Azure Data Lake Storage Gen2 の使用に関するベスト プラクティス
この記事では、パフォーマンスを最適化して、コストを削減し、Data Lake Storage Gen2 が有効な Azure Storage アカウントをセキュリティで保護するためのベスト プラクティスのガイドラインについて説明します。
データ レイクの構築に関する一般的な提案については、次の記事を参照してください。
- データ管理および分析シナリオの Azure Data Lake Storage の概要
- データ ランディング ゾーンごとに 3 つの Azure Data Lake Storage Gen2 アカウントをプロビジョニングする
ドキュメントの検索
Azure Data Lake Storage Gen2 は、専用サービスまたはアカウントの種類ではありません。 これは、高スループットの分析ワークロードをサポートする一連の機能です。 Data Lake Storage Gen2 のドキュメントでは、これらの機能を使用するためのベスト プラクティスとガイダンスについて説明します。 ネットワーク セキュリティの設定、高可用性の設計、ディザスター リカバリーなど、アカウント管理のその他のすべての側面については、Blob Storage のドキュメントのコンテンツを参照してください。
機能のサポートと既知の問題を評価する
Blob Storage の機能を使用するようにアカウントを構成する場合は、次のパターンを使用します。
アカウントで機能が完全にサポートされているかどうかを判断するには、「Azure ストレージ アカウントにおける Blob Storage 機能のサポート」を参照してください。 一部の機能はまだサポートされていないか、Data Lake Storage Gen2 が有効なアカウントで一部サポートされています。 機能のサポートは常に拡張されているため、この記事の更新について定期的に確認してください。
使用する機能に関する制限事項や特別なガイダンスがあるかどうかを確認するには、「Azure Data Lake Storage Gen2 に関する既知の問題」を参照してください。
Data Lake Storage Gen2 が有効なアカウントに固有のガイダンスについては、機能に関する記事に目を通しておいてください。
ドキュメントで使用されている用語を理解する
コンテンツ セット間を移動すると、わずかな用語の違いがわかります。 たとえば、Blob Storage のドキュメントに含まれるコンテンツでは、"ファイル" ではなく "BLOB" という用語が使用されます。 技術的には、ストレージ アカウントに取り込むファイルは、アカウント内の BLOB になります。 そのため、その用語が正しくなります。 ただし、"ファイル" という用語に慣れている場合、"BLOB" という用語によって混乱が生じる可能性があります。 "ファイル システム" を指す場合は、 "コンテナー" という用語も使用されます。 これらの用語は同義と見なします。
Premium を検討する
ワークロードで待機時間を一貫して短くする必要がある場合、また 1 秒あたりの入出力操作数 (IOP) を高くする必要がある場合は、Premium ブロック BLOB ストレージ アカウントの使用を検討してください。 このタイプのアカウントでは、高パフォーマンスのハードウェアを介してデータを処理できます。 データは、低待機時間のために最適化されたソリッドステート ドライブ (SSD) に格納されています。 SSD は従来のハード ドライブと比べ、スループットが高くなります。 Premium パフォーマンスの方がストレージ コストは高くなりますが、トランザクション コストは低くなります。 したがって、ワークロードで多数のトランザクションを実行する場合、Premium パフォーマンス ブロック BLOB アカウントは経済的である可能性があります。
ストレージ アカウントを分析に使用する場合は、Premium ブロック BLOB ストレージ アカウントと共に Azure Data Lake Storage Gen2 を使用することを強くお勧めします。 Premium ブロック BLOB ストレージ アカウントと Data Lake Storage 対応アカウントを組み合わせて使用する方法は、Azure Data Lake Storage の Premium レベルと呼ばれています。
データの取り込みを最適化する
ソース システムからデータを取り込むときに、ソース ハードウェア、ソース ネットワーク ハードウェア、またはストレージ アカウントへのネットワーク接続がボトルネックになることがあります。

ソース ハードウェア
オンプレミスのマシンを使用するか、Azure で仮想マシン (VM) を使用しているかにかかわらず、適切なハードウェアを慎重に選択してください。 ディスク ハードウェアの場合は、ソリッド ステート ドライブ (SSD) の使用を検討し、より高速なスピンドルを搭載したディスク ハードウェアを選択してください。 ネットワーク ハードウェアの場合は、できるだけ最速のネットワーク インターフェイス コントローラー (NIC) を使用します。 Azure に関しては、適度に強力なディスクとネットワーク ハードウェアを備えた Azure D14 VM をお勧めします。
ストレージ アカウントへのネットワーク接続
ソース データとストレージ アカウントとの間のネットワーク接続がボトルネックになることがあります。 ソース データがオンプレミスの場合、Azure ExpressRoute で専用のリンクを使用することを検討してください。 ソース データが Azure にある場合、データが Data Lake Storage Gen2 対応アカウントと同じ Azure リージョンにあると、パフォーマンスは最適となります。
データ インジェスト ツールの最大並列化処理の構成
最高のパフォーマンスを得るには、できるだけ多くの読み取りと書き込みを並列に実行して、使用可能なすべてのスループットを使用します。
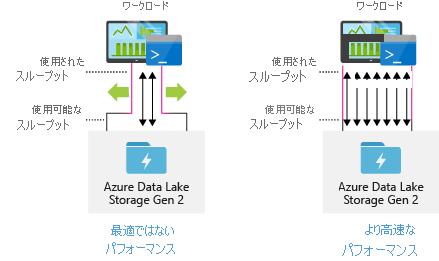
次の表に、一般的なインジェスト ツールの主要な設定の概要を示します。
| ツール | 設定 |
|---|---|
| DistCp | -m (マッパー) |
| Azure Data Factory | parallelCopies |
| Sqoop | fs.azure.block.size、-m (マッパー) |
Note
取り込み操作の全体的なパフォーマンスは、データの取り込みに使用しているツールに固有の他の要因によって異なります。 最新のガイダンスについては、使用する予定の各ツールのドキュメントを参照してください。
アカウントは、あらゆる分析シナリオで必要とされるスループットを提供するようにスケーリングできます。 既定では、Data Lake Storage Gen2 対応アカウントは、広範なカテゴリのユース ケースのニーズを満たすのに十分なスループットを既定の構成で提供します。 既定の制限に達した場合、Azure サポートに連絡して、さらに高いスループットを提供するようにアカウントを構成することができます。
構造体のデータセット
データの構造を事前に計画することを検討してください。 ファイル形式、ファイル サイズ、ディレクトリ構造は、すべてパフォーマンスとコストに影響します。
ファイル形式
データはさまざまな形式で読み込むことができます。 データは、JSON、CSV、XML などの人間が判読できる形式、または .tar.gz などの圧縮されたバイナリ形式で表示できます。 データのサイズもさまざまです。 データは、オンプレミス システムからの SQL テーブルのエクスポートのデータなど、大きなファイル (数テラバイト) で構成できます。 データは、モノのインターネット (IoT) ソリューションのリアルタイム イベントからのデータなど、多数の小さなファイル (数キロバイト) の形式で表示されることもあります。 適切なファイル形式とファイル サイズを選択すれば、効率とコストを最適化できます。
Hadoop では、構造化データを格納および処理するために最適化された一連のファイル形式をサポートしています。 一般的な形式としては、Avro、Parquet、Optimized Row Columnar (ORC) があります。 これらの形式はすべて、コンピューターが判読できるバイナリ ファイル形式です。 これらは、ファイル サイズを管理できるように圧縮されています。 各ファイルにはスキーマが埋め込まれているため、自己記述型になります。 これらの形式の違いは、データの格納方法です。 Avro では行ベースの形式でデータが格納され、Parquet および ORC 形式では列形式でデータが格納されます。
Avro ファイル形式は、I/O パターンの書き込み負荷が高い場合や、クエリ パターンで複数行のレコード全体の取得に重点を置いている場合に使用を検討してください。 たとえば、Avro 形式は、複数のイベント/メッセージを連続して書き込む Event Hubs や Kafka などのメッセージ バスに適しています。
Parquet および ORC ファイル形式は、I/O パターンの読み取り負荷が高い場合や、クエリ パターンでレコード内の列のサブセットに重点を置いている場合に検討してください。 レコード全体を読み取るのではなく、特定の列を取得するために読み取りトランザクションを最適化できます。
Apache Parquet は、読み取り負荷の高い分析パイプラインに最適化されたオープン ソース ファイル形式です。 Parquet の列指向ストレージ構造を使用すると、関連のないデータをスキップできます。 ストレージから分析エンジンに送信するデータの範囲を絞ることができるので、クエリの方がはるかに効率的です。 また、類似のデータ型 (列の場合) が一緒に格納されるため、Parquet ではデータ ストレージ コストを削減できる効率的なデータ圧縮とエンコード スキームをサポートしています。 Azure Synapse Analytics、Azure Databricks、Azure Data Factory などのサービスには、Parquet ファイル形式を利用するネイティブ機能があります。
ファイル サイズ
ファイル サイズを大きくすると、パフォーマンスが向上し、コストが削減されます。
通常、HDInsight などの分析エンジンには、一覧表示、アクセスの確認、さまざまなメタデータ操作の実行などのタスクを含むファイルごとのオーバーヘッドがあります。 データを多数の小さなファイルとして保存すると、パフォーマンスに悪影響を及ぼすことがあります。 一般的に、データを大きなサイズ (256 MB から 100 GB のサイズ) のファイルに整理するとパフォーマンスが向上します。 エンジンとアプリケーションの中には、サイズが 100 GB を超えるファイルを効率的に処理できないものもあります。
ファイル サイズを大きくすると、トランザクションのコストを削減することもできます。 読み取りと書き込みの操作は 4 MB 単位で課金されるため、ファイルのサイズが 4 MB であるか、数キロバイトであるかにかかわらず、操作に対して課金されます。 価格の情報については、「Azure Data Lake Storage の価格」を参照してください。
場合によっては、データ パイプラインで小さなファイルを多数含む生データの制御が制限されることがあります。 一般に、ダウンストリーム アプリケーションで使用できるように小さいファイルを大きなファイルに集約する何らかのプロセスを、お使いのシステムに用意することをお勧めします。 リアルタイムでデータを処理している場合、リアル タイム ストリーミング エンジン (Azure Stream Analytics や Spark Streaming など) を、メッセージ ブローカー (Event Hubs や Apache Kafka など) と一緒に使用して、より大きなファイルとしてデータを保存できます。 小さいファイルを大きなファイルにまとめるときは、ダウンストリーム処理のために Apache Parquet などの読み取り最適化形式で保存することを検討してください。
ディレクトリの構造
すべてのワークロードのデータの消費方法に関する要件は異なりますが、モノのインターネット (IoT) およびバッチのシナリオを操作する場合、または時系列データを最適化する場合の共通のレイアウトをいくつか紹介します。
IoT の構造
IoT のワークロードでは、取り込まれるデータは、製品、端末、組織、お客様と多岐にわたります。 ダウンストリーム コンシューマーのために、組織のディレクトリのレイアウト、セキュリティ、データの効率的な処理について、事前に計画することが重要です。 考慮する一般的なテンプレートは、次のようなレイアウトになります。
- {Region}/{SubjectMatter(s)}/{yyyy}/{mm}/{dd}/{hh}/
たとえば、英国の飛行機のエンジンのランディング テレメトリは次のような構造になります。
- UK/Planes/BA1293/Engine1/2017/08/11/12/
この例では、ディレクトリ構造の末尾に日付を指定することで、ACL を使用して、より簡単に特定のユーザーとグループに対してリージョンと主題をセキュリティで保護できます。 日付構造を先頭に指定すると、これらのリージョンと主題をセキュリティで保護することが大幅に難しくなります。 たとえば、英国のデータまたは特定の飛行機のみにアクセスを提供する場合は、時間ごとのディレクトリの下にある多数のディレクトリに対して個別にアクセス許可を適用する必要があります。 また、この構造の場合、時間が経過するにつれてディレクトリの数が指数関数的に増加します。
バッチ ジョブの構造
バッチ処理で一般的に使用される方法は、データを "in" ディレクトリに配置することです。 その後、データが処理されたら新しいデータを "out" ディレクトリに入れて、ダウンストリームのプロセスで使用できるようにします。 このディレクトリ構造は、個々のファイルに対する処理が必要で、大規模なデータセットに対する膨大な並列処理が必要とされない可能性があるジョブで使用されることがあります。 前述の推奨される IoT の構造と同様に、優れたディレクトリ構造にはリージョンや主題 (例: 組織、製品、製造業者) などの項目用に、親レベルのディレクトリがあります。 プロセスでより優れた組織、フィルター検索、セキュリティ、自動化を実現するために、構造で日付と時間を考慮します。 日付構造の細分性のレベルは、データがアップロードまたは処理される間隔 (毎時、毎日、毎月など) によって決まります。
ファイルのプロセスがデータの破損や予期しない形式により失敗することがあります。 このようなケースでは、 /bad フォルダーにファイルを移動してさらに調査すると便利な場合があります。 また、バッチ ジョブはこれらの "不良" ファイルのレポート作成や通知を管理し、手動で介入できるようにします。 次のテンプレート構造を考慮してください。
- {Region}/{SubjectMatter(s)}/In/{yyyy}/{mm}/{dd}/{hh}/
- {Region}/{SubjectMatter(s)}/Out/{yyyy}/{mm}/{dd}/{hh}/
- {Region}/{SubjectMatter(s)}/Bad/{yyyy}/{mm}/{dd}/{hh}/
たとえば、ある北米のマーケティング企業は、更新されたお客様情報の抽出データをクライアントから毎日受け取ります。 処理される前と後では、次のスニペットのようになります。
- NA/Extracts/ACMEPaperCo/In/2017/08/14/updates_08142017.csv
- NA/Extracts/ACMEPaperCo/Out/2017/08/14/processed_updates_08142017.csv
Hive や従来の SQL データベースなどのデータベースで直接処理される一般的なバッチ データの場合、出力は既に Hive テーブルまたは外部データベースの別のフォルダーに入るように設定されているため、 /in または /out ディレクトリは不要です。 たとえば、顧客から日単位で抽出したものをそれぞれのディレクトリに配置します。 さらに、Azure Data Factory、Apache Oozie、Apache Airflow などのサービスによって、Hive や Spark の毎日のジョブをトリガーし、データを処理して Hive のテーブルに書き込みます。
時系列データ構造
Hive ワークロードでは、時系列データのパーティションを削除すると、一部のクエリがデータのサブセットのみを読み取るようにできるため、パフォーマンスを向上させることができます。
時系列データを取り込むこれらのパイプラインでは、多くの場合、ファイルに構造化されたファイル名やフォルダー名が付けられます。 以下に、日付によって構成されたデータの一般的な例を示します。
"/DataSet/YYYY/MM/DD/datafile_YYYY_MM_DD.tsv"
フォルダーとファイル名の両方に、日時の情報が示されていることに注意してください。
日付と時刻については、以下が一般的なパターンです。
"/DataSet/YYYY/MM/DD/HH/mm/datafile_YYYY_MM_DD_HH_mm.tsv"
繰り返しになりますが、フォルダーとファイルの整理については、より大きなファイルサイズに最適化され、各フォルダーに妥当な数のファイルが配置されるような選択を行ってください。
セキュリティを設定する
まず、「BLOB ストレージのセキュリティに関する推奨事項」の記事の推奨事項を確認してください。 偶発的または悪意のある削除からデータを保護する方法、ファイアウォールの内側にあるデータをセキュリティで保護する方法、ID 管理の基礎として Microsoft Entra ID を使用する方法についてのベスト プラクティスのガイダンスを紹介します。
次に、Data Lake Storage Gen2 が有効なアカウントに固有のガイダンスについては、「Azure Data Lake Storage Gen2 のアクセス制御モデル」を参照してください。 この記事は、Azure のロールベースのアクセス制御 (Azure RBAC) ロールをアクセス制御リスト (ACL) とともに使用して、階層ファイル システム内のディレクトリとファイルにセキュリティ アクセス許可を適用する方法を理解するのに役立ちます。
取り込み、処理、分析
Data Lake Storage Gen2 対応アカウントにデータを取り込むには、数多くのデータ ソースとさまざまな方法が存在します。
たとえば、HDInsight と Hadoop クラスターから大量のデータ セットを取り込んだり、アプリケーションのプロトタイプを作成するために、アドホック データの小さなセットを取り込んだりできます。 アプリケーション、デバイス、センサーなどのさまざまなソースによって生成されたストリーミング データを取り込むことができます。 この種類のデータでは、ツールを使用して、リアルタイムでイベントごとにデータをキャプチャして処理し、その後、イベントをアカウントに一括で書き込むことができます。 ページ要求の履歴などの情報を含む Web サーバー ログを取り込むこともできます。 ログ データの場合は、データをアップロードするためのカスタム スクリプトまたはアプリケーションを作成することを検討してください。これにより、大規模なビッグ データ アプリケーションの一部としてデータ アップロード コンポーネントを柔軟に組み込むことができます。
アカウントでデータを使用できるようになると、そのデータに対して分析を実行したり、視覚エフェクトを作成したり、データをローカル コンピューターやその他のリポジトリ (Azure SQL データベースや SQL Server インスタンスなど) にダウンロードしたりすることができます。
以下の表では、データの取り込み、分析、視覚化、ダウンロードに使用できるツールを推奨しています。 この表のリンクで、各ツールの構成方法と使用方法に関するガイダンスを参照してください。
| 目的 | ツールとツールのガイダンス |
|---|---|
| アドホック データの取り込み | Azure portal、Azure PowerShell、Azure CLI、REST、Azure Storage Explorer、Apache DistCp、AzCopy |
| リレーショナル データの取り込み | Azure Data Factory |
| Web サーバーのログの取り込み | Azure PowerShell、Azure CLI、REST、Azure SDK (.NET、Java、Python、Node.js)、Azure Data Factory |
| HDInsight クラスターから取り込み | Azure Data Factory、Apache DistCp、AzCopy |
| Hadoop クラスターから取り込み | Azure Data Factory、Apache DistCp、WANdisco LiveData Migrator for Azure、Azure Data Box |
| 大きなデータ セットの取り込み (数テラバイト) | Azure ExpressRoute |
| データの表示と分析 | Azure Synapse Analytics、Azure HDInsight、Databricks |
| データの視覚化 | Power BI、Azure Data Lake Storage のクエリ アクセラレーション |
| データをダウンロードする | Azure portal、PowerShell、Azure CLI、REST、Azure SDK (.NET、Java、Python、Node.js)、Azure Storage Explorer、AzCopy、Azure Data Factory、Apache DistCp |
Note
この表には、Data Lake Storage Gen2 がサポートされる Azure サービスの完全な一覧が反映されているわけではありません。 サポートされる Azure サービスの一覧と、そのサポートのレベルについては、「Azure Data Lake Storage Gen2 がサポートされている Azure のサービス」を参照してください。
テレメトリを監視する
使用とパフォーマンスの監視は、サービスの運用の重要な部分です。 たとえば、頻繁な操作、待機時間の長い操作、サービス側の調整を引き起こす操作などです。
ストレージ アカウントのすべてのテレメトリは、Azure Monitor の Azure Storage のログで確認できます。 この機能により、ストレージ アカウントと Log Analytics およびイベント ハブが統合され、ログを別のストレージ アカウントにアーカイブすることもできます。 メトリックとリソース ログの完全な一覧と、関連付けられているスキーマについては、「Azure Blob Storage 監視データのリファレンス」を参照してください。
ログを格納する場所は、ログにアクセスする方法によって異なります。 たとえば、ほぼリアルタイムでログにアクセスし、ログ内のイベントを Azure Monitor の他のメトリックと関連付けできる場合は、Log Analytics ワークスペースにログを格納できます。 その後、KQL を使用してログに対してクエリを実行し、ワークスペースに StorageBlobLogs テーブルを列挙するクエリを作成できます。
ほぼリアルタイムのクエリと長期保有の両方のログを格納する場合は、Log Analytics ワークスペースとストレージ アカウントの両方にログを送信する診断設定を構成できます。
Splunk などの別のクエリ エンジンを介してログにアクセスする場合は、イベント ハブにログを送信し、イベント ハブから、選択した宛先にログを取り込む診断設定を構成できます。
Azure Monitor の Azure Storage は、Azure portal、PowerShell、Azure CLI、Azure Resource Manager テンプレートを使用して有効にできます。 大規模なデプロイの場合、修復タスクを完全にサポートした Azure Policy を使用できます。 詳細については、ciphertxt/AzureStoragePolicy を参照してください。