Azure VM バックアップの概要
この記事では、Azure Backup サービスによって Azure 仮想マシン (VM) がどのようにバックアップされるかについて説明します。
Azure Backup では、VM 上のデータが誤って破壊されることを防ぐために、独立して分離されたバックアップを提供しています。 バックアップは、復旧ポイントの管理機能をビルトインで備えた Recovery Services コンテナーに格納されます。 構成とスケーリングは単純で、バックアップは最適化され、必要に応じて簡単に復元することができます。
バックアップ プロセスの一環として、スナップショットが取得され、運用環境のワークロードに影響を与えることなく、データが Recovery Services コンテナーに転送されます。 スナップショットは、こちらで説明されているように、さまざまなレベルの一貫性を提供します。 バックアップ ポリシーの中で、エージェントベースのアプリケーション整合性/ファイル整合性バックアップを選ぶことも、エージェントレスのクラッシュ整合性バックアップを選ぶこともできます。
また Azure Backup には、SQL Server や SAP HANA のようなデータベース ワークロードに特化したワークロード対応のサービスがあり、15 分間の RPO (目標復旧時点) を提供し、個々のデータベースのバックアップと復元を可能にします。
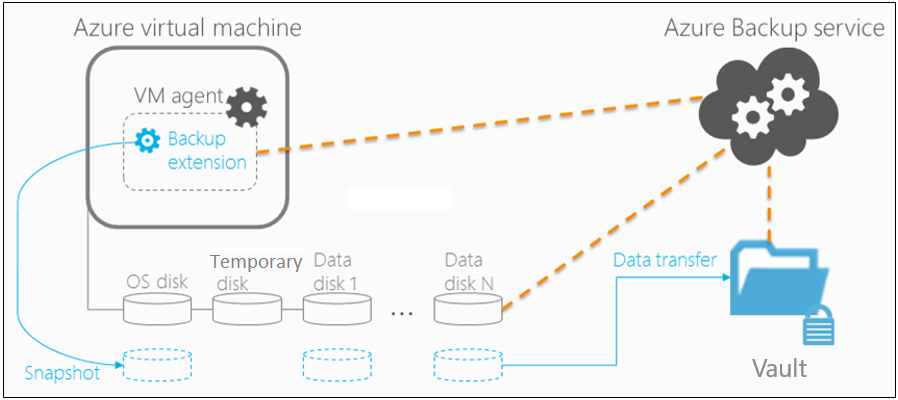
バックアップ プロセス
Azure Backup によって Azure VM のバックアップが行われる方法を説明します。
バックアップの対象として選択されている Azure VM に対して、Azure Backup はユーザーが指定したバックアップ スケジュールに従ってバックアップ ジョブを開始します。
アプリケーションまたはファイル システム整合性バックアップを選択した場合は、スナップショット プロセスと連携させるためのバックアップ拡張機能が VM にインストールされている必要があります。
クラッシュ整合性バックアップを選択した場合は、VM 内にエージェントは必要ありません。
最初のバックアップ時に、バックアップ拡張機能が VM にインストールされます (VM が実行されている場合)。
- Windows VM の場合、VMSnapshot 拡張機能がインストールされます。
- Linux VM の場合、VMSnapshotLinux 拡張機能がインストールされます。
実行中の Windows VM については、Azure Backup と Windows ボリューム シャドウ コピー サービス (VSS) との連携によって VM のアプリ整合性スナップショットが取得されます。
- 既定では、Backup によって完全 VSS バックアップが取得されます。
- Backup はアプリ整合性スナップショットを取得できない場合、基になるストレージのファイル整合性スナップショットを取得します (VM の停止中はアプリケーションの書き込みは行われないため)。
Linux VM の場合、Backup ではファイル整合性スナップショットが取得されます。 アプリ整合性スナップショットの場合は、事前/事後スクリプトを手動でカスタマイズする必要があります。
Windows VM の場合、Microsoft Visual C++ 2013 再頒布可能パッケージ (x64) バージョン 12.0.40660 がインストールされ、ボリューム シャドウ コピー サービス (VSS) の起動が "自動" に変更され、Windows サービス IaaSVmProvider が追加されます。
Backup でスナップショットが取得された後、コンテナーにデータが転送されます。
- バックアップは、各 VM ディスクを並列にバックアップすることで最適化されます。
- バックアップされているディスクごとに、Azure Backup はディスク上のブロックを読み取り、前回のバックアップ以降に変更されたデータ ブロックのみ (差分) を識別して転送します。
- スナップショット データはコンテナーにすぐにコピーされない場合があります。 ピーク時には、数時間かかる場合があります。 毎日のバックアップ ポリシーでは、VM のバックアップの合計時間は 24 時間未満になります。
Azure VM バックアップの暗号化
Azure Backup を使用して Azure VM をバックアップすると、保存中の VM は Storage Service Encryption (SSE) を使用して暗号化されます。 Azure Backup では、Azure Disk Encryption を使用して暗号化されている Azure VM もバックアップできます。
| 暗号化 | 詳細 | サポート |
|---|---|---|
| SSE | SSE では、Azure Storage により、データを格納する前に自動的に暗号化することで、保存中の暗号化が提供されます。 Azure Storage では、取得前にデータの暗号化解除も行われます。 Azure Backup では、次の 2 種類の Storage Service Encryption を使用した VM のバックアップがサポートされています。 |
Azure Backup では、Azure VM の保存中の暗号化のために SSE が使用されます。 |
| Azure Disk Encryption | Azure Disk Encryption では Azure VM の OS とデータ ディスクの両方が暗号化されます。 Azure Disk Encryption は、シークレットとしてキー コンテナーで保護されている BitLocker 暗号化キー (BEK) と統合されます。 Azure Disk Encryption は、Azure Key Vault キー暗号化キー (KEK) とも統合されます。 |
Azure Backup では、BEK のみで、または BEK と KEK を併用して、暗号化されたマネージドおよびアンマネージド Azure VM のバックアップがサポートされます。 BEK と KEK の両方がバックアップされて暗号化されます。 KEK と BEK がバックアップされるため、必要に応じて、必要なアクセス許可を持つユーザーは、キーとシークレットをキー コンテナーに復元できます。 ユーザーは、暗号化された VM を復旧することもできます。 暗号化されたキーとシークレットは、承認されていないユーザー、または Azure は読み取ることはできません。 |
マネージドおよびアンマネージド Azure VM の場合、Backup では、BEK のみで暗号化された VM と、BEK と KEK を併用して暗号化された VM の両方がサポートされます。
バックアップされる BEK (シークレット) と KEK (キー) は暗号化されます。 承認されたユーザーによってキー コンテナーに復元されたときに限り、読み取りと使用が可能です。 承認されていないユーザーも Azure も、バックアップされたキーまたはシークレットの読み取りまたは使用はできません。
BEK もバックアップされます。 そのため、BEK が失われた場合、承認されたユーザーは BEK をキー コンテナーに復元し、暗号化された VM を復旧できます。 必要なレベルの権限を持つユーザーのみが、暗号化された VM またはキーとシークレットを、バックアップして復元できます。
スナップショットの作成
Azure Backup では、バックアップ スケジュールに従ってスナップショットが取得されます。
アプリケーションまたはファイル システム整合性バックアップを選択した場合は、スナップショット プロセスと連携させるためのバックアップ拡張機能が VM にインストールされている必要があります。 "エージェントレス マルチディスク クラッシュ整合性" バックアップの場合は、スナップショット用の VM エージェントは必要ありません。
Windows VM: Windows VM の場合、Backup サービスは VSS と連携して、VM ディスクのアプリ整合性スナップショットを取得します。 既定の Azure Backup では、VSS の完全バックアップが作成されます (アプリケーション レベルで整合性のあるバックアップを取得するため、バックアップ時に、SQL Server などのアプリケーションのログは切り捨てられます)。 Azure VM バックアップで SQL Server データベースを使用している場合は、(ログを保持するために) VSS コピー バックアップを作成するように設定を変更できます。 詳細については、 こちらの記事を参照してください。
Linux VM: Linux VM のアプリ整合性スナップショットを取得するには、Linux の事前スクリプトおよび事後スクリプトのフレームワークを使用して、整合性を保証するための独自のカスタム スクリプトを記述します。
- Azure Backup では、ユーザーが記述した事前/事後スクリプトのみが呼び出されます。
- 事前スクリプトと事後スクリプトが正常に実行されると、Azure Backup は復旧ポイントをアプリケーション整合性としてマークします。 ただし、カスタム スクリプトを使用している場合、アプリケーションの整合性については最終的にユーザーが責任を負います。
- スクリプトの構成方法に関する詳細を確認してください。
スナップショットの整合性
次の表では、スナップショットの整合性の種類について説明します。
| スナップショット | 詳細 | 回復 | 考慮事項 |
|---|---|---|---|
| アプリケーションの整合性 | これは、VM バックアップ ポリシーでの既定の設定です。 アプリ整合性バックアップでは、メモリの内容と保留中の I/O 操作がキャプチャされます。 アプリ整合性スナップショットでは、バックアップが発生する前にアプリ データの整合性を保証するために、VSS ライター (または Linux の事前/事後スクリプト) が使用されます。 | アプリ整合性スナップショットで VM を復旧すると、VM が起動されます。 データの損失や破損はありません。 アプリは整合性が確保された状態で開始します。 | Windows: すべての VSS ライターが成功した Linux: 事前/事後スクリプトが構成されて成功した |
| ファイル システム整合性 | これは、VM バックアップ ポリシーでの既定の設定です。 ファイル システム整合性バックアップでは、同時にすべてのファイルのスナップショットを作成することで整合性が提供されます。 |
ファイル システム整合性スナップショットで VM を復旧すると、VM が起動されます。 データの損失や破損はありません。 復元されたデータの整合性を確保するために、アプリには独自の "修正" メカニズムを実装する必要があります。 | Windows: 一部の VSS ライターが失敗した Linux: 既定 (事前/事後スクリプトが構成されていないか失敗した) |
| クラッシュ整合性 | クラッシュ整合性スナップショットは、VM バックアップ ポリシーでのオプトイン設定です。 Azure Backup によるクラッシュ整合性バックアップは、バックアップ中に VM が実行されていない場合や、アプリケーション/ファイル整合性バックアップが失敗した場合にも実行されます。 バックアップ操作時にディスクに既に存在するデータのみがキャプチャされてバックアップされます。読み取り/書き込みホスト キャッシュ内のデータはキャプチャされません。 |
VM のブート プロセスから開始し、その後ディスク チェックを行って破損エラーを修正します。 クラッシュ前にディスクに転送されなかったメモリ内のデータや書き込み操作は、すべて失われます。 アプリは独自のデータ検証を実装しています。 たとえば、データベース アプリでは検証のためトランザクション ログを使用できます。 トランザクション ログにデータベース内に存在しないエントリが含まれている場合、データベース ソフトウェアはデータの整合性が得られるまでトランザクションをロールバックします。 | アプリケーション/ファイル システム バックアップが選択されていて VM がシャットダウン (停止/割り当て解除済み) 状態のとき、およびスナップショットが再試行されたとき。 エージェントレス クラッシュ整合性バックアップが選択済み |
Note
プロビジョニングの状態が成功の場合、Azure Backup ではファイル システム整合性バックアップが実行されます。 プロビジョニングの状態が使用不可または失敗の場合は、クラッシュ整合性バックアップが実行されます。 プロビジョニングの状態が作成中または削除中の場合は、Azure Backup が操作を再試行していることを意味します。
バックアップと復元の考慮事項
| 考慮事項 | 詳細 |
|---|---|
| ディスク | VM ディスクのバックアップは並列です。 たとえば、VM にディスクが 4 つある場合、Backup サービスは 4 つすべてのディスクを並列でバックアップしようとします。 バックアップは増分的 (変更されたデータのみ) です。 |
| スケジュール設定 | バックアップ トラフィックを減らすには、異なる VM を一日の異なる時間帯にバックアップし、時間帯が重ならないようにします。 同時に VM をバックアップすると、トラフィックの渋滞が発生します。 |
| バックアップの準備 | バックアップの準備に必要な時間に注意してください。 準備時間には、バックアップ拡張機能のインストールまたは更新と、バックアップ スケジュールに従ったスナップショットのトリガーが含まれることが考えられます。 |
| データ転送 | Azure Backup で前回のバックアップからの増分変更を識別するために必要な時間を考慮してください。 増分バックアップの Azure Backup では、ブロックのチェックサムを計算することによって、変更が特定されます。 ブロックが変更されている場合は、コンテナーに転送するようにマークされます。 サービスは識別されたブロックを分析して、転送するデータ量をさらに最小化しようとします。 変更されたブロックすべての評価が完了した後に、その変更が Azure Backup によってコンテナーに転送されます。 スナップショットを取得してからコンテナーにコピーするまでの間、ラグが生じる場合があります。 ピーク時には、スナップショットがコンテナーに転送されるまで、最大 8 時間かかることがあります。 毎日のバックアップでは、VM のバックアップ時間は 24 時間未満になります。 |
| 初回バックアップ | 増分バックアップの合計バックアップ時間は 24 時間未満ですが、初回バックアップの場合は、このとおりではないこともあります。 初回バックアップに必要な時間は、データのサイズと、いつバックアップが処理されるかによって異なります。 |
| 復元キュー | Azure Backup では複数のストレージ アカウントからの復元ジョブが同時に処理され、復元要求はキューに入れられます。 |
| 復元コピー | 復元処理の間、データがコンテナーからストレージ アカウントにコピーされます。 合計復元時間は、1 秒あたりの I/O 操作数 (IOPS) とストレージ アカウントのスループットによって異なります。 コピー時間を短縮するには、他のアプリケーションの書き込みおよび読み取りの負荷がないストレージ アカウントを選択します。 |
Note
Azure Backup では、拡張ポリシーを使用して Azure VM を 1 日に複数回バックアップできるようになりました。 この機能を使用すると、Azure Virtual Machines の更新が頻繁に行われる場合に、バックアップ ジョブがトリガーされる期間を定義し、バックアップ スケジュールを業務時間に合わせて調整することもできます。 詳細については、こちらを参照してください。
バックアップ パフォーマンス
以下の一般的なシナリオは、合計バックアップ時間に影響を与える可能性があります。
- 保護された Azure VM への新しいディスクの追加: VM で増分バックアップが行われているときに、新しいディスクが追加されると、バックアップの時間が長くなります。 既存ディスクの差分レプリケーションに加えて、新しいディスクの初期レプリケーションが行われるため、合計バックアップが 24 時間を超える場合があります。
- 断片化したディスク: ディスクの変更が連続していると、バックアップ操作は速くなります。 変更がディスク全体に分散および断片化している場合、バックアップは遅くなります。
- ディスク チャーン: 増分バックアップが実行されている保護されたディスクで毎日のチャーンが 200 GB を超える場合、バックアップの完了に時間がかかる (8 時間を超える) 可能性があります。
- バックアップのバージョン: (インスタント リストア バージョンと呼ばれる) 最新バージョンの Backup では、変更の識別に、チェックサム比較より最適化されたプロセスが使用されます。 ただし、インスタント リストアを使用していて、バックアップ スナップショットを削除した場合、バックアップはチェックサム比較に切り替わります。 この場合、バックアップ操作は 24 時間を超えます (または失敗します)。
復元のパフォーマンス
以下の一般的なシナリオは、合計復元時間に影響を与える可能性があります。
- 合計復元時間は、1 秒あたりの I/O 操作数 (IOPS) とストレージ アカウントのスループットによって異なります。
- 合計復元時間は、ターゲットのストレージ アカウントに他のアプリケーションの読み取りや書き込み操作が読み込まれる場合、影響を受けることがあります。 復元操作を改善するには、他のアプリケーション データが読み込まれないストレージ アカウントを選択します。
ベスト プラクティス
VM バックアップを構成するときは、次のプラクティスに従うことをお勧めします。
- ポリシーで設定されている既定のスケジュール時間を変更します。 たとえば、ポリシーで既定の時間が午前 0 時の場合、リソースが最適に使用されるよう、数分時間を進めることを検討してください。
- 1 つのコンテナーから複数の VM を復元する場合は、ターゲットのストレージ アカウントがスロットルされないようにするために、それぞれ異なる汎用 v2 ストレージ アカウントを使用することを強くお勧めします。 たとえば、VM ごとに異なるストレージ アカウントが必要です。 たとえば、10 個の VM を復元する場合は、10 個の異なるストレージ アカウントを使用します。
- インスタント リストアでの Premium Storage を使用している VM のバックアップについては、割り当てられた合計記憶域スペースの 50% の空き領域を割り当てることが推奨されます。これは最初のバックアップにのみ必要です。 最初のバックアップが完了すると、バックアップに 50% の空き領域は不要になります。
- ストレージ アカウントあたりのディスク数の制限は、サービスとしてのインフラストラクチャ (IaaS) VM で実行されているアプリケーションがディスクにどれくらいアクセスするかによって決まります。 通常、1 つのストレージ アカウント上に 5 ~ 10 個以上のディスクが存在する場合は、一部のディスクを別のストレージ アカウントに移動して負荷を分散します。
- PowerShell を使用してマネージド ディスクが含まれている VM を復元するには、追加のパラメーター TargetResourceGroupName を指定して、マネージド ディスクの復元先となるリソース グループを指定します。詳細についてはこちらを参照してください。
バックアップのコスト
Azure Backup を使用してバックアップされている Azure VM は、Azure Backup の価格の対象になります。
課金は、最初のバックアップが正常に完了するまでは開始されません。 この時点で、ストレージと保護する VM の両方に対する課金が開始されます。 VM のバックアップ データがコンテナーに格納されている限り、課金は継続されます。 VM の保護を停止したが VM のバックアップ データがコンテナーに存在している場合、課金は継続されます。
指定された VM に対する課金は、保護が停止され、かつすべてのバックアップ データが削除された場合にのみ停止します。 保護が停止してアクティブなバックアップ ジョブがないとき、最後に成功した VM バックアップのサイズは、毎月の課金に使用する保護されたインスタンスのサイズになります。
エージェントベースのアプリケーション整合性またはファイル システム整合性バックアップを選択した場合は、保護されたインスタンスのサイズは VM の "実際の" サイズに基づいて計算されます。 VM のサイズは、一時的なストレージを除く、VM 内のすべてのデータの合計です。 価格は、VM にアタッチされている各データ ディスクの最大サポート サイズではなく、データ ディスクに格納されている実際のデータに基づきます。
Note
エージェントレス クラッシュ整合性バックアップについては、プレビュー期間中は現在 VM あたり 0.5 個の保護されたインスタンス (PI) の料金が請求されます。
同様に、バックアップ ストレージの課金は、Azure Backup に格納されているデータ量 (各回復ポイントの実際のデータの合計) に基づきます。
たとえば、最大サイズが各 32 TB のデータ ディスクが 2 台追加で搭載されている A2 Standard サイズの VM があるとします。 次の表は、これらの各ディスクに格納されている実際のデータです。
| ディスク | 最大サイズ | 実際のデータ量 |
|---|---|---|
| OS ディスク | 32 TB | 17 GB |
| ローカル/一時ディスク | 135 GB | 5 GB (バックアップに含まれない) |
| データ ディスク 1 | 32 TB | 30 GB |
| データ ディスク 2 | 32 TB | 0 GB |
この場合の VM の実際のサイズは、17 GB + 30 GB + 0 GB = 47 GB です。 この保護されたインスタンスのサイズ (47 GB) が、毎月の課金の基礎になります。 VM のデータ量が大きくなると、課金に使用される保護されたインスタンスのサイズもそれに応じて変化します。