自動シード処理を使用して、Always On 可用性グループのセカンダリ レプリカを初期化する
適用対象:![]() SQL Server
SQL Server
SQL Server 2012 および 2014 では、SQL Server Always On 可用性グループでセカンダリ レプリカを初期化する唯一の方法はバックアップ、コピー、および復元を使用することです。 SQL Server 2016 では、セカンダリ レプリカを初期化するための自動シード処理という新機能が導入されています。 自動シード処理ではログ ストリーム トランスポートを使用して、VDI を使用するバックアップを、構成済みのエンドポイントを使用する可用性グループの各データベースのセカンダリ レプリカにストリーミングします。 この新機能は、可用性グループの最初の作成時やデータベースの追加時に使用できます。 自動シード処理は、Always On 可用性グループをサポートする SQL Server のすべてのエディションで、従来の可用性グループと分散型可用性グループの両方で使用できます。
セキュリティ
セキュリティのアクセス許可は、初期化されるレプリカの種類によって異なります。
- 従来の可用性グループの場合、セカンダリ レプリカは可用性グループに結合されているため、その可用性グループにアクセス許可を与える必要があります。 Transact-SQL では、コマンド
ALTER AVAILABILITY GROUP [<AGName>] GRANT CREATE ANY DATABASEを使用します。 - 作成されるレプリカのデータベースが 2 番目の可用性グループのプライマリ レプリカにある分散型可用性グループの場合、既にそれはプライマリであるため、余分なアクセス許可は必要ありません。 ただし、2 番目の可用性グループにレプリカが 1 つしかない場合は、2 番目の可用性グループの名前に
CREATE ANY DATABASEアクセス許可を付与します。そうしないと、自動シード処理が失敗する可能性があります。 - 分散型可用性グループの 2 番目の可用性グループのセカンダリ レプリカの場合は、コマンド
ALTER AVAILABILITY GROUP [<2ndAGName>] GRANT CREATE ANY DATABASEを使用する必要があります。 このセカンダリ レプリカは 2 番目の可用性グループのプライマリからシード処理されます。
プライマリ レプリカへのパフォーマンスおよびトランザクション ログの影響
自動シード処理は、データベースのサイズ、ネットワーク速度、およびプライマリ レプリカとセカンダリ レプリカの間の距離に応じて、セカンダリ レプリカを初期化するのに実用的である場合とそうでない場合があります。 次に例を示します。
- データベース サイズが 5 TB である。
- ネットワーク速度が 1Gb/秒である。
- 2 つのサイト間の距離が 1000 マイルである。
全帯域を使用可能な場合、1Gb/秒のネットワークは 125 MB/秒の持続スループットを提供できます。この例では、自動シード処理時間が 11 時間をわずかに超えます。 実際に、距離が長いほどネットワーク信号が弱くなり、リンクはネットワーク上の他のリソースと共有されるため、自動シード処理プロセスの速度は低下します。 シード処理中に、プライマリ レプリカでのデータベースのトランザクション ログは増大し続け、データベースの自動シード処理が完了するまで切り捨てることはできません。 そのため、トランザクション ログを切り捨てる場合はトランザクション ログ バックアップを使用します。
自動シード処理は、最大 5 つのデータベースを処理できるシングル スレッド プロセスです。 シングル スレッドは、可用性グループに複数のデータベースがある場合は特に、パフォーマンスに影響する可能性があります。
自動シード処理では圧縮を使用できますが、既定では使用不可になっています。 圧縮を有効にすると、ネットワーク帯域幅が減り、プロセス速度が上がる可能性はありますが、その代りにプロセッサのオーバーヘッドが増えます。 自動シード処理中に圧縮を使用するには、トレース フラグ 9567 を有効にします (「可用性グループの圧縮の調整」を参照)。
ディスク レイアウト
SQL Server 2016 以前では、自動シード処理でデータベースが作成されるフォルダーが既に存在しており、プライマリ レプリカのパスと同じである必要があります。
SQL Server 2017 では、可用性グループに参加するすべてのレプリカで同じデータとログ ファイルのパスを使用することをお勧めしますが、必要に応じて別のパスを使用することもできます。 たとえば、クロス プラットフォーム可用性グループの場合、SQL Server のあるインスタンスは Windows 上に、SQL Server の別インスタンスは Linux 上に展開することができます。 プラットフォームによって、既定のパスは異なります。 SQL Server 2017 は、既定のパスが異なる SQL Server のインスタンス上にある可用性グループ レプリカをサポートしています。
次の表は、自動シード処理に対応できるサポート対象のデータ ディスク レイアウトの例をまとめたものです。
| プライマリ インスタンス の既定のデータ パス |
セカンダリ インスタンス の既定のデータ パス |
プライマリ インスタンス のソース ファイルの場所 |
セカンダリ インスタンス のターゲット ファイルの場所 |
|---|---|---|---|
| c:\data\ | /var/opt/mssql/data/ | c:\data\ | /var/opt/mssql/data/ |
| c:\data\ | /var/opt/mssql/data/ | c:\data\group1\ | /var/opt/mssql/data/group1/ |
| c:\data\ | d:\data\ | c:\data\ | d:\data\ |
| c:\data\ | d:\data\ | c:\data\group1\ | d:\data\group1\ |
プライマリおよびセカンダリのレプリカ データベースの場所がインスタンスの既定のパスではないシナリオは、この変更の影響を受けません。 セカンダリ レプリカ ファイルのパスをプライマリ レプリカ ファイルのパスと合わせるという要件は同じままです。
| プライマリ インスタンス の既定のデータ パス |
セカンダリ インスタンス の既定のデータ パス |
プライマリ インスタンス のファイルの場所 |
セカンダリ インスタンス のファイルの場所 |
|---|---|---|---|
| c:\data\ | c:\data\ | d:\group1\ | d:\group1\ |
| c:\data\ | c:\data\ | d:\data\ | d:\data\ |
| c:\data\ | c:\data\ | d:\data\group1\ | d:\data\group1\ |
プライマリ レプリカとセカンダリ レプリカで既定のパスと既定以外のパスを混合していると、SQL Server 2017 は以前のリリースと異なる動作になります。 次の表は、SQL Server 2017 の動作の一覧です。
| プライマリ インスタンス の既定のデータ パス |
セカンダリ インスタンス の既定のデータ パス |
プライマリ インスタンス のファイルの場所 |
SQL Server 2016 セカンダリ インスタンス のファイルの場所 |
SQL Server 2017 セカンダリ インスタンス のファイルの場所 |
|---|---|---|---|---|
| c:\data\ | d:\data\ | c:\data\ | c:\data\ | d:\data\ |
| c:\data\ | d:\data\ | c:\data\group1\ | c:\data\group1\ | d:\data\group1\ |
SQL Server 2016 以前の動作に戻すには、トレース フラグ 9571 を有効にします。 トレース フラグを有効にする方法については、「DBCC TRACEON (Transact-SQL)」を参照してください。
自動シード処理で可用性グループを作成する
Transact-SQL または SQL Server Management Studio (SSMS、バージョン 17 以降) で自動シード処理を使用して、可用性グループを作成します。 SSMS で可用性グループ ウィザードを使用するには、これらの手順に従います。手順 9 に進むと、最初の既定のオプションとして自動シード処理が示されます。
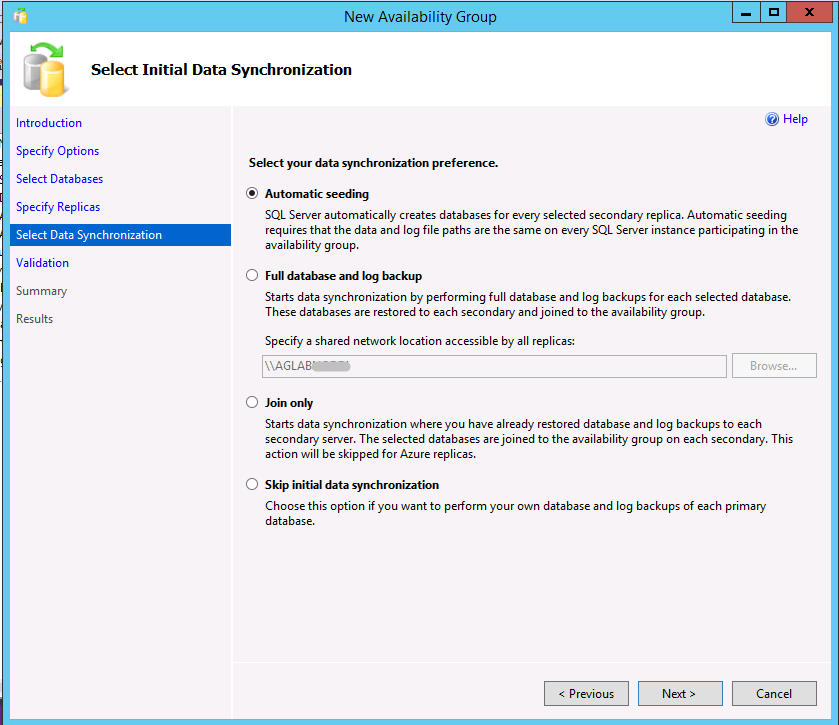
次の例では、Transact-SQL の自動シード処理を使用して可用性グループを作成します。 「可用性グループの作成 (Transact-SQL)」も参照してください。 シード処理は、SEEDING_MODE オプションを AUTOMATIC に設定することでセカンダリ レプリカで有効になります。 既定の動作は MANUAL です。これは、SQL Server 2016 より前の動作であり、プライマリ レプリカでのデータベースのバックアップ作成、セカンダリ レプリカへのバックアップ ファイルのコピー、および WITH NORECOVERY を指定したバックアップの復元が必要です。
CREATE AVAILABILITY GROUP [<AGName>]
FOR DATABASE db1
REPLICA ON N'Primary_Replica'
WITH (
ENDPOINT_URL = N'TCP://Primary_Replica.Contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT
),
N'Secondary_Replica' WITH (
ENDPOINT_URL = N'TCP://Secondary_Replica.Contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
SEEDING_MODE = AUTOMATIC);
GO
CREATE AVAILABILITY GROUP ステートメントの実行中にプライマリ レプリカで SEEDING_MODE を設定しても、プライマリ レプリカには既にデータベースの主要な読み取り/書き込みコピーが含まれているため、効果はありません。 SEEDING_MODE が適用されるのは、別のレプリカがプライマリになっており、データベースが追加されている場合のみです。 シード処理モードは後で変更できます (「レプリカのシード処理モードを変更する」を参照)。
セカンダリ レプリカになるインスタンスの場合、インスタンスが結合されると、SQL Server ログに次のようなメッセージが追加されます。
可用性グループ 'AGName' のローカル可用性レプリカには、データベースの作成アクセス許可は与えられていませんが、
SEEDING_MODEがAUTOMATICになっています。ALTER AVAILABILITY GROUP ... GRANT CREATE ANY DATABASEコマンドを使用して、プライマリ可用性レプリカによってシード処理されるデータベースを作成できるようにします。
セカンダリ レプリカの CREATE DATABASE アクセス許可を可用性グループに付与する
参加後に、SQL Server のセカンダリ レプリカ インスタンスでデータベースを作成するアクセス許可を可用性グループに付与します。 自動シード処理が動作するには、データベースを作成するアクセス許可が可用性グループに必要です。
ヒント
可用性グループがセカンダリ レプリカにデータベースを作成すると、データベース所有者の所有者として "sa" (さらに具体的には sid が 0x01 のアカウント) が設定されます。
セカンダリ レプリカにデータベースが自動的に作成された後にデータベース所有者を変更するには、ALTER AUTHORIZATION を使用します。 「ALTER AUTHORIZATION (Transact-SQL)」を参照してください。
次の例では、このアクセス許可を AGName という可用性グループに付与します。
ALTER AVAILABILITY GROUP [<AGName>]
GRANT CREATE ANY DATABASE
GO
必要に応じて、セカンダリ レプリカのデータベース所有者を設定します。
自動シード処理を確認する
成功した場合、次のいずれかの状態のセカンダリ レプリカでデータベースが自動的に作成されます。
- SYNCHRONIZED: セカンダリ レプリカが同期されるように構成されており、データが同期されている場合。
- SYNCHRONIZING: セカンダリ レプリカが非同期データ移動で構成されているか、同期で構成されているが、プライマリ レプリカとはまだ同期していない場合。
以下に示す動的管理ビューに加え、自動シード処理の開始および完了を SQL Server ログで確認することができます。

バックアップおよび復元を自動シード処理と組み合わせる
従来のバックアップ、コピー、および復元を自動シード処理と組み合わせることができます。 その場合は、まず、すべての使用可能なトランザクション ログを含め、セカンダリ レプリカでデータベースを復元します。 次に、ログ末尾のバックアップの復元の場合と同じように (「ログ末尾のバックアップ (SQL Server)」を参照)、セカンダリ レプリカのデータベースを "キャッチアップ" するための可用性グループを作成する際に自動シード処理を有効にします。
自動シード処理で可用性グループにデータベースを追加する
Transact-SQL または SQL Server Management Studio (SSMS、バージョン 17 以降) で自動シード処理を使用して、可用性グループにデータベースを追加することができます。
セカンダリ レプリカで、可用性グループへの追加時に自動シード処理が使用された場合は、何もする必要はありません。 セカンダリ レプリカで、バックアップ、コピー、および復元が使用された場合は、まず、シード処理モードを変更し (次のセクションを参照)、データベースを追加する際に GRANT ステートメントを使用します (「可用性グループ - データベースの追加」を参照)。
レプリカのシード処理モードを変更する
可用性グループの作成後にレプリカのシード処理モードを変更できます。したがって、自動シード処理を有効または無効にすることができます。 作成後に自動シード処理を有効にすれば、バックアップ、コピー、および復元で作成する場合と同じように、自動シード処理を使用して可用性グループにデータベースを追加できます。 次に例を示します。
ALTER AVAILABILITY GROUP [AGName]
MODIFY REPLICA ON 'Replica_Name'
WITH (SEEDING_MODE = AUTOMATIC)
自動シード処理を無効にするには、MANUAL の値を使用します。
可用性グループの作成後の自動シード処理を防ぐ
セカンダリ レプリカで自動シード処理を完全に無効にはしないが、セカンダリ レプリカが一時的にデータベースを自動作成できないようにする場合は、可用性グループの CREATE アクセス許可を拒否します。 これは、新しいデータベースは可用性グループに追加されるが、可用性グループがセカンダリ レプリカでデータベースを作成するのを許可すべきではない場合です。
ALTER AVAILABILITY GROUP [AGName]
DENY CREATE ANY DATABASE
GO
自動シード処理を監視する
自動シード処理を監視してトラブルシューティングを行う方法には次の 4 つがあります。
- SQL Server ログ (前述のとおり)
- 動的管理ビュー
- バックアップ履歴テーブル
- 拡張イベント
動的管理ビュー
シード処理の監視に使用できる動的管理ビュー (DMV) には、sys.dm_hadr_automatic_seeding と sys.dm_hadr_physical_seeding_stats の 2 つがあります。
sys.dm_hadr_automatic_seedingには自動シード処理の一般的な状態が含まれ、実行ごとに (成功したかどうかに関係なく) 履歴が保持されます。current_state列には COMPLETED または FAILED の値が含まれます。 値が FAILED の場合は、failure_state_descの値を使用します。これは、問題の診断に役立ちます。 SQL Server ログに示されているものと組み合わせて問題を確認する必要がある場合があります。 この DMV はプライマリ レプリカとすべてのセカンダリ レプリカで設定されます。sys.dm_hadr_physical_seeding_statsには、自動シード処理操作の実行時の状態が表示されます。sys.dm_hadr_automatic_seedingと同様に、プライマリ レプリカとセカンダリ レプリカの両方について値を返しますが、その履歴は保存されません。 値は現在の実行のみに関するものであり、保持されません。 関係する列にはstart_time_utc、end_time_utc、estimate_time_complete_utc、total_disk_io_wait_time_ms、total_network_wait_time_msなどがあり、シード処理操作が失敗した場合は failure_message になります。
バックアップ履歴テーブル
自動シード処理では、バックアップと復元の履歴を格納する msdb テーブルにもエントリが入力されます。 自動シード処理を受信するセカンダリ レプリカでは、backupmediafamily テーブルの physical_device_name 列にその値の GUID が示され、backupset の対応するエントリには server_name および machine_name のプライマリ レプリカの名前が示されます。
拡張イベント
自動シード処理には、初期化中の状態変更、エラー、およびパフォーマンス統計情報を追跡するための新しい拡張イベントが追加されています。 たとえば、以下のスクリプトでは、自動シード処理に関連したイベントをキャプチャする拡張イベント セッションを作成します。
CREATE EVENT SESSION [AlwaysOn_autoseed] ON SERVER
ADD EVENT sqlserver.hadr_automatic_seeding_state_transition,
ADD EVENT sqlserver.hadr_automatic_seeding_timeout,
ADD EVENT sqlserver.hadr_db_manager_seeding_request_msg,
ADD EVENT sqlserver.hadr_physical_seeding_backup_state_change,
ADD EVENT sqlserver.hadr_physical_seeding_failure,
ADD EVENT sqlserver.hadr_physical_seeding_forwarder_state_change,
ADD EVENT sqlserver.hadr_physical_seeding_forwarder_target_state_change,
ADD EVENT sqlserver.hadr_physical_seeding_progress,
ADD EVENT sqlserver.hadr_physical_seeding_restore_state_change,
ADD EVENT sqlserver.hadr_physical_seeding_submit_callback
ADD TARGET package0.event_file(
SET filename=N'autoseed.xel',
max_file_size=(5),
max_rollover_files=(4)
)
WITH (
MAX_MEMORY=4096 KB,
EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,
MAX_DISPATCH_LATENCY=30 SECONDS,
MAX_EVENT_SIZE=0 KB,
MEMORY_PARTITION_MODE=NONE,
TRACK_CAUSALITY=OFF,
STARTUP_STATE=ON
)
GO
ALTER EVENT SESSION AlwaysOn_autoseed ON SERVER STATE=START
GO
次の表に、自動シード処理に関連する拡張イベントを示します。
| 名前 | 説明 |
|---|---|
| hadr_db_manager_seeding_request_msg | シード処理要求メッセージ。 |
| hadr_physical_seeding_backup_state_change | 物理シード処理のバックアップ側の状態変更。 |
| hadr_physical_seeding_restore_state_change | 物理シード処理の復元側の状態変更。 |
| hadr_physical_seeding_forwarder_state_change | 物理シード処理のフォワーダー側の状態変更。 |
| hadr_physical_seeding_forwarder_target_state_change | 物理シード処理のフォワーダー ターゲット側の状態変更。 |
| hadr_physical_seeding_submit_callback | 物理シード処理のコールバック送信イベント。 |
| hadr_physical_seeding_failure | 物理シード処理のエラー イベント。 |
| hadr_physical_seeding_progress | 物理シード処理の進行状況イベント。 |
| hadr_physical_seeding_schedule_long_task_failure | 物理シード処理のスケジュール長期タスク障害イベント。 |
| hadr_automatic_seeding_start | 自動シード処理操作が提出されるときに発生します。 |
| hadr_automatic_seeding_state_transition | 自動シード処理操作が状態を変更するときに発生します。 |
| hadr_automatic_seeding_success | 自動シード処理操作が成功するときに発生します。 |
| hadr_automatic_seeding_failure | 自動シード処理操作が失敗するときに発生します。 |
| hadr_automatic_seeding_timeout | 自動シード処理操作がタイムアウトになるときに発生します。 |
関連項目
ALTER AVAILABILITY GROUP (Transact-SQL)
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示