric, i domini di errore e i domini di aggiornamento vengono gestiti automaticamente. In altri ambienti potrebbero non esserlo. Se si creano cluster in locale, assicurarsi di eseguire il mapping e di pianificare il layout del dominio di errore correttamente.
I domini di aggiornamento sono utili per la creazione di aree in cui il software viene aggiornato nello stesso momento. Per questo motivo, i domini di aggiornamento spesso definiscono anche i limiti in cui software viene disattivato durante gli aggiornamenti pianificati. Gli aggiornamenti sia di Service Fabric che dei servizi seguono lo stesso modello. Per altre informazioni sulla distribuzione degli aggiornamenti, i domini di aggiornamento e il modello di integrità di Service Fabric che aiuta a impedire che eventuali modifiche accidentali abbiano ripercussioni sul cluster e sul servizio, vedere:
- Aggiornamento dell'applicazione
- Esercitazione sull'aggiornamento di un'applicazione
- Service Fabric Health Model (Modello di integrità di Service Fabric)
È possibile visualizzare il layout del cluster usando la mappa del cluster disponibile in Service Fabric Explorer:
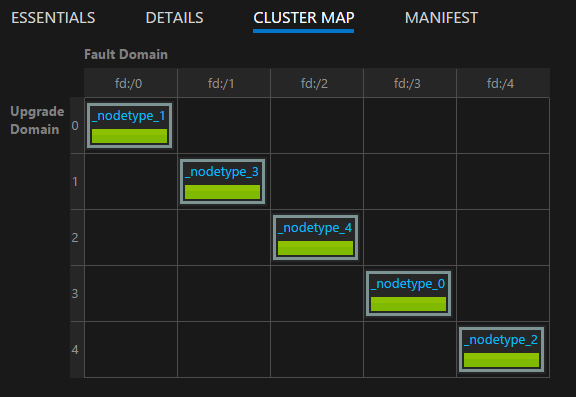
Nota
La creazione di aree di errore, la distribuzione di aggiornamenti, l'esecuzione di molte istanze del codice e dello stato del servizio, le regole di posizionamento che garantiscono l'esecuzione dei servizi nei domini di errore e di aggiornamento e il monitoraggio dell'integrità incorporato sono solo alcune delle funzionalità che Service Fabric offre per evitare che normali errori e problemi operativi si trasformino in situazioni di emergenza.
Gestione di errori hardware o software simultanei
Stiamo parlando di errori singoli. Come si può vedere, questi errori possono essere facilmente gestiti sia per i servizi senza stato che per quelli con stato semplicemente mantenendo più copie del codice (e dello stato) in esecuzione in domini di errore e di aggiornamento.
I servizi possono essere interessati anche da più errori casuali simultanei. Questi errori hanno più probabilità di generare un tempo di inattività o un'emergenza effettiva.
Servizi senza stato
Il numero di istanze per un servizio senza stato indica il numero desiderato di istanze che devono essere in esecuzione. Quando una delle istanze (o tutte) determinano un errore, Service Fabric risponde creando automaticamente istanze sostitutive in altri nodi. Service Fabric continuerà a creare sostituzioni fino a quando il servizio non avrà raggiunto di nuovo il numero di istanze desiderato.
Ad esempio, si supponga che il servizio senza stato abbia un valore InstanceCount di -1. Questo valore significa che un'istanza dovrebbe essere in esecuzione su ogni nodo nel cluster. Se alcune di queste istanze determinano un errore, Service Fabric rileverà che il servizio non è nel suo stato desiderato e tenterà di creare le istanze sui nodi in cui mancano.
Servizi con stato
Sono disponibili due tipi di servizi con stato:
- Con stato con stato persistente.
- Con stato con stato non persistente. (Stato archiviato in memoria.)
Il recupero da un errore di un servizio con stato dipende dal tipo di servizio con stato, dal numero di repliche che il servizio aveva e dal numero di repliche che hanno determinato un errore.
In un servizio con stato, i dati in arrivo vengono replicati tra le repliche (la primaria e le secondarie disponibili). Se la maggior parte delle repliche riceve i dati, si considera che il commit dei dati sia stato eseguito con quorum. (Per cinque repliche, tre costituiranno un quorum.) Ciò significa che in ogni momento ci sarà almeno un quorum di repliche con i dati più recenti. Se delle repliche determinano errori (ad esempio due su cinque), si può utilizzare il valore del quorum per calcolare se è possibile recuperare. (Poiché le restanti tre su cinque repliche sono ancora disponibili, è garantito che almeno una replica avrà dati completi.)
Quando un quorum di repliche determina errori, la partizione viene dichiarata in uno stato di perdita di quorum. Diciamo che una partizione possiede cinque repliche, il che implica che almeno tre sono assicurate di disporre di dati completi. Se un quorum (tre su cinque) di repliche non determina errori, Service Fabric non può determinare se le repliche rimanenti (due su cinque) abbiano abbastanza dati per ripristinare la partizione. Nei casi in cui Service Fabric rileva la perdita del quorum, il suo comportamento predefinito è impedire ulteriori scritture sulla partizione, dichiarare la perdita del quorum e attendere che un quorum di repliche venga ripristinato.
La determinazione di una situazione di emergenza per un servizio con stato e quindi la relativa gestione seguono tre fasi:
Determinazione di una eventuale perdita del quorum.
La perdita del quorum viene dichiarata quando la maggioranza delle repliche di un servizio con stato è inattiva nello stesso momento.
Determinazione se la perdita del quorum è permanente o meno.
Nella maggior parte dei casi gli errori sono temporanei. I processi, i nodi e le macchine virtuali vengono riavviati e le partizioni di rete vengono corrette. In alcuni casi, invece, gli errori sono permanenti. Il fatto che gli errori siano permanenti o meno dipende dal fatto che il servizio senza stato persista nel suo stato o lo mantenga solo in memoria:
- Per i servizi senza stato persistente, un errore di uno o più quorum di repliche determina immediatamente una perdita del quorum permanente. Quando Service Fabric rileva la perdita del quorum in un servizio non persistente con stato, passa immediatamente alla fase 3 dichiarando una (potenziale) perdita di dati. La dichiarazione di una perdita di dati è motivata dal fatto che Service Fabric è a conoscenza dell'inutilità di attendere che le repliche siano nuovamente disponibili. Anche se si recuperano, i dati andranno persi a causa della natura non persistente del servizio.
- Per i servizi permanenti con stato, un errore di uno o più quorum di repliche fa sì che Service Fabric attenda che le repliche tornino disponibili e il quorum venga ripristinato. Si verifica di conseguenza un'interruzione del servizio per tutte le operazioni di scrittura alla partizione interessata (o "set di repliche") del servizio. Le operazioni di lettura restano invece ancora possibili con una minore garanzia di coerenza. La quantità di tempo predefinita in cui Service Fabric attende il ripristino del quorum è infinita, poiché il passaggio successivo è un evento di perdita di dati (potenziale) e comporta altri rischi. Ciò significa che Service Fabric non procederà alla fase successiva a meno che un amministratore non intervenga per dichiarare la perdita di dati.
Determinare se i dati sono persi e ripristinare i backup.
Se la perdita del quorum è stata dichiarata (automaticamente o tramite un'azione amministrativa), Service Fabric e i servizi passano a determinare se i dati sono stati effettivamente persi. A questo punto Service Fabric sa che anche le altre repliche non torneranno disponibili. Si arriva così alla decisione di smettere di attendere che la perdita del quorum si risolva da sola. La migliore linea di azione per il servizio è in genere bloccare la situazione e attendere un intervento specifico da parte dell'amministratore.
Quando Service Fabric chiama il metodo
OnDataLossAsync, è sempre a causa di una sospetta perdita di dati. Service Fabric assicura che la chiamata venga inviata alla migliore replica rimanente, vale a dire quella che ha fatto i maggiori progressi.Il motivo per cui si parla di sospetta perdita di dati è che è possibile che la replica rimanente abbia lo stesso stato della replica primaria è stato perso il quorum. Senza quello stato con cui fare il confronto, tuttavia, non esiste un modo utile che dica a Service Fabric o agli operatori l'effettivo stato.
Cosa fa quindi una tipica implementazione del metodo
OnDataLossAsync?L'implementazione registra che è stato generato un evento
OnDataLossAsynce genera tutti i necessari avvisi amministrativi.Di solito, l'implementazione sospende l'esecuzione e attende ulteriori decisioni e interventi manuali. Questo perché, anche se sono disponibili backup, può essere necessario prepararli.
Se, ad esempio, due servizi diversi coordinano le informazioni, i backup potrebbero dover essere modificati per garantire che dopo il ripristino le informazioni di cui si occupano i due servizi siano coerenti.
Sono spesso presenti anche alcuni dati di telemetria e di scarico dal servizio. Questi metadati possono essere contenuti in altri servizi o in log. Queste informazioni possono essere usate, se necessario, per determinare se sono state ricevute ed elaborate chiamate nella replica primaria che non erano presenti nel backup o replicate in questa replica specifica. Queste chiamate devono essere riprodotte o aggiunte al backup prima che sia fattibile il ripristino.
L'implementazione confronta lo stato della replica rimanente con quello contenuto in tutti i backup disponibili. Se si usano le raccolte affidabili di Service Fabric, sono disponibili strumenti e processi per questa operazione. L'obiettivo consiste nel vedere se lo stato all'interno della replica è sufficiente e vedere cosa potrebbe mancare al backup.
Dopo che è stato eseguito il confronto ed è stato completato il ripristino (se necessario), il codice del servizio dovrebbe restituire true se sono state apportate modifiche allo stato. Se la replica ha determinato che era la migliore copia disponibile dello stato e che non state apportate modifiche, il codice restituisce false.
Un valore di true indica che qualsiasi altra replica rimanente potrebbe ora essere incoerente con questa. Le repliche rimanenti verranno eliminate e ricreate da questa replica. Un valore di false indica che non sono state apportate modifiche allo stato, pertanto le altre repliche possono conservare le informazioni che includono.
È estremamente importante che gli autori del servizio simulino gli scenari di errore e di potenziale perdita di dati prima che i servizi vengano distribuiti nell'ambiente di produzione. Per evitare la possibilità di perdere i dati, è importante eseguire periodicamente il backup dello stato di tutti i servizi con stato in un archivio con ridondanza geografica.
È inoltre necessario assicurarsi di poter ripristinare lo stato. Poiché i backup di numerosi servizi diversi vengono eseguiti in momenti diversi, è necessario assicurarsi che dopo un ripristino i servizi abbiano una visione coerente tra loro.
Si consideri, ad esempio, una situazione in cui un servizio genera un numero e lo archivia, e quindi lo invia a un altro servizio che lo archivia a sua volta. Dopo un ripristino, potrebbe accadere che il secondo servizio abbia conservato il numero mentre il primo servizio non lo conservi più perché il relativo backup non includeva tale operazione.
Se si scopre che le repliche rimanenti non sono sufficienti per continuare in uno scenario di perdita di dati e non è possibile ricostruire lo stato del servizio dai dati di telemetria o di scarico, la frequenza dei backup determina il migliore obiettivo del punto di recupero (RPO) possibile. Service Fabric include molti strumenti per testare vari scenari di errore, tra cui il quorum permanente e la perdita di dati che richiede il ripristino da un backup. Questi scenari sono inclusi nell'ambito degli strumenti di testabilità di Service Fabric, gestiti dal servizio di analisi degli errori. Per altre informazioni su questi strumenti e criteri, vedere la pagina sull'introduzione al servizio di analisi degli errori.
Nota
Anche i servizi di sistema possono subire una perdita di quorum. L'impatto è specifico del servizio in questione. La perdita del quorum nel servizio di denominazione, ad esempio, incide sulla risoluzione dei nomi, mentre la perdita del quorum nel servizio di Gestione failover blocca la creazione e i failover di nuovi servizi.
I servizi di sistema di Service Fabric seguono lo stesso criterio dei servizi per la gestione dello stato, non è consigliabile spostarli dalla perdita del quorum alla potenziale perdita di dati. In alternativa, si consiglia di richiedere supporto per identificare una soluzione adatta alla propria situazione specifica. È di solito preferibile attendere semplicemente che le repliche tornino disponibili.
Risoluzione dei problemi di perdita di quorum
Le repliche potrebbero essere temporaneamente non disponibili a causa di un errore temporaneo. Attendere mentre Service Fabric tenta di renderle disponibili. Se le repliche sono disponibili per un periodo superiore a quello previsto, seguire le azioni seguenti di risoluzione dei problemi:
- Le repliche potrebbero aver subito un arresto anomalo. Verificare i report sull'integrità a livello di replica e i registri applicazioni. Raccogliere i dettagli dell'arresto anomalo e intraprendere le azioni necessarie per il ripristino.
- Il processo di replica potrebbe aver smesso di rispondere. Controllare i registri applicazioni per verificarlo. Raccogliere i dettagli sul processo e quindi interrompere il processo non reattivo. Service Fabric creerà un processo di sostituzione e tenterà di ripristinare la replica.
- I nodi che ospitano le repliche potrebbero essere non attivi. Riavviare la macchina virtuale sottostante per riattivare i nodi.
Talvolta, potrebbe non essere possibile ripristinare le repliche. Ad esempio perché tutte le unità hanno generato errori o perché i computer non rispondono fisicamente. In questi casi, a Service Fabric deve essere comunicato di non attendere il ripristino della replica.
Non usare questi metodi se una potenziale perdita di dati è inaccettabile per riportare il servizio online. In tal caso, si dovrebbero compiere tutti gli sforzi per recuperare le macchine fisiche.
Le seguenti azioni potrebbero comportare una perdita di dati. Verificare prima di seguirle.
Nota
Non è mai sicuro usare questi metodi diversamente dal modo per cui è stata studiata quando si ha a che fare con partizioni specifiche.
- Usare
Repair-ServiceFabricPartition -PartitionIdoppureSystem.Fabric.FabricClient.ClusterManagementClient.RecoverPartitionAsync(Guid partitionId)API. Questa API consente di specificare l'ID della partizione da spostare fuori dalla perdita del quorum e inserirla nella perdita di dati potenziale. - Se il cluster genera frequenti errori che causano lo stato di perdita di quorum dei servizi e una perdita di dati è accettabile, specificare un valore QuorumLossWaitDuration appropriato può aiutare il proprio servizio a recuperare automaticamente. Service Fabric attenderà il valore
QuorumLossWaitDurationfornito (il default è infinito) prima di eseguire il ripristino. Questo metodo non è consigliabile, perché può causare perdite di dati impreviste.
Disponibilità del cluster di Service Fabric
In generale, il cluster di Service Fabric è un ambiente altamente distribuito senza singoli punti di errore. Un errore di un qualsiasi nodo non comporta problemi di disponibilità o di affidabilità per il cluster, principalmente perché i servizi di sistema di Service Fabric seguono le stesse linee guida indicate in precedenza. In altri termini, vengono sempre eseguiti con tre o più repliche per impostazione predefinita e i servizi di sistema che sono senza stato vengono eseguiti in tutti i nodi.
I livelli di rete e di rilevamento degli errori di Service Fabric sono completamente distribuiti. La maggior parte dei servizi di sistema può essere ricreata dai metadati del cluster o sa come risincronizzare il proprio stato da altre posizioni. La disponibilità del cluster può venire compromessa se i servizi di sistema incorrono in situazioni di perdita del quorum come quelle descritte in precedenza. In questi casi potrebbe non essere possibile eseguire determinate operazioni in un cluster, come avviare un aggiornamento o distribuire nuovi servizi, ma il cluster resterebbe attivo.
I servizi di un cluster in esecuzione rimarranno in esecuzione in queste condizioni a meno che non richiedano operazioni di scrittura per i servizi di sistema per continuare a funzionare. Ad esempio, se Gestione failover si trova in uno stato di perdita di quorum, tutti i servizi continueranno a essere eseguiti. Tuttavia, i servizi che generano errori non saranno in grado di riavviarsi automaticamente, poiché ciò richiede l'intervento di Gestione failover.
Errori di un data center o un'area di Azure
In casi rari è possibile che un data center fisico diventi temporaneamente non disponibile a causa di un'interruzione dell'alimentazione o della perdita della connettività di rete. In questi casi i cluster e i servizi di Service Fabric presenti nel data center o nell'area di Azure non saranno disponibili. I dati saranno tuttavia preservati.
Per i cluster in esecuzione in Azure, è possibile visualizzare gli aggiornamenti sulle interruzioni del servizio nella pagina Stato di Azure. Nell'improbabile caso in cui un data center fisico venga danneggiato parzialmente o completamente, tutti i cluster di Service Fabric in esso ospitati o i servizi presenti nei cluster potrebbero andare persi. Questa perdita include tutti gli stati di cui non è stato eseguito il backup al di fuori del data center o dell'area.
Esistono diverse strategie per superare un errore permanente o prolungato di un singolo data center o di un'area:
Eseguire cluster di Service Fabric distinti in più aree e usare un qualche sistema per il failover e il failover tra questi ambienti. Questo tipo di modello cluster multipli attivo-attivo o attivo-passivo richiede codice di gestione e operativo aggiuntivo. Questo modello richiede anche il coordinamento di backup dai servizi in un unico data center o un'unica area in modo che siano disponibili in altri data center o altre aree quando uno di loro genera un errore.
Eseguire un singolo cluster di Service Fabric che si estende su più data center. La configurazione minima supportata per questa strategia è tre data center. Per altre informazioni, vedere Distribuire un cluster di Azure Service Fabric tra zone di disponibilità.
Questo modello richiede una configurazione aggiuntiva. Il vantaggio che offre, tuttavia, è che l'errore di un data center viene convertito da emergenza in errore normale. Questi errori possono essere gestiti dai meccanismi usati per i cluster in una singola area. I domini di errore, i domini di aggiornamento e le regole di posizionamento di Service Fabric assicurano che i carichi di lavoro vengano distribuiti in modo da essere in grado di tollerare gli errori normali.
Per altre informazioni sui criteri che aiutano a far funzionare i servizi in questo tipo di cluster, vedere i Criteri di posizionamento per i servizi Service Fabric.
Eseguire un singolo cluster di Service Fabric che si estende su più aree usando il modello Standalone. Il numero consigliato di aree è tre. Vedere Crea un cluster autonomo per dettagli sulla configurazione di Service Fabric autonomo.
Errori casuali che generano errori del cluster
In Service Fabric è presente il concetto di nodi di inizializzazione. Si tratta di nodi che gestiscono la disponibilità del cluster sottostante.
I nodi aiutano a garantire che il cluster rimanga attivo stabilendo lease con altri nodi e servendo da tiebreaker durante determinati tipi di errori. Se si verificano errori casuali che rimuovono la maggior parte dei nodi di inizializzazione nel cluster e i nodi non vengono ripristinati rapidamente, il cluster si arresta automaticamente. Il cluster quindi determina un errore.
In Azure, il provider di risorse di Service Fabric gestisce le configurazioni dei cluster di Service Fabric. Per impostazione predefinita, il provider di risorse distribuisce i nodi di inizializzazione attraverso domini di errore e di aggiornamento per il tipo di nodo primario. Se il tipo di nodo primario è contrassegnato come di durabilità Silver o Gold, quando si rimuove un nodo di inizializzazione (sia riducendo le dimensioni del tipo di nodo primario sia rimuovendolo manualmente), il cluster tenterà di promuovere un altro nodo di non inizializzazione dalla capacità disponibile del tipo di nodo primario. Questo tentativo avrà esito negativo se si dispone di meno capacità disponibile di quanto il livello di affidabilità del cluster richieda per il tipo di nodo primario.
Sia nei cluster di Service Fabric autonomi che in Azure il tipo di nodo primario è quello che esegue il seeding. Quando si definisce un tipo di nodo primario, Service Fabric sfrutta automaticamente il numero di nodi offerti creando fino a nove nodi di inizializzazione e sette repliche di ognuno dei servizi di sistema. Se un set di errori casuali interrompe l'esecuzione contemporaneamente della maggior parte delle repliche, i servizi del sistema saranno coinvolti nella perdita del quorum. Se la maggior parte dei nodi di inizializzazione viene persa, il cluster si arresta subito dopo.
Passaggi successivi
- Informazioni su come simulare diversi errori usando il framework di verificabilità.
- Lettura di altre risorse sul ripristino di emergenza e sulla disponibilità elevata. Microsoft ha pubblicato molti documenti su questi argomenti. Sebbene alcuni di queste risorse si riferiscano a tecniche specifiche da applicare in altri prodotti, contengono anche molte procedure consigliate generali valide per Service Fabric:
- Informazioni sulle opzioni di supporto di Service Fabric.