検索サービスの容量を見積もって管理する
Azure AI Search では、容量はワークロードに合わせてスケーリングできる "レプリカ" と "パーティション" に基づいています。 レプリカは検索エンジンのコピーです。 パーティションはストレージの単位です。 新しい検索サービスはそれぞれ 1 つずつ開始されますが、変動するワークロードに対応するために、レプリカとパーティションの追加または削除を個別に行うことができます。 容量を追加すると、検索サービスを実行するコストが増加します。
処理速度やディスク IO など、レプリカとパーティションの物理的な特性は、サービス レベルによって異なります。 標準の検索サービスでは、レプリカとパーティションは基本サービスにあるものよりも高速で大きくなります。
容量の変更は瞬時には行われません。 特に大量のデータが含まれているサービスでは、パーティションのコミッションまたは使用停止に最大で 1 時間かかることがあります。
検索サービスをスケーリングする場合は、次のツールと方法で選択できます。
概念: 検索ユニット、レプリカ、パーティション
容量は、パーティションとレプリカの組み合わせで割り当てることができる検索ユニットで表されます。
| 概念 | 定義 |
|---|---|
| 検索単位 | 使用可能な合計容量の単一増分 (36 ユニット)。 これは、Azure AI Search サービスの課金単位でもあります。 サービスを実行するには、少なくとも 1 つの単位が必要です。 |
| [レプリカ] | 主にクエリ操作の負荷分散に使用される Search サービスのインスタンスです。 各レプリカは、インデックスの 1 つのコピーをホストします。 3 つのレプリカを割り当てると、クエリ要求のサービスに使用できるインデックスのコピーが 3 つ作成されます。 |
| パーティション | 読み取り/書き込み操作 (たとえば、インデックスを再構築または更新する場合など) のための物理ストレージと I/O。 各パーティションにインデックス全体のスライスがあります。 3 つのパーティションを割り当てると、インデックスは 3 つに分割されます。 |
パーティションとレプリカのテーブルで、36 ユニットの制限を超えない可能性のある組み合わせを確認します。
容量をいつ追加するか
最初に、1 つのパーティションと 1 つのレプリカで構成される最小限のリソースがサービスに割り当てられます。 選択するレベルによってパーティションのサイズと速度が決まり、各レベルはさまざまなシナリオに適した一連の特性に対して最適化されます。 ハイエンド レベルを選択した場合は、S1 を使用する場合よりもパーティション数を減らす必要がある場合があります。 自己指示型のテストを通じて回答する必要がある質問の 1 つは、より大きなパーティションの方が、低いレベルでプロビジョニングされたサービス上の 2 つの安価なパーティションよりもパフォーマンスが優れているかどうかということです。
1 つのサービスに、すべてのワークロード (インデックスおよびクエリ) を処理するための十分なリソースが必要です。 どちらのワークロードもバックグラウンドで実行されません。 クエリ要求の頻度が低い時間帯にインデックスを作成するようにスケジュールできますが、それ以外の時間帯では、特定のタスクが別のタスクより優先されることはありません。 さらに、ある程度の冗長性により、サービスまたはノードが内部的に更新されるときのクエリのパフォーマンスの問題を解決します。
容量を追加するかどうかを判断するためのガイドラインを次に示します。
- サービス レベル アグリーメントの高可用性条件を満たす
- HTTP 503 エラーの頻度が増加している
- 大規模なクエリ ボリュームが想定される
一般的な規則として、検索アプリケーションでは、パーティションよりもレプリカの方が多く必要となる傾向があります。特に、サービス操作でクエリ ワークロードの比重が高い場合は、その傾向が強まります。 各レプリカは、インデックスの 1 コピーです。これにより、サービスでは、複数のコピーに対して要求を負荷分散できます。 インデックスの負荷分散とレプリケーションはすべて Azure AI Search によって管理されます。サービスに割り当てられたレプリカの数はいつでも変更できます。 Standard Search サービスでは最大 12 個、Basic Search サービスでは最大 3 個のレプリカを割り当てることができます。 レプリカの割り当ては、Azure portal またはプログラム オプションの 1 つのいずれかから行うことができます。
追加のパーティションは、集中的なインデックス作成ワークロードに役立ちます。 パーティションを追加すると、読み取り/書き込み操作がより多くのコンピューティング リソースに分散されます。
最後に、インデックスが大きくなると、クエリの実行に時間がかかります。 そのため、パーティションで段階的な増加が発生するたびに、レプリカでは小規模であるが比例的な増加が必要となる場合があります。 クエリの複雑さとボリュームは、クエリの実行が完了するまでの速度の要因となります。
Note
レプリカやパーティションを追加すると、サービスの実行コストが増加し、結果の並べ替え方法が少し変化する可能性があります。 ノードを追加した場合の課金の影響を理解するには、料金計算ツール を必ず確認してください。 下のグラフは、特定の構成に必要な検索単位の数を相互参照するのに役立ちます。 レプリカの追加によるクエリ処理への影響について詳しくは、「結果の並べ替え」をご覧ください。
容量を変更する方法
検索サービスの容量を増減するには、パーティションとレプリカを追加または削除します。
Azure Portal にサインインし、Search サービスを選択します。
[設定] で、[スケール] ページを開いてレプリカとパーティションの数を変更します。
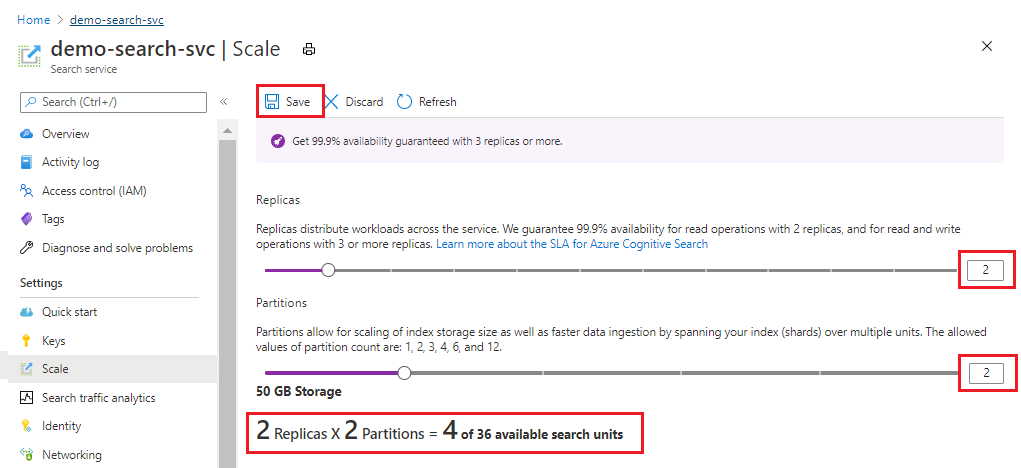
次のスクリーンショットは、1 つのレプリカとパーティションでプロビジョニングされる Standard サービスを示しています。 下部の式は、使用される検索ユニットの数 (1) を示しています。 ユニットの価格が 100 ドル (実際の価格ではありません) の場合、このサービスを実行するための毎月のコストは平均 100 ドルになります。
![現在の値が表示されている [スケール] ページ](media/search-capacity-planning/1-initial-values.png)
スライダーを使ってパーティションの数を増減します。 [保存] を選択します。
この例では、2 つ目のレプリカおよびパーティションを追加します。 請求の計算式では、レプリカ数とパーティション数が乗算されるため (2 x 2)、検索ユニット数が 4 になっていることに注意してください。 容量を 2 倍にすると、サービスを実行するためのコストが 2 倍以上になります。 検索ユニットのコストが 100 ドルの場合、新しい毎月の請求額は 400 ドルになります。
各レベルの現在のユニットあたりのコストについては、価格のページをご覧ください。
保存した後、通知を確認して、操作が成功したことを確認できます。
容量の変更が完了するまでに 15 分から最大で数時間かかることがあります。 プロセスが開始されたらキャンセルすることはできません。また、レプリカとパーティションの調整のリアルタイムの監視はありません。 ただし、変更が行われている間、次のメッセージが常に表示されています。

Note
サービスをプロビジョニングした後は、上位のレベルにアップグレードすることはできません。 新しいレベルで Search Service を作成し、インデックスを再度読み込む必要があります。 サービス プロビジョニングについては、「ポータルで Azure AI Search サービスを作成する」を参照してください。
スケーリング要求を処理する方法
スケーリング要求を受け取ると、検索サービスでは次のことを行います。
- 要求が有効であるかどうかを確認します。
- データとシステム情報のバックアップを開始します。
- サービスが既にプロビジョニング状態になっているかどうかを確認します (現在、レプリカまたはパーティションの追加または削除を実行中)。
- プロビジョニングを開始します。
サービスのスケーリングには、サービスのサイズと要求の範囲に応じて、わずか 15 分しかかからないこともあれば、1 時間以上かかることもあります。 バックアップには、データ量とパーティションおよびレプリカの数に応じて、数分かかることがあります。
上記の手順は完全に連続しているわけではありません。 たとえば、システムでは、安全に行えるようになったときに、プロビジョニングを開始します。それは、バックアップが終わり近づいているときかもしれません。
スケーリング中のエラー
"前の要求を処理中であるため、現時点ではサービスの更新操作は許可されません" というエラー メッセージが表示される原因は、サービスによって既に前の要求の処理が開始されているときに、スケール ダウンまたはスケール アップの要求が繰り返されたことにあります。
このエラーを解決するには、サービスの状態を調べてプロビジョニングの状態を確認します。
- 管理 REST API、Azure PowerShell 、またはAzure CLI を使用してサービス ステータスを取得します。
- Get Service (REST) または PowerShell または CLI でそれに相当するものを呼び出します。
- 応答を調べて、"provisioningState": "provisioning" を確認します。
状態が "Provisioning" である場合は、要求が完了するまで待ちます。 別の要求が試行されるには、状態が "Succeeded" または "Failed" のいずれかになっている必要があります。 バックアップの状態は存在しません。 バックアップは内部操作であって、スケーリング演習の中断の要因になる可能性はほとんどありません。
検索サービスがプロビジョニング状態で停止しているように見られる場合は、クエリ ボリュームが 0 でインデックスが更新されていない状態の、使用できない孤立したインデックスがないか確認します。 使用できないインデックスがある場合、サービス容量の変更がブロックされることがあります。 特に、キーが無効になっている、CMK で暗号化されたインデックスを探します。 インデックスを削除するか、キーを復元してインデックスをオンラインに戻し、スケール操作のブロックを解除する必要があります。
パーティションとレプリカの組み合わせ
次のグラフは、Standard レベル以上に適用されます。 パーティションとレプリカのすべての可能な組み合わせが表示されます。サービスごとに最大 36 個の検索ユニットが適用されます。
| 1 個のパーティション | 2 個のパーティション | 3 個のパーティション | 4 個のパーティション | 6 個のパーティション | 12 個のパーティション | |
|---|---|---|---|---|---|---|
| 1 つのレプリカ | 1 SU | 2 SU | 3 SU | 4 SU | 6 SU | 12 SU |
| 2 つのレプリカ | 2 SU | 4 SU | 6 SU | 8 SU | 12 SU | 24 SU |
| 3 つのレプリカ | 3 SU | 6 SU | 9 SU | 12 SU | 18 SU | 36 SU |
| 4 つのレプリカ | 4 SU | 8 SU | 12 SU | 16 SU | 24 SU | 該当なし |
| 5 つのレプリカ | 5 SU | 10 SU | 15 SU | 20 SU | 30 SU | 該当なし |
| 6 つのレプリカ | 6 SU | 12 SU | 18 SU | 24 SU | 36 SU | 該当なし |
| 12 レプリカ | 12 SU | 24 SU | 36 SU | 該当なし | 該当なし | 該当なし |
Basic 検索サービスでは、検索ユニット数が少なくなります。
2024 年 4 月 3 日より前に作成された検索サービスの場合、Basic 検索サービスでは、パーティションを 1 つのみ、レプリカを 3 つまで持つことができ、SU の上限は 3 つです。 調整可能なリソースはレプリカだけです。
サポートされているリージョンに 2024 年 4 月 3 日より後に作成された検索サービスの場合、Basic サービスでは最大 3 つのパーティションと 3 つのレプリカを持つことができます。 パーティションとレプリカを完全にサポートするために、SU の上限は 9 です。
作成日に関係なく、どの課金対象レベルの検索サービスでも、クエリの高可用性を実現するには少なくとも 2 つのレプリカが必要です。
レベルごとの課金レートと通貨については、Azure AI 検索の価格に関するページを参照してください。
課金対象レベルを使用した容量の見積もり
ストレージのニーズは、構築する予定のインデックスのサイズによって決まります。 見積もりに役立つような、信頼できる経験則や一般原則はありません。 インデックスのサイズを見極める唯一の方法は、1 つ構築することです。 そのサイズは、トークン化と埋め込み、suggester、フィルター処理、並べ替えを有効にするか、ベクトル圧縮を利用できるかに基づいています。
課金対象レベル (Basic 以上) で見積もることをお勧めします。 Free レベルは、複数の顧客が共有する物理リソースで実行され、制御を超える要因の対象となります。 課金対象の検索サービスの専用のリソースでのみ、より長いサンプリングと処理時間に対応でき、開発段階でのインデックスの数量、サイズ、クエリ量についてより現実的な見積もりを求めることができます。
各レベルのサービス制限を確認して、より低いレベルで、必要なインデックス数に対応できるかどうかを判断してください。 アクティブな開発、テスト、運用のためにインデックスの複数のコピーが必要かどうかを検討します。
検索サービスには、オブジェクトの制限 (インデックス、インデクサー、スキルセットの最大数など) とストレージの制限が適用されます。 最初に達した制限が、有効な制限になります。
課金対象レベルでサービスを作成します。 レベルは、特定のワークロード向けに最適化されています。 たとえば、ストレージ最適化レベルは、少数の非常に大きいインデックスをサポートするように設計されているため、10 インデックスに制限されています。
予想される負荷がわからない場合は、Basic または S1 の低いレベルで始めます。
テストに大規模なインデックス作成とクエリの負荷が含まれている場合は、S2 または S3 の高レベルから始めます。
社内のビジネス アプリケーションのように、インデックスを付けるデータの量が多く、クエリの負荷が比較的低い場合は、Storage Optimized (L1 または L2) から始めます。
最初のインデックスを構築して、ソース データがどのようにインデックスに変換されるかを特定します。 これは、インデックスのサイズを推測する唯一の方法です。 フィールド定義の属性は、物理ストレージの要件に影響します。
キーワード検索の場合、フィールドをフィルター可能および並べ替え可能としてマークすると、インデックス サイズが大きくなります。
ベクトル検索の場合は、パラメーターを設定してストレージを減らすことができます。
ポータルで、ストレージ、サービス制限、クエリ量、および待機時間を監視します。 秒あたりのクエリ数、調整されたクエリ数、および検索の待ち時間がポータルに表示されます。 これらすべての値が、適切なレベルを選択したかどうかを判断するために役立ちます。
可用性を高めたり、クエリのパフォーマンス低下を軽減したりするためにレプリカを追加します。
クエリの負荷に対応するために必要なレプリカの数に関するガイドラインはありません。 クエリのパフォーマンスは、クエリおよび競合するワークロードの複雑さによって異なります。 レプリカを追加するとパフォーマンスが向上しますが、厳密に線形に向上するわけではありません。3 つのレプリカを追加しても、スループットが 3 倍になるとは限りません。 ソリューションの QPS を推定する方法のガイダンスについては、パフォーマンスのための分析と、クエリの監視に関する記事を参照してください。
転置インデックスのサイズと複雑性はコンテンツによって決まり、必ずしもそれにフィードするデータ量によって決まるものではありません。 冗長性の高い大規模なデータ ソースは、変動の多いコンテンツを含む小さいデータセットよりも、インデックスのサイズが小さくなることがあります。 そのため、元のデータ セットのサイズに基づいてインデックスのサイズを推測できることはほとんどありません。
検索されることのないデータが含まれていると、ストレージの要件が増大することがあります。 ドキュメントには、検索機能に必要なデータのみが含まれていることが理想的な状態です。
サービス レベル アグリーメントに関する考慮事項
Free レベルおよびプレビュー機能は、サービス レベル アグリーメント (SLA) の対象ではありません。 課金対象のすべてのレベルで、SLA が有効になるのは、サービスにとって十分な冗長性がプロビジョニングされるときです。
2 つ以上のレプリカがクエリ (読み取り) の SLA を満たしている。
3 つ以上のレプリカがクエリとインデックス作成 (読み取り/書き込み) の SLA を満たしている。
パーティションの数は、SLA に影響しません。